Unit - 5
Implementation Techniques
Q1) What is data storage?
A1) A database system gives you a ultimate view of your data. Data in the form of bits and bytes, on the other hand, is saved in various storage devices.
Types of Data Storage
Different types of storage options are available for storing the data. The speed and accessibility of these storage options differ from one another. The following are the several sorts of storage devices that are used to store data.
○ Primary Storage
○ Secondary Storage
○ Tertiary Storage
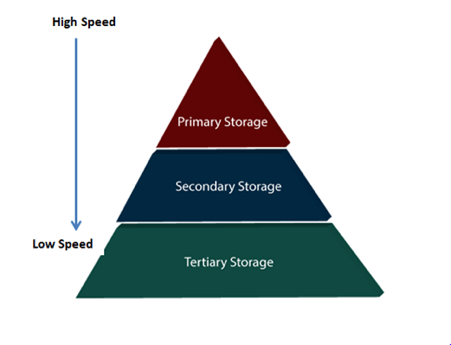
Fig: Types of data storage
1. Primary storage
It's the main location where you may get quick access to the info you've saved. Primary storage is also known as volatile storage. This is due to the fact that this sort of memory does not store data indefinitely. When the system has a power outage or a crash, the data is gone as well. Primary storage is divided into two categories: main memory and cache.
Main memory - It is the one who is in charge of managing the data that is stored on the storage medium. Each instruction of a computer machine is handled by the main memory. This sort of memory may hold gigabytes of data on a device while still being compact enough to fit the complete database. Finally, if the machine shuts down due to a power outage or other reasons, the main memory loses its whole contents.
2. Secondary Storage
Online storage is another name for secondary storage. It's the storage region where the user can save and store data indefinitely. Any data stored in this type of memory is not lost in the event of a power outage or a system crash. That is why it is also referred to as non-volatile storage.
Secondary storage media come in a variety of shapes and sizes, and are found in practically every form of computer system:
Flash memory - A flash memory stores data in USB (Universal Serial Bus) keys, which are then plugged into a computer system's USB slots. These USB keys assist in the transfer of data to a computer system, although their size limitations vary. Unlike main memory, it is possible to recover data that has been lost due to a power outage or other circumstances. For caching frequently accessed data, this form of memory storage is most widely utilized in server systems. This improves system performance and allows for the storage of larger databases than the primary memory allows.
Magnetic disk storage - Online storage media is another name for this sort of storage media. A magnetic disk is used to store data for long periods of time. It has the capacity to store a full database. The computer system is responsible for making data from a drive accessible to the main memory for further processing. In addition, if the system modifies the data in any way, the updated data should be copied back to the disk. A magnetic disk's incredible capability is that it does not influence data in the event of a system breakdown or failure, whereas a disk failure can quickly spoil as well as erase the stored data.
3. Tertiary Storage
It is a sort of storage that is not connected to the computer system. It moves at the slowest pace. It can, however, store a significant quantity of data. Offline storage is another name for it. Data backup is commonly done with tertiary storage. There are a variety of tertiary storage devices to choose from:
Optical storage - Data can be stored on optical storage in megabytes or gigabytes. A Compact Disk (CD) can hold 700 megabytes of data and has an 80-minute runtime. A Digital Video Disk or DVD, on the other hand, may store 4.7 or 8.5 gigabytes of data on each side of the disk.
Tape storage - It is the most cost-effective storage medium compared to disks. Tapes are typically used for data preservation or backup. Because it accesses data progressively from the beginning, it delivers delayed data access. As a result, sequential-access storage is another name for tape storage. Because we may access data from any position on disk, disk storage is referred to as direct-access storage.
Q2) What do you mean by file organization?
A2) Relative data and information is stored collectively in file formats. A file is a sequence of records stored in binary format. A disk drive is formatted into several blocks that can store records. File records are mapped onto those disk blocks.
File Organization
File Organization defines how file records are mapped onto disk blocks. We have four types of File Organization to organize file records −
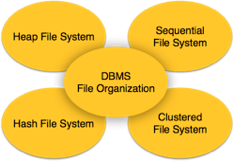
Fig – DBMS file organization
Heap File Organization
When a file is created using Heap File Organization, the Operating System allocates memory area to that file without any further accounting details. File records can be placed anywhere in that memory area. It is the responsibility of the software to manage the records. Heap File does not support any ordering, sequencing, or indexing on its own.
