Unit - 4
File System
Q1) What is a file system?
A1) A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes. It is a method of data collection that is used as a medium for giving input and receiving output from that program.
In general, a file is a sequence of bits, bytes, or records whose meaning is defined by the file creator and user. Every File has a logical location where they are located for storage and retrieval.
Objective of File management System
Here are the main objectives of the file management system:
● It provides I/O support for a variety of storage device types.
● Minimizes the chances of lost or destroyed data
● Helps OS to standardized I/O interface routines for user processes.
● It provides I/O support for multiple users in a multiuser systems environment.
Properties of a File System
Here, are important properties of a file system:
● Files are stored on disk or other storage and do not disappear when a user logs off.
● Files have names and are associated with access permission that permits controlled sharing.
● Files could be arranged or more complex structures to reflect the relationship between them.
File structure
A File Structure needs to be predefined format in such a way that an operating system understands. It has an exclusively defined structure, which is based on its type.
Three types of files structure in OS:
● A text file: It is a series of characters that is organized in lines.
● An object file: It is a series of bytes that is organized into blocks.
● A source file: It is a series of functions and processes.
File Attributes
A file has a name and data. Moreover, it also stores meta information like file creation date and time, current size, last modified date, etc. All this information is called the attributes of a file system.
Here, are some important File attributes used in OS:
● Name: It is the only information stored in a human-readable form.
● Identifier: Every file is identified by a unique tag number within a file system known as an identifier.
● Location: Points to file location on device.
● Type: This attribute is required for systems that support various types of files.
● Size. Attribute used to display the current file size.
● Protection. This attribute assigns and controls the access rights of reading, writing, and executing the file.
● Time, date and security: It is used for protection, security, and also used for monitoring
File Type
It refers to the ability of the operating system to differentiate various types of files like text files, binary, and source files. However, Operating systems like MS_DOS and UNIX has the following type of files:
Character Special File
It is a hardware file that reads or writes data character by character, like mouse, printer, and more.
Ordinary files
● These types of files stores user information.
● It may be text, executable programs, and databases.
● It allows the user to perform operations like add, delete, and modify.
Directory Files
● Directory contains files and other related information about those files. It’s basically a folder to hold and organize multiple files.
Special Files
● These files are also called device files. It represents physical devices like printers, disks, networks, flash drive, etc.
Functions of File
● Create file, find space on disk, and make an entry in the directory.
● Write to file, requires positioning within the file
● Read from file involves positioning within the file
● Delete directory entry, regain disk space.
● Reposition: move read/write position.
Commonly used terms in File systems
Field:
This element stores a single value, which can be static or variable length.
DATABASE:
Collection of related data is called a database. Relationships among elements of data are explicit.
FILES:
Files is the collection of similar record which is treated as a single entity.
RECORD:
A Record type is a complex data type that allows the programmer to create a new data type with the desired column structure. Its groups one or more columns to form a new data type. These columns will have their own names and data type.
Q2) What do you mean by file directory?
A2) File Directories
A single directory may or may not contain multiple files. It can also have subdirectories inside the main directory. Information about files is maintained by Directories. In Windows OS, it is called folders.
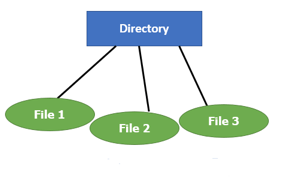
Fig 1 - Single Level Directory
Following is the information which is maintained in a directory:
● Name The name which is displayed to the user.
● Type: Type of the directory.
● Position: Current next-read/write pointers.
● Location: Location on the device where the file header is stored.
● Size: Number of bytes, block, and words in the file.
● Protection: Access control on read/write/execute/delete.
● Usage: Time of creation, access, modification
File types- name, extension
File Type | Usual extension | Function |
Executable | Exe, com, bin or none | Ready-to-run machine- language program |
Object | Obj, o | Complied, machine language, not linked |
Source code | c. p, pas, 177, asm, a | Source code in various languages |
Batch | Bat, sh | Series of commands to be executed |
Text | Txt, doc | Textual data documents |
Word processor | Doc, docs, tex, rrf, etc. | Various word-processor formats |
Library | Lib, h | Libraries of routines |
Archive | Arc, zip, tar | Related files grouped into one file, sometimes compressed. |
Q3) What do you mean by space allocation?
