Unit - 1
Machine learning
Q1) What is machine learning?
A1) In the real world, we are surrounded by individuals who can learn anything from their experiences thanks to their ability to learn, and we have computers or machines that follow our commands. But, like a human, can a machine learn from past experiences or data? So here's where Machine Learning comes in.
Machine learning is a subfield of artificial intelligence that focuses on the development of algorithms that allow a computer to learn on its own from data and previous experiences. Arthur Samuel was the first to coin the term "machine learning" in 1959. In a nutshell, we can characterise it as follows:
“Machine learning enables a machine to automatically learn from data, improve performance from experiences, and predict things without being explicitly programmed.”
Machine learning algorithms create a mathematical model with the help of sample historical data, referred to as training data, that aids in making predictions or judgments without being explicitly programmed. In order to create predictive models, machine learning combines computer science and statistics. Machine learning is the process of creating or employing algorithms that learn from past data. The more information we supply, the better our performance will be.
If a system can enhance its performance by gaining new data, it has the potential to learn.
Q2) Write the features of machine learning?
A2) Features of machine learning
● Data is used by machine learning to find distinct patterns in a dataset.
● It can learn from previous data and improve on its own.
● It is a technology that is based on data.
● Data mining and machine learning are very similar in that they both deal with large amounts of data.
Q3) What are the basic principles of ml?
A3) The Responsible Machine Learning Principles are a practical framework created by specialists in the field.
Their goal is to provide assistance to technologists on how to ethically construct machine learning systems.
1. Human augmentation
I pledge to consider the consequences of inaccurate predictions and, where possible, develop systems that include human-in-the-loop review methods.
2. Bias evaluation
I pledge to build processes that allow me to understand, document, and track bias in development and production on a constant basis.
3. Explainability by justification
Wherever possible, I pledge to develop tools and methods to improve the transparency and explainability of machine learning systems.
4. Reproducible operations
I pledge to build the infrastructure necessary to ensure a decent level of reproducibility in the operations of machine learning systems.
5. Displacement strategy
I pledge to uncover and document important data so that business change processes may be designed to limit the impact of automation on workers.
6. Practical accuracy
I pledge to create mechanisms to verify that my accuracy and cost metric functions are in line with domain-specific applications.
7. Trust by privacy
I pledge to create and disclose data-protection and data-handling protocols to all stakeholders who may engage with the system directly or indirectly.
8. Data risk awareness
I pledge to create and improve suitable methods and infrastructure to ensure that data and model security is taken into account when developing machine learning systems.
Q4) How to design a learning system?
A4) Steps for Designing Learning System are:
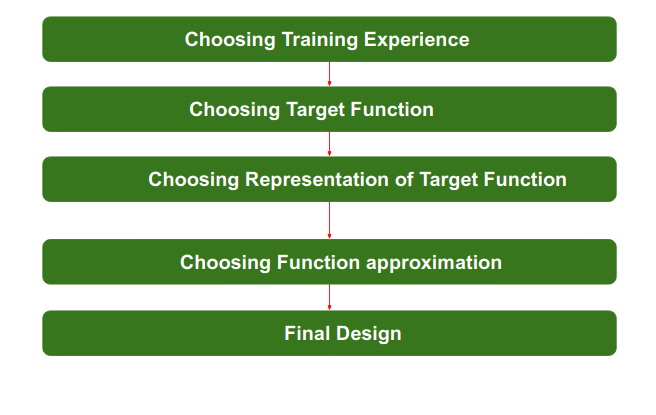
Fig 1: Steps of designing
Step 1 - Choosing the Training Experience:
The first and most crucial duty is to select the training data or experience that will be supplied to the Machine Learning Algorithm. It's worth noting that the data or experience we provided the algorithm had to have a major impact on the model's success or failure. As a result, training data or experience should be carefully picked.
The following are the characteristics that will influence the success or failure of data:
● The training experience will be able to provide either direct or indirect feedback on options. For example, while playing chess, the training data will give itself feedback such as if this move is chosen instead of this, the odds of success rise.
● The learner's ability to regulate the sequences of training examples is the second crucial factor to consider. For example, when the machine is fed training data, its accuracy is low at first, but as it acquires experience by playing against itself or an opponent over and over, the machine algorithm will receive feedback and adjust the chess game accordingly.
