UNIT 1
UNIT 1
Introduction
- What is a Flowchart explain in detail?
A flowchart is a graphical representations of steps. It was originated from computer science as a tool for representing algorithms and programming logic but had extended to use in all other kinds of processes. Nowadays, flowcharts play an extremely important role in displaying information and assisting reasoning. They help us visualize complex processes, or make explicit the structure of problems and tasks. A flowchart can also be used to define a process or project to be implemented.
Flowchart Symbols
Different flowchart shapes have different conventional meanings. The meanings of some of the more common shapes are as follows:
Terminator
The terminator symbol represents the starting or ending point of the system.

Process
A box indicates some particular operation.

Document
This represents a printout, such as a document or a report.

Decision
A diamond represents a decision or branching point. Lines coming out from the diamond indicates different possible situations, leading to different sub-processes.

Data
It represents information entering or leaving the system. An input might be an order from a customer. Output can be a product to be delivered.

On-Page Reference
This symbol would contain a letter inside. It indicates that the flow continues on a matching symbol containing the same letter somewhere else on the same page.

Off-Page Reference
This symbol would contain a letter inside. It indicates that the flow continues on a matching symbol containing the same letter somewhere else on a different page.

Delay or Bottleneck
Identifies a delay or a bottleneck.

Flow
Lines represent the flow of the sequence and direction of a process.