A3) Space Allocation
In the Operating system, files are always allocated disk spaces.
Three types of space allocation methods are:
● Linked Allocation
● Indexed Allocation
● Contiguous Allocation
Contiguous Allocation
In this method,
● Every file user a contiguous address space on memory.
● Here, the OS assigns disk address is in linear order.
● In the contiguous allocation method, external fragmentation is the biggest issue.
Linked Allocation
In this method,
● Every file includes a list of links.
● The directory contains a link or pointer in the first block of a file.
● With this method, there is no external fragmentation
● This File allocation method is used for sequential access files.
● This method is not ideal for a direct access file.
Indexed Allocation
In this method,
● Directory comprises the addresses of index blocks of the specific files.
● An index block is created, having all the pointers for specific files.
● All files should have individual index blocks to store the addresses for disk space.
Q4) Write about file access method?
A4) File Access Methods
File access is a process that determines the way that files are accessed and read into memory. Generally, a single access method is always supported by operating systems. Though there are some operating system which also supports multiple access methods.
Three file access methods are:
● Sequential access
● Direct random access
● Index sequential access
Sequential Access
In this type of file access method, records are accessed in a certain predefined sequence. In the sequential access method, information stored in the file is also processed one by one. Most compilers access files using this access method.
Random Access
The random access method is also called direct random access. This method allows accessing the record directly. Each record has its own address on which can be directly accessed for reading and writing.
Index Sequential Access
This type of accessing method is based on simple sequential access. In this access method, an index is built for every file, with a direct pointer to different memory blocks. In this method, the Index is searched sequentially, and its pointer can access the file directly. Multiple levels of indexing can be used to offer greater efficiency in access. It also reduces the time needed to access a single record.
Q5) Describe file system implementation?
A5) In the disk, file systems store several important data structures:
● A boot-control block (per volume), also known as the boot block in UNIX or the partition boot sector in Windows, includes instructions on how to start the computer from this disk. If the disk contains a bootable system, this will usually be the first sector of the volume; otherwise, the block will be left empty.
● A volume control block, also known as the master file table in UNIX or the superblock in Windows, holds information such as the partition table, the number of blocks on each filesystem, and pointers to free blocks and free FCB blocks (per volume).
● A directory structure containing file names and pointers to related FCBs (per file system). Inode numbers are used in UNIX, while a master file table is used in NTFS.
● The File Control Block, or FCB, is a per-file data structure that contains information such as file ownership, size, permissions, dates, and so on. UNIX saves this information in inodes, but NTFS stores it in a relational database structure called the master file table.
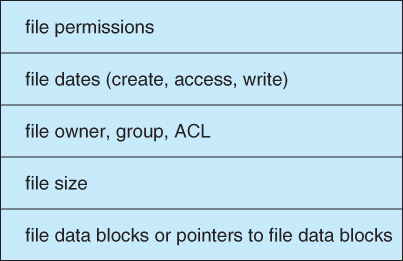
Fig 2: File control block
Several important data structures are also kept in memory:
● A mount table that is stored in memory.
● A directory cache of recently visited directory information that is kept in memory.
● A system-wide open file table that contains a copy of the FCB for each presently open file in the system, as well as some other related data.
● A pointer to the system open file database as well as certain additional information is stored in a per-process open file table. (Depending on the implementation and whether the file is shared or not, the current file position pointer may be here or in the system file table.)
When files are created and/or used, the following interactions of file system components are shown:
● When a new file is generated, a new FCB is assigned to it and filled out with crucial information about it. The new file name and FCB information are added to the relevant directory.
● The open() system call reads the FCB information from disk and stores it in the system-wide open file table when a file is accessed during a program. The open() system call returns an index into the per-process table and adds an entry to the per-process open file table referencing the system-wide table. This index is known as a file descriptor in UNIX and a file handle in Windows.
● When a new request for the same file arrives and it is sharable, a counter in the system-wide table is incremented and the per-process table is modified to point to the existing entry in the system-wide table.

