UNIT 4
Q1 What is transaction processing?
Answer 1
. Transaction Processing
- Transaction – A transaction is a unit of program execution that accesses and possibly updates various data items.
- A transaction is a program including a collection of database operations, executed as a logical unit of data processing.
- Usually, a transaction is initiated by a user program written in a high-level data manipulation language or programming language (for example, SQL, COBOL, C, C++, or Java), where it is delimited by statements (or function calls) of the form begin transaction and end transaction.
- The transaction consists of all operations executed between the begin transaction and end transaction.
- The operations performed in a transaction include one or more of database operations like insert, delete, update or retrieve data.
- It is an atomic process that is either performed into completion entirely or is not performed at all.
- A transaction involving only data retrieval without any data update is called read-only transaction.
- To ensure integrity of the data, we require that the database system maintain the following properties of the transactions:
- Atomicity – Either all operations of the transaction are reflected property in the database, or none are.
- Consistency – Execution of a transaction in isolation (that is, with no other transaction executing concurrently) preserves the consistency of the database.
- Isolation – Even though multiple transactions may execute concurrently, the system guarantees that, for every pair of transactions Ti and Tj, it appears to Ti that either Tj finished execution before Ti started, or Tj started execution after Ti finished. Thus, each transaction is unaware of other transactions executing concurrently in the system.
- Durability – After a transaction completes successfully, the changes it has made to the database persist, even if there are system failures.
In Transaction processing each high level operation can be divided into a number of low level tasks or operations.
Transaction access data using two operations:
- Read (X), which transfers the data item X from the database to a local buffer belonging to the transaction that executed the read operation.
- Write (X), which transfers the data item X from the local buffer of the transaction that executed the write back to the database.
- Modify(X), which modifies the data item X present in the database.
For example, a data update operation can be divided into three tasks −
- Read_item() − reads data item from storage to main memory.
- Modify_item() − change value of item in the main memory.
- Write_item() − write the modified value from main memory to storage.
Database access is restricted to read_item() and write_item() operations. Likewise, for all transactions, read and write forms the basic database operations.
Q2 Explain concurrency control and lost update problem?
Answer 2
Concurrency Control – The process of managing simultaneous operations on the database without having them interfere with one other.
The Need for Concurrency Control
- A major objective in developing a database is to enable many users to access shared data concurrently.
- Concurrent access is relatively easy if all users are only reading data, as there is no way that they can interfere with one another. However, when two or more users are accessing the database simultaneously and at least one is updating data, there may be interference that can result in inconsistencies.
- However, although two transactions may be perfectly correct in themselves, the interleaving of operations in this way may produce an incorrect result, thus compromising the integrity and consistency of the database.
- There are 3 potential problems caused by concurrency:
- Lost Update Problem
- Uncommitted Dependency Problem (Dirty Read Problem)
- Inconsistent Analysis Problem
1. Lost Update Problem
An apparently successfully completed update operation by one user can be overridden by another user. This
Is known as the lost update problem.
Time | T1 | T2 | X |
t1 |
| Begin transaction | 100 |
t2 | Begin transaction | Read(X) | 100 |
t3 | Read(X) | X=X+100 | 100 |
t4 | X=X-10 | Write(X) | 200 |
t5 | Write(X) | Commit | 90 |
t6 | Commit |
| 90 |
From the above figure,
- Transaction T1 is executing concurrently with transaction T2. T1 is withdrawing $10 from an account with balance bal X , initially $100, and T2 is depositing $100 into the same account. If these transactions are executed serially, one after the other with no interleaving of operations, the final balance would be $190 no matter which transactions is performed first.
- Transactions T1 and T2 start at nearly the same time, and both read the balance as $100. T2 increases bal X by $100 to $200 and stores the update in the database. Meanwhile, transaction T1 decrements its copy of bal X by $10 to $90 and stores this value in the database, overwriting the previous update, and thereby ‘losing’ the $100 previously added to the balance.
- The loss of T2’s update is avoided by preventing T1 from reading the value of bal X until after T2’s update has been completed.
2. Uncommitted Dependency (Dirty Read Problem)
- The uncommitted dependency problem occurs when one transaction is allowed to see the intermediate results of another transaction before it has committed.
- Figure below shows an example of an uncommitted dependency that causes an error, using the initial value for balance X as 100. Here, transaction T4 updates X to $200, but it aborts the transaction so that X should be restored to its original value of $100. However, by this time, transaction T3 has read the new value of X ($200) and is using this value as the basis of the $10 reduction, giving a new incorrect balance of $190, instead of $90. The value of X read by T3 is called dirty data, giving rise to the alternative name, the dirty read problem.
