Unit - 5
Distributed Systems
Q1) What is a distributed system?
A1) The structure illustrated in fig comprises a collection of individual computer systems and workstations connected by communication systems, but we can't call it a distributed system because whether a system is distributed or not is determined by the software, not the hardware.
Users of a properly distributed system should have no idea where their files are kept or on which machine their programs are operating. The best examples of distributed operating systems are LOCUS and MICROS.
It was able to access local and remote files in a consistent manner using the LOCUS operating system. This feature allowed a user to log on to any network node and access the network's resources without revealing his or her location. MICROS allows for resource sharing to be done automatically. To balance the load on different nodes, the jobs were assigned to different nodes throughout the system.
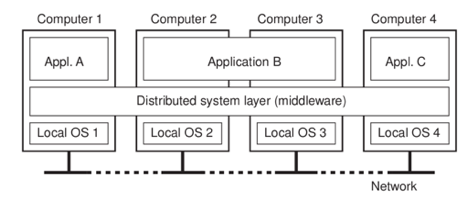
Fig 1: Distributed system
Distributed systems provide the following advantages:
1 Sharing of resources.
2 Reliability.
3 Communication.
4 Computation speedup
Because a system with only one instance of a vital component, such as a CPU, disk, or network interface, will go down if that component fails, distributed systems are potentially more reliable than central systems. When there are several instances, the system may be able to keep running even if some of them fail. Software failures might be considered in addition to hardware failures. Both hardware and software failures can be handled in distributed systems.
A distributed system is a collection of computers that communicate and work with one another via software and hardware components. Multiprocessors (MIMD computers with shared memory architecture), multi-computers connected via static or dynamic interconnection networks (MIMD computers with message passing architecture), and workstations connected via local area network are all instances of distributed systems.
A distributed operating system is in charge of managing a distributed system. A distributed operating system controls system shared resources used by many processes, process scheduling (how processes allocate processors), communication and synchronization among running processes, and so on. Parallel computer software can be either tightly coupled or loosely coupled. Loosely connected software allows computers and users in a distributed system to be autonomous from one another while still having limited opportunities to collaborate. A set of computers connected by a local network is an example of such a system. Every computer has its own hard disk and memory.
Q2) Explain distributed operating system?
A2) Distributed systems use multiple central processors to serve multiple real-time applications and multiple users. Data processing jobs are distributed among the processors accordingly.
The processors communicate with one another through various communication lines (such as high-speed buses or telephone lines). These are referred to as loosely coupled systems or distributed systems. Processors in a distributed system may vary in size and function. These processors are referred to as sites, nodes, computers, and so on.
A distributed operating system (DOS) is a concept in which distributed programs execute on numerous machines that are connected by communications. A distributed operating system is an extension of the network operating system that allows devices on the network to communicate and integrate at higher levels.
This system seems to users to be a standard centralized operating system, but it is actually made up of several independent central processing units (CPUs).
Loosely linked systems are those in which each CPU has its own local memory and processors communicate with one another via a variety of communication channels, such as high-speed buses or telephone lines. Loosely coupled systems are computers that have no hardware connections at the CPU–memory bus level, but are connected via external interfaces that are controlled by software.
The Distributed Operating System is made up of a group of independent computer systems that may communicate and collaborate with one another through a LAN or WAN. A Distributed OS provides its users with a virtual machine abstraction and broad resource sharing, such as computing capacity, I/O, and files.
Q3) Write the advantages of distributed systems?
A3) Advantages
The advantages of distributed systems are as follows −
● With a resource sharing facility, a user at one site may be able to use the resources available at another.
● Speedup the exchange of data with one another via electronic mail.
● If one site fails in a distributed system, the remaining sites can potentially continue operating.
● Better service to the customers.
● Reduction of the load on the host computer.
● Reduction of delays in data processing.
Q4) Describe distributed file systems?
A4) A Distributed File System (DFS) is a file system that is distributed among numerous file servers or locations, as the name implies. It enables programs to access and store isolated data in the same way that they access and save local files, allowing programmers to access files from any network or computer.
The Dispersed File System (DFS) is a file system that allows users of physically distributed systems to exchange data and resources using a common file system. A configuration on a Distributed File System is a group of workstations and mainframes connected by a Local Area Network (LAN). A DFS is a type of file system that runs as part of the operating system. In DFS, a namespace is created and this process is transparent for the clients.