Fig 3 - In-memory file-system structures. (a) File open. (b) File read
● The per-process table entry is freed when a file is closed, and the number in the system-wide table is decremented. When that counter approaches 0, the entire system table is liberated as well. If necessary, any data currently held in the memory cache for this file is written to disk.
Partitioning and Mounting
● Partitions are used to divide physical drives into smaller parts. They can also be combined to make larger units, but this is most usually done for RAID setups.
● Partitions can be prepared to hold a filesystem or utilized as raw devices (with no structure imposed on them) (i.e., populated with FCBs and initial directory structures as appropriate.) Raw partitions are commonly used for swap space, but they can also be used for programs that manage their own disk storage system, such as databases.
● The boot program accesses the boot block as part of a raw partition before loading any operating system. Modern boot programs can recognize a variety of operating systems and filesystem formats, and can provide the user the option of booting from one of numerous options.
● The root partition contains the operating system kernel, as well as at least the critical elements of the operating system required to complete the boot process. The root partition is mounted at boot time, and control is passed from the boot loader to the kernel on that partition.
● As the boot process continues, more filesystems are mounted, and their information is added to the proper mount table structure. The file systems may be examined for problems or inconsistencies as part of the mounting procedure, either because they were identified as not being correctly closed the last time they were used, or just for general purposes. Filesystems can be mounted manually or automatically. In UNIX, a mount point is specified by setting a flag in the in-memory copy of the inode, which redirects all future references to that inode to the mounted filesystem's root directory.
Q6) Define Linux file system?
A6) From smartphones to cars, supercomputers and home appliances, the Linux operating system is ubiquitous.
Linux is an operating system, just like Windows XP, Windows 7, Windows 8, and Mac OS X. An operating system is a piece of software that controls all of the hardware resources on your computer or laptop. Simply explained, the operating system is in charge of coordinating the connection between your program and your hardware. The software would not work without the operating system (also known as the "OS").
Components of Linux
The Linux Operating System is made up of three main parts.
Kernel - The kernel is the most important component of Linux. It is in charge of the operating system's major functions. It is made up of numerous modules that interface directly with the hardware. Kernel offers the necessary abstraction for system or application applications to mask low-level hardware specifics.
System library - System libraries are special functions or programs that are used to access Kernel functionality by application applications or system utilities. These libraries implement the majority of the operating system's features without requiring kernel module code access.
System utility - System Utility programs are in charge of performing specialized, unique duties.
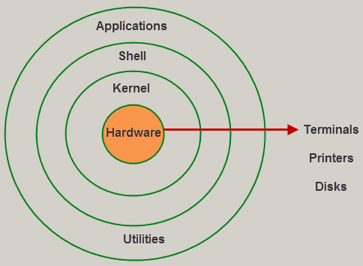
Fig 4: Linux architecture
Features of Linux
Some of the most significant features of the Linux Operating System are mentioned below.
● Portable - Software's portability refers to its ability to run on various types of hardware in the same way. The Linux kernel and application programs can be installed on virtually any hardware platform.
● Open Source - Linux is a community-based programming project with freely available source code. Multiple teams collaborate to improve the capabilities of the Linux operating system, which is constantly changing.
● Multi-User - Linux is a multiuser system, which means that multiple users can share system resources such as memory, ram, and application programs.
● Multiprogramming - Linux is a multiprogramming method, which means it can run several programs at the same time.
● Hierarchical File System - System files and user files are organized in a common file structure in Linux.
● Shell - Linux has a special interpreter program that can be used to run operating system commands. It can be used to perform a variety of tasks, such as calling application programs.
● Security - User security is provided by Linux by authentication features such as password protection, restricted access to sensitive files, and data encryption.
Q7) Explain mass storage structure?
A7) A broad review of secondary and tertiary storage devices' physical structures.
Magnetic Disks
Magnetic disks make up the majority of secondary storage in today's computers. Disks are a rather straightforward concept. Each disk platter is shaped like a CD and has a flat circular shape. The diameters of most platters range from 1.8 to 5.25 inches. A magnetic substance is applied to the two surfaces of a platter. We keep information on platters by recording it magnetically.
