Unit 2
Regular Expressions and Languages
Q.1 ) Explain the regular language with example ?
Sol : Regular language -
● Simple expressions called Regular Expressions can readily define the language adopted by finite automata. This is the most powerful way of expressing any language.
● Regular languages are referred to as the languages recognised by certain regular expressions.
● A regular expression may also be defined as a pattern sequence that defines a series.
● For matching character combinations in strings, regular expressions are used. This pattern is used by the string search algorithm to locate operations on a string.
A Regular Expression can be recursively defined as follows -
● ε is a Regular Expression indicates the language containing an empty string. (L (ε) = {ε})
● φ is a Regular Expression denoting an empty language. (L (φ) = { })
● x is a Regular Expression where L = {x}
● If X is a Regular Expression denoting the language L(X) and Y is a Regular Expression denoting the language L(Y), then
➢ X + Y is a Regular Expression corresponding to the language L(X) ∪ L(Y) where L(X+Y) = L(X) ∪ L(Y).
➢ X . Y is a Regular Expression corresponding to the language L(X) . L(Y) where L(X.Y) = L(X) . L(Y)
➢ R* is a Regular Expression corresponding to the language L(R*)where L(R*) = (L(R))*
Example :
Write the regular expression beginning with a but not including consecutive b's for the language.
Sol : The regular expression has to be create for the language:
L = {a, aba, aab, aba, aaa, abab, .....}
Q.2 ) write down the closure property of regular language ?
Sol : Regular languages are closed under a wide variety of operations.
Union and intersection -
Pick DFAs recognizing the two languages and use the cross-product
Construction to build a DFA recognizing their union or intersection.
Set complement -
Pick a DFA recognizing the language, then swap the accept/non-accept
Markings on its states.
Set difference -
Rewrite set difference using a combination of intersection and set
Complement
Concatenation and Star -
Pick an NFA recognizing the language and modify it
Homomorphism -
A homomorphism is a function from strings to strings. What makes it a
Homomorphism is that its output on a multi-character string is just the
Concatenation of its outputs on each individual character in the string. Or,
Equivalently, h(xy) = h(x)h(y) for any strings x and y. If S is a set of strings,
Then h(S) is {w : w = h(x) for some x in S}.
To show that regular languages are closed under homomorphism, choose
An arbitrary regular language L and a homomorphism h. It can be
Represented using a regular expression R. But then h(R) is a regular
Expression representing h(L). So h(L) must also be regular.
Notice that regular languages are not closed under the subset/superset relation. For
Example, 0 * 1 * is regular, but its subset {O n 1 n : n >= 0} is not regular, but its subset {01,0011, 000111} is regular again.
Q.3 ) what are the application of regular expression ?
Sol :
★ Regular Expressions in Software Engineering
● The usefulness of regular languages in this comes from the fact that regular languages deal in the finite which is true in reference to a computer.
● Regular expressions are also used in test case characterizations. These test case characterizations are related to the programs directly, or to the corresponding models for it.
● Regular language theory is used to handle paths, and regular expressions are used over the terminals and no terminals of the paths, which are called “regular path expressions.”
● A regular expression is sufficient enough to abstractly describe a test case or a class of test cases, but sets of expressions require their own criteria. The use of regular language theory makes it easy for coverage analysis and test set generation.
● Regression testing is an important part of the software development cycle. It is a process that is used to determine if a modified program still meets its specifications or if new errors have been found.
★ Regular Expressions in Lexical Analysis
● Lexical analysis is the process of tokenizing a sequence of symbols to eventually parse a string. To perform lexical analysis, two components are required: a scanner and a tokenizer.
● A token is simply a block of symbols, also known as a lexeme. The purpose of tokenization is to categorize the lexemes found in a string to sort them by meaning.
● For example, the C programming language could contain tokens such as numbers, string constants, characters, identifiers (variable names), keywords, or operators.
● The best way to define a token is by a regular expression. Scanning process can be quite complex and may require more than one pass to complete.
● Backtracking is rereading an earlier part of a string to see if it matches a regular expression based on some information that could only be obtained by analyzing a later part of the string.
● For example, to determine if a lexeme is a valid identifier in C, we could use the following regular expression:
[a-zA-Z ][a-zA-Z 0-9]∗
This regular expression says that identifiers must begin with a Roman letter or an
Underscore and may be followed by any number of letters, underscores, or numbers.
Q.4 ) What is the Algebraic law of regular expression in automata ?
Sol : A regular expression is an algebraic formula whose value is a pattern consisting of a set of strings, called the language of the expression.
Operands in a regular expression can be:
❏ characters
❏ variables
❏ epsilon
❏ null
Operators used in regular expressions include:
● Union: If R1 and R2 are regular expressions, then R1 | R2 (also written as R1 U R2 or R1 + R2) is also a regular expression.
L(R1|R2) = L(R1) U L(R2).
● Concatenation: If R1 and R2 are regular expressions, then R1R2 (also written as R1.R2) is also a regular expression.
L(R1R2) = L(R1) concatenated with L(R2).
● Kleene closure: If R1 is a regular expression, then R1* (the Kleene closure of R1) is also a regular expression.
L(R1*) = epsilon U L(R1) U L(R1R1) U L(R1R1R1) U …
Closure has the highest precedence, followed by concatenation, followed by union.
Examples
The set of strings over {0,1} that end in 3 consecutive 1's.
(0 | 1)* 111
The set of strings over {0,1} that have at least one 1.
0* 1 (0 | 1)*
The set of strings over {0,1} that have at most one 1.
