Unit – 4
Security
Q1) What kind of Security Challenges in WSN?
A1)
Challenges of Security in WSN
For several decades, security has been a difficulty in computing systems and networks, during which time the sorts of attacks, as well as the security measures and processes to resist them, have improved and expanded greatly, owing in part to the Internet's rapid growth.
While compared to standard Internet attacks and security methods, WSNs present a number of unique issues that must be taken into account when resolving security concerns in sensor network applications:
- Resource constraints:
Traditional security techniques, which have substantial overheads, are unsuitable for WSNs with little resources. Many security techniques are computationally expensive or necessitate contact with other nodes or "remote" devices (for example, for permission purposes), resulting in energy consumption.
The amount of memory and storage accessible to small sensor devices is similarly limited. Common sensor devices have very minimal memory; for example, TelosB devices have only 10 kbytes of RAM and 48 kbytes of flash memory. Traditional security algorithms, which necessitate a large amount of memory and storage space, are thus unsuitable for such sensors.
2. Lack of central control:
Because of their huge scale, resource limits, and network dynamics, it is generally impossible to establish a central point of control in sensor networks (topology changes, network partitioning). As a result, decentralized security methods should be used, and nodes must work together to accomplish security.
3. Remote location:
Only allow controlled physical access to a sensor node as a first line of defense against security assaults. Many WSNs are left unattended because they are run in remote and difficult-to-reach places, deployed in open environments with public access, or are so large that constant monitoring and protection of sensor nodes would be impossible.
4. Error-prone communication:
Packets in wireless sensor networks (WSNs) can be lost or corrupted for a variety of causes, including channel faults, routing failures, and collisions. Some security systems, as well as their capacity to gather critical event reports, may be hampered as a result. Furthermore, it may be difficult to distinguish between "harmless" erroneous communications or node and connection failures and malicious assaults as a result of this.
On the other side, certain aspects of sensor networks make security easier to provide. A WSN's ability to self-manage and self-repair, for example, may allow it to continue to function even if a sensor or entire portions of the sensor network have been hacked.
A sensor network's redundancy allows it to collect data about events in the environment even if certain sensors are unavailable due to an attack. This redundancy can also be utilized to identify, isolate, and hide possibly compromised nodes.
Q2) Explain Security Attacks in Sensor Networks?
A2)
Security Attacks in Sensor Networks
Sensor networks are vulnerable to a range of attacks aimed at compromising the network's functionality and the data generated by the sensor nodes. Sensor networks, in particular, need to be protected from illegal access and alteration when they are used for applications like battlefield evaluations and civil infrastructure monitoring.
Denial-of-Service
A Denial-of-Service (DoS) assault is an attempt by an adversary to prevent a network from functioning or to impair the services provided by a network. DoS attacks in wireless sensor networks can occur at different layers of the protocol stack, with some affecting many layers at once or attempting to exploit interconnections between them.
● Physical Layer DoS
A WSN's wireless media supports a number of assaults. When an opponent interferes with a WSN's radio frequency, it is called a jamming attack. Even though the number of attacking nodes is far fewer than the number of nodes in the network, a few well-positioned attacking nodes can disable an entire network.
Even a single attacking node can disable a whole network if it is located near a "important" node (e.g., a gateway, preventing any sensor data from leaving the sensor network) or if its transmission power is high enough to prevent all nodes in the network from receiving any relevant data. Spread-spectrum communication, as found in well-known standards like IEEE 802.11 and Bluetooth, is a typical strategy for avoiding jamming.
● Link Layer DoS
In some MAC systems, a collision attack at the link layer attempts to interfere with packet transmissions, resulting in costly exponential backoff processes and retransmissions.
While error-correcting codes can be used to recover from corrupted bits in a packet, they may not be able to recover from all forms of interference (for example, if too many bits are affected), and they come at a cost in terms of resources and energy. An attacker might potentially try to generate collisions near the end of a frame, forcing a node to retransmit the complete packet multiple times. An attacker's purpose could be to cause the node's energy resources to be depleted prematurely (exhaustion attack)
Attacks on Routing
The blackhole attack is an example of a sensor network routing protocol attack.
An adversary tries to be a data forwarder for one or more routes across the network in this type of attack. A rogue node can then simply drop all communication that is supposed to flow through it, ensuring that it never reaches its intended destination.
A comparable approach is the selective forwarding attack, which drops just packets that meet certain criteria rather than all packets indiscriminately. Because they are harder to distinguish from packet losses due to mobility or channel faults, selective forwarding attacks are more difficult to detect or respond to than blackhole attacks.
The nature of the route discovery mechanism of on-demand routing protocols, such as AODV and DSR, is exploited in a rushing attack on a sensor network. In this sort of attack, a rogue node forwards inbound route request messages to its neighbors without considering any protocol requirements, thus "rushing" the messages (e.g. That specify certain timeouts or queuing procedures before forwarding). As a result, the node has a higher chance of being included in the chosen path between source and destination.
Attacks on Transport Layer
The transport layer of the network protocol stack is in charge of managing end-to-end connections; for example, Transmission Control Protocol (TCP) for reliable stream-based communication and User Datagram Protocol (UDP) for unreliable packet-based communication are two well-known transport layer protocols. The flooding attack takes advantage of the fact that many transport protocols, including TCP, keep state information and are thus subject to memory exhaustion.