Components of distributed file system
DFS has 2 components:
- Location Transparency - The namespace component is used to achieve location transparency.
- Redundancy - A file replication component provides redundancy.
These components work together to increase data availability in the event of failure or high demand by allowing data from multiple places to be logically combined under one folder, known as the "DFS root."
It is not required to utilize both components of DFS at the same time; the namespace component can be used without the file replication component, and the file replication component can be used without the namespace component across servers.
Features
● High availability: Any partial failures, such as a link failure, a node failure, or a storage device crash, should not prevent a Distributed File System from continuing.
Diverse and independent file servers should control different and independent storage devices in a highly authentic and adaptive distributed file system.
● Scalability: The distributed system will surely increase over time when more machines are added to the network or two networks are joined together. As a result, a successful distributed file system should be designed to scale rapidly as the system's number of nodes and users grows. As the number of nodes and users rises, the service should not be significantly affected.
● High reliability: In a good distributed file system, the risk of data loss should be minimized as much as possible. Users should not feel compelled to make backup copies of their files due to the system's instability. Instead, a file system should make backup copies of important files that may be used in the event that the originals are lost. As a high-reliability method, many file systems use stable storage.
● Data integrity: A file system is commonly shared by multiple users. The file system must ensure the integrity of data saved in a shared file. That is, a concurrency control technique must correctly synchronize concurrent access requests from numerous users who are competing for access to the same file. A file system commonly provides users with atomic transactions, which are a high-level concurrency control method for data integrity.
● Security: As a result of their massive scale, heterogeneity in distributed systems is unavoidable. Users of heterogeneous distributed systems can choose from a variety of computer platforms for various tasks.
● Performance: The average amount of time it takes to persuade a client is used to determine performance. This time includes CPU time, secondary storage access time, and network access time. The performance of the Distributed File System should be comparable to that of a centralized file system.
● Simplicity and ease of use: A file system's user interface should be straightforward, and the amount of commands in the file should be limited.
Q5) Write the advantages and disadvantages of a distributed file system?
A5) Advantages
● Data can be accessed or stored by numerous users using DFS.
● It enables data to be shared through the internet.
● It increased file accessibility, access time, and network efficiency.
● The ability to adjust the amount of data as well as the ability to interchange data has been improved.
● Even if a server or disk fails, the data is transparent because to the Distributed File System.
Disadvantages
● Because nodes and connections in a Distributed File System must be safeguarded, we can state that security is at risk.
● While moving from one node to another, there is a chance that messages and data will be lost in the network.
● In the case of a Distributed File System, the database connection is difficult.
● In addition, in a Distributed File System, database management is more difficult than in a single user system.
● If all nodes try to communicate data at the same time, there is a danger of overloading.
Q6) Write about distributed synchronization?
A6) A distributed system is a group of computers that are linked together by a high-speed communication network. Message passing allows the hardware and software components in a distributed system to interact and coordinate their operations. In distributed systems, each node can share its resources with other nodes. As a result, efficient resource allocation is required to maintain the status of resources and to aid coordination between the various operations. Synchronization is employed to address such issues. Clocks are used in distributed systems to achieve synchronization.
The time of nodes is adjusted using hardware clocks. Each node in the system has the ability to share its local time with other nodes. UTC is used to set the time (Universal Time Coordination). The nodes in the system use UTC as their reference time clock.
External and internal clock synchronization are two methods for achieving clock synchronization.
- External clock synchronization refers to the use of an external reference clock. It serves as a point of reference, and the system's nodes can set and alter their time accordingly.
- Internal clock synchronization occurs when each node shares its time with other nodes and everyone sets and adjusts their clocks accordingly.
Clock synchronization algorithms are divided into two categories: centralized and distributed.
● Centralized - A centralized system is one that uses a time server as a reference. The time is propagated to the nodes by a single time server, and all nodes change their clocks accordingly. It is reliant on a single time server, therefore if one node fails, the entire system will be out of sync. Berkeley Algorithm, Passive Time Server, Active Time Server, and other centralized algorithms are examples.
● Distributed - The term "distributed" refers to the absence of a centralized time server. Instead, the nodes update their time by first utilizing their local time and then averaging the time disparities with other nodes. Distributed algorithms solve centralized algorithms' scalability and single point failure problems. Global Averaging Algorithm, Localized Averaging Algorithm, NTP (Network Time Protocol), and other distributed algorithms are examples.




