Unit – 5
Application Layer
Q1) Explain domain name system?
A1) Domain Name System
The Domain Name System (DNS) is a hierarchical decentralized naming system for computers, services, or other resources connected to the Internet or a private network. It associates various information with domain names assigned to each of the participating entities.
Currently, the limit on domain name length is 63 characters, including www. And .com or other extensions. Domain names are also restricted to only a subset of ASCII characters, making many other languages unable to properly represent their names and words. Punycode-based IDNA systems, which map Unicode strings to valid DNS character sets, have been validated and adopted by some registries as a workaround.
A protocol that can be used on various platforms is DNS. The domain name space (tree) is split into three separate parts on the Internet: generic domains, country domains, and the inverse domain.
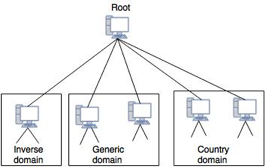
Fig 1: DNS in internet
Q2) Write the part of DNS?
A2) Parts of DNS
A protocol that can be used on various platforms is DNS. The domain name space (tree) is split into three separate parts on the Internet: generic domains, country domains, and the inverse domain.
Generic Domains
Based on their generic behaviour, the generic domains identify registered hosts. A domain, which is an index to the domain name space database, is specified by each node in the tree.
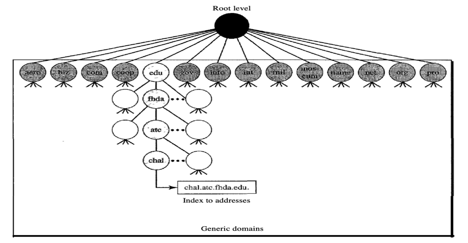
Fig 2: Generic domain
Looking at the tree, we see that 14 possible labels are allowed by the first level in the generic domains segment.
Label | Description |
aero | Airlines and aerospace companies |
biz | Business or firms |
com | Commercial organizations |
coop | Cooperative business organization |
edu | Educational institutions |
gov | Government institutions |
info | Information service provider |
int | International organizations |
mil | Military groups |
museum | Museum and other nonprofit organization |
name | Personal name |
net | Network support centers |
org | Nonprofit organizations |
pro | Professional individual organizations |
Country Domains
The segment on country domains utilizes two-character country abbreviations (e.g., us for United States). The second labels may be organizational, or national designations may be more precise.
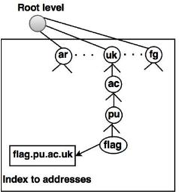
Fig 3: country domain
For instance, the country domain is "au" for Australia, India is .in, and the UK is .uk
Inverse domains
For mapping an address to a name, the inverse domain is used. This can happen when a server has received a request from a client to do a task for testing. Although the server has a file containing a list of approved clients, only the client's IP address (extracted from the IP packet received) is identified. The server prompts its resolver to send a question to the DNS server to map a name to an address to decide if the client is on the approved list.
A reverse or pointer (PTR) query is called this type of query. The inverse domain is added to the domain name space with a first-level node named arpa to handle a pointer query (for historical reasons). One single node called in-adder is also the second stage (for inverse address). IP addresses are specified in the rest of the domain.
Also, the servers managing the inverse domain are hierarchical.
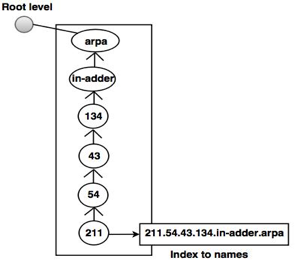
Fig 4: inverse domain
For example, when a client sends a request to a server to perform a specific task, the server finds an approved client list. The list includes only the client's IP addresses.
Q3) What do you mean by WWW?
A3) WWW
World Wide Web, which is also known as a Web, is a collection of websites or web pages stored in web servers and connected to local computers through the internet. These websites contain text pages, digital images, audios, videos, etc. Users can access the content of these sites from any part of the world over the internet using their devices such as computers, laptops, cell phones, etc. The WWW, along with the internet, enables the retrieval and display of text and media to your device.

Fig 5: WWW
The building blocks of the Web are web pages which are formatted in HTML and connected by links called "hypertext" or hyperlinks and accessed by HTTP. These links are electronic connections that link related pieces of information so that users can access the desired information quickly. Hypertext offers the advantage to select a word or phrase from text and thus to access other pages that provide additional information related to that word or phrase.
