Unit - 2
Process Scheduling
Q1) What do you mean by process scheduling?
A1) The process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process on the basis of a particular strategy.
Process scheduling is an essential part of a Multiprogramming operating systems. Such operating systems allow more than one process to be loaded into the executable memory at a time and the loaded process shares the CPU using time multiplexing.
Process Scheduling Queues
The OS maintains all PCBs in Process Scheduling Queues. The OS maintains a separate queue for each of the process states and PCBs of all processes in the same execution state are placed in the same queue. When the state of a process is changed, its PCB is unlinked from its current queue and moved to its new state queue.
The Operating System maintains the following important process scheduling queues −
● Job queue − This queue keeps all the processes in the system.
● Ready queue − This queue keeps a set of all processes residing in main memory, ready and waiting to execute. A new process is always put in this queue.
● Device queues − The processes which are blocked due to unavailability of an I/O device constitute this queue.
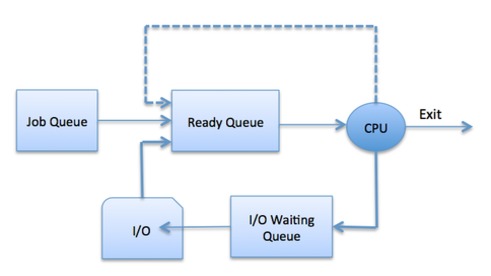
Fig 1 – Process state
The OS can use different policies to manage each queue (FIFO, Round Robin, Priority, etc.). The OS scheduler determines how to move processes between the ready and run queues which can only have one entry per processor core on the system; in the above diagram, it has been merged with the CPU.
Two-State Process Model
Two-state process model refers to running and non-running states which are described below −
S.N. | State & Description |
1 | Running When a new process is created, it enters into the system as in the running state. |
2 | Not Running Processes that are not running are kept in queue, waiting for their turn to execute. Each entry in the queue is a pointer to a particular process. Queue is implemented by using linked list. Use of dispatcher is as follows. When a process is interrupted, that process is transferred in the waiting queue. If the process has completed or aborted, the process is discarded. In either case, the dispatcher then selects a process from the queue to execute. |
Q2) What is scheduler?
A2) Schedulers
Schedulers are special system software which handle process scheduling in various ways. Their main task is to select the jobs to be submitted into the system and to decide which process to run. Schedulers are of three types −
● Long-Term Scheduler
● Short-Term Scheduler
● Medium-Term Scheduler
Long Term Scheduler
It is also called a job scheduler. A long-term scheduler determines which programs are admitted to the system for processing. It selects processes from the queue and loads them into memory for execution. Process loads into the memory for CPU scheduling.
The primary objective of the job scheduler is to provide a balanced mix of jobs, such as I/O bound and processor bound. It also controls the degree of multiprogramming. If the degree of multiprogramming is stable, then the average rate of process creation must be equal to the average departure rate of processes leaving the system.
On some systems, the long-term scheduler may not be available or minimal. Time-sharing operating systems have no long-term scheduler. When a process changes the state from new to ready, then there is use of long-term scheduler.
Short Term Scheduler
It is also called as CPU scheduler. Its main objective is to increase system performance in accordance with the chosen set of criteria. It is the change of ready state to running state of the process. CPU scheduler selects a process among the processes that are ready to execute and allocates CPU to one of them.
Short-term schedulers, also known as dispatchers, make the decision of which process to execute next. Short-term schedulers are faster than long-term schedulers.
Medium Term Scheduler
Medium-term scheduling is a part of swapping. It removes the processes from the memory. It reduces the degree of multiprogramming. The medium-term scheduler is in-charge of handling the swapped out-processes.
A running process may become suspended if it makes an I/O request. A suspended process cannot make any progress towards completion. In this condition, to remove the process from memory and make space for other processes, the suspended process is moved to the secondary storage. This process is called swapping, and the process is said to be swapped out or rolled out. Swapping may be necessary to improve the process mix.
Q3) Write the difference between schedulers?
A3) Comparison among Scheduler
S.N. | Long-Term Scheduler | Short-Term Scheduler | Medium-Term Scheduler |
1 | It is a job scheduler | It is a CPU scheduler | It is a process swapping scheduler. |
2 | Speed is lesser than short term scheduler | Speed is fastest among other two | Speed is in between both short- and long-term scheduler. |
3 | It controls the degree of multiprogramming | It provides lesser control over degree of multiprogramming | It reduces the degree of multiprogramming. |
4 | It is almost absent or minimal in time sharing system | It is also minimal in time sharing system | It is a part of Time-sharing systems. |
5 | It selects processes from pool and loads them into memory for execution | It selects those processes which are ready to execute | It can re-introduce the process into memory and execution can be continued. |
Q4) Define context switching?
