UNIT 6
Q1). What is object oriented database?
Answer 1
Object-Oriented Database (OORD)
- Object oriented database serves two main purposes:
- It connects the divide between relational databases and the object-oriented modeling techniques that are usually used in programming languages like C#, Java and C++.
- It bridges the gap between conceptual data modeling techniques for relational and object-oriented databases like entry-relationship diagram (ERD) and object-relational mapping (ORM).
- An object-oriented database is organized around objects rather than actions and data rather than logic.
- The main feature of object-oriented databases is allowing the definition of objects, which are different from normal database objects.
- Objects, in an object-oriented database, reference the ability to develop a product, then define and name it.
- The object can then be referenced, or called later, as a unit without having to go into its complexities. This is very similar to objects used in object-oriented programming.
- Therefore, an object database is a database management system in which information is represented in the form of objects as used in object-oriented programming.
- Usually, when OODBMS is integrated with an object programming language, there is a much greater consistency between the database and the programming language because both use the same model of data representation.
- When compared to a relational database management system, an object-oriented database stores complex data and relationships between data directly, without mapping to relational rows and columns whereas a relational database stores information in tables with rows and columns.
- Examples of object-oriented database engines include db4o, Smalltalk and Cache.
Features Of Object Oriented Database (OODBMS)
- In object oriented database, relationships are represented by references via the object identifier (OID).
- Object oriented systems employ indexing techniques to locate disk pages that store the object. Therefore, they are able to provide persistent storage for complex-structured objects.
- Handles larger and complex data than RDBMS.
- The constraints supported by object oriented systems vary from system to system.
- In object oriented systems, the data management language is typically incorporated into a programming language such as #C++.
- Stores data entries are described as object.
- Object oriented database can handle different types of data.
- In the object oriented database, the data is stored in the form of objects.
S No | Basis of Comparison | Object Relational Database(ORDBMS) | Object Oriented Database(OODBMS) |
1 | Connection Between Two Relations | Connections between two relations are represented by foreign key attributes in one relation that reference the primary key of another relation. | Relationships are represented by references via the object identifier (OID). |
2 | Data Storage Structure | It does not specify any data storage structure, each base relation is implemented as separate file and therefore, they are unable to provide persistent storage for complex-structured objects | It employs indexing techniques to locate disk pages that store the object. Therefore, they are able to provide persistent storage for complex-structured objects. |
3 | Quantity Of Data | Handles comparatively simpler data. | Handles larger and complex data than RDBMS. |
4 | Constraints | It has keys, entity integrity and referential integrity. | The constraints supported by this system vary from system to system. |
5 | Data Manipulation Language | There are data manipulation languages such as SQL, QUEL and QBE which are based on relational calculus. | The data management language is typically incorporated into a programming language such as #C++. |
6 | Description Of Stored Data | Stores data in entries is described as tables. | Stores data entries are described as object. |
7 | Type Of Data | Relational database can handle a single type of data. | Object oriented database can handle different types of data. |
8 | Data Storage | Data is stored in the form of tables, which contains rows and column. | The data is stored in the form of objects. |
Q2). Explain logical database and what views and tasks oriented in logical database?
Answer 2
Logical Databases
- Logical database design is the process of transforming (or mapping) a conceptual schema of the application domain into a schema for the data model underlying a particular DBMS, such as the relational or object-oriented data model.
- Logical databases are special ABAP programs that retrieve data and make it available to application programs.
- The most common use of logical databases is still to read data from database tables and associate them with executable ABAP programs while defining the program contents. You edit logical databases using Logical Database Builder in ABAP Workbench
- Logical databases contain Open SQL statements that read data from the database.
- This mapping can be understood as the result of trying to achieve two distinct sets of goals:
- Representation goal: preserving the ability to capture and distinguish all valid states of the conceptual schema;
- Data management goals: addressing issues related to the ease and cost of querying the logical schema, as well as costs of storage and constraint maintenance.
- This entry focuses mostly on the mapping of (Extended) Entity-Relationship (EER) diagrams to relational database
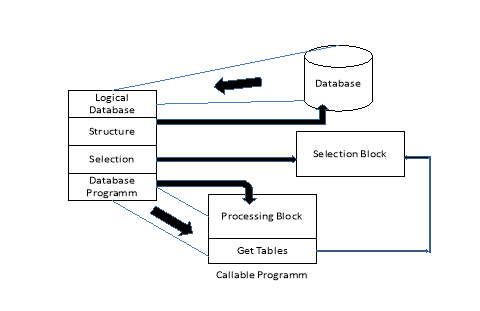
Figure: - Logical Database
Data Views in Logical Databases
- Logical databases provide a particular view of database tables.
