Unit - 4
Transaction Processing Concept
Q1) What is a transaction system?
A1) A transaction is a logical unit of data processing that consists of a collection of database actions. One or more database operations, such as insert, remove, update, or retrieve data, are executed in a transaction. It is an atomic process that is either completed completely or not at all. A read-only transaction is one that involves simply data retrieval and no data updating.
A transaction is a group of operations that are logically related. It consists of a number of tasks. An activity or series of acts is referred to as a transaction. It is carried out by a single user to perform operations on the database's contents.
Each high-level operation can be broken down into several lower-level jobs or operations. A data update operation, for example, can be separated into three tasks:
Read_item() - retrieves a data item from storage and stores it in the main memory.
Modify_item() - Change the item's value in the main memory.
Write_item() - write the changed value to storage from main memory
Only the read item() and write item() methods have access to the database. Similarly, read and write are the fundamental database operations for all transactions.
Q2) Explain testing of serializability?
A2) The Serialization Graph is used to determine whether or not a schedule is Serializable.
Assume you have a schedule S. We create a graph called a precedence graph for S. G = (V, E) is a pair in this graph, where V is a collection of vertices and E is a set of edges. All of the transactions in the schedule are represented by a set of vertices. All edges Ti ->Tj that satisfy one of the three conditions are included in the set of edges:
- If Ti executes write (Q) before Tj executes read(Q), create a node Ti → Tj .
- Create a node Ti → Tj if Ti executes read (Q) before Tj executes write (Q) .
- If Ti executes write (Q) before Tj executes write(Q), create a node Ti → Tj .
Q3) Explain Serializability of Schedules?
A3) If a precedence graph has only one edge Ti Tj, then all of Ti's instructions are performed before the first instruction of Tj.
Schedule S is non-serializable if its precedence graph comprises a cycle. S is serializable if the precedence graph does not have a cycle.
Example
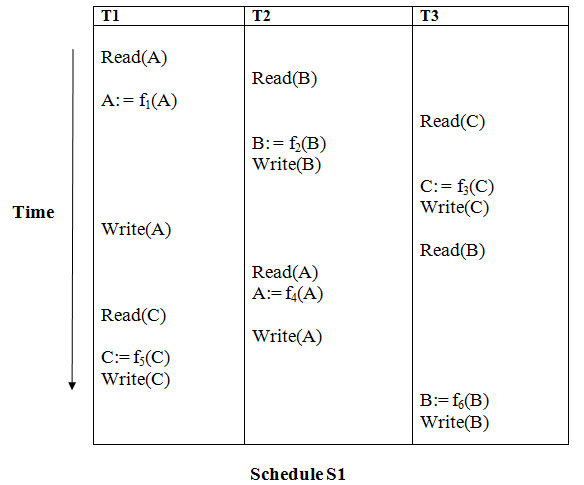
Solution:
Read (A) - There are no new edges in T1 because there are no additional writes to A.
Read (B) - There are no new edges in T2 because there are no subsequent writes to B.
Read (C) - There are no new edges in T3 since there are no additional writes to C.
Write (B) - T3 will read B after that, therefore add edge T2 → T3.
Write (C) - T1 will read C after that, therefore add edge T3 → T1.
Write (A) - T2 will read A after that, therefore add edge T1 → T2.
Write (A) - There are no new edges in T2 because there are no additional reads to A.
Write (C) - There are no new edges in T1 since there are no additional reads to C.
Write (B) - There are no additional readings to B in T3, hence there are no new edges.
Precedence graph for schedule S1:
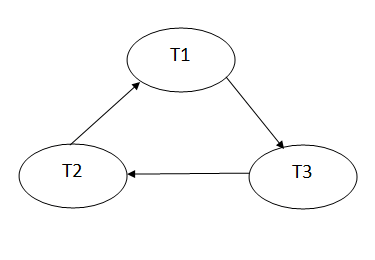
Fig 1: Precedence graph for schedule S1
Schedule S1 has a cycle in its precedence graph, which is why it is non-serializable.
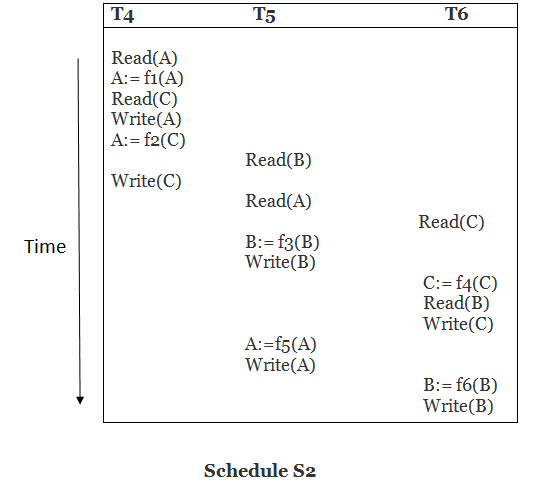
Solution:
Read (A) - There are no new edges in T4 because there are no additional writes to A.
Read (C) - There are no new edges in T4 since there are no additional writes to C.
Write (A) - T5 will read A after that, therefore add edge T4 T5.
Read (B) - There are no new edges in T5 since there are no additional writes to B.
Write (C) - T6 will read C after that, therefore add edge T4 T6.
Write (B) - T6 will read A after that, therefore add edge T5 T6.
Write (C) - There are no subsequent readings to C in T6, hence there are no new edges.
Write (A) - There are no additional reads to A in T5, hence there are no new edges.
Write (B) - There are no additional reads to B in T6, hence there are no new edges.
Precedence graph for schedule S2:
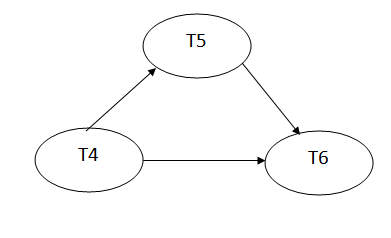
Fig 2: Precedence graph for schedule S2
The precedence graph for schedule S2 contains no cycle that's why ScheduleS2 is serializable.
Q4) Describe conflict schedule?
A4) If a schedule can turn into a serial schedule by exchanging non-conflicting procedures, it is called conflict serializability.
If the schedule is conflict equivalent to a serial schedule, it will be conflict serializable.
When two active transactions conduct non-compatible activities in a schedule with numerous transactions, a conflict develops. When all three of the following requirements exist at the same time, two operations are said to be in conflict.
● The two activities are separated by a transaction.
● Both operations refer to the same data object.
● One of the actions is a write item() operation, which attempts to modify the data item.
Example
Only if S1 and S2 are logically equivalent may they be swapped.
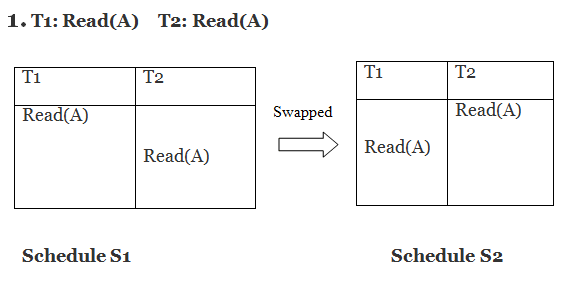
S1 = S2 in this case. This suggests there isn't any conflict.
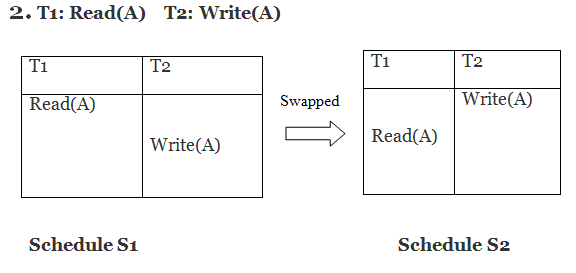
S1 ≠ S2 in this case. That suggests there's a fight going on.
Conflict Equivalent
By switching non-conflicting activities, one can be turned into another in the conflict equivalent. S2 is conflict equal to S1 in the example (S1 can be converted to S2 by swapping non-conflicting operations).
If and only if, two schedules are said to be conflict equivalent:
● They both have the identical set of transaction data.
● If each conflict operation pair is ordered the same way.
Example
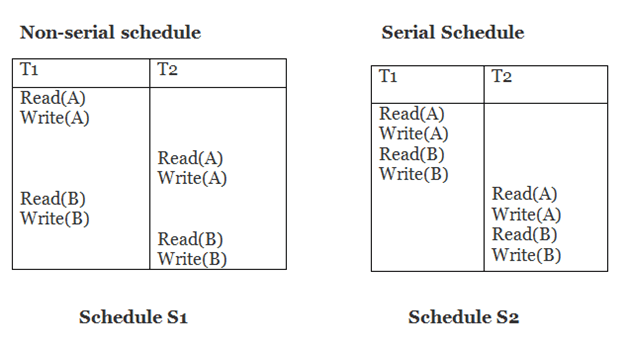
Schedule S2 is a serial schedule since it completes all T1 operations before beginning any T2 operations. By exchanging non-conflicting operations from S1, schedule S1 can be turned into a serial schedule.
The schedule S1 becomes: after exchanging non-conflict operations
T1 | T2 |
Read(A) Write(A) Read(B) Write(B) |
Read(A) Write(A) Read(B) Write(B) |
Since, S1 is conflict serializable.
Q5) Define View Serializability?
A5) If a schedule is viewed as equivalent to a serial schedule, it will be serializable.
If a schedule is view serializable, it is also conflict serializable.
Blind writes are contained in the view serializable, which does not conflict with serializable.
View Equivalent
If two schedules S1 and S2 meet the following criteria, they are said to be view equivalent:
1. Initial Read
Both schedules must be read at the same time. Assume there are two schedules, S1 and S2. If a transaction T1 in schedule S1 reads data item A, then transaction T1 in schedule S2 should likewise read A.
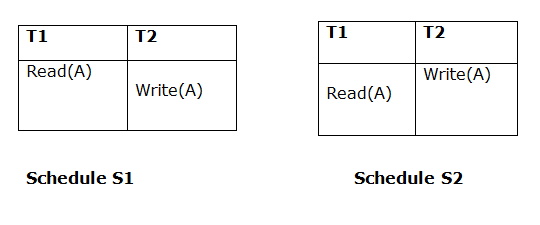
Because T1 performs the initial read operation in S1 and S2, the two schedules are considered comparable.
2. Updated Read
If Ti is reading A, which is updated by Tj in schedule S1, Ti should also read A, which is updated by Tj in schedule S2.
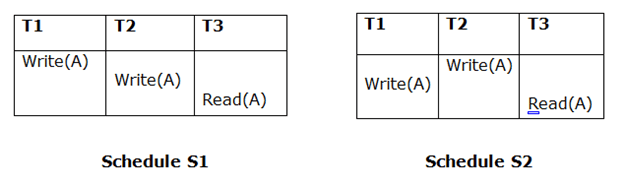
Because T3 in S1 is reading A updated by T2 and T3 in S2 is reading A updated by T1, the two schedules are not equivalent.
3. Final Write
The final writing for both schedules must be the same. If a transaction T1 updates A last in schedule S1, T1 should also perform final writes operations in schedule S2.
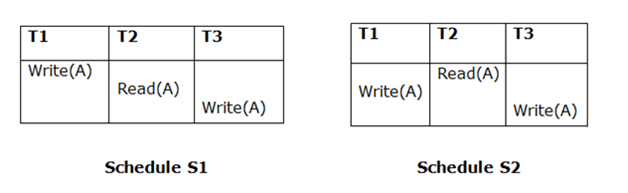
Because T3 performs the final write operation in S1 and T3 performs the final write operation in S2, the two schedules are considered equivalent.
Example

Schedule S
The total number of possible schedules grows to three with three transactions.
= 3! = 6
S1 = <T1 T2 T3>
S2 = <T1 T3 T2>
S3 = <T2 T3 T1>
S4 = <T2 T1 T3>
S5 = <T3 T1 T2>
S6 = <T3 T2 T1>
Taking first schedule S1:

Schedule S1:
Step 1 - final updation on data items
There is no read besides the initial read in both schedules S and S1, thus we don't need to check that condition.
Step 2 - Initial Read
T1 performs the initial read operation in S, and T1 also performs it in S1.
Step 3 - Final Write
T3 performs the final write operation in S, and T3 also performs it in S1. As a result, S and S1 are viewed as equivalent.
We don't need to verify another schedule because the first one, S1, meets all three criteria.
As a result, the comparable serial schedule is as follows:
T1 → T2 → T3
Q6) What is recoverability?
A6) Due to a software fault, system crash, or hardware malfunction, a transaction may not finish completely. The unsuccessful transaction must be rolled back in this scenario. However, the value generated by the unsuccessful transaction may have been utilised by another transaction. As a result, we must also rollback those transactions. Table displays a schedule with two transactions.
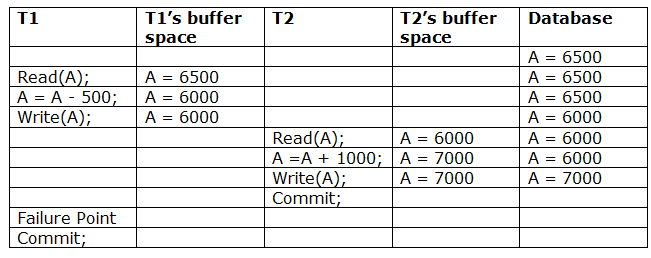
T1 reads and writes the value of A, which is read and written by T2.T2 commits, but T1 fails later. As a result of the failure, we must rollback T1.T2 should also be rolled back because it reads the value written by T1, but T2 can't because it has already committed.
Irrecoverable schedule: If Tj receives the revised value of Ti and commits before Ti commits, the schedule will be irreversible.
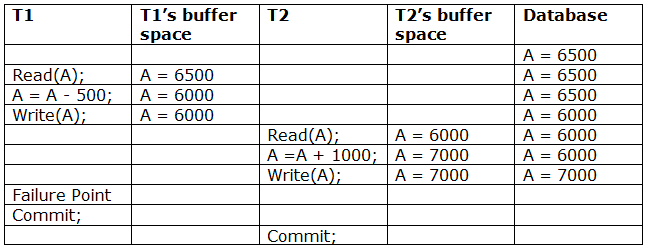
A schedule with two transactions is shown in table 2 above. Transaction T1 reads and writes A, and transaction T2 reads and writes that value. T1 eventually fails. As a result, T1 must be rolled back. Because T2 has read the value written by T1, T2 should be rolled back. We can rewind transaction T2 as well because it hasn't been committed before T1. As a result, cascade rollback can be used to recover it.
Recoverable with cascading rollback: If Tj reads the modified value of Ti, the schedule can be recovered using cascading rollback. Tj's commit is postponed till Ti's is completed.
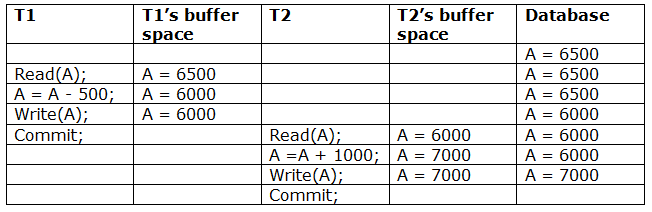
A schedule with two transactions is shown in Table 3 above. T1 commits after reading and writing A, and T2 reads and writes that value. As a result, this is a less recoverable cascade schedule.