A4) Context Switch
A context switch is the mechanism to store and restore the state or context of a CPU in Process Control block so that a process execution can be resumed from the same point at a later time. Using this technique, a context switcher enables multiple processes to share a single CPU. Context switching is an essential part of a multitasking operating system features.
When the scheduler switches the CPU from executing one process to execute another, the state from the current running process is stored into the process control block. After this, the state for the process to run next is loaded from its own PCB and used to set the PC, registers, etc. At that point, the second process can start executing.
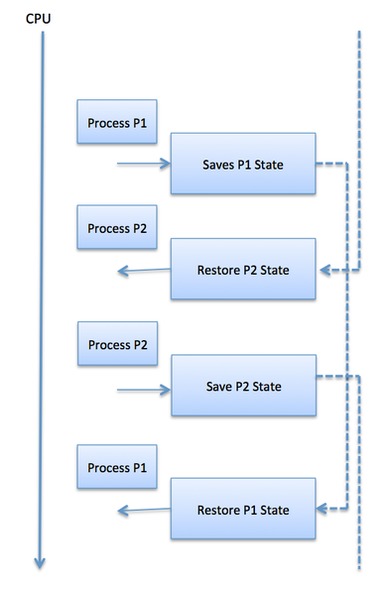
Fig 2 – Process state
Context switches are computationally intensive since register and memory state must be saved and restored. To avoid the amount of context switching time, some hardware systems employ two or more sets of processor registers. When the process is switched, the following information is stored for later use.
● Program Counter
● Scheduling information
● Base and limit register value
● Currently used register
● Changed State
● I/O State information
● Accounting information
Q5) Explain process co-ordination?
A5) Process coordination or concurrency control deals with mutual exclusion and synchronization.
Mutual exclusion - ensuring that two concurrent activities do not access shared data (resource) at the same time; crucial region — a set of instructions that can only be executed by one activity.
Synchronization - It is the process of employing a condition to synchronize the actions of multiple activities that are taking place at the same time. Mutual exclusion has been generalized.
When considering process coordination, keep the following scenarios in mind:
1. Deadlock - When two activities are waiting for each other and neither can move forward, it is called a deadlock. Consider the following scenario: Assume that processes A and B each require two tape drives to continue, but that only one drive has been assigned to each. If the system only has two disks, neither process can run.
2. Starvation - When a blocked activity is repeatedly passed over and not permitted to run, starvation ensues. Consider two CPU-intensive activities, one of which is executing at a higher priority than the other. The process with the lowest priority will never be allowed to run.
Mutual Exclusion
The following requirements must be met by any solution to the mutual exclusion problem:
Mutual exclusion— Never run more than one process in a key part at the same time.
Environment independent — there are no assumptions about comparable process speeds or processor counts.
Resources shared only in critical region — No process should be blocked if it is stopped outside of the crucial region.
Bounded waiting — Once a process requests entry to a crucial region, the number of times other processes are allowed to enter the critical parts until the request is granted must be limited.
Q6) What is process synchronization?
A6) Process Synchronization is the task of coordinating the execution of processes in a way that no two processes can have access to the same shared data and resources.
It is specially needed in a multi-process system when multiple processes are running together, and more than one processes try to gain access to the same shared resource or data at the same time.
This can lead to the inconsistency of shared data. So, the change made by one process not necessarily reflected when other processes accessed the same shared data. To avoid this type of inconsistency of data, the processes need to be synchronized with each other.
How Process Synchronization Works?
For Example, process A changing the data in a memory location while another process B is trying to read the data from the same memory location. There is a high probability that data read by the second process will be erroneous.
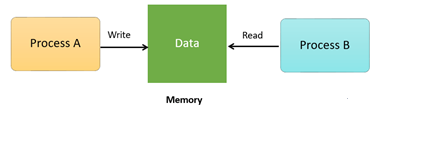
Fig 3 – Memory
Sections of a Program
Here, are four essential elements of the critical section:
● Entry Section: It is part of the process which decides the entry of a particular process.
● Critical Section: This part allows one process to enter and modify the shared variable.
● Exit Section: Exit section allows the other process that are waiting in the Entry Section, to enter into the Critical Sections. It also checks that a process that finished its execution should be removed through this Section.
● Remainder Section: All other parts of the Code, which is not in Critical, Entry, and Exit Section, are known as the Remainder Section.
Q7) Write short notes on semaphores?