A web page is given an online address called a Uniform Resource Locator (URL). A particular collection of web pages that belong to a specific URL is called a website, e.g., www.facebook.com, www.google.com, etc. So, the World Wide Web is like a huge electronic book whose pages are stored on multiple servers across the world.
Small websites store all of their Webpages on a single server, but big websites or organizations place their Webpages on different servers in different countries so that when users of a country search their site they could get the information quickly from the nearest server.
So, the web provides a communication platform for users to retrieve and exchange information over the internet. Unlike a book, where we move from one page to another in a sequence, on the World Wide Web we follow a web of hypertext links to visit a web page and from that web page to move to other web pages. You need a browser, which is installed on your computer, to access the Web.
Difference between World Wide Web and Internet:
Some people use the terms 'internet' and 'World Wide Web' interchangeably. They think they are the same thing, but it is not so. The Internet is entirely different from WWW. It is a worldwide network of devices like computers, laptops, tablets, etc. It enables users to send emails to other users and chat with them online. For example, when you send an email or chat with someone online, you are using the internet.
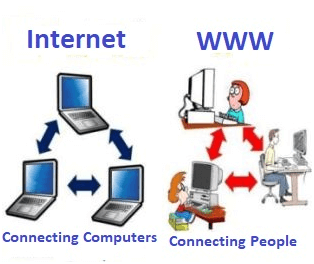
Fig 6: Internet and WWW
But, when you have opened a website like google.com for information, you are using the World Wide Web; a network of servers over the internet. You request a webpage from your computer using a browser, and the server renders that page to your browser. Your computer is called a client who runs a program (web browser), and asks the other computer (server) for the information it needs.
Q4) How the World Wide Web Works?
A4) World Wide Web Works
Now, we have understood that WWW is a collection of websites connected to the internet so that people can search and share information. Now, let us understand how it works!
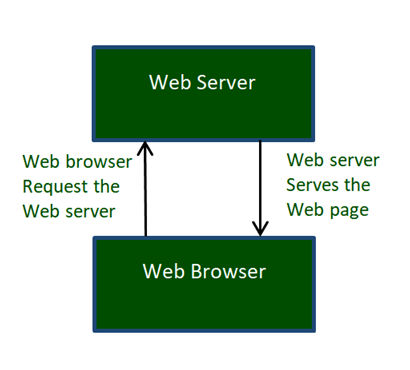
Fig 7: World Wide Web Works
The Web works as per the internet's basic client-server format as shown in the following image. The servers store and transfer web pages or information to user's computers on the network when requested by the users. A web server is a software program which serves the web pages requested by web users using a browser. The computer of a user who requests documents from a server is known as a client. Browser, which is installed on the user' computer, allows users to view the retrieved documents.
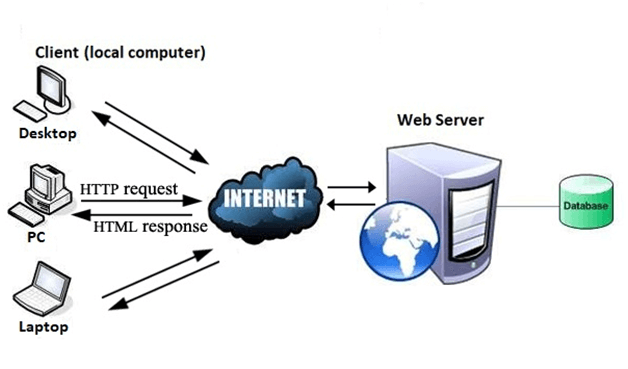
Fig 8: Internet
All the websites are stored in web servers. Just as someone lives on rent in a house, a website occupies a space in a server and remains stored in it. The server hosts the website whenever a user requests its Webpages, and the website owner has to pay the hosting price for the same.
The moment you open the browser and type a URL in the address bar or search something on Google, the WWW starts working. There are three main technologies involved in transferring information (web pages) from servers to clients (computers of users). These technologies include Hypertext Markup Language (HTML), Hypertext Transfer Protocol (HTTP) and Web browsers.