An attacker may, for example, submit new connection requests repeatedly, each one sending more state information to the vulnerable node and potentially causing the node to refuse further connections owing to resource depletion. This, in turn, stops genuine node connection requests from succeeding.
Attacks on Data Aggregation
To merge multiple sensor data and reduce redundant information, data aggregation and data fusion are frequently utilized. Aggregation can often reduce the frequency of transmissions or the size of packets, which can help reduce the resource requirements of sensor flows. Even simple aggregation functions can be easily manipulated by an attacker to change the behavior of a network.
For example, the average function f (x1,...,xn) = (x1 +···+ xn)/n is insecure even in the presence of a single malicious node. By replacing one real measurement x1 with a fake reading x*1 , the average is changed from y = f (x1, ..., xn) to y* = f (x*1 , x2, ..., xn) = y + (x*1 − x1)/n. An attacker has complete control over the value of x*1 and thus the aggregation's outcome.
Privacy Attacks
While the security concerns discussed thus far are mostly aimed at preventing a network from functioning properly, the large amount of data generated in a WSN is also vulnerable to misuse. An adversary may try to gain sensitive information by accessing data stored on a sensor node or by listening in on the network.
Wireless networks' broadcast nature makes it simple to monitor and record communications between nodes, especially when no cryptographic techniques are utilized to safeguard sensor data. Eavesdropping can also be paired with traffic analysis, which an attacker can employ to locate sensor nodes of interest in a network.
Q3) Describe Protocols and Mechanisms for Security?
A3)
Protocols and Mechanisms for Security
A variety of security protocols and other defense mechanisms can be employed to guard against the various possible attacks in a WSN. This examines a number of such protocols and methods, with a focus on their use in sensor networks.
Symmetric and Public Key Cryptography
While public key cryptography can guarantee confidentiality, integrity, and authentication, the computational cost of public key algorithms may limit their usage in resource-constrained sensor networks. Even though implementations of RSA and ECC (elliptic curve cryptography) for resource-constrained sensors exist, symmetric key encryption approaches can be much more resource-efficient, making them the more prevalent choice in WSNs.
The problem of key distribution, which requires both communicating nodes to know the shared symmetric key before they can securely exchange data, is a major shortcoming of symmetric key systems.
Key Management
When resource constraints prevent the use of more complex public key systems, symmetric cryptographic algorithms are the preferred option for sensor networks. However, key management, or the dependable and safe establishment of shared cryptographic keys among surrounding nodes in a WSN, is a major drawback of symmetric cryptography.
The Peer Intermediaries for Key Establishment (PIKE) mechanism, for example, employs sensor nodes as trusted intermediaries for key distribution. Every sensor in this approach has a unique pairwise key that it shares with each of the O(n) other nodes in the network, where n is the number of nodes in the network.
Defenses Against DoS Attacks
In sensor networks, denial-of-service (DoS) attacks are widespread, and efficient techniques to stop or prevent them from spreading throughout the network are required. When a jamming assault is detected or suspected, for example, a sensor network can seek to isolate the damaged area by routing traffic around the network's disabled components.
Spread-spectrum approaches are another way to mitigate the harm caused by jamming attacks. Error-correcting codes (which increase processing and communication overheads) and rate-limiting techniques (which allow a device to ignore requests that could lead to premature energy depletion) can be used at the link layer to combat collision and exhaustion attacks.
At the network layer, message authentication code, or MAC (not to be confused with medium access control), which can be thought of as a cryptographically secure checksum of a message, can be used to prevent spoofing and tampering.
The path-based denial-of-service (PDoS) attack overwhelms nodes in a distant sensor network by flooding a multi-hop end-to-end communication path with replayed packets or randomly inserted packets.
Defenses Against Aggregation Attacks
Many simple aggregating functions, such as sum, minimum, and maximum, are intrinsically unsafe, as previously described. However, there are a number of strategies for strengthening the resilience of aggregating functions, including delayed aggregation and delayed authentication.
The base station is supposed to generate a one-way key chain using a public one-way function F, where Ki = F (Ki +1) in these procedures. Before deployment, each device stores the key K0, where K0 = Fn(K) (i.e., F applied to a secret key n times). The first broadcasts from the base station will then be encrypted with key K1 = F n-1 (K).
As a result, all nodes can compute F (K1) = F (Fn-1(K)) and compare it to K0 = Fn(K). Furthermore, sensor nodes may now decrypt communications that were previously encrypted with K0. Subsequent keys can be revealed in a similar fashion until Kn = K is reached (if more keys are needed, the base station can then start a new sequence).
Defenses Against Routing Attacks
Simple link-layer encryption and authentication with a globally shared key can prevent most assaults from the "outside" of a network. Attacks like selective forwarding and sinkholes aren't viable because the adversary can't join the network.
When networks are attacked from the inside, such as through a compromised node, however, this strategy is useless, and more sophisticated solutions are required.
The identities of sensor nodes can be verified to counter Sybil attacks. For example, each sensor node and a trusted base station may share a unique symmetric key that could be used to authenticate each other's identification. A base station can also limit the number of neighbors a node can have, so that even if a node is hacked, it can only connect with its verified neighbors.
In a rushing attack, a node attempts to position itself on as many routes as possible by exploiting the route discovery process in on-demand routing protocols. However, a combination of defensive measures can be taken to prevent such attacks. Some attackers, for example, may send route requests outside the typical radio broadcast range (e.g., by utilizing high transmission power), preventing following request messages from being affected by the route discovery. Both the sender and receiver of a route request can utilize a secure neighbor detection approach to ensure that the other party is inside the regular transmission range.
