Unit - 4
Transactions
Q1) What do you mean by transaction processing?
A1) A transaction can be defined as a group of tasks. A single task is the minimum processing unit which cannot be divided further.
Let’s take an example of a simple transaction. Suppose a bank employee transfers Rs 500 from A's account to B's account. This very simple and small transaction involves several low-level tasks.
A’s Account
Open_Account(A)
Old_Balance = A.balance
New_Balance = Old_Balance - 500
A.balance = New_Balance
Close_Account(A)
B’s Account
Open_Account(B)
Old_Balance = B.balance
New_Balance = Old_Balance + 500
B.balance = New_Balance
Close_Account(B)
ACID Properties
A transaction is a very small unit of a program and it may contain several lowlevel tasks. A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity.
● Atomicity−This property states that a transaction must be treated as an atomic unit, that is, either all of its operations are executed or none. There must be no state in a database where a transaction is left partially completed. States should be defined either before the execution of the transaction or after the execution/abortion/failure of the transaction.
● Consistency−The database must remain in a consistent state after any transaction. No transaction should have any adverse effect on the data residing in the database. If the database was in a consistent state before the execution of a transaction, it must remain consistent after the execution of the transaction as well.
● Durability−The database should be durable enough to hold all its latest updates even if the system fails or restarts. If a transaction updates a chunk of data in a database and commits, then the database will hold the modified data. If a transaction commits but the system fails before the data could be written on to the disk, then that data will be updated once the system springs back into action.
● Isolation− In a database system where more than one transaction are being executed simultaneously and in parallel, the property of isolation states that all the transactions will be carried out and executed as if it is the only transaction in the system. No transaction will affect the existence of any other transaction.
Q2) What is serializability?
A2) Serializability
When multiple transactions are being executed by the operating system in a multiprogramming environment, there are possibilities that instructions of one transaction are interleaved with some other transaction.
● Schedule− A chronological execution sequence of a transaction is called a schedule. A schedule can have many transactions in it, each comprising of a number of instructions/tasks.
● Serial Schedule− It is a schedule in which transactions are aligned in such a way that one transaction is executed first. When the first transaction completes its cycle, then the next transaction is executed. Transactions are ordered one after the other. This type of schedule is called a serial schedule, as transactions are executed in a serial manner.
In a multi-transaction environment, serial schedules are considered as a benchmark. The execution sequence of an instruction in a transaction cannot be changed, but two transactions can have their instructions executed in a random fashion. This execution does no harm if two transactions are mutually independent and working on different segments of data; but in case these two transactions are working on the same data, then the results may vary. This ever-varying result may bring the database to an inconsistent state.
To resolve this problem, we allow parallel execution of a transaction schedule, if its transactions are either serializable or have some equivalence relation among them.
Equivalence Schedules
An equivalence schedule can be of the following types −
Result Equivalence
If two schedules produce the same result after execution, they are said to be result equivalent. They may yield the same result for some value and different results for another set of values. That's why this equivalence is not generally considered significant.
View Equivalence
Two schedules would be view equivalence if the transactions in both the schedules perform similar actions in a similar manner.
For example −
● If T reads the initial data in S1, then it also reads the initial data in S2.
● If T reads the value written by J in S1, then it also reads the value written by J in S2.
● If T performs the final write on the data value in S1, then it also performs the final write on the data value in S2.
Conflict Equivalence
Two schedules would be conflicting if they have the following properties −
● Both belong to separate transactions.
● Both accesses the same data item.
● At least one of them is "write" operation.
Two schedules having multiple transactions with conflicting operations are said to be conflict equivalent if and only if −
● Both the schedules contain the same set of Transactions.
● The order of conflicting pairs of operation is maintained in both the schedules.
Note− View equivalent schedules are view serializable and conflict equivalent schedules are conflict serializable. All conflict serializable schedules are view serializable too.
Q3) What is the state of the transaction?
A3) States of Transactions
A transaction in a database can be in one of the following states −
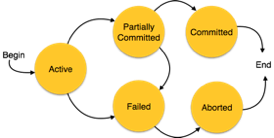
Fig - States of Transactions
● Active−In this state, the transaction is being executed. This is the initial state of every transaction.
● Partially Committed− When a transaction executes its final operation, it is said to be in a partially committed state.