Every platter has a read-write head that "flies" slightly over the surface. The heads are connected to a disk arm that moves all of them together. A platter's surface is divided logically into circular tracks, which are further separated by sectors. A cylinder is formed by a set of tracks in one arm position. A disk drive can have thousands of concentric cylinders, with each track containing hundreds of sectors. Gigabytes are the unit of measurement for the storage capacity of popular disk drives. A drive motor rotates the disk at a high speed when it is in use.
The majority of drives revolve at a rate of 60 to 200 times per second. There are two aspects to disk speed. The transfer rate is the speed at which data is transferred from the hard drive to the computer. The seek time, also known as the random-access time, is the time it takes for the disk arm to travel to the requested cylinder, while the rotational latency is the time it takes for the desired sector to rotate to the disk head. Typical drives have search times and rotational latencies of several milliseconds and can transport several megabytes of data per second. The disk head flies on an incredibly thin cushion of air (measured in microns), thus there's a chance it'll collide with the disk surface.

Fig 5: Moving head disk mechanism
Magnetic Tapes
Magnetic tape was employed as a supplemental storage media in the early days. Although it is very permanent and capable of storing vast amounts of data, it has a slow access time when compared to main memory and magnetic disk. Furthermore, because random access to magnetic tape is a thousand times slower than random access to magnetic disk, tapes are ineffective as supplementary storage. Tapes are mostly used for backup, archiving infrequently used data, and transferring data from one system to another. A tape is wound or rewound past a read-write head and retained on a spool.
It can take minutes to get to the right point on a tape, but once there, tape drives can write data at speeds comparable to disk drives. Tape capacity varies substantially depending on the type of tape drive used. They typically store 20 GB to 200 GB of data. Some come with built-in compression, which can more than double the amount of storage available. Tapes and their drivers are often divided into four width categories: 4, 8, and 19 milli meters, as well as 1/4 and 1/2 inch.
Q8) What is disk scheduling?
A8) As we know, a process needs two type of time, CPU time and IO time. For I/O, it requests the Operating system to access the disk.
However, the operating system must be fair enough to satisfy each request and at the same time, operating system must maintain the efficiency and speed of process execution.
The technique that operating system uses to determine the request which is to be satisfied next is called disk scheduling.
Let's discuss some important terms related to disk scheduling.
Seek Time
Seek time is the time taken in locating the disk arm to a specified track where the read/write request will be satisfied.
Rotational Latency
It is the time taken by the desired sector to rotate itself to the position from where it can access the R/W heads.
Transfer Time
It is the time taken to transfer the data.
Disk Access Time
Disk access time is given as,
Disk Access Time = Rotational Latency + Seek Time + Transfer Time
Disk Response Time
It is the average of time spent by each request waiting for the IO operation.
Purpose of Disk Scheduling
The main purpose of disk scheduling algorithm is to select a disk request from the queue of IO requests and decide the schedule when this request will be processed.
Goal of Disk Scheduling Algorithm
● Fairness
● High throughout
● Minimal traveling head time
Disk Scheduling Algorithms
The list of various disks scheduling algorithm is given below. Each algorithm is carrying some advantages and disadvantages. The limitation of each algorithm leads to the evolution of a new algorithm.
● FCFS scheduling algorithm
● SSTF (shortest seek time first) algorithm
● SCAN scheduling
● C-SCAN scheduling
● LOOK Scheduling
● C-LOOK scheduling
FCFS Scheduling Algorithm
It is the simplest Disk Scheduling algorithm. It services the IO requests in the order in which they arrive. There is no starvation in this algorithm, every request is serviced.
Disadvantages
● The scheme does not optimize the seek time.
● The request may come from different processes therefore there is the possibility of inappropriate movement of the head.
Example
Consider the following disk request sequence for a disk with 100 tracks 45, 21, 67, 90, 4, 50, 89, 52, 61, 87, 25
Head pointer starting at 50 and moving in left direction. Find the number of head movements in cylinders using FCFS scheduling.