Security Protocols for Sensor Networks
The Secure Network Encryption Protocol (SNEP) and a "micro" version of the Timed, Efficient, Streaming, Loss-tolerant Authentication (TESLA) protocol are the two primary contributions of the Security Protocols for Sensor Networks (SPINS) project to guarding against assaults. The SNEP protocol's major purpose is to provide confidentiality, two-party data authentication, and data freshness, whereas TESLA provides data broadcast authentication. It's expected that each node has a shared secret key with the base station.
Q4) What do you mean by Localized Encryption and Authentication Protocol?
A4)
Localized Encryption and Authentication Protocol
The LEAP protocol (Localized Encryption and Authentication System) is a key management protocol for sensor networks that enables in-network processing. The fact that different sorts of communications (e.g., control packets versus data packets) in a sensor network have distinct security requirements is one of the driving forces for this protocol. While authentication may be necessary for all sorts of packets, secrecy may only be required for particular types of messages, and a single keying scheme may not be adequate for achieving these needs (e.g., aggregated sensor readings).
Individual keys, group keys, cluster keys, and pairwise shared keys are the four keying schemes offered by LEAP. Every node in the individual key mechanism has its own unique key that is shared with the base station. If a node needs the base station to authenticate its detected readings, this key is utilized for secret communication or computing message authentication codes. A group key is a globally shared key that the base station uses to send encrypted communications throughout the sensor network. Queries and interests are common instances of such signals.
A cluster key is a shared key that is used to secure local broadcast messages between sensor nodes and their neighbors (e.g., routing control messages). A pairwise shared key, on the other hand, is a key that is shared by a sensor node and one of its immediate neighbors. These keys are used by LEAP to provide secure communication between two nodes, such as allowing a node to safely disseminate its cluster key to its neighbors or securely transfer sensor readings to an aggregate node.
Q5) Write short notes on TinySec?
A5)
TinySec
TinySec is a lightweight and generic link-layer security package that may be readily integrated into sensor network applications by developers. It has two security options: (1) authenticated encryption (TinySec-AE), which encrypts the data payload and uses a MAC to authenticate a packet, and (2) authentication alone (TinySec-Auth), which authenticates the entire packet with a MAC (but the payload is left unencrypted).
TinySec encrypts data using cipher block chaining (CBC) and an 8-byte initialization vector (IV) that has been properly prepared. TinySec uses a quick and efficient cipher block chaining construction (CBC-MAC) for computing and verifying MACs for authentication. Because it uses a block cipher, CBC-MAC has the advantage of reducing the amount of cryptographic primitives that must be implemented, which is advantageous for sensor nodes with limited storage capacities.
Because the MAC is just 4 bytes long, an adversary can attempt blind forgeries multiple times, with a maximum of 232 tries leading to success. While this looks to be a modest quantity, it is important to remember that an adversary must evaluate the authenticity of a code by delivering it to an approved receiver. This also indicates that up to 232 messages must be transmitted, which is sufficient for sensor networks' security.
Q6) Explain Introduction to IEEE 802.15.4 and ZigBee Security?
A6)
Introduction to IEEE 802.15.4 and ZigBee Security
For WSNs, the IEEE 802.15.4 standard and the ZigBee specification are prominent options. Access control, message integrity, message confidentiality, and replay protection are the four core security concepts provided by the IEEE 802.15.4 standard.
The MAC layer handles security in IEEE 802.15.4, and an application can select certain security needs by setting relevant parameters in the radio stack (by default, security is not enabled). The standard defines eight security suites, each with varying levels of data transmission protection.
The first suite provides no security, while the second provides just encryption (AES – CTR), followed by a group of suites that provide only authentication (AES – CBC – MAC), and a group that provides both authentication and encryption (AES – CCM). The sizes of the MAC, which range from 32 to 128 bits, vary amongst authentication suites. IEEE 802.15.4 includes optional replay protection for every encryption suite, consisting of monotonically growing sequence numbers for communications to help a recipient to identify replay assaults.
The first suite is comprised of Null does not offer any protection. The Advanced Encryption Standard (AES) block cipher, often known as Rijndael, is used by all other security suites. The counter (CTR) and cipher block chaining (CBC) modes are among the five modes of operation defined by the National Institute of Standards and Technology.
The ZigBee specification incorporates the idea of a trust center, which is normally adopted by the ZigBee coordinator, in addition to the security features of IEEE 802.15.4. The trust center is in charge of ensuring that devices desiring to join a network are authenticated (trust manager), keeping and distributing keys (network manager), and providing end-to-end security between devices (configuration manager).
In addition, ZigBee distinguishes between a residential and a commercial mode. The trust center permits nodes to join the network in residential mode, but it does not establish keys with the network devices. It generates and maintains keys and freshness counters with every device in the network in commercial mode. The disadvantage of the commercial mode is its high memory cost, which increases as the network develops in size.
The security services in the ZigBee specification are provided via the CCM* mode, which is a combination of CTR mode and CBC – MAC mode. CCM* offers encryption-only and integrity-only capabilities in comparison to CCM mode. ZigBee includes various degrees of security, similar to the IEEE 802.15.4 standard, including no security, encryption only, authenticated only, and both encryption and authentication. The MAC used by authentication levels can range from 4 to 16 bytes.