● The representation of the distribution of samples across which performance will be tested is the third crucial property. A machine learning algorithm, for example, will gain experience by passing through a variety of distinct cases and examples. As a result of passing through more and more cases, the Machine Learning Algorithm will gain more and more experience, and its performance will improve.
Step 2 - Choosing target function:
The next crucial step is to pick a target function. It means that the machine learning system will choose the NextMove function, which will explain what type of lawful moves should be taken, based on the knowledge provided to it. For example, when playing chess with an opponent, the machine learning algorithm will determine the amount of feasible legal moves to make in order to win.
Step 3 - Choosing Representation for Target function:
When the machine algorithm has a complete list of all permitted moves, it can choose the best one using any representation, such as linear equations, hierarchical graph representation, tabular form, and so on. Out of these moves, the NextMove function will move the Target move, which will increase the success rate. For example, if a chess machine has four alternative moves, the machine will choose the most optimal move that will lead to victory.
Step 4 - Choosing Function Approximation Algorithm
It is impossible to choose an optimal move only based on the training data. The training data had to go through a series of instances, and from these examples, the training data was able to guess which actions should be taken, and then the machine provided feedback. For example, if a training data set for playing chess is provided to an algorithm, the system will either fail or succeed, and based on that failure or success, it will determine which step to do next and what its success rate is.
Step 5 - Final design
When the system has gone through a number of examples, failures and successes, correct and erroneous decisions, and what the next step will be, the final design is established. For example, DeepBlue, a machine learning-based intelligent computer, defeated chess champion Garry Kasparov, becoming the first computer to defeat a human chess expert.
Q5) What do you mean by a well defined learning system?
A5) If a computer program's performance on T, as measured by P, improves with experience E, it is said to learn from experience E in the context of some task T and some performance metric P.
If a problem exhibits three characteristics, it can be classified as a well-posed learning problem.
● Task
● Performance Measure
● Experience
The following are some examples that effectively characterise a well-posed learning problem:
1. To better filter emails as spam or not
Task – Classifying emails as spam or not
Performance Measure – The fraction of emails accurately classified as spam or not spam
Experience – Observing you label emails as spam or not spam
2. A checkers learning problem
Task – Playing checkers game
Performance Measure – percent of games won against opposer
Experience – playing implementation games against itself
3. Handwriting Recognition Problem
Task – Acknowledging handwritten words within portrayal
Performance Measure – percent of words accurately classified
Experience – a directory of handwritten words with given classifications
4. A Robot Driving Problem
Task – driving on public four-lane highways using sight scanners
Performance Measure – average distance progressed before a fallacy
Experience – order of images and steering instructions noted down while observing a human driver
5. Fruit Prediction Problem
Task – forecasting different fruits for recognition
Performance Measure – able to predict maximum variety of fruits
Experience – training machine with the largest datasets of fruits images
6. Face Recognition Problem
Task – predicting different types of faces
Performance Measure – able to predict maximum types of faces
Experience – training machine with maximum amount of datasets of different face images
7. Automatic Translation of documents
Task – translating one type of language used in a document to other language
Performance Measure – able to convert one language to other efficiently
Experience – training machine with a large dataset of different types of languages
Q6) Write the challenges of ML?
A6) We'll go over some of the biggest issues you could encounter while building your machine learning model. Assuming you understand what machine learning is, why people use it, what different types of machine learning there are, and how the whole development pipeline works.
When people hear the words Machine Learning (ML) or Artificial Intelligence, they often think of a robot or a terminator (AI). They aren't, though, anything out of a movie; they are far from a cutting-edge fantasy. It has already arrived. Despite the fact that there are multiple cutting-edge apps produced utilising machine learning, there are some problems that an ML practitioner may face while designing an application from the ground up and putting it to production.
Not enough training data
Once the data has been acquired, check to see if the quantity is adequate for the use case (for time-series data, we need at least 3–5 years of data).
Selecting a learning method and training the model using part of the gathered data are the two most crucial things we perform when working on a machine learning project. As a result of our innate tendency to make mistakes, things may go wrong. The errors here could include choosing the incorrect model or picking inaccurate data. So, what exactly do I mean when I say "poor data"? Let us make an effort to comprehend.