Solution
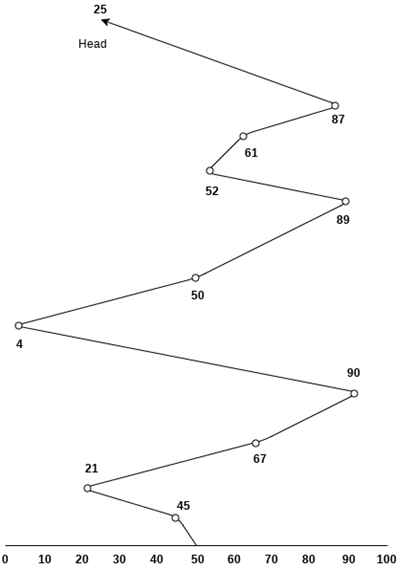
Number of cylinders moved by the head
= (50-45) +(45-21) +(67-21) +(90-67) +(90-4) +(50-4) +(89-50) +(61-52) +(87-61) +(87-25)
= 5 + 24 + 46 + 23 + 86 + 46 + 49 + 9 + 26 + 62
= 376
SSTF Scheduling Algorithm
Shortest seek time first (SSTF) algorithm selects the disk I/O request which requires the least disk arm movement from its current position regardless of the direction. It reduces the total seek time as compared to FCFS.
It allows the head to move to the closest track in the service queue.
Disadvantages
● It may cause starvation for some requests.
● Switching direction on the frequent basis slows the working of algorithm.
● It is not the most optimal algorithm.
Example
Consider the following disk request sequence for a disk with 100 tracks
45, 21, 67, 90, 4, 89, 52, 61, 87, 25
Head pointer starting at 50. Find the number of head movements in cylinders using SSTF scheduling.
Solution:
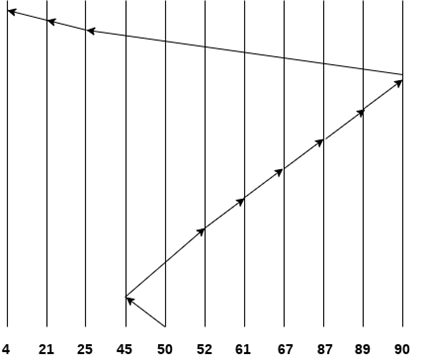
Number of cylinders = 5 + 7 + 9 + 6 + 20 + 2 + 1 + 65 + 4 + 17 = 136
SCAN and C-SCAN algorithm
Scan Algorithm
It is also called as Elevator Algorithm. In this algorithm, the disk arm moves into a particular direction till the end, satisfying all the requests coming in its path and then it turns back and moves in the reverse direction satisfying requests coming in its path.
It works in the way an elevator works, elevator moves in a direction completely till the last floor of that direction and then turns back.
Example
Consider the following disk request sequence for a disk with 100 tracks
98, 137, 122, 183, 14, 133, 65, 78
Head pointer starting at 54 and moving in left direction. Find the number of head movements in cylinders using SCAN scheduling.
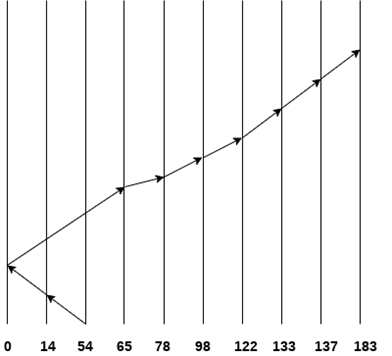
Number of Cylinders = 40 + 14 + 65 + 13 + 20 + 24 + 11 + 4 + 46 = 237
C-SCAN algorithm
In C-SCAN algorithm, the arm of the disk moves in a particular direction servicing requests until it reaches the last cylinder, then it jumps to the last cylinder of the opposite direction without servicing any request then it turns back and start moving in that direction servicing the remaining requests.
Example
Consider the following disk request sequence for a disk with 100 tracks
98, 137, 122, 183, 14, 133, 65, 78
Head pointer starting at 54 and moving in left direction. Find the number of head movements in cylinders using C-SCAN scheduling.
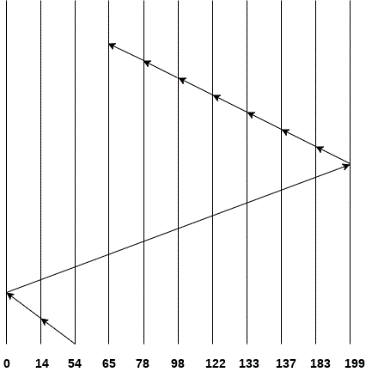
No. Of cylinders crossed = 40 + 14 + 199 + 16 + 46 + 4 + 11 + 24 + 20 + 13 = 387
Q9) Describe disk management?
