Computer Organization and Architecture
UNIT - 4Introduction to Parallel ProcessingQ1) What is the Process Concept?A1)A process is a program in execution. The execution of a process must go in a sequentially. Process isn't as same as program code yet much more than it. A process is a 'active' element instead of program which is viewed as a 'passive' entity. Properties held by process incorporate hardware state, memory, CPU and so forth. Based on the operating system (OS), a process might be comprised of numerous threads of execution that execute instructions simultaneously. While a computer program is an inactive collection of instructions, a process is the real execution of those instructions. A few processes might be related with a similar program; for instance, opening up a few occurrences of a similar program regularly brings about more than one process being executed. Process memory is isolated into four segments for effective working : max
0A process can be comprehensively ordered into the following two types dependent on its execution:
- The Text section is comprised of the compiled program code, read in from non-volatile storage when the program is launched.
- The Data section is made up of global and static variables, allotted and introduced before executing the primary.
- The Heap is utilized for the dynamic memory distribution, and is managed through calls to new, delete, malloc, free, and so on.
- The Stack is utilized for local variables. Space on the stack is saved for local variables when they are declared.
Stack |
|
Heap |
Data |
Text |
- I/O-Bound Process - An I/O-bound process is a process whose execution time is resolved principally by the measure of time it spends finishing I/O operations.
- CPU-Bound Process - A CPU-bound process is a process whose execution time is dictated by the speed of the CPU it keeps running on. A CPU-bound process can finish its execution quicker in the event that it is running on a quicker processor.
Q2) What is process control back and process state of an operating system? A2) Process Control Back (PCB)A Process Control Block is a data structure kept up by the Operating System for each process. The PCB is distinguished by a number process ID (PID). The job of the PCBs is main in process management: they are accessed and/or altered by most OS utilities, incorporating those associated with scheduling, memory and I/O resource access and performance monitoring. It very well may be said that the arrangement of the PCBs characterizes the present condition of the operating system. A PCB keeps all the data expected to monitor a process as mentioned below − The engineering of a PCB is totally subject to Operating System and may contain distinctive data in various operating systems. Here is an improved graph of a PCB −
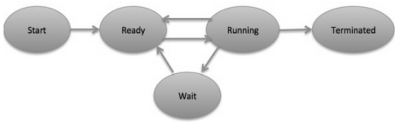
Process StateAt some point when a process executes, it goes through various states. These stages may contrast in various operating systems, and the names of these states are likewise not fixed. All in all, a process can have one of the accompanying five states one after another.
Q3) What is Process Scheduling of an operating system?A3)On a computer system, there are various processes that should be executed at the same time. Besides, the request for resources vital for their execution are made non concurrently. To deal with contending demands for resources including the processor, the OS utilizes a process scheduler. The process scheduler allots each process the important resources and its turn for execution on the CPU. The decision to schedule a process is made by a basic scheduling algorithm. The scheduler keeps up three queues, appeared in figure below, to schedule the processes. Flow of a process through the Scheduling QueuesProcesses from the job queue will be moved to the ready queue when they are prepared to be executed. At the point when an executing process wait for an I/O device to be free, at that point that process is moved to the device queue where it stays until the mentioned I/O resource ends up available. At that point the process is moved back to the ready queue where it waits for its turn to execute. Q4) What is the different Operation on process of an operating system?A4)There are numerous operations that can be performed on processes. A portion of these are process creation, process preemption, process blocking, and process termination.
- Process State- The present condition of the process i.e., regardless of whether it is ready, running, waiting or whatever.
- Process privileges- This is required to permit/deny access to system resources.
- Process ID- It kept the unique identification number for every process in the t system.
- Pointer- It keeps pointer to parent process.
- Program Counter- It is a pointer to the location of the next instruction that is to be executed by the process.
- CPU registers- Different CPU registers are used where process should be kept for execution in running state.
- CPU Scheduling Information- This keeps process priority and other scheduling information which is needed to schedule a process.
- Memory management information- This incorporates the data of page table, memory limits, Segment table based upon memory utilized by the operating system.
- Accounting information- This incorporates the amount of CPU utilized for process execution, time limits, execution ID and so forth.
- IO status information- This keeps a record of all the I/O devices assigned to the process.
|

- Start- This is the underlying state when a process is first started/created.
- Ready- The process is waiting on to be assigned out to a processor. Ready processes are waiting on to have the processor dispensed to them by the operating system with the goal that they can run. Process may come into this state after Start state or while running it by however interrupted by the scheduler to appoint CPU to some different process.
- Running- When the process has been allotted to a processor by the OS scheduler, the process state is set to running and the processor executes its instructions.
- Waiting- Process moves into the waiting up state on the off chance that it needs to wait tight for a resource, for example, sitting waiting for user input, or waiting that a file will end up accessible.
- Terminated or Exit- When the process completes its execution, or it is ended by the operating system, it is moved to the terminate state where it waits back to be expelled from main memory.
|
- Job queue - The job queue is the arrangement of all processes on the system
- Ready queue - The ready queue has every processes that are loaded in main memory. These processes are ready and waiting for their chance to execute when the CPU will be available.