- It is appropriate to use logical databases if the database tables you want to read correspond largely to the structure of the logical database and where the flow of the system program (select > read > process > display) meets the requirements of the application.
- The data structure in a logical database is hierarchical. Many tables in the SAP system are linked to each other using foreign key relationships. Some of these dependencies form tree-like hierarchical structures. Logical databases read data from database tables that are part of these structures.
Tasks of Logical Databases
- Logical databases serve mainly to reuse predefined functions for reading data from database tables, but they can also be programmed for other tasks. To keep the application logic of application programs free from technical details, logical databases can perform the following tasks:
- Reading the same data for multiple programs
- The individual programs do not then need to know the exact structure of the relevant database tables (and especially not their foreign key relationships). Instead, they can rely on the logical database to read the database entries in the right order during the GET event.
- Defining the same user interface for multiple programs
- Each program that uses the same logical databases uses the selection screens of these databases as user interfaces.
- Central authorization checks
- Authorization checks for centralized sensitive data can be programmed centrally in the database to prevent them from being bypassed by simple application programs.
Q3). Explain distributed Database?
Answer 3
Distributed Database
Definition - A distributed database is a collection of multiple interconnected databases, which are spread physically across various locations that communicate via a computer network.
Features:
- Databases in the collection are logically interrelated with each other. Often they represent a single logical database.
- Data is physically stored across multiple sites. Data in each site can be managed by a DBMS independent of the other sites.
- The processors in the sites are connected via a network. They do not have any multiprocessor configuration.
- A distributed database is not a loosely connected file system.
- A distributed database incorporates transaction processing, but it is not synonymous with a transaction processing system.
Distributed Database Management System
Figure: Distributed Database System
A distributed database management system (DDBMS) is a centralized software system that manages a distributed database in a manner as if it were all stored in a single location.
Features:
- It is used to create, retrieve, update and delete distributed databases.
- It synchronizes the database periodically and provides access mechanisms by the virtue of which the distribution becomes transparent to the users.
- It ensures that the data modified at any site is universally updated.
- It is used in application areas where large volumes of data are processed and accessed by numerous users simultaneously.
- It is designed for heterogeneous database platforms.
- It maintains confidentiality and data integrity of the databases.
Properties of distributed database system
- Distributed data independence:
- Users should be able to ask queries without specifying where the referenced relations, or copies or fragments of the relations, are located.
- This principle is a natural extension of physical and logical data Independence.
- Queries that span multiple sites should be optimized systematically in a cost-based manner, taking into account communication costs and differences in local computation costs.
2. Distributed transaction atomicity:
- Users should be able to write transactions that access and update data at several sites just as they would write transactions over purely local data.
- In particular, the effects of a transaction across sites should continue to be atomic; that is, all changes persist if the transaction commits, and none persist if it aborts.
Factors Encouraging DDBMS
- Distributed Nature of Organizational Units − Most organizations in the current times are subdivided into multiple units that are physically distributed over the globe. Each unit requires its own set of local data. Thus, the overall database of the organization becomes distributed.
- Need for Sharing of Data − The multiple organizational units often need to communicate with each other and share their data and resources. This demands common databases or replicated databases that should be used in a synchronized manner.
- Support for Both OLTP and OLAP − Online Transaction Processing (OLTP) and Online Analytical Processing (OLAP) work upon diversified systems which may have common data. Distributed database systems aid both these processing by providing synchronized data.
- Database Recovery − One of the common techniques used in DDBMS is replication of data across different sites. Replication of data automatically helps in data recovery if database in any site is damaged. Users can access data from other sites while the damaged site is being reconstructed. Thus, database failure may become almost inconspicuous to users.
- Support for Multiple Application Software − Most organizations use a variety of application software each with its specific database support. DDBMS provides a uniform functionality for using the same data among different platforms.
Advantages of Distributed Databases:-
- Modular Development − If the system needs to be expanded to new locations or new units, in centralized database systems, the action requires substantial efforts and disruption in the existing functioning. However, in distributed databases, the work simply requires adding new computers and local data to the new site and finally connecting them to the distributed system, with no interruption in current functions.