Q7) How to recover from transaction failure?
A7) When a transaction fails to execute or reaches a point where it can't go any further, it is called a transaction failure. Transaction failure occurs when a number of transactions or processes are harmed.
Logical errors: When a transaction cannot complete owing to a coding error or an internal error situation, a logical error occurs.
Syntax error: When a database management system (DBMS) stops an active transaction because the database system is unable to perform it, this is known as a syntax error. For example, in the event of a deadlock or resource unavailability, the system aborts an active transaction.
When a system crashes, numerous transactions may be running and various files may be open, allowing them to modify data items. Transactions are made up of a variety of operations that are all atomic. However, atomicity of transactions as a whole must be preserved, which means that either all or none of the operations must be done, depending on the ACID features of DBMS.
When a database management system (DBMS) recovers after a crash -
● It should check the statuses of all the transactions that were in progress.
● A transaction may be in the middle of an operation; in this situation, the DBMS must ensure the transaction's atomicity.
● It should determine if the transaction can be completed at this time or whether it has to be turned back.
● There would be no transactions that would leave the DBMS in an inconsistent state.
Maintaining the logs of each transaction and writing them onto some stable storage before actually altering the database are two strategies that can assist a DBMS in recovering and maintaining the atomicity of a transaction.
There are two sorts of approaches that can assist a DBMS in recovering and sustaining transaction atomicity.
● Maintaining shadow paging, in which updates are made in volatile memory and the actual database is updated afterwards.
● Before actually altering the database, keep track of each transaction's logs and save them somewhere safe.
Q8) Explain log based recovery?
A8) The log is made up of a series of records. Each transaction is logged and stored in a secure location so that it may be recovered in the event of a failure.
Any operation that is performed on the database is documented in the log.
However, before the actual transaction is applied to the database, the procedure of saving the logs should be completed.
Let's pretend there's a transaction to change a student's city. This transaction generates the following logs.
● When a transaction is started, the start' log is written.
<Tn, Start>
● Another log is written to the file when the transaction changes the City from 'Noida' to 'Bangalore.'
<Tn, City, 'Noida', 'Bangalore' >
● When the transaction is completed, it writes another log to mark the transaction's completion.
<Tn, Commit>
The database can be modified in two ways:
1. Deferred database modification:
If a transaction does not affect the database until it has committed, it is said to use the postponed modification strategy. When a transaction commits, the database is updated, and all logs are created and stored in the stable storage.
2. Immediate database modification:
If a database change is made while the transaction is still running, the Immediate modification approach is used.
The database is changed immediately after each action in this method. It occurs after a database change has been made.
Recovery using Log records
When a system crashes, the system reads the log to determine which transactions must be undone and which must be redone.
● The Transaction Ti must be redone if the log contains the records <Ti, Start> and <Ti, Commit> or <Ti, Commit>.
● If the log contains the record <Tn, Start> but not the records <Ti, commit> or <Ti, abort>, then the Transaction Ti must be undone.
Q9) What are checkpoints?
A9) The checkpoint is a technique that removes all previous logs from the system and stores them permanently on the storage drive.
The checkpoint functions similarly to a bookmark. Such checkpoints are indicated during transaction execution, and the transaction is then executed utilizing the steps of the transaction, resulting in the creation of log files.
The transaction will be updated into the database when it reaches the checkpoint, and the full log file will be purged from the file until then. The log file is then updated with the new transaction step till the next checkpoint, and so on.
The checkpoint specifies a time when the DBMS was in a consistent state and all transactions had been committed.
Recovery using Checkpoint
A recovery system then restores the database from the failure in the following manner.
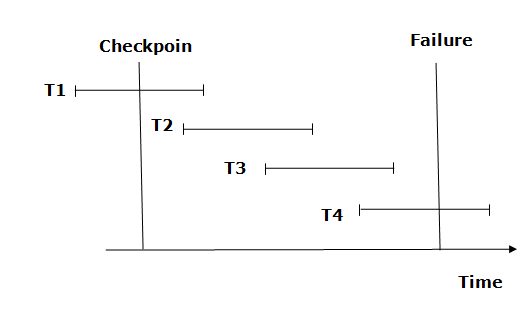
Fig 3: Checkpoint
From beginning to end, the recovery system reads log files. It reads T4 through T1 log files.
A redo-list and an undo-list are kept by the recovery system.
If the recovery system encounters a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, the transaction is put into redo state. All transactions in the redo-list and prior list are removed and then redone before the logs are saved.
Example: <Tn, Start> and <Tn, Commit> will appear in the log file for transactions T2 and T3. In the log file for the T1 transaction, there will be only <Tn, commit>. As a result, after the checkpoint is passed, the transaction is committed. As a result, T1, T2, and T3 transactions are added to the redo list.
If the recovery system finds a log containing Tn, Start> but no commit or abort log, the transaction is put into undo state. All transactions are undone and their logs are erased from the undo-list.
Example: <Tn, Start>, for example, will appear in Transaction T4. As a result, T4 will be added to the undo list because the transaction has not yet been completed and has failed in the middle.
Q10) What do you mean by deadlock handling?
A10) A deadlock occurs when two or more transactions are stuck waiting for one another to release locks indefinitely. Deadlock is regarded to be one of the most dreaded DBMS difficulties because no work is ever completed and remains in a waiting state indefinitely.
For example, transaction T1 has a lock on some entries in the student table and needs to update some rows in the grade table. At the same time, transaction T2 is holding locks on some rows in the grade table and needs to update the rows in the Student table that Transaction T1 is holding.
The primary issue now arises. T1 is currently waiting for T2 to release its lock, and T2 is currently waiting for T1 to release its lock. All actions come to a complete halt and remain in this state. It will remain at a halt until the database management system (DBMS) recognizes the deadlock and aborts one of the transactions.
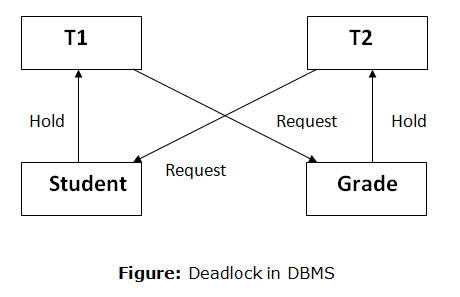
Fig 5: Deadlock
Deadlock Avoidance
When a database becomes stuck in a deadlock condition, it is preferable to avoid the database rather than abort or restate it. This is a waste of both time and money.
Any deadlock condition is detected in advance using a deadlock avoidance strategy. For detecting deadlocks, a method such as "wait for graph" is employed, although this method is only effective for smaller databases. A deadlock prevention strategy can be utilized for larger databases.
Deadlock Detection
When a transaction in a database waits endlessly for a lock, the database management system (DBMS) should determine whether the transaction is in a deadlock or not. The lock management keeps a Wait for the graph to detect the database's deadlock cycle.
Wait for Graph
This is the best way for detecting deadlock. This method generates a graph based on the transaction and its lock. There is a deadlock if the constructed graph has a cycle or closed loop.
The system maintains a wait for the graph for each transaction that is awaiting data from another transaction. If there is a cycle in the graph, the system will keep checking it.
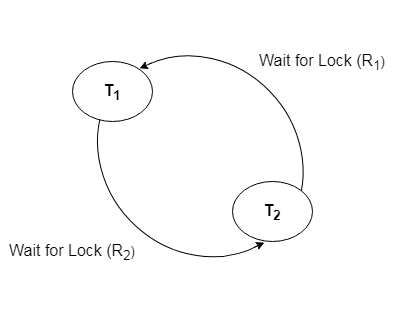
Fig 6: Wait for a graph
Deadlock Prevention
A huge database can benefit from a deadlock prevention strategy. Deadlock can be avoided if resources are distributed in such a way that deadlock never arises.
The database management system examines the transaction's operations to see if they are likely to cause a deadlock. If they do, the database management system (DBMS) never allows that transaction to be completed.
Q11) Explain distributed data storage?
A11) A distributed database is a database that is not restricted to a single system and is dispersed across numerous places, such as multiple computers or a network of computers. A distributed database system is made up of multiple sites with no physical components in common. This may be necessary if a database needs to be viewed by a large number of people all over the world. It must be administered in such a way that it appears to users as a single database.
Distributed data storage
Data can be kept on separate sites in two different ways. These are the following:
- Replication
The complete relation is stored redundantly at two or more sites in this manner. It is a fully redundant database if the entire database is available at all sites. As a result, in replication, systems keep duplicates of data.
This is useful since it increases data availability across several places. Query queries can now be executed in parallel as well.
It does, however, have some downsides. Data must be updated on a regular basis. Any modification made at one site must be recorded at every site where that relationship is saved, or else inconsistency would result. This is a significant amount of overhead. Concurrent access must now be checked across multiple sites, making concurrency control much more difficult.
2. Fragmentation
The relations are broken (i.e., divided into smaller portions) with this manner, and each of the fragments is kept in multiple locations as needed. It must be ensured that the fragments can be utilized to recreate the original relationship (i.e. that no data is lost).
Fragmentation is useful since it avoids the creation of duplicate data, and consistency is not an issue.
Relationships can be fragmented in two ways:
Horizontal fragmentation – Splitting by rows –Each tuple is assigned to at least one fragment once the relation is broken into groups of tuples.
Vertical fragmentation – Splitting by columns – The relation's schema is broken into smaller schemas. To ensure a lossless join, each fragment must have a common candidate key.
Q12) Explain concurrency control?
A12) Concurrency Control is a management process for controlling the concurrent execution of database operations.
Concurrent Execution
Multiple users can access and use the same database at the same time in a multi-user system, which is known as concurrent database execution. It means that different users on a multi-user system are running the same database at the same time.
When working on database transactions, it may be necessary to use the database by numerous users to complete separate activities, in which case concurrent database execution is performed.
The thing is, the simultaneous execution should be done in an interleaved way, with no action interfering with the other performing activities, thereby maintaining database consistency. As a result, when the transaction procedures are executed concurrently, various difficult challenges arise that must be resolved.
Concurrency Control is the working concept for controlling and managing the concurrent execution of database activities and therefore avoiding database inconsistencies. As a result, we have concurrency control techniques for preserving database concurrency.
Protocols
Concurrency control techniques ensure atomicity, consistency, isolation, durability, and serializability of database transactions while they are being executed concurrently. As a result, these protocols are classified as follows:
● Lock based protocols
● Timestamp based protocols
Q13) Describe Lock based protocols?
A13) Lock-based protocols in database systems use a method that prevents any transaction from reading or writing data until it obtains an appropriate lock on it. There are two types of locks.
Binary Locks - A data item's lock can be in one of two states: locked or unlocked.
Shared/exclusive - This sort of locking mechanism distinguishes the locks according to their intended usage. It is an exclusive lock when a lock is obtained on a data item in order to perform a write operation. Allowing many transactions to write to the same data item would cause the database to become incompatible. Because no data value is changed, read locks are shared.
There are four different types of lock procedures.
Simplistic Lock Protocol
Transactions can obtain a lock on every object before performing a 'write' operation using simple lock-based protocols. After performing the ‘write' procedure, transactions may unlock the data item.
Pre-claiming Lock Protocol
Pre-claiming protocols assess their activities and generate a list of data items for which locks are required. Before beginning an execution, the transaction requests all of the locks it will require from the system. If all of the locks are granted, the transaction runs and then releases all of the locks when it's finished. If none of the locks are granted, the transaction is aborted and the user must wait until all of the locks are granted.
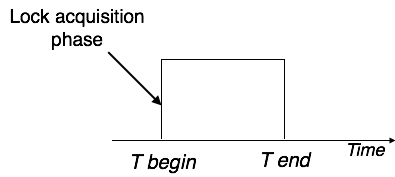
Fig 7: Pre claiming lock protocol
Two-Phase Locking 2PL
This locking protocol divides a transaction's execution phase into three segments. When the transaction first starts, it asks for permission to obtain the locks it requires. The transaction then obtains all of the locks in the second section. The third phase begins as soon as the transaction's first lock is released. The transaction can't demand any additional locks at this point; it can only release the ones it already possesses.
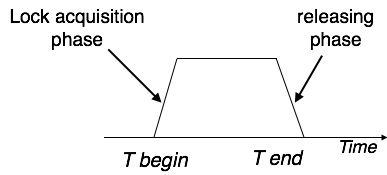
Fig 8: Two phase locking
Two-phase locking has two phases: one is growing, in which the transaction acquires all of the locks, and the other is shrinking, in which the transaction releases the locks it has gained.
A transaction must first obtain a shared (read) lock and then upgrade it to an exclusive lock in order to claim an exclusive (write) lock.
Strict Two-Phase Locking
Strict-2PL's initial phase is identical as 2PL's. The transaction continues to run normally after gaining all of the locks in the first phase. However, unlike 2PL, Strict-2PL does not release a lock after it has been used. Strict-2PL keeps all locks until the commit point, then releases them all at once.
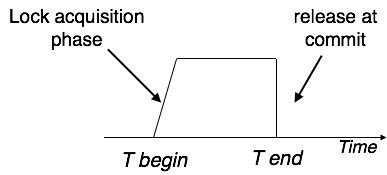
Fig 9: Strict two phase locking
Q14) Explain Timestamp-based Protocols?
A14) The timestamp-based protocol is the most widely used concurrency protocol. As a timestamp, this protocol employs either system time or a logical counter.
At the moment of execution, lock-based protocols regulate the order between conflicting pairings among transactions, whereas timestamp-based protocols begin working as soon as a transaction is initiated.
Every transaction has a timestamp, and the order of the transactions is controlled by the transaction's age. All subsequent transactions would be older than a transaction started at 0002 clock time. For example, any transaction 'y' entering the system at 0004 is two seconds younger than the older one, and the older one will be prioritized.
In addition, the most recent read and write timestamps are assigned to each data item. This tells the system when the last ‘read and write' operation on the data item was done.
Q15) Write about the directory system?
A15) A directory is a type of container that holds folders and files. It uses a hierarchical structure to organize files and directories.
A directory can have numerous logical structures, which are listed below.
Single level directory
The simplest directory structure is a single-level directory. All files are stored in the same directory, making it simple to maintain and comprehend.
When the number of files grows or the system has more than one user, a single level directory becomes a severe constraint. Because all of the files are in the same directory, they must all be named differently. The unique name rule is broken if two users call their dataset test.
Two level directory
As we've seen, a single-level directory frequently leads to file name confusion among users. This problem can be solved by creating a different directory for each user.
Each user has their own user files directory in the two-level directory structure (UFD). The UFDs have similar architecture, but only one user's files are listed in each. When a new user id=s logs in, the system's master file directory (MFD) is searched. Each element in the MFD points to the user's UFD, which is indexed by username or account number.
Tree structured directory
The natural generalization of a two-level directory as a tree of height 2 is to extend the directory structure to a tree of any height.
This generalization enables users to construct their own subdirectories and organize their files as needed.
The most frequent directory structure is a tree structure. Every file in the system has a unique path, and the tree has a root directory.
