Unit - 2
Relational Model
Q1) Explain relational data model?
A1) The primary data model is the Relational Data Model, which is commonly used for data storage and processing around the world. This model is simple and has all the features and functionality needed to process data with efficiency in storage.
The relational model can be interpreted as a table with rows and columns. Each row is called a tuple. There's a name or attribute for each table in the column.
Basic concept:
Table: Relationships are saved in the format of tables in a relational data model. The relationship between entities is stored in this format. A table includes rows and columns, where rows represent information, and attributes are represented by columns.
Tuple: A tuple is called a single row of a table, which contains a single record for that relationship.
Attributes and Domains
Domain: It includes a set of atomic values that can be adopted by an attribute.
Attribute: In a specific table, it includes the name of a column. Every Ai attribute must have a domain, a domain (Ai)
Relational instance: The relational example is represented in the relational database structure by a finite set of tuples. There are no duplicate tuples for relation instances.
Relational schema: The name of the relationship and the name of all columns or attributes are used in a relational schema.
Relational key: Each row has one or more attributes in the relational key. It can uniquely identify the row in the association.
Example: STUDENT Relation
NAME | ROLL_NO | PHONE_NO | ADDRESS | AGE |
Ram | 14795 | 7305758992 | Noida | 24 |
Shyam | 12839 | 9026288936 | Delhi | 35 |
Laxman | 33289 | 8583287182 | Gurugram | 20 |
Mahesh | 27857 | 7086819134 | Ghaziabad | 27 |
Ganesh | 17282 | 9028 9i3988 | Delhi | 40 |
● In the given table, NAME, ROLL_NO, PHONE_NO, ADDRESS, and AGE are the attributes.
● The instance of schema STUDENT has 5 tuples.
● t3 = <Laxman, 33289, 8583287182, Gurugram, 20>
Q2) Write the properties of relational models?
A2) Properties of Relational model
● The relation's name is separate from the names of all other relatives.
● There is just one atomic (single) value in each relation cell.
● Each attribute is given a unique name.
● The domain of an attribute has no meaning.
● There are no duplicate values in tuple.
● The sequence of a tuple can be different.
Q3) What is the concept of relation?
A3) Relational data model is the primary data model, which is used widely around the world for data storage and processing. This model is simple and it has all the properties and capabilities required to process data with storage efficiency.
Concepts
Tables−In relational data model, relations are saved in the format of Tables. This format stores the relation among entities. A table has rows and columns, where rows represent records and columns represent the attributes.
Tuple− A single row of a table, which contains a single record for that relation is called a tuple.
Relation instance− A finite set of tuples in the relational database system represents relation instance. Relation instances do not have duplicate tuples.
Relation schema− A relation schema describes the relation name (table name), attributes, and their names.
Relation key−Each row has one or more attributes, known as relation key, which can identify the row in the relation (table) uniquely.
Attribute domain−Every attribute has some predefined value scope, known as attribute domain.
Constraints
Every relation has some conditions that must hold for it to be a valid relation. These conditions are called Relational Integrity Constraints. There are three main integrity constraints −
● Key constraints
● Domain constraints
● Referential integrity constraints
Key Constraints
There must be at least one minimal subset of attributes in the relation, which can identify a tuple uniquely. This minimal subset of attributes is called key for that relation. If there are more than one such minimal subsets, these are called candidate keys.
Key constraints force that −
● in a relation with a key attribute, no two tuples can have identical values for key attributes.
● a key attribute cannot have NULL values.
Key constraints are also referred to as Entity Constraints.
Domain Constraints
Attributes have specific values in real-world scenario. For example, age can only be a positive integer. The same constraints have been tried to employ on the attributes of a relation. Every attribute is bound to have a specific range of values. For example, age cannot be less than zero and telephone numbers cannot contain a digit outside 0-9.
Referential integrity Constraints
Referential integrity constraints work on the concept of Foreign Keys. A foreign key is a key attribute of a relation that can be referred in other relation.
Referential integrity constraint states that if a relation refers to a key attribute of a different or same relation, then that key element must exist.
Q4) Explain schema and instance?
A4) Database Schema
A database schema is the skeleton structure that represents the logical view of the entire database. It defines how the data is organized and how the relations among them are associated. It formulates all the constraints that are to be applied on the data.
A database schema defines its entities and the relationship among them. It contains a descriptive detail of the database, which can be depicted by means of schema diagrams. It’s the database designers who design the schema to help programmers understand the database and make it useful.
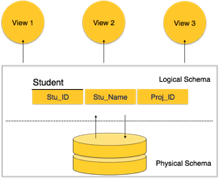
Fig - Database schema
A database schema can be divided broadly into two categories −
● Physical Database Schema−This schema pertains to the actual storage of data and its form of storage like files, indices, etc. It defines how the data will be stored in a secondary storage.
● Logical Database Schema−This schema defines all the logical constraints that need to be applied on the data stored. It defines tables, views, and integrity constraints.
Database Instance
It is important that we distinguish these two terms individually. Database schema is the skeleton of database. It is designed when the database doesn't exist at all. Once the database is operational, it is very difficult to make any changes to it. A database schema does not contain any data or information.