0* | 0* 1 0*
The set of strings over {A..Z,a..z} that contain the word "main".
Let <letter> = A | B | ... | Z | a | b | ... | z
<letter>* main <letter>*
The set of strings over {A..Z,a..z} that contain 3 x’s.
<letter>* x <letter>* x <letter>* x <letter>*
The set of identifiers in Pascal.
Let <letter> = A | B | ... | Z | a | b | ... | z
Let <digit> = 0 | 1 | 2 | 3 ... | 9
<letter> (<letter> | <digit>)*
The set of real numbers in Pascal.
Let <digit> = 0 | 1 | 2 | 3 ... | 9
Let <exp> = ‘E’ <sign><digit><digit>* | epsilon
Let <sign> = ‘+’ | ‘-’ | epsilon
Let <decimal> = ‘.’ <digit><digit>* | epsilon
<digit><digit>* <decimal><exp>
Q.5 ) Construct an FA (finite automata) from an RE(regular expression) and also write the algorithm for eliminating epsilon transitions ?
Sol : Construct a FA from RE
We begin by showing how to construct an FA for the operands in a regular
Expression.
● If the operand is a character c, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and a transition from s0 to sF with label c.
● If the operand is epsilon, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and an epsilon transition from s0 to sF.
● If the operand is null, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and no transitions.
Given FA for R1 and R2, we now show how to build an FA for R1R2, R1|R2, and
R1*. Let A (with start state a0 and final state aF) be the machine accepting L(R1)
And B (with start state b0 and final state bF) be the machine accepting L(R2).
● The machine C accepting L(R1R2) includes A and B, with start state a0, final state bF, and an epsilon transition from aF to b0.
● The machine C accepting L(R1|R2) includes A and B, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and b0, and from aF and bF to cF.
● The machine C accepting L(R1*) includes A, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and cF, and from aF to a0, and from aF to cF.
Algorithm for Eliminating Epsilon Transitions
A finite automaton F2 can be build with no epsilon transitions from a finite
Automaton F1 as follows:
1. The states of F2 are all the states of F1 that have an entering transition
Labeled by some symbol other than epsilon, plus the start state of F1, which is
Also the start state of F2.
2. For each state in F1, determine which other states are reachable via epsilon
Transitions only. If a state of F1 can reach a final state in F1 via epsilon
Transitions, then the corresponding state is a final state in F2.
For each pair of states i and j in F2, there is a transition from state i to state j on input
x if there exists a state k that is reachable from state i via epsilon transitions in F1,
And there is a transition in F1 from state k to state j on input x.
Q.6 ) Define the transition graph ?
Sol : It is possible to view the transition graph as a flowchart for a language recognising algorithm. Three items consist of a transition graph:
- A finite set of states, some of which are designated as final states, and at least one of which is designated as the starting state.
- An alphabet of possible input symbols that form the input strings.
- A finite set of transitions that represent on a given input the change of state from the given state.
An effective path through the graph of transition is a set of edges that form a path starting at the beginning state and ending at one of the final states.
Some of the transition graphs are given below -
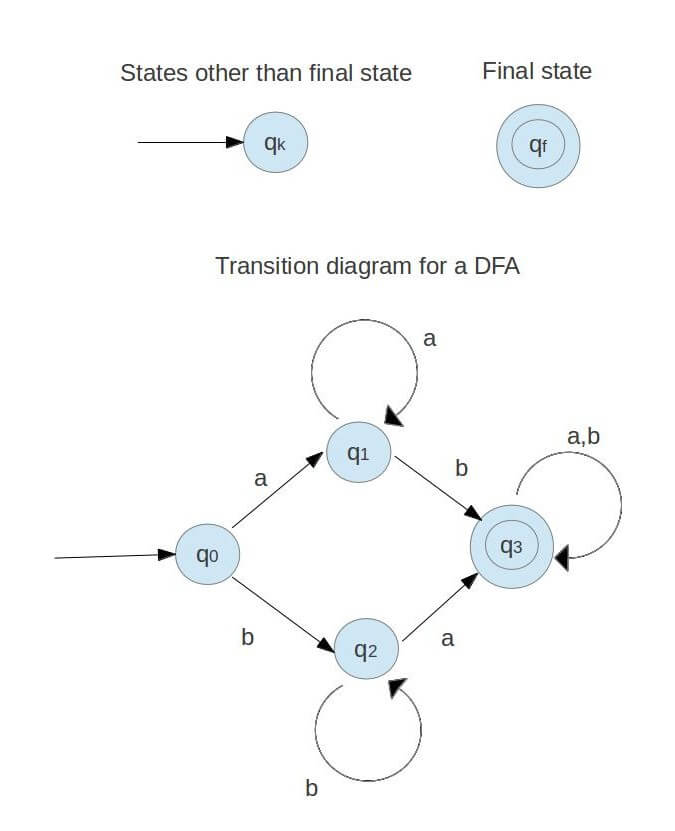
Fig : transition graph for DFA
Q.7 ) For the given DFA construct the regular expression ?
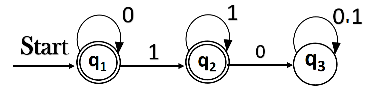
Sol : Let’s write the equation :
q1 = q1 0 + ε
Here q1 is the starting state, then ε added and input 0 is coming to q1 from q1. Hence write
State = source state of input × input coming to it
Likewise,
q2 = q1 1 + q2 1
q3 = q2 0 + q3 (0+1)
So, the final state is q1 and q2 . Here we are solving only q1 and q2 only. Let’s see q1 first
q1 = q1 0 + ε
Rewrite the above statement
q1 = ε + q1 0
This is similar to R = Q + RP, and gets reduced to R = OP*.