For example, if you want a toddler to learn what an apple is, all you have to do is point to one and say apple repeatedly. The child can now identify a variety of apples.
Machine learning, on the other hand, is still not there yet; most algorithms require a large amount of data to perform successfully. For a simple activity, thousands of examples are required, while complex tasks such as picture or speech recognition may require lakhs (millions) of instances.
Irrelevant features
The machine learning system will not produce the desired results if the training data comprises a significant number of irrelevant features and not enough relevant features. The selection of good features to train the model, also known as Feature Selection, is a key part of a machine learning project's success.
Let's pretend we're working on a project to estimate how many hours a person needs to exercise based on the data we've gathered — age, gender, weight, height, and location (i.e., where he or she resides).
● One of these five features, location value, may or may not have an impact on our output function. This is a non-essential feature; we already know that we can achieve better results without it.
● We can also use Feature Extraction to combine two features to create a more useful one. By removing weight and height from our example, we can create a feature called BMI. On the dataset, we may also apply transformations.
● Creating new features by accumulating more data is also beneficial.
Poor Quality of data
In practise, we don't start training the model right once; instead, the most crucial phase is data analysis. However, the data we gathered may not be suitable for training; some samples differ from others in terms of outliers or missing values, for example.
In these scenarios, we can either eliminate the outliers, fill in the missing features/values with median or mean (to fill height), or simply remove the attributes/instances with missing values, or train the model with and without them.
Isn't it true that we don't want our system to produce incorrect predictions? As a result, data quality is critical in obtaining accurate results. Data preprocessing entails filtering missing values, extracting, and rearrangement to meet the model's requirements.
Overfitting and Underfitting
● Overfitting
Let's assume you're heading down the street to buy something when a dog appears out of nowhere. You offer him something to eat, but instead of eating, he begins barking and chasing you, but you manage to escape. You could think that all dogs aren't worth treating kindly after this scenario.
So, we humans overgeneralize a lot of the time, and sadly, machine learning models do the same if they aren't careful. This is referred to as overfitting in machine learning, where a model performs well on training data but fails to generalise well.
When our model is too complicated, overfitting occurs.
Things we can do to solve this situation include:
● Reduce the number of parameters in the model by choosing one with fewer.
● The amount of attributes in training data can be reduced.
● The model is restrained.
● More training data is needed.
● Reduce the amount of noise.
● Underfitting
Underfitting is the polar opposite of overfitting, as you may have surmised. When our model is too simplistic to learn anything from the data, this happens. If you run a linear model on a set with multicollinearity, for example, it will almost certainly underfit, and the predictions will almost certainly be erroneous on the training set as well.
Things we can do to solve this situation include:
● Choose a more advanced model with additional options.
● Better and more relevant features should be practised.
● Reduce the restrictions.
Non-representative training data
To generalise properly, the training data should be indicative of new situations, i.e., the data we use for training should include all cases that have occurred and will occur. The trained model is unlikely to produce accurate predictions if the training set is non-representative.
Machine learning models are defined as systems that are designed to produce predictions for generalised scenarios in the context of a business challenge. It will aid the model's performance even when dealing with data that the model has never seen before.
If the number of training samples is low, we have sampling noise, which is unrepresentative data; likewise, a large number of training tests might lead to sampling bias if the training technique is flawed.
To ensure that our model generalises properly, we must ensure that our training data is reflective of the new circumstances to which we wish to apply it.
If we train our model with a nonrepresentative training set, it will be biassed towards one class or group in its predictions.
Let's imagine you're attempting to create a model that recognises music genres. One method for constructing your training set is to conduct a YouTube search and use the results. We're assuming that YouTube's search engine is producing accurate results, but in reality, the results will be skewed toward well-known artists, and possibly even artists who are well-known in your area (if you live in India you will be getting the music of Arijit Singh, Sonu Nigam or etc).
So, when it comes to testing data, use representative data during training so that your model isn't skewed toward one or two classes.
Q7) Describe the application of ML?
