Unit - 4
Memory
Q1) What is Instruction Level Parallelism?
A1)
Pipelining is used to overlap the execution of instructions and improve performance. This potential overlap among instructions is called instruction level parallelism (ILP).
Q2) Explain various types of Dependences in ILP.
A2)
- Data Dependences
- Name Dependences
- Control Dependences
Q3) What is Multithreading?
A3)
Multithreading allows multiple threads to share the functional units of a single processor in an overlapping fashion. To permit this sharing, the processor must duplicate the independent state of each thread.
Q4) What are multiprocessors? Mention the categories of multiprocessors?
A4)
Multiprocessor are used to increase performance and improve availability.
The different categories are SISD, SIMD, MIMD.
Q5) What are two main approaches to multithreading?
A5)
- Fine-grained multithreading
- Coarse-grained multithreading
Q6) What is the need to use multiprocessors?
A6)
1. Microprocessors as the fastest CPUs
Collecting several much easier than redesigning 1
2. Complexity of current microprocessors
Do we have enough ideas to sustain 1.5X/yr?
Can we deliver such complexity on schedule?
3. Slow (but steady) improvement in parallel software (scientific apps, databases, OS)
4. Emergence of embedded and server markets driving microprocessors in addition to desktops
Embedded functional parallelism, producer/consumer model
5. Server figure of merit is tasks per hour vs. Latency.
Q7) Write the advantages of Multithreading.
A7)
If a thread gets a lot of cache misses, the other thread(s) can continue, taking advantage of the unused computing resources, which thus can lead to faster overall execution, as these resources would have been idle if only a single thread was executed. If a thread cannot use all the computing resources of the CPU (because instructions depend on each other's result), running another thread permits to not leave these idle.
If several threads work on the same set of data, they can actually share their cache, leading to better cache usage or synchronization on its values.
Q8) Write the disadvantages of Multithreading.
A8)
Multiple threads can interfere with each other when sharing hardware resources such as caches or translation lookaside buffers (TLBs). Execution times of a single-thread are not improved but can be degraded, even when only one thread is executing. This is due to slower frequencies and/or additional pipeline stages that arc necessary to accommodate thread-switching hardware. Hardware support for Multithreading is more visible to software, thus requiring more changes to both application programs and operating systems than Multi processing.
Q9) What is CMT?
A9)
Chip multiprocessors - also called multi-core microprocessors or CMPs for short - are now the only way to build high-performance microprocessors, for a variety of reasons. Large uniprocessors are no longer scaling in performance, because it is only possible to extract a limited amount of parallelism from a typical instruction stream using conventional superscalar instruction issue techniques. In addition, one cannot simply ratchet up the clock speed on today's processors, or the power dissipation will become prohibitive in all but water-cooled systems.
Q10) What is SMT?
A10)
Simultaneous multithreading, often abbreviated as SMT, is a technique for improving the overall efficiency of superscalar CPUs with hardware multithreading. SMT permits multiple independent threads of execution to better utilize the resources provided by modern processor architectures.
Q11) Write the advantages of CMP?
A11)
CMPs have several advantages over single processor solutions energy and silicon area efficiency
i. By Incorporating smaller less complex cores onto a single chip
Ii. Dynamically switching between cores and powering down unused cores
Iii. Increased throughput performance by exploiting parallelism
Iv. Multiple computing resources can take better advantage of instruction, thread, and process level
Q12) What are the Disadvantages of SMT?
A12)
Simultaneous multithreading cannot improve performance if any of the shared resources are limiting bottlenecks for the performance. In fact, some applications run slower when simultaneous multithreading is enabled. Critics argue that it is a considerable burden to put on software developers that they have to test whether simultaneous multithreading is good or bad for their application in various situations and insert extra logic to turn it off if it decreases performance.
Q13) What are the types of Multithreading?
A13)
- Block multi-threading
- Interleaved multi-threading
Q14) What Thread-level parallelism (TLP)?
A14)
- Explicit parallel programs already have TLP (inherent)
- Sequential programs that are hard to parallelize or ILP-limited can be speculatively parallelized in
Hardware.
Q15) List the major MIMD Styles?