When to Draw Flowchart?
Using a flowchart has a variety of benefits:
- It helps to clarify complex processes.
- It identifies steps that do not add value to the internal or external customer, including delays; needless storage and transportation; unnecessary work, duplication, and added expense; breakdowns in communication.
- It helps team members gain a shared understanding of the process and use this knowledge to collect data, identify problems, focus discussions, and identify resources.
- It serves as a basis for designing new processes.
Flowchart examples
Here are several flowchart examples. See how you can apply a flowchart practically.
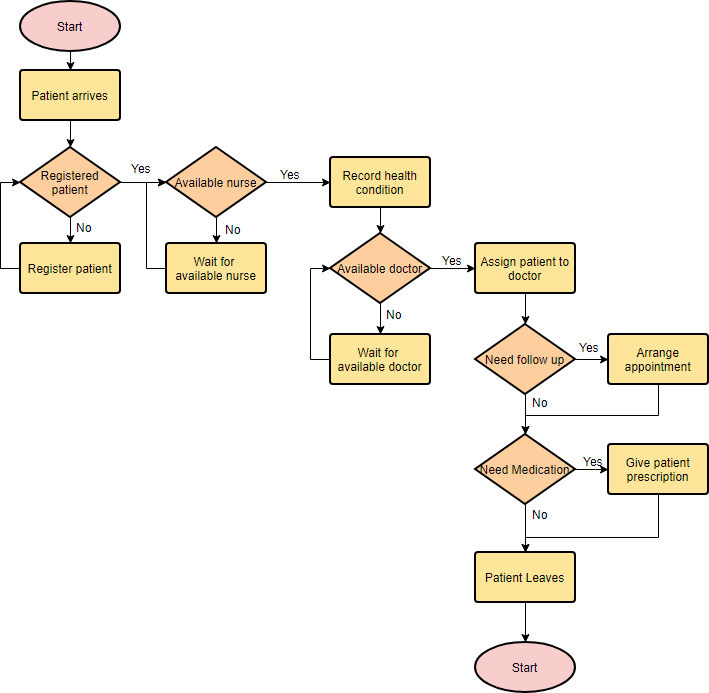
Flowchart Example – Medical Service
This is a hospital flowchart example that shows how clinical cases shall be processed. This flowchart uses decision shapes intensively in representing alternative flows.
2. Explain pseudo code with examples
Pseudo code is a term which is often used in programming and algorithm based fields. It is a methodology that allows the programmer to represent the implementation of an algorithm. Simply, we can say that it’s the cooked up representation of an algorithm. Often at times, algorithms are represented with the help of pseudo codes as they can be interpreted by programmers no matter what their programming background or knowledge is. Pseudo code, as the name suggests, is a false code or a representation of code which can be understood by even a layman with some school level programming knowledge.
Algorithm: It’s an organized logical sequence of the actions or the approach towards a particular problem. A programmer implements an algorithm to solve a problem. Algorithms are expressed using natural verbal but somewhat technical annotations.
Pseudo code: It’s simply an implementation of an algorithm in the form of annotations and informative text written in plain English. It has no syntax like any of the programming language and thus can’t be compiled or interpreted by the computer.
Advantages of Pseudocode
- Improves the readability of any approach. It’s one of the best approaches to start implementation of an algorithm.
- Acts as a bridge between the program and the algorithm or flowchart. Also works as a rough documentation, so the program of one developer can be understood easily when a pseudo code is written out. In industries, the approach of documentation is essential. And that’s where a pseudo-code proves vital.
- The main goal of a pseudo code is to explain what exactly each line of a program should do, hence making the code construction phase easier for the programmer.
How to write a Pseudo-code?
- Arrange the sequence of tasks and write the pseudocode accordingly.
- Start with the statement of a pseudo code which establishes the main goal or the aim.
Example:
This program will allow the user to check
The number whether it's even or odd.
3. The way the if-else, for, while loops are indented in a program, indent the statements likewise, as it helps to comprehend the decision control and execution mechanism. They also improve the readability to a great extent.
4. Example:
5.
6. if "1"
7. print response
8. "I am case 1"
9.
10. if "2"
11. print response
12. "I am case 2"
13. Use appropriate naming conventions. The human tendency follows the approach to follow what we see. If a programmer goes through a pseudo code, his approach will be the same as per it, so the naming must be simple and distinct.
14. Use appropriate sentence casings, such as CamelCase for methods, upper case for constants and lower case for variables.
15. Elaborate everything which is going to happen in the actual code. Don’t make the pseudo code abstract.
16. Use standard programming structures such as ‘if-then’, ‘for’, ‘while’, ‘cases’ the way we use it in programming.
17. Check whether all the sections of a pseudo code is complete, finite and clear to understand and comprehend.
18. Don’t write the pseudo code in a complete programmatic manner. It is necessary to be simple to understand even for a layman or client, hence don’t incorporate too many technical terms.
3. Write a program to calculates the Lowest Common multiple for excessively long input values
Import java.util.*;
Public class LowestCommonMultiple {
Private static long LcmNaive(long numberOne, long numberTwo) {
Long lowestCommonMultiple;
LowestCommonMultiple = (numberOne * numberTwo) / greatestCommonDivisor(numberOne, NumberTwo);
Return lowestCommonMultiple; }
Private static long GreatestCommonDivisor(long numberOne, long numberTwo) {
If (numberTwo == 0) Return numberOne;
Return greatestCommonDivisor(numberTwo, NumberOne % numberTwo); } Public static void main(String args[]) {
Scanner scanner = new Scanner(System.in); System.out.println("Enter the inputs"); Long numberOne = scanner.nextInt(); Long numberTwo = scanner.nextInt();
System.out.println(lcmNaive(numberOne, numberTwo)); } } |
And here’s the Pseudo Code for the same.
This program calculates the Lowest Common multiple For excessively long input values
Function lcmNaive(Argument one, Argument two){
Calculate the lowest common variable of Argument 1 and Argument 2 by dividing their product by their Greatest common divisor product