Hence , R = q1, Q = ε, P = 0
Then we get
q1 = ε.(0)*
q1 = 0* (ε.R*= R*)
Replace the value into q2, then we will get
q2 = 0* 1 + q2 1
q2 = 0* 1 (1)* (R = Q + RP → Q P*)
The regular expression is given by
r = q1 + q2
= 0* + 0* 1.1*
r = 0* + 0* 1+ (1.1* = 1+)
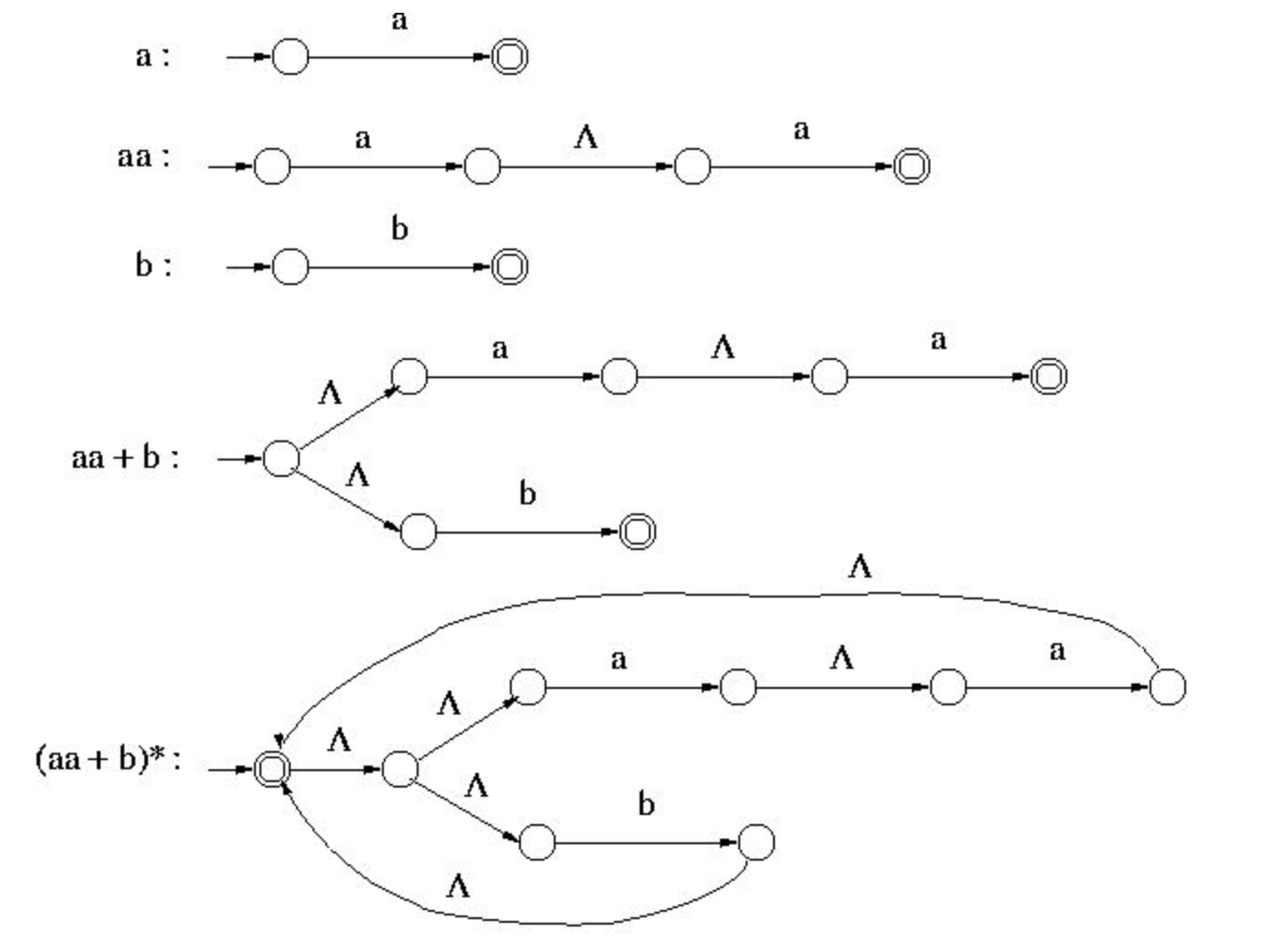
Q.8 ) Write Kleen’s theorem with some example ?
Sol : Kleen’s theorem states that an FA accepts any regular language and, conversely, that any language that an FA accepts is regular.
Theorem 1: A finite automatic acknowledges every normal language.
Proof : The general induction following the recursive description of regular language would prove this
Common step : The languages 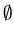 , {
, {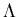 } and { a } for any symbol a in
} and { a } for any symbol a in  are accepted by an FA.
are accepted by an FA.