A database instance is a state of operational database with data at any given time. It contains a snapshot of the database. Database instances tend to change with time. A DBMS ensures that its every instance (state) is in a valid state, by diligently following all the validations, constraints, and conditions that the database designers have imposed.
Q5) Explain keys?
A5) Keys are the entity's attributes, which define the entity's record uniquely.
Several types of keys exist.
These are listed underneath:
● Composite key
A composite key consists of two attributes or more, but it must be minimal.
● Candidate key
A candidate key is a key that is simple or composite and special and minimal. It is special since no two rows can have the same value at any time in a table. It is minimal since, in order to achieve uniqueness, every column is required.
● Super key
The Super Key is one or more of the entity's attributes that uniquely define the database record.
● Primary key
The primary key is a candidate key that the database designer chooses to be used as an identification mechanism for the entire set of entities. In a table, it must uniquely classify tuples and not be null.
In the ER model, the primary key is indicated by underlining the attribute.
● To uniquely recognize tuples in a table, the designer selects a candidate key. It must not be empty.
● A key is selected by the database builder to be used by the entire entity collection as an authentication mechanism. This is regarded as the primary key. In the ER model, this key is indicated by underlining the attribute.
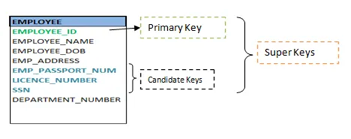
Fig: Shows different keys
● Alternate key
Alternate keys are all candidate keys not chosen as the primary key.
● Foreign key
A foreign key (FK) is an attribute in a table that, in another table, references the primary key OR it may be null. The same data type must be used for both international and primary keys.

Fig: Foreign key
● Secondary key
A secondary key is an attribute used exclusively (can be composite) for retrieval purposes, such as: phone and last name.
Q6) Describe integrity constraints?
A6) Integrity constraints are a set of rules. It is used to maintain the quality of information.
● Integrity constraints ensure that the data insertion, updating, and other processes have to be performed in such a way that data integrity is not affected.
● Thus, integrity constraint is used to guard against accidental damage to the database.
Types of Integrity Constraint
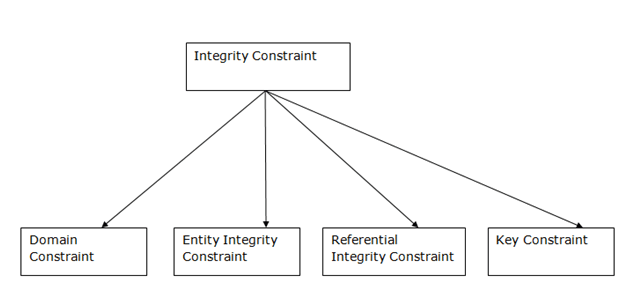
Fig - Integrity Constraint
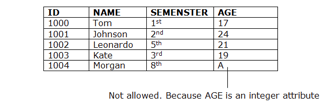
1. Domain constraints
● Domain constraints can be defined as the definition of a valid set of values for an attribute.
● The data type of domain includes string, character, integer, time, date, currency, etc. The value of the attribute must be available in the corresponding domain.
Example:
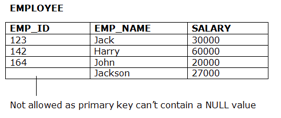
2. Entity integrity constraints
● The entity integrity constraint states that primary key value can't be null.
● This is because the primary key value is used to identify individual rows in relation and if the primary key has a null value, then we can't identify those rows.
● A table can contain a null value other than the primary key field.
Example:
3. Referential Integrity Constraints
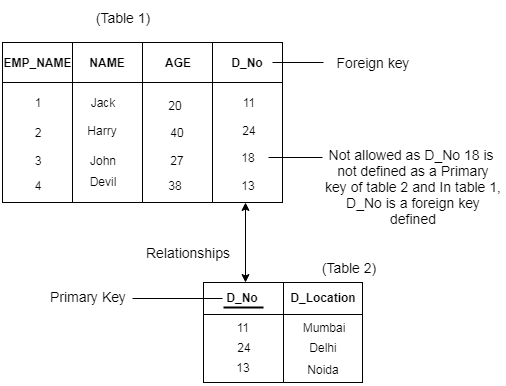
● A referential integrity constraint is specified between two tables.
● In the Referential integrity constraints, if a foreign key in Table 1 refers to the Primary Key of Table 2, then every value of the Foreign Key in Table 1 must be null or be available in Table 2.
Example:
4. Key constraints
● Keys are the entity set that is used to identify an entity within its entity set uniquely.
● An entity set can have multiple keys, but out of which one key will be the primary key. A primary key can contain a unique and null value in the relational table.
Example:

Q7) Define relational algebra operators?
A7) Relational Algebra is procedural query language. It takes Relation as input and generates relation as output. Relational algebra mainly provides theoretical foundation for relational databases and SQL.
Basic Operations which can be performed using relational algebra are:
1. Projection
2. Selection
3. Join
4. Union
5. Set Difference
6. Intersection
7. Cartesian product
8. Rename
Consider following relation R (A, B, C)
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
2 | 3 | 4 |
5 | 4 | 5 |
- Projection (π):
This operation is used to select particular columns from the relation.
Π(AB) R:
It will select A and B column from the relation R. It produces the output like:
A | B |
1 | 1 |
2 | 3 |
4 | 1 |
5 | 4 |
Project operation automatically removes duplicates from the resultant set.