- The reason for the rollback is unimportant; it may be that the transaction was in error, perhaps crediting the wrong account. The effect is the assumption by T3 that T4’s update completed successfully, although the update was subsequently rolled back. This problem is avoided by preventing T3 from reading X until after the decision has been made to either commit or abort T4’s effects.
Time | T3 | T4 | X |
t1 |
| Begin transaction | 100 |
t2 |
| Read(X) | 100 |
t3 |
| X=X+100 | 100 |
t4 | Begin transaction | Write(X) | 200 |
t5 | Read (X) |
| 200 |
t6 | X=X-10 | Rollback | 100 |
t7 | Write(X) |
| 190 |
t8 | Commit |
| 190 |
3. Inconsistent Analysis Problem
- The problem of inconsistent analysis occurs when a transaction reads several values from the database but a second transaction updates some of them during the execution of the first.
- For example, a transaction that is summarizing data in a database (for example, totaling balances) will obtain inaccurate results if, while it is executing, other transactions are updating the database.
Time | T5 | T6 | X | Y | Z | Sum |
t1 |
| Begin transaction | 100 | 50 | 2 |
|
t2 | Begin transaction | Sum=0 | 100 | 50 | 25 | 0 |
t3 | Read(X) | Read(X) | 100 | 50 | 25 | 0 |
t4 | X=X-10 | Sum=Sum+X | 100 | 50 | 25 | 100 |
t5 | Write(X) | Read(Y) | 90 | 50 | 25 | 100 |
t6 | Read(Z) | Sum=Sum+Y | 90 | 50 | 25 | 150 |
t7 | Z=Z+10 |
| 90 | 50 | 25 | 150 |
t8 | Write(Z) |
| 90 | 50 | 35 | 150 |
t9 | Commit | Read(Z) | 90 | 50 | 35 | 150 |
t10 |
| Sum=Sum+Z | 90 | 50 | 35 | 185 |
t11 |
| Commit | 90 | 50 | 35 | 185 |
- From above figure, transaction T6 is executing concurrently with transaction T5. Transaction T6 is totaling the balances of account X ($100), account Y ($50) and account Z ($25).
- However, in the meanwhile, transaction T5 has transferred $10 from X to Z, so that T6 now has the wrong result ($10 too high). This problem is avoided by preventing transaction T6 from reading X and Z until after T5 has completed its updates.
Q3 What is serializibility and explain view serisalizibility?
Answer 3
Serializability
- The objective of concurrency control component is to schedule or arrange the transactions in such a way as to avoid any interference. One obvious way of avoiding the interference of the transactions is to execute them serially i.e. one transaction is committed before another is allowed to begin. But in a multi-user environment, where there are hundreds of users and thousands of transactions the serial execution of the transactions is not a viable option. The DBMS will have to find ways and device strategies to maximize concurrency in the system, so that many transactions can execute in parallel without interfering with one another.
- We can ensure consistency of the database under concurrent execution by making sure that any schedule that executed has the same effect as a schedule that could have occurred without any concurrent execution. That is, the schedule should, in some sense, be equivalent to a serial schedule.
- Serializability is a concept that ensures the correctness of the instance of the database under concurrent execution of the transactions.
- We say that a non-serial schedule (concurrent schedule) is correct if it produces the same results a some serial schedule. Such schedule is said to be serializable.
View Seralizability
- Consider two schedules S and S’, where the same set of transactions participates in both schedules. The schedules S and S’ are said to be view equivalent if three conditions are met:
- For each data item Q, if transaction Ti reads the initial value of Q in schedule S, then transaction Ti must, in schedule S’, also read the initial value of Q.
- For each data item Q, if transaction Ti executes read(Q) in schedule S, and if that value was produced by a write(Q) operation executed by transaction Tj , then the read(Q) operation of transaction Ti must, in schedule S’, also read the value of Q that was produced by the same write(Q) operation of transaction Tj .
- For each data item Q, the transaction (if any) that performs the final write(Q) operation in schedule S must perform the final write(Q) operation in schedule S’
- Conditions 1 and 2 ensure that each transaction reads the same values in both schedules and, therefore, performs the same computation. Condition 3, coupled with conditions 1 and 2, and ensures that both schedules result in the same final system state.