- Device queue - The set of processes waiting for an I/O device to end up accessible, for example, printer. This queue is otherwise called the Blocked Queue.
Process Creation Processes should be created in the system for various activities. This should be possible by the accompanying events: A process might be created by another process utilizing fork(). The creating process is known as the parent process and the created process is the child process. A child process can have just one parent yet a parent process may have numerous childs. Both the parent and child processes have a similar memory space, open files, and environment strings. But they may have different address spaces.
- User request for process creation
- System initialization
- Execution of a process creation system call by a running process
- Batch job initialization
Process Preemption An interrupt component is utilized in preemption that suspends the process executing as of now and the next process to execute is identified by the short term scheduler. Preemption ensures that all processes get some CPU time for execution.
Process Blocking The process is blocked only if that process is waiting for some event to occur like I?O device availability. This event might be I/O, because the I/O events are executed in the main memory and they don't require the processor for their execution. After the event is finished, the process again goes to the ready state to completes its execution.
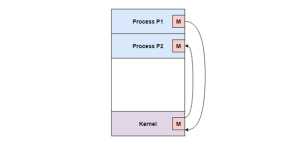
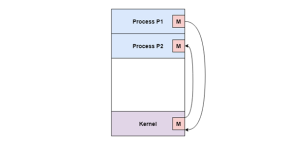
Process Termination After the process has finished the execution all its instructions, it will be terminated. All the resources held by a process are released as soon it is terminated. A child process can be terminated by its parent process if its task is no longer needed. Before terminating the child process sends its complete status to the parent process. Additionally, if the parent process is terminated first, all its child processes terminate automatically also the child processes can't run if the parent processes are terminated. Q5) What is Cooperating process of an operating system?A5) Cooperating processes are those that can affect or are affected by other processes running on the system. Cooperating processes may share data with each other.Reasons for needing cooperating processesThere may be many reasons for the requirement of cooperating processes. Some of these are given as follows −Modularity Modularity involves dividing complicated tasks into smaller subtasks. These subtasks can completed by different cooperating processes. This leads to faster and more efficient completion of the required tasks.Information Sharing Sharing of information between multiple processes can be accomplished using cooperating processes. This may include access to the same files. A mechanism is required so that the processes can access the files in parallel to each other.Convenience There are many tasks that a user needs to do such as compiling, printing, editing etc. It is convenient if these tasks can be managed by cooperating processes.Computation Speedup Subtasks of a single task can be performed parallely using cooperating processes. This increases the computation speedup as the task can be executed faster. However, this is only possible if the system has multiple processing elements.Methods of CooperationCooperating processes can coordinate with each other using shared data or messages. Details about these are given as follows −Cooperation by Sharing The cooperating processes can cooperate with each other using shared data such as memory, variables, files, databases etc. Critical section is used to provide data integrity and writing is mutually exclusive to prevent inconsistent data.A diagram that demonstrates cooperation by sharing is given as follows −In the above diagram, Process P1 and P2 can cooperate with each other using shared data such as memory, variables, files, databases etc.Cooperation by Communication The cooperating processes can cooperate with each other using messages. This may lead to deadlock if each process is waiting for a message from the other to perform a operation. Starvation is also possible if a process never receives a message.A diagram that demonstrates cooperation by communication is given as follows −
In the above diagram, Process P1 and P2 can cooperate with each other using messages to communicate. Q6) What is Threads in an operating system?A6)Thread is a single sequential stream inside a process. Threads have same properties same like process that is why they are also known as light weight processes. Threads are executed in a steady progression however they gives the illusion as though they are executing in parallel. A thread is a progression of execution through the process code, with its very own program counter that monitors which instruction to execute next, system registers which hold its present working factors, and a stack which contains the execution history. Each thread has various states. Each thread has Threads are not free of one another as they share the code, data, OS resources and so forth. Every thread has a place with precisely one process and no thread can exist outside a process. Every thread has a different flow of control. Threads have been effectively utilized in implementing network servers and web server. They additionally give a reasonable establishment to parallel execution of applications on shared memory multiprocessors.
|
- A program counter
- A register set
- A stack space
Q7) Why Threads in an operating system? A7) Following are a few reasons why we use threads in planning operating systems. A process with various threads make an incredible server for instance printer server. Since threads can share regular data, they don't have to utilize interprocess communication. As a result of the very nature, threads can make use of multiprocessors. Threads are cheapest as in Yet, this affordability does not come free - the greatest downside is that there is no assurance between threads.
- They just need a stack and storage for registers subsequently, threads are cheap to make.
- Threads utilize almost no resources of an operating system where they are working. That is, threads needn't bother with new address space, worldwide data, program code or operating system resources.
- Context switching are quick when working with threads. The reason is that we just need to spare and additionally re-establish computer, SP and registers.