● Failed− A transaction is said to be in a failed state if any of the checks made by the database recovery system fails. A failed transaction can no longer proceed further.
● Aborted− If any of the checks fails and the transaction has reached a failed state, then the recovery manager rolls back all its write operations on the database to bring the database back to its original state where it was prior to the execution of the transaction. Transactions in this state are called aborted. The database recovery module can select one of the two operations after a transaction aborts −
● Re-start the transaction
● Kill the transaction
● Committed− If a transaction executes all its operations successfully, it is said to be committed. All its effects are now permanently established on the database system.
Q4) Explain ACID property?
A4) DBMS is the management of data that should remain integrated when any changes are done in it. It is because if the integrity of the data is affected, whole data will get disturbed and corrupted. Therefore, to maintain the integrity of the data, there are four properties described in the database management system, which are known as the ACID properties. The ACID properties are meant for the transaction that goes through a different group of tasks, and there we come to see the role of the ACID properties.
In this section, we will learn and understand about the ACID properties. We will learn what these properties stand for and what does each property is used for. We will also understand the ACID properties with the help of some examples.
ACID Properties
The expansion of the term ACID defines for:
Fig - ACID Properties
1) Atomicity: The term atomicity defines that the data remains atomic. It means if any operation is performed on the data, either it should be performed or executed completely or should not be executed at all. It further means that the operation should not break in between or execute partially. In the case of executing operations on the transaction, the operation should be completely executed and not partially.
Example: If Remo has account A having $30 in his account from which he wishes to send $10 to Sheero's account, which is B. In account B, a sum of $ 100 is already present. When $10 will be transferred to account B, the sum will become $110. Now, there will be two operations that will take place. One is the amount of $10 that Remo wants to transfer will be debited from his account A, and the same amount will get credited to account B, i.e., into Sheero's account. Now, what happens - the first operation of debit executes successfully, but the credit operation, however, fails. Thus, in Remo's account A, the value becomes $20, and to that of Sheero's account, it remains $100 as it was previously present.
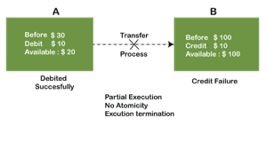
In the above diagram, it can be seen that after crediting $10, the amount is still $100 in account B. So, it is not an atomic transaction.
The below image shows that both debit and credit operations are done successfully. Thus the transaction is atomic.

Thus, when the amount loses atomicity, then in the bank systems, this becomes a huge issue, and so the atomicity is the main focus in the bank systems.
2) Consistency: The word consistency means that the value should remain preserved always. In DBMS, the integrity of the data should be maintained, which means if a change in the database is made, it should remain preserved always. In the case of transactions, the integrity of the data is very essential so that the database remains consistent before and after the transaction. The data should always be correct.
Example:
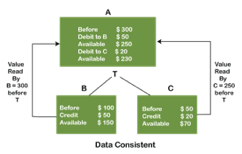
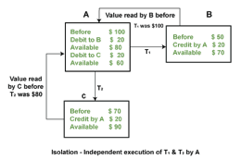
In the above figure, there are three accounts, A, B, and C, where A is making a transaction T one by one to both B & C. There are two operations that take place, i.e., Debit and Credit. Account A firstly debits $50 to account B, and the amount in account A is read $300 by B before the transaction. After the successful transaction T, the available amount in B becomes $150. Now, A debits $20 to account C, and that time, the value read by C is $250 (that is correct as a debit of $50 has been successfully done to B). The debit and credit operation from account A to C has been done successfully. We can see that the transaction is done successfully, and the value is also read correctly. Thus, the data is consistent. In case the value read by B and C is $300, which means that data is inconsistent because when the debit operation executes, it will not be consistent.
3) Isolation: The term 'isolation' means separation. In DBMS, Isolation is the property of a database where no data should affect the other one and may occur concurrently. In short, the operation on one database should begin when the operation on the first database gets complete. It means if two operations are being performed on two different databases, they may not affect the value of one another. In the case of transactions, when two or more transactions occur simultaneously, the consistency should remain maintained. Any changes that occur in any particular transaction will not be seen by other transactions until the change is not committed in the memory.
Example: If two operations are concurrently running on two different accounts, then the value of both accounts should not get affected. The value should remain persistent. As you can see in the below diagram, account A is making T1 and T2 transactions to account B and C, but both are executing independently without affecting each other. It is known as Isolation.