- For example, schedule 1 is not view equivalent to schedule 2, since, in schedule 1, the value of account A read by transaction T2 was produced by T1, whereas this case does not hold in schedule 2. However, schedule 1 is view equivalent to schedule 3, because the values of account A and B read by transaction T2 were produced by T1 in both schedules.
Schedule 1(T1 followed by T2) Schedule 2(T2 followed by T1)
T1 | T2 |
| Read(A); |
| Temp=A*0.1; |
| A=A-temp; |
| Write(A); |
| Read(B); |
| B=B+temp; |
| Write(B); |
Read(A); |
|
A=A-50; |
|
Write(A); |
|
Read(B); |
|
B=B+50; |
|
Write(B) |
|
T1 | T2 |
Read(A); |
|
A=A-50; |
|
Write(A); |
|
Read(B); |
|
B=B+50; |
|
Write(B); |
|
| Read(A); |
| Temp=A*0.1; |
| A=A-temp; |
| Write(A); |
| Read(B); |
| Temp=B+temp; |
| Write(B); |
Schedule 3 Schedule 4
Schedule T1 | T2 |
Read(A); |
|
A=A-50; |
|
Write(A); |
|
| Read(A); |
| Temp=A*0.1; |
| A=A-temp; |
| Write(A); |
Read(B); |
|
B=B+50; |
|
Write(B); |
|
| Read(B); |
| B=B+temp; |
| Write(B); |
T1 | T2 | T3 |
Read(Q) |
|
|
| Write(Q) |
|
Write(Q) |
|
|
|
| Write(Q) |
T1 | T2 | T3 |
Read(Q) |
|
|
Write(Q) |
|
|
| Write(Q) |
|
|
| Write(Q) |
Equivalent Serial Schedule
- The concept of view equivalence leads to the concept of view serializability. We say that a schedule S is view serializable if it is view equivalent to a serial schedule.
- For example, Schedule 4 is view serializable. Indeed, it is view equivalent to the serial schedule <T1, T2, T3>, since the one read(Q) instruction reads the initial value of Q in both schedules, and T3 performs the final write of Q in both schedules.
- Every conflict-serializable schedule is also view serializable, but there are view serializable schedules that are not conflict serializable. Indeed, schedule 4 is not conflict serializable, since every pair of consecutive instructions conflicts, and, thus, no swapping of instructions is possible.
- Observe that, in schedule 4, transactions T2 and T3 perform write(Q) operations without having performed a read(Q) operation. Writes of this sort are called blind writes. Blind writes appear in any view-serializable schedule that is not conflict serializable.
Q4 Explain multiversion concurrency schemes?
Answer 4
5 Multiversion Concurrency Control Schemes
- Multiversion schemes is a type of approach that maintains a number of versions of a data item and allocates the right version to a read operation of a transaction.
- Thus unlike other mechanisms a read operation in this mechanism is never rejected.
Side effect of multiversion concurrency control schemes:
- Significantly more storage (RAM and disk) is required to maintain multiple versions. To check unlimited growth of versions, a garbage collection is run when some criteria is satisfied.
Multiversion concurrency control schemes
- The concurrency-control schemes discussed thus far ensure serializability by either delaying an operation or aborting the transaction that issued the operation
- Multiversion schemes keep old versions of data item to increase concurrency.
- Multiversion Timestamp Ordering
- Multiversion Two-Phase Locking
- Each successful write results in the creation of a new version of the data item written.
- Use timestamps to label versions.
- When a read(Q) operation is issued, select an appropriate version of Q based on the timestamp of the transaction, and return the value of the selected version.
- Reads never have to wait as an appropriate version is returned immediately.
Multiversion Timestamp Ordering
- The most common transaction ordering technique used by multiversion schemes is time stamping
- This approach maintains a number of versions of a data item and allocates the right version to a read operation of a transaction.
- Thus unlike other mechanisms a read operation in this mechanism is never rejected.
Side effects of multiversion timestamp ordering:
- Significantly more storage (RAM and disk) is required to maintain multiple versions.
- To check unlimited growth of versions, a garbage collection is run when some criteria is satisfied.
- Each data item Q has a sequence of versions <Q1, Q2,...., Qm>. Each version Qk contains three data fields:
- Content -- the value of version Qk.
- W-timestamp(Qk) -- timestamp of the transaction that created (wrote) version Qk
- R-timestamp(Qk) -- largest timestamp of a transaction that successfully read version Qk .