Q8) What are the benefits of threads in an operating system?A8) Benefits of ThreadsResponsiveness: Multithreading is an interactive application that may enable a program to keep running regardless of whether a piece of it is blocked or is taking longer time to perform a operation, subsequently expanding responsiveness to the user. In a non multi threaded environment, a server listens to the port for some request and when the request comes, it processes the request and after that resume listening to another request. The time taken while processing of request makes different users hold up superfluously. Rather a superior methodology is pass the request to a worker thread and keep listening to the port. In the event that the process is partitioned into different thread, if one of the thread finishes its execution, at that point its output can be quickly returned. 2. Quicker context switch: Threads are economical to make and wreck, and they are modest to represent. For instance, they expect space to store, the PC, the SP, and the general purpose registers, however they don't expect space to share memory data, information about open files of I/O devices being used, and so forth. With so little context, it is a lot quicker to switch between threads. At the end of the day, it is moderately simpler for a context switch utilizing strings. 3. Effective use of multiprocessor system: If we have various threads in a single process, at that point we can plan numerous threads on different processor. This will make process execution quicker. 4. Resource sharing: Processes may share resources just through strategies, as, Message Passing Shared Memory Such strategies must be expressly sorted out by developer. In any case, threads share the memory and the resources of the process to which they have a place of course. The advantage of sharing code and data is that it enables an application to have a few threads of activity inside same location space. 5. Communication: Communication between various threads is simpler, as the threads shares same location space, while in process we need to pursue some particular communication method for communication between two process. Upgraded throughput of the system: If a process is separated into numerous threads, and each thread function is considered as one job, at that point the quantity of job finished per unit of time is expanded, in this way expanding the throughput of the system. Q9) What is Inter process communication (Algorithm evaluation) of an operating system?A9)Inter-process communication (IPC) is a system that permits the trading of data between processes. By providing a user with a lot of programming interfaces, IPC enables a software engineer to compose the activities among various processes. IPC enables one application to control another application, by empowering data sharing without interference. IPC empowers data communication by enabling processes to utilize segments, semaphores, and different strategies to share memory and data. IPC encourages effective message move between processes. The base of IPC depends on Task Control Architecture (TCA). It is an adaptable method that can send and get variable length clusters, data structures, and lists. There are various explanations behind giving a domain or circumstance which permits process co-operation: Cooperating with different processes, require an interprocess communication (IPC) strategy which will enable them to exchange data with different data. There are two essential models of interprocess communication: Figure below exhibits the shared memory model and message passing model is shown below:
Models of Interprocess Communication
- Data sharing: Since certain users might be interested in a similar piece of data (for instance, a shared file), you should give a circumstance to enabling simultaneous access to that data.
- Computation speedup: If you need a specific work to run quick, you should break it into sub-tasks where every one of them will get executed in parallel with other tasks. Note that such an accelerate can be achieved just when the computer has compound or different processing components like CPUs or I/O channels.
- Modularity: You might need to build the system in a modular manner by partitioning the system functions into split processes or threads.
- Convenience: Even a single user will be able to work on many tasks simultaneously. For instance, a user might be editing, formatting, printing, and compiling in parallel.
- Shared memory and
- Message passing.
|
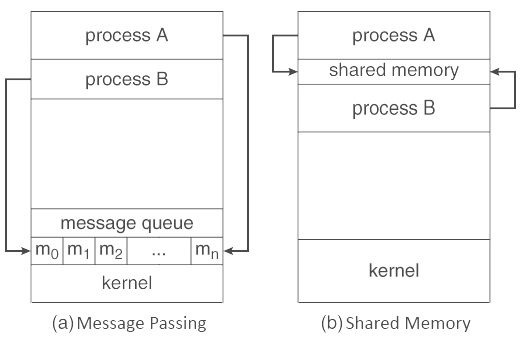
Shared Memory Model In the shared-memory model, an area of memory which is shared by cooperating processes gets set up. Processes can be then ready to share data by reading and writing every data to the shared region. Shared memory is the memory that can be at the same time access by different processes. This is done as such that the processes can speak with one another. All POSIX systems, just as Windows operating systems utilize shared memory. Advantages of Shared Memory Model Memory communication is quicker on the shared memory model when contrasted with the message passing model on a similar machine. Disadvantages of Shared Memory Model Every one of the processes that utilize the shared memory model need to ensure that they are not writing to the same memory area. Shared memory model may make issues, for example, synchronization and memory protection that should be tended to.
Message Passing Model In the message-passing structure, communication happens by method of messages exchange among the cooperating processes. Various processes can read and write data to the message queue without being associated with one another. Messages are stored on the queue until their respective recipient recovers them. Message queues are very helpful for interprocess communication and are utilized by most operating systems. Advantages of Messaging Passing Model The message passing model is a lot simpler to design than the shared memory model. Disadvantage of Messaging Passing Model The message passing model has more slow communication than the shared memory model on the grounds that the connection implementation requires more time. Q10) What is Multiple processor scheduling in an operating system explain in detail?A10) In multiple-processor scheduling multiple CPU’s are available and hence Load Sharing becomes possible. However multiple processor scheduling is more complex as compared to single processor scheduling. In multiple processor scheduling there are cases when the processors are identical i.e. HOMOGENEOUS, in terms of their functionality, we can use any processor available to run any process in the queue.Approaches to Multiple-Processor Scheduling –One approach is when all the scheduling decisions and I/O processing are handled by a single processor which is called the Master Server and the other processors executes only the user code. This is simple and reduces the need of data sharing. This entire scenario is called Asymmetric Multiprocessing.A second approach uses Symmetric Multiprocessing where each processor is self scheduling. All processes may be in a common ready queue or each processor may have its own private queue for ready processes. The scheduling proceeds further by having the scheduler for each processor examine the ready queue and select a process to execute.Processor Affinity –Processor Affinity means a processes has an affinity for the processor on which it is currently running.