Return lowest common multiple End } Function greatestCommonDivisor(Argument one, Argument two){ If Argument two is equal to zero Then return Argument one
Return the greatest common divisor
End }
{ In the main function
Print prompt "Input two numbers"
Take the first number from the user Take the second number from the user
Send the first number and second number To the lcmNaive function and print The result to the user } |
4. What is a source code?
If you’re neither a programmer nor a web designer, you probably don’t think much about what’s behind the programs and internet pages that you use every day. They are based in part on very complicated and long instructions to your computer. This command text is called source code. On the basis of a particular programming language, programmers lay out all of the rules for a computer-executable application. If the author writes an unnoticed error into their work that violates the specifications of the programming language, then the program either won’t function properly, will do nothing, or will crash.
What is source code?
Computers - regardless of whether it’s a home PC, modern smartphone, or scientific computer - work in the binary system: on/off, loaded/not loaded, 1/0. A sequence of bits instructs the computer as to what it should do. While commands were created in this way in the early days of computer technology, we have long since switched to writing applications in a human-readable programming language. This may sound strange at first since source code could also look like confused gibberish to a layman.
In context, “human-readable” is understood as the counterpart to the term “machine-readable”. While computers only work with number values, humans communicate with words. So, just like a foreign language, one must learn at least one of the various programming languages before being able to program, etc.
Different programming languages
There are hundreds of different programming languages. It’s impossible to say for certain which are better or worse, as it depends on the context of the project and the application for which the source code is used. Some of the most popular programming languages are:
- BASIC
- Java
- C
- C++
- Pascal
- Python
- PHP
- JavaScript
For the computer to understand these languages, however, they need to first be translated into machine code.
5. Explain variables in programming language
Variables are the names you give to computer memory locations which are used to store values in a computer program.
For example, assume you want to store two values 10 and 20 in your program and at a later stage, you want to use these two values. Let's see how you will do it. Here are the following three simple steps −
- Create variables with appropriate names.
- Store your values in those two variables.
- Retrieve and use the stored values from the variables.
Creating variables
Creating variables is also called declaring variables in C programming. Different programming languages have different ways of creating variables inside a program. For example, C programming has the following simple way of creating variables −
#include <stdio.h>
Int main() {
int a;
int b;
}
The above program creates two variables to reserve two memory locations with names a and b. We created these variables using int keyword to specify variable data type which means we want to store integer values in these two variables. Similarly, you can create variables to store long, float, char or any other data type. For example −
/* variable to store long value */
Long a;
/* variable to store float value */
Float b;
You can create variables of similar type by putting them in a single line but separated by comma as follows −
#include <stdio.h>
Int main() {
int a, b;
}
Listed below are the key points about variables that you need to keep in mind −
- A variable name can hold a single type of value. For example, if variable a has been defined int type, then it can store only integer.
- C programming language requires a variable creation, i.e., declaration before its usage in your program. You cannot use a variable name in your program without creating it, though programming language like Python allows you to use a variable name without creating it.
- You can use a variable name only once inside your program. For example, if a variable a has been defined to store an integer value, then you cannot define a again to store any other type of value.
- There are programming languages like Python, PHP, Perl, etc., which do not want you to specify data type at the time of creating variables. So you can store integer, float, or long without specifying their data type.
- You can give any name to a variable like age, sex, salary, year1990 or anything else you like to give, but most of the programming languages allow to use only limited characters in their variables names. For now, we will suggest to use only a....z, A....Z, 0....9 in your variable names and start their names using alphabets only instead of digits.
- Almost none of the programming languages allow to start their variable names with a digit, so 1990year will not be a valid variable name whereas year1990 or ye1990ar are valid variable names.