A15)
Centralized shared memory ("Uniform Memory Access" time or "Shared Memory Processor") Decentralized memory (memory module CPU) get more memory bandwidth, lower memory
Drawback:
Longer communication latency and Software model more complex
Q16) Distinguish between shared memory multiprocessor and message-passing multiprocessor.
A16)
- A multiprocessor with a shared address space, that address space can be used to communicate data implicitly via load and store operations is shared memory multiprocessor.
- A multiprocessor with a multiple address space, communication of data is done by explicitly passing message among processor is message-passing multiprocessor.
Q17) Draw the basic structure of Basic Structure of a Symmetric Shared Memory Multiprocessor
A17)
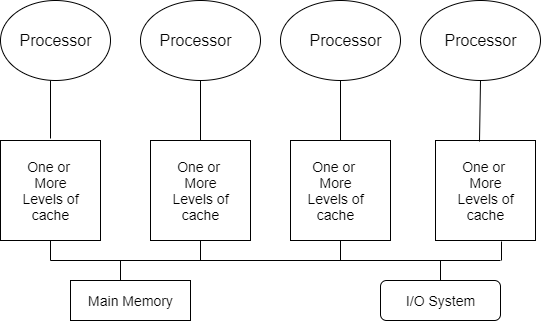
Q18) What is multicore?
A18)
At its simplest, multi-core is a design in which a single physical processor contains the core logic of more than one processor. It's as if an Intel Xeon processor were opened up and inside were packaged all the circuitry and logic for two (or more) Intel Xcon processors. The multi-core design takes several such processor "cores" and packages them as a single physical processor. The goal of this design is to enable a system to run more tasks simultaneously and thereby achieve greater overall system performance.
Q19) Write the software implications of a multicore processor?
A19)
Multi-core systems will deliver benefits to all software, but especially multi-threaded programs. All code that supports HT Technology or multiple processors, for example, will benefit automatically from multi-core processors, without need for modification. Most server-side enterprise packages and many desktop productivity tools fall into this category.
Q20) What is coarse grained multithreading?
A20)
It switches threads only on costly stalls. Thus, it is much less likely to slow down the execution an individual thread.
Q21) Define Memory Hierarchy?
A21)
A memory unit is the collection of storage units or devices together. The memory unit stores the binary information in the form of bits.
Memory Hierarchy is an enhancement to organize the memory such that it can minimize the access time. The Memory Hierarchy was developed based on a program behaviour known as locality of references.
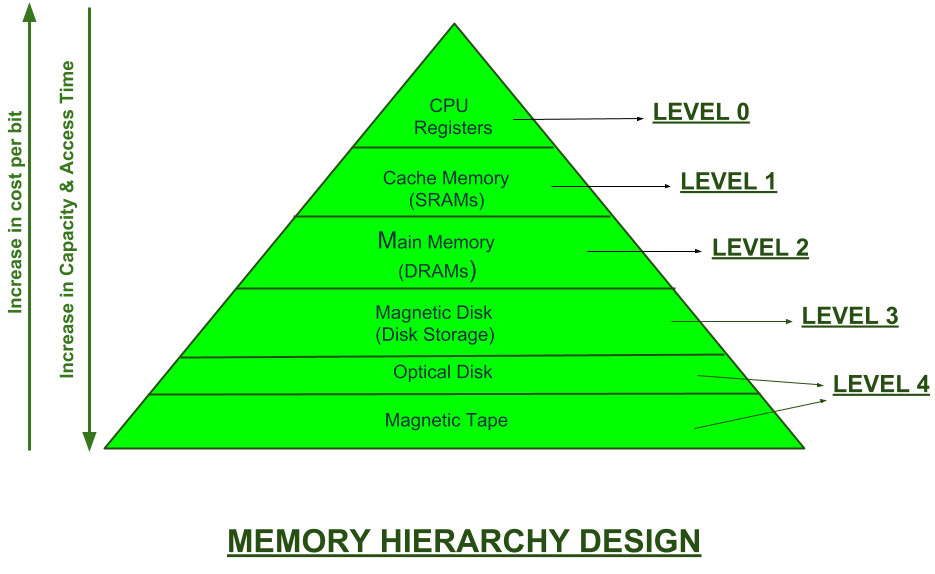
Memory Hierarchy is divided into 2 main types:
- External Memory or Secondary Memory –
Comprising of Magnetic Disk, Optical Disk, Magnetic Tape i.e., peripheral storage devices which are accessible by the processor via I/O Module.