Q5) Write the history of WWW?
A5) History of the World Wide Web
The World Wide Web was invented by a British scientist, Tim Berners-Lee in 1989. He was working at CERN at that time. Originally, it was developed by him to fulfill the need of automated information sharing between scientists across the world, so that they could easily share the data and results of their experiments and studies with each other.
CERN, where Tim Berners worked, is a community of more than 1700 scientists from more than 100 countries. These scientists spend some time on the CERN site, and rest of the time they work at their universities and national laboratories in their home countries, so there is a need for reliable communication tools so that they can exchange information.
The Internet and Hypertext were available at this time, but no one thought how to use the internet to link or share one document to another. Tim focused on three main technologies that could make computers understand each other, HTML, URL, and HTTP. So, the objective behind the invention of WWW was to combine recent computer technologies, data networks, and hypertext into a user-friendly and effective global information system.
Q6) Write short notes on http?
A6) HTTP
Hypertext Transfer Protocol (HTTP) is an application layer protocol which enables WWW to work smoothly and effectively. It is based on a client-server model. The client is a web browser which communicates with the web server which hosts the website. This protocol defines how messages are formatted and transmitted and what actions the Web Server and browser should take in response to different commands. When you enter a URL in the browser, an HTTP command is sent to the Web server, and it transmits the requested Web Page.
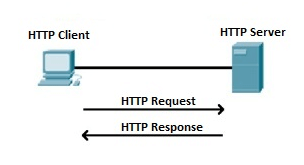
Fig 9: HTTP Request and Response
When we open a website using a browser, a connection to the web server is opened, and the browser communicates with the server through HTTP and sends a request. HTTP is carried over TCP/IP to communicate with the server. The server processes the browser's request and sends a response, and then the connection is closed. Thus, the browser retrieves content from the server for the user.
HTTP
● HTTP stands for Hypertext Transfer Protocol.
● It is a protocol used to access the data on the World Wide Web (www).
● The HTTP protocol can be used to transfer the data in the form of plain text, hypertext, audio, video, and so on.
● This protocol is known as Hypertext Transfer Protocol because of its efficiency that allows us to use it in a hypertext environment where there are rapid jumps from one document to another document.
● HTTP is similar to the FTP as it also transfers the files from one host to another host. But HTTP is simpler than FTP as HTTP uses only one connection, i.e., no control connection to transfer the files.
● HTTP is used to carry the data in the form of MIME-like format.
● HTTP is similar to SMTP as the data is transferred between client and server. The HTTP differs from the SMTP in the way the messages are sent from the client to the server and from server to the client. SMTP messages are stored and forwarded while HTTP messages are delivered immediately.
Q7) Write the features of http?
A7) Feature of HTTP
● Connectionless protocol: HTTP is a connectionless protocol. HTTP client initiates a request and waits for a response from the server. When the server receives the request, the server processes the request and sends back the response to the HTTP client after which the client disconnects the connection. The connection between client and server exists only during the current request and response time only.
● Media independent: HTTP protocol is a media independent as data can be sent as long as both the client and server know how to handle the data content. It is required for both the client and server to specify the content type in MIME-type header.
● Stateless: HTTP is a stateless protocol as both the client and server know each other only during the current request. Due to this nature of the protocol, both the client and server do not retain the information between various requests of the web pages.
Q8) Define e-mail?
A8) Electronic mail (emails)
Electronic Mail (e-mail) is one of most widely used services on the Internet. This service allows an Internet user to send a message in formatted manner (mail) to the other Internet user in any part of the world. Messages in mail not only contain text, but it also contains images, audio and videos data. The person who is sending mail is called the sender and the person who receives mail is called the recipient. It is just like postal mail service.
Components of E-Mail System
The basic components of an email system are: User Agent (UA), Message Transfer Agent (MTA), Mail Box, and Spool file.
1. User Agent (UA): The UA is normally a program which is used to send and receive mail. Sometimes, it is called a mail reader. It accepts a variety of commands for composing, receiving and replying to messages as well as for manipulation of the mailboxes.
2. Message Transfer Agent (MTA): MTA is actually responsible for transfer of mail from one system to another. To send a mail, a system must have client MTA and system MTA. It transfers mail to mailboxes of recipients if they are connected in the same machine. It delivers mail to the peer MTA if the destination mailbox is in another machine.