4) Durability: Durability ensures the permanency of something. In DBMS, the term durability ensures that the data after the successful execution of the operation becomes permanent in the database. The durability of the data should be so perfect that even if the system fails or leads to a crash, the database still survives. However, if gets lost, it becomes the responsibility of the recovery manager for ensuring the durability of the database. For committing the values, the COMMIT command must be used every time we make changes.
Therefore, the ACID property of DBMS plays a vital role in maintaining the consistency and availability of data in the database.
Q5) Describe concurrency control?
A5) Concurrency Control is the management procedure that is required for controlling concurrent execution of the operations that take place on a database.
Concurrent Execution in DBMS
● In a multi-user system, multiple users can access and use the same database at one time, which is known as the concurrent execution of the database. It means that the same database is executed simultaneously on a multi-user system by different users.
● While working on the database transactions, there occurs the requirement of using the database by multiple users for performing different operations, and in that case, concurrent execution of the database is performed.
● The thing is that the simultaneous execution that is performed should be done in an interleaved manner, and no operation should affect the other executing operations, thus maintaining the consistency of the database. Thus, on making the concurrent execution of the transaction operations, there occur several challenging problems that need to be solved.
Problems with Concurrent Execution
In a database transaction, the two main operations are READ and WRITE operations. So, there is a need to manage these two operations in the concurrent execution of the transactions as if these operations are not performed in an interleaved manner, and the data may become inconsistent. So, the following problems occur with the Concurrent Execution of the operations:
Problem 1: Lost Update Problems (W - W Conflict)
The problem occurs when two different database transactions perform the read/write operations on the same database items in an interleaved manner (i.e., concurrent execution) that makes the values of the items incorrect hence making the database inconsistent.
For example:
Consider the below diagram where two transactions TX and TY, are performed on the same account A where the balance of account A is $300.
● At time t1, transaction TX reads the value of account A, i.e., $300 (only read).
● At time t2, transaction TX deducts $50 from account A that becomes $250 (only deducted and not updated/write).
● Alternately, at time t3, transaction TY reads the value of account A that will be $300 only because TX didn't update the value yet.
● At time t4, transaction TY adds $100 to account A that becomes $400 (only added but not updated/write).
● At time t6, transaction TX writes the value of account A that will be updated as $250 only, as TY didn't update the value yet.
● Similarly, at time t7, transaction TY writes the values of account A, so it will write as done at time t4 that will be $400. It means the value written by TX is lost, i.e., $250 is lost.
Hence data becomes incorrect, and database sets to inconsistent.
Dirty Read Problems (W-R Conflict)
The dirty read problem occurs when one transaction updates an item of the database, and somehow the transaction fails, and before the data gets rollback, the updated database item is accessed by another transaction. There comes the
Read-Write Conflict between both transactions.
For example:
Consider two transactions TX and TY in the below diagram performing read/write operations on account A where the available balance in account A is $300:
● At time t1, transaction TX reads the value of account A, i.e., $300.
● At time t2, transaction TX adds $50 to account A that becomes $350.
● At time t3, transaction TX writes the updated value in account A, i.e., $350.
● Then at time t4, transaction TY reads account A that will be read as $350.
● Then at time t5, transaction TX rollbacks due to server problem, and the value changes back to $300 (as initially).
● But the value for account A remains $350 for transaction TY as committed, which is the dirty read and therefore known as the Dirty Read Problem.
Unrepeatable Read Problem (W-R Conflict)
Also known as Inconsistent Retrievals Problem that occurs when in a transaction, two different values are read for the same database item.
For example:
Consider two transactions, TX and TY, performing the read/write operations on account A, having an available balance = $300. The diagram is shown below:
● At time t1, transaction TX reads the value from account A, i.e., $300.
● At time t2, transaction TY reads the value from account A, i.e., $300.
● At time t3, transaction TY updates the value of account A by adding $100 to the available balance, and then it becomes $400.
● At time t4, transaction TY writes the updated value, i.e., $400.
● After that, at time t5, transaction TX reads the available value of account A, and that will be read as $400.
● It means that within the same transaction TX, it reads two different values of account A, i.e., $ 300 initially, and after updation made by transaction TY, it reads $400. It is an unrepeatable read and is therefore known as the Unrepeatable read problem.