Q7) Describe Sensor Database Challenges?
A7)
Sensor Database Challenges
In a sensor network, each sensor takes a timestamp measurement of physical phenomena like heat, sound, light pressure, or motion. The same data detection, classification, or tracking outputs may be produced by signal processing modules on a sensor in a more abstract form. A sensor also has a description of its properties, such as the sensor's location or type. All of the following data from each sensor is stored in a sensor network database.
Transferring all of this data to one or a few external warehouses, where a typical DBMS system may be implemented, is one way to construct such a database. This, however, has a number of disadvantages. The other option is to store the data within the network and allow queries to be injected anywhere within it.
It's vital to remember that the type of data collected from sensors, as well as the physical structure of a sensor network, change greatly from each database system type. At the most basic level, in a sensor network, we must think of all the data the system might acquire as a big virtual database, separate from the data the system has actually felt and/or stored. When using configurable sensors, such as Pan tilt cameras, the system must pick between two non-overlapping fields of view to detect in order to best fulfill the inserted query.
As a result, resource contention must be considered all the way down to what data can enter the physical database. When it comes to database implementation, there are two primary distinguishing aspects of sensor networks at the physical level. The first is that the network takes the place of the storage and buffer manager; data is transferred from Node memory rather than data blocks on disk. Second, unlike disk storage, which has grown quite inexpensive, node memory is constrained by cost and energy considerations.
As a result of these variations, sensor network databases face numerous new challenges:
● The system as a whole is quite volatile; nodes can be depleted, links can fail, and so on. However, the database system must conceal all of this from the end user or application, giving the impression of a stable, reliable environment in which queries complete successfully.
● Because fresh data is constantly being sensed, relational tables are not static. They're best thought of as append-only streams that don't have access to certain useful reordering operations like sorting.
● During query execution, the high energy cost of connectivity encourages in-networking processing. Query processing, in general, must be tightly connected and optimized with the networking layer. It's still a work in progress to figure out how to do it the best way possible.
● Arbitrarily long waits can make data difficult to access, and the rate at which input data comes at a database operator like a join can be highly unpredictable. As a result, creating a query execution plan only once is insufficient. Instead, to achieve optimal query execution, the rate and availability of data must be continuously checked, and operator location and operator sequencing may need to be modified on a regular basis.
● Because of the limited storage on nodes and the high cost of Hai communication, older data must be destroyed. The database system could try to keep more high-level statistical summaries information so that past queries can still be answered in some form. Strategies for dealing with stale data are a topic of current investigation.
On a logical level, there are also major discrepancies between sensor network data and data from other databases.
● Sensor network data is made up of measurements taken in the real world. Error purchase interference from other signals, device noise, and other factors are all inevitable in such measurements. As a result, accurate inquiries in sensor networks aren't very useful. Range searches, as well as probabilistic or approximation queries, are better options.
● To describe the length and sampling rates for the data to be gathered, more operators must be introduced to the query language.
● While single-shot queries are viable and helpful in sensor networks, we anticipate that a significant portion of the inquiries will be continuous and long-running, such as tracking the average temperature in a room. As a result, sensor network databases resemble data streams more closely, and research on query languages from that field can be used here.
● Open Sensor Networks (OSNs) are used to monitor the environment and report unusual conditions or other noteworthy events. As a result, having operators for correlating sensor readings and comparing them to pass statistics is critical. The logical basis for such procedures requires more work. The same applies to language for describing event detection and action triggers.
Q8) Define Querying the physical environment?
A8)
Querying the physical environment
Using relational languages like SQL, it is convenient to express queries to a sensor network database at a logical declarative level. Non-expert users can readily interact with the database thanks to high-level interfaces. Furthermore, querying in a way that is independent of the physical structure or organization of a sensor network shields users from database implementation details. The actual topology and connectivity of a network, for example, may vary over the course of the time window in which a query is executed. For a non-expert user, anticipating all probable occurrences and designing the associated query execution strategy would be challenging.
As an example of SQL-style sensor network querying, consider the following flood warning system. “For the next 3 hours, retrieve every 10 minutes the maximum rainfall level in each country in Southern California if it is greater than 3.0 inches,” a user from a state disaster management agency may query the flood sensor database. This is an example of a long-running coma monitoring query, which may be written in SQL-like syntax as follows:
SELECT max(Rain_Level), county
FROM sensors
WHERE state = California
GROUP BY country
HAVING max(Rain_Level) > 3.0in
DURATION [now, now+180 min]
SAMPLING PERIOD 10 min
The time clause, which describes the period during which data will be gathered, and the sampling period clause, which specifies the frequency at which query results will be provided, are the only differences from SQL Syntax. It is assumed that the database schema is known at a fixed base station because the query is expressed over a single table including all of the sensors in the network, each of which corresponds to a row in the table.
To summarize, sensor network queries could
● Aggregate data over a group of fences or a time window.
● Contain conditions restricting the set of sensors from contributing data.
● Correlate data from different sensors.
● Trigger data collections for signal processing on sensor Nodes.
● Spawn subqueries necessary.
To effectively support each of these inquiries, we must first understand how the data organization and query execution must be integrated with the sensor network's spatially distributed processing and communication.
Q9) What are Query interfaces?
A9)
Query interfaces
As an example of a sensor database query interface, a front-end server connected to a sensor network maintains a SQL type query interface for users. The resource use and response time of distributed query execution are optimized. The cougar method aims to keep as much of the appeal and familiarity of a traditional data warehousing system as feasible while also being efficient.