3. Mailbox: It is a file on a local hard drive to collect mails. Delivered mails are present in this file. The user can read it and delete it according to his/her requirement. To use the e-mail system each user must have a mailbox. Access to mailboxes is only to the owner of the mailbox.
4. Spool file: This file contains mails that are to be sent. User agent appends outgoing mails in this file using SMTP. MTA extracts pending mail from a spool file for their delivery. E-mail allows one name, an alias, to represent several different email addresses. It is known as a mailing list, whenever a user has to send a message, the system checks recipient’s name against the alias database. If a mailing list is present for a defined alias, separate messages, one for each entry in the list, must be prepared and handed to MTA. If for a defined alias, there is no such mailing list present, the name itself becomes the naming address and a single message is delivered to the mail transfer entity.
Q9) Explain architecture of emails?
A9) Architecture of Email
We propose four scenarios to illustrate the architecture of e-mail.
First scenario:
In the first case, users (or application programmes) on the same device are the sender and the email recipient; they are directly connected to a common system. For every user where the received messages are kept, the administrator has generated one mailbox. A mailbox, a special file with authorization limits, is part of a local hard drive.
Only the mailbox owner has access to it. Alice runs a user agent (VA) programme to prepare the message and store it in Bob's mailbox when Alice, a user, needs to send a message to Bob, another user. The message has the mail-box addresses of the sender and receiver (names of files).
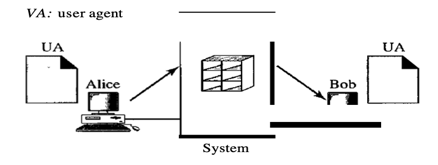
Fig 14: first scenario in electronic mail
At his convenience, using a user agent, Bob can retrieve and read the contents of his mailbox.
The author writes the memo and inserts it in Bob's mailbox when Alice wants to send a memo to Bob. He notices Alice's memo when Bob opens his inbox, and reads it.
Second scenario:
In the second scenario, users (or application programmes) on two separate systems are the sender and the recipient of the e-mail. The message has to be transmitted over the Internet. We need user agents (VAs) and agents for message transfer here (MTAs).
To deliver her message to the device at her own place, Alice needs to use a user agent programme. The framework at her site (sometimes referred to as the mail server) uses a queue to store messages waiting to be sent. In order to retrieve messages saved in the system's mailbox at his location, Bob also requires a user agent application. The post, however, needs to be sent from Alice's site to Bob's site through the Internet.
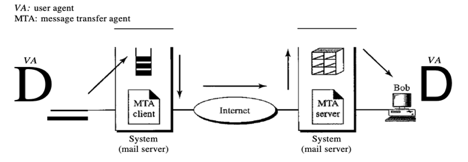
Fig 15: second scenario
Third scenario:
Bob, as in the second scenario, is directly linked to his system in the third scenario. However, Alice is isolated from her system. Either Alice is connected to the device through a point-to-point WAN, such as a dial-up modem, a DSL, or a cable modem; or, in a company that uses a single mail server to handle emails, it is connected to a LAN; all users have to send their messages to that mail server.
To prepare their post, Alice still needs a user agent. Then via the LAN or WAN, she needs to send the message. A pair of message transfer agents will do this (client and server). She calls the user agent if Alice has a message to send, which, in turn, calls the MTA client. The MTA client creates a connection that is running all the time with the MTA server on the device.
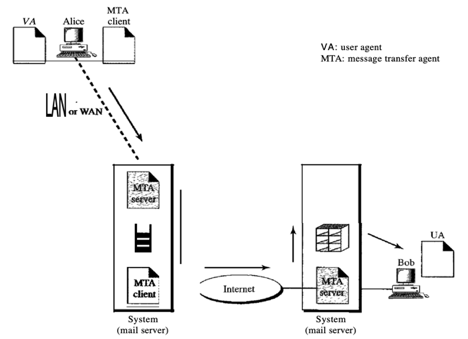
Fig16 : third scenario
Fourth scenario:
Bob is also linked to his mail server by a WAN or a LAN in the fourth and most popular scenario. Bob has to retrieve it after the message has hit Bob's mail server. We need another set of client/server agents here, which we call agents for message access (MAAs). To retrieve his messages, Bob uses an MAA client. The client sends a request to the MAA server, which is running all the time, and asks for messages to be transferred.