Unit - 4
Transaction Processing Concept
Q1) What is a transaction system?
A1) A transaction is a logical unit of data processing that consists of a collection of database actions. One or more database operations, such as insert, remove, update, or retrieve data, are executed in a transaction. It is an atomic process that is either completed completely or not at all. A read-only transaction is one that involves simply data retrieval and no data updating.
A transaction is a group of operations that are logically related. It consists of a number of tasks. An activity or series of acts is referred to as a transaction. It is carried out by a single user to perform operations on the database's contents.
Each high-level operation can be broken down into several lower-level jobs or operations. A data update operation, for example, can be separated into three tasks:
Read_item() - retrieves a data item from storage and stores it in the main memory.
Modify_item() - Change the item's value in the main memory.
Write_item() - write the changed value to storage from main memory
Only the read item() and write item() methods have access to the database. Similarly, read and write are the fundamental database operations for all transactions.
Q2) Explain testing of serializability?
A2) The Serialization Graph is used to determine whether or not a schedule is Serializable.
Assume you have a schedule S. We create a graph called a precedence graph for S. G = (V, E) is a pair in this graph, where V is a collection of vertices and E is a set of edges. All of the transactions in the schedule are represented by a set of vertices. All edges Ti ->Tj that satisfy one of the three conditions are included in the set of edges:
- If Ti executes write (Q) before Tj executes read(Q), create a node Ti → Tj .
- Create a node Ti → Tj if Ti executes read (Q) before Tj executes write (Q) .
- If Ti executes write (Q) before Tj executes write(Q), create a node Ti → Tj .
Q3) Explain Serializability of Schedules?
A3) If a precedence graph has only one edge Ti Tj, then all of Ti's instructions are performed before the first instruction of Tj.
Schedule S is non-serializable if its precedence graph comprises a cycle. S is serializable if the precedence graph does not have a cycle.
Example
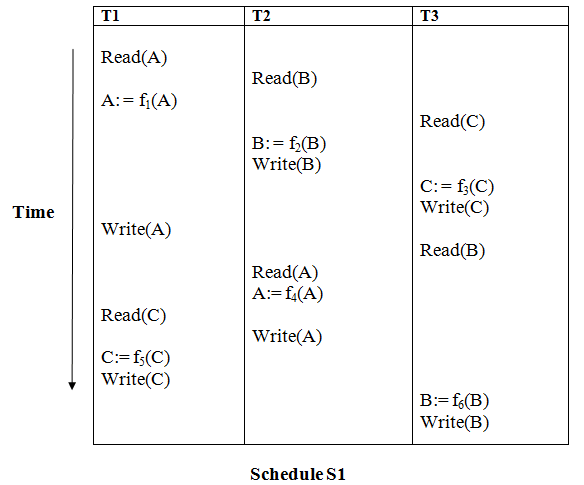
Solution:
Read (A) - There are no new edges in T1 because there are no additional writes to A.
Read (B) - There are no new edges in T2 because there are no subsequent writes to B.
Read (C) - There are no new edges in T3 since there are no additional writes to C.
Write (B) - T3 will read B after that, therefore add edge T2 → T3.
Write (C) - T1 will read C after that, therefore add edge T3 → T1.
Write (A) - T2 will read A after that, therefore add edge T1 → T2.
Write (A) - There are no new edges in T2 because there are no additional reads to A.
Write (C) - There are no new edges in T1 since there are no additional reads to C.
Write (B) - There are no additional readings to B in T3, hence there are no new edges.
Precedence graph for schedule S1:
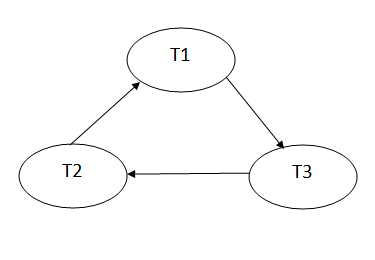
Fig 1: Precedence graph for schedule S1
Schedule S1 has a cycle in its precedence graph, which is why it is non-serializable.
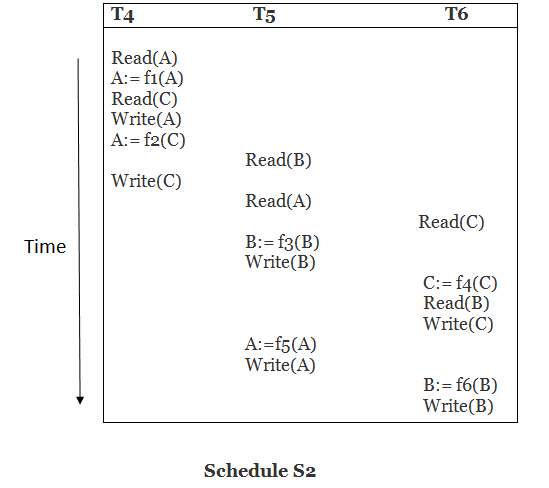
Solution:
Read (A) - There are no new edges in T4 because there are no additional writes to A.
Read (C) - There are no new edges in T4 since there are no additional writes to C.
Write (A) - T5 will read A after that, therefore add edge T4 T5.
Read (B) - There are no new edges in T5 since there are no additional writes to B.
Write (C) - T6 will read C after that, therefore add edge T4 T6.
Write (B) - T6 will read A after that, therefore add edge T5 T6.
Write (C) - There are no subsequent readings to C in T6, hence there are no new edges.
Write (A) - There are no additional reads to A in T5, hence there are no new edges.
Write (B) - There are no additional reads to B in T6, hence there are no new edges.
Precedence graph for schedule S2:
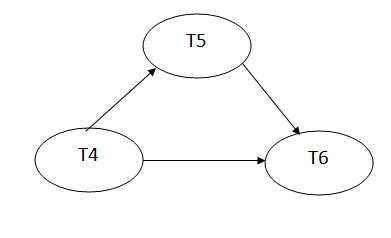
Fig 2: Precedence graph for schedule S2
The precedence graph for schedule S2 contains no cycle that's why ScheduleS2 is serializable.
Q4) Describe conflict schedule?
A4) If a schedule can turn into a serial schedule by exchanging non-conflicting procedures, it is called conflict serializability.
If the schedule is conflict equivalent to a serial schedule, it will be conflict serializable.
When two active transactions conduct non-compatible activities in a schedule with numerous transactions, a conflict develops. When all three of the following requirements exist at the same time, two operations are said to be in conflict.
● The two activities are separated by a transaction.
● Both operations refer to the same data object.
● One of the actions is a write item() operation, which attempts to modify the data item.
Example
Only if S1 and S2 are logically equivalent may they be swapped.
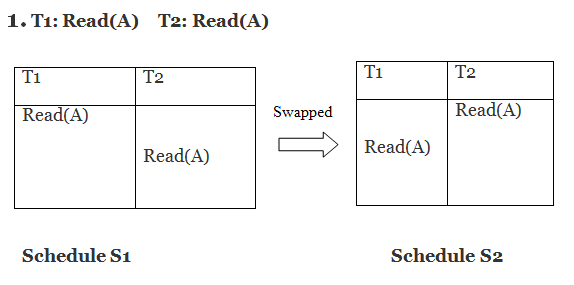
S1 = S2 in this case. This suggests there isn't any conflict.
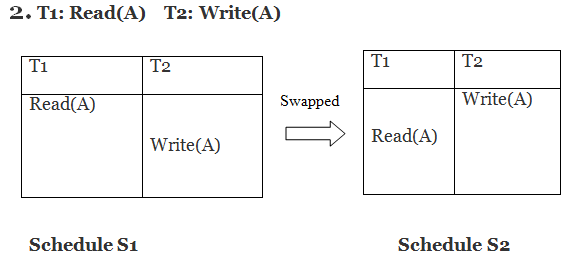
S1 ≠ S2 in this case. That suggests there's a fight going on.
Conflict Equivalent
By switching non-conflicting activities, one can be turned into another in the conflict equivalent. S2 is conflict equal to S1 in the example (S1 can be converted to S2 by swapping non-conflicting operations).
If and only if, two schedules are said to be conflict equivalent:
● They both have the identical set of transaction data.
● If each conflict operation pair is ordered the same way.
Example
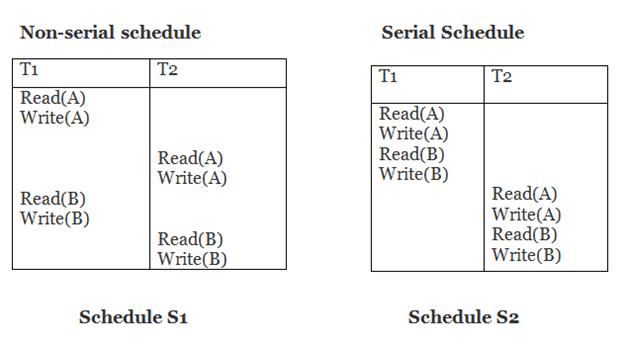
Schedule S2 is a serial schedule since it completes all T1 operations before beginning any T2 operations. By exchanging non-conflicting operations from S1, schedule S1 can be turned into a serial schedule.
The schedule S1 becomes: after exchanging non-conflict operations
T1 | T2 |
Read(A) Write(A) Read(B) Write(B) |
Read(A) Write(A) Read(B) Write(B) |
Since, S1 is conflict serializable.
Q5) Define View Serializability?
A5) If a schedule is viewed as equivalent to a serial schedule, it will be serializable.
If a schedule is view serializable, it is also conflict serializable.
Blind writes are contained in the view serializable, which does not conflict with serializable.
View Equivalent
If two schedules S1 and S2 meet the following criteria, they are said to be view equivalent:
1. Initial Read
Both schedules must be read at the same time. Assume there are two schedules, S1 and S2. If a transaction T1 in schedule S1 reads data item A, then transaction T1 in schedule S2 should likewise read A.
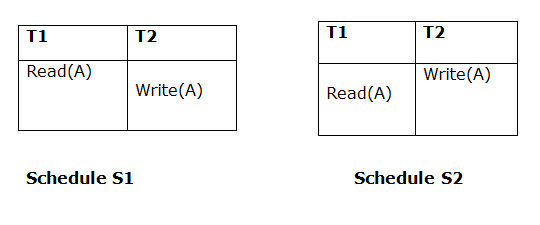
Because T1 performs the initial read operation in S1 and S2, the two schedules are considered comparable.
2. Updated Read
If Ti is reading A, which is updated by Tj in schedule S1, Ti should also read A, which is updated by Tj in schedule S2.
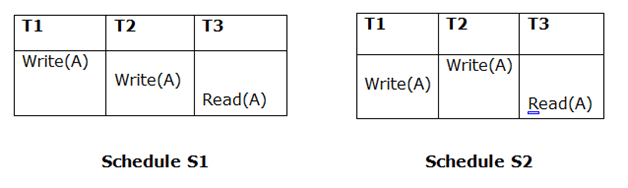
Because T3 in S1 is reading A updated by T2 and T3 in S2 is reading A updated by T1, the two schedules are not equivalent.
3. Final Write
The final writing for both schedules must be the same. If a transaction T1 updates A last in schedule S1, T1 should also perform final writes operations in schedule S2.
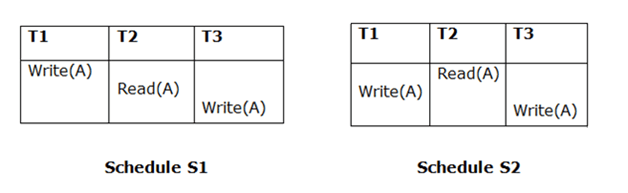
Because T3 performs the final write operation in S1 and T3 performs the final write operation in S2, the two schedules are considered equivalent.
Example

Schedule S
The total number of possible schedules grows to three with three transactions.
= 3! = 6
S1 = <T1 T2 T3>
S2 = <T1 T3 T2>
S3 = <T2 T3 T1>
S4 = <T2 T1 T3>
S5 = <T3 T1 T2>
S6 = <T3 T2 T1>
Taking first schedule S1:

Schedule S1:
Step 1 - final updation on data items
There is no read besides the initial read in both schedules S and S1, thus we don't need to check that condition.
Step 2 - Initial Read
T1 performs the initial read operation in S, and T1 also performs it in S1.
Step 3 - Final Write
T3 performs the final write operation in S, and T3 also performs it in S1. As a result, S and S1 are viewed as equivalent.
We don't need to verify another schedule because the first one, S1, meets all three criteria.
As a result, the comparable serial schedule is as follows:
T1 → T2 → T3
Q6) What is recoverability?
A6) Due to a software fault, system crash, or hardware malfunction, a transaction may not finish completely. The unsuccessful transaction must be rolled back in this scenario. However, the value generated by the unsuccessful transaction may have been utilised by another transaction. As a result, we must also rollback those transactions. Table displays a schedule with two transactions.
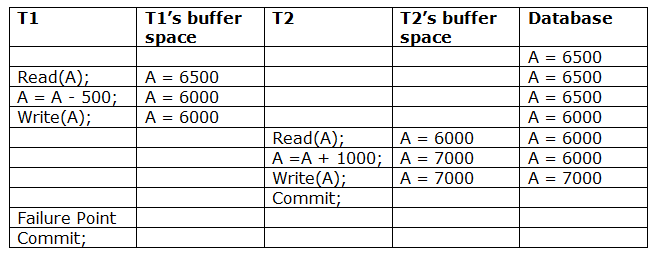
T1 reads and writes the value of A, which is read and written by T2.T2 commits, but T1 fails later. As a result of the failure, we must rollback T1.T2 should also be rolled back because it reads the value written by T1, but T2 can't because it has already committed.
Irrecoverable schedule: If Tj receives the revised value of Ti and commits before Ti commits, the schedule will be irreversible.
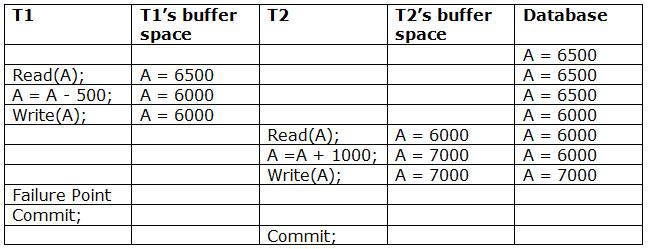
A schedule with two transactions is shown in table 2 above. Transaction T1 reads and writes A, and transaction T2 reads and writes that value. T1 eventually fails. As a result, T1 must be rolled back. Because T2 has read the value written by T1, T2 should be rolled back. We can rewind transaction T2 as well because it hasn't been committed before T1. As a result, cascade rollback can be used to recover it.
Recoverable with cascading rollback: If Tj reads the modified value of Ti, the schedule can be recovered using cascading rollback. Tj's commit is postponed till Ti's is completed.
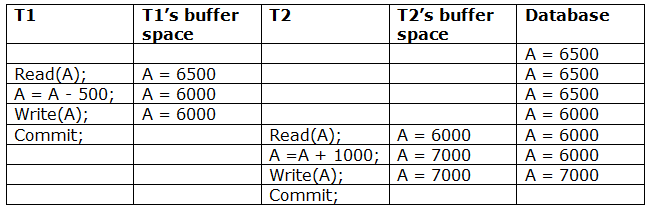
A schedule with two transactions is shown in Table 3 above. T1 commits after reading and writing A, and T2 reads and writes that value. As a result, this is a less recoverable cascade schedule.