Cougar sensor database and abstract data types
Cougar, like most modern object relational databases, treats each type of sensor in a network as an abstract data type. Through a well-defined set of access functions, an ADT allows controlled access to enclosed data. In the Cougar database, an ADT object corresponds to a physical sensor in the actual world. Signal Processing features, such as a short-time fourier transform and vibration signature analysis, may be included in the public interface of a seismic sensor ADT, for example.
Sensor measurements are represented as time series in the Cougar data model, with each measurement associated with a timestamp. Assume that the nodes are suitably time synchronized with one another, so that there is no misalignment when several time series are aggregated. In contrast to the base relation defined in the database design, Cougar provides virtual relations — relations that are not actually materialized as regular tables – to account for the fact that a measurement for a sensor is not instantaneously accessible owing to network latency. When a signal processing function provides a value, a record is appended to the virtual relation, which means that records are never modified or destroyed. Virtual relations are a powerful tool for dealing with ADT functions that don't provide a value in a timely manner, such as sensor networks.
It would be very expensive to transmit data from all the sensors to the frontend server where the query processing could be performed
Probabilistic Queries
Due to device noise or environmental perturbations, sensor data necessarily involves measurement error. As a result, requests for exact sensor reading values must be replaced with a Formalism that allows the inherent uncertainty to be expressed. Because measurements are generally exposed to a large number of minor and random perturbations, one technique to characterize uncertainty in a database system is to use gaussian ADT, which models uncertainty as a continuous probability distribution function over all possible measurement values. A GADT can be conveniently expressed by the gaussian mean μ and standard deviation σ. Just like an ordinary edit in a database, a is a first class object, with a set of well-defined functions such as a prob, Diff and conf whose semantics are defined.
Q10) Explain High- level database organization?
A10)
High - Level database organisation
To handle queries like the ones described earlier efficiently, the design of a sensor data-based system must be coordinated with the underlying routing infrastructure as well as the application's characteristics, such as data generation and access patterns. Let's look at two possible ways that data from a sensor network could be stored to demonstrate the trade-off mentioned. In the centralised warehousing approach it sensor forward fit data to a central server or their house connected to the network wire and access point. For a reasonably uniform distribution of the nodes coma we use the average routine distance from a note to the access point comma to characterize the cost of communication – this would be O(√n), Where n is the number of nodes in the network.
Because user requests are processed on an external server, there are no additional sensor network transmission costs. The centralised strategy, on the other hand, has a number of drawbacks. The nodes closest to the access point become traffic hotspots and failure centers. When all of the aggregate data needs to be reported, this strategy does not take advantage of data aggregation in the network to reduce communication load. Also, sample rates must be said to be the highest possible for any prospective query, otherwise the network will be overburdened with superfluous traffic.
Finally, there are customers. Other apps operating on network nodes may be able to access the data. For example, a flood detecting mean Trigger action for the local flow regulator in a closed loop float control system. It is possible that transmitting and receiving data from a remote Central server will create excessive delays.
The use of so-called in-network storage, which stores data within the network, is an appealing alternative. The optimal choice of data storage point, which is at rendezvous points between data and queries in figure, is at the heart of the architecture, so that the overhead to store and retrieve the data is minimized and the overall load is balanced across the network. The cost of communication for storing data remains comparable to that of warehousing. The query time coma, on the other hand, is highly dependent on how the data is indexed. Flooding the network with a query can incur O(n)communication costs and may be undesirable in many cases. In a data-centric storage system the communication overhead for a query can be reduced to O(√n) via Geographic hashing methods. Most notably, in network storage allows data to be aggregated before being transmitted to an external query, allowing for the advantages of locality of information for or in network queries, as well as load balancing database costs among nodes if appropriately structured.

Fig 1: rendezvous mechanism for a sensor network database
We need to build a set of matrices to compare alternative methodologies and characterize the performance of a sensor network database system. The following is an adaptation of metric for generic database systems for sensor networks.
● Network usage is characterized by
● Total usage - the total number of packets sent in the network.
● Hotspot usage – the maximum amount of packets that a node may process at any given time. Before partitioning, hotspot consumption has an impact on the total network lifetime.
● Preprocessing time - the time taken to construct and index.
● Storage space requirement - the storage for the data and index.
● Query time – the amount of time it takes to evaluate a query, put together an answer sentence, and return his response.
● Throughput – for each unit of time, the average number of requests processed.
● Update and maintenance cost – When nodes fail, expenditures such as processing sensor data, coma elimination, and repair are incurred.
Q11) What do you mean by In-network Aggregation?
A11)
In - network Aggregation
When providing aggregate inquiries, in-network query processing can save a lot of time and energy. This savings is achieved because combining data at intermediary nodes reduces the overall number of messages that the network must send, lowering communication and extending the network's lifetime.
Query Propagation and Aggregation
Consider the following example, which computes an average reading over a network of six nodes arranged in a three-level routing tree. Each sensor delivers its data directly to the server in the server-based approach, where the aggregation takes place on an external server. A total of 16 message transfers are required. Sansar Mein's computer parcel state record, on the other hand, consists of a sum, an account based on its data and that of its children, if any. This only necessitates six message transmissions in total.