Here, there are two major points. Second, it's not possible for Bob to bypass the mail server and directly use the MTA server. Bob will need to run the MTA server all the time to use the MTA server directly, so he doesn't know when a message is coming. This means that if he is linked to his machine via a LAN, Bob must keep his computer on all the time. He must keep the link up all the time if he is linked via a-WAN. Today, none of these situations is feasible.
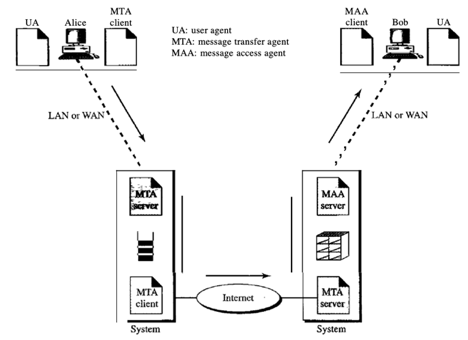
Fig 17: fourth scenario
Q10) Define file transfer protocol?
A10) File Transfer Protocol
File Transfer Protocol (FTP) is an application layer protocol which moves files between local and remote file systems. It runs on the top of TCP, like HTTP. To transfer a file, 2 TCP connections are used by FTP in parallel: control connection and data connection. Transferring files from one system to another is very simple and straightforward, but sometimes it can cause problems. For example, two systems may have different file conventions. Two systems may have different ways to represent text and data. Two systems may have different directory structures. FTP protocol overcomes these problems by establishing two connections between hosts. One connection is used for data transfer, and another connection is used for the control connection.
● Control Connection: The control connection uses very simple rules for communication. Through control connection, we can transfer a line of command or line of response at a time. The control connection is made between the control processes. The control connection remains connected during the entire interactive FTP session.
● Data Connection: The Data Connection uses very complex rules as data types may vary. The data connection is made between data transfer processes. The data connection opens when a command comes for transferring the files and closes when the file is transferred.
During the entire interactive FTP session, the control connection stays connected. For every file transferred, the data connection is opened and then closed. Every time commands involving file transfer are used, it opens and closes when the file is transferred.
In other words, the control connection opens when a user starts an FTP session. Whilst the control connection is open, if several files are transferred, the data connection can be opened and closed multiple times.
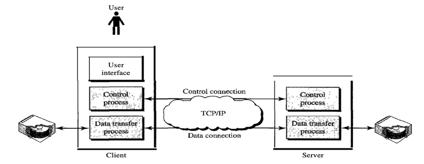
Fig 18: FTP
The client has three components: the user interface, the process of client control, and the process of transferring client data. The server has two components: the process of server control and the process of data transfer from the server. Between the control processes, the control connection is made. Between the data transfer processes, the data connection is made.
Q11) Write the advantages and disadvantages of FTP?
A11) Advantages of FTP
● Speed: One of the biggest advantages of FTP is speed. The FTP is one of the fastest ways to transfer the files from one computer to another computer.
● Efficient: It is more efficient as we do not need to complete all the operations to get the entire file.
● Security: To access the FTP server, we need to login with the username and password. Therefore, we can say that FTP is more secure.
● Back & forth movement: FTP allows us to transfer the files back and forth. Suppose you are a manager of the company, you send some information to all the employees, and they all send information back on the same server.
Disadvantages of FTP
● The standard requirement of the industry is that all the FTP transmissions should be encrypted. However, not all the FTP providers are equal and not all the providers offer encryption. So, we will have to look out for the FTP providers that provide encryption.
● FTP serves two operations, i.e., to send and receive large files on a network. However, the size limit of the file is 2GB that can be sent. It also doesn't allow you to run simultaneous transfers to multiple receivers.
● Passwords and file contents are sent in clear text that allows unwanted eavesdropping. So, it is quite possible that attackers can carry out the brute force attack by trying to guess the FTP password.
● It is not compatible with every system.
Q12) Describe remote login?