A7) Semaphores square measure number variables that square measure accustomed to solve the important section downside by exploitation 2 atomic operations, wait and signal that square measure used for method synchronization.
The definitions of wait and signal square measure as follows −
● Wait
The wait operation decrements the worth of its argument S if it's positive. If S is negative or zero, then no operation is performed.
Wait(S)
Whereas (S<=0);
S--;
}
● Signal
The signal operation increments the worth of its argument S.
Signal(S)
Types of Semaphores
There square measure 2 main kinds of semaphores i.e., reckoning semaphores and binary semaphores. Details concerning these square measure given as follows –
● Counting Semaphores
These square measure number worth semaphores Associate in Nursing has an unrestricted worth domain. These semaphores square measure accustomed coordinate the resource access, wherever the semaphore count is that the range of accessible resources. If the resources square measure extra, the semaphore count is mechanically incremented and if the resources square measure is removed, the count is decremented.
● Binary Semaphores
The binary semaphores square measure like reckoning semaphores however their worth is restrict-ed to zero and one. The wait operation solely works once the semaphore is one and therefore the signal operation succeeds once the semaphore is zero. It's typically easier to implement binary semaphores than reckoning semaphores.
Q8) What are the advantages and disadvantages of semaphore?
A8) Advantages of Semaphores
Some of the benefits of semaphores square measure as follows −
● Semaphores permit only 1 method into the important section. They follow the mutual Pauli exclusion principle strictly and square measure far more economical than another way of synchronization.
● There isn't any resource wastage as a result of busy waiting in semaphores as processor time isn't wasted unnecessarily to ascertain if a condition is consummated to permit a method to access the important section.
● Semaphores square measure enforced within the machine freelance code of the microkernel. So that they square measure machine freelance.
Disadvantages of Semaphores
Some of the disadvantages of semaphores square measure as follows −
● Semaphores square measure difficult therefore the wait and signal operations should be implemented within the correct order to stop deadlocks.
● Semaphores square measure impractical for last scale use as their use ends up in the loss of modularity. This happens as a result of the wait and signal operations stop the creation of a structured layout for the system.
● Semaphores might cause a priority inversion wherever low priority processes might access the important section 1st and high priority processes later.
Q9) Describe deadlock?
A9) Every process needs some resources to complete its execution. However, the resource is granted in a sequential order.
- The process requests for some resource.
- OS grant the resource if it is available otherwise let the process waits.
- The process uses it and release on the completion.
A Deadlock is a situation where each of the computer process waits for a resource which is being assigned to some another process. In this situation, none of the process gets executed since the resource it needs, is held by some other process which is also waiting for some other resource to be released.
Let us assume that there are three processes P1, P2 and P3. There are three different resources R1, R2 and R3. R1 is assigned to P1, R2 is assigned to P2 and R3 is assigned to P3.
After some time, P1 demands for R1 which is being used by P2. P1 halts its execution since it can't complete without R2. P2 also demands for R3 which is being used by P3. P2 also stops its execution because it can't continue without R3. P3 also demands for R1 which is being used by P1 therefore P3 also stops its execution.
In this scenario, a cycle is being formed among the three processes. None of the process is progressing and they are all waiting. The computer becomes unresponsive since all the processes got blocked.
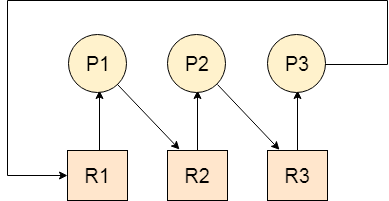
Fig 4 – Process cycle
Necessary conditions for Deadlocks
- Mutual Exclusion
A resource can only be shared in mutually exclusive manner. It implies, if two process cannot use the same resource at the same time.
2. Hold and Wait
A process waits for some resources while holding another resource at the same time.
3. No preemption
The process which once scheduled will be executed till the completion. No other process can be scheduled by the scheduler meanwhile.
4. Circular Wait
All the processes must be waiting for the resources in a cyclic manner so that the last process is waiting for the resource which is being held by the first process.
Q10) Write the difference between deadlock and starvation?
A10) Difference between Starvation and Deadlock
Sn. | Deadlock | Starvation |
1 | Deadlock is a situation where no process got blocked and no process proceeds | Starvation is a situation where the low priority process got blocked and the high priority processes proceed. |
2 | Deadlock is an infinite waiting. | Starvation is a long waiting but not infinite. |
3 | Every Deadlock is always a starvation. | Every starvation need not be deadlock. |
4 | The requested resource is blocked by the other process. | The requested resource is continuously be used by the higher priority processes. |
5 | Deadlock happens when Mutual exclusion, hold and wait, No preemption and circular wait occurs simultaneously. | It occurs due to the uncontrolled priority and resource management. |
Q11) Describe Deadlock in resource allocation?