- When a transaction Ti creates a new version Qk of Q, Qk's W-timestamp and R-timestamp are initialized to TS(Ti).
- R-timestamp of Qk is updated whenever a transaction Tj reads Qk, and TS(Tj) > R-timestamp(Qk).
- Suppose that transaction Ti issues a read(Q) or write(Q) operation. Let Qk denote the version of Q whose write timestamp is the largest write timestamp less than or equal to TS(Ti).
- If transaction Ti issues a read(Q), then the value returned is the content of version Qk.
- If transaction Ti issues a write(Q)
- If TS(Ti) < R-timestamp(Qk), then transaction Ti is rolled back.
- If TS(Ti) = W-timestamp(Qk), the contents of Qk are overwritten
- Else a new version of Q is created.
- Observe that
- Reads always succeed
- A write by Ti is rejected if some other transaction Tj that (in the serialization order defined by the timestamp values) should read
Ti's write, has already read a version created by a transaction older than Ti.
- Protocol guarantees serializability.
Multiversion Two-Phase Locking
The multiversion two-phase locking protocol attempts to combine the advantages of multiversion concurrency control with the advantages of two-phase locking. This protocol differentiates between read-only transactions and update transactions.
- Allow a transaction T’ to read a data item X while it is write locked by a conflicting transaction T.
- This is accomplished by maintaining two versions of each data item X where one version must always have been written by some committed transaction. This means a write operation always creates a new version of X.
- Differentiates between read-only transactions and update transactions.
- Update transactions acquire read and write locks, and hold all locks up to the end of the transaction. That is, update transactions follow rigorous two-phase locking.
- Each successful write results in the creation of a new version of the data item written.
- Each version of a data item has a single timestamp whose value is obtained from a counter ts-counter that is incremented during commit processing.
- Read-only transactions are assigned a timestamp by reading the current value of ts-counter before they start execution; they follow the multiversion timestamp-ordering protocol for performing reads.
- When an update transaction wants to read a data item:
- It obtains a shared lock on it, and reads the latest version.
- When it wants to write an item
- It obtains X lock on; it then creates a new version of the item and sets this version's timestamp to .
- When update transaction Ti completes, commit processing occurs:
- Ti sets timestamp on the versions it has created to ts-counter + 1.
- Ti increments ts-counter by 1.
- Read-only transactions that start after Ti increments ts-counter will see the values updated by Ti.
- Read-only transactions that start before Ti increments the
ts-counter will see the value before the updates by Ti. - Only serializable schedules are produced.
- Versions are deleted in a manner like that of multiversion timestamp ordering.
- Multiversion two-phase locking or variations of it are used in some commercial database systems
Q5 Explain log based database recovery?
Answer 5
Recovery Techniques –
- Log Based recovery technique
- Shadow Paging
Log-Based Recovery
- The most widely used structure for recording database modifications is the log. The log is a sequence of log records, recording all the update activities in the database.
- There are several types of log records. An update log record describes a single database write.
It has these fields:
- Transaction identifier is the unique identifier of the transaction that performed the write operation.
- Data-item identifier is the unique identifier of the data item written. Typically, it is the location on disk of the data item.
- Old value is the value of the data item prior to the write.
- New value is the value that the data item will have after the write. Other special log records exist to record significant events during transaction processing, such as the start of a transaction and the commit or abort of a transaction.
We denote the various types of log records as:
• <Ti start>. Transaction Ti has started.
• <Ti, Xj, V1, V2>. Transaction Ti has performed a write on data item Xj . Xj
Had value V1 before the write, and will have value V2 after the write.
• <Ti commit>. Transaction Ti has committed.
• <Ti abort>. Transaction Ti has aborted.
- Whenever a transaction performs a write, it is essential that the log record for that write be created before the database is modified.
- Once a log record exists, we can output the modification to the database if that is desirable. Also, we have the ability to undo a modification that has already been output to the database.
- We undo it by using the old-value field in log records. For log records to be useful for recovery from system and disk failures, the log must reside in stable storage.
Deferred Database Modification
- The deferred-modification technique ensures transaction atomicity by recording all database modifications in the log, but deferring the execution of all write operations of a transaction until the transaction partially commits.
- When a transaction partially commits, the information on the log associated with the transaction is used in executing the deferred writes. If the system crashes before the transaction completes its execution, or if the transaction aborts, then the information on the log is simply ignored.