When a process runs on a specific processor there are certain effects on the cache memory. The data most recently accessed by the process populate the cache for the processor and as a result successive memory access by the process are often satisfied in the cache memory. Now if the process migrates to another processor, the contents of the cache memory must be invalidated for the first processor and the cache for the second processor must be repopulated. Because of the high cost of invalidating and repopulating caches, most of the SMP(symmetric multiprocessing) systems try to avoid migration of processes from one processor to another and try to keep a process running on the same processor. This is known as PROCESSOR AFFINITY.There are two types of processor affinity:Soft Affinity – When an operating system has a policy of attempting to keep a process running on the same processor but not guaranteeing it will do so, this situation is called soft affinity. Hard Affinity – Hard Affinity allows a process to specify a subset of processors on which it may run. Some systems such as Linux implements soft affinity but also provide some system calls like sched_setaffinity() that supports hard affinity. Load Balancing –Load Balancing is the phenomena which keeps the workload evenly distributed across all processors in an SMP system. Load balancing is necessary only on systems where each processor has its own private queue of process which are eligible to execute. Load balancing is unnecessary because once a processor becomes idle it immediately extracts a runnable process from the common run queue. On SMP(symmetric multiprocessing), it is important to keep the workload balanced among all processors to fully utilize the benefits of having more than one processor else one or more processor will sit idle while other processors have high workloads along with lists of processors awaiting the CPU.There are two general approaches to load balancing :Push Migration – In push migration a task routinely checks the load on each processor and if it finds an imbalance then it evenly distributes load on each processors by moving the processes from overloaded to idle or less busy processors. Pull Migration – Pull Migration occurs when an idle processor pulls a waiting task from a busy processor for its execution. Multicore Processors –In multicore processors multiple processor cores are places on the same physical chip. Each core has a register set to maintain its architectural state and thus appears to the operating system as a separate physical processor. SMP systems that use multicore processors are faster and consume less power than systems in which each processor has its own physical chip.However multicore processors may complicate the scheduling problems. When processor accesses memory then it spends a significant amount of time waiting for the data to become available. This situation is called MEMORY STALL. It occurs for various reasons such as cache miss, which is accessing the data that is not in the cache memory. In such cases the processor can spend upto fifty percent of its time waiting for data to become available from the memory. To solve this problem recent hardware designs have implemented multithreaded processor cores in which two or more hardware threads are assigned to each core. Therefore if one thread stalls while waiting for the memory, core can switch to another thread.There are two ways to multithread a processor :Coarse-Grained Multithreading – In coarse grained multithreading a thread executes on a processor until a long latency event such as a memory stall occurs, because of the delay caused by the long latency event, the processor must switch to another thread to begin execution. The cost of switching between threads is high as the instruction pipeline must be terminated before the other thread can begin execution on the processor core. Once this new thread begins execution it begins filling the pipeline with its instructions. Fine-Grained Multithreading – This multithreading switches between threads at a much finer level mainly at the boundary of an instruction cycle. The architectural design of fine grained systems include logic for thread switching and as a result the cost of switching between threads is small. Virtualization and Threading –In this type of multiple-processor scheduling even a single CPU system acts like a multiple-processor system. In a system with Virtualization, the virtualization presents one or more virtual CPU to each of virtual machines running on the system and then schedules the use of physical CPU among the virtual machines. Most virtualized environments have one host operating system and many guest operating systems. The host operating system creates and manages the virtual machines. Each virtual machine has a guest operating system installed and applications run within that guest.Each guest operating system may be assigned for specific use cases,applications or users including time sharing or even real-time operation. Any guest operating-system scheduling algorithm that assumes a certain amount of progress in a given amount of time will be negatively impacted by the virtualization. A time sharing operating system tries to allot 100 milliseconds to each time slice to give users a reasonable response time. A given 100 millisecond time slice may take much more than 100 milliseconds of virtual CPU time. Depending on how busy the system is, the time slice may take a second or more which results in a very poor response time for users logged into that virtual machine. The net effect of such scheduling layering is that individual virtualized operating systems receive only a portion of the available CPU cycles, even though they believe they are receiving all cycles and that they are scheduling all of those cycles.Commonly, the time-of-day clocks in virtual machines are incorrect because timers take no longer to trigger than they would on dedicated CPU’s. Virtualizations can thus undo the good scheduling-algorithm efforts of the operating systems within virtual machines.