A9) Several additional areas of disk management are also handled by the operating system. We'll go over disk startup, booting from disk, and bad-block recovery.
Disk formatting
A new magnetic disk is essentially a blank slate: it is nothing more than a platter of magnetic recording material. A disk must first be partitioned into sectors that the disk controller can read and write before it can store data. Low-level formatting, often known as physical formatting, is the term for this procedure. Low-level formatting creates a unique data structure for each sector on the drive. A sector's data format normally includes a header, a data section (usually 512 bytes in size), and a trailer.
The disk controller uses the header and trailer to store information like a sector number and an error-correcting code (ECC). The ECC is updated with a value calculated from all the bytes in the data area when the controller writes a sector of data during regular I/O. The ECC is recalculated and compared to the stored value when the sector is read. If the stored and calculated values differ, this indicates that the sector's data region has gotten corrupted and that the disk sector may be faulty.
When a disk is formatted with a bigger sector size, fewer sectors can fit on each track, but fewer headers and trailers are written on each track, leaving more space for user data.
Only 512-byte sectors are supported by some operating systems. The operating system must still record its own data structures on the disk in order to utilize it as a storage medium for files. It accomplishes this in two phases. Partitioning the disk into one or more groups of cylinders is the initial stage. Each partition can be treated as a separate disk by the operating system. One partition might include a copy of the operating system's executable code, while another might contain user files.
Boot Block
A computer must have an initial program to run before it can start running, such as when it is turned on or rebooted. This initial bootstrap software is usually straightforward. It begins the operating system after initializing all parts of the system, from CPU registers to device controllers and the contents of main memory. The bootstrap software does its work by looking for the operating system kernel on disk, loading it into memory, and jumping to a beginning address to start the operating system.
The bootstrap is stored in read-only memory on most systems (ROM). This position is convenient since ROM requires no startup and is located in a fixed area where the CPU may begin executing immediately after being powered on or reset. ROM can't be infected by a computer virus because it's read-only. The issue is that replacing the bootstrap code necessitates replacing the ROM and hardware chips.
As a result, most systems include a small bootstrap loader program in the boot ROM whose sole purpose is to load a full bootstrap program from disk. The entire bootstrap software can be easily changed: The disk is simply written with a new version. The complete bootstrap program is stored in a defined area on the disk called "the boot blocks." A disk that has a boot partition is called a boot disk or system disk.
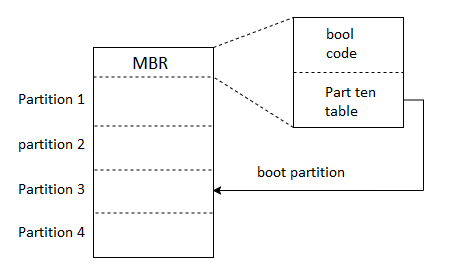
Fig 6: Booting from disk in windows 2000.
The boot ROM code tells the disk controller to read the boot blocks into memory (no device drivers are installed yet) and then begin executing that code. The full bootstrap program is more advanced than the boot ROM's bootstrap loader; it can load the entire operating system from a non-fixed location on disk and start it up. Despite this, the complete bootstrap code may be minimal.
Bad Blocks
Disks are prone to failure because they feature moving parts and narrow tolerances (recall that the disk head flies barely above the disk surface). When a disk fails completely, it must be replaced and the contents must be restored from backup media to the new disk. One or more sectors are more commonly faulty. Most disks have faulty blocks right out of the box. These blocks are handled in a variety of ways depending on the disk and controller in use. Bad blocks are manually handled on simple disks, such as some disks using [DE controllers. For example, the MS-DOS format command conducts logical formatting and examines the disk for faulty blocks as part of the process.
Format adds a special value into the corresponding FAT entry if it identifies a faulty block, telling the allocation procedures not to utilize that block. If blocks get corrupted during regular operation, a special application (such as chkdsk) must be run manually to locate the corrupted blocks and lock them away as before. The data stored on the faulty blocks is frequently lost.