2. Selection (σ):
This operation is used to select particular tuples from the relation.
σ(C<4) R:
It will select the tuples which have a value of c less than 4.
But select operation is used to only select the required tuples from the relation. To display those tuples on screen, select operation must be combined with project operation.
Π (σ (C<4) R) will produce the result like:
A | B | C |
1 | 1 | 1 |
2 | 3 | 1 |
4 | 1 | 3 |
3. Join
A Cartesian product followed by a selection criterion is basically a joint process.
Operation of join, denoted by ⋈
The JOIN operation often allows tuples from different relationships to join different tuples
Types of JOIN:
Various forms of join operation are:
Inner Joins:
● Theta join
● EQUI join
● Natural join
Outer join:
● Left Outer Join
● Right Outer Join
● Full Outer Join
4. Union
Union operation in relational algebra is the same as union operation in set theory, only the restriction is that both relations must have the same set of attributes for a union of two relationships.
Syntax: table_name1 ∪ table_name2
For instance, if we have two tables with RegularClass and ExtraClass, both have a student column to save the student name, then,
∏Student(RegularClass) ∪ ∏Student(ExtraClass)
The above operation will send us the names of students who attend both normal and extra classes, reducing repetition.
5. Set difference
Set Difference in relational algebra is the same operation of set difference as in set theory, with the limitation that the same set of attributes can have both relationships.
Syntax: A - B
Where the A and B relationships.
For instance, if we want to find the names of students who attend the regular class, but not the extra class, then we can use the following procedure:
∏Student(RegularClass) - ∏Student(ExtraClass)
6. Intersection
The symbol ∩ is the definition of an intersection.
A ∩ B
Defines a relationship consisting of a set of all the tuples in both A and B. A and B must be union-compatible, however.
7. Cartesian product
This is used to merge information into one from two separate relationships(tables) and to fetch information from the merged relationship.
Syntax: A X B
For example, if we want to find the morning Regular Class and Extra Class data, then we can use the following operation:
σtime = 'morning' (RegularClass X ExtraClass)
Both RegularClass and ExtraClass should have the attribute time for the above query to operate.
8. Rename
Rename is a unified operation that is used to rename relationship attributes.
ρ (a/b)R renames the 'b' component of the partnership to 'a'.
Syntax: ρ(RelationNew, RelationOld)
Q8) Define SQL?
A8) SQL
● SQL stands for Structured Query Language. It is used for storing and managing data in relational database management system (RDMS).
● It is a standard language for Relational Database System. It enables a user to create, read, update and delete relational databases and tables.
● All the RDBMS like MySQL, Informix, Oracle, MS Access and SQL Server use SQL as their standard database language.
● SQL allows users to query the database in a number of ways, using English-like statements.
Rules:
SQL follows the following rules:
● Structure query language is not case sensitive. Generally, keywords of SQL are written in uppercase.
● Statements of SQL are dependent on text lines. We can use a single SQL statement on one or multiple text line.
● Using the SQL statements, you can perform most of the actions in a database.
● SQL depends on tuple relational calculus and relational algebra.
SQL process:
● When an SQL command is executing for any RDBMS, then the system figure out the best way to carry out the request and the SQL engine determines that how to interpret the task.
● In the process, various components are included. These components can be optimization Engine, Query engine, Query dispatcher, classic, etc.
● All the non-SQL queries are handled by the classic query engine, but SQL query engine won't handle logical files.
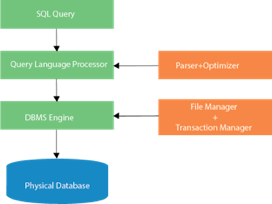
Fig - SQL process
Q9) Write the advantages of SQL?
A9) Advantages of SQL
There are the following advantages of SQL:
High speed
Using the SQL queries, the user can quickly and efficiently retrieve a large amount of records from a database.
No coding needed
In the standard SQL, it is very easy to manage the database system. It doesn't require a substantial amount of code to manage the database system.
Well defined standards
Long established are used by the SQL databases that are being used by ISO and ANSI.
Portability
SQL can be used in laptop, PCs, server and even some mobile phones.
Interactive language
SQL is a domain language used to communicate with the database. It is also used to receive answers to the complex questions in seconds.
Multiple data view
Using the SQL language, the users can make different views of the database structure.
Q10) Write the characteristics of SQL?
A10) Characteristics of SQL
● SQL is easy to learn.
● SQL is used to access data from relational database management systems.
● SQL can execute queries against the database.
● SQL is used to describe the data.
● SQL is used to define the data in the database and manipulate it when needed.
● SQL is used to create and drop the database and table.
● SQL is used to create a view, stored procedure, function in a database.
● SQL allows users to set permissions on tables, procedures, and views.
Q11) What is data definition in SQL?
A11) Data definition phrases, also known as data description phrases, are used in SQL statements to specify how to store data in a table's columns, how to present data in query results, and if column-level integrity constraints should be applied.
Data description phrases can also be used in expressions to convert data to a different type or to change data properties. 
Where,
Data_type_declaration: a column's data type, such as BYTE or FLOAT.
Data_type_attribute: characteristics for a column, such as a default value to insert when the value is omitted from an INSERT query.
