Unit – 4
Run Time Environment
Q1) What is a storage organization?
A1) Storage Organization
● When the target program executes then it runs in its own logical address space in which the value of each program has a location.
● The logical address space is shared among the compiler, operating system and target machine for management and organization. The operating system is used to map the logical address into a physical address which is usually spread throughout the memory.
Subdivision of Run-time Memory:
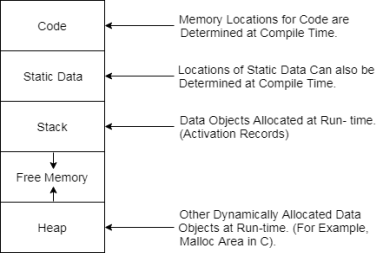
Fig: run time memory
● Runtime storage comes into blocks, where a byte is used to show the smallest unit of addressable memory. Using the four bytes a machine word can form. Object of multibyte is stored in consecutive bytes and gives the first byte address.
● Run-time storage can be subdivided to hold the different components of an executing program:
Q2) Explain static and dynamic storage allocation?
A2) Static storage allocation
● In static allocation, names are bound to storage as the program is compiled, so there is no need for a run-time support package.
● Since the bindings do not change at run time, every time a procedure is activated, its names are bound to the same storage locations.
● The above property allows the values of local names to be retained across activations of a procedure. That is, when control returns to a procedure, the values of the locals are the same as they were when control left the last time.
● From the type of a name, the compiler determines the amount of storage to set aside for that name.
● The address of this storage consists of an offset from an end of the activation record for the procedure.
● The compiler must eventually decide where the activation records go, relative to the target code and to one another.
Limitation of Static Allocation
● The size of a data object and constraints on its position in memory must be known at compile time.
● Recursive procedures are restricted, because all activations of a procedure use the same bindings for local names.
● Dynamic allocation is not allowed. so, data structures cannot be created dynamically.
Dynamic memory allocation
● The techniques needed to implement dynamic storage allocation mainly depends on how the storage is deallocated.
● If deallocation is implicit, then the run-time support package is responsible for determining when a storage block is no longer needed.
● There is less a compiler has to do if deallocation is done explicitly by the programmer.
Q3) Write about stack allocation?
A3) Stack allocation
● Stack allocation is based on the idea of a control slack.
● A stack is a Last In First Out (LIFO) storage device where new storage is allocated and deallocated at only one end'', called the top of the stack.
● Storage is organized as a stack, and activation records are pushed and popped as activations begin and end, respectively.
● Storage for the locals in each call of a procedure is contained in the activation record for that call. Thus, locals are bound to fresh storage in each activation, because a new activation record is pushed onto the stack when a call is made.
● Furthermore, the values of locals are detected when the activation ends. that is, the values are lost because the storage for locals disappears when the activation record is popped.
● At run time, an activation record can be allocated and de-allocated by incrementing and decrementing the top of the stack respectively.
Q4) What are activation records?
A4) Activation records
● Control stack is a run time stack which is used to keep track of the live procedure activations i.e., it is used to find out the procedures whose execution have not been completed.
● When it is called (activation begins) then the procedure name will push on to the stack and when it returns (activation ends) then it will be popped.
● Activation record is used to manage the information needed by a single execution of a procedure.
● An activation record is pushed into the stack when a procedure is called and it is popped when the control returns to the caller function.
The diagram below shows the contents of activation records:
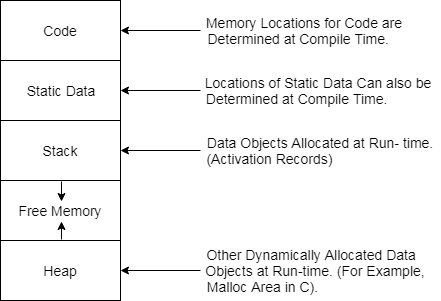
Fig: activation records
● Return Value: It is used by calling procedure to return a value to calling procedure.
● Actual Parameter: It is used by calling procedures to supply parameters to the called procedures.
● Control Link: It points to the activation record of the caller.
● Access Link: It is used to refer to non-local data held in other activation records.
● Saved Machine Status: It holds the information about the status of the machine before the procedure is called.
● Local Data: It holds the data that is local to the execution of the procedure.
● Temporaries: It stores the value that arises in the evaluation of an expression.
Q5) Define Syntax Directed Definitions (SDD)?
A5) Syntax Directed Definitions (SDD)
A Syntax Driven Description (SDD) is a context-free grammar generalization in which each grammar symbol has an associated collection of attributes, divided into two subsets of that grammar symbol's synthesized and inherited attributes.