SCSI drives, which are found in high-end PCs as well as most workstations and servers, are more intelligent when it comes to bad-block recovery. A list of defective blocks on the disk is kept by the controller. The list is created during the factory's low-level formatting and is updated during the disk's life.
The following is an example of a bad-sector transaction: Logic block 87 is attempted to be read by the operating system. The controller performs an ECC calculation and determines that the sector is defective. It informs the operating system of this discovery. A special command is run the next time the system is rebooted to notify the SCSI controller to replace the defective sector with a spare. After that, anytime the system asks logical block 87, the controller converts the request into the address of the new sector.
Q10) Explain the I/O system?
A10) File system is the part of the operating system which is responsible for file management. It provides a mechanism to store the data and access to the file contents including data and programs. Some Operating systems treats everything as a file for example Ubuntu.
The File system takes care of the following issues
● File Structure
We have seen various data structures in which the file can be stored. The task of the file system is to maintain an optimal file structure.
● Recovering Free space
Whenever a file gets deleted from the hard disk, there is a free space created in the disk. There can be many such spaces which need to be recovered in order to reallocate them to other files.
● disk space assignment to the files
The major concern about the file is deciding where to store the files on the hard disk. There are various disks scheduling algorithm which will be covered later in this tutorial.
● tracking data location
A File may or may not be stored within only one block. It can be stored in the non-contiguous blocks on the disk. We need to keep track of all the blocks on which the part of the files resides.
File System provide efficient access to the disk by allowing data to be stored, located and retrieved in a convenient way. A file System must be able to store the file, locate the file and retrieve the file.
Most of the Operating Systems use layering approach for every task including file systems. Every layer of the file system is responsible for some activities.
The image shown below, elaborates how the file system is divided in different layers, and also the functionality of each layer.
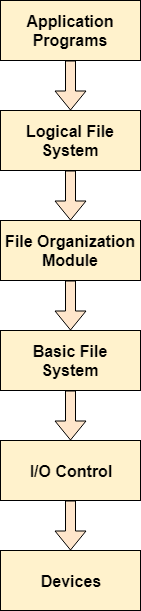
Fig 7 – File system layers
● When an application program asks for a file, the first request is directed to the logical file system. The logical file system contains the Meta data of the file and directory structure. If the application program doesn't have the required permissions of the file, then this layer will throw an error. Logical file systems also verify the path to the file.
● Generally, files are divided into various logical blocks. Files are to be stored in the hard disk and to be retrieved from the hard disk. Hard disk is divided into various tracks and sectors. Therefore, in order to store and retrieve the files, the logical blocks need to be mapped to physical blocks. This mapping is done by File organization module. It is also responsible for free space management.
● Once File organization module decided which physical block the application program needs, it passes this information to basic file system. The basic file system is responsible for issuing the commands to I/O control in order to fetch those blocks.
● I/O controls contain the codes by using which it can access hard disk. These codes are known as device drivers. I/O controls are also responsible for handling interrupts.
Q11) What do you mean by system protection and security?
A11) The various approaches that may provide protection and security for various computer systems are as follows:
Authentication
This is the process of identifying each user in the system and verifying that they are who they say they are. Before any user may access the system, the operating system ensures that they have been authenticated. The following are some of the methods for ensuring that users are genuine:
Username / password - Each user has a unique username and password combination that they must successfully enter in order to gain access to the system.
User key / user card - To get access to the system, users must punch a card into a slot or use an individual key on a keypad.
User attribute identification - Fingerprint, ocular retina, and other user attributes can be used to identify users. These are unique to each user and are compared to the database's current samples. If there is a match, the user can access the system.
One time password
These passwords offer a high level of authentication security. Every time a user wants to log into the system, a one-time password can be generated exclusively for that login. It's not possible to utilize it more than once. A one-time password can be implemented in a variety of ways.
Random number s- The system can ask for integers that correlate to pre-arranged alphabets. Each time a login is required, this combination can be modified.
Secret key
A hardware device can create a secret key related to the user id for login. This key can change each time.