Column_storage_attribute: for one or more columns of a table to compress particular values and nulls
Column_constraints_attribute: Integrity requirements at the column level, such as PRIMARY KEY.
The columns of the Employee table are defined using Teradata SQL data definition words in the following CREATE TABLE statement:
CREATE TABLE Employee
(EmpNo PRIMARY KEY SMALLINT FORMAT '9(5)'
CHECK(EmpNo BETWEEN 1000 AND 32001),
Name VARCHAR(12) CHARACTER SET LATIN NOT CASESPECIFIC NOT NULL,
DeptNo SMALLINT FORMAT '999'
CHECK (DeptNo BETWEEN 100 AND 900),
JobTitle VARCHAR(12) CHARACTER SET LATIN NOT CASESPECIFIC,
Salary DECIMAL(8,2) FORMAT 'ZZZ,ZZ9.99'
CHECK (Salary BETWEEN 1.00 AND 999000.00),
YrsExp BYTEINT FORMAT 'Z9'
CHECK (YrsExp BETWEEN -99 AND 99),
DOB DATE FORMAT ’MMMbDDbYYYY’ NOT NULL,
Sex CHAR CHARACTER SET LATIN UPPERCASE NOT NULL,
Race CHAR CHARACTER SET LATIN UPPERCASE,
MStat CHAR CHARACTER SET LATIN UPPERCASE,
EdLev BYTEINT FORMAT 'Z9'
CHECK (EdLev BETWEEN 0 AND 2) NOT NULL,
HCap BYTEINT FORMAT 'Z9'
CHECK (HCap BETWEEN -99 AND 99)
INDEX (Name);
The following SELECT statement modifies the title of the EmpNo column and the format of the Salary column results using Teradata SQL data definition phrases:
SELECT EmpNo (TITLE 'Employee Number'),
Salary (FORMAT 'GLLZ(I)D9(F)')
FROM Employee;
Q12) What is a table?
A12) A database is a collection of data that is linked together. Each of these data sets is divided into groups that are related to one another. Each of these groupings is stored as bits in physical memory, similar to disks. When a user wants to see specific data, however, he will not be able to interpret it if it is presented to him in the form of bits. Furthermore, records in the RAM are dispersed throughout many data blocks and will not be in any particular sequence. However, users prefer to see data that is both meaningful and well-formatted.
As a result, the user has a logical perspective of the data in the database. This is accomplished by presenting the records as a table with rows and columns. Each column in the table represents an object's linked set of data. Any living or non-living object in the actual world can be used as an object.
A SQL Table is a collection of data that has been grouped into rows and columns. The table is referred to as a relation, and the row is referred to as a tuple in relational databases.
A table is a simple data storage format. A table can also be thought of as a convenient way to display relationships.
Let's have a look at an EMPLOYEE table in action:
EMP_ID | EMP_NAME | CITY | PHONE_NO |
1 | Kristen | Washington | 7289201223 |
2 | Anna | Franklin | 9378282882 |
3 | Jackson | Bristol | 9264783838 |
4 | Kellan | California | 7254728346 |
5 | Ashley | Hawaii | 9638482678 |
The table name is "EMPLOYEE," and the column names are "EMP ID," "EMP NAME," "CITY," and "PHONE NO." A row is formed by the combination of data from many columns, such as 1, "Kristen," "Washington," and 7289201223.
Operation on Table
- Create Table
- Drop Table
- Delete Table
Create Table
To build a table in the database, use SQL create table. To define the table, you must first declare the table's name, as well as the table's columns and data types.
Syntax
Create table "table_name"
("column1" "data type",
"column2" "data type",
"column3" "data type",
...
"columnN" "data type");
Example
SQL> CREATE TABLE EMPLOYEE (
EMP_ID INT NOT NULL,
EMP_NAME VARCHAR (25) NOT NULL,
PHONE_NO INT NOT NULL,
ADDRESS CHAR (30),
PRIMARY KEY (ID)
);
Drop Table
A SQL drop table is used to remove a table's definition as well as all of its contents. While this command is used, all of the data in the database is permanently deleted, therefore be cautious when using it.
Syntax
DROP TABLE "table_name";
Delete Table
To delete rows from a table in SQL, use the DELETE statement. To delete a specific record from a table, we can utilize the WHERE condition. You don't need to use the WHERE clause if you wish to delete all the records from the table.
Syntax
DELETE FROM table_name WHERE condition;
Q13) Describe key and foriegn key?
A13) In a database management system, a key is an attribute or group of attributes that helps you identify a row (tuple) in a relation (table). They make it possible to discover the relationship between two tables. A combination of one or more columns in a table can be used as a key to uniquely identify a row in that table. The key can also be used to locate a specific record or row in a table. The database key can also be used to locate a specific record or row in a table.
Example
Employee ID | FirstName | LastName |
11 | Andrew | Johnson |
22 | Tom | Wood |
33 | Alex | Hale |
Employee ID is a primary key in the example above because it uniquely identifies an employee record. No other employee can have the same employee ID in this table.
Why do need keys?
Here are some of the benefits of using SQL keys in a database management system.
● Keys aid in the identification of any row of data in a table. A table in a real-world application could have thousands of records. Furthermore, the records may be duplicated. Despite these obstacles, RDBMS keys ensure that you can uniquely identify a table record.
