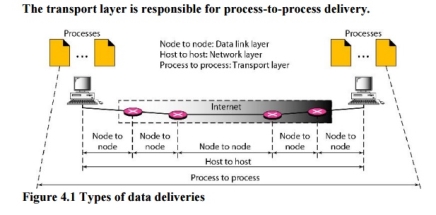
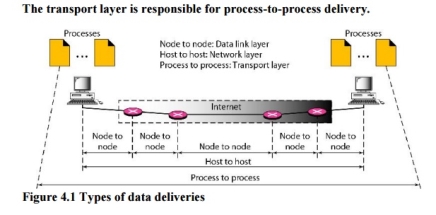
The data link layer is responsible for delivery of frames between two neighbouring nodes over a link. This is called node-to-node delivery. The network layer is responsible for delivery of datagrams between two hosts. This is called host-to-host delivery. Real communication takes place between two processes (application programs). We need process-to-process delivery. The transport layer is responsible for process-to-process delivery-the delivery of a packet, part of a message, from one process to another. Figure 4.1 shows these three types of deliveries and their domains
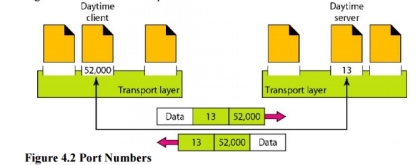
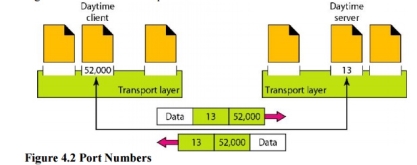
1. Client/Server Paradigm Although there are several ways to achieve process-to-process communication, the most common one is through the client/server paradigm. A process on the local host, called a client, needs services from a process usually on the remote host, called a server. Both processes (client and server) have the same name. For example, to get the day and time from a remote machine, we need a Daytime client process running on the local host and a Daytime server process running on a remote machine. For communication, we must define the following: 1. Local host 2. Local process 3. Remote host 4. Remote process 2. Addressing Whenever we need to deliver something to one specific destination among many, we need an address. At the data link layer, we need a MAC address to choose one node among several nodes if the connection is not point-to-point. A frame in the data link layer needs a Destination MAC address for delivery and a source address for the next node's reply. Figure 4.2 shows this concept.
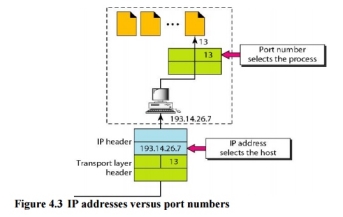
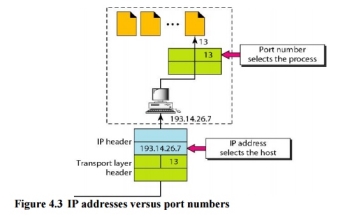
The IP addresses and port numbers play different roles in selecting the final destination of data. The destination IP address defines the host among the different hosts in the world. After the host has been selected, the port number defines one of the processes on this particular host (see Figure 4.3).
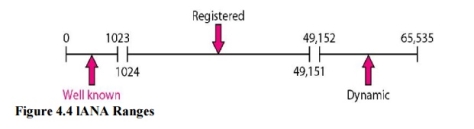
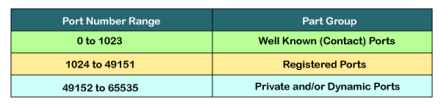
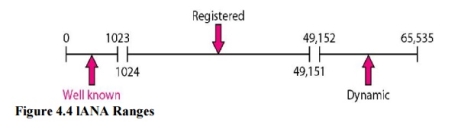
3. lANA Ranges The lANA (Internet Assigned Number Authority) has divided the port numbers into three ranges: well known, registered, and dynamic (or private), as shown in Figure 4.4. Well-known ports. The ports ranging from 0 to 1023 are assigned and controlledby lANA. These are the well-known ports. Registered ports. The ports ranging from 1024 to 49,151 are not assigned orcontrolled by lANA. They can only be registered with lANA to prevent duplication. Dynamic ports. The ports ranging from 49,152 to 65,535 are neither controllednor registered. They can be used by any process. These are the ephemeral ports.
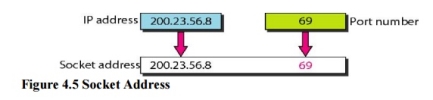
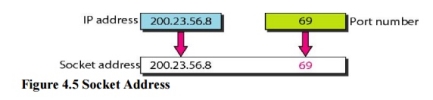
4. Socket Addresses Process-to-process delivery needs two identifiers, IP address and the port number, at each end to make a connection. The combination of an IP address and a port number is called a socket address. The client socket address defines the client process uniquely just as the server socket address defines the server process uniquely (see Figure 4.5). UDP or TCP header contains the port numbers.
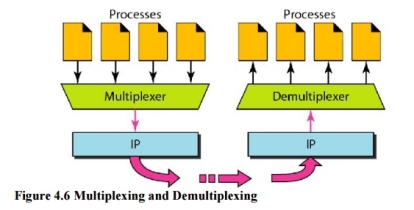
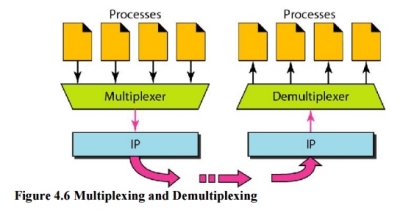
5. Multiplexing and Demultiplexing The addressing mechanism allows multiplexing and demultiplexing by the transport layer, as shown in Figure 4.6. Multiplexing At the sender site, there may be several processes that need to send packets. However, there is only one transport layer protocol at any time. This is a many-to-one relationship and requires multiplexing. Demultiplexing At the receiver site, the relationship is one-to-many and requires demultiplexing. The transport layer receives datagrams from the network layer. After error checking and dropping of the header, the transport layer delivers each message to the appropriate process based on the port number.