- The execution of transaction Ti proceeds as follows.
- Before Ti starts its execution, a record <Ti start> is written to the log.
- A write(X) operation by Ti results in the writing of a new record to the log.
- Finally, when Ti partially commits, a record <Ti commit> is written to the log.
- When transaction Ti partially commits, the records associated with it in the log are used in executing the deferred writes. Since a failure may occur while this updating is taking place, we must ensure that, before the start of these updates, all the log records are written out to stable storage.
- Once they have been written, the actual updating takes place, and the transaction enters the committed state.
- Observe that only the new value of the data item is required by the deferred modification technique.
- Thus, we can simplify the general update-log record structure that we saw in the previous section, by omitting the old-value field.
Immediate Database Modification
- The immediate-modification technique allows database modifications to be output to the database while the transaction is still in the active state.
- Data modifications written by active transactions are called uncommitted modifications.
- In the event of a crash or a transaction failure, the system must use the old-value field of the log records to restore the modified data items to the value they had prior to the start of the transaction.
- The undo operation, described next, accomplishes this restoration. Before a transaction
- Ti starts its execution, the system writes the record <Ti start> to the log. During its execution, any write(X) operation by Ti is preceded by the writing of the appropriate new update record to the log. When Ti partially commits, the system writes the record <Ti commit> to the log.
- Since the information in the log is used in reconstructing the state of the database, we cannot allow the actual update to the database to take place before the corresponding log record is written out to stable storage.
- We therefore require that, before execution of an output(B) operation, the log
Q6 Explain timestamp based locking protocols?
Answer 6
Timestamp Based Protocols
- The locking protocols discussed so far determine the order between every pair of conflicting transactions at execution time by the first lock that both members of the pair request that involves incompatible modes.
- Another method for determining the serializability order is to select an ordering among transactions in advance. The most common method for doing so is to use a timestamp-ordering scheme.
Timestamps
- With each transaction Ti in the system, we associate a unique fixed timestamp, denoted by TS(Ti). This timestamp is assigned by the database system before the transaction Ti starts execution. If a transaction Ti has been assigned timestamp TS(Ti), and a new transaction Tj enters the system, then TS(Ti) < TS(Tj ).
- There are two simple methods for implementing this scheme:
- Use the value of the system clock as the timestamp; that is, a transaction’s timestamp is equal to the value of the clock when the transaction enters the system.
- Use a logical counter that is incremented after a new timestamp has been assigned; that is, a transaction’s timestamp is equal to the value of the counter when the transaction enters the system.
The timestamps of the transactions determine the serializability order. Thus, if TS(Ti) < TS(Tj ), then the system must ensure that the produced schedule is equivalent to a serial schedule in which transaction Ti appears before transaction Tj . To implement this scheme, we associate with each data item Q two timestamp values:
- W-timestamp (Q) ->denotes the largest timestamp of any transaction that executed write(Q) successfully.
- R-timestamp (Q) ->denotes the largest timestamp of any transaction that executed read(Q) successfully.
- These timestamps are updated whenever a new read(Q) or write(Q) instruction is executed.
The Timestamp – Ordering Protocol
- The timestamp-ordering protocol ensures that any conflicting read and write operations are executed in timestamp order. This protocol operates as follows:
- Suppose that transaction Ti issues read(Q).
a) If TS(Ti) < W-timestamp(Q), then Ti needs to read a value of Q that was already overwritten. Hence, the read operation is rejected, and Ti is rolled back.
b) If TS(Ti) ≥ W-timestamp(Q), then the read operation is executed, and R-timestamp(Q) is set to the maximum of R-timestamp(Q) and TS(Ti).
2. Suppose that transaction Ti issues write(Q).
a) If TS(Ti) < R-timestamp(Q), then the value of Q that Ti is producing was needed previously, and the system assumed that that value would never be produced. Hence, the system rejects the write operation and rolls Ti back.
b) If TS(Ti) < W-timestamp(Q), then Ti is attempting to write an obsolete value of Q. Hence, the system rejects this write operation and rolls Ti back.
c) Otherwise, the system executes the write operation and sets W-timestamp (Q) to TS(Ti).
A transaction Ti, that is rolled back by the concurrency-control scheme as result of either a read or write operation being issued is assigned a new timestamp and is restarted.