● Allows you to construct a relationship between tables and determine their relationship.
● Assist you in enforcing the relationship's identification and integrity.
Types of Keys
There are mainly Eight different types of Keys in DBMS and each key has it’s different functionality:
- Super Key
- Primary Key
- Candidate Key
- Alternate Key
- Foreign Key
- Compound Key
- Composite Key
- Surrogate Key
Foreign key
A foreign key differs from a super key, candidate key, or primary key in that it is used to join two tables or link them together.
A foreign key is a secondary key that connects two tables via the primary key. It signifies that one table's columns point to the other table's primary key attribute. It also means that any attribute set as a primary key attribute will serve as a foreign key attribute in another table. A foreign key, on the other hand, has nothing to do with the primary key.
A Foreign Key column establishes a connection between two tables. Foreign keys are used to guarantee data integrity while also allowing navigation between two different instances of the same entity. It functions as a cross-reference between two tables since it refers to another table's main key.
Example
DeptCode | DeptName |
1 | Computer |
2 | Science |
3 | English |
TeacherID | Fname | Lname |
T007 | Sara | Choubey |
T019 | David | Chopda |
T004 | Raj | Sharma |
We have two tables in this key in dbms example, teach and department in a school. There is, however, no way to see which searches are used in which departments.
We may construct a relationship between the two tables in this table by adding the foreign key in DeptCode to the Teacher name.
TeacherID | DeptCode | Fname | Lname |
T007 | 1 | Sara | Choubey |
T019 | 2 | David | Chopda |
T004 | 3 | Raj | Sharma |
This concept is also known as Referential Integrity.
Q14) Define update statements?
A14) The SQL UPDATE statement is used to modify the data that is already in the database. The condition in the WHERE clause decides that which row is to be updated.
Syntax
- UPDATE table_name
- SET column1 = value1, column2 = value2, ...
- WHERE condition;
Sample Table
EMPLOYEE
EMP_ID | EMP_NAME | CITY | SALARY | AGE |
1 | Angelina | Chicago | 200000 | 30 |
2 | Robert | Austin | 300000 | 26 |
3 | Christian | Denver | 100000 | 42 |
4 | Kristen | Washington | 500000 | 29 |
5 | Russell | Los angels | 200000 | 36 |
6 | Marry | Canada | 600000 | 48 |
Updating single record
Update the column EMP_NAME and set the value to 'Emma' in the row where SALARY is 500000.
Syntax
- UPDATE table_name
- SET column_name = value
- WHERE condition;
Query
- UPDATE EMPLOYEE
- SET EMP_NAME = 'Emma'
- WHERE SALARY = 500000;
Output: After executing this query, the EMPLOYEE table will look like:
EMP_ID | EMP_NAME | CITY | SALARY | AGE |
1 | Angelina | Chicago | 200000 | 30 |
2 | Robert | Austin | 300000 | 26 |
3 | Christian | Denver | 100000 | 42 |
4 | Emma | Washington | 500000 | 29 |
5 | Russell | Los angels | 200000 | 36 |
6 | Marry | Canada | 600000 | 48 |
Updating multiple records
If you want to update multiple columns, you should separate each field assigned with a comma. In the EMPLOYEE table, update the column EMP_NAME to 'Kevin' and CITY to 'Boston' where EMP_ID is 5.
Syntax
- UPDATE table_name
- SET column_name = value1, column_name2 = value2
- WHERE condition;
Query
- UPDATE EMPLOYEE
- SET EMP_NAME = 'Kevin', City = 'Boston'
- WHERE EMP_ID = 5;
Output
EMP_ID | EMP_NAME | CITY | SALARY | AGE |
1 | Angelina | Chicago | 200000 | 30 |
2 | Robert | Austin | 300000 | 26 |
3 | Christian | Denver | 100000 | 42 |
4 | Kristen | Washington | 500000 | 29 |
5 | Kevin | Boston | 200000 | 36 |
6 | Marry | Canada | 600000 | 48 |
Without use of WHERE clause
If you want to update all row from a table, then you don't need to use the WHERE clause. In the EMPLOYEE table, update the column EMP_NAME as 'Harry'.
Syntax
- UPDATE table_name
- SET column_name = value1;
Query
- UPDATE EMPLOYEE
- SET EMP_NAME = 'Harry';
Output
EMP_ID | EMP_NAME | CITY | SALARY | AGE |
1 | Harry | Chicago | 200000 | 30 |
2 | Harry | Austin | 300000 | 26 |
3 | Harry | Denver | 100000 | 42 |
4 | Harry | Washington | 500000 | 29 |
5 | Harry | Los angels | 200000 | 36 |
6 | Harry | Canada | 600000 | 48 |
Q15) What do you mean by querying in SQL?
A15) SQL Sub Query
A Subquery is a query within another SQL query and embedded within the WHERE clause.
Important Rule:
● A subquery can be placed in a number of SQL clauses like WHERE clause, FROM clause, HAVING clause.
● You can use Subquery with SELECT, UPDATE, INSERT, DELETE statements along with the operators like =, <, >, >=, <=, IN, BETWEEN, etc.
● A subquery is a query within another query. The outer query is known as the main query, and the inner query is known as a subquery.
● Subqueries are on the right side of the comparison operator.