An attribute may represent a string, a number, a type, a position in the memory, or something. A semantic rule associated with the output used on that node determines the value of an attribute at a parse-tree node.
Types of Attributes: Attributes are grouped into two kinds:
1. Synthesized Attributes: These are the attributes that derive their values from their child nodes, i.e., the synthesized attribute value at the node is determined from the attribute values at the child nodes in the parse tree.
Example
E --> E1 + T {E.val = E1.val + T.val}
● Write the SDD using applicable semantic rules in the specified grammar for each production.
● The annotated parse tree is created and bottom-up attribute values are computed.
● The final output will be the value obtained at the root node.
Considering the above example:
S --> E
E --> E1 + T
E --> T
T --> T1 * F
T --> F
F --> digit
You can write the SDD for the above grammar as follows:
Production | Semantic Action |
S --> E | Print (E.val) |
E --> E1 + T | E.val = E1.val + T.val |
E --> T | E.val = T. val |
T --> T1 * F | T. val = T1.val * F. val |
T --> F | T. val = F. val |
F --> digit | F. val = digit.lexval |
For arithmetic expressions, let us consider the grammar. The Syntax Directed Description associates a synthesized attribute, called val, to each non-terminal. The semantic rule measures the value of the non-terminal attribute val on the left side of the non-terminal value on the right side of the attribute val.
2. Inherited Attributes: These are the attributes derived from their parent or sibling nodes by their values, i.e., the value of the inherited attributes is determined by the parent or sibling node value.
Example
A --> BCD {C.in = A.in, C. type = B. type}
● Using semantic behaviour, create the SDD.
● The annotated parse tree is created and the values of attributes are computed top-down.
Consider the grammar below
S --> T L
T --> int
T --> float
T --> double
L --> L1, id
L --> id
You can write the SDD for the above grammar as follows:
Production | Semantic Action |
S --> T L | L.in = T.type |
T --> int | T.type = int |
T --> float | T.type = float |
T --> double | T.type = double |
L --> L1, id | L1.in = L.in Enter_type(id.entry, L.in) |
L --> id | Entry _type(id.entry, L.in) |
Q6) What are Synthesized Attributes?
A6) Synthesized attributes
An attribute of a nonterminal on the right-hand side of a production is called an inherited attribute. The attribute can take value either from its parent or from its siblings (variables in the LHS or RHS of the production).
For example, let’s say A -> BC is a production of a grammar and B’s attribute is dependent on A’s attributes or C’s attributes then it will be an inherited attribute.
Synthesized Attributes
A Synthesized attribute is an attribute of the non-terminal on the left-hand side of a production. Synthesized attributes represent information that is being passed up the parse tree. The attribute can take value only from its children (Variables in the RHS of the production).
For eg. let’s say A -> BC is a production of a grammar, and A’s attribute is dependent on B’s attributes or C’s attributes then it will be a synthesized attribute.
Q7) Explain dependency graphs?
A7) Dependency graph
A dependency graph depicts the flow of information among the attribute instances in a particular parse tree; an edge from one attribute instance to another means that the value of the first is needed to compute the second. Edges express constraints implied by the semantic rules. In more detail:
Since a node N can have several children labeled X, we again assume that subscripts distinguish among uses of the same symbol at different places in the production.
Q8) What are the evaluation orders for SDD?
A8) Evaluation orders for SDD
Dependency graphs" are a useful tool for determining an evaluation order for the attribute instances in a given parse tree. While an annotated parse tree shows the values of attributes, a dependency graph helps us determine how those values can be computed.
Ordering the evaluation
The dependency graph characterizes the possible orders in which we can evaluate the attributes at the various nodes of a parse tree. If the dependency graph has an edge from node M to node N, then the attribute corresponding to M must be evaluated before the attribute of N. Thus, the only allowable orders of evaluation are those sequences of nodes N1, N2, ………, Nk such that if there is an edge of the dependency graph from Ni to Nj then i < j. Such an ordering embeds a directed graph into a linear order, and is called a topological sort of the graph.
If there is any cycle in the graph, then there are no topological sorts; that is, there is no way to evaluate the SDD on this parse tree. If there are no cycles, however, then there is always at least one topological sort. To see why, since there are no cycles, we can surely find a node with no edge entering.
For if there were no such nodes, we could proceed from predecessor to predecessor until we came back to some node we had already seen, yielding a cycle. Make this node the first in the topological order, remove it from the dependency graph, and repeat the process on the remaining nodes.
Q9) Write about semantic rules?