Sequential File Organization
Every file record contains a data field (attribute) to uniquely identify that record. In sequential file organization, records are placed in the file in some sequential order based on the unique key field or search key. Practically, it is not possible to store all the records sequentially in physical form.
Hash File Organization
Hash File Organization uses Hash function computation on some fields of the records. The output of the hash function determines the location of disk block where the records are to be placed.
Clustered File Organization
Clustered file organization is not considered good for large databases. In this mechanism, related records from one or more relations are kept in the same disk block, that is, the ordering of records is not based on primary key or search key.
File Operations
Operations on database files can be broadly classified into two categories −
● Update Operations
● Retrieval Operations
Update operations change the data values by insertion, deletion, or update. Retrieval operations, on the other hand, do not alter the data but retrieve them after optional conditional filtering. In both types of operations, selection plays a significant role. Other than creation and deletion of a file, there could be several operations, which can be done on files.
● Open− A file can be opened in one of the two modes, read mode or write mode. In read mode, the operating system does not allow anyone to alter data. In other words, data is read only. Files opened in read mode can be shared among several entities. Write mode allows data modification. Files opened in write mode can be read but cannot be shared.
● Locate−Every file has a file pointer, which tells the current position where the data is to be read or written. This pointer can be adjusted accordingly. Using find (seek) operation, it can be moved forward or backward.
● Read−By default, when files are opened in read mode, the file pointer points to the beginning of the file. There are options where the user can tell the operating system where to locate the file pointer at the time of opening a file. The very next data to the file pointer is read.
● Write− User can select to open a file in write mode, which enables them to edit its contents. It can be deletion, insertion, or modification. The file pointer can be located at the time of opening or can be dynamically changed if the operating system allows to do so.
● Close−This is the most important operation from the operating system’s point of view. When a request to close a file is generated, the operating system
● removes all the locks (if in shared mode),
● saves the data (if altered) to the secondary storage media, and
● releases all the buffers and file handlers associated with the file.
The organization of data inside a file plays a major role here. The process to locate the file pointer to a desired record inside a file various based on whether the records are arranged sequentially or clustered.
Q3) Describe index structure?
A3) Indexing in DBMS
● Indexing is used to optimize the performance of a database by minimizing the number of disk accesses required when a query is processed.
● The index is a type of data structure. It is used to locate and access the data in a database table quickly.
Index structure:
Indexes can be created using some database columns.

Fig – Structure of Index
● The first column of the database is the search key that contains a copy of the primary key or candidate key of the table. The values of the primary key are stored in sorted order so that the corresponding data can be accessed easily.
● The second column of the database is the data reference. It contains a set of pointers holding the address of the disk block where the value of the particular key can be found.
Indexing Methods
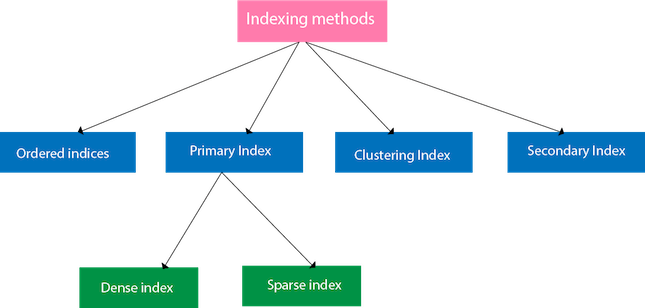
Fig – Indexing Methods
Ordered indices
The indices are usually sorted to make searching faster. The indices which are sorted are known as ordered indices.
Example: Suppose we have an employee table with thousands of record and each of which is 10 bytes long. If their IDs start with 1, 2, 3....and so on and we have to search student with ID-543.
● In the case of a database with no index, we have to search the disk block from starting till it reaches 543. The DBMS will read the record after reading 543*10=5430 bytes.
● In the case of an index, we will search using indexes and the DBMS will read the record after reading 542*2= 1084 bytes which are very less compared to the previous case.