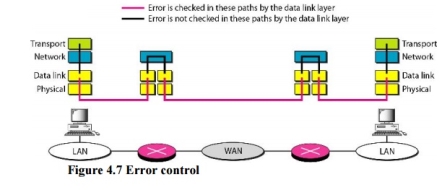
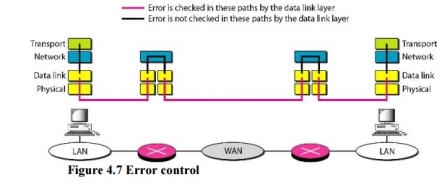
6. Connectionless Versus Connection-Oriented Service A transport layer protocol can either be connectionless or connection-oriented. Connectionless Service In a connectionless service, the packets are sent from one party to another with no need for connection establishment or connection release. The packets are not numbered; they may be delayed or lost or may arrive out of sequence. There is no acknowledgment either. Connection~Oriented Service In a connection-oriented service, a connection is first established between the sender and the receiver. Data are transferred. At the end, the connection is released. 7. Reliable Versus Unreliable The transport layer service can be reliable or unreliable. If the application layer program needs reliability, we use a reliable transport layer protocol by implementing flow and error control at the transport layer. This means a slower and more complex service. In the Internet, there are three common different transport layer protocols. UDP is connectionless and unreliable; TCP and SCTP are connection oriented and reliable. These three can respond to the demands of the application layer programs. The network layer in the Internet is unreliable (best-effort delivery), we need to implement reliability at the transport layer. To understand that error control at the data link layer does not guarantee error control at the transport layer, let us look at Figure 4.7.
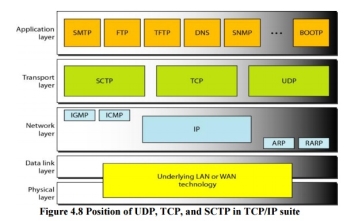
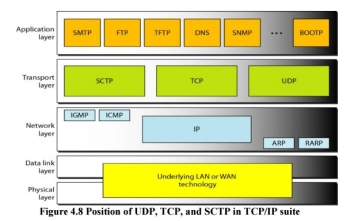
8. Three Protocols The original TCP/IP protocol suite specifies two protocols for the transport layer: UDP and TCP. We first focus on UDP, the simpler of the two, before discussing TCP. A new transport layer protocol, SCTP, has been designed. Figure 4.8 shows the position of these protocols in the TCP/IP protocol suite.
|
UDP Protocol In computer networking, the UDP stands for User Datagram Protocol. The David P. Reed developed the UDP protocol in 1980. It is defined in RFC 768, and it is a part of the TCP/IP protocol, so it is a standard protocol over the internet. The UDP protocol allows the computer applications to send the messages in the form of datagrams from one machine to another machine over the Internet protocol (IP) network. The UDP is an alternative communication protocol to the TCP protocol (transmission control protocol). Like TCP, UDP provides a set of rules that governs how the data should be exchanged over the internet. The UDP works by encapsulating the data into the packet and providing its own header information to the packet. Then, this UDP packet is encapsulated to the IP packet and sent off to its destination. Both the TCP and UDP protocols send the data over the internet protocol network, so it is also known as TCP/IP and UDP/IP. There are many differences between these two protocols. UDP enables the process to process communication, whereas the TCP provides host to host communication. Since UDP sends the messages in the form of datagrams, it is considered the best-effort mode of communication. TCP sends the individual packets, so it is a reliable transport medium. Another difference is that the TCP is a connection-oriented protocol whereas, the UDP is a connectionless protocol as it does not require any virtual circuit to transfer the data. UDP also provides a different port number to distinguish different user requests and also provides the checksum capability to verify whether the complete data has arrived or not; the IP layer does not provide these two services. Features of UDP protocol The following are the features of the UDP protocol: Transport layer protocol UDP is the simplest transport layer communication protocol. It contains a minimum amount of communication mechanisms. It is considered an unreliable protocol, and it is based on best-effort delivery services. UDP provides no acknowledgment mechanism, which means that the receiver does not send the acknowledgment for the received packet, and the sender also does not wait for the acknowledgment for the packet that it has sent. Connectionless The UDP is a connectionless protocol as it does not create a virtual path to transfer the data. It does not use the virtual path, so packets are sent in different paths between the sender and the receiver, which leads to the loss of packets or received out of order. Ordered delivery of data is not guaranteed. In the case of UDP, the datagrams are sent in some order will be received in the same order is not guaranteed as the datagrams are not numbered. Ports The UDP protocol uses different port numbers so that the data can be sent to the correct destination. The port numbers are defined between 0 and 1023. Faster transmission UDP enables faster transmission as it is a connectionless protocol, i.e., no virtual path is required to transfer the data. But there is a chance that the individual packet is lost, which affects the transmission quality. On the other hand, if the packet is lost in TCP connection, that packet will be resent, so it guarantees the delivery of the data packets. Acknowledgment mechanism The UDP does have any acknowledgment mechanism, i.e., there is no handshaking between the UDP sender and UDP receiver. If the message is sent in TCP, then the receiver acknowledges that I am ready, then the sender sends the data. In the case of TCP, the handshaking occurs between the sender and the receiver, whereas in UDP, there is no handshaking between the sender and the receiver. Segments are handled independently. Each UDP segment is handled individually of others as each segment takes different path to reach the destination. The UDP segments can be lost or delivered out of order to reach the destination as there is no connection setup between the sender and the receiver. Stateless It is a stateless protocol that means that the sender does not get the acknowledgement for the packet which has been sent. |
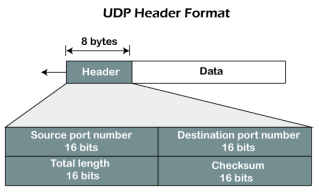
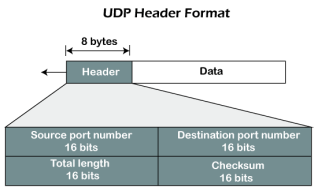
As we know that the UDP is an unreliable protocol, but we still require a UDP protocol in some cases. The UDP is deployed where the packets require a large amount of bandwidth along with the actual data. For example, in video streaming, acknowledging thousands of packets is troublesome and wastes a lot of bandwidth. In the case of video streaming, the loss of some packets couldn't create a problem, and it can also be ignored. UDP Header Format
