Unit - 2
Process Management
Q1) Define process?
A1) A process is basically a program in execution. The execution of a process must progress in a sequential fashion.
A process is defined as an entity which represents the basic unit of work to be implemented in the system.
To put it in simple terms, we write our computer programs in a text file and when we execute this program, it becomes a process which performs all the tasks mentioned in the program.
When a program is loaded into the memory and it becomes a process, it can be divided into four sections ─ stack, heap, text and data. The following image shows a simplified layout of a process inside main memory −
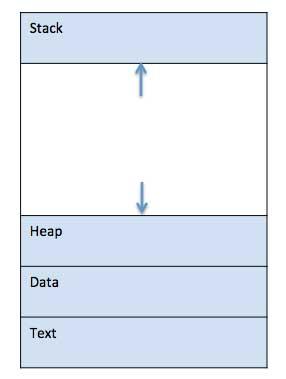
Fig 1: A simplified layout of a process inside main memory
S.N. | Component & Description |
1 | Stack The process Stack contains the temporary data such as method/function parameters, return address and local variables. |
2 | Heap This is dynamically allocated memory to a process during its run time. |
3 | Text This includes the current activity represented by the value of Program Counter and the contents of the processor's registers. |
4 | Data This section contains the global and static variables. |
Q2) Write a small program for the process?
A2) Program
A program is a piece of code which may be a single line or millions of lines. A computer program is usually written by a computer programmer in a programming language. For example, here is a simple program written in C programming language-
#include <stdio.h>
Int main() {
Printf("Hello, World! \n");
Return 0;
}
A computer program is a collection of instructions that performs a specific task when executed by a computer. When we compare a program with a process, we can conclude that a process is a dynamic instance of a computer program.
A part of a computer program that performs a well-defined task is known as an algorithm. A collection of computer programs, libraries and related data are referred to as a software.
Q3) Explain process life cycle?
A3) Process Life Cycle
When a process executes, it passes through different states. These stages may differ in different operating systems, and the names of these states are also not standardized.
In general, a process can have one of the following five states at a time.
S.N. | State & Description |
1 | Start This is the initial state when a process is first started/created. |
2 | Ready The process is waiting to be assigned to a processor. Ready processes are waiting to have the processor allocated to them by the operating system so that they can run. Process may come into this state after Start state or while running it by but interrupted by the scheduler to assign CPU to some other process. |
3 | Running Once the process has been assigned to a processor by the OS scheduler, the process state is set to running and the processor executes its instructions. |
4 | Waiting Process moves into the waiting state if it needs to wait for a resource, such as waiting for user input, or waiting for a file to become available. |
5 | Terminated or Exit Once the process finishes its execution, or it is terminated by the operating system, it is moved to the terminated state where it waits to be removed from main memory. |
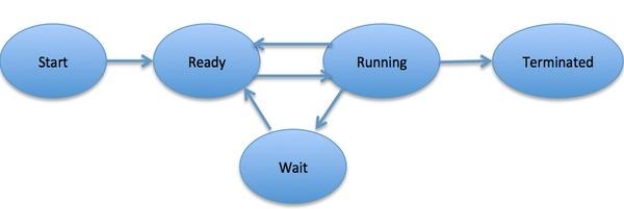
Fig 2: Process state
Q4) Describe the process state?
A4) Process state
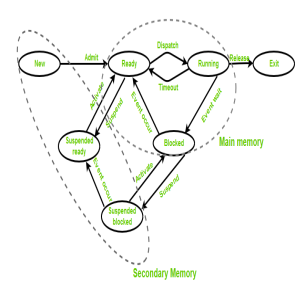
Fig 3: States of a process
● New (Create) – during this step, the method is close to be created however not nevertheless created, it's the program that is gift in secondary memory which will be picked up by OS to make the method.
● Ready – New -> able to run. When the creation of a method, the method enters the prepared state i.e. the method is loaded into the most memory. The method here is prepared to run and is waiting to urge the central processor time for its execution. Processes that ar prepared for execution by the central processor ar maintained during a queue for prepared processes.
● Run – the method is chosen by central processor for execution and therefore the directions among the method ar dead by anyone of the on the market central processor cores.
● Blocked or wait – Whenever the method requests access to I/O or desires input from the user or desires access to a crucial region(the lock that is already acquired) it enters the blocked or wait state. The method continues to attend within the main memory and doesn't need central processor. Once the I/O operation is completed the method goes to the prepared state.