Primary Index
● If the index is created on the basis of the primary key of the table, then it is known as primary indexing. These primary keys are unique to each record and contain 1:1 relation between the records.
● As primary keys are stored in sorted order, the performance of the searching operation is quite efficient.
● The primary index can be classified into two types: Dense index and Sparse index.
Dense index
● The dense index contains an index record for every search key value in the data file. It makes searching faster.
● In this, the number of records in the index table is same as the number of records in the main table.
● It needs more space to store index record itself. The index records have the search key and a pointer to the actual record on the disk.
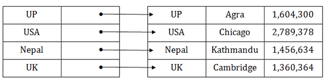
Fig – Dense Index
Sparse index
● In the data file, index record appears only for a few items. Each item points to a block.
● In this, instead of pointing to each record in the main table, the index points to the records in the main table in a gap.
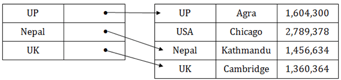
Fig 6 – Sparse Index
Clustering Index
● A clustered index can be defined as an ordered data file. Sometimes the index is created on non-primary key columns which may not be unique for each record.
● In this case, to identify the record faster, we will group two or more columns to get the unique value and create index out of them. This method is called a clustering index.
● The records which have similar characteristics are grouped, and indexes are created for these group.
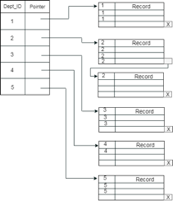
Example: suppose a company contains several employees in each department. Suppose we use a clustering index, where all employees which belong to the same Dept_ID are considered within a single cluster, and index pointers point to the cluster as a whole. Here Dept_Id is a non-unique key.
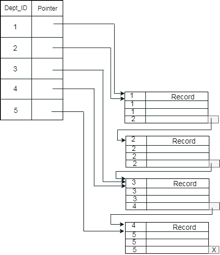
The previous schema is little confusing because one disk block is shared by records which belong to the different cluster. If we use separate disk block for separate clusters, then it is called better technique.
Q4) Define secondary index?
A4) Secondary Index
In the sparse indexing, as the size of the table grows, the size of mapping also grows. These mappings are usually kept in the primary memory so that address fetch should be faster. Then the secondary memory searches the actual data based on the address got from mapping. If the mapping size grows then fetching the address itself becomes slower. In this case, the sparse index will not be efficient. To overcome this problem, secondary indexing is introduced.
In secondary indexing, to reduce the size of mapping, another level of indexing is introduced. In this method, the huge range for the columns is selected initially so that the mapping size of the first level becomes small. Then each range is further divided into smaller ranges. The mapping of the first level is stored in the primary memory, so that address fetch is faster. The mapping of the second level and actual data are stored in the secondary memory (hard disk).

Fig – Secondary Index
For example:
● If you want to find the record of roll 111 in the diagram, then it will search the highest entry which is smaller than or equal to 111 in the first level index. It will get 100 at this level.
● Then in the second index level, again it does max (111) <= 111 and gets 110. Now using the address 110, it goes to the data block and starts searching each record till it gets 111.
● This is how a search is performed in this method. Inserting, updating or deleting is also done in the same manner.
Q5) Write short notes on hashing?
A5) Hashing
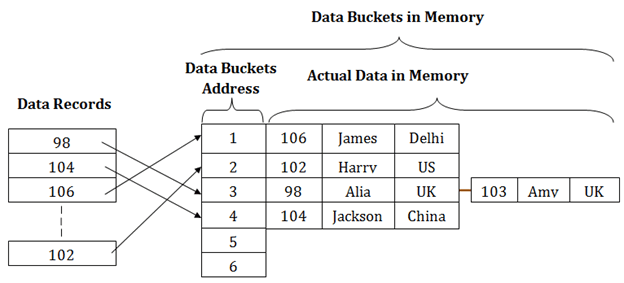
In a huge database structure, it is very inefficient to search all the index values and reach the desired data. Hashing technique is used to calculate the direct location of a data record on the disk without using index structure.
In this technique, data is stored at the data blocks whose address is generated by using the hashing function. The memory location where these records are stored is known as data bucket or data blocks.