A12) Remote Login
Remote Login is a procedure that allows a user to access a remote site, such as a computer, and use services that are accessible on that computer. A user can understand the results of moving processing results from the remote computer to the local computer using remote login.
Telnet is used to introduce it.
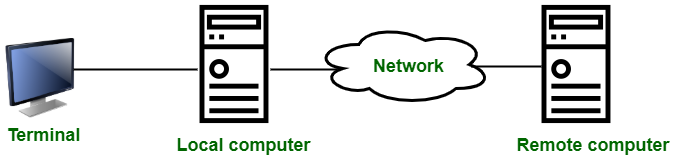
Fig 19: remote login
Procedures of Remote login:
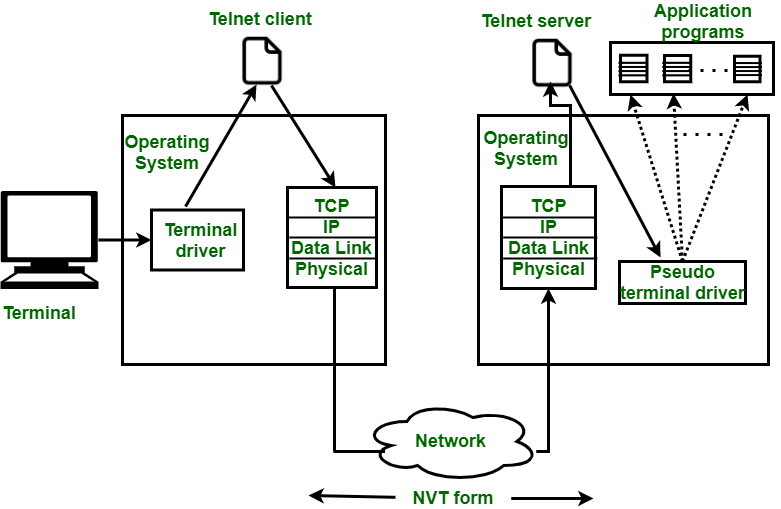
Fig 20: remote login procedure
Q13) Explain network management?
A13) Network Management
Network management is an important part of running a successful network. Network administrators require software to keep track of the network devices' capabilities, as well as the interactions between them and the services they provide. SNMP has become the de facto standard for network management solutions, and it is closely linked to remote monitoring (RMON) and Management Information Bases (MIBs) (MIB).
Each controlled device in the network has a set of variables that describe its current state. You can read the values of these variables to track managed devices, and you can write values into these variables to manipulate managed devices.
Network Management Architecture
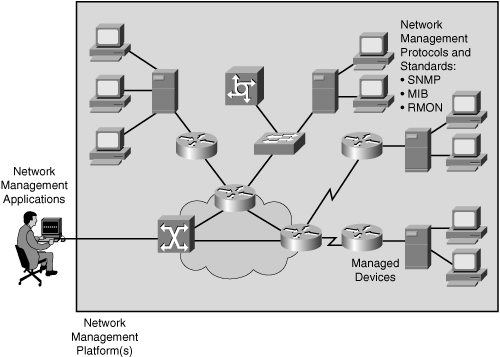
Fig 21: network management architecture
The following components make up the network management architecture:
● A network management system (NMS) is a computer system that runs programs to track and control controlled devices. The majority of the processing and memory resources needed for network management are provided by NMSs.
● SNMP, MIB, and RMON are examples of network management protocols that allow the sharing of management information between the NMS and managed devices.
● A computer (such as a router) that is operated by an NMS is referred to as a managed device.
● Management agents, such as SNMP agents and RMON agents, are software that gathers and stores management information on controlled devices.
● Management information: Data that is relevant to the management of a system and is typically stored in MIBs.
A network management system can run a number of network management applications, depending on the network platform (such as the hardware or operating system). Management information is stored on network computers, with management agents collecting and storing data in a standardized data definition system known as the MIB.
The data collected by the management agents is retrieved by the network management program using SNMP or other network management protocols. The retrieved data is usually processed and prepared for display with a GUI, which allows the user to monitor controlled devices and program the network management framework using a graphical representation of the network.
Q14) What is data compression?
A14) Data Compression
In the OSI reference model, data compression is a feature of the presentation layer. When saving data, compression is often used to maximize the use of bandwidth across a network or to save disk space.