Query propagation and data aggregation are common components of in-network aggregation and query processing. To push a query to every node in a network, an efficient procedure structure, such as a routing tree rooted at a base station, must be constructed. A query can be broadcast via the routing structure in its entirety, or it can be multicast to reach only those nodes that can contribute to the inquiry. If the having predicate specifies a Geographic region, for example, elements of the routing structure that do not satisfy the having predicates may be excluded from the query propagation.
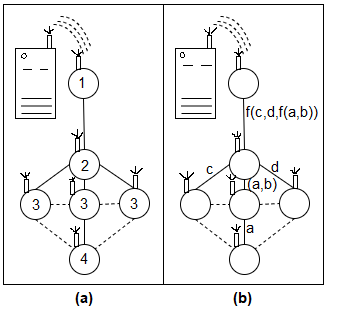
Fig 2: external server (a) verses in network aggregation (b)
Query Processing Scheduling and Optimization
In Tiny DB, it is assumed that a query is issued from a server external to the sensor network. A routing tree rooted at the server distributes the Quarry. Here the focus is on how data is aggregated. Tiny DB uses an epoch-based mechanism. Each epoch, or sampling period, is divided into time intervals. The number of intervals reflects the depth of the routing tree.
Aggregation results are reported at the end of each sampling period, and the server receives a stream of aggregates, one per sampling period, over time. The choice of the sampling period is important – this period should be sufficiently large for data to travel from the deepest leaf nodes to the root of the tree.
According to its depth in the trees, each node schedules its processing, listening, receiving, and transmitting periods. When a node broadcasts a query, it specifies the time interval in which it expects its children to respond. This interval is calculated to terminate shortly before the moment when it is supposed to send up its own result. Each node waits for packets from its children during its scheduled interval, gets them, computes a new partial state record using its own data and the partial state records from its children, and transmits the result up the tree to its parents. This saves energy because each node only needs to power up during its specified interval.
Figure illustrates an example of such a schedule full stop note that each parent's listening period is slightly longer than the children's and includes the children's transmission interval. This is to allow for minor mistakes in note time synchronisation, and to boost throughput, aggregation processes at various depths off the tree may be pipelined so that an aggregate is computed at each sub interval.
In the query example given, grouping predicates such as (GROUP BY country) may be used in Tiny DB queries. When grouping predicates are present, each partial record is assigned a group ID, and only those records with the same group ID are aggregated at intermediate nodes.
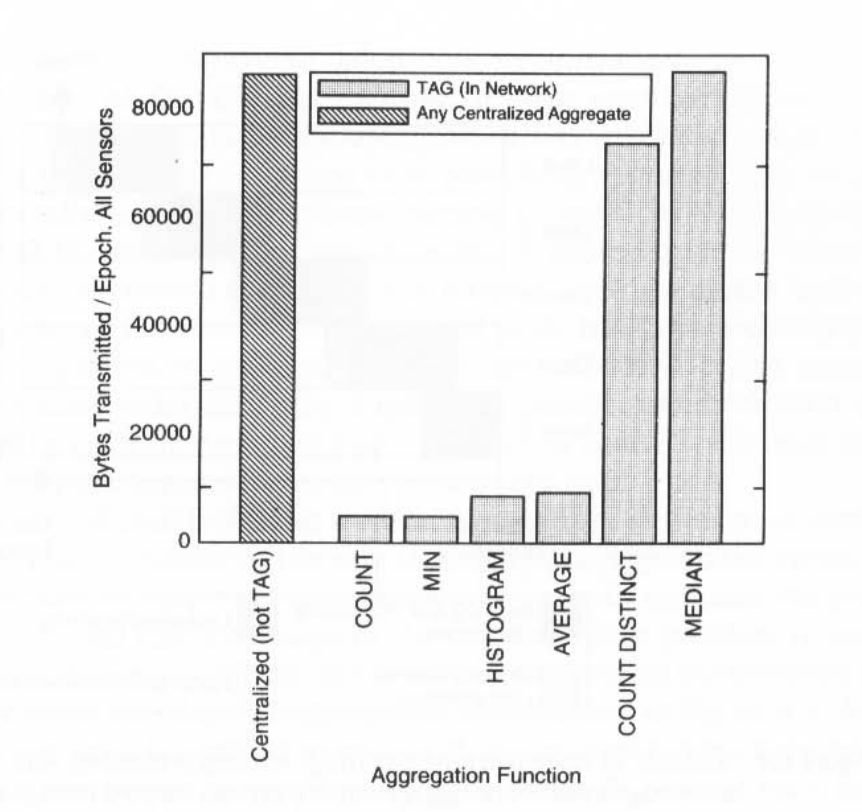
Fig 3: benefits of in network aggregation for different aggregation functions supported in TinyDB.
Q12) Describe Data Centric Storage?
A12)
Data Centric Storage
Patri based query propagation mechanisms such as the one used by TinyDB is appropriate for a server based application full stop to support data access when queries may originate from multiple and arbitrary nodes within a network however more flexible storage and access mechanisms are needed. one may think of using multiple trees, one for each query node and overlaying them to share the same physical network full stop but this requires far more sophisticated scheduling than that used in tiny DB. Furthermore, it is still server-centric and requires flooding the network with the queries. Data- centric storage is a method proposed to support queries from any node in the network by providing a rendezvous mechanism for data and queries that avoids loading the entire network.