In UDP, the header size is 8 bytes, and the packet size is upto 65,535 bytes. But this packet size is not possible as the data needs to be encapsulated in the IP datagram, and an IP packet, the header size can be 20 bytes; therefore, the maximum of UDP would be 65,535 minus 20. The size of the data that the UDP packet can carry would be 65,535 minus 28 as 8 bytes for the header of the UDP packet and 20 bytes for IP header. The UDP header contains four fields: Source port number: It is 16-bit information that identifies which port is going t send the packet. Destination port number: It identifies which port is going to accept the information. It is 16-bit information which is used to identify application-level service on the destination machine. Length: It is 16-bit field that specifies the entire length of the UDP packet that includes the header also. The minimum value would be 8-byte as the size of the header is 8 bytes. Checksum: It is a 16-bits field, and it is an optional field. This checksum field checks whether the information is accurate or not as there is the possibility that the information can be corrupted while transmission. It is an optional field, which means that it depends upon the application, whether it wants to write the checksum or not. If it does not want to write the checksum, then all the 16 bits are zero; otherwise, it writes the checksum. In UDP, the checksum field is applied to the entire packet, i.e., header as well as data part whereas, in IP, the checksum field is applied to only the header field. |
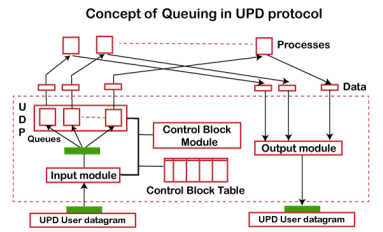
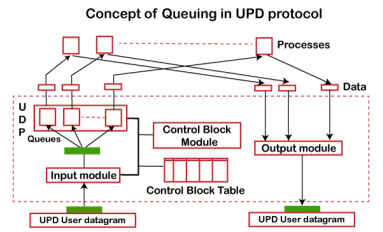
In UDP protocol, numbers are used to distinguish the different processes on a server and client. We know that UDP provides a process to process communication. The client generates the processes that need services while the server generates the processes that provide services. The queues are available for both the processes, i.e., two queues for each process. The first queue is the incoming queue that receives the messages, and the second one is the outgoing queue that sends the messages. The queue functions when the process is running. If the process is terminated then the queue will also get destroyed. UDP handles the sending and receiving of the UDP packets with the help of the following components: Input queue: The UDP packets uses a set of queues for each process. Input module: This module takes the user datagram from the IP, and then it finds the information from the control block table of the same port. If it finds the entry in the control block table with the same port as the user datagram, it enqueues the data. Control Block Module: It manages the control block table. Control Block Table: The control block table contains the entry of open ports. Output module: The output module creates and sends the user datagram. Several processes want to use the services of UDP. The UDP multiplexes and demultiplexes the processes so that the multiple processes can run on a single host. Limitations It provides an unreliable connection delivery service. It does not provide any services of IP except that it provides process-to-process communication. The UDP message can be lost, delayed, duplicated, or can be out of order. It does not provide a reliable transport delivery service. It does not provide any acknowledgment or flow control mechanism. However, it does provide error control to some extent. Advantages It produces a minimal number of overheads |
TCP TCP stands for Transmission Control Protocol. It is a transport layer protocol that facilitates the transmission of packets from source to destination. It is a connection-oriented protocol that means it establishes the connection prior to the communication that occurs between the computing devices in a network. This protocol is used with an IP protocol, so together, they are referred to as a TCP/IP. The main functionality of the TCP is to take the data from the application layer. Then it divides the data into a several packets, provides numbering to these packets, and finally transmits these packets to the destination. The TCP, on the other side, will reassemble the packets and transmits them to the application layer. As we know that TCP is a connection-oriented protocol, so the connection will remain established until the communication is not completed between the sender and the receiver. Features of TCP protocol The following are the features of a TCP protocol: Transport Layer Protocol TCP is a transport layer protocol as it is used in transmitting the data from the sender to the receiver. Reliable TCP is a reliable protocol as it follows the flow and error control mechanism. It also supports the acknowledgment mechanism, which checks the state and sound arrival of the data. In the acknowledgment mechanism, the receiver sends either positive or negative acknowledgment to the sender so that the sender can get to know whether the data packet has been received or needs to resend. Order of the data is maintained This protocol ensures that the data reaches the intended receiver in the same order in which it is sent. It orders and numbers each segment so that the TCP layer on the destination side can reassemble them based on their ordering. Connection-oriented It is a connection-oriented service that means the data exchange occurs only after the connection establishment. When the data transfer is completed, then the connection will get terminated. Full duplex It is a full-duplex means that the data can transfer in both directions at the same time. Stream-oriented TCP is a stream-oriented protocol as it allows the sender to send the data in the form of a stream of bytes and also allows the receiver to accept the data in the form of a stream of bytes. TCP creates an environment in which both the sender and receiver are connected by an imaginary tube known as a virtual circuit. This virtual circuit carries the stream of bytes across the internet.
|
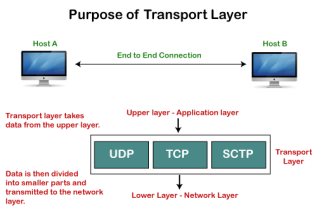
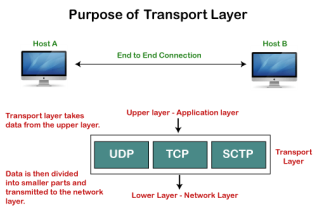
Need of Transport Control Protocol In the layered architecture of a network model, the whole task is divided into smaller tasks. Each task is assigned to a particular layer that processes the task. In the TCP/IP model, five layers are application layer, transport layer, network layer, data link layer, and physical layer. The transport layer has a critical role in providing end-to-end communication to the directly application processes. It creates 65,000 ports so that the multiple applications can be accessed at the same time. It takes the data from the upper layer, and it divides the data into smaller packets and then transmits them to the network layer.
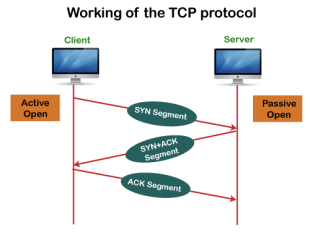
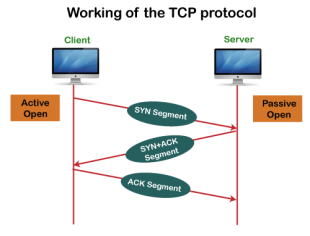
Working of TCP In TCP, the connection is established by using three-way handshaking. The client sends the segment with its sequence number. The server, in return, sends its segment with its own sequence number as well as the acknowledgement sequence, which is one more than the client sequence number. When the client receives the acknowledgment of its segment, then it sends the acknowledgment to the server. In this way, the connection is established between the client and the server.