Thus, in order to maintain consistency in the database and avoid such problems that take place in concurrent execution, management is needed, and that is where the concept of Concurrency Control comes into role.
Q6) Define concurrency protocol?
A6) Concurrency Control Protocols
The concurrency control protocols ensure the atomicity, consistency, isolation, durability and serializability of the concurrent execution of the database transactions. Therefore, these protocols are categorized as:
● Lock Based Concurrency Control Protocol
● Time Stamp Concurrency Control Protocol
● Validation Based Concurrency Control Protocol
Lock-Based Protocol
In this type of protocol, any transaction cannot read or write data until it acquires an appropriate lock on it. There are two types of lock:
1. Shared lock:
● It is also known as a Read-only lock. In a shared lock, the data item can only read by the transaction.
● It can be shared between the transactions because when the transaction holds a lock, then it can't update the data on the data item.
2. Exclusive lock:
● In the exclusive lock, the data item can be both reads as well as written by the transaction.
● This lock is exclusive, and in this lock, multiple transactions do not modify the same data simultaneously.
There are four types of lock protocols available:
1. Simplistic lock protocol
It is the simplest way of locking the data while transaction. Simplistic lock-based protocols allow all the transactions to get the lock on the data before insert or delete or update on it. It will unlock the data item after completing the transaction.
2. Pre-claiming Lock Protocol
● Pre-claiming Lock Protocols evaluate the transaction to list all the data items on which they need locks.
● Before initiating an execution of the transaction, it requests DBMS for all the lock on all those data items.
● If all the locks are granted then this protocol allows the transaction to begin. When the transaction is completed then it releases all the lock.
● If all the locks are not granted then this protocol allows the transaction to rolls back and waits until all the locks are granted.

Fig – Pre-claiming lock protocol
3. Two-phase locking (2PL)
● The two-phase locking protocol divides the execution phase of the transaction into three parts.
● In the first part, when the execution of the transaction starts, it seeks permission for the lock it requires.
● In the second part, the transaction acquires all the locks. The third phase is started as soon as the transaction releases its first lock.
● In the third phase, the transaction cannot demand any new locks. It only releases the acquired locks.

Fig - Two-phase locking protocol
There are two phases of 2PL:
Growing phase: In the growing phase, a new lock on the data item may be acquired by the transaction, but none can be released.
Shrinking phase: In the shrinking phase, existing lock held by the transaction may be released, but no new locks can be acquired.
In the below example, if lock conversion is allowed then the following phase can happen:
- Upgrading of lock (from S(a) to X (a)) is allowed in growing phase.
- Downgrading of lock (from X(a) to S(a)) must be done in shrinking phase.
Example:

The following way shows how unlocking and locking work with 2-PL.
Transaction T1:
● Growing phase: from step 1-3
● Shrinking phase: from step 5-7
● Lock point: at 3
Transaction T2:
● Growing phase: from step 2-6
● Shrinking phase: from step 8-9
● Lock point: at 6
4. Strict Two-phase locking (Strict-2PL)
● The first phase of Strict-2PL is similar to 2PL. In the first phase, after acquiring all the locks, the transaction continues to execute normally.
● The only difference between 2PL and strict 2PL is that Strict-2PL does not release a lock after using it.
● Strict-2PL waits until the whole transaction to commit, and then it releases all the locks at a time.
● Strict-2PL protocol does not have shrinking phase of lock release.
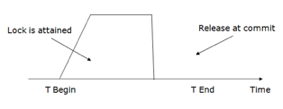
Fig - Strict-2PL
It does not have cascading abort as 2PL does.
Q7) What do you mean by error recovery and logging?
A7) In the event of a failure at the time of the transaction or after the completion of a procedure, this is the method of restoring the database to its correct state. The idea of database recovery was previously given to you as a service that should be offered by all the DBMS to ensure that the database is stable and stays in a consistent state in the presence of failures. Reliability in this sense refers to both the DBMS's flexibility for different forms of failure and its ability to recover from those failures.
You will first learn about the need for recovery and its types of failure, which usually happens in a database environment, to gain a better understanding of the possible problems you may encounter in providing a consistent system.
The recovery of databases can be divided into two parts:
- In the corresponding data blocks, Rolling Forward applies redo records.
- Rolling Back adds segments of rollback to the data files. It is stored in tables for transactions.
Using Log–Based Recovery, we can restore the database.