DCS names and stores data by external attributes, similar to data center routing, rather than network information such as addresses of machines where the data originated. Data and queries give a means for translating the characteristics or keys into a node, and DCS provides a technique for converting the attributes into a node at the heart of a DCS system. When compared to local data storage on the node where the data was generated for external warehousing waste storage, the location for ID is where the data is stored. The storage burden is distributed throughout the entire network using DCS. Such load balancing is effective when most queries can be resolved by utilising only a small fraction of the data stored in the network.
The Geographic Hash table is an example of DCS (GHT). To examine in ght, a Hash Function performs the translation from node attribute to two storage places, attempting to spread data equitably across the network. Ghtf jiom Using a GPSas or other node location service, each node knows its geographical location. A key is connected with a data object, and each node in the system is in charge of storing a specific range of keys. In reality, any key can be used as long as it can identify this data in a query individually.
GHT hashes keys in two geographical coordinates and stores a key-value pair at the sensor node that is closest to the hash of its key geographically. In the event that one or more nodes fail, the system replicates stored data locally to ensure data permanence. Any node in the system can use a geographic routing method to find the storage node for any key. The delivery routing system used by GHT is a modified GPSR, a routing algorithm. This allows nodes to store and retrieve data depending on their keys, allowing for a Hash table-like interface. Data consistency and persistence are achieved by replicating data at nodes around the location to which the key hashes furthermore, GHT and show that one note is Susan consistently as the home note for that key.
If a large number of events with the same key are discovered, the key's home node Good becomes a communication and storage hotspot. A replication technique in which the key space is hierarchically partitioned, as illustrated in the image, can be used to prevent the hot spot.
The basic GHT can be extended in a variety of ways. In many applications, data collected by a node may only be required by nodes in close proximity to the data source node. This necessitates hashing to places that respect geographic proximity in order to prevent wasteful network traffic. Second, it is often more beneficial to hash to regions rather than to locations, for reasons such as avoiding Hotspots and increasing robustness. The structured application is one way to do this.

Fig 4: structured replication in GHT
Q13) What do you mean by Distributed and Hierarchical aggregation?
A13)
Distributed and Hierarchical aggregation
To allow quick query execution with a minimal storage cost, range search data structures rely heavily on hierarchical aggregation of data. Even without range searching, hierarchical aggregation is one of the most important methods for structuring and organizing data collected by a sensor network. However, in a distributed network setting, these tree topologies must be superimposed on the node's network structure.
Except in a few simple scenarios, it's unclear how this mapping should be done, and as we've already mentioned, the root and nodes around the root main will become a traffic bottleneck. In sensor networks, data is generated through sensors that represent leaf nodes in the tree, as opposed to a centralised system where data is inserted from the root. In order to update the index, any new data generated by a sensor may need to be propagated all the way up to the root. Similarly, all access to sensor data will have to travel through the root of the search tree and then dig down.
Multiresolution Summarization
Indices range searching gives a hierarchical summary of records or events in a database based on simple attributes of interest. The summaries are tailored to answer the questions that have been provided. In general, we might wish to get statistical summaries of such recordings or events at many spatial or temporal dimensions that a human user can look at as well as my software. An environmentalist, for example, could be interested in the concentration of pollutant flow across a country.
Instead of querying the entire country, the user may try to figure out which regions might have similar phenomena, and then drill down into subregions of those regions. A traffic analyst, for example, would be interested in Vehicle speed data in a city through her neighborhood at an intersection or over the past week, day, or hours if she's trying to set lights to enhance traffic flow. Due to storage and communication constraints, it is advantageous to summarise partial temporal data in the network at multiple resolutions so that the summaries can be easily queried, finer details can be found by drilling down the summarisation tree, and correlations between data can be detected, and so on.
Wavelet transforms are frequently utilized in signal and image processing because they give a mechanism to compress and summarize information for both temporal and spatial signals. Wavelet compression isolates significant aspects of the signal, such as discontinuities or long-term patterns, which might help comprehend the phenomenon of interest. To summarize data over a specific domain, that domain must be broken down into components in a hierarchical order. A wavelet compression strategy computes the wavelet transform for each of the sub regions independently first, then combines the wavelet coefficients of the wavelet transform for the entire region. To keep storage and communication efficiency at some levels of the hierarchy, the upper level transform is thresholded so that the size transform does not rise as it progresses up the summarisation hierarchy, where more data is represented and storage efficiency is gained at the expense of some detail.
Partitioning the Summaries
We can distribute aggregated data over various nodes in the network and therefore reduce the strain on nodes near the hierarchy root if we can split aggregated data in a meaningful fashion. DIFS is a system that has pioneered this method (distributed index for features in sensor networks). For events, DIFS considers a one-dimensional attribute space, with nodes containing histograms summarizing statistics about the attribute's value.
Assuming that sensors are located in a two-dimensional spatial domain, DIFS recommends partitioning the domain using a multi-rooted quadtree. A typical quadtree divides the sensor domain into four equal quadrants in a recursive manner. Each kid in a multi-rooted quad-tree can have l= 2,4,8..... Parents. This is to help with the hotspot problem higher up in the tree. DIFS follows the following rule to combine the breakdown of the geographical domain with the indexing of data attributes: The greater the spatial size of the Intex note nose, the more constrained the value range covered by its histogram.
DIFS finds and indexes not provided a data event and a bounding box a Geographically bounded has Returns a position within that box using a modified GHT. This can be accomplished by concatenating the bounding Box's upper order bits with the data event's hash. The Hash Function is used to identify the nearest leaf index note that covers the value of the event in order to insert it into the index tree. The index node updates its histogram before passing the event on to its parent, and so on.