When a process runs on a specific processor there are certain effects on the cache memory. The data most recently accessed by the process populate the cache for the processor and as a result successive memory access by the process are often satisfied in the cache memory. Now if the process migrates to another processor, the contents of the cache memory must be invalidated for the first processor and the cache for the second processor must be repopulated. Because of the high cost of invalidating and repopulating caches, most of the SMP(symmetric multiprocessing) systems try to avoid migration of processes from one processor to another and try to keep a process running on the same processor. This is known as PROCESSOR AFFINITY.There are two types of processor affinity:
UNIT - 4Introduction to Parallel ProcessingQ1) What is the Process Concept?A1)A process is a program in execution. The execution of a process must go in a sequentially. Process isn't as same as program code yet much more than it. A process is a 'active' element instead of program which is viewed as a 'passive' entity. Properties held by process incorporate hardware state, memory, CPU and so forth. Based on the operating system (OS), a process might be comprised of numerous threads of execution that execute instructions simultaneously. While a computer program is an inactive collection of instructions, a process is the real execution of those instructions. A few processes might be related with a similar program; for instance, opening up a few occurrences of a similar program regularly brings about more than one process being executed. Process memory is isolated into four segments for effective working : max
0A process can be comprehensively ordered into the following two types dependent on its execution:
- The Text section is comprised of the compiled program code, read in from non-volatile storage when the program is launched.
- The Data section is made up of global and static variables, allotted and introduced before executing the primary.
- The Heap is utilized for the dynamic memory distribution, and is managed through calls to new, delete, malloc, free, and so on.
- The Stack is utilized for local variables. Space on the stack is saved for local variables when they are declared.
Stack |
|
Heap |
Data |
Text |
- I/O-Bound Process - An I/O-bound process is a process whose execution time is resolved principally by the measure of time it spends finishing I/O operations.
- CPU-Bound Process - A CPU-bound process is a process whose execution time is dictated by the speed of the CPU it keeps running on. A CPU-bound process can finish its execution quicker in the event that it is running on a quicker processor.
Q2) What is process control back and process state of an operating system? A2) Process Control Back (PCB)A Process Control Block is a data structure kept up by the Operating System for each process. The PCB is distinguished by a number process ID (PID). The job of the PCBs is main in process management: they are accessed and/or altered by most OS utilities, incorporating those associated with scheduling, memory and I/O resource access and performance monitoring. It very well may be said that the arrangement of the PCBs characterizes the present condition of the operating system. A PCB keeps all the data expected to monitor a process as mentioned below − The engineering of a PCB is totally subject to Operating System and may contain distinctive data in various operating systems. Here is an improved graph of a PCB −
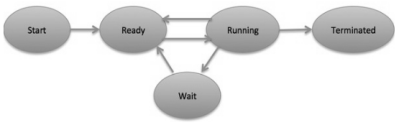
Process StateAt some point when a process executes, it goes through various states. These stages may contrast in various operating systems, and the names of these states are likewise not fixed. All in all, a process can have one of the accompanying five states one after another.
Q3) What is Process Scheduling of an operating system?A3)On a computer system, there are various processes that should be executed at the same time. Besides, the request for resources vital for their execution are made non concurrently. To deal with contending demands for resources including the processor, the OS utilizes a process scheduler. The process scheduler allots each process the important resources and its turn for execution on the CPU. The decision to schedule a process is made by a basic scheduling algorithm. The scheduler keeps up three queues, appeared in figure below, to schedule the processes. Flow of a process through the Scheduling QueuesProcesses from the job queue will be moved to the ready queue when they are prepared to be executed. At the point when an executing process wait for an I/O device to be free, at that point that process is moved to the device queue where it stays until the mentioned I/O resource ends up available. At that point the process is moved back to the ready queue where it waits for its turn to execute. Q4) What is the different Operation on process of an operating system?A4)There are numerous operations that can be performed on processes. A portion of these are process creation, process preemption, process blocking, and process termination.
- Process State- The present condition of the process i.e., regardless of whether it is ready, running, waiting or whatever.
- Process privileges- This is required to permit/deny access to system resources.
- Process ID- It kept the unique identification number for every process in the t system.
- Pointer- It keeps pointer to parent process.
- Program Counter- It is a pointer to the location of the next instruction that is to be executed by the process.
- CPU registers- Different CPU registers are used where process should be kept for execution in running state.
- CPU Scheduling Information- This keeps process priority and other scheduling information which is needed to schedule a process.
- Memory management information- This incorporates the data of page table, memory limits, Segment table based upon memory utilized by the operating system.
- Accounting information- This incorporates the amount of CPU utilized for process execution, time limits, execution ID and so forth.
- IO status information- This keeps a record of all the I/O devices assigned to the process.
|

- Start- This is the underlying state when a process is first started/created.
- Ready- The process is waiting on to be assigned out to a processor. Ready processes are waiting on to have the processor dispensed to them by the operating system with the goal that they can run. Process may come into this state after Start state or while running it by however interrupted by the scheduler to appoint CPU to some different process.
- Running- When the process has been allotted to a processor by the OS scheduler, the process state is set to running and the processor executes its instructions.
- Waiting- Process moves into the waiting up state on the off chance that it needs to wait tight for a resource, for example, sitting waiting for user input, or waiting that a file will end up accessible.
- Terminated or Exit- When the process completes its execution, or it is ended by the operating system, it is moved to the terminate state where it waits back to be expelled from main memory.
|
- Job queue - The job queue is the arrangement of all processes on the system
- Ready queue - The ready queue has every processes that are loaded in main memory. These processes are ready and waiting for their chance to execute when the CPU will be available.