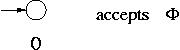
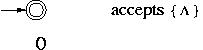

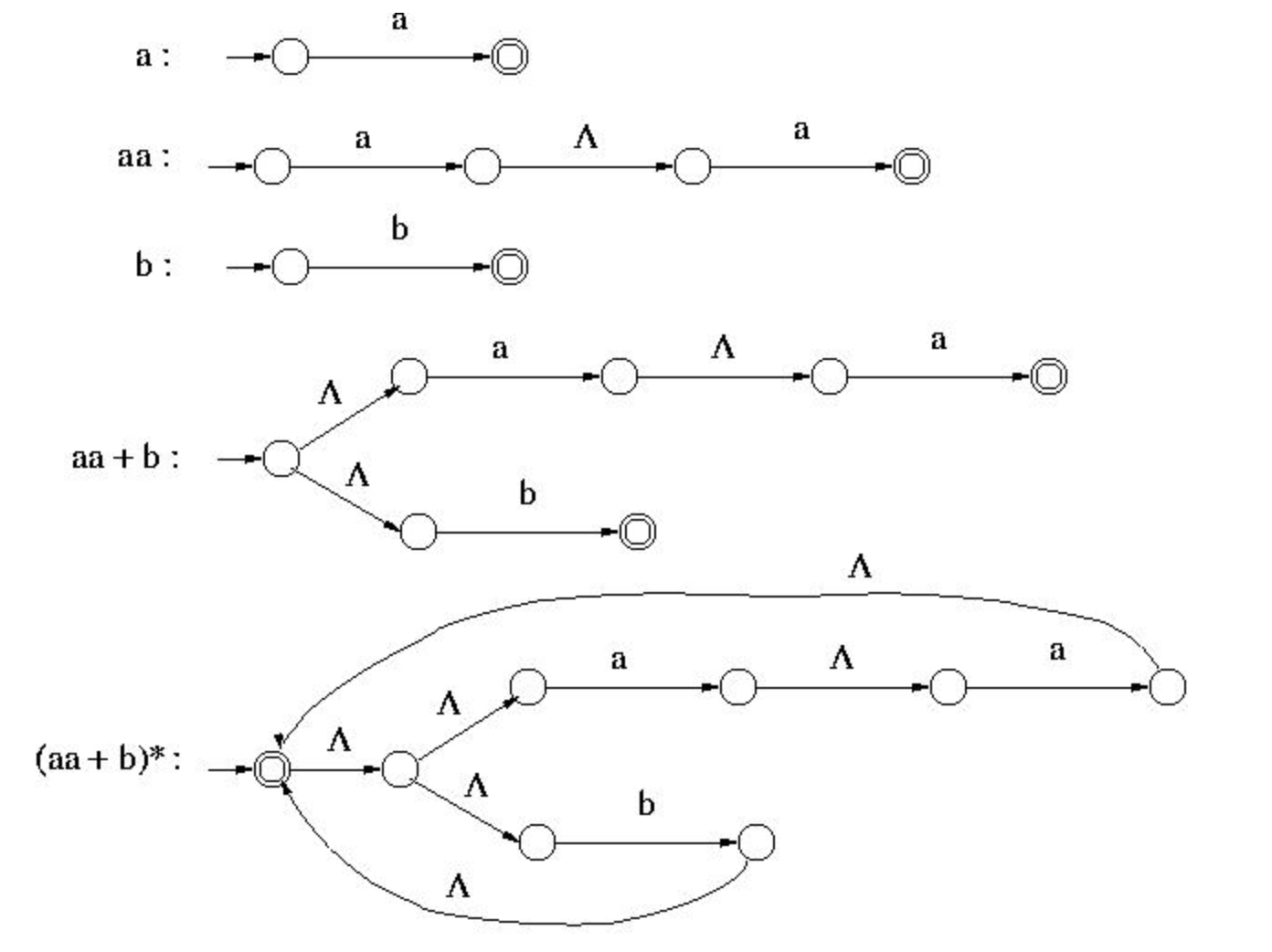
Example :
An NFA- that accepts the language represented by the regular expression is given - (aa + b)*
that accepts the language represented by the regular expression is given - (aa + b)*
The given regular expression can be constructed using the operation , as below
Q.9 ) Describe the Equivalence and minimization of automata and write the algorithm with suitable example?
Sol : If X and Y are two states in a DFA, we can combine these two states into {X, Y} if
They are not distinguishable. Two states are distinguishable, if there is at least one string S, such that one of δ (X, S) and δ (Y, S) is accepting and another is not accepting.
Hence, a DFA is minimal if and only if all the states are distinguishable.
Algorithm
Step 1: All the states Q are divided in two partitions: final states and non-final
States and are denoted by P0. All the states in a partition are 0 th equivalent. Take a
Counter k and initialize it with 0.
Step 2: Increment k by 1. For each partition in Pk, divide the states in Pk into two
Partitions if they are k-distinguishable. Two states within this partition X and Y are k-
Distinguishable if there is an input S such that δ(X, S) and δ(Y, S) are (k-1)-
Distinguishable.
Step 3: If Pk ≠ Pk-1, repeat Step 2, otherwise go to Step 4.
Step 4: Combine k th equivalent sets and make them the new states of the reduced
DFA.