In this, a hash function can choose any of the column value to generate the address. Most of the time, the hash function uses the primary key to generate the address of the data block. A hash function is a simple mathematical function to any complex mathematical function. We can even consider the primary key itself as the address of the data block. That means each row whose address will be the same as a primary key stored in the data block.
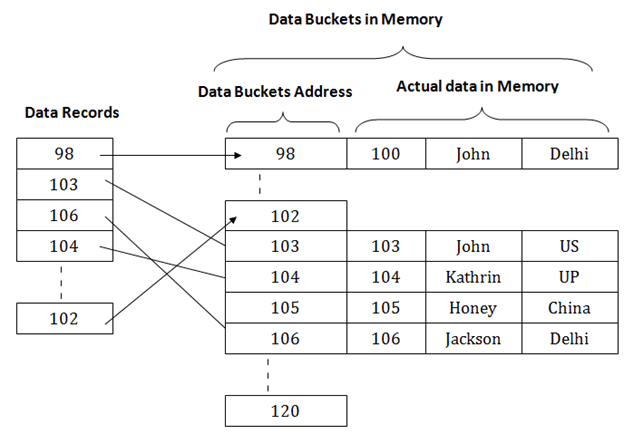
Fig – Data buckets in memory
The above diagram shows data block addresses same as primary key value. This hash function can also be a simple mathematical function like exponential, mod, cos, sin, etc. Suppose we have mod (5) hash function to determine the address of the data block. In this case, it applies mod (5) hash function on the primary keys and generates 3, 3, 1, 4 and 2 respectively, and records are stored in those data block addresses.
Q6) What are the types of hashing?
A6) Types of Hashing:
Fig - Hashing
● Static Hashing
● Dynamic Hashing
Static Hashing
In static hashing, the resultant data bucket address will always be the same. That means if we generate an address for EMP_ID =103 using the hash function mod (5) then it will always result in same bucket address 3. Here, there will be no change in the bucket address.
Hence in this static hashing, the number of data buckets in memory remains constant throughout. In this example, we will have five data buckets in the memory used to store the data.
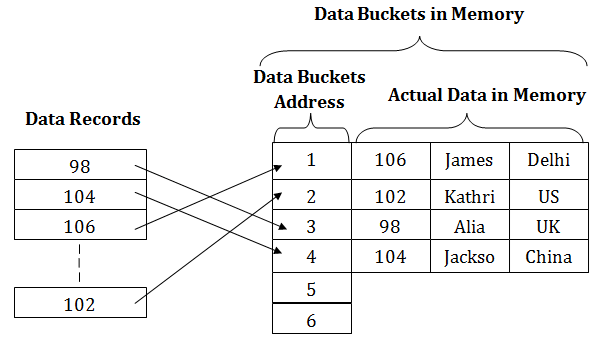
Fig – Static hashing
Operations of Static Hashing
● Searching a record
When a record needs to be searched, then the same hash function retrieves the address of the bucket where the data is stored.
● Insert a Record
When a new record is inserted into the table, then we will generate an address for a new record based on the hash key and record is stored in that location.
● Delete a Record
To delete a record, we will first fetch the record which is supposed to be deleted. Then we will delete the records for that address in memory.
● Update a Record
To update a record, we will first search it using a hash function, and then the data record is updated.
If we want to insert some new record into the file but the address of a data bucket generated by the hash function is not empty, or data already exists in that address. This situation in the static hashing is known as bucket overflow. This is a critical situation in this method.
To overcome this situation, there are various methods. Some commonly used methods are as follows:
1. Open Hashing
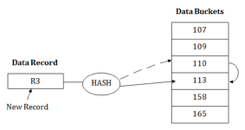
When a hash function generates an address at which data is already stored, then the next bucket will be allocated to it. This mechanism is called as Linear Probing.
For example: suppose R3 is a new address which needs to be inserted, the hash function generates address as 112 for R3. But the generated address is already full. So the system searches next available data bucket, 113 and assigns R3 to it.
2. Close Hashing
When buckets are full, then a new data bucket is allocated for the same hash result and is linked after the previous one. This mechanism is known as Overflow chaining.