● Terminated or completed – method is killed also as PCB is deleted.
● Suspend prepared – method that was ab initio within the prepared state however were swapped out of main memory (refer storage topic) and placed onto auxiliary storage by hardware are aforesaid to be in suspend prepared state. The method can transition back to prepared state whenever the method is once more brought onto the most memory.
● Suspend wait or suspend blocked – kind of like suspend prepared however uses the method that was playing I/O operation and lack of main memory caused them to maneuver to secondary memory.
Q5) Explain process control block (PCB)?
A5) A Process Control Block is a data structure maintained by the Operating System for every process. The PCB is identified by an integer process ID (PID). A PCB keeps all the information needed to keep track of a process as listed below in the table −
S.N. | Information & Description |
1 | Process State The current state of the process i.e., whether it is ready, running, waiting, or whatever. |
2 | Process privileges This is required to allow/disallow access to system resources. |
3 | Process ID Unique identification for each of the process in the operating system. |
4 | Pointer A pointer to parent process. |
5 | Program Counter Program Counter is a pointer to the address of the next instruction to be executed for this process. |
6 | CPU registers Various CPU registers where process need to be stored for execution for running state. |
7 | CPU Scheduling Information Process priority and other scheduling information which is required to schedule the process. |
8 | Memory management information This includes the information of page table, memory limits, Segment table depending on memory used by the operating system. |
9 | Accounting information This includes the amount of CPU used for process execution, time limits, execution ID etc. |
10 | IO status information This includes a list of I/O devices allocated to the process. |
The architecture of a PCB is completely dependent on Operating System and may contain different information in different operating systems. Here is a simplified diagram of a PCB −

Fig 4: PCB
Q6) What is scheduling queue?
A6) All PCBs are kept in Process Scheduling Queues by the OS. Each process state has its own queue in the OS, and PCBs from all processes in the same execution state are placed in the same queue. A process's PCB is unlinked from its current queue and moved to its new state queue when its status is changed.
The following major process scheduling queues are maintained by the Operating System:
● Job queue − The job queue is where all of the system's processes are kept.
● Ready queue − This queue holds a list of all processes in main memory that are ready and waiting to be executed. This queue is always filled with new processes.
● Device queues − Device queues are a collection of processes that are stalled owing to the lack of an I/O device.
To handle each queue, the OS might employ a variety of policies (FIFO, Round Robin, Priority, etc.). The OS scheduler governs how processes are moved between the ready and run queues, each of which can only have one item per processor core on the system.
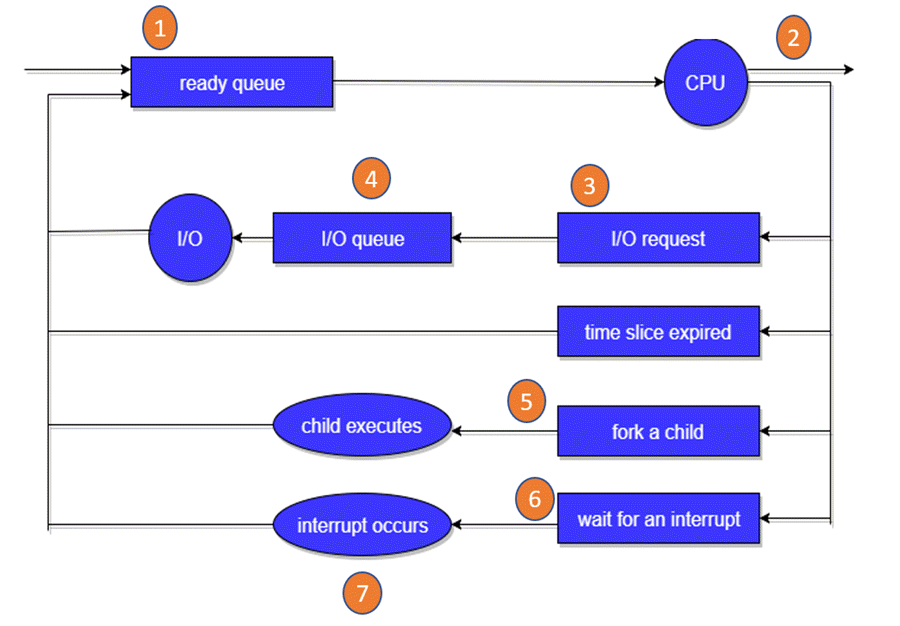
Fig 5: Scheduling queue
In the diagram shown above,
● Rectangle represents a queue.