Advantages of TCP It provides a connection-oriented reliable service, which means that it guarantees the delivery of data packets. If the data packet is lost across the network, then the TCP will resend the lost packets. It provides a flow control mechanism using a sliding window protocol. It provides error detection by using checksum and error control by using Go Back or ARP protocol. It eliminates the congestion by using a network congestion avoidance algorithm that includes various schemes such as additive increase/multiplicative decrease (AIMD), slow start, and congestion window. Disadvantage of TCP It increases a large amount of overhead as each segment gets its own TCP header, so fragmentation by the router increases the overhead |
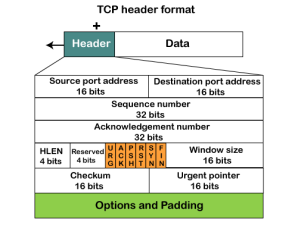
TCP Header format
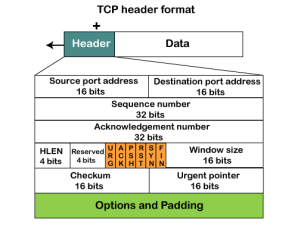
Source port: It defines the port of the application, which is sending the data. So, this field contains the source port address, which is 16 bits. Destination port: It defines the port of the application on the receiving side. So, this field contains the destination port address, which is 16 bits. Sequence number: This field contains the sequence number of data bytes in a particular session. Acknowledgment number: When the ACK flag is set, then this contains the next sequence number of the data byte and works as an acknowledgment for the previous data received. For example, if the receiver receives the segment number 'x', then it responds 'x+1' as an acknowledgment number. HLEN: It specifies the length of the header indicated by the 4-byte words in the header. The size of the header lies between 20 and 60 bytes. Therefore, the value of this field would lie between 5 and 15. Reserved: It is a 4-bit field reserved for future use, and by default, all are set to zero. Flags URG: It represents an urgent pointer. If it is set, then the data is processed urgently. ACK: If the ACK is set to 0, then it means that the data packet does not contain an acknowledgment. PSH: If this field is set, then it requests the receiving device to push the data to the receiving application without buffering it. RST: If it is set, then it requests to restart a connection. SYN: It is used to establish a connection between the hosts. FIN: It is used to release a connection, and no further data exchange will happen. Window size It is a 16-bit field. It contains the size of data that the receiver can accept. This field is used for the flow control between the sender and receiver and also determines the amount of buffer allocated by the receiver for a segment. The value of this field is determined by the receiver. Checksum Urgent pointer It is a pointer that points to the urgent data byte if the URG flag is set to 1. It defines a value that will be added to the sequence number to get the sequence number of the last urgent byte. Options |
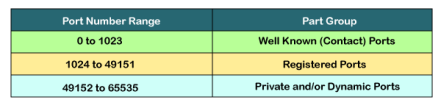
The TCP port is a unique number assigned to different applications. For example, we have opened the email and games applications on our computer; through email application, we want to send the mail to the host, and through games application, we want to play the online games. In order to do all these tasks, different unique numbers are assigned to these applications. Each protocol and address have a port known as a port number. The TCP (Transmission control protocol) and UDP (User Datagram Protocol) protocols mainly use the port numbers. A port number is a unique identifier used with an IP address. A port is a 16-bit unsigned integer, and the total number of ports available in the TCP/IP model is 65,535 ports. Therefore, the range of port numbers is 0 to 65535. In the case of TCP, the zero-port number is reserved and cannot be used, whereas, in UDP, the zero port is not available. IANA (Internet Assigned Numbers Authority) is a standard body that assigns the port numbers. Example of port number: 192.168.1.100: 7 In the above case, 192.168.1.100 is an IP address, and 7 is a port number. To access a particular service, the port number is used with an IP address. The range from 0 to 1023 port numbers are reserved for the standard protocols, and the other port numbers are user-defined. Why do we require port numbers? A single client can have multiple connections with the same server or multiple servers. The client may be running multiple applications at the same time. When the client tries to access some service, then the IP address is not sufficient to access the service. To access the service from a server, the port number is required. So, the transport layer plays a major role in providing multiple communication between these applications by assigning a port number to the applications. Classification of port numbers The port numbers are divided into three categories: Well-known ports Registered ports Dynamic ports
Well-known ports The range of well-known port is 0 to 1023. The well-known ports are used with those protocols that serve common applications and services such as HTTP (Hypertext transfer protocol), IMAP (Internet Message Access Protocol), SMTP (Simple Mail Transfer Protocol), etc. For example, we want to visit some websites on an internet; then, we use http protocol; the http is available with a port number 80, which means that when we use http protocol with an application then it gets port number 80. It is defined that whenever http protocol is used, then port number 80 will be used. Similarly, with other protocols such as SMTP, IMAP; well-known ports are defined. The remaining port numbers are used for random applications. Registered ports The range of registered port is 1024 to 49151. The registered ports are used for the user processes. These processes are individual applications rather than the common applications that have a well-known port. Dynamic ports The range of dynamic port is 49152 to 65535. Another name of the dynamic port is ephemeral ports. These port numbers are assigned to the client application dynamically when a client creates a connection. The dynamic port is identified when the client initiates the connection, whereas the client knows the well-known port prior to the connection. This port is not known to the client when the client connects to the service. |
TCP and UDP header As we know that both TCP and UDP contain source and destination port numbers, and these port numbers are used to identify the application or a server both at the source and the destination side. Both TCP and UDP use port numbers to pass the information to the upper layers. Let's understand this scenario. Suppose a client is accessing a web page. The TCP header contains both the source and destination port.
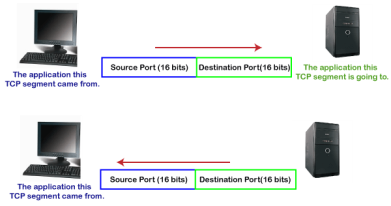
Client-side In the above diagram, Source Port: The source port defines an application to which the TCP segment belongs to, and this port number is dynamically assigned by the client. This is basically a process to which the port number is assigned. Destination port: The destination port identifies the location of the service on the server so that the server can serve the request of the client. Server-side In the above diagram, Source port: It defines the application from where the TCP segment came from. Destination port: It defines the application to which the TCP segment is going to. In the above case, two processes are used: Encapsulation: Port numbers are used by the sender to tell the receiver which application it should use for the data. Decapsulation: Port numbers are used by the receiver to identify which application should it sends the data to. Let's understand the above example by using all three ports, i.e., well-known port, registered port, and dynamic port. First, we look at a well-known port.
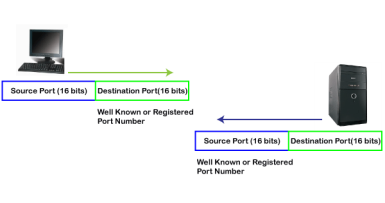
The well-known ports are the ports that serve the common services and applications like http, ftp, smtp, etc. Here, the client uses a well-known port as a destination port while the server uses a well-known port as a source port. For example, the client sends an http request, then, in this case, the destination port would be 80, whereas the http server is serving the request so its source port number would be 80. Now, we look at the registered port.