A7) Machine learning is a buzzword in today's technology, and it's gaining traction at a breakneck pace. Even if we aren't aware of it, we use machine learning in our daily lives through Google Maps, Google Assistant, Alexa, and other similar services. The following are some of the most popular real-world Machine Learning applications:
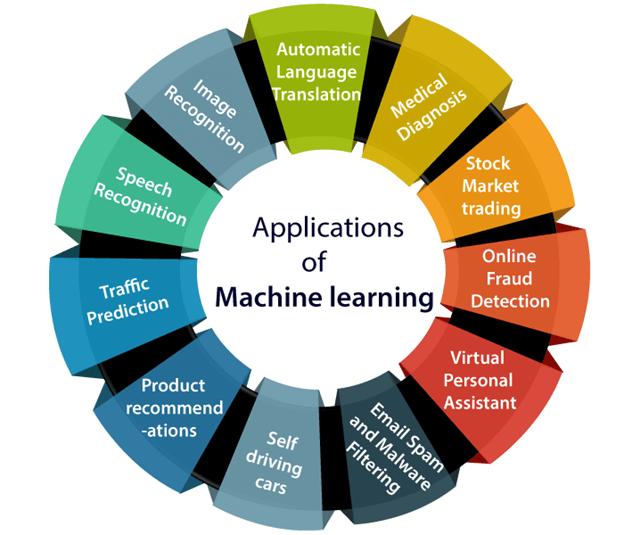
Fig 2: Application of ML
- Image recognition
One of the most common uses of machine learning is image recognition. It's used to identify things like people, places, and digital photographs. Automatic buddy tagging suggestion is a common use of picture recognition and facial identification.
Facebook has a tool that suggests auto-tagging of friends. When we submit a photo with our Facebook friends, we get an automatic tagging recommendation with their names, which is powered by machine learning's face identification and recognition algorithm.
It is based on the "Deep Facial" Facebook project, which is in charge of face recognition and individual identification in photos.
2. Traffic prediction
When we want to go somewhere new, we use Google Maps, which offers us the best path with the shortest route and anticipates traffic conditions.
It uses two methods to anticipate traffic conditions, such as whether traffic is clear, sluggish moving, or extremely congested:
● The vehicle's location is tracked in real time using the Google Maps app and sensors.
● At the same time, average time has been taken on previous days.
Everyone who uses Google Map contributes to the app's improvement. It collects data from the user and transmits it back to its database in order to improve performance.
3. Speech recognition
When we use Google, we have the option to "Search by voice," which falls under the category of speech recognition and is a prominent machine learning application.
Speech recognition, often known as "Speech to text" or "Computer speech recognition," is the process of turning voice instructions into text. Machine learning techniques are now widely used in a variety of speech recognition applications. Speech recognition technology is used by Google Assistant, Siri, Cortana, and Alexa to obey voice commands.
4. Online fraud detection
By detecting fraud transactions, machine learning makes our online transactions safer and more secure. When we conduct an online transaction, there are a number of ways for a fraudulent transaction to occur, including the use of phoney accounts, fake ids, and the theft of funds in the middle of a transaction. To detect this, the Feed Forward Neural Network assists us by determining whether the transaction is genuine or fraudulent.
The output of each valid transaction is translated into some hash values, which are then used as the input for the next round. There is a certain pattern for each genuine transaction that changes for the fraud transaction, thus it detects it and makes our online transactions more safe. e user and sends the information back to its database in order to improve speed.
5. Stock market trading
In stock market trading, machine learning is commonly used. Because there is always the possibility of share price fluctuations in the stock market, a machine learning long short term memory neural network is utilised to forecast stock market trends.
6. Medical diagnosis
Machine learning is used to diagnose disorders in medical science. As a result, medical technology is rapidly evolving, and 3D models that can predict the exact location of lesions in the brain are now possible.
It facilitates the detection of brain cancers and other brain-related illnesses.
7. Automatic language translation
Nowadays, visiting a new area and not knowing the language is not an issue; machine learning can help us with this by transforming the text into our native languages. This feature is provided by Google's GNMT (Google Neural Machine Translation), which is a Neural Machine Learning that automatically translates text into our native language.
A sequence to sequence learning method, which is combined with picture recognition and translates text from one language to another, is the technology behind automatic translation.