A11) Resource Allocation Graph
The resource allocation graph is the pictorial representation of the state of a system. As its name suggests, the resource allocation graph is the complete information about all the processes which are holding some resources or waiting for some resources.
It also contains the information about all the instances of all the resources whether they are available or being used by the processes.
In Resource allocation graph, the process is represented by a Circle while the Resource is represented by a rectangle. Let's see the types of vertices and edges in detail.
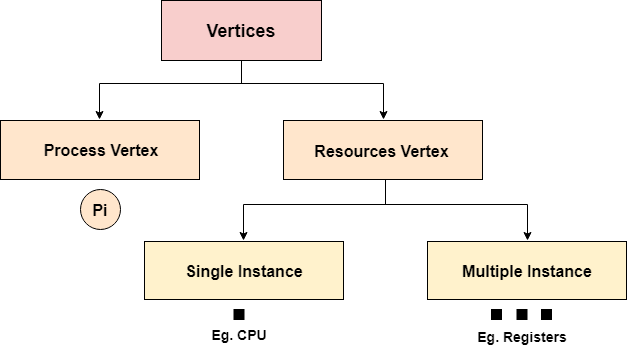
Fig 5 - Vertices
Vertices are mainly of two types, Resource and process. Each of them will be represented by a different shape. Circle represents process while rectangle represents resource.
A resource can have more than one instance. Each instance will be represented by a dot inside the rectangle.
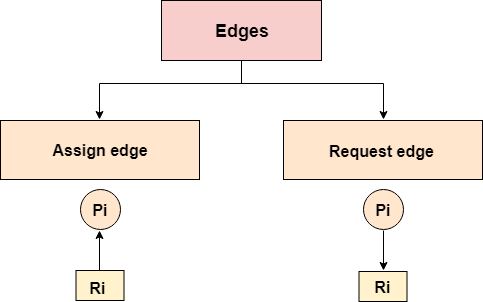
Fig 6 - Edges
Edges in RAG are also of two types, one represents assignment and other represents the wait of a process for a resource. The above image shows each of them.
A resource is shown as assigned to a process if the tail of the arrow is attached to an instance to the resource and the head is attached to a process.
A process is shown as waiting for a resource if the tail of an arrow is attached to the process while the head is pointing towards the resource.
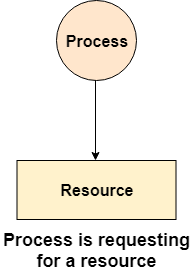
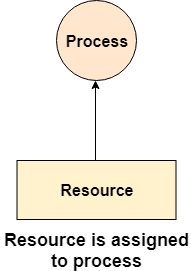
Fig 7 - Waiting for a resource
Example
Let's Consider 3 processes P1, P2 and P3, and two types of resources R1 and R2. The resources are having 1 instance each.
According to the graph, R1 is being used by P1, P2 is holding R2 and waiting for R1, P3 is waiting for R1 as well as R2.
The graph is deadlock free since no cycle is being formed in the graph.
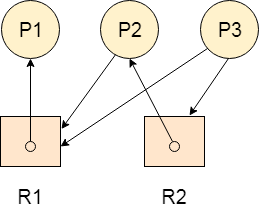
Fig 8 - Deadlock free
Deadlock Detection using RAG
If a cycle is being formed in a Resource allocation graph where all the resources have the single instance then the system is deadlocked.
In Case of Resource allocation graph with multi-instanced resource types, Cycle is a necessary condition of deadlock but not the sufficient condition.
The following example contains three processes P1, P2, P3 and three resources R2, R2, R3. All the resources are having single instances each.
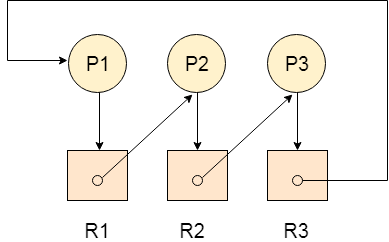
Fig 9 - Example
If we analyze the graph then we can find out that there is a cycle formed in the graph since the system is satisfying all the four conditions of deadlock.
Allocation Matrix
Allocation matrix can be formed by using the Resource allocation graph of a system. In Allocation matrix, an entry will be made for each of the resource assigned. For Example, in the following matrix, an entry is being made in front of P1 and below R3 since R3 is assigned to P1.