There are two types of compression algorithms in general:
Fig 22: types of compression
Lossless compression:
Lossless compression compresses data in such a way that when it is decompressed, it is identical to what it was before compression, i.e., no data is lost.
Since programs that process such file data cannot accept errors in the data, lossless compression is used to compress file data such as executable code, text files, and numeric data.
Lossless compression does not compress files as well as lossy compression techniques, and it can require more computing power to complete.
Lossless compression algorithm
The following are some of the algorithms that are used to implement lossless data compression:
Lossy compression
Lossy compression does not guarantee that the data received is identical to the data sent, i.e., the data may be lost. This is because a lossy algorithm discards data that cannot be recovered later.
Still images, video, and audio are all compressed using lossy algorithms. Lossy algorithms usually outperform lossless algorithms in terms of compression ratios.
Q15) Explain Cryptography?
A15) Cryptography
The method of translating ordinary plain text into unintelligible text, and vice versa, is known as cryptography. It is a way of storing and transmitting data in a specific format that can only be read and processed by those who are supposed to. Cryptography may be used for user authentication as well as protecting data from theft or modification.
Evolution of Cryptography
During and after the European Renaissance, various Italian and Papal states led the rapid proliferation of cryptographic techniques. Various analysis and attack techniques were researched in this era to break the secret codes.
● Improved coding techniques such as Vigenere Coding came into existence in the 15th century, which offered moving letters in the message with a number of variable places instead of moving them the same number of places.
● Only after the 19th century, cryptography evolved from the ad hoc approaches to encryption to the more sophisticated art and science of information security.
● In the early 20th century, the invention of mechanical and electromechanical machines, such as the Enigma rotor machine, provided more advanced and efficient means of coding the information.
● During the period of World War II, both cryptography and cryptanalysis became excessively mathematical.
With the advances taking place in this field, government organizations, military units, and some corporate houses started adopting the applications of cryptography. They used cryptography to guard their secrets from others. Now, the arrival of computers and the Internet has brought effective cryptography within the reach of common people.
Security Services of Cryptography
The primary objective of using cryptography is to provide the following four fundamental information security services. Let us now see the possible goals intended to be fulfilled by cryptography.
Confidentiality
Confidentiality is the fundamental security service provided by cryptography. It is a security service that keeps the information from an unauthorized person. It is sometimes referred to as privacy or secrecy.
Confidentiality can be achieved through numerous means starting from physical securing to the use of mathematical algorithms for data encryption.
Data Integrity
It is a security service that deals with identifying any alteration to the data. The data may get modified by an unauthorized entity intentionally or accidentally. Integrity service confirms that whether data is intact or not since it was last created, transmitted, or stored by an authorized user.
Data integrity cannot prevent the alteration of data, but provides a means for detecting whether data has been manipulated in an unauthorized manner.
Authentication
Authentication provides the identification of the originator. It confirms to the receiver that the data received has been sent only by an identified and verified sender.
Authentication service has two variants −
● Message authentication identifies the originator of the message without any regard to the router or system that has sent the message.
● Entity authentication is assurance that data has been received from a specific entity, say a particular website.
Apart from the originator, authentication may also provide assurance about other parameters related to data such as the date and time of creation/transmission.
Non-repudiation
It is a security service that ensures that an entity cannot refuse the ownership of a previous commitment or an action. It is an assurance that the original creator of the data cannot deny the creation or transmission of the said data to a recipient or third party.
Non-repudiation is a property that is most desirable in situations where there are chances of a dispute over the exchange of data. For example, once an order is placed electronically, a purchaser cannot deny the purchase order, if non-repudiation service was enabled in this transaction.
Cryptography Primitives
Cryptography primitives are nothing but the tools and techniques in Cryptography that can be selectively used to provide a set of desired security services −
● Encryption
● Hash functions
● Message Authentication codes (MAC)
● Digital Signatures
The following table shows the primitives that can achieve a particular security service on their own.
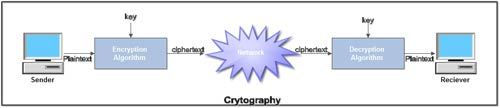
Fig 24: Cryptography
Components of a Cryptosystem
The various components of a basic cryptosystem are as follows −
● Plaintext. It is the data to be protected during transmission.