For example: Suppose R3 is a new address which needs to be inserted into the table, the hash function generates address as 110 for it. But this bucket is full to store the new data. In this case, a new bucket is inserted at the end of 110 buckets and is linked to it.
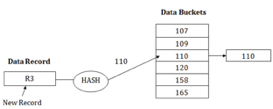
Q7) What is dynamic hashing?
A7) Dynamic Hashing
● The dynamic hashing method is used to overcome the problems of static hashing like bucket overflow.
● In this method, data buckets grow or shrink as the records increases or decreases. This method is also known as Extendable hashing method.
● This method makes hashing dynamic, i.e., it allows insertion or deletion without resulting in poor performance.
How to search a key
● First, calculate the hash address of the key.
● Check how many bits are used in the directory, and these bits are called as i.
● Take the least significant i bits of the hash address. This gives an index of the directory.
● Now using the index, go to the directory and find bucket address where the record might be.
How to insert a new record
● Firstly, you have to follow the same procedure for retrieval, ending up in some bucket.
● If there is still space in that bucket, then place the record in it.
● If the bucket is full, then we will split the bucket and redistribute the records.
For example:
Consider the following grouping of keys into buckets, depending on the prefix of their hash address:
Key | Hash address |
1 | 11010 |
2 | 00000 |
3 | 11110 |
4 | 00000 |
5 | 01001 |
6 | 10101 |
7 | 10111 |
The last two bits of 2 and 4 are 00. So it will go into bucket B0. The last two bits of 5 and 6 are 01, so it will go into bucket B1. The last two bits of 1 and 3 are 10, so it will go into bucket B2. The last two bits of 7 are 11, so it will go into B3.
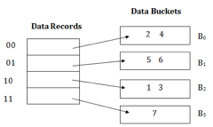
Insert key 9 with hash address 10001 into the above structure:
● Since key 9 has hash address 10001, it must go into the first bucket. But bucket B1 is full, so it will get split.
● The splitting will separate 5, 9 from 6 since last three bits of 5, 9 are 001, so it will go into bucket B1, and the last three bits of 6 are 101, so it will go into bucket B5.
● Keys 2 and 4 are still in B0. The record in B0 pointed by the 000 and 100 entry because last two bits of both the entry are 00.
● Keys 1 and 3 are still in B2. The record in B2 pointed by the 010 and 110 entry because last two bits of both the entry are 10.
● Key 7 are still in B3. The record in B3 pointed by the 111 and 011 entry because last two bits of both the entry are 11.

Q8) Write advantages and disadvantages of dynamic hashing?
A8) Advantages of dynamic hashing
● In this method, the performance does not decrease as the data grows in the system. It simply increases the size of memory to accommodate the data.
● In this method, memory is well utilized as it grows and shrinks with the data. There will not be any unused memory lying.
● This method is good for the dynamic database where data grows and shrinks frequently.
Disadvantages of dynamic hashing
● In this method, if the data size increases then the bucket size is also increased. These addresses of data will be maintained in the bucket address table. This is because the data address will keep changing as buckets grow and shrink. If there is a huge increase in data, maintaining the bucket address table becomes tedious.
● In this case, the bucket overflow situation will also occur. But it might take little time to reach this situation than static hashing.
Q9) Define multilevel indexes?
A9) We know that data is stored in the form of records. Every record has a key field, which helps it to be recognized uniquely.
Indexing is a data structure technique to efficiently retrieve records from the database files based on some attributes on which the indexing has been done. Indexing in database systems is similar to what we see in books.
Indexing is defined based on its indexing attributes. Indexing can be of the following types −
● Primary Index− Primary index is defined on an ordered data file. The data file is ordered on a key field. The key field is generally the primary key of the relation.
● Secondary Index− Secondary index may be generated from a field which is a candidate key and has a unique value in every record, or a non-key with duplicate values.
● Clustering Index− Clustering index is defined on an ordered data file. The data file is ordered on a non-key field.
Ordered Indexing is of two types −
● Dense Index
● Sparse Index
Dense Index
In a dense index, there is an index record for every search key value in the database. This makes searching faster but requires more space to store index records itself. Index records contain search key value and a pointer to the actual record on the disk.