To query for events in a value range, first find the smallest number of index nodes that cover the query range exactly, and then route the query components of the associated index node to get the values included in the subtree rooted at these nodes. This search for the covering node takes place across the full spatial domain, which might be time-consuming. DIFS distributes the index Data Structure across the network using a multi-rooted index tree to load-balance traffic and reduce energy consumption.
Fractional Cascading
In a sensor network, query data access patterns are not random. In many situations, a query injected into a network node is significantly more likely to request data acquired in the query's spatial and temporal locality rather than arbitrary data. This is because the majority of physical occurrences and interactions in sensor networks are spatially and/or temporally limited. Indeed, one of the critiques leveled against the GHT strategy is that data may be stored far from the node that created it, and thus far from the area where it is most likely to be requested.
The fractional cascading approach to storing data in a sensor network is based on this idea of storing information locally. This technique is also totally symmetric — despite some information duplication, no node plays a unique role any longer, preventing hotspot difficulties. The main idea behind the fractional cascading approach is to store information about data available elsewhere in the network at each sensor, but in such a way that each sensor only knows a fraction of the information from far away parts of the network in an exponentially decaying fashion by distance.
This accomplishes three objectives at the same time.
● Because of the geometric decrease in distance, the total amount of information duplicated across all sensors is kept small.
● Because information travels only short distances on average, the communication costs associated with creating this index and updating it remain manageable.
● Neighboring sensors' world views are highly correlated, allowing for a smooth information gradient and efficient local search methods.
The term fractional cascading was coined to describe how information decays geometrically with distance. The technique adapts the resolution at which information is stored automatically so that more precise information about data acquired in the sensor's spatiotemporal locality where the query is injected is available without sacrificing the ability to query distant regions or time. Furthermore, load balancing across the entire network field is used to achieve this.
Q14) Introduce discrete event network simulators?
A14)
Introduction to discrete event network simulators
Size, power consumption, and cost have all been reduced thanks to advancements in hardware technology and engineering design. As a result, compact autonomous nodes with one or more sensors, computing and communication capabilities, and a power source have been developed. The rapid convergence of the following three major technologies has resulted in wireless sensor networks.
● Computing / Internet: Computing power is shrinking in size and cost, making it possible to incorporate it into practically any item. Computer networks make collaboration easier by allowing people to share information and resources.
● Sensor: Miniaturization and micromachining result in smaller sizes, lower power consumption, and lower costs, allowing for more granular monitoring. There are many different types of sensors available now, and more are being created.
● Wireless / Antennas: Bluetooth and WiFi networks, as well as cellular and satellite connections, are all covered.
The definition and application of Wireless Sensor Networks has resulted from recent technological advancements (WSN). Sensor nodes are often dispersed over a sensor field. Each of these dispersed sensor nodes has the ability to collect data and send it back to the sink. A multi-hop infrastructure architecture is used to route data back to the sink. The sink and the task manager node can communicate over the Internet or satellite.
Channel access control, routing protocol specification, network management, QoS, energy consumption, and CPU activity are just a few of the areas where wireless sensor network research is now focused. Different simulators exist for representing WSN activity and performance.
SensorSim adds sensor channel models as well as precise battery and power usage to the NS-2 network simulator. Each node has a sensor stack that serves as a sink for each other's signals.
Atemu is a software emulator for computers with AVR processors. It also supports various peripheral devices on the MICA2 sensor node platform, such as the radio, in addition to the AVR processor. In a controlled environment, Atemu can be utilized to do high-fidelity large-scale sensor network emulation experiments. Despite the fact that the current release only supports MICA2 hardware, it may simply be expanded to include additional sensor node platforms. It permits heterogeneous sensor nodes to be used in the same sensor network. Because of its high abstraction level, Atemu is unable to describe varied actions of hardware components.
The DEVS formalism is a straightforward approach of describing how discrete event simulation languages can define discrete event system parameters. It's more than a tool for creating simulation models. It serves the same purpose as differential equations in that it gives a formal description of discrete event systems that may be mathematically manipulated. Furthermore, the DEVS formalism is the ideal technique to execute an efficient simulation of complex systems using a computer since it allows an explicit separation between the modeling and simulation phases.
One must specify:
1) Basic models from which larger ones are generated, and
2) How these models are connected in a hierarchical fashion in the DEVS formalism.
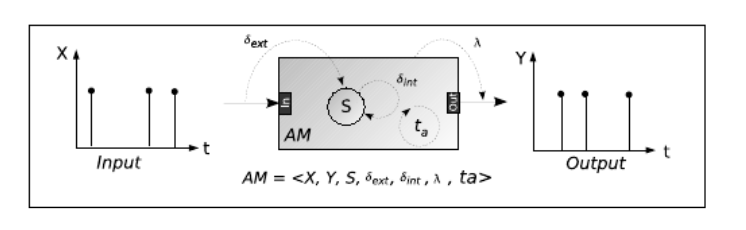
Fig 5: DEVS atomic mode
The output data Y of an AM atomic model is calculated based on the input data X in the figure. S is a state variable in the AM atomic model that can be achieved during simulation. The functions ext, int, and ta allow the model to change state when an external event occurs on one of those outputs (external transition function), dispose of the output Y (output function), change state after giving an output (internal transition function), and finally determine the duration of the model's state (ta) (time advance function).