● Encryption Algorithm. It is a mathematical process that produces a ciphertext for any given plaintext and encryption key. It is a cryptographic algorithm that takes plaintext and an encryption key as input and produces a ciphertext.
● Ciphertext. It is the scrambled version of the plaintext produced by the encryption algorithm using a specific encryption key. The ciphertext is not guarded. It flows on a public channel. It can be intercepted or compromised by anyone who has access to the communication channel.
● Decryption Algorithm, it is a mathematical process that produces a unique plaintext for any given ciphertext and decryption key. It is a cryptographic algorithm that takes a ciphertext and a decryption key as input, and outputs a plaintext. The decryption algorithm essentially reverses the encryption algorithm and is thus closely related to it.
● Encryption Key. It is a value that is known to the sender. The sender inputs the encryption key into the encryption algorithm along with the plaintext in order to compute the ciphertext.
● Decryption Key. It is a value that is known to the receiver. The decryption key is related to the encryption key, but is not always identical to it. The receiver inputs the decryption key into the decryption algorithm along with the ciphertext in order to compute the plaintext.
For a given cryptosystem, a collection of all possible decryption keys is called a key space.
An interceptor (an attacker) is an unauthorized entity who attempts to determine the plaintext. He can see the ciphertext and may know the decryption algorithm. He, however, must never know the decryption key.
Q16) Write the types of cryptosystems?
A16) Types of Cryptosystems
Fundamentally, there are two types of cryptosystems based on the manner in which encryption-decryption is carried out in the system −
● Symmetric Key Encryption
● Asymmetric Key Encryption
The main difference between these cryptosystems is the relationship between the encryption and the decryption key. Logically, in any cryptosystem, both the keys are closely associated. It is practically impossible to decrypt the ciphertext with the key that is unrelated to the encryption key.
Symmetric Key Encryption
The encryption process where the same keys are used for encrypting and decrypting the information is known as Symmetric Key Encryption.
The study of symmetric cryptosystems is referred to as symmetric cryptography. Symmetric cryptosystems are also sometimes referred to as secret key cryptosystems.
A few well-known examples of symmetric key encryption methods are − Digital Encryption Standard (DES), Triple-DES (3DES), IDEA, and BLOWFISH.
The salient features of cryptosystem based on symmetric key encryption are −
● Persons using symmetric key encryption must share a common key prior to exchange of information.
● Keys are recommended to be changed regularly to prevent any attack on the system.
● A robust mechanism needs to exist to exchange the key between the communicating parties. As keys are required to be changed regularly, this mechanism becomes expensive and cumbersome.
● In a group of n people, to enable two-party communication between any two persons, the number of keys required for a group is n × (n – 1)/2.
● Length of Key (number of bits) in this encryption is smaller and hence, the process of encryption-decryption is faster than asymmetric key encryption.
● Processing power of the computer system required to run a symmetric algorithm is less.
Asymmetric Key Encryption
The encryption process where different keys are used for encrypting and decrypting the information is known as Asymmetric Key Encryption. Though the keys are different, they are mathematically related and hence, retrieving the plaintext by decrypting ciphertext is feasible.
The process is depicted in the following illustration −
Asymmetric Key Encryption was invented in the 20th century to overcome the necessity of a pre-shared secret key between communicating persons. The salient features of this encryption scheme are as follows −
● Every user in this system needs to have a pair of dissimilar keys, private key and public key. These keys are mathematically related − when one key is used for encryption, the other can decrypt the ciphertext back to the original plaintext.
● It requires to put the public key in a public repository and the private key as a well-guarded secret. Hence, this scheme of encryption is also called Public Key Encryption.
● Though public and private keys of the user are related, it is computationally not feasible to find one from another. This is the strength of this scheme.
● When Host1 needs to send data to Host2, he obtains the public key of Host2 from the repository, encrypts the data, and transmits.
● Host2 uses his private key to extract the plaintext.
● Length of Keys (number of bits) in this encryption is large and hence, the process of encryption-decryption is slower than symmetric key encryption.
● Processing power of the computer system required to run an asymmetric algorithm is higher.