Every programming language provides more rules related to variables and you will learn them when you will go in further detail of that programming language.
6. Explain Store Values in Variables in detail and Access stored values in variables
You have seen how we created variables in the previous section. Now, let's store some values in those variables −
#include <stdio.h>
Int main() {
int a;
int b;
a = 10;
b = 20;
}
The above program has two additional statements where we are storing 10 in variable a and 20 is being stored in variable b. Almost all the programming languages have similar way of storing values in variable where we keep variable name in the left hand side of an equal sign = and whatever value we want to store in the variable, we keep that value in the right hand side.
Now, we have completed two steps, first we created two variables and then we stored required values in those variables. Now variable a has value 10 and variable b has value 20. In other words we can say, when above program is executed, the memory location named a will hold 10 and memory location b will hold 20.
Access stored values in variables
If we do not use the stored values in the variables, then there is no point in creating variables and storing values in them. We know that the above program has two variables a and b and they store the values 10 and 20, respectively. So let's try to print the values stored in these two variables. Following is a C program, which prints the values stored in its variables −
#include <stdio.h>
Int main() {
int a;
int b;
a = 10;
b = 20;
printf( "Value of a = %d\n", a );
printf( "Value of b = %d\n", b );
}
When the above program is executed, it produces the following result −
Value of a = 10
Value of b = 20
You must have seen printf() function in the previous chapter where we had used it to print "Hello, World!". This time, we are using it to print the values of variables. We are making use of %d, which will be replaced with the values of the given variable in printf() statements. We can print both the values using a single printf() statement as follows −
#include <stdio.h>
Int main() {
int a;
int b;
a = 10;
b = 20;
printf( "Value of a = %d and value of b = %d\n", a, b );
}
When the above program is executed, it produces the following result −
Value of a = 10 and value of b = 20
If you want to use float variable in C programming, then you will have to use %f instead of %d, and if you want to print a character value, then you will have to use %c. Similarly, different data types can be printed using different % and characters.
7. Explain data types in detail
Let's discuss about a very simple but very important concept available in almost all the programming languages which is called data types. As its name indicates, a data type represents a type of the data which you can process using your computer program. It can be numeric, alphanumeric, decimal, etc.
Let’s keep Computer Programming aside for a while and take an easy example of adding two whole numbers 10 & 20, which can be done simply as follows −
10 + 20
Let's take another problem where we want to add two decimal numbers 10.50 & 20.50, which will be written as follows −
10.50 + 20.50
The two examples are straightforward. Now let's take another example where we want to record student information in a notebook. Here we would like to record the following information −
Name:
Class:
Section:
Age:
Sex:
Now, let's put one student record as per the given requirement −
Name: Zara Ali
Class: 6th
Section: J
Age: 13
Sex: F
The first example dealt with whole numbers, the second example added two decimal numbers, whereas the third example is dealing with a mix of different data. Let's put it as follows −
- Student name "Zara Ali" is a sequence of characters which is also called a string.
- Student class "6th" has been represented by a mix of whole number and a string of two characters. Such a mix is called alphanumeric.
- Student section has been represented by a single character which is 'J'.
- Student age has been represented by a whole number which is 13.
- Student sex has been represented by a single character which is 'F'.
This way, we realized that in our day-to-day life, we deal with different types of data such as strings, characters, whole numbers (integers), and decimal numbers (floating point numbers).
Similarly, when we write a computer program to process different types of data, we need to specify its type clearly; otherwise the computer does not understand how different operations can be performed on that given data. Different programming languages use different keywords to specify different data types. For example, C and Java programming languages use int to specify integer data, whereas char specifies a character data type.
Subsequent chapters will show you how to use different data types in different situations. For now, let's check the important data types available in C, Java, and Python and the keywords we will use to specify those data types.
8. Explain memory location in detail
A typical memory representation of C program consists of following sections.
1. Text segment
2. Initialized data segment
3. Uninitialized data segment
4. Stack
5. Heap