- More Reliable − In case of database failures, the total system of centralized databases comes to a halt. However, in distributed systems, when a component fails, the functioning of the system continues may be at a reduced performance. Hence DDBMS is more reliable.
- Better Response − If data is distributed in an efficient manner, then user requests can be met from local data itself, thus providing faster response. On the other hand, in centralized systems, all queries have to pass through the central computer for processing, which increases the response time.
- Lower Communication Cost − In distributed database systems, if data is located locally where it is mostly used, then the communication costs for data manipulation can be minimized. This is not feasible in centralized systems.
Q4). Explain data warehousing and why it’s needed?
Answer 4
Data warehouse: - The term Data Warehouse was coined by Bill Inmon in 1990, which he defined in the following way: "A warehouse is a subject-oriented, integrated, time-variant and non-volatile collection of data in support of management's decision making process". He defined the terms in the sentence as follows:
- Subject Oriented: Data that gives information about a particular subject instead of about a company's ongoing operations.
- Integrated: Data that is gathered into the data warehouse from a variety of sources and merged into a coherent whole.
- Time-variant: All data in the data warehouse is identified with a particular time period.
- Non-volatile: Data is stable in a data warehouse. More data is added but data is never removed. This enables management to gain a consistent picture of the business.
- Granularity: Data granularity in a data warehouse refers to the level of detail. The lower the level of detail, the finer the data granularity. Of course, if you want to keep data in the lowest level of detail, you have to store a lot of data in the data warehouse. You will have to decide on the granularity levels based on the data types and the expected system performance for queries.
Need for Data Warehousing:
- Industry has huge amount of operational data
- Knowledge worker wants to turn this data into useful information.
- This information is used by them to support strategic decision making.
- It is a platform for consolidated historical data for analysis.
- It stores data of good quality so that knowledge worker can make correct decisions.
- In most organization data about specific part of business is there which contains lots and lots of data somewhere in some form.
- To help worker in their everyday business activity & improve their activity.
- To help knowledge workers make faster & better decisions.
- Bring together info from multiple sources as to provide a consistent database source for DSS.
- Range from desktop to high warehouse.
- Two types of application: 1) Operational. 2) Analytical.
- Support current and historical decision support info, i.e. hand to hand access or presently traditional operational data store.
- Requires sharing the discovery & exploration of important business trends & dependencies that otherwise would have unnoticed.
- Information need of strategic business opportunity.
- Business climate of a global market place.
- In order to survive & succeed in today’s highly competitive global environment.
- Decisions need to be made quickly & correctly using all available data.
- Users are business domain experts not computer professionals
- The amount of data doubles every 18 months, which effects response time & the shear ability to comprehend its control.
- Competition is heating up in the areas of business intelligence & added info value.
- Address the incompatibility of informational & transactional systems.
- Technological aspects
- Price of computer processing speed continuous to decline.
- N/w bandwidth is increasing while price of high bandwidth is decreasing.
- Workplace is increasingly heterogeneous in terms of H/w & S/W.
- Legacy system can be integrated with new approach.
- From business perspective
- It is latest marketing weapon
- Helps to keep customers by learning more about their needs.
- Valuable tool in today’s competitive fast evolving world.
Q5). What is data mining and explain data mining architecture?
Answer 5
Data Mining
Data mining refers to extracting or mining interesting (non-trivial, implicit, previously unknown and potentially useful) information or patterns from large amount of data/large databases.
Data mining is a multidisciplinary field, drawing work from areas including database technology, artificial intelligence, machine learning, neural networks, statistics, pattern recognition, knowledge based systems, knowledge acquisition, information retrieval, high performance computing, and data visualization.
Architecture of typical data mining system-
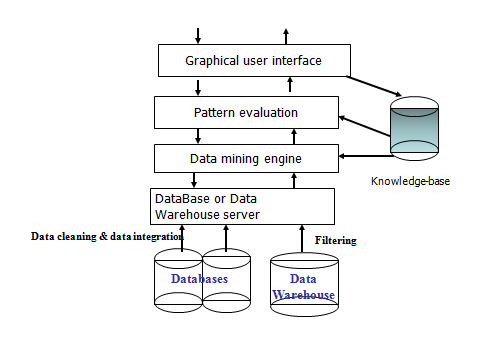
Figure: Architecture of Typical Data Mining System
Architecture of typical data mining system
1) Database, data warehouse, or other information repository-.