Log based recovery
● Logs are a series of documents that hold records of a transaction's actions.
● In Log-Based Recovery, in some secure storage, the log of each transaction is stored. It can be retrieved from there to restore the database if any malfunction happens.
● The log includes information about the transaction being executed, changed values, and the status of the transaction.
● All this data will be processed in the execution order.
Example
Assume that a transaction modifies an employee's address. For this transaction, the logs below are written,
Log 1: It begins the transaction, writes 'START' log.
Log: <Tn START>
Log 2: The transaction modifies the address to 'Raipur' from 'Mumbai'.
Log: <Tn Address, 'Mumbai', 'Raipur'>
Log 3: The transaction is finished. The log shows the transaction's end.
Log: <Tn COMMIT>
There are two ways to build the log files and to update the database:
1. Deferred Database Modification
Both logs are created for the transaction and stored in a secure storage system. In the example above, three log records are generated and stored in a storage system, and these steps will update the database.
2. Immediate Database Modification
After each log record has been generated, the database is automatically updated for each log entry stage. In the above example, at each step of the log entry, the database is updated, which means that after the first log entry, the transaction hits the database to fetch the record, then the second log is entered, followed by updating the address of the employee, then the third log, followed by committing changes to the database.
Recovery with Concurrent Transaction
● If two transactions are executed in parallel, the logs are split. The recovery system will find it difficult to restore all logs to an earlier point and then start recovering.
● 'Checkpoint' is used to fix this example.
Q8) Write short notes on undo?
A8) The DBMS Server handles undo or transaction backout recovery. When a transaction is canceled, for example, the information in the transaction log file is used to roll back all relevant updates. The Compensation Log Records (CLRs) are written by the DBMS Server to keep track of the activities taken during undo operations.
Make database repairs by undoing the effects of unfinished transactions, such as uncommitted transactions prior to a crash or aborted transactions.
Types of Undo log records
<START T> - transaction T has begun.
<COMMIT T> - T has been successfully completed; no further changes will be made.
– Note that seeing <COMMIT T> does not guarantee that modifications have been put to disk; the log manager must enforce this.
<ABORT T> - transaction T was unable to complete the task.
– The transaction manager's role is to ensure that T's changes are never written to disk or canceled.
<T,X,v> - Update the UNDO log's record.
– T has modified the value of object X, which was previously v. (to Undo write if needed).
Q9) Write short notes on redo?
A9) We can't commit a transaction without first writing all of its altered data to disk, which is a problem with undo logging. We may lose I/Os as a result of this.
● Redo logging can be used to get around this restriction.
● The following are the main distinctions between undo and redo logging:
1. Undo logging ignores committed transactions and eliminates the consequences of unfinished transactions; redo logging ignores committed transactions and redoes them as needed.
2. Undo logging necessitates the writing of altered DB components to disk before the commit log record is written to disk; redo logging necessitates the writing of the COMMIT before any changed values are written to disk.
3. We had undo logging rules U1 and U2 to ensure that undo logging worked. These two rules will be replaced with R1, a redo log rule.
The Redo Logging Rule
(R1) [Also known as the WAL (write-ahead logging) rule] All log records relevant to this modification of X (that is, both the update record and the record) must appear on disk before altering X on disk.
● Instead of the old value as in undo logging, v is now the new value.
Recovery with Redo Logging
When using redo logging to recover, we must:
1. Determine which transactions have been committed.
2. Start scanning the log from the beginning and work your way forward. For each log record you come across, make the following notes:
a) Do nothing if T is not a committed transaction.
b) Write the value for database element X if T committed.
3. Write an <ABORT T> entry to the log for each incomplete transaction T and flush the log.
Q10) What is undo - redo logging?
A10) There are drawbacks to both undo and redo logging.
• One drawback of redo logging is that all updated blocks must be buffered until the transaction commits and the log records are flushed.
• If one has a block in memory that has been updated by both an ongoing transaction and a transaction that has committed, both present difficulties.
• We can use undo/redo logging to try to mix the best of both worlds.
• The following are the new rules in this setup:
(UR1) The update record must be present on disk before altering X on disk as a result of T. (The old value is v, and the new value is w.)
(UR2) As soon as A arrives in the log, it must be flushed to disk.