Example
Let us consider the following DFA:
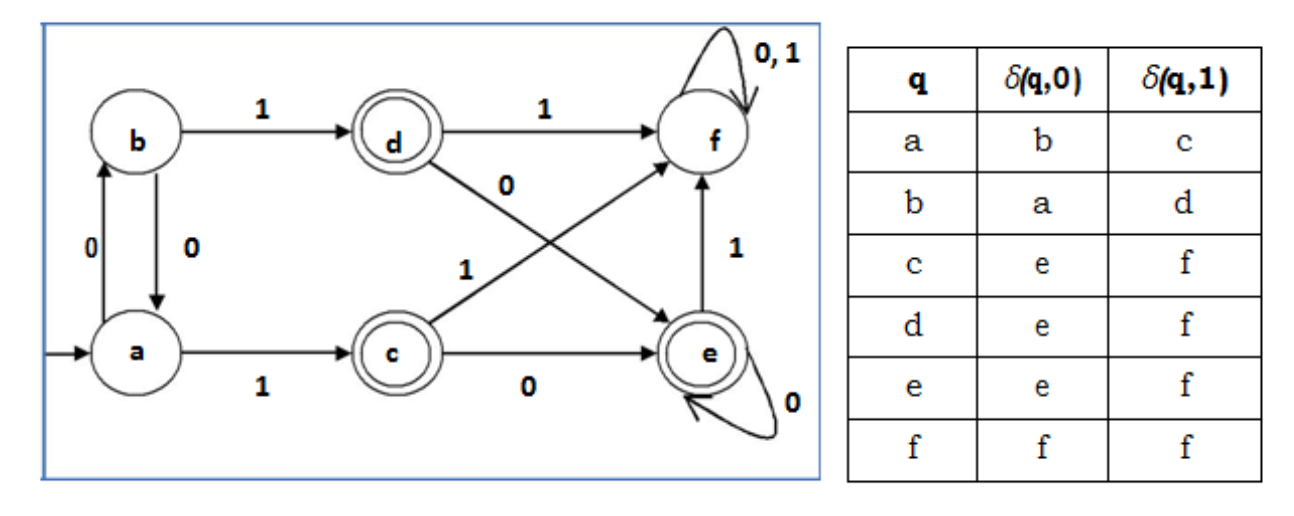
Fig : example of DFA
Let us apply Algorithm 3 to the above DFA:
· P0 = {(c,d,e), (a,b,f)}
· P1 = {(c,d,e), (a,b),(f)}
· P2 = {(c,d,e), (a,b),(f)}
Hence, P1 = P2.
There are three states in the reduced DFA. The reduced DFA is as follows:
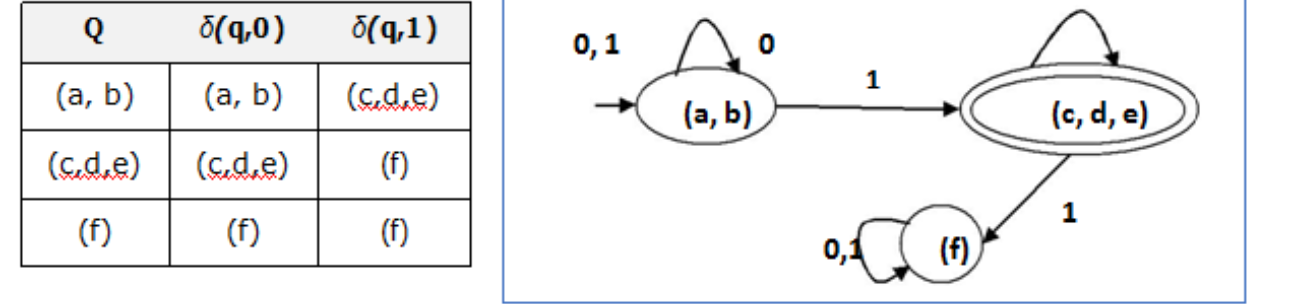
Fig : State Table and State Diagram of Reduced DFA
Q.10 ) Define the Arden’s theorem ?
Sol : Arden’s theorem
★ The Arden's Theorem is useful both for testing the equivalence of two regular phrases and for converting the DFA to a regular phrase.
★ In the conversion of DFA to a regular expression, let us see its use.
★ There are some algorithms used to build the regular expression form given in the DFA.
1. Let q1 be the initial state.
2. There are q2, q3, q4 ....qn number of states. The final state may be some qj where j<= n.
3. Let αji represents the transition from qj to qi.
4. Calculate qi such that
qi = αji * qj
If qj is a start state then we have:
qi = αji * qj + ε
5. Similarly, compute the final state which ultimately gives the regular expression 'r'.
Unit 2
Regular Expressions and Languages
Q.1 ) Explain the regular language with example ?
Sol : Regular language -
● Simple expressions called Regular Expressions can readily define the language adopted by finite automata. This is the most powerful way of expressing any language.
● Regular languages are referred to as the languages recognised by certain regular expressions.
● A regular expression may also be defined as a pattern sequence that defines a series.
● For matching character combinations in strings, regular expressions are used. This pattern is used by the string search algorithm to locate operations on a string.
A Regular Expression can be recursively defined as follows -
● ε is a Regular Expression indicates the language containing an empty string. (L (ε) = {ε})
● φ is a Regular Expression denoting an empty language. (L (φ) = { })
● x is a Regular Expression where L = {x}
● If X is a Regular Expression denoting the language L(X) and Y is a Regular Expression denoting the language L(Y), then
➢ X + Y is a Regular Expression corresponding to the language L(X) ∪ L(Y) where L(X+Y) = L(X) ∪ L(Y).
➢ X . Y is a Regular Expression corresponding to the language L(X) . L(Y) where L(X.Y) = L(X) . L(Y)
➢ R* is a Regular Expression corresponding to the language L(R*)where L(R*) = (L(R))*
Example :
Write the regular expression beginning with a but not including consecutive b's for the language.
Sol : The regular expression has to be create for the language:
L = {a, aba, aab, aba, aaa, abab, .....}
Q.2 ) write down the closure property of regular language ?
Sol : Regular languages are closed under a wide variety of operations.
Union and intersection -
Pick DFAs recognizing the two languages and use the cross-product
Construction to build a DFA recognizing their union or intersection.
Set complement -
Pick a DFA recognizing the language, then swap the accept/non-accept
Markings on its states.