8. Product recommendations
Various e-commerce and entertainment organisations, such as Amazon, Netflix, and others, employ machine learning to make product recommendations to users. Because of machine learning, whenever we look for a product on Amazon, we begin to receive advertisements for the same goods while browsing the internet on the same browser.
Using multiple machine learning techniques, Google deduces the user's interests and recommends products based on those interests.
Similarly, when we use Netflix, we receive recommendations for entertainment series, movies, and other content, which is also based on machine learning.
9. Virtual personal assistant
We have Google Assistant, Alexa, Cortana, and Siri, among other virtual personal assistants. They assist us in discovering information using our voice commands, as the name implies. These assistants can aid us in a variety of ways simply by following our voice commands, such as playing music, calling someone, opening an email, scheduling an appointment, and so on.
Machine learning algorithms are a crucial aspect of these virtual assistants.
These assistants record our vocal commands, transfer them to a cloud server, where they are decoded using machine learning techniques and acted upon.
Q8) Write the difference between AI and machine learning?
A8) Difference between AI and ML
Artificial Intelligence | Machine Learning |
Artificial intelligence is a technology which enables a machine to simulate human behavior. | Machine learning is a subset of AI which allows a machine to automatically learn from past data without programming explicitly. |
The goal of AI is to make a smart computer system like humans to solve complex problems. | The goal of ML is to allow machines to learn from data so that they can give accurate output. |
In AI, we make intelligent systems to perform any task like a human. | In ML, we teach machines with data to perform a particular task and give an accurate result. |
Machine learning and deep learning are the two main subsets of AI. | Deep learning is a main subset of machine learning. |
AI has a very wide range of scope. | Machine learning has a limited scope. |
AI is working to create an intelligent system which can perform various complex tasks. | Machine learning is working to create machines that can perform only those specific tasks for which they are trained. |
AI systems are concerned about maximizing the chances of success. | Machine learning is mainly concerned about accuracy and patterns. |
The main applications of AI are Siri, customer support using catboats, Expert System, Online game playing, intelligent humanoid robot, etc. | The main applications of machine learning are Online recommender system, Google search algorithms, Facebook auto friend tagging suggestions, etc. |
On the basis of capabilities, AI can be divided into three types, which are, Weak AI, General AI, and Strong AI. | Machine learning can also be divided into mainly three types that are Supervised learning, Unsupervised learning, and Reinforcement learning. |
It includes learning, reasoning, and self-correction. | It includes learning and self-correction when introduced with new data. |
AI completely deals with Structured, semi-structured, and unstructured data. | Machine learning deals with Structured and semi-structured data. |
Q9) What are the types of machine learning?
A9) There are several ways to frame this definition, but largely there are three main known categories: supervised learning, unsupervised learning, and reinforcement learning.

Fig 3: Types of Learning
In a world filled by artificial intelligence, machine learning, and over-zealous talk about both, it is interesting to learn to understand and define the types of machine learning we may encounter. For the average computer user, this may take the form of knowing the forms of machine learning and how they can exhibit themselves in applications we use.
And for the practitioners designing these applications, it’s important to know the styles of machine learning so that for any given task you can face, you can craft the proper learning environment and understand why what you did succeeded.
- Supervised Learning
Supervised learning is the most common model for machine learning. It is the easiest to grasp and the quickest to execute. It is quite close to training a child through the use of flash cards.
Supervised learning is also defined as task-oriented because of this. It is highly focused on a single task, feeding more and more examples to the algorithm before it can reliably perform on that task.
There are two major types of supervised learning problems: classification that involves predicting a class mark and regression that involves predicting a numerical value.
● Classification: Supervised learning problem that involves predicting a class mark.
● Regression: Supervised learning problem that requires predicting a numerical mark.
Both classification and regression problems can have one or more input variables and input variables may be any data form, such as numerical or categorical.
2. Unsupervised Learning
Unsupervised learning is very much the opposite of supervised learning. It features no marks. Instead, our algorithm will be fed a lot of data and provided the tools to understand the properties of the data. From there, it can learn to group, cluster, and/or arrange the data in a way so that a person (or other intelligent algorithm) can come in and make sense of the newly arranged data.