When using undo/redo logging, we must:
1. Undo all committed transactions in the order they were committed, and
2. Redo all incomplete transactions in the order they were committed.
Recovery with Redo Logging
When using redo logging to recover, we must:
1. Determine which transactions have been committed.
2. Start scanning the log from the beginning and work your way forward. For each log record you come across, make the following notes:
a) Do nothing if T is not a committed transaction.
b) Write the value for database element X if T committed.
3. Write an <ABORT T> entry to the log for each incomplete transaction T and flush the log.
Checkpointing on Undo/Redo Log
This time, the steps are as follows:
1. Enter a <START CKPT(T1,...Tk)> command in the log.
2. Delete all dirty buffers from the system.
3. Finish with an <END CKPT> and flush the log.
• We require that a transaction not write any values to memory buffers until it is certain that it will terminate.
Q11) How to recover from transaction failure?
A11) When a transaction fails to execute or reaches a point where it can't go any further, it is called a transaction failure. Transaction failure occurs when a number of transactions or processes are harmed.
Logical errors: When a transaction cannot complete owing to a coding error or an internal error situation, a logical error occurs.
Syntax error: When a database management system (DBMS) stops an active transaction because the database system is unable to perform it, this is known as a syntax error. For example, in the event of a deadlock or resource unavailability, the system aborts an active transaction.
When a system crashes, numerous transactions may be running and various files may be open, allowing them to modify data items. Transactions are made up of a variety of operations that are all atomic. However, atomicity of transactions as a whole must be preserved, which means that either all or none of the operations must be done, depending on the ACID features of DBMS.
When a database management system (DBMS) recovers after a crash -
● It should check the statuses of all the transactions that were in progress.
● A transaction may be in the middle of an operation; in this situation, the DBMS must ensure the transaction's atomicity.
● It should determine if the transaction can be completed at this time or whether it has to be turned back.
● There would be no transactions that would leave the DBMS in an inconsistent state.
Maintaining the logs of each transaction and writing them onto some stable storage before actually altering the database are two strategies that can assist a DBMS in recovering and maintaining the atomicity of a transaction.
There are two sorts of approaches that can assist a DBMS in recovering and sustaining transaction atomicity.
● Maintaining shadow paging, in which updates are made in volatile memory and the actual database is updated afterwards.
● Before actually altering the database, keep track of each transaction's logs and save them somewhere safe.
Q12) Define View Serializability?
A12) If a schedule is viewed as equivalent to a serial schedule, it will be serializable.
If a schedule is view serializable, it is also conflict serializable.
Blind writes are contained in the view serializable, which does not conflict with serializable.
View Equivalent
If two schedules S1 and S2 meet the following criteria, they are said to be view equivalent:
1. Initial Read
Both schedules must be read at the same time. Assume there are two schedules, S1 and S2. If a transaction T1 in schedule S1 reads data item A, then transaction T1 in schedule S2 should likewise read A.
Because T1 performs the initial read operation in S1 and S2, the two schedules are considered comparable.
2. Updated Read
If Ti is reading A, which is updated by Tj in schedule S1, Ti should also read A, which is updated by Tj in schedule S2.

Because T3 in S1 is reading A updated by T2 and T3 in S2 is reading A updated by T1, the two schedules are not equivalent.
3. Final Write
The final writing for both schedules must be the same. If a transaction T1 updates A last in schedule S1, T1 should also perform final writes operations in schedule S2.
Because T3 performs the final write operation in S1 and T3 performs the final write operation in S2, the two schedules are considered equivalent.
Example

Schedule S
The total number of possible schedules grows to three with three transactions.
= 3! = 6
S1 = <T1 T2 T3>
S2 = <T1 T3 T2>
S3 = <T2 T3 T1>
S4 = <T2 T1 T3>
S5 = <T3 T1 T2>
S6 = <T3 T2 T1>
Taking first schedule S1:

Schedule S1:
Step 1 - final updation on data items
There is no read besides the initial read in both schedules S and S1, thus we don't need to check that condition.
Step 2 - Initial Read
T1 performs the initial read operation in S, and T1 also performs it in S1.
Step 3 - Final Write
T3 performs the final write operation in S, and T3 also performs it in S1. As a result, S and S1 are viewed as equivalent.
We don't need to verify another schedule because the first one, S1, meets all three criteria.
As a result, the comparable serial schedule is as follows:
T1 → T2 → T3