A typical memory layout of a running process
1. Text Segment:
A text segment , also known as a code segment or simply as text, is one of the sections of a program in an object file or in memory, which contains executable instructions.
As a memory region, a text segment may be placed below the heap or stack in order to prevent heaps and stack overflows from overwriting it.
Usually, the text segment is sharable so that only a single copy needs to be in memory for frequently executed programs, such as text editors, the C compiler, the shells, and so on. Also, the text segment is often read-only, to prevent a program from accidentally modifying its instructions.
2. Initialized Data Segment:
Initialized data segment, usually called simply the Data Segment. A data segment is a portion of virtual address space of a program, which contains the global variables and static variables that are initialized by the programmer.
Note that, data segment is not read-only, since the values of the variables can be altered at run time.
This segment can be further classified into initialized read-only area and initialized read-write area.
For instance the global string defined by char s[] = “hello world” in C and a C statement like int debug=1 outside the main (i.e. global) would be stored in initialized read-write area. And a global C statement like const char* string = “hello world” makes the string literal “hello world” to be stored in initialized read-only area and the character pointer variable string in initialized read-write area.
Ex: static int i = 10 will be stored in data segment and global int i = 10 will also be stored in data segment
3. Uninitialized Data Segment:
Uninitialized data segment, often called the “bss” segment, named after an ancient assembler operator that stood for “block started by symbol.” Data in this segment is initialized by the kernel to arithmetic 0 before the program starts executing
Uninitialized data starts at the end of the data segment and contains all global variables and static variables that are initialized to zero or do not have explicit initialization in source code.
For instance a variable declared static int i; would be contained in the BSS segment.
For instance a global variable declared int j; would be contained in the BSS segment.
4. Stack:
The stack area traditionally adjoined the heap area and grew the opposite direction; when the stack pointer met the heap pointer, free memory was exhausted. (With modern large address spaces and virtual memory techniques they may be placed almost anywhere, but they still typically grow opposite directions.)
The stack area contains the program stack, a LIFO structure, typically located in the higher parts of memory. On the standard PC x86 computer architecture it grows toward address zero; on some other architectures it grows the opposite direction. A “stack pointer” register tracks the top of the stack; it is adjusted each time a value is “pushed” onto the stack. The set of values pushed for one function call is termed a “stack frame”; A stack frame consists at minimum of a return address.
Stack, where automatic variables are stored, along with information that is saved each time a function is called. Each time a function is called, the address of where to return to and certain information about the caller’s environment, such as some of the machine registers, are saved on the stack. The newly called function then allocates room on the stack for its automatic and temporary variables. This is how recursive functions in C can work. Each time a recursive function calls itself, a new stack frame is used, so one set of variables doesn’t interfere with the variables from another instance of the function.
9. Explain heap in memory location with examples
Heap:
Heap is the segment where dynamic memory allocation usually takes place.
The heap area begins at the end of the BSS segment and grows to larger addresses from there.The Heap area is managed by malloc, realloc, and free, which may use the brk and sbrk system calls to adjust its size (note that the use of brk/sbrk and a single “heap area” is not required to fulfill the contract of malloc/realloc/free; they may also be implemented using mmap to reserve potentially non-contiguous regions of virtual memory into the process’ virtual address space). The Heap area is shared by all shared libraries and dynamically loaded modules in a process.
Examples.
The size(1) command reports the sizes (in bytes) of the text, data, and bss segments. ( for more details please refer man page of size(1) )
1. Check the following simple C program
#include <stdio.h>
Int main(void) { Return 0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bss dec hex filename
960 248 8 1216 4c0 memory-layout
2. Let us add one global variable in program, now check the size of bss (highlighted in red color).
#include <stdio.h>
Int global; /* Uninitialized variable stored in bss*/
Int main(void) { Return 0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bss dec hex filename
960 248 12 1220 4c4 memory-layout
3. Let us add one static variable which is also stored in bss.
#include <stdio.h>
Int global; /* Uninitialized variable stored in bss*/
Int main(void) { Static int i; /* Uninitialized static variable stored in bss */ Return 0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bss dec hex filename
960 248 16 1224 4c8 memory-layout
4. Let us initialize the static variable which will then be stored in Data Segment (DS)
#include <stdio.h>
Int global; /* Uninitialized variable stored in bss*/
Int main(void) { Static int i = 100; /* Initialized static variable stored in DS*/ Return 0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bss dec hex filename
960 252 12 1224 4c8 memory-layout
5. Let us initialize the global variable which will then be stored in Data Segment (DS)
#include <stdio.h>
Int global = 10; /* initialized global variable stored in DS*/
Int main(void) { Static int i = 100; /* Initialized static variable stored in DS*/ Return 0; } |
[narendra@CentOS]$ gcc memory-layout.c -o memory-layout
[narendra@CentOS]$ size memory-layout
Text data bss dec hex filename
960 256 8 1224 4c8 memory-layout
10. What is object code and executable code?
Object and executable code
Source code is the C program that you write in your editor and save with a ‘ .C ‘ extension. Which is un-compiled (when written for the first time or whenever a change is made in it and saved).
Object code is the output of a compiler after it processes the source code. The object code is usually a machine code, also called a machine language, which can be understood directly by a specific type of CPU (central processing unit), such as x86 (i.e., Intel-compatible) or PowerPC. However, some compilers are designed to convert source code into an assembly language or some other another programming language. An assembly language is a human-readable notation using the mnemonics (mnemonicis a symbolic name for a single executable machine language instruction called an opcode) in the ISA ( Instruction Set Architecture) of that particular CPU .
Executable (also called the Binary) is the output of a linker after it processes the object code. A machine code file can be immediately executable (i.e., runnable as a program), or it might require linking with other object code files (e.g. Libraries) to produce a complete executable program.