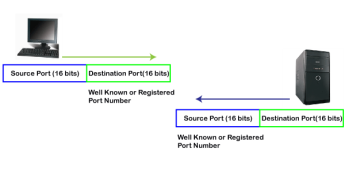
The registered port is assigned to the non-common applications. Lots of vendor applications use this port. Like the well-known port, client uses this port as a destination port whereas the server uses this port as a source port. At the end, we see how dynamic port works in this scenario.
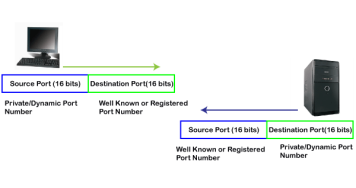
The dynamic port is the port that is dynamically assigned to the client application when initiating a connection. In this case, the client uses a dynamic port as a source port, whereas the server uses a dynamic port as a destination port. For example, the client sends an http request; then in this case, destination port would be 80 as it is a http request, and the source port will only be assigned by the client. When the server serves the request, then the source port would be 80 as it is an http server, and the destination port would be the same as the source port of the client. The registered port can also be used in place of a dynamic port. Let's look at the below example. Suppose client is communicating with a server, and sending the http request. So, the client sends the TCP segment to the well-known port, i.e., 80 of the HTTP protocols. In this case, the destination port would be 80 and suppose the source port assigned dynamically by the client is 1028. When the server responds, the destination port is 1028 as the source port defined by the client is 1028, and the source port at the server end would be 80 as the HTTP server is responding to the request of the client.
|
A state occurring in network layer when the message traffic is so heavy that it slows down network response time. Effects of Congestion As delay increases, performance decreases. If delay increases, retransmission occurs, making situation worse.
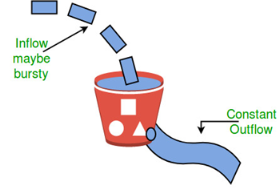
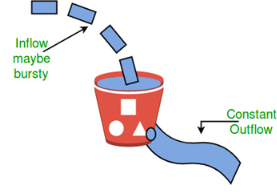
Congestion control algorithms Leaky Bucket Algorithm Let us consider an example to understand Imagine a bucket with a small hole in the bottom.No matter at what rate water enters the bucket, the outflow is at constant rate.When the bucket is full with water additional water entering spills over the sides and is lost.
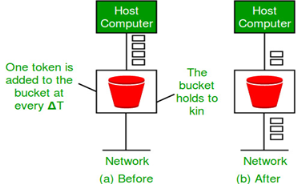
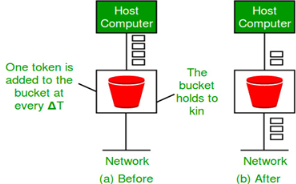
Similarly, each network interface contains a leaky bucket and the following steps are involved in leaky bucket algorithm: When host wants to send packet, packet is thrown into the bucket. The bucket leaks at a constant rate, meaning the network interface transmits packets at a constant rate. Bursty traffic is converted to a uniform traffic by the leaky bucket. In practice the bucket is a finite queue that outputs at a finite rate. Token bucket Algorithm Need of token bucket Algorithm:- The leaky bucket algorithm enforces output pattern at the average rate, no matter how bursty the traffic is. So in order to deal with the bursty traffic we need a flexible algorithm so that the data is not lost. One such algorithm is token bucket algorithm. Steps of this algorithm can be described as follows: In regular intervals tokens are thrown into the bucket. ƒ The bucket has a maximum capacity. ƒ If there is a ready packet, a token is removed from the bucket, and the packet is sent. If there is no token in the bucket, the packet cannot be sent. Let’s understand with an example, In figure (A) we see a bucket holding three tokens, with five packets waiting to be transmitted. For a packet to be transmitted, it must capture and destroy one token. In figure (B) We see that three of the five packets have gotten through, but the other two are stuck waiting for more tokens to be generated. Ways in which token bucket is superior to leaky bucket: Formula: M * s = C + ρ * s Let’s understand with an example,
|
The data link layer is responsible for delivery of frames between two neighbouring nodes over a link. This is called node-to-node delivery. The network layer is responsible for delivery of datagrams between two hosts. This is called host-to-host delivery. Real communication takes place between two processes (application programs). We need process-to-process delivery. The transport layer is responsible for process-to-process delivery-the delivery of a packet, part of a message, from one process to another. Figure 4.1 shows these three types of deliveries and their domains
1. Client/Server Paradigm Although there are several ways to achieve process-to-process communication, the most common one is through the client/server paradigm. A process on the local host, called a client, needs services from a process usually on the remote host, called a server. Both processes (client and server) have the same name. For example, to get the day and time from a remote machine, we need a Daytime client process running on the local host and a Daytime server process running on a remote machine. For communication, we must define the following: 1. Local host 2. Local process 3. Remote host 4. Remote process 2. Addressing Whenever we need to deliver something to one specific destination among many, we need an address. At the data link layer, we need a MAC address to choose one node among several nodes if the connection is not point-to-point. A frame in the data link layer needs a Destination MAC address for delivery and a source address for the next node's reply. Figure 4.2 shows this concept.
The IP addresses and port numbers play different roles in selecting the final destination of data. The destination IP address defines the host among the different hosts in the world. After the host has been selected, the port number defines one of the processes on this particular host (see Figure 4.3).
3. lANA Ranges The lANA (Internet Assigned Number Authority) has divided the port numbers into three ranges: well known, registered, and dynamic (or private), as shown in Figure 4.4. Well-known ports. The ports ranging from 0 to 1023 are assigned and controlledby lANA. These are the well-known ports. Registered ports. The ports ranging from 1024 to 49,151 are not assigned orcontrolled by lANA. They can only be registered with lANA to prevent duplication. Dynamic ports. The ports ranging from 49,152 to 65,535 are neither controllednor registered. They can be used by any process. These are the ephemeral ports.
4. Socket Addresses Process-to-process delivery needs two identifiers, IP address and the port number, at each end to make a connection. The combination of an IP address and a port number is called a socket address. The client socket address defines the client process uniquely just as the server socket address defines the server process uniquely (see Figure 4.5). UDP or TCP header contains the port numbers.
5. Multiplexing and Demultiplexing The addressing mechanism allows multiplexing and demultiplexing by the transport layer, as shown in Figure 4.6. Multiplexing At the sender site, there may be several processes that need to send packets. However, there is only one transport layer protocol at any time. This is a many-to-one relationship and requires multiplexing. Demultiplexing At the receiver site, the relationship is one-to-many and requires demultiplexing. The transport layer receives datagrams from the network layer. After error checking and dropping of the header, the transport layer delivers each message to the appropriate process based on the port number.