For example, we consider transactions T1 and T2. Transaction T1 displays the contents of accounts A and B and is defined as:
T1: read(B);
T1 | T2 |
Read(B) |
|
| Read(B) |
| B=B-50 |
| Write(B) |
Read(A) |
|
| Read(A) |
Display(A+B) |
|
| A=A+50 |
| Write(A) |
| Display(A+B) |
Read(A);
Display(A+B).
Transaction T2 transfers $50 from
account A to account B and then shows
The contents of both and is defined as:
T2: read(B);
B = B – 50;
Write(B);
Read(A);
A = A + 50;
Write(A);
Display(A+B);
In presenting schedules under the timestamp protocol, we shall assume that a transaction is assigned a timestamp immediately before its first instruction. Thus, in schedule of Figure (h) TS(T1) < TS(T2), and the schedule is possible under the timestamp protocol.
Q7 What are the states of any transaction processing?
Answer 7
Transaction State
- Sometimes it so happens that a transaction is not completed successfully. Such a transaction is called aborted.
- To ensure the atomicity property, any changes that the aborted transaction has made to the database are undone. When the changes made by an aborted transaction to the database are undone, the transaction is said to have been rolled back. It is part of the responsibility of the recovery scheme to manage transaction aborts.
- The transaction that has completed its execution successfully is said to be committed. If a transaction has committed, its effect cannot be undone.
A transaction must be in one of the following states:
- Active – It is the initial state. While the transaction is being executed, it stays in active state. The transaction remains in this state while it is executing read, write or other operations
- Partially committed – Transaction becomes partially committed after its final statement has been executed.
- Failed – When the normal execution can no longer be carried on. The transaction goes from partially committed state or active state to failed state when it is discovered that normal execution can no longer proceed or system checks fail.
- Aborted – It is the state after the transaction has been rolled back and database has been restore to the state prior to the transaction’s starting.
- Committed – State after the successful completion of transaction. The transaction enters this state after successful completion of the transaction and system checks have issued commit signal.
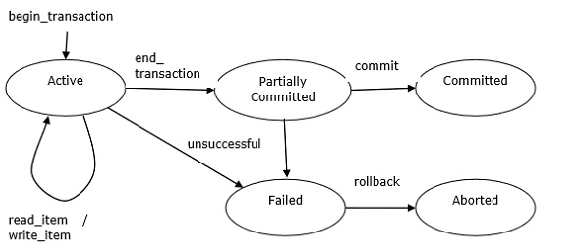
Transaction processing in various states
- We say that a transaction has committed only if it has entered the committing state. Similarly, we say that a transaction has aborted only if it has entered the aborted state. A transaction is said to have terminated if it has either committed or aborted.
- A transaction starts in the active state. When it finishes its final statement, it enters the partially committed state. At this point, the transaction has completed its execution, but it is still possible that it may have to be aborted, since the actual output may still be temporarily residing in main memory, and thus a hardware failure may preclude its successful completion.
- The database system then writes out enough information to disk that, even in the event of a failure, the updates performed by the transaction can be recreated when the system restarts after the failure. When the last of this information is written out, the transaction enters the committed state.
- A transaction enters the failed state after the system determines that the transaction can no longer proceed with its normal execution due to some hardware or logical errors. Such a transaction must be rolled back. Then, it enters the aborted state. At this point, the system has two options:
- It can restart the transaction, but only if the transaction was aborted as a result of some hardware or software errors that were not created though the internal logic of the transaction. A restarted transaction is considered to be a new transaction.
- It can kill the transaction. It usually does so because of some internal logical error that can be corrected only by rewriting the application program, or because the input was bad, or because the desired data were not found in the database.
Q8 Explain lock based protocols?
Answer 8
Lock-based Protocols
Database systems equipped with lock-based protocols use a mechanism by which any transaction cannot read or write data until it acquires an appropriate lock on it. Locks are of two kinds −
- Binary Locks − A lock on a data item can be in two states; it is either locked or unlocked.
- Shared/exclusive − This type of locking mechanism differentiates the locks based on their uses. If a lock is acquired on a data item to perform a write operation, it is an exclusive lock. Allowing more than one transaction to write on the same data item would lead the database into an inconsistent state. Read locks are shared because no data value is being changed.
There are four types of lock protocols available −
1. Simplistic Lock Protocol:- Simplistic lock-based protocols allow transactions to obtain a lock on every object before a 'write' operation is performed. Transactions may unlock the data item after completing the ‘write’ operation.