- This is one or a set of databases, data-warehouses, spread sheets, or other kinds of information repositories. Data cleaning and data integration techniques may be performed on the data.
2) Database or data warehouse server-.
- The database or data warehouse server is responsible for fetching the relevant data, based on the user's data mining request.
3) Knowledge base-.
- This is the domain knowledge that is used to guide the search, or evaluate the interestingness of resulting patterns.
- Such knowledge can include concept hierarchies, used to organize attributes or attribute values into different levels of abstraction. Knowledge such as user beliefs, which can be used to assess a pattern's interestingness based on its unexpectedness, may also be included.
- Other examples of domain knowledge are additional interestingness constraints or thresholds, and metadata (e.g., describing data from multiple heterogeneous sources).
4) Data mining engine-.
- This is essential to the data mining system and ideally consists of a set of functional modules for tasks such as characterization, association analysis, classification, evolution and deviation analysis.
5) Pattern evaluation module.
- This component typically employs interestingness measures and interacts with the data mining modules so as to focus the search towards interesting patterns.
- It may access interestingness thresholds stored in the knowledge base. Alternatively, the pattern evaluation module may be integrated with the mining module, depending on the implementation of the data mining method used.
- For efficient data mining, it is highly recommended to push the evaluation of pattern interestingness as deep as possible into the mining process so as to confine the search to only the interesting patterns.
6) Graphical user interface.-
- This module communicates between users and the data mining system, allowing the user to interact with the system by specifying a data mining query or task, providing information to help focus the search, and performing exploratory data mining based on the intermediate data mining results.
- In addition, this component allows the user to browse database and data warehouse schemas or data structures, evaluate mined patterns, and visualize the patterns in different forms.
Q6 How object oriented database differ from object relational database?
Answer 6
S No | Basis of Comparison | Object Relational Database(ORDBMS) | Object Oriented Database(OODBMS) |
1 | Connection Between Two Relations | Connections between two relations are represented by foreign key attributes in one relation that reference the primary key of another relation. | Relationships are represented by references via the object identifier (OID). |
2 | Data Storage Structure | It does not specify any data storage structure, each base relation is implemented as separate file and therefore, they are unable to provide persistent storage for complex-structured objects | It employs indexing techniques to locate disk pages that store the object. Therefore, they are able to provide persistent storage for complex-structured objects. |
3 | Quantity Of Data | Handles comparatively simpler data. | Handles larger and complex data than RDBMS. |
4 | Constraints | It has keys, entity integrity and referential integrity. | The constraints supported by this system vary from system to system. |
5 | Data Manipulation Language | There are data manipulation languages such as SQL, QUEL and QBE which are based on relational calculus. | The data management language is typically incorporated into a programming language such as #C++. |
6 | Description Of Stored Data | Stores data in entries is described as tables. | Stores data entries are described as object. |
7 | Type Of Data | Relational database can handle a single type of data. | Object oriented database can handle different types of data. |
8 | Data Storage | Data is stored in the form of tables, which contains rows and column. | The data is stored in the form of objects. |
Q7 What are the types of data mining
Answer 7
Text mining:
- Application of data mining to textual documents.
- Cluster web pages to find related pages
- Cluster pages a user has visited to organize their visit history
- Classify Web pages automatically into a Web directory
Data visualization
- Data visualization systems help users examine large volumes of data and detect patterns visually.
- Can visually encode large amounts of information on a single screen
- Humans are very good a detecting visual patterns.
Spatial Mining
- Spatial data are data that have a spatial or location component.
- Spatial data viewed as data about objects that themselves are stored in a physical space.
- This may be implemented with a specific location attribute(s) such as address or latitude/longitude or may be more implicitly included such as by partitioning of database based on location.
- Spatial data can be accessed using queries containing spatial operators such as near, north, south, adjacent and contained in.
- Spatial data are stored in spatial databases that contain the spatial and nonspatial data about objects, because of inherent distance information associated with spatial data.
- Spatial databases are stored using special data structures or indices built using distance or topological information.
- Geographical Information System (GIS) are used to store information related to geographic locations on the surface of earth.
- This includes application related to weather, community infrastructure needs, and disaster management.
- Data mining activities include prediction of environmental catastrophes.
- Biomedical applications including medical Imaging and Illness Diagnosis.
Temporal Data Mining:-
- By taking into account the time aspect of data in mining techniques, we gain some insight into the temporal arrangement of events and thus an ability to discover cause and effect.