● Circle denotes the resource
● Arrow indicates the flow of the process.
- Each new process is placed in the Ready queue first. It sits in the ready queue, waiting to be processed for execution. The new process is added to the ready queue and placed there until it is either selected for execution or despatched.
- One of the processes has been given the CPU and is now running.
- An I/O request should be issued by the process.
- It should then be added to the I/O queue.
- A new subprocess should be created by the process.
- The procedure should be inactive until it is finished.
- As a result of the interrupt, it should violently remove itself off the CPU. When the interrupt is finished, it should be returned to the ready queue.
Q7) Write about process scheduling?
A7) The process scheduling is the activity of the process manager that handles the removal of the running process from the CPU and the selection of another process on the basis of a particular strategy.
Process scheduling is an essential part of a Multiprogramming operating systems. Such operating systems allow more than one process to be loaded into the executable memory at a time and the loaded process shares the CPU using time multiplexing.
Process Scheduling Queues
The OS maintains all PCBs in Process Scheduling Queues. The OS maintains a separate queue for each of the process states and PCBs of all processes in the same execution state are placed in the same queue. When the state of a process is changed, its PCB is unlinked from its current queue and moved to its new state queue.
The Operating System maintains the following important process scheduling queues−
● Job queue − This queue keeps all the processes in the system.
● Ready queue − This queue keeps a set of all processes residing in main memory, ready and waiting to execute. A new process is always put in this queue.
● Device queues − The processes which are blocked due to unavailability of an I/O device constitute this queue.
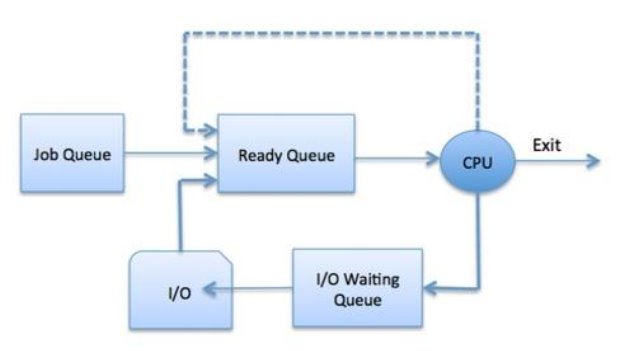
Fig 6: Process state
The OS can use different policies to manage each queue (FIFO, Round Robin, Priority, etc.). The OS scheduler determines how to move processes between the ready and run queues which can only have one entry per processor core on the system; in the above diagram, it has been merged with the CPU.
Q8) What is a two state process model?
A8) Two-State Process Model
Two-state process model refers to running and non-running states which are described below −
S.N. | State & Description |
1 | Running When a new process is created, it enters into the system as in the running state. |
2 | Not Running Processes that are not running are kept in queue, waiting for their turn to execute. Each entry in the queue is a pointer to a particular process. Queue is implemented by using linked list. Use of dispatcher is as follows. When a process is interrupted, that process is transferred in the waiting queue. If the process has completed or aborted, the process is discarded. In either case, the dispatcher then selects a process from the queue to execute. |
Q9) Describe scheduler?
A9) Schedulers
Schedulers are special system software which handle process scheduling in various ways. Their main task is to select the jobs to be submitted into the system and to decide which process to run. Schedulers are of three types −
● Long-Term Scheduler
● Short-Term Scheduler
● Medium-Term Scheduler
Long Term Scheduler
It is also called a job scheduler. A long-term scheduler determines which programs are admitted to the system for processing. It selects processes from the queue and loads them into memory for execution. Process loads into the memory for CPU scheduling.
The primary objective of the job scheduler is to provide a balanced mix of jobs, such as I/O bound and processor bound. It also controls the degree of multiprogramming. If the degree of multiprogramming is stable, then the average rate of process creation must be equal to the average departure rate of processes leaving the system.
On some systems, the long-term scheduler may not be available or minimal. Time-sharing operating systems have no long-term scheduler. When a process changes the state from new to ready, then there is use of long-term scheduler.
Short Term Scheduler
It is also called as CPU scheduler. Its main objective is to increase system performance in accordance with the chosen set of criteria. It is the change of ready state to running state of the process. CPU scheduler selects a process among the processes that are ready to execute and allocates CPU to one of them.
Short-term schedulers, also known as dispatchers, make the decision of which process to execute next. Short-term schedulers are faster than long-term schedulers.