Q7) How to recover from transaction failure?
A7) When a transaction fails to execute or reaches a point where it can't go any further, it is called a transaction failure. Transaction failure occurs when a number of transactions or processes are harmed.
Logical errors: When a transaction cannot complete owing to a coding error or an internal error situation, a logical error occurs.
Syntax error: When a database management system (DBMS) stops an active transaction because the database system is unable to perform it, this is known as a syntax error. For example, in the event of a deadlock or resource unavailability, the system aborts an active transaction.
When a system crashes, numerous transactions may be running and various files may be open, allowing them to modify data items. Transactions are made up of a variety of operations that are all atomic. However, atomicity of transactions as a whole must be preserved, which means that either all or none of the operations must be done, depending on the ACID features of DBMS.
When a database management system (DBMS) recovers after a crash -
● It should check the statuses of all the transactions that were in progress.
● A transaction may be in the middle of an operation; in this situation, the DBMS must ensure the transaction's atomicity.
● It should determine if the transaction can be completed at this time or whether it has to be turned back.
● There would be no transactions that would leave the DBMS in an inconsistent state.
Maintaining the logs of each transaction and writing them onto some stable storage before actually altering the database are two strategies that can assist a DBMS in recovering and maintaining the atomicity of a transaction.
There are two sorts of approaches that can assist a DBMS in recovering and sustaining transaction atomicity.
● Maintaining shadow paging, in which updates are made in volatile memory and the actual database is updated afterwards.
● Before actually altering the database, keep track of each transaction's logs and save them somewhere safe.
Q8) Explain log based recovery?
A8) The log is made up of a series of records. Each transaction is logged and stored in a secure location so that it may be recovered in the event of a failure.
Any operation that is performed on the database is documented in the log.
However, before the actual transaction is applied to the database, the procedure of saving the logs should be completed.
Let's pretend there's a transaction to change a student's city. This transaction generates the following logs.
● When a transaction is started, the start' log is written.
<Tn, Start>
● Another log is written to the file when the transaction changes the City from 'Noida' to 'Bangalore.'
<Tn, City, 'Noida', 'Bangalore' >
● When the transaction is completed, it writes another log to mark the transaction's completion.
<Tn, Commit>
The database can be modified in two ways:
1. Deferred database modification:
If a transaction does not affect the database until it has committed, it is said to use the postponed modification strategy. When a transaction commits, the database is updated, and all logs are created and stored in the stable storage.
2. Immediate database modification:
If a database change is made while the transaction is still running, the Immediate modification approach is used.
The database is changed immediately after each action in this method. It occurs after a database change has been made.
Recovery using Log records
When a system crashes, the system reads the log to determine which transactions must be undone and which must be redone.
● The Transaction Ti must be redone if the log contains the records <Ti, Start> and <Ti, Commit> or <Ti, Commit>.
● If the log contains the record <Tn, Start> but not the records <Ti, commit> or <Ti, abort>, then the Transaction Ti must be undone.
Q9) What are checkpoints?
A9) The checkpoint is a technique that removes all previous logs from the system and stores them permanently on the storage drive.
The checkpoint functions similarly to a bookmark. Such checkpoints are indicated during transaction execution, and the transaction is then executed utilizing the steps of the transaction, resulting in the creation of log files.
The transaction will be updated into the database when it reaches the checkpoint, and the full log file will be purged from the file until then. The log file is then updated with the new transaction step till the next checkpoint, and so on.
The checkpoint specifies a time when the DBMS was in a consistent state and all transactions had been committed.
Recovery using Checkpoint
A recovery system then restores the database from the failure in the following manner.
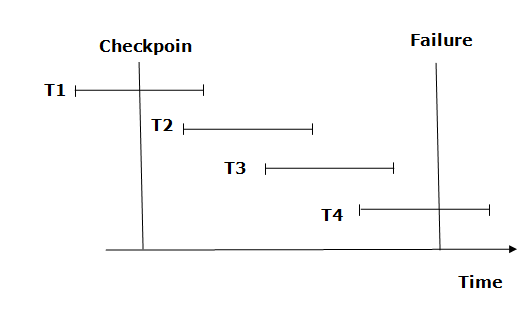
Fig 3: Checkpoint
From beginning to end, the recovery system reads log files. It reads T4 through T1 log files.
A redo-list and an undo-list are kept by the recovery system.
If the recovery system encounters a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, the transaction is put into redo state. All transactions in the redo-list and prior list are removed and then redone before the logs are saved.
Example: <Tn, Start> and <Tn, Commit> will appear in the log file for transactions T2 and T3. In the log file for the T1 transaction, there will be only <Tn, commit>. As a result, after the checkpoint is passed, the transaction is committed. As a result, T1, T2, and T3 transactions are added to the redo list.
If the recovery system finds a log containing Tn, Start> but no commit or abort log, the transaction is put into undo state. All transactions are undone and their logs are erased from the undo-list.
Example: <Tn, Start>, for example, will appear in Transaction T4. As a result, T4 will be added to the undo list because the transaction has not yet been completed and has failed in the middle.
Q10) What do you mean by deadlock handling?
A10) A deadlock occurs when two or more transactions are stuck waiting for one another to release locks indefinitely. Deadlock is regarded to be one of the most dreaded DBMS difficulties because no work is ever completed and remains in a waiting state indefinitely.
For example, transaction T1 has a lock on some entries in the student table and needs to update some rows in the grade table. At the same time, transaction T2 is holding locks on some rows in the grade table and needs to update the rows in the Student table that Transaction T1 is holding.
The primary issue now arises. T1 is currently waiting for T2 to release its lock, and T2 is currently waiting for T1 to release its lock. All actions come to a complete halt and remain in this state. It will remain at a halt until the database management system (DBMS) recognizes the deadlock and aborts one of the transactions.
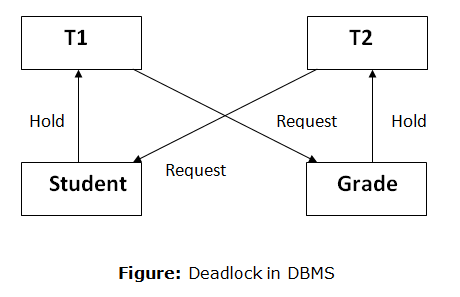
Fig 5: Deadlock
Deadlock Avoidance
When a database becomes stuck in a deadlock condition, it is preferable to avoid the database rather than abort or restate it. This is a waste of both time and money.
Any deadlock condition is detected in advance using a deadlock avoidance strategy. For detecting deadlocks, a method such as "wait for graph" is employed, although this method is only effective for smaller databases. A deadlock prevention strategy can be utilized for larger databases.
Deadlock Detection
When a transaction in a database waits endlessly for a lock, the database management system (DBMS) should determine whether the transaction is in a deadlock or not. The lock management keeps a Wait for the graph to detect the database's deadlock cycle.
Wait for Graph
This is the best way for detecting deadlock. This method generates a graph based on the transaction and its lock. There is a deadlock if the constructed graph has a cycle or closed loop.
The system maintains a wait for the graph for each transaction that is awaiting data from another transaction. If there is a cycle in the graph, the system will keep checking it.
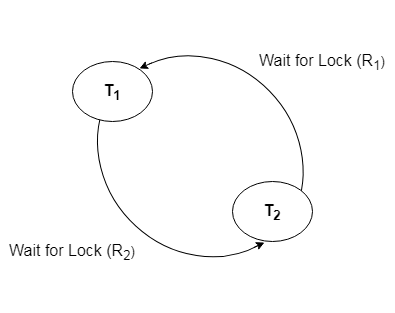
Fig 6: Wait for a graph
Deadlock Prevention
A huge database can benefit from a deadlock prevention strategy. Deadlock can be avoided if resources are distributed in such a way that deadlock never arises.
The database management system examines the transaction's operations to see if they are likely to cause a deadlock. If they do, the database management system (DBMS) never allows that transaction to be completed.
Q11) Explain distributed data storage?
A11) A distributed database is a database that is not restricted to a single system and is dispersed across numerous places, such as multiple computers or a network of computers. A distributed database system is made up of multiple sites with no physical components in common. This may be necessary if a database needs to be viewed by a large number of people all over the world. It must be administered in such a way that it appears to users as a single database.
Distributed data storage
Data can be kept on separate sites in two different ways. These are the following:
- Replication
The complete relation is stored redundantly at two or more sites in this manner. It is a fully redundant database if the entire database is available at all sites. As a result, in replication, systems keep duplicates of data.
This is useful since it increases data availability across several places. Query queries can now be executed in parallel as well.
It does, however, have some downsides. Data must be updated on a regular basis. Any modification made at one site must be recorded at every site where that relationship is saved, or else inconsistency would result. This is a significant amount of overhead. Concurrent access must now be checked across multiple sites, making concurrency control much more difficult.
2. Fragmentation
The relations are broken (i.e., divided into smaller portions) with this manner, and each of the fragments is kept in multiple locations as needed. It must be ensured that the fragments can be utilized to recreate the original relationship (i.e. that no data is lost).
Fragmentation is useful since it avoids the creation of duplicate data, and consistency is not an issue.
Relationships can be fragmented in two ways:
Horizontal fragmentation – Splitting by rows –Each tuple is assigned to at least one fragment once the relation is broken into groups of tuples.
Vertical fragmentation – Splitting by columns – The relation's schema is broken into smaller schemas. To ensure a lossless join, each fragment must have a common candidate key.
Q12) Explain concurrency control?
A12) Concurrency Control is a management process for controlling the concurrent execution of database operations.
Concurrent Execution
Multiple users can access and use the same database at the same time in a multi-user system, which is known as concurrent database execution. It means that different users on a multi-user system are running the same database at the same time.
When working on database transactions, it may be necessary to use the database by numerous users to complete separate activities, in which case concurrent database execution is performed.
The thing is, the simultaneous execution should be done in an interleaved way, with no action interfering with the other performing activities, thereby maintaining database consistency. As a result, when the transaction procedures are executed concurrently, various difficult challenges arise that must be resolved.
Concurrency Control is the working concept for controlling and managing the concurrent execution of database activities and therefore avoiding database inconsistencies. As a result, we have concurrency control techniques for preserving database concurrency.
Protocols
Concurrency control techniques ensure atomicity, consistency, isolation, durability, and serializability of database transactions while they are being executed concurrently. As a result, these protocols are classified as follows:
● Lock based protocols
● Timestamp based protocols
Q13) Describe Lock based protocols?
A13) Lock-based protocols in database systems use a method that prevents any transaction from reading or writing data until it obtains an appropriate lock on it. There are two types of locks.
Binary Locks - A data item's lock can be in one of two states: locked or unlocked.
Shared/exclusive - This sort of locking mechanism distinguishes the locks according to their intended usage. It is an exclusive lock when a lock is obtained on a data item in order to perform a write operation. Allowing many transactions to write to the same data item would cause the database to become incompatible. Because no data value is changed, read locks are shared.
There are four different types of lock procedures.
Simplistic Lock Protocol
Transactions can obtain a lock on every object before performing a 'write' operation using simple lock-based protocols. After performing the ‘write' procedure, transactions may unlock the data item.
Pre-claiming Lock Protocol
Pre-claiming protocols assess their activities and generate a list of data items for which locks are required. Before beginning an execution, the transaction requests all of the locks it will require from the system. If all of the locks are granted, the transaction runs and then releases all of the locks when it's finished. If none of the locks are granted, the transaction is aborted and the user must wait until all of the locks are granted.
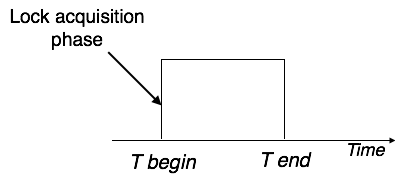
Fig 7: Pre claiming lock protocol
Two-Phase Locking 2PL
This locking protocol divides a transaction's execution phase into three segments. When the transaction first starts, it asks for permission to obtain the locks it requires. The transaction then obtains all of the locks in the second section. The third phase begins as soon as the transaction's first lock is released. The transaction can't demand any additional locks at this point; it can only release the ones it already possesses.
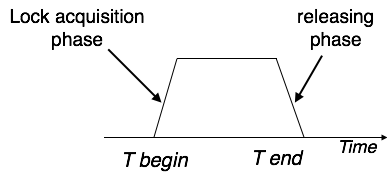
Fig 8: Two phase locking
Two-phase locking has two phases: one is growing, in which the transaction acquires all of the locks, and the other is shrinking, in which the transaction releases the locks it has gained.
A transaction must first obtain a shared (read) lock and then upgrade it to an exclusive lock in order to claim an exclusive (write) lock.
Strict Two-Phase Locking
Strict-2PL's initial phase is identical as 2PL's. The transaction continues to run normally after gaining all of the locks in the first phase. However, unlike 2PL, Strict-2PL does not release a lock after it has been used. Strict-2PL keeps all locks until the commit point, then releases them all at once.
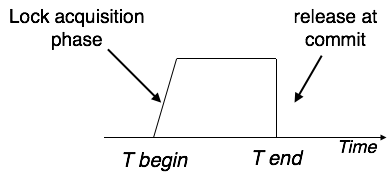
Fig 9: Strict two phase locking
Q14) Explain Timestamp-based Protocols?
A14) The timestamp-based protocol is the most widely used concurrency protocol. As a timestamp, this protocol employs either system time or a logical counter.
At the moment of execution, lock-based protocols regulate the order between conflicting pairings among transactions, whereas timestamp-based protocols begin working as soon as a transaction is initiated.
Every transaction has a timestamp, and the order of the transactions is controlled by the transaction's age. All subsequent transactions would be older than a transaction started at 0002 clock time. For example, any transaction 'y' entering the system at 0004 is two seconds younger than the older one, and the older one will be prioritized.
In addition, the most recent read and write timestamps are assigned to each data item. This tells the system when the last ‘read and write' operation on the data item was done.
Q15) Write about the directory system?
A15) A directory is a type of container that holds folders and files. It uses a hierarchical structure to organize files and directories.
A directory can have numerous logical structures, which are listed below.
Single level directory
The simplest directory structure is a single-level directory. All files are stored in the same directory, making it simple to maintain and comprehend.
When the number of files grows or the system has more than one user, a single level directory becomes a severe constraint. Because all of the files are in the same directory, they must all be named differently. The unique name rule is broken if two users call their dataset test.
Two level directory
As we've seen, a single-level directory frequently leads to file name confusion among users. This problem can be solved by creating a different directory for each user.
Each user has their own user files directory in the two-level directory structure (UFD). The UFDs have similar architecture, but only one user's files are listed in each. When a new user id=s logs in, the system's master file directory (MFD) is searched. Each element in the MFD points to the user's UFD, which is indexed by username or account number.
Tree structured directory
The natural generalization of a two-level directory as a tree of height 2 is to extend the directory structure to a tree of any height.
This generalization enables users to construct their own subdirectories and organize their files as needed.
The most frequent directory structure is a tree structure. Every file in the system has a unique path, and the tree has a root directory.