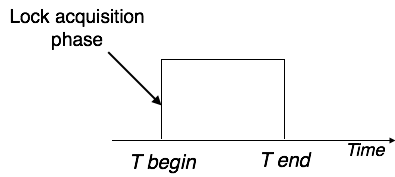
2. Pre-claiming Lock Protocol:- Pre-claiming protocols evaluate their operations and create a list of data items on which they need locks. Before initiating an execution, the transaction requests the system for all the locks it needs beforehand. If all the locks are granted, the transaction executes and releases all the locks when all its operations are over. If all the locks are not granted, the transaction rolls back and waits until all the locks are granted.
3. Two-Phase Locking 2PL:- This locking protocol divides the execution phase of a transaction into three parts. In the first part, when the transaction starts executing, it seeks permission for the locks it requires. The second part is where the transaction acquires all the locks. As soon as the transaction releases its first lock, the third phase starts. In this phase, the transaction cannot demand any new locks; it only releases the acquired locks.
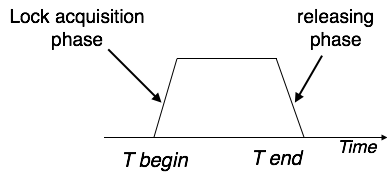
Two-phase locking has two phases, one is growing, where all the locks are being acquired by the transaction; and the second phase is shrinking, where the locks held by the transaction are being released.
To claim an exclusive (write) lock, a transaction must first acquire a shared (read) lock and then upgrade it to an exclusive lock.
4:-Strict Two-Phase Locking:- The first phase of Strict-2PL is same as 2PL. After acquiring all the locks in the first phase, the transaction continues to execute normally. But in contrast to 2PL, Strict-2PL does not release a lock after using it. Strict-2PL holds all the locks until the commit point and releases all the locks at a time.
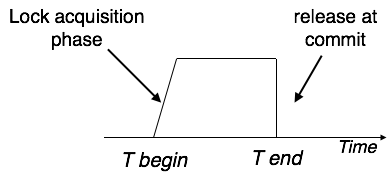
Strict-2PL does not have cascading abort as 2PL does.
Q9 Explain shadow paging based database recovery?
Answer 9
Shadow Paging
- An alternative to log-based crash-recovery techniques is shadow paging. Under certain circumstances, shadow paging may require fewer disk accesses than do the log-based methods.
- There are, however, disadvantages to the shadow-paging approach, as we shall see, that limit its use.
- For example, it is hard to extend shadow paging to allow multiple transactions to execute concurrently.
- As before, the database is partitioned into some number of fixed-length blocks, which are referred to as pages. The term page is borrowed from operating systems, since we are using a paging scheme for memory management.
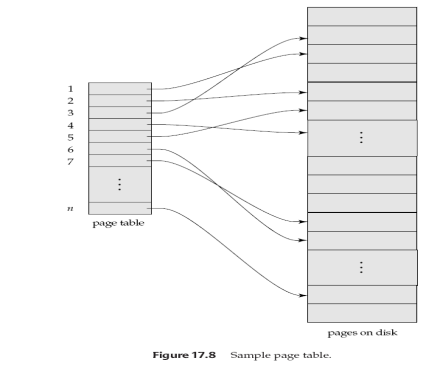
- Assume that there are n pages, numbered 1 through n. These pages do not need to be stored in any particular order on disk. However, there must be a way to find the ith page of the database for any given i.
- The page table has n entries—one for each database page.
- Each entry contains a pointer to a page on disk.
- The first entry contains a pointer to the first page of the database, the second entry points to the second page, and so on.
- The logical order of database pages does not need to correspond to the physical order in which the pages are placed on disk.
- The key idea behind the shadow-paging technique is to maintain two page tables during the life of a transaction: the current page table and the shadow page table.
- When the transaction starts, both page tables are identical.
- The shadow page table is never changed over the duration of the transaction. The current page table may be changed when a transaction performs a write operation.
- All input and output operations use the current page table to locate database pages on disk. Suppose that the transaction Tj performs a write(X) operation, and that X resides on the ith page. The system executes the write operation as follows:
- If the ith page (that is, the page on which X resides) is not already in main memory, then the system issues input(X).
- If this is the write first performed on the ith page by this transaction, then the system modifies the current page table as follows:
- It finds an unused page on disk. Usually, the database system has access to a list of unused (free) pages
- It deletes the page found in step 2a from the list of free page frames; it copies the contents of the ith page to the page found in step 2a.
- It modifies the current page table so that the ith entry points to the page found in step 2a.