- Temporal data mining is NonTrivial Extraction of implicit, potentially useful and previously unrecorded information with an implicit or explicit temporal content, from large quantities of data.
- It has the capability to infer causal and temporal proximity relationships.
- Data mining from temporal data is not temporal data mining, if the temporal component is either ignored or treated as a simple numerical attribute.
- Temporal rules cannot be mined from a database which is free of temporal components by traditional (non-temporal) data mining techniques. Thus, the underlying database must be a temporal one and specific temporal data mining techniques are also necessary.
- Mining of Temporal data involves many of the conventional data mining activities of course, is complicated by temporal aspect and more complicated types of queries.
- Time series data may be clustered based on similarities found. Determining similarity between two different sets of time series data is difficult.
Sequence Mining:-
• Sequence
• A sequence is an ordered list of events. A sequence, α is denoted as α1-> α2-> α3 where αi is an event A sequence is called a k-sequence, if the sum of the cardinalities of αi, is k.
• Subsequence
• A subsequence is a sequence within a sequence preserving the order .in other words, its items need not be adjacent in time but their ordering in a sequence should not violate the time ordering of the supporting events.
• A subsequence can be obtain from a sequence by deleting some items and/or events
• The Sequence s=(α1->α2->….. αn) is said to be subsequence of s1 =(β1->β2->…. Βn) if there exists indices t1<t2<t3,…..tq of s1 such that α1
• A sequence S1 is said to support another sequence s if s is a subsequence of S1 Let D be the Database of input sequences and a sequence is a set of temporally ordered transaction.
• Frequency-
• The frequency of a sequence s, with respect to this database D, is the total number of input sequence in D that support it.
• Frequent Sequence-
• A frequent sequence is a sequence whose frequency exceeds some user-specified Threshold A. Frequent set is maximal if it is not a subsequence of another frequent sequence.
• An efficient approach to mining causal relations is sequence mining.
• Sequence mining has application domain such DNA sequence , signal processing ,and speech analysis which require mining of sequence data, even though there is no explicit temporality in the data,
• Discovering sequential patterns from a large database of sequences has been recognized as an important problem in the field of knowledge discovery and data mining.
• Given a set of data sequences the problem is to discover subsequences that are frequent, in the sense that the percentage of data sequences containing them exceeds a user-specified minimum support.
Q8 Explain object relational database?
Answer 8
Object Relational Database (ORD)
- An object-relational database (ORD) is a database management system (DBMS) that’s composed of both a relational database management system (RDBMS) and an object-oriented database management system (OODBMS).
- An object-relational database acts as an interface between relational and object-oriented databases because it contains aspects and characteristics from both models.
- ORD is said to be the middleman between relational and object-oriented databases because it contains aspects and characteristics from both models.
- In ORD, the basic approach is based on RDB, since the data is stored in a traditional database and manipulated and accessed using queries written in a query language like SQL
- APIs are used to store and access the data as objects.
- ORD’s aims is to bridge the gap between conceptual data modeling techniques for relational and object-oriented databases like the entity-relationship diagram (ERD) and object-relational mapping (ORM).
- It also aims to connect the divide between relational databases and the object-oriented modeling techniques that are usually used in programming languages like Java, C# and C++.
- ORDBMS has a feature that allows developers to build and innovate their own data types and methods, which can be applied to the DBMS.
- ORDBMS intends to allow developers to increase the abstraction with which they view the problem area..
- Objects perform computation and process by making requests of one another through the passing of messages. This allows the data to be worked on by the process in place.
- Every object has its own memory, which consists of other objects that are replications of its image. This is the history of the object that allows information to persist as objects after the process is complete.
- Every object is an instantiation or instance of a class. A class groups, collects, or encompasses similar objects.
- The class is also the repository for behavior or process actions associated with an object. These can be broken down into subclasses and superclasses.
- Classes are most often organized into singly rooted tree structures, called inheritance hierarchies.
- Sometimes in complex systems, the classes have developed multiple inheritances, in which case the inheritance hierarchy really becomes a cross-reference hierarchy or lattice hierarchy.
Features of Object Relational Database Management System (ORDBMS)
- In object t relational database, connections between two relations are represented by foreign key attributes in one relation that reference the primary key of another relation.
- Relational database systems do not specify any data storage structure, each base relation is implemented as separate file and therefore, they are unable to provide persistent storage for complex-structured objects.