6. Connectionless Versus Connection-Oriented Service A transport layer protocol can either be connectionless or connection-oriented. Connectionless Service In a connectionless service, the packets are sent from one party to another with no need for connection establishment or connection release. The packets are not numbered; they may be delayed or lost or may arrive out of sequence. There is no acknowledgment either. Connection~Oriented Service In a connection-oriented service, a connection is first established between the sender and the receiver. Data are transferred. At the end, the connection is released. 7. Reliable Versus Unreliable The transport layer service can be reliable or unreliable. If the application layer program needs reliability, we use a reliable transport layer protocol by implementing flow and error control at the transport layer. This means a slower and more complex service. In the Internet, there are three common different transport layer protocols. UDP is connectionless and unreliable; TCP and SCTP are connection oriented and reliable. These three can respond to the demands of the application layer programs. The network layer in the Internet is unreliable (best-effort delivery), we need to implement reliability at the transport layer. To understand that error control at the data link layer does not guarantee error control at the transport layer, let us look at Figure 4.7.
8. Three Protocols The original TCP/IP protocol suite specifies two protocols for the transport layer: UDP and TCP. We first focus on UDP, the simpler of the two, before discussing TCP. A new transport layer protocol, SCTP, has been designed. Figure 4.8 shows the position of these protocols in the TCP/IP protocol suite.
|
UDP Protocol In computer networking, the UDP stands for User Datagram Protocol. The David P. Reed developed the UDP protocol in 1980. It is defined in RFC 768, and it is a part of the TCP/IP protocol, so it is a standard protocol over the internet. The UDP protocol allows the computer applications to send the messages in the form of datagrams from one machine to another machine over the Internet protocol (IP) network. The UDP is an alternative communication protocol to the TCP protocol (transmission control protocol). Like TCP, UDP provides a set of rules that governs how the data should be exchanged over the internet. The UDP works by encapsulating the data into the packet and providing its own header information to the packet. Then, this UDP packet is encapsulated to the IP packet and sent off to its destination. Both the TCP and UDP protocols send the data over the internet protocol network, so it is also known as TCP/IP and UDP/IP. There are many differences between these two protocols. UDP enables the process to process communication, whereas the TCP provides host to host communication. Since UDP sends the messages in the form of datagrams, it is considered the best-effort mode of communication. TCP sends the individual packets, so it is a reliable transport medium. Another difference is that the TCP is a connection-oriented protocol whereas, the UDP is a connectionless protocol as it does not require any virtual circuit to transfer the data. UDP also provides a different port number to distinguish different user requests and also provides the checksum capability to verify whether the complete data has arrived or not; the IP layer does not provide these two services. Features of UDP protocol The following are the features of the UDP protocol: Transport layer protocol UDP is the simplest transport layer communication protocol. It contains a minimum amount of communication mechanisms. It is considered an unreliable protocol, and it is based on best-effort delivery services. UDP provides no acknowledgment mechanism, which means that the receiver does not send the acknowledgment for the received packet, and the sender also does not wait for the acknowledgment for the packet that it has sent. Connectionless The UDP is a connectionless protocol as it does not create a virtual path to transfer the data. It does not use the virtual path, so packets are sent in different paths between the sender and the receiver, which leads to the loss of packets or received out of order. Ordered delivery of data is not guaranteed. In the case of UDP, the datagrams are sent in some order will be received in the same order is not guaranteed as the datagrams are not numbered. Ports The UDP protocol uses different port numbers so that the data can be sent to the correct destination. The port numbers are defined between 0 and 1023. Faster transmission UDP enables faster transmission as it is a connectionless protocol, i.e., no virtual path is required to transfer the data. But there is a chance that the individual packet is lost, which affects the transmission quality. On the other hand, if the packet is lost in TCP connection, that packet will be resent, so it guarantees the delivery of the data packets. Acknowledgment mechanism The UDP does have any acknowledgment mechanism, i.e., there is no handshaking between the UDP sender and UDP receiver. If the message is sent in TCP, then the receiver acknowledges that I am ready, then the sender sends the data. In the case of TCP, the handshaking occurs between the sender and the receiver, whereas in UDP, there is no handshaking between the sender and the receiver. Segments are handled independently. Each UDP segment is handled individually of others as each segment takes different path to reach the destination. The UDP segments can be lost or delivered out of order to reach the destination as there is no connection setup between the sender and the receiver. Stateless It is a stateless protocol that means that the sender does not get the acknowledgement for the packet which has been sent. |
As we know that the UDP is an unreliable protocol, but we still require a UDP protocol in some cases. The UDP is deployed where the packets require a large amount of bandwidth along with the actual data. For example, in video streaming, acknowledging thousands of packets is troublesome and wastes a lot of bandwidth. In the case of video streaming, the loss of some packets couldn't create a problem, and it can also be ignored. UDP Header Format
In UDP, the header size is 8 bytes, and the packet size is upto 65,535 bytes. But this packet size is not possible as the data needs to be encapsulated in the IP datagram, and an IP packet, the header size can be 20 bytes; therefore, the maximum of UDP would be 65,535 minus 20. The size of the data that the UDP packet can carry would be 65,535 minus 28 as 8 bytes for the header of the UDP packet and 20 bytes for IP header. The UDP header contains four fields: Source port number: It is 16-bit information that identifies which port is going t send the packet. Destination port number: It identifies which port is going to accept the information. It is 16-bit information which is used to identify application-level service on the destination machine. Length: It is 16-bit field that specifies the entire length of the UDP packet that includes the header also. The minimum value would be 8-byte as the size of the header is 8 bytes. Checksum: It is a 16-bits field, and it is an optional field. This checksum field checks whether the information is accurate or not as there is the possibility that the information can be corrupted while transmission. It is an optional field, which means that it depends upon the application, whether it wants to write the checksum or not. If it does not want to write the checksum, then all the 16 bits are zero; otherwise, it writes the checksum. In UDP, the checksum field is applied to the entire packet, i.e., header as well as data part whereas, in IP, the checksum field is applied to only the header field. |