Set difference -
Rewrite set difference using a combination of intersection and set
Complement
Concatenation and Star -
Pick an NFA recognizing the language and modify it
Homomorphism -
A homomorphism is a function from strings to strings. What makes it a
Homomorphism is that its output on a multi-character string is just the
Concatenation of its outputs on each individual character in the string. Or,
Equivalently, h(xy) = h(x)h(y) for any strings x and y. If S is a set of strings,
Then h(S) is {w : w = h(x) for some x in S}.
To show that regular languages are closed under homomorphism, choose
An arbitrary regular language L and a homomorphism h. It can be
Represented using a regular expression R. But then h(R) is a regular
Expression representing h(L). So h(L) must also be regular.
Notice that regular languages are not closed under the subset/superset relation. For
Example, 0 * 1 * is regular, but its subset {O n 1 n : n >= 0} is not regular, but its subset {01,0011, 000111} is regular again.
Q.3 ) what are the application of regular expression ?
Sol :
★ Regular Expressions in Software Engineering
● The usefulness of regular languages in this comes from the fact that regular languages deal in the finite which is true in reference to a computer.
● Regular expressions are also used in test case characterizations. These test case characterizations are related to the programs directly, or to the corresponding models for it.
● Regular language theory is used to handle paths, and regular expressions are used over the terminals and no terminals of the paths, which are called “regular path expressions.”
● A regular expression is sufficient enough to abstractly describe a test case or a class of test cases, but sets of expressions require their own criteria. The use of regular language theory makes it easy for coverage analysis and test set generation.
● Regression testing is an important part of the software development cycle. It is a process that is used to determine if a modified program still meets its specifications or if new errors have been found.
★ Regular Expressions in Lexical Analysis
● Lexical analysis is the process of tokenizing a sequence of symbols to eventually parse a string. To perform lexical analysis, two components are required: a scanner and a tokenizer.
● A token is simply a block of symbols, also known as a lexeme. The purpose of tokenization is to categorize the lexemes found in a string to sort them by meaning.
● For example, the C programming language could contain tokens such as numbers, string constants, characters, identifiers (variable names), keywords, or operators.
● The best way to define a token is by a regular expression. Scanning process can be quite complex and may require more than one pass to complete.
● Backtracking is rereading an earlier part of a string to see if it matches a regular expression based on some information that could only be obtained by analyzing a later part of the string.
● For example, to determine if a lexeme is a valid identifier in C, we could use the following regular expression:
[a-zA-Z ][a-zA-Z 0-9]∗
This regular expression says that identifiers must begin with a Roman letter or an
Underscore and may be followed by any number of letters, underscores, or numbers.
Q.4 ) What is the Algebraic law of regular expression in automata ?
Sol : A regular expression is an algebraic formula whose value is a pattern consisting of a set of strings, called the language of the expression.
Operands in a regular expression can be:
❏ characters
❏ variables
❏ epsilon
❏ null
Operators used in regular expressions include:
● Union: If R1 and R2 are regular expressions, then R1 | R2 (also written as R1 U R2 or R1 + R2) is also a regular expression.
L(R1|R2) = L(R1) U L(R2).
● Concatenation: If R1 and R2 are regular expressions, then R1R2 (also written as R1.R2) is also a regular expression.
L(R1R2) = L(R1) concatenated with L(R2).
● Kleene closure: If R1 is a regular expression, then R1* (the Kleene closure of R1) is also a regular expression.
L(R1*) = epsilon U L(R1) U L(R1R1) U L(R1R1R1) U …
Closure has the highest precedence, followed by concatenation, followed by union.
Examples
The set of strings over {0,1} that end in 3 consecutive 1's.
(0 | 1)* 111
The set of strings over {0,1} that have at least one 1.
0* 1 (0 | 1)*
The set of strings over {0,1} that have at most one 1.
0* | 0* 1 0*
The set of strings over {A..Z,a..z} that contain the word "main".
Let <letter> = A | B | ... | Z | a | b | ... | z
<letter>* main <letter>*
The set of strings over {A..Z,a..z} that contain 3 x’s.
<letter>* x <letter>* x <letter>* x <letter>*
The set of identifiers in Pascal.
Let <letter> = A | B | ... | Z | a | b | ... | z
Let <digit> = 0 | 1 | 2 | 3 ... | 9
<letter> (<letter> | <digit>)*
The set of real numbers in Pascal.
Let <digit> = 0 | 1 | 2 | 3 ... | 9
Let <exp> = ‘E’ <sign><digit><digit>* | epsilon
Let <sign> = ‘+’ | ‘-’ | epsilon
Let <decimal> = ‘.’ <digit><digit>* | epsilon
<digit><digit>* <decimal><exp>
Q.5 ) Construct an FA (finite automata) from an RE(regular expression) and also write the algorithm for eliminating epsilon transitions ?
Sol : Construct a FA from RE
We begin by showing how to construct an FA for the operands in a regular
Expression.
● If the operand is a character c, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and a transition from s0 to sF with label c.
● If the operand is epsilon, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and an epsilon transition from s0 to sF.
● If the operand is null, then our FA has two states, s0 (the start state) and sF (the final, accepting state), and no transitions.
Given FA for R1 and R2, we now show how to build an FA for R1R2, R1|R2, and
R1*. Let A (with start state a0 and final state aF) be the machine accepting L(R1)
And B (with start state b0 and final state bF) be the machine accepting L(R2).
● The machine C accepting L(R1R2) includes A and B, with start state a0, final state bF, and an epsilon transition from aF to b0.