A9) Semantic rules
The plain parse-tree constructed in that phase is generally of no use for a compiler, as it does not carry any information of how to evaluate the tree. The productions of context-free grammar, which makes the rules of the language, do not accommodate how to interpret them.
For example
E → E + T
The above CFG production has no semantic rule associated with it, and it cannot help in making any sense of the production.
Semantics
Semantics of a language provide meaning to its constructs, like tokens and syntax structure. Semantics help interpret symbols, their types, and their relations with each other. Semantic analysis judges whether the syntax structure constructed in the source program derives any meaning or not.
CFG + semantic rules = Syntax Directed Definitions
For example:
int a = “value”;
should not issue an error in lexical and syntax analysis phase, as it is lexically and structurally correct, but it should generate a semantic error as the type of the assignment differs. These rules are set by the grammar of the language and evaluated in semantic analysis.
The following tasks should be performed in semantic analysis:
● Scope resolution
● Type checking
● Array-bound checking
Q10) Write the application of Syntax Directed Translation?
A10) Syntax Directed Translation
● SDT is used for Executing Arithmetic Expression.
● In the conversion from infix to postfix expression.
● In the conversion from infix to prefix expression.
● It is also used for Binary to decimal conversion.
● In counting the number of Reduction.
● In creating a Syntax tree.
● SDT is used to generate intermediate code.
● In storing information into a symbol table.
● SDT is commonly used for type checking also.
Example
Here, we are going to cover an example of an application of SDT for better understanding the SDT application uses. Let's consider an example of arithmetic expression and then you will see how SDT will be constructed.
Let’s consider Arithmetic Expression is given
Input: 2+3*4
output: 14
SDT for the above example.

Fig: SDT for 2 +3*4
Semantic Action is given as follows.
E -> E+T {E.val = E.val + T.val then print (E.val)}
|T {E.val = T.val}
T -> T*F {T.val = T.val * F.val}
|F {T.val = F.val}
F -> Id {F.val = id}
Q11) What do you mean by symbol table?
A11) Symbol table
Symbol table is an important data structure used in a compiler.
Symbol table is used to store the information about the occurrence of various entities such as objects, classes, variable name, interface, function name etc. it is used by both the analysis and synthesis phases.
The symbol table used for following purposes:
● It is used to store the name of all entities in a structured form at one place.
● It is used to verify if a variable has been declared.
● It is used to determine the scope of a name.
● It is used to implement type checking by verifying assignments and expressions in the source code are semantically correct.
A symbol table can either be linear or a hash table. Using the following format, it maintains the entry for each name.
<symbol name, type, attribute>
For example, suppose a variable store the information about the following variable declaration:
static int salary
then, it stores an entry in the following format:
<salary, int, static>
The clause attribute contains the entries related to the name.
Q12) What is the structure of the symbol table?
A12) Structure of the symbol table
When judging various data structures, the following should be taken into consideration:
Linear lists
Searching is performed in linear fashion from beginning to end. The search halts as soon as the name you are looking for is found.
Linear lists are easy to implement and require little memory space. Scoping is easily introduced using the LIFO principle. However, search times are unacceptable. Reports have shown that a compiler, which implements symbol tables using linear lists, can spend 25% of compilation time on searching.
Trees
The symbol table can be in the form of a tree; then each subprogram has a symbol table attached to its node in the abstract syntax tree. The main program has a similar table for globally declared objects. The advantage of this structure is that it is easy to represent scoping and is quicker than linear lists.
Hashing
When high demands are made on the search time, hashing is used. Entry to the hash table is calculated using a suitable key transformation. If the symbol is not in the entry, you have to follow the link field. By making the hash table large enough you can control the search time.
Q13) What are scopes?
A13) Scopes
Every name in the source program has a valid region called the scope of that name.
The following are the rules for a block-structured language:
● If a name is declared within block B, it is only valid within that block.
● Unless the name's identifier is re-declared in B1, the name that is valid for block B2 is likewise valid for B1.
● These scope rules necessitate a more complex symbol table arrangement than a set of name-attribute connections.
● Each table has a list of names and their associated properties, and each table is grouped into a stack.
● A new table is added to the stack every time a new block is entered. The name that is designated as local to this block is stored in the new table.
● The table is searched for a name once the declaration is constructed.
● If the name is not found in the table, it is replaced with a new name.
● After the name's reference has been translated, each table in the stack is searched one by one.
For Example
int x;
void f(int m) {
float x, y;
{
int i, j;
int u, v;
}
}
int g (int n)
{
bool t;
}

Fig: Symbol table organization that complies with static scope information rules