● A subquery is enclosed in parentheses.
● In the Subquery, ORDER BY command cannot be used. But GROUP BY command can be used to perform the same function as ORDER BY command.
1. Subqueries with the Select Statement
SQL subqueries are most frequently used with the Select statement.
Syntax
- SELECT column_name
- FROM table_name
- WHERE column_name expression operator
- (SELECT column_name from table_name WHERE ... );
Example
Consider the EMPLOYEE table have the following records:
ID | NAME | AGE | ADDRESS | SALARY |
1 | John | 20 | US | 2000.00 |
2 | Stephan | 26 | Dubai | 1500.00 |
3 | David | 27 | Bangkok | 2000.00 |
4 | Alina | 29 | UK | 6500.00 |
5 | Kathrin | 34 | Bangalore | 8500.00 |
6 | Harry | 42 | China | 4500.00 |
7 | Jackson | 25 | Mizoram | 10000.00 |
The subquery with a SELECT statement will be:
- SELECT *
- FROM EMPLOYEE
- WHERE ID IN (SELECT ID
- FROM EMPLOYEE
- WHERE SALARY > 4500);
This would produce the following result:
ID | NAME | AGE | ADDRESS | SALARY |
4 | Alina | 29 | UK | 6500.00 |
5 | Kathrin | 34 | Bangalore | 8500.00 |
7 | Jackson | 25 | Mizoram | 10000.00 |
2. Subqueries with the INSERT Statement
● SQL subquery can also be used with the Insert statement. In the insert statement, data returned from the subquery is used to insert into another table.
● In the subquery, the selected data can be modified with any of the character, date functions.
Syntax:
- INSERT INTO table_name (column1, column2, column3....)
- SELECT *
- FROM table_name
- WHERE VALUE OPERATOR
Example
Consider a table EMPLOYEE_BKP with similar as EMPLOYEE.
Now use the following syntax to copy the complete EMPLOYEE table into the EMPLOYEE_BKP table.
- INSERT INTO EMPLOYEE_BKP
- SELECT * FROM EMPLOYEE
- WHERE ID IN (SELECT ID
- FROM EMPLOYEE);
3. Subqueries with the UPDATE Statement
The subquery of SQL can be used in conjunction with the Update statement. When a subquery is used with the Update statement, then either single or multiple columns in a table can be updated.
Syntax
- UPDATE table
- SET column_name = new_value
- WHERE VALUE OPERATOR
- (SELECT COLUMN_NAME
- FROM TABLE_NAME
- WHERE condition);
Example
Let's assume we have an EMPLOYEE_BKP table available which is backup of EMPLOYEE table. The given example updates the SALARY by .25 times in the EMPLOYEE table for all employee whose AGE is greater than or equal to 29.
- UPDATE EMPLOYEE
- SET SALARY = SALARY * 0.25
- WHERE AGE IN (SELECT AGE FROM CUSTOMERS_BKP
- WHERE AGE >= 29);
This would impact three rows, and finally, the EMPLOYEE table would have the following records.
ID | NAME | AGE | ADDRESS | SALARY |
1 | John | 20 | US | 2000.00 |
2 | Stephan | 26 | Dubai | 1500.00 |
3 | David | 27 | Bangkok | 2000.00 |
4 | Alina | 29 | UK | 1625.00 |
5 | Kathrin | 34 | Bangalore | 2125.00 |
6 | Harry | 42 | China | 1125.00 |
7 | Jackson | 25 | Mizoram | 10000.00 |
4. Subqueries with the DELETE Statement
The subquery of SQL can be used in conjunction with the Delete statement just like any other statements mentioned above.
Syntax
- DELETE FROM TABLE_NAME
- WHERE VALUE OPERATOR
- (SELECT COLUMN_NAME
- FROM TABLE_NAME
- WHERE condition);
Example
Let's assume we have an EMPLOYEE_BKP table available which is backup of EMPLOYEE table. The given example deletes the records from the EMPLOYEE table for all EMPLOYEE whose AGE is greater than or equal to 29.
- DELETE FROM EMPLOYEE
- WHERE AGE IN (SELECT AGE FROM EMPLOYEE_BKP
- WHERE AGE >= 29 );
This would impact three rows, and finally, the EMPLOYEE table would have the following records.
ID | NAME | AGE | ADDRESS | SALARY |
1 | John | 20 | US | 2000.00 |
2 | Stephan | 26 | Dubai | 1500.00 |
3 | David | 27 | Bangkok | 2000.00 |
7 | Jackson | 25 | Mizoram | 10000.00 |
Q16) Define notation of aggregation?
A16) The relationship between two entities is treated as a single unit in aggregate. Aggregation is the process of combining relationships with their related entities into a higher level object.
In a database management system (DBMS), aggregation is the process of joining two or more entities to create a more meaningful new entity. When the entities on their own don't make sense, the aggregation method is used. A relationship is built and the final product is created into a new entity in order to generate aggregation between two entities that cannot be utilised for their own features. Any form of relationship can be used, such as SUM, AVG, AND, OR, and so on. Aggregation on tables can be done with a variety of solutions on the market.
For example, the Center entity provides the Course entity with the ability to behave as a single entity in a relationship with another entity visitor. When a visitor enters a coaching center in the real world, he will never inquire about the Course or the Center alone; instead, he will inquire about both.