2. Internal Memory or Primary Memory –
Comprising of Main Memory, Cache Memory & CPU registers. This is directly accessible by the processor.
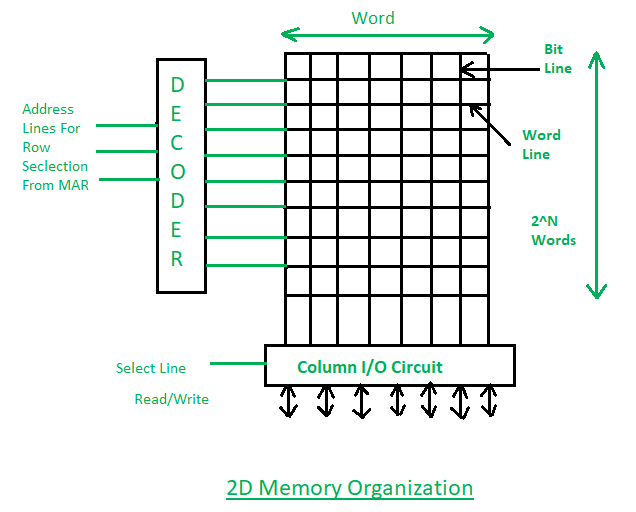
Q22) Define 2D & 2 1/2D memory organization?
A22)
2D Memory Organization has following properties:
1. Basically in 2D organization memory is divides in the form of rows and columns.
2. Each row contains a word now in this memory organization there is a decoder.
3. A decoder is a combinational circuit which contains n input lines and 2n output lines. One of the output lines will select the row which address is contained in the MAR.
4. And the word which is represented by the row that will get selected and either read or write through the data lines.
2.5D Memory Organization has following properties:
1. In 2.5D Organization the scenario is the same but we have two different decoders one is column decoder and another is row decoder.
2. Column decoder used to select the column and row decoder is used to select the row. Address from the MAR will go in decoders’ input. Decoders will select the respective cell.
3. Through the bit outline, the data from that location will be read or through the bit in line data will be written at that memory location.
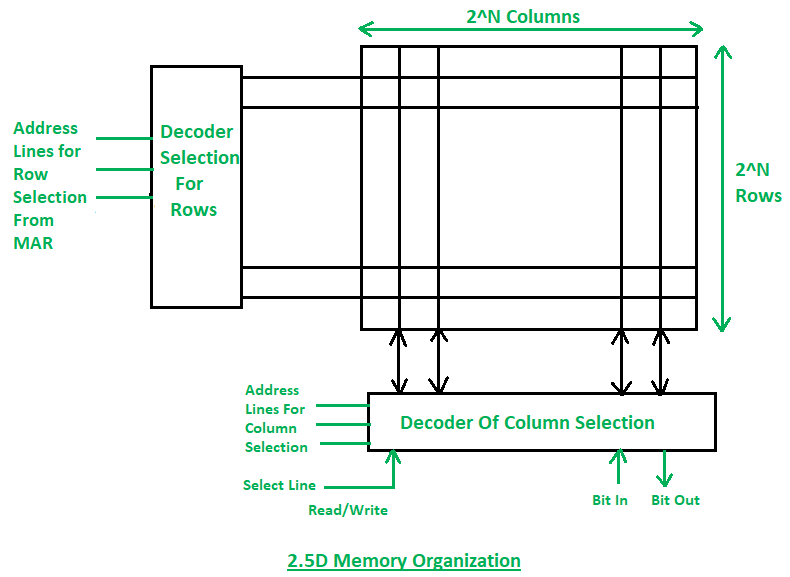
Comparison between 2D & 2.5D Organizations:
1. In 2D organization hardware is fixed but in 2.5D hardware changes.
2. 2D Organization requires more no. Of Gates while 2.5D requires less no. Of Gates.
3. 2D is more complex in comparison to the 2.5D Organization.
4. Error correction is not possible in the 2D organization but in 2.5D error correction is easy.
5. 2D is more difficult to fabricate in comparison to the 2.5D organization.
