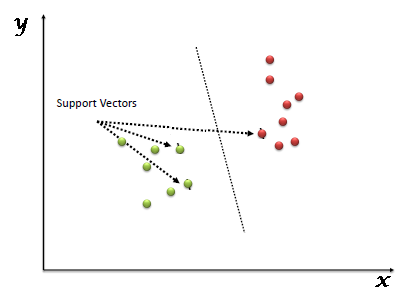
|
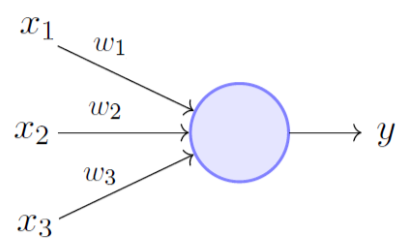
|
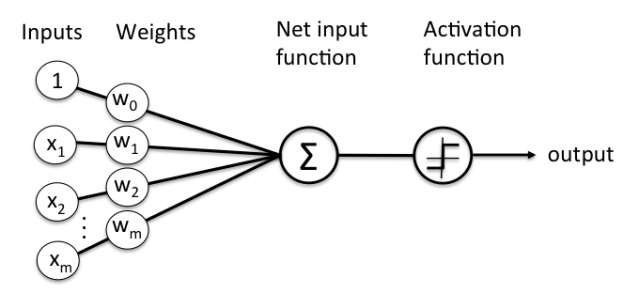
|
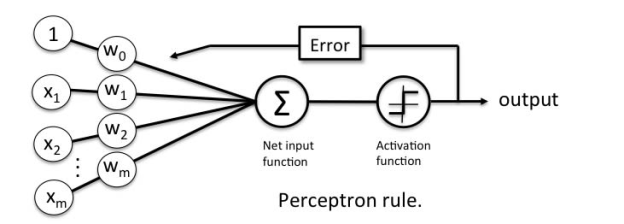
|
|
where G stands for the real, observed class. From here, the probabilities of an observation belonging to each of the groups can be determined as
that clearly shows that all class probabilities add up to one.
|
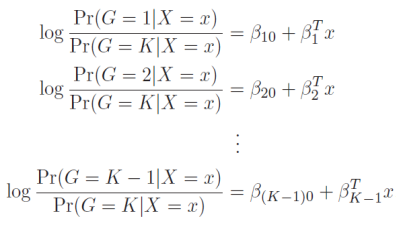
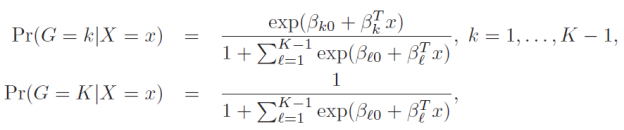
|
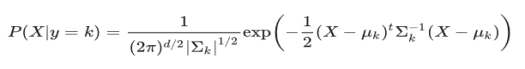
This yields a decision boundary between k and l that is linear in X:
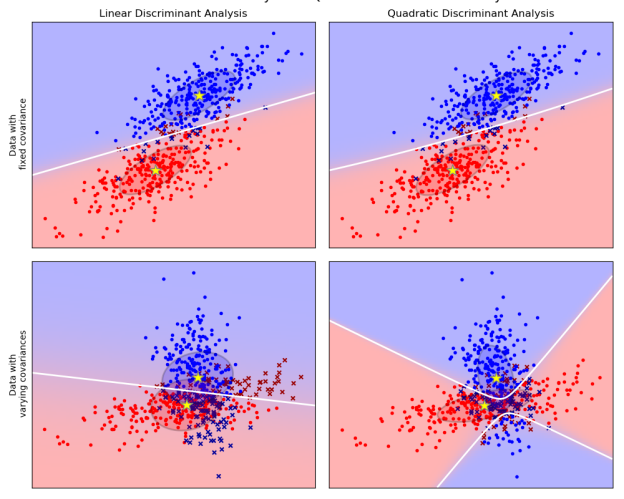
To measure the density of the features, P(X|y=k), one only has to estimate the Gaussian parameters: the means μ k as the sample means and the covariance matrix Σ as the empirical sample covariance matrix.
where P(y=k) is the prior likelihood of belonging to class k and can be determined by the proportion of k-class observations in the sample. |
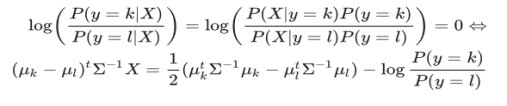
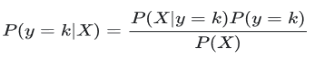
|
|
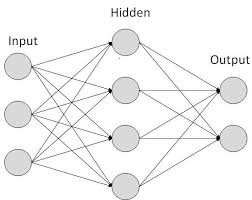
|
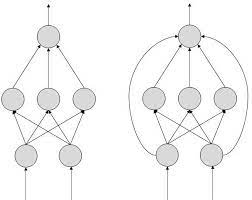
|
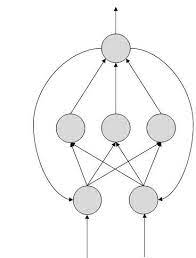
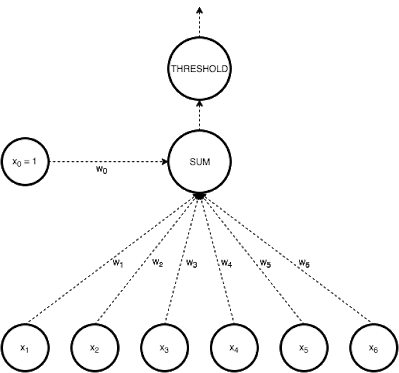
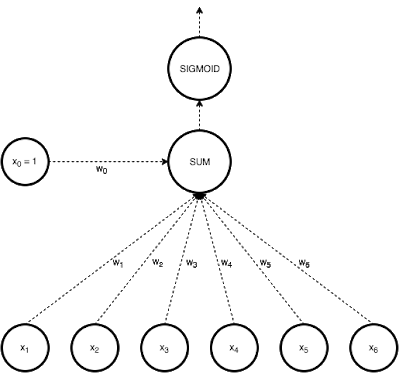
netj = Σi wjiai
where a i is the input activation from unit i and w ji is the weight connecting unit i to unit j. However, instead of calculating a binary output, the net input is added to the unit’s bias and the resulting value is passed through a sigmoid function:
|
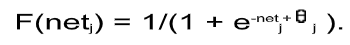
|
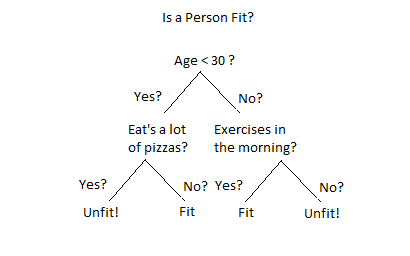
|
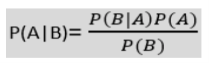
|