In UDP protocol, numbers are used to distinguish the different processes on a server and client. We know that UDP provides a process to process communication. The client generates the processes that need services while the server generates the processes that provide services. The queues are available for both the processes, i.e., two queues for each process. The first queue is the incoming queue that receives the messages, and the second one is the outgoing queue that sends the messages. The queue functions when the process is running. If the process is terminated then the queue will also get destroyed. UDP handles the sending and receiving of the UDP packets with the help of the following components: Input queue: The UDP packets uses a set of queues for each process. Input module: This module takes the user datagram from the IP, and then it finds the information from the control block table of the same port. If it finds the entry in the control block table with the same port as the user datagram, it enqueues the data. Control Block Module: It manages the control block table. Control Block Table: The control block table contains the entry of open ports. Output module: The output module creates and sends the user datagram. Several processes want to use the services of UDP. The UDP multiplexes and demultiplexes the processes so that the multiple processes can run on a single host. Limitations It provides an unreliable connection delivery service. It does not provide any services of IP except that it provides process-to-process communication. The UDP message can be lost, delayed, duplicated, or can be out of order. It does not provide a reliable transport delivery service. It does not provide any acknowledgment or flow control mechanism. However, it does provide error control to some extent. Advantages It produces a minimal number of overheads |
TCP TCP stands for Transmission Control Protocol. It is a transport layer protocol that facilitates the transmission of packets from source to destination. It is a connection-oriented protocol that means it establishes the connection prior to the communication that occurs between the computing devices in a network. This protocol is used with an IP protocol, so together, they are referred to as a TCP/IP. The main functionality of the TCP is to take the data from the application layer. Then it divides the data into a several packets, provides numbering to these packets, and finally transmits these packets to the destination. The TCP, on the other side, will reassemble the packets and transmits them to the application layer. As we know that TCP is a connection-oriented protocol, so the connection will remain established until the communication is not completed between the sender and the receiver. Features of TCP protocol The following are the features of a TCP protocol: Transport Layer Protocol TCP is a transport layer protocol as it is used in transmitting the data from the sender to the receiver. Reliable TCP is a reliable protocol as it follows the flow and error control mechanism. It also supports the acknowledgment mechanism, which checks the state and sound arrival of the data. In the acknowledgment mechanism, the receiver sends either positive or negative acknowledgment to the sender so that the sender can get to know whether the data packet has been received or needs to resend. Order of the data is maintained This protocol ensures that the data reaches the intended receiver in the same order in which it is sent. It orders and numbers each segment so that the TCP layer on the destination side can reassemble them based on their ordering. Connection-oriented It is a connection-oriented service that means the data exchange occurs only after the connection establishment. When the data transfer is completed, then the connection will get terminated. Full duplex It is a full-duplex means that the data can transfer in both directions at the same time. Stream-oriented TCP is a stream-oriented protocol as it allows the sender to send the data in the form of a stream of bytes and also allows the receiver to accept the data in the form of a stream of bytes. TCP creates an environment in which both the sender and receiver are connected by an imaginary tube known as a virtual circuit. This virtual circuit carries the stream of bytes across the internet.
|
Need of Transport Control Protocol In the layered architecture of a network model, the whole task is divided into smaller tasks. Each task is assigned to a particular layer that processes the task. In the TCP/IP model, five layers are application layer, transport layer, network layer, data link layer, and physical layer. The transport layer has a critical role in providing end-to-end communication to the directly application processes. It creates 65,000 ports so that the multiple applications can be accessed at the same time. It takes the data from the upper layer, and it divides the data into smaller packets and then transmits them to the network layer.
Working of TCP In TCP, the connection is established by using three-way handshaking. The client sends the segment with its sequence number. The server, in return, sends its segment with its own sequence number as well as the acknowledgement sequence, which is one more than the client sequence number. When the client receives the acknowledgment of its segment, then it sends the acknowledgment to the server. In this way, the connection is established between the client and the server.
Advantages of TCP It provides a connection-oriented reliable service, which means that it guarantees the delivery of data packets. If the data packet is lost across the network, then the TCP will resend the lost packets. It provides a flow control mechanism using a sliding window protocol. It provides error detection by using checksum and error control by using Go Back or ARP protocol. It eliminates the congestion by using a network congestion avoidance algorithm that includes various schemes such as additive increase/multiplicative decrease (AIMD), slow start, and congestion window. Disadvantage of TCP It increases a large amount of overhead as each segment gets its own TCP header, so fragmentation by the router increases the overhead |
TCP Header format
Source port: It defines the port of the application, which is sending the data. So, this field contains the source port address, which is 16 bits. Destination port: It defines the port of the application on the receiving side. So, this field contains the destination port address, which is 16 bits. Sequence number: This field contains the sequence number of data bytes in a particular session. Acknowledgment number: When the ACK flag is set, then this contains the next sequence number of the data byte and works as an acknowledgment for the previous data received. For example, if the receiver receives the segment number 'x', then it responds 'x+1' as an acknowledgment number. HLEN: It specifies the length of the header indicated by the 4-byte words in the header. The size of the header lies between 20 and 60 bytes. Therefore, the value of this field would lie between 5 and 15. Reserved: It is a 4-bit field reserved for future use, and by default, all are set to zero. Flags URG: It represents an urgent pointer. If it is set, then the data is processed urgently. ACK: If the ACK is set to 0, then it means that the data packet does not contain an acknowledgment. PSH: If this field is set, then it requests the receiving device to push the data to the receiving application without buffering it. RST: If it is set, then it requests to restart a connection. SYN: It is used to establish a connection between the hosts. FIN: It is used to release a connection, and no further data exchange will happen. Window size It is a 16-bit field. It contains the size of data that the receiver can accept. This field is used for the flow control between the sender and receiver and also determines the amount of buffer allocated by the receiver for a segment. The value of this field is determined by the receiver. Checksum Urgent pointer It is a pointer that points to the urgent data byte if the URG flag is set to 1. It defines a value that will be added to the sequence number to get the sequence number of the last urgent byte. Options |