Q23) Define Direct Mapping and Set Associative Mapping?
A23)
Direct Mapping:
- The simplest technique, known as direct mapping, maps each block of main memory into only one possible cache line.
- In Direct mapping, assigned each memory block to a specific line in the cache. If a line is previously taken up by a memory block when a new block needs to be loaded, the old block is trashed.
- An address space is split into two parts index field and a tag field. The cache is used to store the tag field whereas the rest is stored in the main memory.
- Direct mappings performance is directly proportional to the Hit ratio.
- For purposes of cache access, each main memory address can be viewed as consisting of three fields. The least significant w bits identify a unique word or byte within a block of main memory. In most contemporary machines, the address is at the byte level. The remaining s bits specify one of the 2s blocks of main memory.
- The cache logic interprets these s bits as a tag of s-r bits (most significant portion) and a line field of r bits. This latter field identifies one of the m=2r lines of the cache.
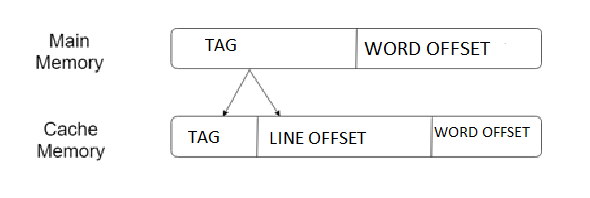
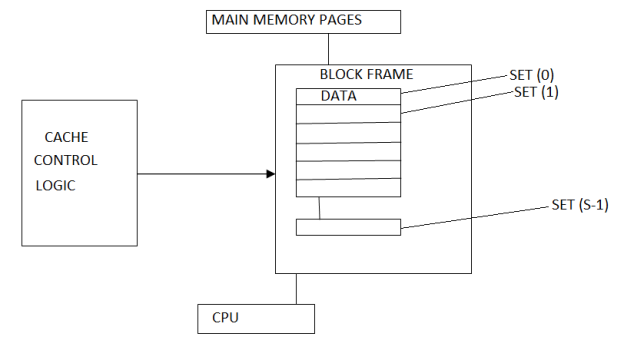
Figure: Direct Mapping Process
Associative Mapping:
- The associative memory is used to store content and addresses of the memory word.
- Any block can go into any line of the cache i.e., that the word id bits are used to identify which word in the block is needed, but the tag becomes all of the remaining bits.
- It is considered to be the fastest and the most flexible mapping form.
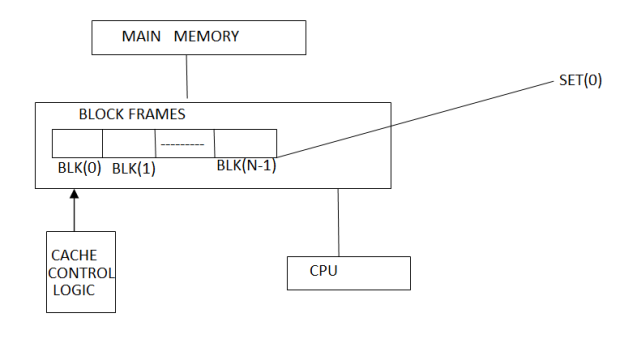
Figure: Associative Mapping
Set Associative Mapping:
- Set associative memory is an enhanced form of direct mapping; it removes the drawback of direct mapping.
- Set associative addresses the problem of thrashing in the direct mapping method, it does this by saying that instead of having exactly one line that a block can map to in the cache, will group a few lines together creating a set.
- Then a block in memory can map to any one of the lines of a specific set. Set-associative mapping allows that each word that is present in the cache can have two or more words in the main memory for the same index address.