- Device queue - The set of processes waiting for an I/O device to end up accessible, for example, printer. This queue is otherwise called the Blocked Queue.
Process Creation Processes should be created in the system for various activities. This should be possible by the accompanying events: A process might be created by another process utilizing fork(). The creating process is known as the parent process and the created process is the child process. A child process can have just one parent yet a parent process may have numerous childs. Both the parent and child processes have a similar memory space, open files, and environment strings. But they may have different address spaces.
- User request for process creation
- System initialization
- Execution of a process creation system call by a running process
- Batch job initialization
Process Preemption An interrupt component is utilized in preemption that suspends the process executing as of now and the next process to execute is identified by the short term scheduler. Preemption ensures that all processes get some CPU time for execution.
Process Blocking The process is blocked only if that process is waiting for some event to occur like I?O device availability. This event might be I/O, because the I/O events are executed in the main memory and they don't require the processor for their execution. After the event is finished, the process again goes to the ready state to completes its execution.
Process Termination After the process has finished the execution all its instructions, it will be terminated. All the resources held by a process are released as soon it is terminated. A child process can be terminated by its parent process if its task is no longer needed. Before terminating the child process sends its complete status to the parent process. Additionally, if the parent process is terminated first, all its child processes terminate automatically also the child processes can't run if the parent processes are terminated. Q5) What is Cooperating process of an operating system?A5) Cooperating processes are those that can affect or are affected by other processes running on the system. Cooperating processes may share data with each other.Reasons for needing cooperating processesThere may be many reasons for the requirement of cooperating processes. Some of these are given as follows −Modularity Modularity involves dividing complicated tasks into smaller subtasks. These subtasks can completed by different cooperating processes. This leads to faster and more efficient completion of the required tasks.Information Sharing Sharing of information between multiple processes can be accomplished using cooperating processes. This may include access to the same files. A mechanism is required so that the processes can access the files in parallel to each other.Convenience There are many tasks that a user needs to do such as compiling, printing, editing etc. It is convenient if these tasks can be managed by cooperating processes.Computation Speedup Subtasks of a single task can be performed parallely using cooperating processes. This increases the computation speedup as the task can be executed faster. However, this is only possible if the system has multiple processing elements.Methods of CooperationCooperating processes can coordinate with each other using shared data or messages. Details about these are given as follows −Cooperation by Sharing The cooperating processes can cooperate with each other using shared data such as memory, variables, files, databases etc. Critical section is used to provide data integrity and writing is mutually exclusive to prevent inconsistent data.A diagram that demonstrates cooperation by sharing is given as follows −In the above diagram, Process P1 and P2 can cooperate with each other using shared data such as memory, variables, files, databases etc.Cooperation by Communication The cooperating processes can cooperate with each other using messages. This may lead to deadlock if each process is waiting for a message from the other to perform a operation. Starvation is also possible if a process never receives a message.A diagram that demonstrates cooperation by communication is given as follows −
In the above diagram, Process P1 and P2 can cooperate with each other using messages to communicate. Q6) What is Threads in an operating system?A6)Thread is a single sequential stream inside a process. Threads have same properties same like process that is why they are also known as light weight processes. Threads are executed in a steady progression however they gives the illusion as though they are executing in parallel. A thread is a progression of execution through the process code, with its very own program counter that monitors which instruction to execute next, system registers which hold its present working factors, and a stack which contains the execution history. Each thread has various states. Each thread has Threads are not free of one another as they share the code, data, OS resources and so forth. Every thread has a place with precisely one process and no thread can exist outside a process. Every thread has a different flow of control. Threads have been effectively utilized in implementing network servers and web server. They additionally give a reasonable establishment to parallel execution of applications on shared memory multiprocessors.
|
- A program counter
- A register set
- A stack space
Q7) Why Threads in an operating system? A7) Following are a few reasons why we use threads in planning operating systems. A process with various threads make an incredible server for instance printer server. Since threads can share regular data, they don't have to utilize interprocess communication. As a result of the very nature, threads can make use of multiprocessors. Threads are cheapest as in Yet, this affordability does not come free - the greatest downside is that there is no assurance between threads.
- They just need a stack and storage for registers subsequently, threads are cheap to make.
- Threads utilize almost no resources of an operating system where they are working. That is, threads needn't bother with new address space, worldwide data, program code or operating system resources.
- Context switching are quick when working with threads. The reason is that we just need to spare and additionally re-establish computer, SP and registers.