Unit - 4
Unit - 4
Transaction Processing Concept
Q1) What is a transaction system?
A1) A transaction is a logical unit of data processing that consists of a collection of database actions. One or more database operations, such as insert, remove, update, or retrieve data, are executed in a transaction. It is an atomic process that is either completed completely or not at all. A read-only transaction is one that involves simply data retrieval and no data updating.
A transaction is a group of operations that are logically related. It consists of a number of tasks. An activity or series of acts is referred to as a transaction. It is carried out by a single user to perform operations on the database's contents.
Each high-level operation can be broken down into several lower-level jobs or operations. A data update operation, for example, can be separated into three tasks:
Read_item() - retrieves a data item from storage and stores it in the main memory.
Modify_item() - Change the item's value in the main memory.
Write_item() - write the changed value to storage from main memory
Only the read item() and write item() methods have access to the database. Similarly, read and write are the fundamental database operations for all transactions.
Q2) Explain testing of serializability?
A2) The Serialization Graph is used to determine whether or not a schedule is Serializable.
Assume you have a schedule S. We create a graph called a precedence graph for S. G = (V, E) is a pair in this graph, where V is a collection of vertices and E is a set of edges. All of the transactions in the schedule are represented by a set of vertices. All edges Ti ->Tj that satisfy one of the three conditions are included in the set of edges:
- If Ti executes write (Q) before Tj executes read(Q), create a node Ti → Tj .
- Create a node Ti → Tj if Ti executes read (Q) before Tj executes write (Q) .
- If Ti executes write (Q) before Tj executes write(Q), create a node Ti → Tj .
Q3) Explain Serializability of Schedules?
A3) If a precedence graph has only one edge Ti Tj, then all of Ti's instructions are performed before the first instruction of Tj.
Schedule S is non-serializable if its precedence graph comprises a cycle. S is serializable if the precedence graph does not have a cycle.
Example
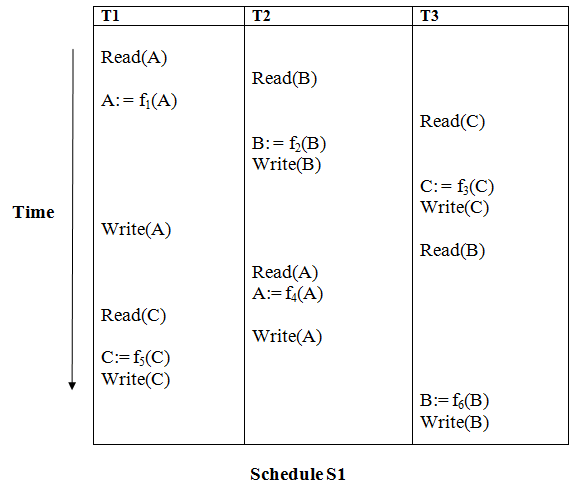
Solution:
Read (A) - There are no new edges in T1 because there are no additional writes to A.
Read (B) - There are no new edges in T2 because there are no subsequent writes to B.
Read (C) - There are no new edges in T3 since there are no additional writes to C.
Write (B) - T3 will read B after that, therefore add edge T2 → T3.
Write (C) - T1 will read C after that, therefore add edge T3 → T1.
Write (A) - T2 will read A after that, therefore add edge T1 → T2.
Write (A) - There are no new edges in T2 because there are no additional reads to A.
Write (C) - There are no new edges in T1 since there are no additional reads to C.
Write (B) - There are no additional readings to B in T3, hence there are no new edges.
Precedence graph for schedule S1:
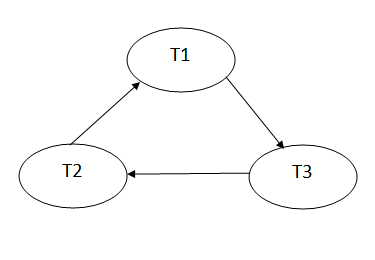
Fig 1: Precedence graph for schedule S1
Schedule S1 has a cycle in its precedence graph, which is why it is non-serializable.
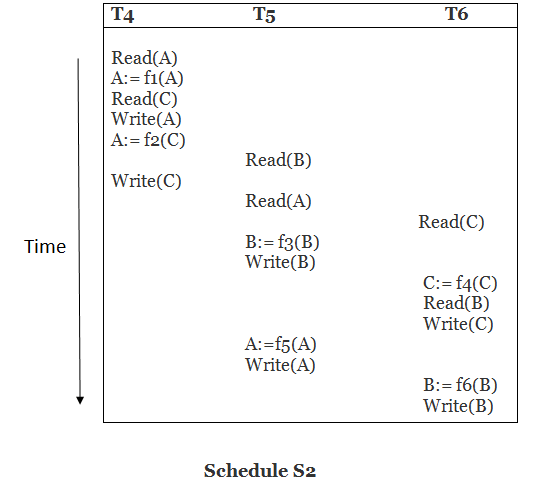
Solution:
Read (A) - There are no new edges in T4 because there are no additional writes to A.
Read (C) - There are no new edges in T4 since there are no additional writes to C.
Write (A) - T5 will read A after that, therefore add edge T4 T5.
Read (B) - There are no new edges in T5 since there are no additional writes to B.
Write (C) - T6 will read C after that, therefore add edge T4 T6.
Write (B) - T6 will read A after that, therefore add edge T5 T6.
Write (C) - There are no subsequent readings to C in T6, hence there are no new edges.
Write (A) - There are no additional reads to A in T5, hence there are no new edges.
Write (B) - There are no additional reads to B in T6, hence there are no new edges.
Precedence graph for schedule S2:
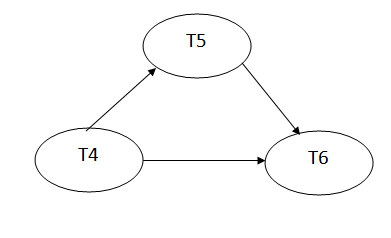
Fig 2: Precedence graph for schedule S2
The precedence graph for schedule S2 contains no cycle that's why ScheduleS2 is serializable.
Q4) Describe conflict schedule?
A4) If a schedule can turn into a serial schedule by exchanging non-conflicting procedures, it is called conflict serializability.
If the schedule is conflict equivalent to a serial schedule, it will be conflict serializable.
When two active transactions conduct non-compatible activities in a schedule with numerous transactions, a conflict develops. When all three of the following requirements exist at the same time, two operations are said to be in conflict.
● The two activities are separated by a transaction.
● Both operations refer to the same data object.
● One of the actions is a write item() operation, which attempts to modify the data item.
Example
Only if S1 and S2 are logically equivalent may they be swapped.
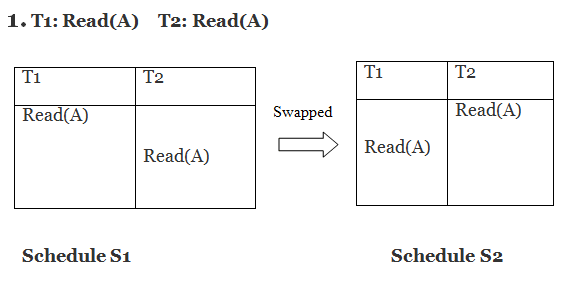
S1 = S2 in this case. This suggests there isn't any conflict.
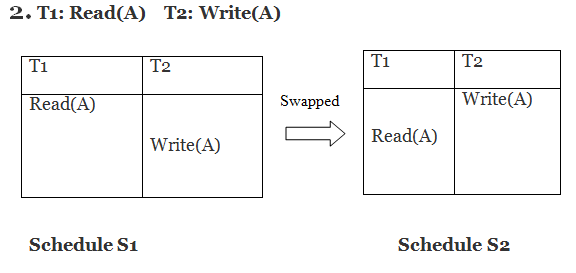
S1 ≠ S2 in this case. That suggests there's a fight going on.
Conflict Equivalent
By switching non-conflicting activities, one can be turned into another in the conflict equivalent. S2 is conflict equal to S1 in the example (S1 can be converted to S2 by swapping non-conflicting operations).
If and only if, two schedules are said to be conflict equivalent:
● They both have the identical set of transaction data.
● If each conflict operation pair is ordered the same way.
Example
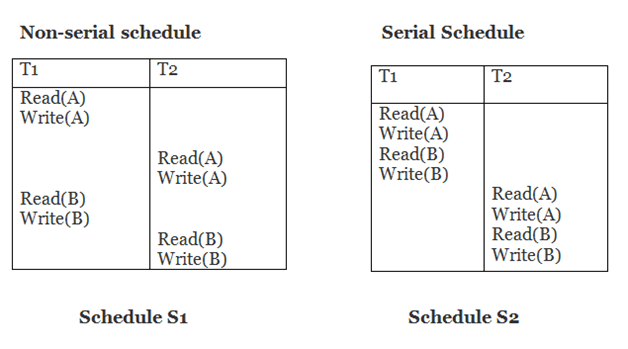
Schedule S2 is a serial schedule since it completes all T1 operations before beginning any T2 operations. By exchanging non-conflicting operations from S1, schedule S1 can be turned into a serial schedule.
The schedule S1 becomes: after exchanging non-conflict operations
T1 | T2 |
Read(A) Write(A) Read(B) Write(B) |
Read(A) Write(A) Read(B) Write(B) |
Since, S1 is conflict serializable.
Q5) Define View Serializability?
A5) If a schedule is viewed as equivalent to a serial schedule, it will be serializable.
If a schedule is view serializable, it is also conflict serializable.
Blind writes are contained in the view serializable, which does not conflict with serializable.
View Equivalent
If two schedules S1 and S2 meet the following criteria, they are said to be view equivalent:
1. Initial Read
Both schedules must be read at the same time. Assume there are two schedules, S1 and S2. If a transaction T1 in schedule S1 reads data item A, then transaction T1 in schedule S2 should likewise read A.
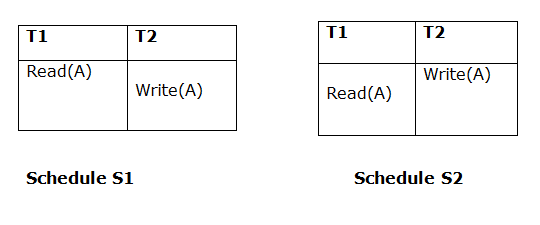
Because T1 performs the initial read operation in S1 and S2, the two schedules are considered comparable.
2. Updated Read
If Ti is reading A, which is updated by Tj in schedule S1, Ti should also read A, which is updated by Tj in schedule S2.
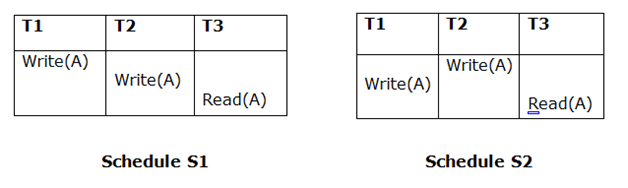
Because T3 in S1 is reading A updated by T2 and T3 in S2 is reading A updated by T1, the two schedules are not equivalent.
3. Final Write
The final writing for both schedules must be the same. If a transaction T1 updates A last in schedule S1, T1 should also perform final writes operations in schedule S2.
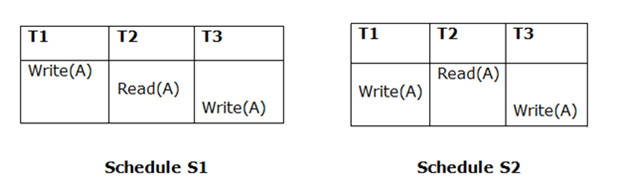
Because T3 performs the final write operation in S1 and T3 performs the final write operation in S2, the two schedules are considered equivalent.
Example

Schedule S
The total number of possible schedules grows to three with three transactions.
= 3! = 6
S1 = <T1 T2 T3>
S2 = <T1 T3 T2>
S3 = <T2 T3 T1>
S4 = <T2 T1 T3>
S5 = <T3 T1 T2>
S6 = <T3 T2 T1>
Taking first schedule S1:

Schedule S1:
Step 1 - final updation on data items
There is no read besides the initial read in both schedules S and S1, thus we don't need to check that condition.
Step 2 - Initial Read
T1 performs the initial read operation in S, and T1 also performs it in S1.
Step 3 - Final Write
T3 performs the final write operation in S, and T3 also performs it in S1. As a result, S and S1 are viewed as equivalent.
We don't need to verify another schedule because the first one, S1, meets all three criteria.
As a result, the comparable serial schedule is as follows:
T1 → T2 → T3
Q6) What is recoverability?
A6) Due to a software fault, system crash, or hardware malfunction, a transaction may not finish completely. The unsuccessful transaction must be rolled back in this scenario. However, the value generated by the unsuccessful transaction may have been utilised by another transaction. As a result, we must also rollback those transactions. Table displays a schedule with two transactions.
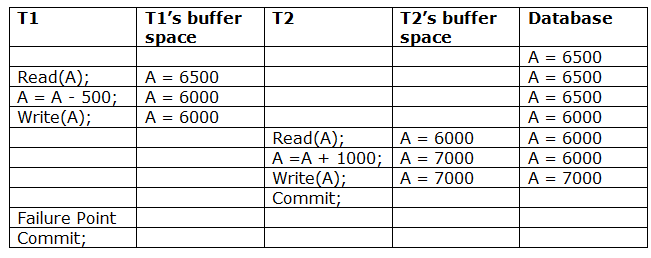
T1 reads and writes the value of A, which is read and written by T2.T2 commits, but T1 fails later. As a result of the failure, we must rollback T1.T2 should also be rolled back because it reads the value written by T1, but T2 can't because it has already committed.
Irrecoverable schedule: If Tj receives the revised value of Ti and commits before Ti commits, the schedule will be irreversible.
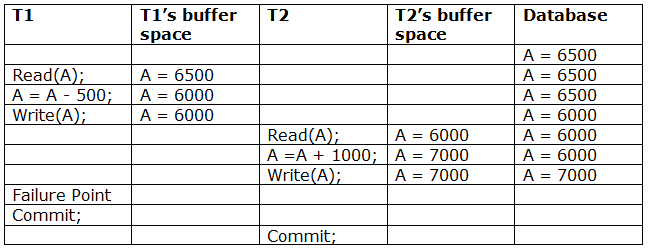
A schedule with two transactions is shown in table 2 above. Transaction T1 reads and writes A, and transaction T2 reads and writes that value. T1 eventually fails. As a result, T1 must be rolled back. Because T2 has read the value written by T1, T2 should be rolled back. We can rewind transaction T2 as well because it hasn't been committed before T1. As a result, cascade rollback can be used to recover it.
Recoverable with cascading rollback: If Tj reads the modified value of Ti, the schedule can be recovered using cascading rollback. Tj's commit is postponed till Ti's is completed.
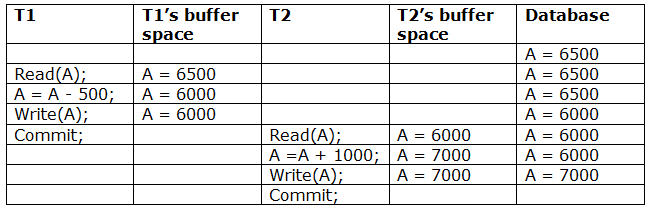
A schedule with two transactions is shown in Table 3 above. T1 commits after reading and writing A, and T2 reads and writes that value. As a result, this is a less recoverable cascade schedule.