- It assigns the value of xj to X in the buffer page.
- Ensure that all buffer pages in main memory that have been changed by the transaction are output to disk.
- Output the current page table to disk. Note that we must not overwrite the shadow page table, since we may need it for recovery from a crash.
Output the disk address of the current page table to the fixed location in stable storage containing the address of the shadow page table. This action overwrites the address of the old shadow page table. Therefore, the current page table has become the shadow page table, and the transaction is committed
Q10 Explain conflict serializibility?
Answer 10
Conflict Serializability
- Let us consider a schedule S in which there are two consecutive instructions Ii and Ij, of transactions Ti and Tj , respectively (i ≠ j). If Ii and Ij refer to different data items, then we can swap Ii and Ij without affecting the results of any instruction in the schedule. However, if Ii and Ij refer to the same data item Q, then the order of the two steps may matter. Since we are dealing with only read and write instructions, there are four cases that we need to consider:
- Ii = read(Q), Ij = read(Q). The order of Ii and Ij does not matter, since the same value of Q is read by Ti and Tj , regardless of the order.
- Ii = read(Q), Ij = write(Q). If Ii comes before Ij, then Ti does not read the value of Q that is written by Tj in instruction Ij. If Ij comes before Ii, then Ti reads the value of Q that is written by Tj. Thus, the order of Ii and Ij matters.
- Ii = write(Q), Ij = read(Q). The order of Ii and Ij matters for reasons similar to those of the previous case.
- Ii = write(Q), Ij = write(Q). Since both instructions are write operations, the order of these instructions does not affect either Ti or Tj . However, the value obtained by the next read(Q) instruction of S is affected, since the result of only the latter of the two write instructions is preserved in the database. If there is no other write(Q) instruction after Ii and Ij in S, then the order of Ii and Ij directly affects the final value of Q in the database state that results from schedule S.
- Thus, only in the case where both Ii and Ij are read instructions does the relative order of their execution not matter.
- We say that Ii and Ij conflict if they are operations by different transactions on the same data item, and at least one of these instructions is a write operation.
- For example, consider the following schedule 1 where only the read and write operations are shown:
Schedule 1
T1 | T2 |
Read(A) |
|
Write(A) |
|
| Read(A) |
| Write(A) |
Read(B) |
|
Write(B) |
|
| Read(B) |
| Write(B) |
In this schedule, the write(A) instruction of T1 conflicts with the read(A) instruction of T2. However, the write(A) instruction of T2 does not conflict with the read(B) instruction of T1, because the two instructions access different data items.
Let Ii and Ij be consecutive instructions of a schedule S. If Ii and Ij are instructions of different transactions and Ii and Ij do not conflict, then we can swap the order of Ii and Ij to produce a new schedule S’. We expect S to be equivalent to S’, since all instructions appear in the same order in both schedules except for Ii and Ij,
Whose order does not matter.
Since the write(A) instruction of T2 in schedule 3does not conflict with the read(B) instruction of T1, we can swap these instructions to generate an equivalent schedule, schedule 4. Regardless of the initial system state, schedules 3 and 4 both produce the same final system state.
We continue to swap non-conflicting instructions:
- Swap the read(B) instruction of T1 with the read(A) instruction of T2.
- Swap the write(B) instruction of T1 with the write(A) instruction of T2.
- Swap the write(B) instruction of T1 with the read(A) instruction of T2.
The final result of these swaps, schedule 3, is a serial schedule. Thus, we have shown that schedule 1 is equivalent to a serial schedule. This equivalence implies that, regardless of the initial system state, schedule 1 will produce the same final state as will some serial schedule.
Schedule 2 Schedule 3
T1 | T2 |
Read(A) |
|
Write(A) |
|
| Read(A) |
Read(B) |
|
| Write(A) |
Write(B) |
|
| Read(B) |
| Write(B) |
T1 | T2 |
Read(A) |
|
Write(A) |
|
Read(B) |
|
Write(B) |
|
| Read(A) |
| Write(A) |
| Read(B) |
| Write(B) |
- If a schedule S can be transformed into a schedule S’ by a series of swaps of non-conflicting instructions, we say that S and S’ are conflict equivalent.
- The concept of conflict equivalence leads to the concept of conflict serializability.
- We say that a schedule S is conflict serializable if it is conflict equivalent to a serial schedule. Thus, schedule 3 is conflict serializable, since it is conflict equivalent to the serial schedule 1.