Q8) What are the benefits of threads in an operating system?A8) Benefits of ThreadsResponsiveness: Multithreading is an interactive application that may enable a program to keep running regardless of whether a piece of it is blocked or is taking longer time to perform a operation, subsequently expanding responsiveness to the user. In a non multi threaded environment, a server listens to the port for some request and when the request comes, it processes the request and after that resume listening to another request. The time taken while processing of request makes different users hold up superfluously. Rather a superior methodology is pass the request to a worker thread and keep listening to the port. In the event that the process is partitioned into different thread, if one of the thread finishes its execution, at that point its output can be quickly returned. 2. Quicker context switch: Threads are economical to make and wreck, and they are modest to represent. For instance, they expect space to store, the PC, the SP, and the general purpose registers, however they don't expect space to share memory data, information about open files of I/O devices being used, and so forth. With so little context, it is a lot quicker to switch between threads. At the end of the day, it is moderately simpler for a context switch utilizing strings. 3. Effective use of multiprocessor system: If we have various threads in a single process, at that point we can plan numerous threads on different processor. This will make process execution quicker. 4. Resource sharing: Processes may share resources just through strategies, as, Message Passing Shared Memory Such strategies must be expressly sorted out by developer. In any case, threads share the memory and the resources of the process to which they have a place of course. The advantage of sharing code and data is that it enables an application to have a few threads of activity inside same location space. 5. Communication: Communication between various threads is simpler, as the threads shares same location space, while in process we need to pursue some particular communication method for communication between two process. Upgraded throughput of the system: If a process is separated into numerous threads, and each thread function is considered as one job, at that point the quantity of job finished per unit of time is expanded, in this way expanding the throughput of the system. Q9) What is Inter process communication (Algorithm evaluation) of an operating system?A9)Inter-process communication (IPC) is a system that permits the trading of data between processes. By providing a user with a lot of programming interfaces, IPC enables a software engineer to compose the activities among various processes. IPC enables one application to control another application, by empowering data sharing without interference. IPC empowers data communication by enabling processes to utilize segments, semaphores, and different strategies to share memory and data. IPC encourages effective message move between processes. The base of IPC depends on Task Control Architecture (TCA). It is an adaptable method that can send and get variable length clusters, data structures, and lists. There are various explanations behind giving a domain or circumstance which permits process co-operation: Cooperating with different processes, require an interprocess communication (IPC) strategy which will enable them to exchange data with different data. There are two essential models of interprocess communication: Figure below exhibits the shared memory model and message passing model is shown below:
Models of Interprocess Communication
- Data sharing: Since certain users might be interested in a similar piece of data (for instance, a shared file), you should give a circumstance to enabling simultaneous access to that data.
- Computation speedup: If you need a specific work to run quick, you should break it into sub-tasks where every one of them will get executed in parallel with other tasks. Note that such an accelerate can be achieved just when the computer has compound or different processing components like CPUs or I/O channels.
- Modularity: You might need to build the system in a modular manner by partitioning the system functions into split processes or threads.
- Convenience: Even a single user will be able to work on many tasks simultaneously. For instance, a user might be editing, formatting, printing, and compiling in parallel.
- Shared memory and
- Message passing.
|
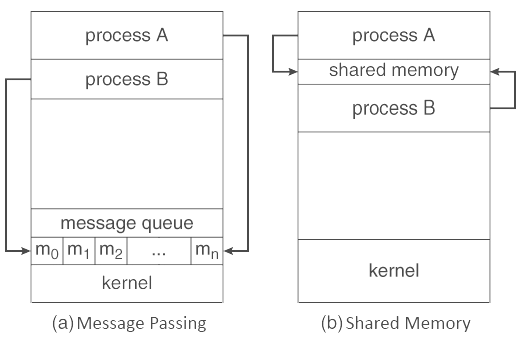
Shared Memory Model In the shared-memory model, an area of memory which is shared by cooperating processes gets set up. Processes can be then ready to share data by reading and writing every data to the shared region. Shared memory is the memory that can be at the same time access by different processes. This is done as such that the processes can speak with one another. All POSIX systems, just as Windows operating systems utilize shared memory. Advantages of Shared Memory Model Memory communication is quicker on the shared memory model when contrasted with the message passing model on a similar machine. Disadvantages of Shared Memory Model Every one of the processes that utilize the shared memory model need to ensure that they are not writing to the same memory area. Shared memory model may make issues, for example, synchronization and memory protection that should be tended to.
Message Passing Model In the message-passing structure, communication happens by method of messages exchange among the cooperating processes. Various processes can read and write data to the message queue without being associated with one another. Messages are stored on the queue until their respective recipient recovers them. Message queues are very helpful for interprocess communication and are utilized by most operating systems. Advantages of Messaging Passing Model The message passing model is a lot simpler to design than the shared memory model. Disadvantage of Messaging Passing Model The message passing model has more slow communication than the shared memory model on the grounds that the connection implementation requires more time. Q10) What is Multiple processor scheduling in an operating system explain in detail?A10) In multiple-processor scheduling multiple CPU’s are available and hence Load Sharing becomes possible. However multiple processor scheduling is more complex as compared to single processor scheduling. In multiple processor scheduling there are cases when the processors are identical i.e. HOMOGENEOUS, in terms of their functionality, we can use any processor available to run any process in the queue.Approaches to Multiple-Processor Scheduling –One approach is when all the scheduling decisions and I/O processing are handled by a single processor which is called the Master Server and the other processors executes only the user code. This is simple and reduces the need of data sharing. This entire scenario is called Asymmetric Multiprocessing.A second approach uses Symmetric Multiprocessing where each processor is self scheduling. All processes may be in a common ready queue or each processor may have its own private queue for ready processes. The scheduling proceeds further by having the scheduler for each processor examine the ready queue and select a process to execute.Processor Affinity –Processor Affinity means a processes has an affinity for the processor on which it is currently running.