● The machine C accepting L(R1|R2) includes A and B, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and b0, and from aF and bF to cF.
● The machine C accepting L(R1*) includes A, with a new start state c0, a new final state cF, and epsilon transitions from c0 to a0 and cF, and from aF to a0, and from aF to cF.
Algorithm for Eliminating Epsilon Transitions
A finite automaton F2 can be build with no epsilon transitions from a finite
Automaton F1 as follows:
1. The states of F2 are all the states of F1 that have an entering transition
Labeled by some symbol other than epsilon, plus the start state of F1, which is
Also the start state of F2.
2. For each state in F1, determine which other states are reachable via epsilon
Transitions only. If a state of F1 can reach a final state in F1 via epsilon
Transitions, then the corresponding state is a final state in F2.
For each pair of states i and j in F2, there is a transition from state i to state j on input
x if there exists a state k that is reachable from state i via epsilon transitions in F1,
And there is a transition in F1 from state k to state j on input x.
Q.6 ) Define the transition graph ?
Sol : It is possible to view the transition graph as a flowchart for a language recognising algorithm. Three items consist of a transition graph:
- A finite set of states, some of which are designated as final states, and at least one of which is designated as the starting state.
- An alphabet of possible input symbols that form the input strings.
- A finite set of transitions that represent on a given input the change of state from the given state.
An effective path through the graph of transition is a set of edges that form a path starting at the beginning state and ending at one of the final states.
Some of the transition graphs are given below -
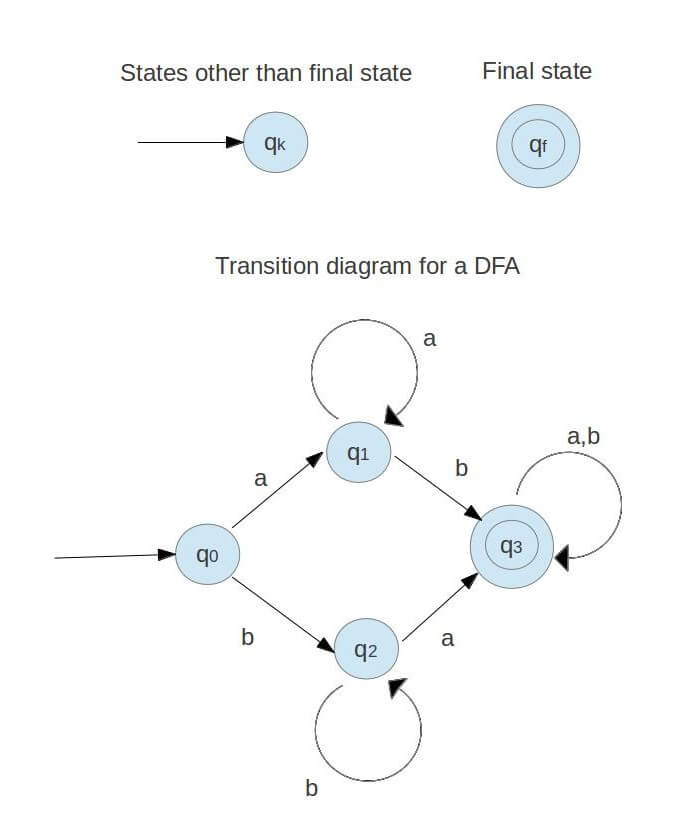
Fig : transition graph for DFA
Q.7 ) For the given DFA construct the regular expression ?
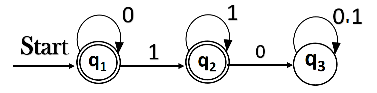
Sol : Let’s write the equation :
q1 = q1 0 + ε
Here q1 is the starting state, then ε added and input 0 is coming to q1 from q1. Hence write
State = source state of input × input coming to it
Likewise,
q2 = q1 1 + q2 1
q3 = q2 0 + q3 (0+1)
So, the final state is q1 and q2 . Here we are solving only q1 and q2 only. Let’s see q1 first
q1 = q1 0 + ε
Rewrite the above statement
q1 = ε + q1 0
This is similar to R = Q + RP, and gets reduced to R = OP*.
Hence , R = q1, Q = ε, P = 0
Then we get
q1 = ε.(0)*
q1 = 0* (ε.R*= R*)
Replace the value into q2, then we will get
q2 = 0* 1 + q2 1
q2 = 0* 1 (1)* (R = Q + RP → Q P*)
The regular expression is given by
r = q1 + q2
= 0* + 0* 1.1*
r = 0* + 0* 1+ (1.1* = 1+)
Q.8 ) Write Kleen’s theorem with some example ?
Sol : Kleen’s theorem states that an FA accepts any regular language and, conversely, that any language that an FA accepts is regular.
Theorem 1: A finite automatic acknowledges every normal language.
Proof : The general induction following the recursive description of regular language would prove this
Common step : The languages 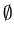 , {
, {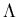 } and { a } for any symbol a in
} and { a } for any symbol a in 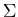 are accepted by an FA.
are accepted by an FA.
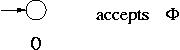
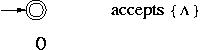

Example :
An NFA- that accepts the language represented by the regular expression is given - (aa + b)*
that accepts the language represented by the regular expression is given - (aa + b)*
The given regular expression can be constructed using the operation , as below
Q.9 ) Describe the Equivalence and minimization of automata and write the algorithm with suitable example?