- Handles comparatively simpler data.
- Object oriented database has keys, entity integrity and referential integrity.
- In relational database systems there are data manipulation languages such as SQL, QUEL and QBE which are based on relational calculus.
- Stores data in entries is described as tables.
- Relational database can handle a single type of data.
- In relational database, data is stored in the form of tables, which contains rows and column.
- Classes are implemented as user-defined data types (UDTs). A new UDT may inherit from an existing UDT, although multiple inheritance is not allowed.
- A UDT will have default accessor and mutator methods, as well as a default constructor, each of which can be overridden by a database programmer.
- UDTs may have methods defined with them. Methods may be overloaded. Polymorphism is supported. Relational databases, however, have no concept of storing procedures with data.
Q9 What is web based database?
Answer 9
Web Database:-
- A web database is essentially a database that can be accessed from a local network or the internet instead of one that has its data stored on a desktop or its attached storage.
- Website operators can manage this collection of data and present analytical results based on the data in the Web database application.
- Databases first appeared in the 1990s, and have been an asset for businesses, allowing the collection of seemingly infinite amounts of data from infinite amounts of customers.
- A web database is essentially a database that can be accessed from a local network or the internet instead of one that has its data stored on a desktop or its attached storage.
- One of the types of web databases that you may be more familiar with is a relational database.
- Relational databases allow you to store data in groups (known as tables), through its ability to link records together.
- It uses indexes and keys, which are added to data, to locate information fields stored in the database, enabling you to retrieve information quickly.
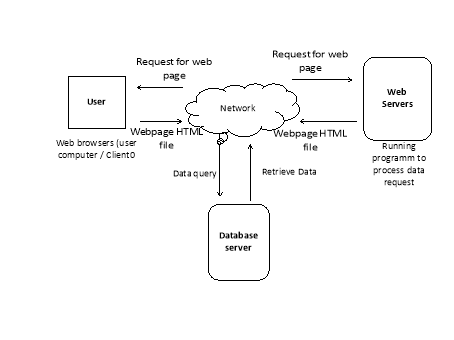
Figure: - Web Database
Some advantages of using a web database include:-
- Web database applications can be free or require payment, usually through monthly subscriptions. Because of this, you pay for the amount you use. So whether your business shrinks or expands, your needs can be accommodated by the amount of server space. You also don’t have to fork out for the cost of installing an entire software program.
- The information is accessible from almost any device. Having things stored in a cloud means that it is not stuck to one computer. As long as you are granted access, you can technically get a hold of the data from just about any compatible device.
- Web database programs usually come with their own technical support team so your IT department folks can focus on other pressing company matters.
- It’s convenient: web databases allow users to update information so all you have to do is to create simple web forms.
Q10 What are the features of object relational database and object oriented database?
Answer 10
Features of Object Oriented Database (OODBMS)
- In object oriented database, relationships are represented by references via the object identifier (OID).
- Object oriented systems employ indexing techniques to locate disk pages that store the object. Therefore, they are able to provide persistent storage for complex-structured objects.
- Handles larger and complex data than RDBMS.
- The constraints supported by object oriented systems vary from system to system.
- In object oriented systems, the data management language is typically incorporated into a programming language such as #C++.
- Stores data entries are described as object.
- Object oriented database can handle different types of data.
- In the object oriented database, the data is stored in the form of objects.
Features of Object Relational Database Management System (ORDBMS)
- In object t relational database, connections between two relations are represented by foreign key attributes in one relation that reference the primary key of another relation.
- Relational database systems do not specify any data storage structure, each base relation is implemented as separate file and therefore, they are unable to provide persistent storage for complex-structured objects.
- Handles comparatively simpler data.
- Object oriented database has keys, entity integrity and referential integrity.
- In relational database systems there are data manipulation languages such as SQL, QUEL and QBE which are based on relational calculus.
- Stores data in entries is described as tables.
- Relational database can handle a single type of data.
- In relational database, data is stored in the form of tables, which contains rows and column.
- Classes are implemented as user-defined data types (UDTs). A new UDT may inherit from an existing UDT, although multiple inheritance is not allowed.
- A UDT will have default accessor and mutator methods, as well as a default constructor, each of which can be overridden by a database programmer.
- UDTs may have methods defined with them. Methods may be overloaded. Polymorphism is supported. Relational databases, however, have no concept of storing procedures with data.