There are several forms of unsupervised learning, but there are two key problems that are mostly faced by a practitioner: they are clustering that involves identifying groups in the data and density estimation that involves summarising the distribution of data.
● Clustering: Unsupervised learning problem that involves finding groups in data.
● Density Estimation: Unsupervised learning problem that involves summarising the distribution of data.
3. Reinforcement Learning
Reinforcement learning is fairly different when compared to supervised and unsupervised learning. Where we can clearly see the relationship between supervised and unsupervised (the existence or absence of labels), the relationship to reinforcement learning is a little murkier. Some people attempt to tie reinforcement learning closer to the two by defining it as a form of learning that relies on a time-dependent sequence of labels, however, my opinion is that that actually makes things more complicated.
For any reinforcement learning challenge, we need an agent and an environment as well as a way to link the two via a feedback loop. To link the agent to the world, we give it a collection of actions that it can take that affect the environment. To link the environment to the agent, we make it continually issue two signals to the agent: an updated state and a reward (our reinforcement signal for behaviour) (our reinforcement signal for behavior).
Q10) What is the need for machine learning?
A10) Machine learning is becoming increasingly important. Machine learning is required because it is capable of performing tasks that are too complex for a human to perform directly. As humans, we have some limits in that we cannot manually access vast amounts of data, necessitating the use of computer systems, which brings us to machine learning.
We can train machine learning algorithms by giving them with a large amount of data and allowing them to autonomously examine the data, build models, and predict the desired output. The cost function can be used to determine the performance of the machine learning algorithm, which is dependent on the amount of data. We can save both time and money with the help of machine learning.
The importance of machine learning can be easily understood by its uses cases, Currently, machine learning is used in self-driving cars, cyber fraud detection, face recognition, and friend suggestion by Facebook, etc. Various top companies such as Netflix and Amazon have build machine learning models that are using a vast amount of data to analyze the user interest and recommend product accordingly.
Q11) How does machine learning work?
A11) A Machine Learning system learns from previous data, constructs prediction models, and predicts the result whenever fresh data is received. The amount of data helps to construct a better model that predicts the output more precisely, hence the accuracy of anticipated output is dependent on the amount of data.
If we have a complex situation for which we need to make predictions, rather than writing code for it, we may just input the data to generic algorithms, and the machine will develop the logic based on the data and forecast the outcome. Machine learning has shifted our perspective on the issue. The following block diagram depicts how the Machine Learning algorithm works:

Fig 4: Working of ML
Q12) Write the difference between supervised and unsupervised learning?
A12) Difference between supervised and unsupervised learning
Supervised Learning | Unsupervised Learning |
Supervised learning algorithms are trained using labeled data. | Unsupervised learning algorithms are trained using unlabeled data. |
Supervised learning model takes direct feedback to check if it is predicting correct output or not. | Unsupervised learning model does not take any feedback. |
Supervised learning model predicts the output. | Unsupervised learning model finds the hidden patterns in data. |
In supervised learning, input data is provided to the model along with the output. | In unsupervised learning, only input data is provided to the model. |
The goal of supervised learning is to train the model so that it can predict the output when it is given new data. | The goal of unsupervised learning is to find the hidden patterns and useful insights from the unknown dataset. |
Supervised learning needs supervision to train the model. | Unsupervised learning does not need any supervision to train the model. |
Supervised learning can be categorized in Classification and Regression problems. | Unsupervised Learning can be classified in Clustering and Associations problems. |
Supervised learning can be used for those cases where we know the input as well as corresponding outputs. | Unsupervised learning can be used for those cases where we have only input data and no corresponding output data. |
Supervised learning model produces an accurate result. | Unsupervised learning model may give less accurate result as compared to supervised learning. |
Supervised learning is not close to true Artificial intelligence as in this, we first train the model for each data, and then only it can predict the correct output. | Unsupervised learning is more close to the true Artificial Intelligence as it learns similarly as a child learns daily routine things by his experiences. |
It includes various algorithms such as Linear Regression, Logistic Regression, Support Vector Machine, Multi-class Classification, Decision tree, Bayesian Logic, etc. | It includes various algorithms such as Clustering, KNN, and Apriori algorithm. |