Process | R1 | R2 | R3 |
P1 | 0 | 0 | 1 |
P2 | 1 | 0 | 0 |
P3 | 0 | 1 | 0 |
Request Matrix
In request matrix, an entry will be made for each of the resource requested. As in the following example, P1 needs R1 therefore an entry is being made in front of P1 and below R1.
Process | R1 | R2 | R3 |
P1 | 1 | 0 | 0 |
P2 | 0 | 1 | 0 |
P3 | 0 | 0 | 1 |
Avial = (0,0,0)
Neither we are having any resource available in the system nor a process going to release. Each of the process needs at least single resource to complete therefore they will continuously be holding each one of them.
We cannot fulfill the demand of at least one process using the available resources therefore the system is deadlocked as determined earlier when we detected a cycle in the graph.
Q12) What are the methods for handling deadlocks?
A12) Strategies for handling Deadlock
1. Deadlock Ignorance
Deadlock Ignorance is the most widely used approach among all the mechanism. This is being used by many operating systems mainly for end user uses. In this approach, the Operating system assumes that deadlock never occurs. It simply ignores deadlock. This approach is best suitable for a single end user system where User uses the system only for browsing and all other normal stuff.
There is always a tradeoff between Correctness and performance. The operating systems like Windows and Linux mainly focus upon performance. However, the performance of the system decreases if it uses deadlock handling mechanism all the time if deadlock happens 1 out of 100 times, then it is completely unnecessary to use the deadlock handling mechanism all the time.
In these types of systems, the user has to simply restart the computer in the case of deadlock. Windows and Linux are mainly using this approach.
2. Deadlock prevention
Deadlock happens only when Mutual Exclusion, hold and wait, No preemption and circular wait holds simultaneously. If it is possible to violate one of the four conditions at any time then the deadlock can never occur in the system.
The idea behind the approach is very simple that we have to fail one of the four conditions but there can be a big argument on its physical implementation in the system.
3. Deadlock avoidance
In deadlock avoidance, the operating system checks whether the system is in safe state or in unsafe state at every step which the operating system performs. The process continues until the system is in safe state. Once the system moves to unsafe state, the OS has to backtrack one step.
In simple words, The OS reviews each allocation so that the allocation doesn't cause the deadlock in the system.
4. Deadlock detection and recovery
This approach let the processes fall in deadlock and then periodically check whether deadlock occur in the system or not. If it occurs then it applies some of the recovery methods to the system to get rid of deadlock.
Q13) How to detect and recover deadlocks?
A13) Deadlock Detection and Recovery
In this approach, The OS doesn't apply any mechanism to avoid or prevent the deadlocks. Therefore, the system considers that the deadlock will definitely occur. In order to get rid of deadlocks, The OS periodically checks the system for any deadlock. In case, it finds any of the deadlock then the OS will recover the system using some recovery techniques.
The main task of the OS is detecting the deadlocks. The OS can detect the deadlocks with the help of Resource allocation graph.
Fig 10 - Detection
In single instanced resource types, if a cycle is being formed in the system, then there will definitely be a deadlock. On the other hand, in multiple instanced resource type graph, detecting a cycle is not just enough. We have to apply the safety algorithm on the system by converting the resource allocation graph into the allocation matrix and request matrix.
In order to recover the system from deadlocks, either OS considers resources or processes.
For Resource
Preempt the resource
We can snatch one of the resources from the owner of the resource (process) and give it to the other process with the expectation that it will complete the execution and will release this resource sooner. Well, choosing a resource which will be snatched is going to be a bit difficult.
Rollback to a safe state
System passes through various states to get into the deadlock state. The operating system can roll back the system to the previous safe state. For this purpose, OS needs to implement check pointing at every state.
The moment, we get into deadlock, we will rollback all the allocations to get into the previous safe state.
For Process
Kill a process
Killing a process can solve our problem but the bigger concern is to decide which process to kill. Generally, Operating system kills a process which has done least amount of work until now.
Kill all process
This is not a suggestible approach but can be implemented if the problem becomes very serious. Killing all process will lead to inefficiency in the system because all the processes will execute again from starting.
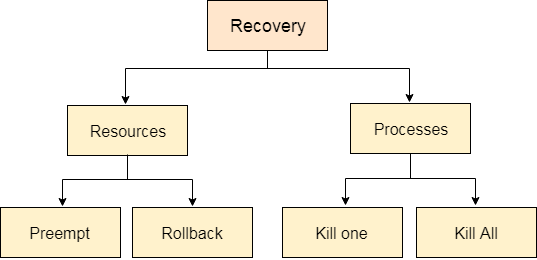
Fig 11 – Recovery