The TCP port is a unique number assigned to different applications. For example, we have opened the email and games applications on our computer; through email application, we want to send the mail to the host, and through games application, we want to play the online games. In order to do all these tasks, different unique numbers are assigned to these applications. Each protocol and address have a port known as a port number. The TCP (Transmission control protocol) and UDP (User Datagram Protocol) protocols mainly use the port numbers. A port number is a unique identifier used with an IP address. A port is a 16-bit unsigned integer, and the total number of ports available in the TCP/IP model is 65,535 ports. Therefore, the range of port numbers is 0 to 65535. In the case of TCP, the zero-port number is reserved and cannot be used, whereas, in UDP, the zero port is not available. IANA (Internet Assigned Numbers Authority) is a standard body that assigns the port numbers. Example of port number: 192.168.1.100: 7 In the above case, 192.168.1.100 is an IP address, and 7 is a port number. To access a particular service, the port number is used with an IP address. The range from 0 to 1023 port numbers are reserved for the standard protocols, and the other port numbers are user-defined. Why do we require port numbers? A single client can have multiple connections with the same server or multiple servers. The client may be running multiple applications at the same time. When the client tries to access some service, then the IP address is not sufficient to access the service. To access the service from a server, the port number is required. So, the transport layer plays a major role in providing multiple communication between these applications by assigning a port number to the applications. Classification of port numbers The port numbers are divided into three categories: Well-known ports Registered ports Dynamic ports
Well-known ports The range of well-known port is 0 to 1023. The well-known ports are used with those protocols that serve common applications and services such as HTTP (Hypertext transfer protocol), IMAP (Internet Message Access Protocol), SMTP (Simple Mail Transfer Protocol), etc. For example, we want to visit some websites on an internet; then, we use http protocol; the http is available with a port number 80, which means that when we use http protocol with an application then it gets port number 80. It is defined that whenever http protocol is used, then port number 80 will be used. Similarly, with other protocols such as SMTP, IMAP; well-known ports are defined. The remaining port numbers are used for random applications. Registered ports The range of registered port is 1024 to 49151. The registered ports are used for the user processes. These processes are individual applications rather than the common applications that have a well-known port. Dynamic ports The range of dynamic port is 49152 to 65535. Another name of the dynamic port is ephemeral ports. These port numbers are assigned to the client application dynamically when a client creates a connection. The dynamic port is identified when the client initiates the connection, whereas the client knows the well-known port prior to the connection. This port is not known to the client when the client connects to the service. |
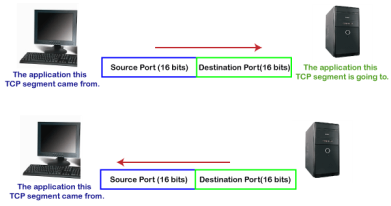
TCP and UDP header As we know that both TCP and UDP contain source and destination port numbers, and these port numbers are used to identify the application or a server both at the source and the destination side. Both TCP and UDP use port numbers to pass the information to the upper layers. Let's understand this scenario. Suppose a client is accessing a web page. The TCP header contains both the source and destination port.
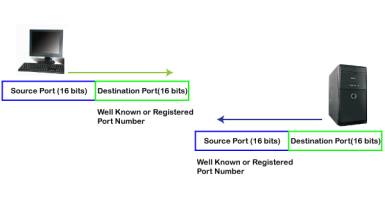
Client-side In the above diagram, Source Port: The source port defines an application to which the TCP segment belongs to, and this port number is dynamically assigned by the client. This is basically a process to which the port number is assigned. Destination port: The destination port identifies the location of the service on the server so that the server can serve the request of the client. Server-side In the above diagram, Source port: It defines the application from where the TCP segment came from. Destination port: It defines the application to which the TCP segment is going to. In the above case, two processes are used: Encapsulation: Port numbers are used by the sender to tell the receiver which application it should use for the data. Decapsulation: Port numbers are used by the receiver to identify which application should it sends the data to. Let's understand the above example by using all three ports, i.e., well-known port, registered port, and dynamic port. First, we look at a well-known port.
The well-known ports are the ports that serve the common services and applications like http, ftp, smtp, etc. Here, the client uses a well-known port as a destination port while the server uses a well-known port as a source port. For example, the client sends an http request, then, in this case, the destination port would be 80, whereas the http server is serving the request so its source port number would be 80. Now, we look at the registered port.
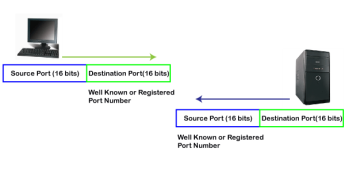
The registered port is assigned to the non-common applications. Lots of vendor applications use this port. Like the well-known port, client uses this port as a destination port whereas the server uses this port as a source port. At the end, we see how dynamic port works in this scenario.
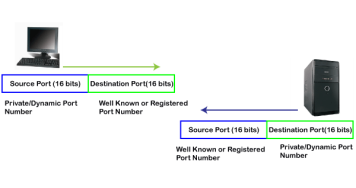
The dynamic port is the port that is dynamically assigned to the client application when initiating a connection. In this case, the client uses a dynamic port as a source port, whereas the server uses a dynamic port as a destination port. For example, the client sends an http request; then in this case, destination port would be 80 as it is a http request, and the source port will only be assigned by the client. When the server serves the request, then the source port would be 80 as it is an http server, and the destination port would be the same as the source port of the client. The registered port can also be used in place of a dynamic port. Let's look at the below example. Suppose client is communicating with a server, and sending the http request. So, the client sends the TCP segment to the well-known port, i.e., 80 of the HTTP protocols. In this case, the destination port would be 80 and suppose the source port assigned dynamically by the client is 1028. When the server responds, the destination port is 1028 as the source port defined by the client is 1028, and the source port at the server end would be 80 as the HTTP server is responding to the request of the client.
|
A state occurring in network layer when the message traffic is so heavy that it slows down network response time. Effects of Congestion As delay increases, performance decreases. If delay increases, retransmission occurs, making situation worse.
Congestion control algorithms Leaky Bucket Algorithm Let us consider an example to understand Imagine a bucket with a small hole in the bottom.No matter at what rate water enters the bucket, the outflow is at constant rate.When the bucket is full with water additional water entering spills over the sides and is lost.
Similarly, each network interface contains a leaky bucket and the following steps are involved in leaky bucket algorithm: When host wants to send packet, packet is thrown into the bucket. The bucket leaks at a constant rate, meaning the network interface transmits packets at a constant rate. Bursty traffic is converted to a uniform traffic by the leaky bucket. In practice the bucket is a finite queue that outputs at a finite rate. Token bucket Algorithm Need of token bucket Algorithm:- The leaky bucket algorithm enforces output pattern at the average rate, no matter how bursty the traffic is. So in order to deal with the bursty traffic we need a flexible algorithm so that the data is not lost. One such algorithm is token bucket algorithm. Steps of this algorithm can be described as follows: In regular intervals tokens are thrown into the bucket. ƒ The bucket has a maximum capacity. ƒ If there is a ready packet, a token is removed from the bucket, and the packet is sent. If there is no token in the bucket, the packet cannot be sent. Let’s understand with an example, In figure (A) we see a bucket holding three tokens, with five packets waiting to be transmitted. For a packet to be transmitted, it must capture and destroy one token. In figure (B) We see that three of the five packets have gotten through, but the other two are stuck waiting for more tokens to be generated. Ways in which token bucket is superior to leaky bucket: Formula: M * s = C + ρ * s Let’s understand with an example,
|