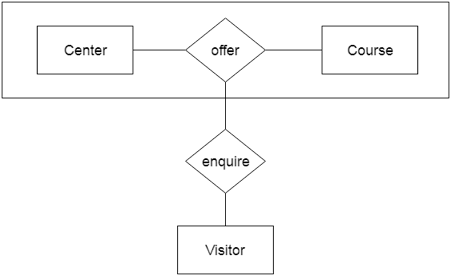
Fig: Aggregation
Reason for using Aggregation
When the DBMS meets the following criteria, the Aggregation technique is used.
● When a database management system only has trivial entities and no complicated entities, it is impossible to modify or expand it in the future. In this case, two or more trivial entities can be combined to construct a new complex entity by forming a new relationship between them.
● When a DBMS contains a single trivial entity that needs to be utilized for several operations, that object is used to form relationships with multiple additional entities. Depending on the procedures applied between the entities, this can result in several aggregation processes and multiple new entities.
● When the Entity-Relationship model is unable to describe the relationship between any of the entities in the system, that entity can be utilized to construct a new relationship with any other entity in the system. In the Entity-Relationship model, the resulting entity can be utilized to establish relationships. Aggregation allows all of the entities in the system to be used rather than having any of them be inactive.
Q17) Explain Aggregate functions group by and having clauses?
A17)
The GROUP BY clause is a SQL command that is used to group rows that have the same values. The GROUP BY clause is used in the SELECT statement. Optionally it is used in conjunction with aggregate functions to produce summary reports from the database.
That's what it does, summarizing data from the database.
The queries that contain the GROUP BY clause are called grouped queries and only return a single row for every grouped item.
SQL GROUP BY Syntax
Now that we know what the SQL GROUP BY clause is, let's look at the syntax for a basic group by query.
SELECT statements... GROUP BY column_name1[,column_name2,...] [HAVING condition];
HERE
● "SELECT statements..." is the standard SQL SELECT command query.
● "GROUP BYcolumn_name1" is the clause that performs the grouping based on column_name1.
● "[,column_name2,...]" is optional; represents other column names when the grouping is done on more than one column.
● "[HAVING condition]" is optional; it is used to restrict the rows affected by the GROUP BY clause. It is similar to the WHERE clause.
Grouping using a Single Column
In order to help understand the effect of SQL Group By clause, let's execute a simple query that returns all the gender entries from the members table.
SELECT gender FROM members;
Gender |
Female |
Female |
Male |
Female |
Male |
Male |
Male |
Male |
Male |
Suppose we want to get the unique values for genders. We can use a following query -
SELECT gender FROM members GROUP BY gender;
Executing the above script in MYSQL workbench against the Myflixdb gives us the following results.
Gender |
Female |
Male |
Note only two results have been returned. This is because we only have two gender types Male and Female. The GROUP BY clause in SQL grouped all the "Male" members together and returned only a single row for it. It did the same with the "Female" members.
Grouping using multiple columns
Suppose that we want to get a list of movie category_id and corresponding years in which they were released.
Let's observe the output of this simple query
SELECT category_id,year_released FROM movies ;
Category_id | Year_released |
1 | 2011 |
2 | 2008 |
NULL | 2008 |
NULL | 2010 |
8 | 2007 |
6 | 2007 |
6 | 2007 |
8 | 2005 |
NULL | 2012 |
7 | 1920 |
8 | NULL |
8 | 1920 |
The above result has many duplicates.
Let's execute the same query using group by in SQL -
SELECT category_id,year_released FROM movies GROUP BY category_id,year_released;
Executing the above script in MySQL workbench against the myflixdb gives us the following results shown below.
Category_id | Year_released |
NULL | 2008 |
NULL | 2010 |
NULL | 2012 |
1 | 2011 |
2 | 2008 |
6 | 2007 |
7 | 1920 |
8 | 1920 |
8 | 2005 |
8 | 2007 |
The GROUP BY clause operates on both the category id and year released to identify unique rows in our above example.
If the category id is the same but the year released is different, then a row is treated as a unique one .If the category id and the year released is the same for more than one row, then it's considered a duplicate and only one row is shown.
Grouping and aggregate functions
Suppose we want total number of males and females in our database. We can use the following script shown below to do that.
SELECT gender,COUNT(membership_number) FROM members GROUP BY gender;
Executing the above script in MySQL workbench against the myflixdb gives us the following results.
Gender | COUNT('membership_number') |
Female | 3 |
Male | 5 |
The results shown below are grouped by every unique gender value posted and the number of grouped rows is counted using the COUNT aggregate function.
Restricting query results using the HAVING clause
It's not always that we will want to perform groupings on all the data in a given table. There will be times when we will want to restrict our results to a certain given criteria. In such cases, we can use the HAVING clause
Suppose we want to know all the release years for movie category id 8. We would use the following script to achieve our results.
SELECT * FROM movies GROUP BY category_id,year_released HAVING category_id = 8;
Executing the above script in MySQL workbench against the Myflixdb gives us the following results shown below.
Movie_id | Title | Director | Year_released | Category_id |
9 | Honey mooners | John Schultz | 2005 | 8 |
5 | Daddy's Little Girls | NULL | 2007 | 8 |
Note only movies with category id 8 have been affected by our GROUP BY clause.