Q7) How to recover from transaction failure?
A7) When a transaction fails to execute or reaches a point where it can't go any further, it is called a transaction failure. Transaction failure occurs when a number of transactions or processes are harmed.
Logical errors: When a transaction cannot complete owing to a coding error or an internal error situation, a logical error occurs.
Syntax error: When a database management system (DBMS) stops an active transaction because the database system is unable to perform it, this is known as a syntax error. For example, in the event of a deadlock or resource unavailability, the system aborts an active transaction.
When a system crashes, numerous transactions may be running and various files may be open, allowing them to modify data items. Transactions are made up of a variety of operations that are all atomic. However, atomicity of transactions as a whole must be preserved, which means that either all or none of the operations must be done, depending on the ACID features of DBMS.
When a database management system (DBMS) recovers after a crash -
● It should check the statuses of all the transactions that were in progress.
● A transaction may be in the middle of an operation; in this situation, the DBMS must ensure the transaction's atomicity.
● It should determine if the transaction can be completed at this time or whether it has to be turned back.
● There would be no transactions that would leave the DBMS in an inconsistent state.
Maintaining the logs of each transaction and writing them onto some stable storage before actually altering the database are two strategies that can assist a DBMS in recovering and maintaining the atomicity of a transaction.
There are two sorts of approaches that can assist a DBMS in recovering and sustaining transaction atomicity.
● Maintaining shadow paging, in which updates are made in volatile memory and the actual database is updated afterwards.
● Before actually altering the database, keep track of each transaction's logs and save them somewhere safe.
Q8) Explain log based recovery?
A8) The log is made up of a series of records. Each transaction is logged and stored in a secure location so that it may be recovered in the event of a failure.
Any operation that is performed on the database is documented in the log.
However, before the actual transaction is applied to the database, the procedure of saving the logs should be completed.
Let's pretend there's a transaction to change a student's city. This transaction generates the following logs.
● When a transaction is started, the start' log is written.
<Tn, Start>
● Another log is written to the file when the transaction changes the City from 'Noida' to 'Bangalore.'
<Tn, City, 'Noida', 'Bangalore' >
● When the transaction is completed, it writes another log to mark the transaction's completion.
<Tn, Commit>
The database can be modified in two ways:
1. Deferred database modification:
If a transaction does not affect the database until it has committed, it is said to use the postponed modification strategy. When a transaction commits, the database is updated, and all logs are created and stored in the stable storage.
2. Immediate database modification:
If a database change is made while the transaction is still running, the Immediate modification approach is used.
The database is changed immediately after each action in this method. It occurs after a database change has been made.
Recovery using Log records
When a system crashes, the system reads the log to determine which transactions must be undone and which must be redone.
● The Transaction Ti must be redone if the log contains the records <Ti, Start> and <Ti, Commit> or <Ti, Commit>.
● If the log contains the record <Tn, Start> but not the records <Ti, commit> or <Ti, abort>, then the Transaction Ti must be undone.
Q9) What are checkpoints?
A9) The checkpoint is a technique that removes all previous logs from the system and stores them permanently on the storage drive.
The checkpoint functions similarly to a bookmark. Such checkpoints are indicated during transaction execution, and the transaction is then executed utilizing the steps of the transaction, resulting in the creation of log files.
The transaction will be updated into the database when it reaches the checkpoint, and the full log file will be purged from the file until then. The log file is then updated with the new transaction step till the next checkpoint, and so on.
The checkpoint specifies a time when the DBMS was in a consistent state and all transactions had been committed.
Recovery using Checkpoint
A recovery system then restores the database from the failure in the following manner.
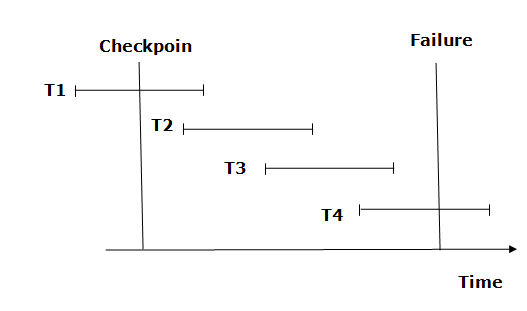
Fig 3: Checkpoint
From beginning to end, the recovery system reads log files. It reads T4 through T1 log files.
A redo-list and an undo-list are kept by the recovery system.
If the recovery system encounters a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, the transaction is put into redo state. All transactions in the redo-list and prior list are removed and then redone before the logs are saved.
Example: <Tn, Start> and <Tn, Commit> will appear in the log file for transactions T2 and T3. In the log file for the T1 transaction, there will be only <Tn, commit>. As a result, after the checkpoint is passed, the transaction is committed. As a result, T1, T2, and T3 transactions are added to the redo list.
If the recovery system finds a log containing Tn, Start> but no commit or abort log, the transaction is put into undo state. All transactions are undone and their logs are erased from the undo-list.
Example: <Tn, Start>, for example, will appear in Transaction T4. As a result, T4 will be added to the undo list because the transaction has not yet been completed and has failed in the middle.
Q10) What do you mean by deadlock handling?
A10) A deadlock occurs when two or more transactions are stuck waiting for one another to release locks indefinitely. Deadlock is regarded to be one of the most dreaded DBMS difficulties because no work is ever completed and remains in a waiting state indefinitely.
For example, transaction T1 has a lock on some entries in the student table and needs to update some rows in the grade table. At the same time, transaction T2 is holding locks on some rows in the grade table and needs to update the rows in the Student table that Transaction T1 is holding.
The primary issue now arises. T1 is currently waiting for T2 to release its lock, and T2 is currently waiting for T1 to release its lock. All actions come to a complete halt and remain in this state. It will remain at a halt until the database management system (DBMS) recognizes the deadlock and aborts one of the transactions.
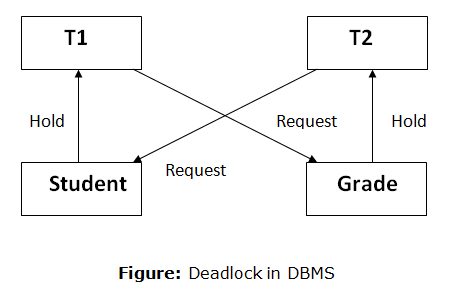
Fig 5: Deadlock
Deadlock Avoidance
When a database becomes stuck in a deadlock condition, it is preferable to avoid the database rather than abort or restate it. This is a waste of both time and money.
Any deadlock condition is detected in advance using a deadlock avoidance strategy. For detecting deadlocks, a method such as "wait for graph" is employed, although this method is only effective for smaller databases. A deadlock prevention strategy can be utilized for larger databases.
Deadlock Detection
When a transaction in a database waits endlessly for a lock, the database management system (DBMS) should determine whether the transaction is in a deadlock or not. The lock management keeps a Wait for the graph to detect the database's deadlock cycle.
Wait for Graph
This is the best way for detecting deadlock. This method generates a graph based on the transaction and its lock. There is a deadlock if the constructed graph has a cycle or closed loop.
The system maintains a wait for the graph for each transaction that is awaiting data from another transaction. If there is a cycle in the graph, the system will keep checking it.
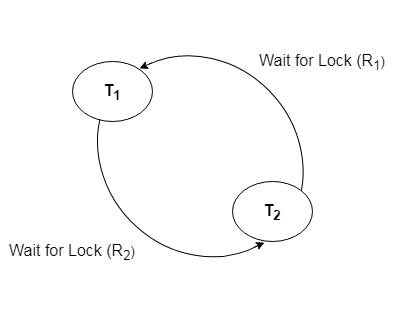
Fig 6: Wait for a graph
Deadlock Prevention
A huge database can benefit from a deadlock prevention strategy. Deadlock can be avoided if resources are distributed in such a way that deadlock never arises.
The database management system examines the transaction's operations to see if they are likely to cause a deadlock. If they do, the database management system (DBMS) never allows that transaction to be completed.
Q11) Explain distributed data storage?
A11) A distributed database is a database that is not restricted to a single system and is dispersed across numerous places, such as multiple computers or a network of computers. A distributed database system is made up of multiple sites with no physical components in common. This may be necessary if a database needs to be viewed by a large number of people all over the world. It must be administered in such a way that it appears to users as a single database.
Distributed data storage
Data can be kept on separate sites in two different ways. These are the following:
- Replication
The complete relation is stored redundantly at two or more sites in this manner. It is a fully redundant database if the entire database is available at all sites. As a result, in replication, systems keep duplicates of data.
This is useful since it increases data availability across several places. Query queries can now be executed in parallel as well.
It does, however, have some downsides. Data must be updated on a regular basis. Any modification made at one site must be recorded at every site where that relationship is saved, or else inconsistency would result. This is a significant amount of overhead. Concurrent access must now be checked across multiple sites, making concurrency control much more difficult.
2. Fragmentation
The relations are broken (i.e., divided into smaller portions) with this manner, and each of the fragments is kept in multiple locations as needed. It must be ensured that the fragments can be utilized to recreate the original relationship (i.e. that no data is lost).
Fragmentation is useful since it avoids the creation of duplicate data, and consistency is not an issue.
Relationships can be fragmented in two ways:
Horizontal fragmentation – Splitting by rows –Each tuple is assigned to at least one fragment once the relation is broken into groups of tuples.
Vertical fragmentation – Splitting by columns – The relation's schema is broken into smaller schemas. To ensure a lossless join, each fragment must have a common candidate key.
Q12) Explain concurrency control?
A12) Concurrency Control is a management process for controlling the concurrent execution of database operations.
Concurrent Execution
Multiple users can access and use the same database at the same time in a multi-user system, which is known as concurrent database execution. It means that different users on a multi-user system are running the same database at the same time.
When working on database transactions, it may be necessary to use the database by numerous users to complete separate activities, in which case concurrent database execution is performed.
The thing is, the simultaneous execution should be done in an interleaved way, with no action interfering with the other performing activities, thereby maintaining database consistency. As a result, when the transaction procedures are executed concurrently, various difficult challenges arise that must be resolved.
Concurrency Control is the working concept for controlling and managing the concurrent execution of database activities and therefore avoiding database inconsistencies. As a result, we have concurrency control techniques for preserving database concurrency.
Protocols
Concurrency control techniques ensure atomicity, consistency, isolation, durability, and serializability of database transactions while they are being executed concurrently. As a result, these protocols are classified as follows:
● Lock based protocols
● Timestamp based protocols
Q13) Describe Lock based protocols?
A13) Lock-based protocols in database systems use a method that prevents any transaction from reading or writing data until it obtains an appropriate lock on it. There are two types of locks.
Binary Locks - A data item's lock can be in one of two states: locked or unlocked.
Shared/exclusive - This sort of locking mechanism distinguishes the locks according to their intended usage. It is an exclusive lock when a lock is obtained on a data item in order to perform a write operation. Allowing many transactions to write to the same data item would cause the database to become incompatible. Because no data value is changed, read locks are shared.
There are four different types of lock procedures.
Simplistic Lock Protocol
Transactions can obtain a lock on every object before performing a 'write' operation using simple lock-based protocols. After performing the ‘write' procedure, transactions may unlock the data item.
Pre-claiming Lock Protocol
Pre-claiming protocols assess their activities and generate a list of data items for which locks are required. Before beginning an execution, the transaction requests all of the locks it will require from the system. If all of the locks are granted, the transaction runs and then releases all of the locks when it's finished. If none of the locks are granted, the transaction is aborted and the user must wait until all of the locks are granted.
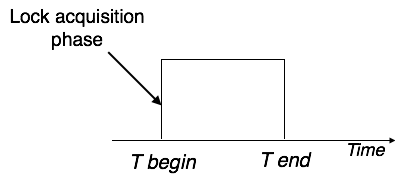
Fig 7: Pre claiming lock protocol
Two-Phase Locking 2PL
This locking protocol divides a transaction's execution phase into three segments. When the transaction first starts, it asks for permission to obtain the locks it requires. The transaction then obtains all of the locks in the second section. The third phase begins as soon as the transaction's first lock is released. The transaction can't demand any additional locks at this point; it can only release the ones it already possesses.
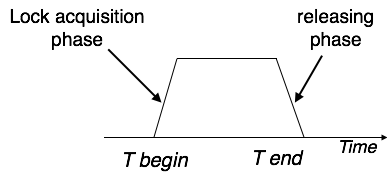
Fig 8: Two phase locking
Two-phase locking has two phases: one is growing, in which the transaction acquires all of the locks, and the other is shrinking, in which the transaction releases the locks it has gained.
A transaction must first obtain a shared (read) lock and then upgrade it to an exclusive lock in order to claim an exclusive (write) lock.
Strict Two-Phase Locking
Strict-2PL's initial phase is identical as 2PL's. The transaction continues to run normally after gaining all of the locks in the first phase. However, unlike 2PL, Strict-2PL does not release a lock after it has been used. Strict-2PL keeps all locks until the commit point, then releases them all at once.
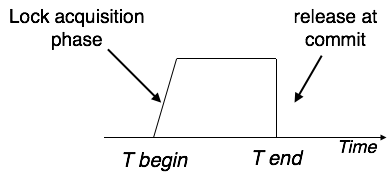
Fig 9: Strict two phase locking
Q14) Explain Timestamp-based Protocols?
A14) The timestamp-based protocol is the most widely used concurrency protocol. As a timestamp, this protocol employs either system time or a logical counter.
At the moment of execution, lock-based protocols regulate the order between conflicting pairings among transactions, whereas timestamp-based protocols begin working as soon as a transaction is initiated.
Every transaction has a timestamp, and the order of the transactions is controlled by the transaction's age. All subsequent transactions would be older than a transaction started at 0002 clock time. For example, any transaction 'y' entering the system at 0004 is two seconds younger than the older one, and the older one will be prioritized.
In addition, the most recent read and write timestamps are assigned to each data item. This tells the system when the last ‘read and write' operation on the data item was done.
Q15) Write about the directory system?
A15) A directory is a type of container that holds folders and files. It uses a hierarchical structure to organize files and directories.
A directory can have numerous logical structures, which are listed below.
Single level directory
The simplest directory structure is a single-level directory. All files are stored in the same directory, making it simple to maintain and comprehend.
When the number of files grows or the system has more than one user, a single level directory becomes a severe constraint. Because all of the files are in the same directory, they must all be named differently. The unique name rule is broken if two users call their dataset test.
Two level directory
As we've seen, a single-level directory frequently leads to file name confusion among users. This problem can be solved by creating a different directory for each user.
Each user has their own user files directory in the two-level directory structure (UFD). The UFDs have similar architecture, but only one user's files are listed in each. When a new user id=s logs in, the system's master file directory (MFD) is searched. Each element in the MFD points to the user's UFD, which is indexed by username or account number.
Tree structured directory
The natural generalization of a two-level directory as a tree of height 2 is to extend the directory structure to a tree of any height.
This generalization enables users to construct their own subdirectories and organize their files as needed.
The most frequent directory structure is a tree structure. Every file in the system has a unique path, and the tree has a root directory.