When a process runs on a specific processor there are certain effects on the cache memory. The data most recently accessed by the process populate the cache for the processor and as a result successive memory access by the process are often satisfied in the cache memory. Now if the process migrates to another processor, the contents of the cache memory must be invalidated for the first processor and the cache for the second processor must be repopulated. Because of the high cost of invalidating and repopulating caches, most of the SMP(symmetric multiprocessing) systems try to avoid migration of processes from one processor to another and try to keep a process running on the same processor. This is known as PROCESSOR AFFINITY.There are two types of processor affinity:Soft Affinity – When an operating system has a policy of attempting to keep a process running on the same processor but not guaranteeing it will do so, this situation is called soft affinity. Hard Affinity – Hard Affinity allows a process to specify a subset of processors on which it may run. Some systems such as Linux implements soft affinity but also provide some system calls like sched_setaffinity() that supports hard affinity. Load Balancing –Load Balancing is the phenomena which keeps the workload evenly distributed across all processors in an SMP system. Load balancing is necessary only on systems where each processor has its own private queue of process which are eligible to execute. Load balancing is unnecessary because once a processor becomes idle it immediately extracts a runnable process from the common run queue. On SMP(symmetric multiprocessing), it is important to keep the workload balanced among all processors to fully utilize the benefits of having more than one processor else one or more processor will sit idle while other processors have high workloads along with lists of processors awaiting the CPU.There are two general approaches to load balancing :Push Migration – In push migration a task routinely checks the load on each processor and if it finds an imbalance then it evenly distributes load on each processors by moving the processes from overloaded to idle or less busy processors. Pull Migration – Pull Migration occurs when an idle processor pulls a waiting task from a busy processor for its execution. Multicore Processors –In multicore processors multiple processor cores are places on the same physical chip. Each core has a register set to maintain its architectural state and thus appears to the operating system as a separate physical processor. SMP systems that use multicore processors are faster and consume less power than systems in which each processor has its own physical chip.However multicore processors may complicate the scheduling problems. When processor accesses memory then it spends a significant amount of time waiting for the data to become available. This situation is called MEMORY STALL. It occurs for various reasons such as cache miss, which is accessing the data that is not in the cache memory. In such cases the processor can spend upto fifty percent of its time waiting for data to become available from the memory. To solve this problem recent hardware designs have implemented multithreaded processor cores in which two or more hardware threads are assigned to each core. Therefore if one thread stalls while waiting for the memory, core can switch to another thread.There are two ways to multithread a processor :Coarse-Grained Multithreading – In coarse grained multithreading a thread executes on a processor until a long latency event such as a memory stall occurs, because of the delay caused by the long latency event, the processor must switch to another thread to begin execution. The cost of switching between threads is high as the instruction pipeline must be terminated before the other thread can begin execution on the processor core. Once this new thread begins execution it begins filling the pipeline with its instructions. Fine-Grained Multithreading – This multithreading switches between threads at a much finer level mainly at the boundary of an instruction cycle. The architectural design of fine grained systems include logic for thread switching and as a result the cost of switching between threads is small. Virtualization and Threading –In this type of multiple-processor scheduling even a single CPU system acts like a multiple-processor system. In a system with Virtualization, the virtualization presents one or more virtual CPU to each of virtual machines running on the system and then schedules the use of physical CPU among the virtual machines. Most virtualized environments have one host operating system and many guest operating systems. The host operating system creates and manages the virtual machines. Each virtual machine has a guest operating system installed and applications run within that guest.Each guest operating system may be assigned for specific use cases,applications or users including time sharing or even real-time operation. Any guest operating-system scheduling algorithm that assumes a certain amount of progress in a given amount of time will be negatively impacted by the virtualization. A time sharing operating system tries to allot 100 milliseconds to each time slice to give users a reasonable response time. A given 100 millisecond time slice may take much more than 100 milliseconds of virtual CPU time. Depending on how busy the system is, the time slice may take a second or more which results in a very poor response time for users logged into that virtual machine. The net effect of such scheduling layering is that individual virtualized operating systems receive only a portion of the available CPU cycles, even though they believe they are receiving all cycles and that they are scheduling all of those cycles.Commonly, the time-of-day clocks in virtual machines are incorrect because timers take no longer to trigger than they would on dedicated CPU’s. Virtualizations can thus undo the good scheduling-algorithm efforts of the operating systems within virtual machines.
When a process runs on a specific processor there are certain effects on the cache memory. The data most recently accessed by the process populate the cache for the processor and as a result successive memory access by the process are often satisfied in the cache memory. Now if the process migrates to another processor, the contents of the cache memory must be invalidated for the first processor and the cache for the second processor must be repopulated. Because of the high cost of invalidating and repopulating caches, most of the SMP(symmetric multiprocessing) systems try to avoid migration of processes from one processor to another and try to keep a process running on the same processor. This is known as PROCESSOR AFFINITY.There are two types of processor affinity:





0 matching results found