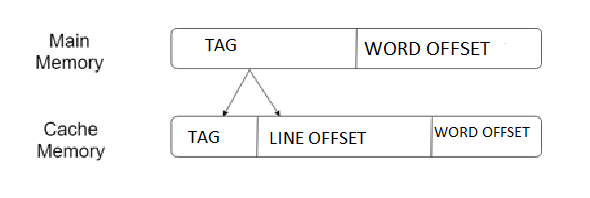
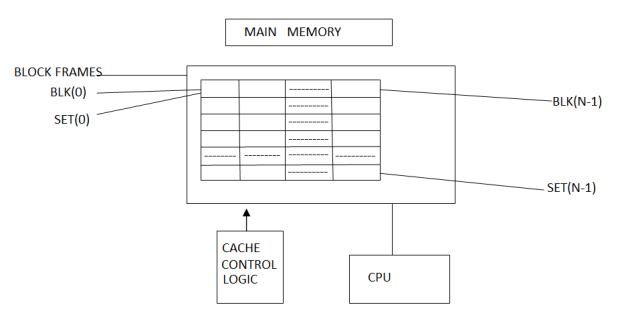
Figure: Set Associative Mapping
Q24) What do you mean by Page Replacement Algorithms?
A24)
Page replacement algorithms are the techniques using which an Operating System decides which memory pages to swap out, write to disk when a page of memory needs to be allocated. Paging happens whenever a page fault occurs and a free page cannot be used for allocation purpose accounting to reason that page are not available or the number of free pages is lower than required pages.
When the page that was selected for replacement and was paged out, is referenced again, it has to read in from disk, and this requires for I/O completion. This process determines the quality of the page replacement algorithm: the lesser the time waiting for page-ins, the better is the algorithm.
A page replacement algorithm looks at the limited information about accessing the pages provided by hardware, and tries to select which pages should be replaced to minimize the total number of page misses, while balancing it with the costs of primary storage and processor time of the algorithm itself. There are many different page replacement algorithms. We evaluate an algorithm by running it on a particular string of memory reference and computing the number of page faults,
Reference String
The string of memory references is called reference string. Reference strings are generated artificially or by tracing a given system and recording the address of each memory reference. The latter choice produces a large number of data, where we note two things.
- For a given page size, we need to consider only the page number, not the entire address.
- If we have a reference to a page p, then any immediately following references to page p will never cause a page fault. Page p will be in memory after the first reference; the immediately following references will not fault.
- For example, consider the following sequence of addresses − 123,215,600,1234,76,96
- If page size is 100, then the reference string is 1,2,6,12,0,0
First In First Out (FIFO) algorithm
- Oldest page in main memory is the one which will be selected for replacement.
- Easy to implement, keep a list, replace pages from the tail and add new pages at the head.
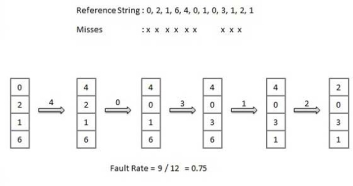
Optimal Page algorithm
- An optimal page-replacement algorithm has the lowest page-fault rate of all algorithms. An optimal page-replacement algorithm exists, and has been called OPT or MIN.
- Replace the page that will not be used for the longest period of time. Use the time when a page is to be used.
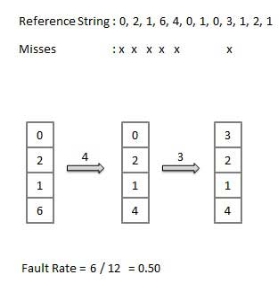
Least Recently Used (LRU) algorithm
- Page which has not been used for the longest time in main memory is the one which will be selected for replacement.
- Easy to implement, keep a list, replace pages by looking back into time.
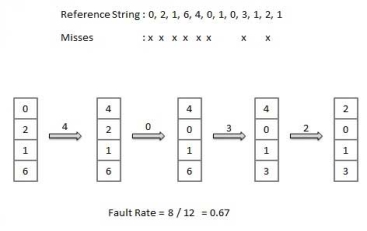
Page Buffering algorithm
- To get a process start quickly, keep a pool of free frames.
- On page fault, select a page to be replaced.
- Write the new page in the frame of free pool, mark the page table and restart the process.
- Now write the dirty page out of disk and place the frame holding replaced page in free pool.
Least frequently Used (LFU) algorithm
- The page with the smallest count is the one which will be selected for replacement.
- This algorithm suffers from the situation in which a page is used heavily during the initial phase of a process, but then is never used again.
Most frequently Used (MFU) algorithm
- This algorithm is based on the argument that the page with the smallest count was probably just brought in and has yet to be used.




