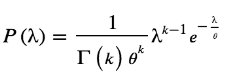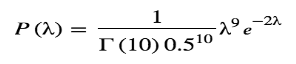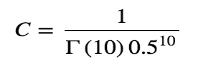|
● Y is the predicted value,
● X is feature value,
● m is coefficients or weights,
● c is the bias value.
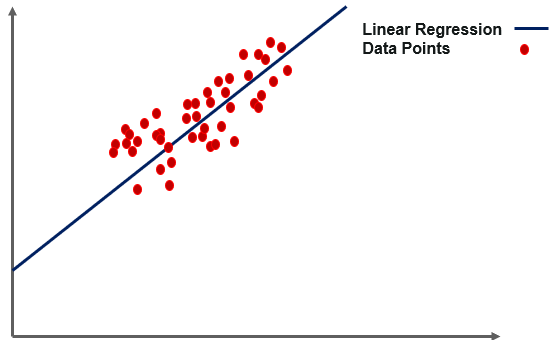
Usage Cases for Linear Regression ● Revenue Forecasting● Risk Evaluation● Applications for Housing To Forecast Prices and Other Factors● Stock price forecasting, investment assessment, and other finance applications The basic concept behind linear regression is to figure out how the dependent and independent variables are related. It's used to find the best-fitting line that can correctly predict the result with the least amount of error. We may use linear regression in simple real-life scenarios, such as predicting SAT scores based on study hours and other important factors. Basic Terminology it's important to understand the following words : Cost functionThe linear equation given below can be used to find the best fit line.
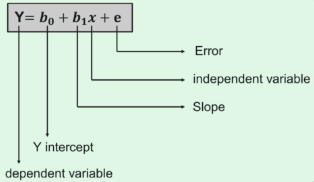
● Y stands for the dependent variable that needs to be expected. ● The intercept b0 denotes a line that touches the y-axis. ● The slope of the line is b1, and the independent variables that decide the prediction of Y are represented by x. ● The error in the final forecast is denoted by the letter e.
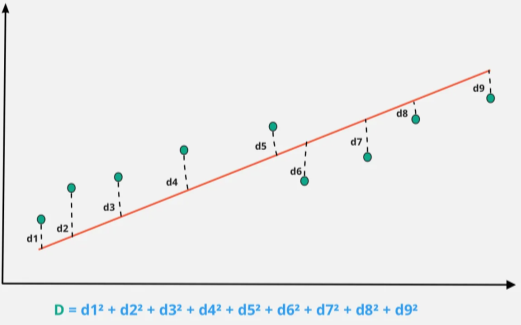
The cost function determines the best possible values for b0 and b1 in order to construct the best possible fit line for the data points. To get the best values for b0 and b1, we turn this problem into a minimization problem.
|
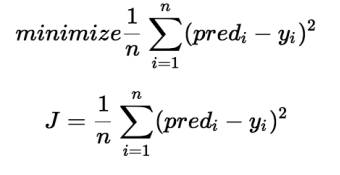
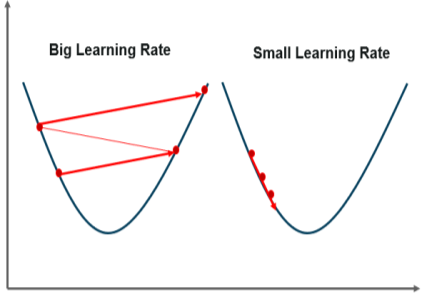
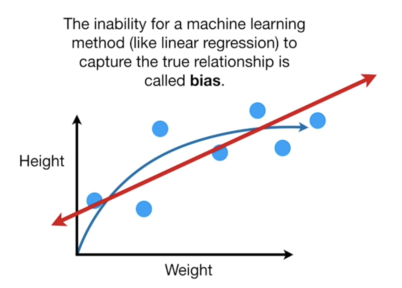
|
|
|
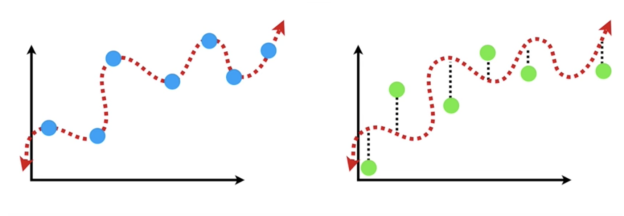
Let's go over it again quickly: ● α = 0: Same coefficients as simple linear regression ● α = ∞: All coefficients zero ● 0 < α < ∞: coefficients between 0 and that of simple linear regression. The RSS plus the sum of absolute values of weight magnitudes is the objective function (also known as the cost) to be minimized. Mathematically, this can be expressed as:
Fig 5: Statistics of lasso regression
|
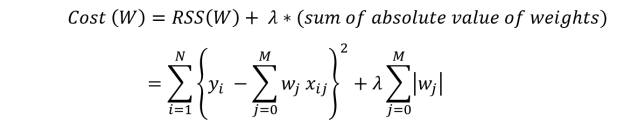
|
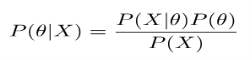
As a consequence, P(X) can be written as:
We write P(X) as an integration for the continuous:
|
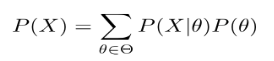
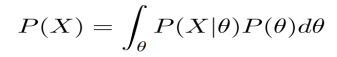
|
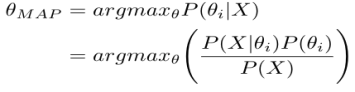
|
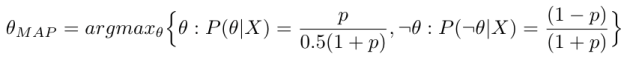
|
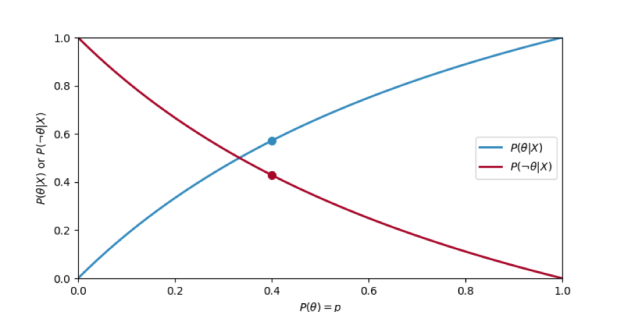
We've estimated our posterior for, but even more impressive, we've returned to the Gamma distribution! Let's take a look at how this works. The gamma distribution is defined as follows:
We chose values for k and quite haphazardly at the start of this article. Now note that if we choose k = 10 and = 0.5, we get our posterior!
that simply implies that we choose C in our posterior calculation:
|