Unit - 4
Transaction Processing Concept
Q1) What is a transaction system?
A1) A transaction is a logical unit of data processing that consists of a collection of database actions. One or more database operations, such as insert, remove, update, or retrieve data, are executed in a transaction. It is an atomic process that is either completed completely or not at all. A read-only transaction is one that involves simply data retrieval and no data updating.
A transaction is a group of operations that are logically related. It consists of a number of tasks. An activity or series of acts is referred to as a transaction. It is carried out by a single user to perform operations on the database's contents.
Each high-level operation can be broken down into several lower-level jobs or operations. A data update operation, for example, can be separated into three tasks:
Read_item() - retrieves a data item from storage and stores it in the main memory.
Modify_item() - Change the item's value in the main memory.
Write_item() - write the changed value to storage from main memory
Only the read item() and write item() methods have access to the database. Similarly, read and write are the fundamental database operations for all transactions.
Q2) Explain testing of serializability?
A2) The Serialization Graph is used to determine whether or not a schedule is Serializable.
Assume you have a schedule S. We create a graph called a precedence graph for S. G = (V, E) is a pair in this graph, where V is a collection of vertices and E is a set of edges. All of the transactions in the schedule are represented by a set of vertices. All edges Ti ->Tj that satisfy one of the three conditions are included in the set of edges:
- If Ti executes write (Q) before Tj executes read(Q), create a node Ti → Tj .
- Create a node Ti → Tj if Ti executes read (Q) before Tj executes write (Q) .
- If Ti executes write (Q) before Tj executes write(Q), create a node Ti → Tj .
Q3) Explain Serializability of Schedules?
A3) If a precedence graph has only one edge Ti Tj, then all of Ti's instructions are performed before the first instruction of Tj.
Schedule S is non-serializable if its precedence graph comprises a cycle. S is serializable if the precedence graph does not have a cycle.
Example
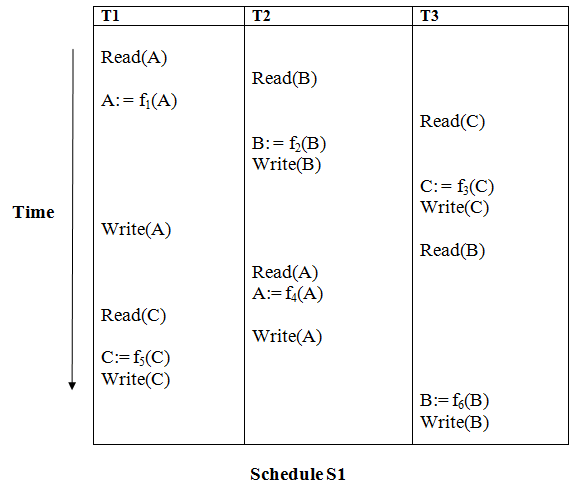
Solution:
Read (A) - There are no new edges in T1 because there are no additional writes to A.
Read (B) - There are no new edges in T2 because there are no subsequent writes to B.
Read (C) - There are no new edges in T3 since there are no additional writes to C.
Write (B) - T3 will read B after that, therefore add edge T2 → T3.
Write (C) - T1 will read C after that, therefore add edge T3 → T1.
Write (A) - T2 will read A after that, therefore add edge T1 → T2.
Write (A) - There are no new edges in T2 because there are no additional reads to A.
Write (C) - There are no new edges in T1 since there are no additional reads to C.
Write (B) - There are no additional readings to B in T3, hence there are no new edges.
Precedence graph for schedule S1:
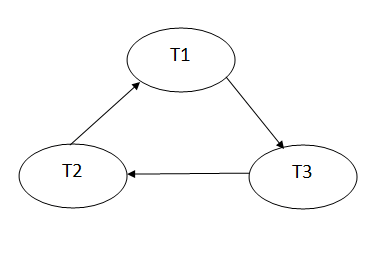
Fig 1: Precedence graph for schedule S1
Schedule S1 has a cycle in its precedence graph, which is why it is non-serializable.
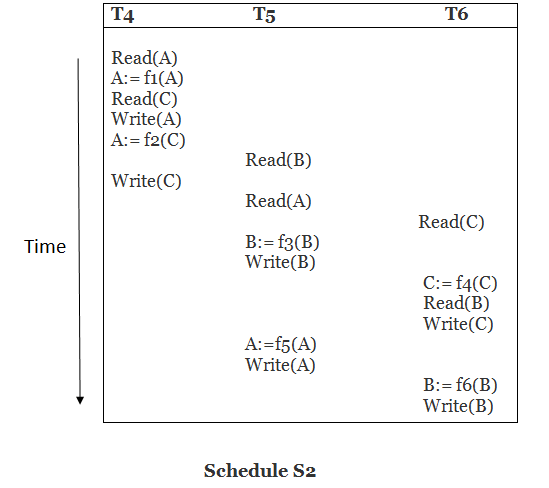
Solution:
Read (A) - There are no new edges in T4 because there are no additional writes to A.
Read (C) - There are no new edges in T4 since there are no additional writes to C.
Write (A) - T5 will read A after that, therefore add edge T4 T5.
Read (B) - There are no new edges in T5 since there are no additional writes to B.
Write (C) - T6 will read C after that, therefore add edge T4 T6.
Write (B) - T6 will read A after that, therefore add edge T5 T6.
Write (C) - There are no subsequent readings to C in T6, hence there are no new edges.
Write (A) - There are no additional reads to A in T5, hence there are no new edges.
Write (B) - There are no additional reads to B in T6, hence there are no new edges.
Precedence graph for schedule S2:
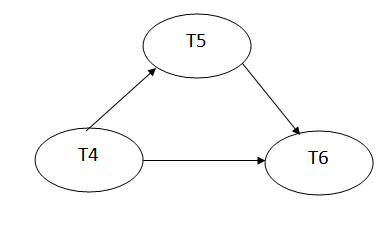
Fig 2: Precedence graph for schedule S2
The precedence graph for schedule S2 contains no cycle that's why ScheduleS2 is serializable.
Q4) Describe conflict schedule?
A4) If a schedule can turn into a serial schedule by exchanging non-conflicting procedures, it is called conflict serializability.
If the schedule is conflict equivalent to a serial schedule, it will be conflict serializable.
When two active transactions conduct non-compatible activities in a schedule with numerous transactions, a conflict develops. When all three of the following requirements exist at the same time, two operations are said to be in conflict.
● The two activities are separated by a transaction.
● Both operations refer to the same data object.
● One of the actions is a write item() operation, which attempts to modify the data item.
Example
Only if S1 and S2 are logically equivalent may they be swapped.
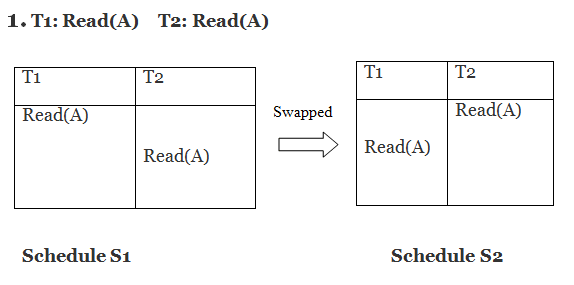
S1 = S2 in this case. This suggests there isn't any conflict.
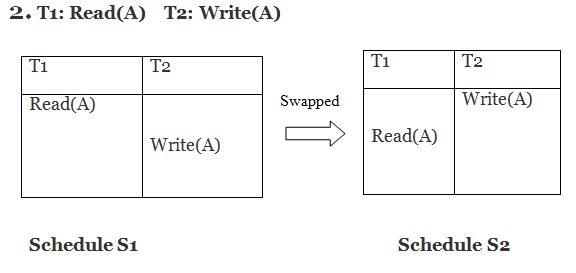
S1 ≠ S2 in this case. That suggests there's a fight going on.
Conflict Equivalent
By switching non-conflicting activities, one can be turned into another in the conflict equivalent. S2 is conflict equal to S1 in the example (S1 can be converted to S2 by swapping non-conflicting operations).
If and only if, two schedules are said to be conflict equivalent:
● They both have the identical set of transaction data.
● If each conflict operation pair is ordered the same way.
Example
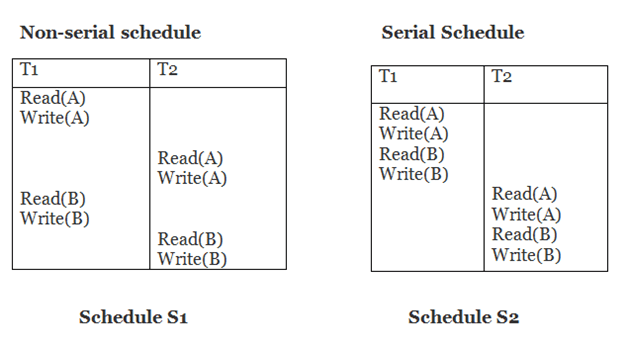
Schedule S2 is a serial schedule since it completes all T1 operations before beginning any T2 operations. By exchanging non-conflicting operations from S1, schedule S1 can be turned into a serial schedule.
The schedule S1 becomes: after exchanging non-conflict operations
T1 | T2 |
Read(A) Write(A) Read(B) Write(B) |
Read(A) Write(A) Read(B) Write(B) |
Since, S1 is conflict serializable.
Q5) Define View Serializability?
A5) If a schedule is viewed as equivalent to a serial schedule, it will be serializable.
If a schedule is view serializable, it is also conflict serializable.
Blind writes are contained in the view serializable, which does not conflict with serializable.
View Equivalent
If two schedules S1 and S2 meet the following criteria, they are said to be view equivalent:
1. Initial Read
Both schedules must be read at the same time. Assume there are two schedules, S1 and S2. If a transaction T1 in schedule S1 reads data item A, then transaction T1 in schedule S2 should likewise read A.
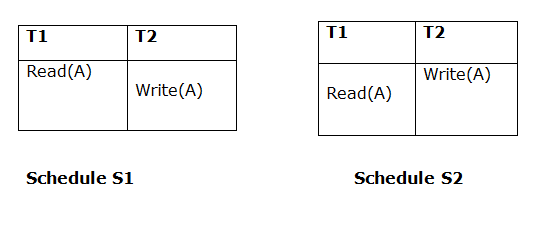
Because T1 performs the initial read operation in S1 and S2, the two schedules are considered comparable.
2. Updated Read
If Ti is reading A, which is updated by Tj in schedule S1, Ti should also read A, which is updated by Tj in schedule S2.
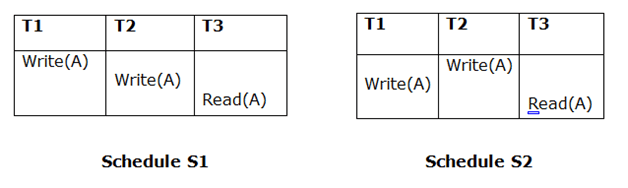
Because T3 in S1 is reading A updated by T2 and T3 in S2 is reading A updated by T1, the two schedules are not equivalent.
3. Final Write
The final writing for both schedules must be the same. If a transaction T1 updates A last in schedule S1, T1 should also perform final writes operations in schedule S2.
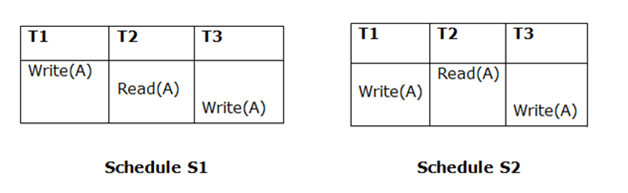
Because T3 performs the final write operation in S1 and T3 performs the final write operation in S2, the two schedules are considered equivalent.
Example

Schedule S
The total number of possible schedules grows to three with three transactions.
= 3! = 6
S1 = <T1 T2 T3>
S2 = <T1 T3 T2>
S3 = <T2 T3 T1>
S4 = <T2 T1 T3>
S5 = <T3 T1 T2>
S6 = <T3 T2 T1>
Taking first schedule S1:

Schedule S1:
Step 1 - final updation on data items
There is no read besides the initial read in both schedules S and S1, thus we don't need to check that condition.
Step 2 - Initial Read
T1 performs the initial read operation in S, and T1 also performs it in S1.
Step 3 - Final Write
T3 performs the final write operation in S, and T3 also performs it in S1. As a result, S and S1 are viewed as equivalent.
We don't need to verify another schedule because the first one, S1, meets all three criteria.
As a result, the comparable serial schedule is as follows:
T1 → T2 → T3
Q6) What is recoverability?
A6) Due to a software fault, system crash, or hardware malfunction, a transaction may not finish completely. The unsuccessful transaction must be rolled back in this scenario. However, the value generated by the unsuccessful transaction may have been utilised by another transaction. As a result, we must also rollback those transactions. Table displays a schedule with two transactions.
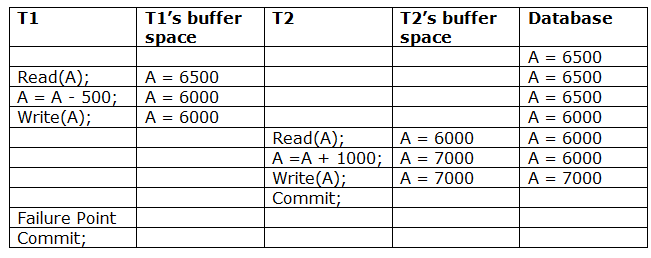
T1 reads and writes the value of A, which is read and written by T2.T2 commits, but T1 fails later. As a result of the failure, we must rollback T1.T2 should also be rolled back because it reads the value written by T1, but T2 can't because it has already committed.
Irrecoverable schedule: If Tj receives the revised value of Ti and commits before Ti commits, the schedule will be irreversible.
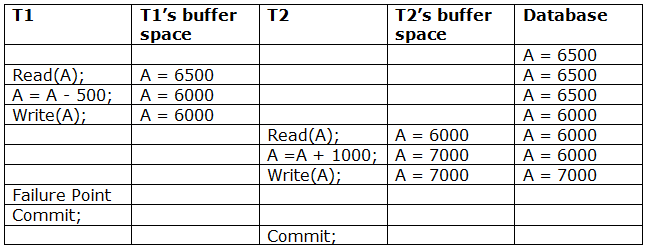
A schedule with two transactions is shown in table 2 above. Transaction T1 reads and writes A, and transaction T2 reads and writes that value. T1 eventually fails. As a result, T1 must be rolled back. Because T2 has read the value written by T1, T2 should be rolled back. We can rewind transaction T2 as well because it hasn't been committed before T1. As a result, cascade rollback can be used to recover it.
Recoverable with cascading rollback: If Tj reads the modified value of Ti, the schedule can be recovered using cascading rollback. Tj's commit is postponed till Ti's is completed.
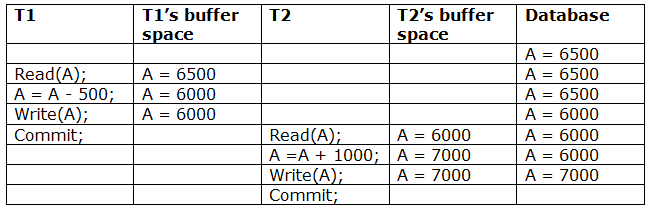
A schedule with two transactions is shown in Table 3 above. T1 commits after reading and writing A, and T2 reads and writes that value. As a result, this is a less recoverable cascade schedule.