Sol : If X and Y are two states in a DFA, we can combine these two states into {X, Y} if
They are not distinguishable. Two states are distinguishable, if there is at least one string S, such that one of δ (X, S) and δ (Y, S) is accepting and another is not accepting.
Hence, a DFA is minimal if and only if all the states are distinguishable.
Algorithm
Step 1: All the states Q are divided in two partitions: final states and non-final
States and are denoted by P0. All the states in a partition are 0 th equivalent. Take a
Counter k and initialize it with 0.
Step 2: Increment k by 1. For each partition in Pk, divide the states in Pk into two
Partitions if they are k-distinguishable. Two states within this partition X and Y are k-
Distinguishable if there is an input S such that δ(X, S) and δ(Y, S) are (k-1)-
Distinguishable.
Step 3: If Pk ≠ Pk-1, repeat Step 2, otherwise go to Step 4.
Step 4: Combine k th equivalent sets and make them the new states of the reduced
DFA.
Example
Let us consider the following DFA:
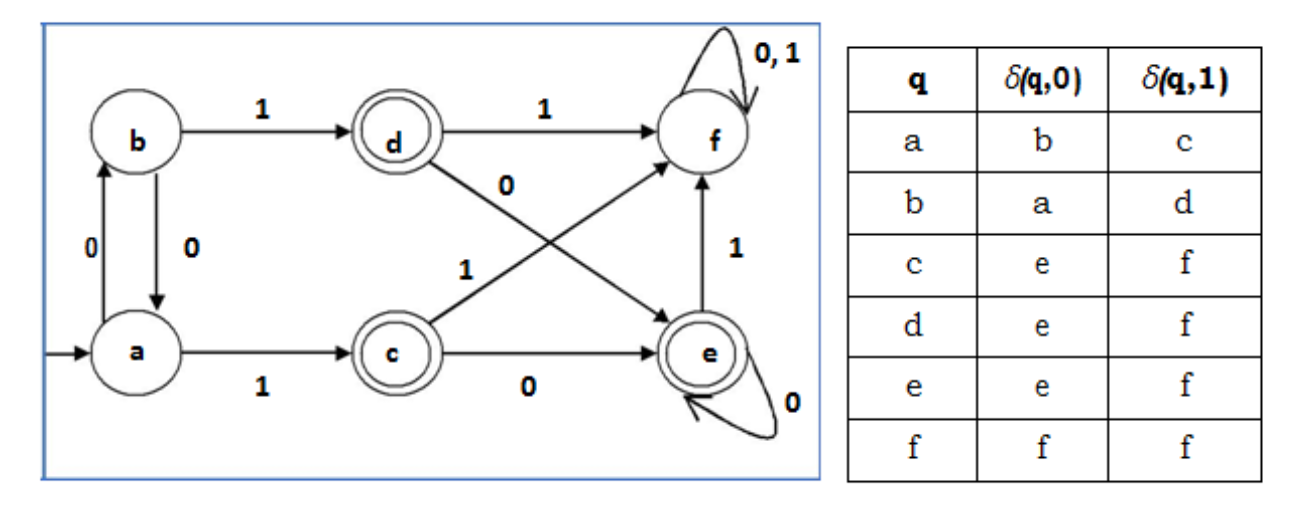
Fig : example of DFA
Let us apply Algorithm 3 to the above DFA:
· P0 = {(c,d,e), (a,b,f)}
· P1 = {(c,d,e), (a,b),(f)}
· P2 = {(c,d,e), (a,b),(f)}
Hence, P1 = P2.
There are three states in the reduced DFA. The reduced DFA is as follows:
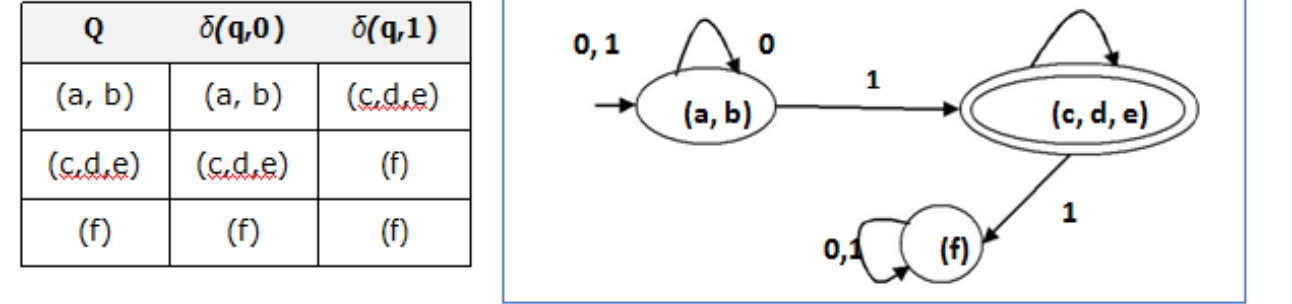
Fig : State Table and State Diagram of Reduced DFA
Q.10 ) Define the Arden’s theorem ?
Sol : Arden’s theorem
★ The Arden's Theorem is useful both for testing the equivalence of two regular phrases and for converting the DFA to a regular phrase.
★ In the conversion of DFA to a regular expression, let us see its use.
★ There are some algorithms used to build the regular expression form given in the DFA.
1. Let q1 be the initial state.
2. There are q2, q3, q4 ....qn number of states. The final state may be some qj where j<= n.
3. Let αji represents the transition from qj to qi.
4. Calculate qi such that
qi = αji * qj
If qj is a start state then we have:
qi = αji * qj + ε
5. Similarly, compute the final state which ultimately gives the regular expression 'r'.