Summary
● The GROUP BY Clause SQL is used to group rows with same values.
● The GROUP BY Clause is used together with the SQL SELECT statement.
● The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions.
● SQL Having Clause is used to restrict the results returned by the GROUP BY clause.
● MYSQL GROUP BY Clause is used to collect data from multiple records and returned record set by one or more columns.
Q18) Describe embedded SQL?
A18) Embedded SQL is used to discuss with SQL statements that are contained within an application programing language like Visual Basic .NET, C#, COBOL, or Java. The program being developed could be a typical binary executable in Windows or Linux.
Embedded SQL is used to maintaining procedural capabilities in DBMS-based applications. Therefore, mixing SQL with procedural languages needs that you simply understand some key differences between SQL and procedural languages.
Run-time mismatch: SQL is a nonprocedural, interpreted language in that every instruction is parsed after that syntax is checked, and execute one instruction at a time. All of the processing takes place at the server side. The host language is a binary-executable program. The host program is runs at the client side in its own memory space.
Processing mismatch: Conventional programming languages like COBOL, ADA, FORTRAN, PASCAL, C++, and PL/I process one data element at a time. Also you can use arrays to hold data and process the array elements one row at a time. This is true for file manipulation, where the host language manipulates data one record at a time. However latest programming environments used multiple object-oriented extensions which help the programmer to manipulate data sets in a cohesive form.
Data type mismatch: SQL provides multiple data types. To understand the differences, the Embedded SQL standard2 defines a framework to integrate SQL within many programming languages. The Embedded SQL framework defines the following:
A standard syntax verifies embedded SQL coding within the host language. Host variables are variables which are present in the host language that receive data from the database and process the data within the host language. All host variables are preceded by a colon (“:”). A communication area is used to exchange status and error information between SQL and host language.
This communications area consists of two variables SQLCODE and SQLSTATE. Also interface host languages and SQL via the use of a call level interface (CLI) during which the programmer writes to an application programming interface (API). A common CLI in Windows is supported by the Open Database Connectivity (ODBC) interface.
The process needs to create and run executable program with embedded SQL statements. If you've programmed in COBOL or C++, you need the multiple steps required to get the ultimate executable program. Although the precise details vary among language and DBMS vendors, the subsequent general steps are standard:
1. The programmer writes embedded SQL code within the host language instructions. The code follows the standard syntax need for the host language and embedded SQL.
2. A preprocessor is used to transform the embedded SQL into specialized procedure calls like DBMS and language-specific. The preprocessor is provided by the DBMS vendor and is particular to the host language.
3. The program is compiled using the host language compiler. The compiler creates an object code module for the program consist of DBMS procedure calls.
4. The object code is linked to the appropriate library modules and generates the executable program. This process binds the DBMS procedure calls to the DBMS run-time libraries. The binding process creates an “access plan” module that contains instructions to run the embedded code at run time.
5. The executable is run, and then the embedded SQL statement retrieves data from the database.
You can also embed individual SQL statements or a whole PL/SQL block. Programmers embed SQL statements within a host language that it's compiled once and executed as when required. To embed SQL into a host language, follow the following syntax:
EXEC SQL
SQL statement;
END-EXEC.
This syntax will work for SELECT, INSERT, UPDATE, and DELETE statements. For example following embedded SQL code will delete employee 109, George Smith, from the employee table:
EXEC SQL
DELETE FROM EMPLOYEE WHERE EMP_NUM = 109;
END-EXEC.
Remember that the above embedded SQL statement is compiled to get an executable statement. Therefore, the statement is fixed and can't change. Whenever the program runs, it deletes an equivalent row. In short above code is good just for the first run; all subsequent runs will likely generate an error.
In embedded SQL, all host variables are preceded by a colon (“:”). The host variables want to send data from the host language to the embedded SQL, or they'll be used to receive the data from the embedded SQL. To use a host variable, you need to first declare it within the host language.
For example, if you're using COBOL, you'd define the host variables within the Working Storage section. Then you'd ask them within the embedded SQL section by preceding them with a colon (“:”). For instance, to delete an employee having employee number is represented by the host variable W_EMP_NUM, consider the following code:
EXEC SQL
DELETE FROM EMPLOYEE WHERE EMP_NUM =:W_EMP_NUM;
END-EXEC.
At run time, the host variable value will be used to execute the embedded SQL statement. In COBOL area is known as the SQLCA area and is defined in the Data Division as follows:
EXEC SQL
INCLUDE SQLCA
END-EXEC.
The SQLCA area consist of two variables for status and error reporting. Following Table shows some of the main values returned by the variables.
Variable name | Value | Explanation |
SQLCODE |
| Old-style error reporting supported for backward compatibility only. It returns an integer value it may be positive or negative. |
| 0 | Successful completion of command |
| 100 | No data; the SQL statement did not return any rows or not select, update, or delete any rows. |
| -999 | Any negative value indicates that an error occurred. |
SQLSTATE |
| Added by SQL-92 standard to provide predefined error codes which is defined as a character string up to 5 characters. |
| 00000 | Successful completion of command. |
|
| Multiple values in the format XXYYY where: XX-> defines the class code. YYY-> defines the subclass code. |