Q7) How to recover from transaction failure?
A7) When a transaction fails to execute or reaches a point where it can't go any further, it is called a transaction failure. Transaction failure occurs when a number of transactions or processes are harmed.
Logical errors: When a transaction cannot complete owing to a coding error or an internal error situation, a logical error occurs.
Syntax error: When a database management system (DBMS) stops an active transaction because the database system is unable to perform it, this is known as a syntax error. For example, in the event of a deadlock or resource unavailability, the system aborts an active transaction.
When a system crashes, numerous transactions may be running and various files may be open, allowing them to modify data items. Transactions are made up of a variety of operations that are all atomic. However, atomicity of transactions as a whole must be preserved, which means that either all or none of the operations must be done, depending on the ACID features of DBMS.
When a database management system (DBMS) recovers after a crash -
● It should check the statuses of all the transactions that were in progress.
● A transaction may be in the middle of an operation; in this situation, the DBMS must ensure the transaction's atomicity.
● It should determine if the transaction can be completed at this time or whether it has to be turned back.
● There would be no transactions that would leave the DBMS in an inconsistent state.
Maintaining the logs of each transaction and writing them onto some stable storage before actually altering the database are two strategies that can assist a DBMS in recovering and maintaining the atomicity of a transaction.
There are two sorts of approaches that can assist a DBMS in recovering and sustaining transaction atomicity.
● Maintaining shadow paging, in which updates are made in volatile memory and the actual database is updated afterwards.
● Before actually altering the database, keep track of each transaction's logs and save them somewhere safe.
Q8) Explain log based recovery?
A8) The log is made up of a series of records. Each transaction is logged and stored in a secure location so that it may be recovered in the event of a failure.
Any operation that is performed on the database is documented in the log.
However, before the actual transaction is applied to the database, the procedure of saving the logs should be completed.
Let's pretend there's a transaction to change a student's city. This transaction generates the following logs.
● When a transaction is started, the start' log is written.
<Tn, Start>
● Another log is written to the file when the transaction changes the City from 'Noida' to 'Bangalore.'
<Tn, City, 'Noida', 'Bangalore' >
● When the transaction is completed, it writes another log to mark the transaction's completion.
<Tn, Commit>
The database can be modified in two ways:
1. Deferred database modification:
If a transaction does not affect the database until it has committed, it is said to use the postponed modification strategy. When a transaction commits, the database is updated, and all logs are created and stored in the stable storage.
2. Immediate database modification:
If a database change is made while the transaction is still running, the Immediate modification approach is used.
The database is changed immediately after each action in this method. It occurs after a database change has been made.
Recovery using Log records
When a system crashes, the system reads the log to determine which transactions must be undone and which must be redone.
● The Transaction Ti must be redone if the log contains the records <Ti, Start> and <Ti, Commit> or <Ti, Commit>.
● If the log contains the record <Tn, Start> but not the records <Ti, commit> or <Ti, abort>, then the Transaction Ti must be undone.
Q9) What are checkpoints?
A9) The checkpoint is a technique that removes all previous logs from the system and stores them permanently on the storage drive.
The checkpoint functions similarly to a bookmark. Such checkpoints are indicated during transaction execution, and the transaction is then executed utilizing the steps of the transaction, resulting in the creation of log files.
The transaction will be updated into the database when it reaches the checkpoint, and the full log file will be purged from the file until then. The log file is then updated with the new transaction step till the next checkpoint, and so on.
The checkpoint specifies a time when the DBMS was in a consistent state and all transactions had been committed.
Recovery using Checkpoint
A recovery system then restores the database from the failure in the following manner.
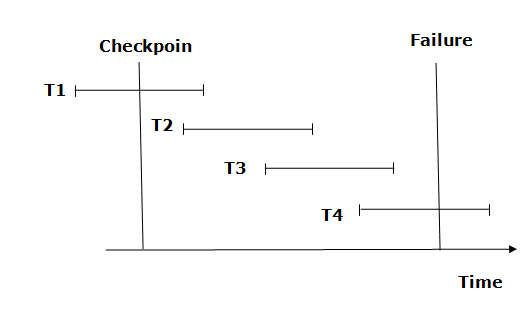
Fig 3: Checkpoint
From beginning to end, the recovery system reads log files. It reads T4 through T1 log files.
A redo-list and an undo-list are kept by the recovery system.
If the recovery system encounters a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, the transaction is put into redo state. All transactions in the redo-list and prior list are removed and then redone before the logs are saved.
Example: <Tn, Start> and <Tn, Commit> will appear in the log file for transactions T2 and T3. In the log file for the T1 transaction, there will be only <Tn, commit>. As a result, after the checkpoint is passed, the transaction is committed. As a result, T1, T2, and T3 transactions are added to the redo list.
If the recovery system finds a log containing Tn, Start> but no commit or abort log, the transaction is put into undo state. All transactions are undone and their logs are erased from the undo-list.
Example: <Tn, Start>, for example, will appear in Transaction T4. As a result, T4 will be added to the undo list because the transaction has not yet been completed and has failed in the middle.
Q10) What do you mean by deadlock handling?
A10) A deadlock occurs when two or more transactions are stuck waiting for one another to release locks indefinitely. Deadlock is regarded to be one of the most dreaded DBMS difficulties because no work is ever completed and remains in a waiting state indefinitely.
For example, transaction T1 has a lock on some entries in the student table and needs to update some rows in the grade table. At the same time, transaction T2 is holding locks on some rows in the grade table and needs to update the rows in the Student table that Transaction T1 is holding.
The primary issue now arises. T1 is currently waiting for T2 to release its lock, and T2 is currently waiting for T1 to release its lock. All actions come to a complete halt and remain in this state. It will remain at a halt until the database management system (DBMS) recognizes the deadlock and aborts one of the transactions.
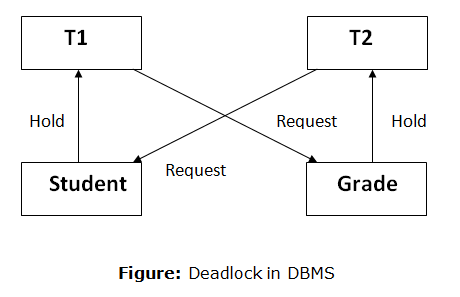
Fig 5: Deadlock
Deadlock Avoidance
When a database becomes stuck in a deadlock condition, it is preferable to avoid the database rather than abort or restate it. This is a waste of both time and money.
Any deadlock condition is detected in advance using a deadlock avoidance strategy. For detecting deadlocks, a method such as "wait for graph" is employed, although this method is only effective for smaller databases. A deadlock prevention strategy can be utilized for larger databases.
Deadlock Detection
When a transaction in a database waits endlessly for a lock, the database management system (DBMS) should determine whether the transaction is in a deadlock or not. The lock management keeps a Wait for the graph to detect the database's deadlock cycle.
Wait for Graph
This is the best way for detecting deadlock. This method generates a graph based on the transaction and its lock. There is a deadlock if the constructed graph has a cycle or closed loop.
The system maintains a wait for the graph for each transaction that is awaiting data from another transaction. If there is a cycle in the graph, the system will keep checking it.
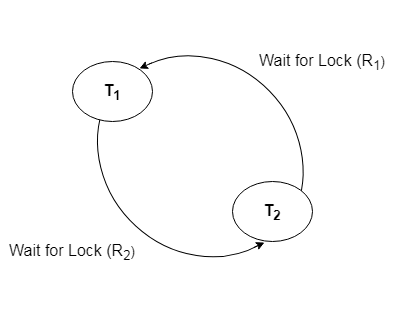
Fig 6: Wait for a graph
Deadlock Prevention
A huge database can benefit from a deadlock prevention strategy. Deadlock can be avoided if resources are distributed in such a way that deadlock never arises.
The database management system examines the transaction's operations to see if they are likely to cause a deadlock. If they do, the database management system (DBMS) never allows that transaction to be completed.
Q11) Explain distributed data storage?
A11) A distributed database is a database that is not restricted to a single system and is dispersed across numerous places, such as multiple computers or a network of computers. A distributed database system is made up of multiple sites with no physical components in common. This may be necessary if a database needs to be viewed by a large number of people all over the world. It must be administered in such a way that it appears to users as a single database.
Distributed data storage
Data can be kept on separate sites in two different ways. These are the following:
- Replication
The complete relation is stored redundantly at two or more sites in this manner. It is a fully redundant database if the entire database is available at all sites. As a result, in replication, systems keep duplicates of data.
This is useful since it increases data availability across several places. Query queries can now be executed in parallel as well.
It does, however, have some downsides. Data must be updated on a regular basis. Any modification made at one site must be recorded at every site where that relationship is saved, or else inconsistency would result. This is a significant amount of overhead. Concurrent access must now be checked across multiple sites, making concurrency control much more difficult.
2. Fragmentation
The relations are broken (i.e., divided into smaller portions) with this manner, and each of the fragments is kept in multiple locations as needed. It must be ensured that the fragments can be utilized to recreate the original relationship (i.e. that no data is lost).
Fragmentation is useful since it avoids the creation of duplicate data, and consistency is not an issue.
Relationships can be fragmented in two ways:
Horizontal fragmentation – Splitting by rows –Each tuple is assigned to at least one fragment once the relation is broken into groups of tuples.
Vertical fragmentation – Splitting by columns – The relation's schema is broken into smaller schemas. To ensure a lossless join, each fragment must have a common candidate key.
Q12) Explain concurrency control?
A12) Concurrency Control is a management process for controlling the concurrent execution of database operations.
Concurrent Execution
Multiple users can access and use the same database at the same time in a multi-user system, which is known as concurrent database execution. It means that different users on a multi-user system are running the same database at the same time.
When working on database transactions, it may be necessary to use the database by numerous users to complete separate activities, in which case concurrent database execution is performed.
The thing is, the simultaneous execution should be done in an interleaved way, with no action interfering with the other performing activities, thereby maintaining database consistency. As a result, when the transaction procedures are executed concurrently, various difficult challenges arise that must be resolved.
Concurrency Control is the working concept for controlling and managing the concurrent execution of database activities and therefore avoiding database inconsistencies. As a result, we have concurrency control techniques for preserving database concurrency.
Protocols
Concurrency control techniques ensure atomicity, consistency, isolation, durability, and serializability of database transactions while they are being executed concurrently. As a result, these protocols are classified as follows:
● Lock based protocols
● Timestamp based protocols
Q13) Describe Lock based protocols?
A13) Lock-based protocols in database systems use a method that prevents any transaction from reading or writing data until it obtains an appropriate lock on it. There are two types of locks.
Binary Locks - A data item's lock can be in one of two states: locked or unlocked.
Shared/exclusive - This sort of locking mechanism distinguishes the locks according to their intended usage. It is an exclusive lock when a lock is obtained on a data item in order to perform a write operation. Allowing many transactions to write to the same data item would cause the database to become incompatible. Because no data value is changed, read locks are shared.
There are four different types of lock procedures.
Simplistic Lock Protocol
Transactions can obtain a lock on every object before performing a 'write' operation using simple lock-based protocols. After performing the ‘write' procedure, transactions may unlock the data item.
Pre-claiming Lock Protocol
Pre-claiming protocols assess their activities and generate a list of data items for which locks are required. Before beginning an execution, the transaction requests all of the locks it will require from the system. If all of the locks are granted, the transaction runs and then releases all of the locks when it's finished. If none of the locks are granted, the transaction is aborted and the user must wait until all of the locks are granted.
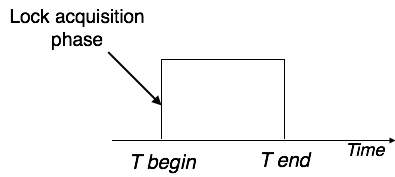
Fig 7: Pre claiming lock protocol
Two-Phase Locking 2PL
This locking protocol divides a transaction's execution phase into three segments. When the transaction first starts, it asks for permission to obtain the locks it requires. The transaction then obtains all of the locks in the second section. The third phase begins as soon as the transaction's first lock is released. The transaction can't demand any additional locks at this point; it can only release the ones it already possesses.
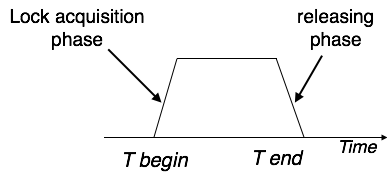
Fig 8: Two phase locking
Two-phase locking has two phases: one is growing, in which the transaction acquires all of the locks, and the other is shrinking, in which the transaction releases the locks it has gained.
A transaction must first obtain a shared (read) lock and then upgrade it to an exclusive lock in order to claim an exclusive (write) lock.
Strict Two-Phase Locking
Strict-2PL's initial phase is identical as 2PL's. The transaction continues to run normally after gaining all of the locks in the first phase. However, unlike 2PL, Strict-2PL does not release a lock after it has been used. Strict-2PL keeps all locks until the commit point, then releases them all at once.
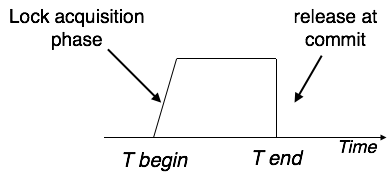
Fig 9: Strict two phase locking
Q14) Explain Timestamp-based Protocols?
A14) The timestamp-based protocol is the most widely used concurrency protocol. As a timestamp, this protocol employs either system time or a logical counter.
At the moment of execution, lock-based protocols regulate the order between conflicting pairings among transactions, whereas timestamp-based protocols begin working as soon as a transaction is initiated.
Every transaction has a timestamp, and the order of the transactions is controlled by the transaction's age. All subsequent transactions would be older than a transaction started at 0002 clock time. For example, any transaction 'y' entering the system at 0004 is two seconds younger than the older one, and the older one will be prioritized.
In addition, the most recent read and write timestamps are assigned to each data item. This tells the system when the last ‘read and write' operation on the data item was done.
Q15) Write about the directory system?
A15) A directory is a type of container that holds folders and files. It uses a hierarchical structure to organize files and directories.
A directory can have numerous logical structures, which are listed below.
Single level directory
The simplest directory structure is a single-level directory. All files are stored in the same directory, making it simple to maintain and comprehend.
When the number of files grows or the system has more than one user, a single level directory becomes a severe constraint. Because all of the files are in the same directory, they must all be named differently. The unique name rule is broken if two users call their dataset test.
Two level directory
As we've seen, a single-level directory frequently leads to file name confusion among users. This problem can be solved by creating a different directory for each user.
Each user has their own user files directory in the two-level directory structure (UFD). The UFDs have similar architecture, but only one user's files are listed in each. When a new user id=s logs in, the system's master file directory (MFD) is searched. Each element in the MFD points to the user's UFD, which is indexed by username or account number.
Tree structured directory
The natural generalization of a two-level directory as a tree of height 2 is to extend the directory structure to a tree of any height.
This generalization enables users to construct their own subdirectories and organize their files as needed.
The most frequent directory structure is a tree structure. Every file in the system has a unique path, and the tree has a root directory.