Fig – Dense Index
Sparse Index
In sparse index, index records are not created for every search key. An index record here contains a search key and an actual pointer to the data on the disk. To search a record, we first proceed by index record and reach at the actual location of the data. If the data we are looking for is not where we directly reach by following the index, then the system starts sequential search until the desired data is found.

Fig – Sparse index
Multilevel Index
Index records comprise search-key values and data pointers. Multilevel index is stored on the disk along with the actual database files. As the size of the database grows, so does the size of the indices. There is an immense need to keep the index records in the main memory so as to speed up the search operations. If single-level index is used, then a large size index cannot be kept in memory which leads to multiple disk accesses.

Fig – Multilevel Index
Multi-level Index helps in breaking down the index into several smaller indices in order to make the outermost level so small that it can be saved in a single disk block, which can easily be accommodated anywhere in the main memory.
Q10) Explain B+ tree?
A10) A B+ tree is a balanced binary search tree that follows a multi-level index format. The leaf nodes of a B+ tree denote actual data pointers. B+ tree ensures that all leaf nodes remain at the same height, thus balanced. Additionally, the leaf nodes are linked using a link list; therefore, a B+ tree can support random access as well as sequential access.
Structure of B+ Tree
Every leaf node is at equal distance from the root node. A B+ tree is of the order n where n is fixed for every B+ tree.
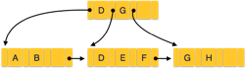
Fig – B+ Tree
Internal nodes−
● Internal (non-leaf) nodes contain at least ⌈n/2⌉ pointers, except the root node.
● At most, an internal node can contain n pointers.
Leaf nodes−
● Leaf nodes contain at least ⌈n/2⌉ record pointers and ⌈n/2⌉ key values.
● At most, a leaf node can contain n record pointers and n key values.
● Every leaf node contains one block pointer P to point to next leaf node and forms a linked list.
B+ Tree Insertion
● B+ trees are filled from bottom and each entry is done at the leaf node.
● If a leaf node overflows −
● Split node into two parts.
● Partition at i = ⌊(m+1)/2⌋.
● First i entries are stored in one node.
● Rest of the entries (i+1 onwards) are moved to a new node.
● ith key is duplicated at the parent of the leaf.
● If a non-leaf node overflows −
● Split node into two parts.
● Partition the node at i = ⌈(m+1)/2⌉.
● Entries up to i are kept in one node.
● Rest of the entries are moved to a new node.
B+ Tree Deletion
● B+ tree entries are deleted at the leaf nodes.
● The target entry is searched and deleted.
● If it is an internal node, delete and replace with the entry from the left position.
● After deletion, underflow is tested,
● If underflow occurs, distribute the entries from the nodes left to it.
● If distribution is not possible from left, then
● Distribute from the nodes right to it.
● If distribution is not possible from left or from right, then
● Merge the node with left and right to it.
Q11) Write the difference between static and dynamic hashing?
A11) Difference between static and dynamic hashing
Dynamic Hashing | Static Hashing |
It allows the number of buckets to vary dynamically. | A fixed number of buckets is allocated to a file to store the records. |
It uses a second stage of mapping to determine the bucket associated with some search-key value. | It uses a fixed hash function to partition the set of all possible search-key values into subsets, and then maps each subset to a bucket. |
Performance does not degrade as the file grows. | Performance degrades due to the bucket overflow. |
The index entries are randomized in a way that the number of index entries in each bucket is roughly the same. | It uses a dynamically changing function that allows the addressed space to grow and shrink with varying database files. |
Q12) What is the difference between primary and secondary index?
A12) Difference between primary and secondary index
Primary Index(P.I) | Secondary Index(S.I) |
1. PI is mandatory | 1. Optional |
2. Only one for = the table | 2. Max 32 for a table |
3. Physical mechanism effect data distribution | 3. Logical mechanism doesn’t provide access path to the row |
4. Can’t be drop | 4. Can be drop |
5. Provides access path to the row | 5. Does not provide access path to the row |
6. Storage and retrieval | 6. Only retrieval |
7. Single Amp Operation | 7. 2 or many Amp Operation |