Medium Term Scheduler
Medium-term scheduling is a part of swapping. It removes the processes from the memory. It reduces the degree of multiprogramming. The medium-term scheduler is in-charge of handling the swapped out-processes.
A running process may become suspended if it makes an I/O request. A suspended process cannot make any progress towards completion. In this condition, to remove the process from memory and make space for other processes, the suspended process is moved to the secondary storage. This process is called swapping, and the process is said to be swapped out or rolled out. Swapping may be necessary to improve the process mix.
Q10) Compare different types of scheduler?
A10) Comparison among Scheduler
S.N. | Long-Term Scheduler | Short-Term Scheduler | Medium-Term Scheduler |
1 | It is a job scheduler | It is a CPU scheduler | It is a process swapping scheduler. |
2 | Speed is lesser than short term scheduler | Speed is fastest among other two | Speed is in between both short- and long-term scheduler. |
3 | It controls the degree of multiprogramming | It provides lesser control over degree of multiprogramming | It reduces the degree of multiprogramming. |
4 | It is almost absent or minimal in time sharing system | It is also minimal in time sharing system | It is a part of Time-sharing systems. |
5 | It selects processes from pool and loads them into memory for execution | It selects those processes which are ready to execute | It can re-introduce the process into memory and execution can be continued. |
Q11) Explain context switch?
A11) Context Switch
A context switch is the mechanism to store and restore the state or context of a CPU in Process Control block so that a process execution can be resumed from the same point at a later time. Using this technique, a context switcher enables multiple processes to share a single CPU. Context switching is an essential part of a multitasking operating system features.
When the scheduler switches the CPU from executing one process to execute another, the state from the current running process is stored into the process control block. After this, the state for the process to run next is loaded from its own PCB and used to set the PC, registers, etc. At that point, the second process can start executing.
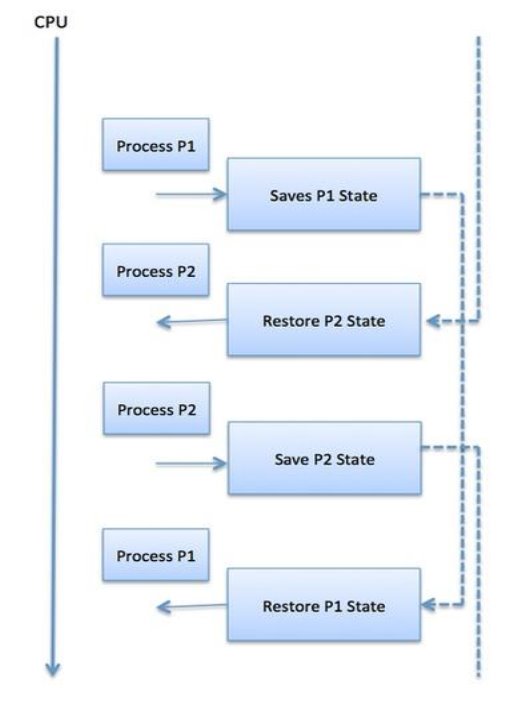
Fig 7: Process state
Context switches are computationally intensive since register and memory state must be saved and restored. To avoid the amount of context switching time, some hardware systems employ two or more sets of processor registers. When the process is switched, the following information is stored for later use.
● Program Counter
● Scheduling information
● Base and limit register value
● Currently used register
● Changed State
● I/O State information
● Accounting information
Q12) What is Inter Process Communication?
A12) Inter process communication (IPC) is used for exchanging data between multiple threads in one or more processes or programs. The Processes may be running on single or multiple computers connected by a network. The full form of IPC is Inter-process communication.
It is a set of programming interface which allow a programmer to coordinate activities among various program processes which can run concurrently in an operating system. This allows a specific program to handle many user requests at the same time.
Since every single user request may result in multiple processes running in the operating system, the process may require to communicate with each other. Each IPC protocol approach has its own advantage and limitation, so it is not unusual for a single program to use all of the IPC methods.
Q13) What are the approaches for Inter-Process Communication?
A13) Approaches for Inter-Process Communication
Here, are few important methods for interprocess communication:
Fig 8: ICP
Pipes
Pipe is widely used for communication between two related processes. This is a half-duplex method, so the first process communicates with the second process. However, in order to achieve a full-duplex, another pipe is needed.
Message Passing:
It is a mechanism for a process to communicate and synchronize. Using message passing, the process communicates with each other without resorting to shared variables.
IPC mechanism provides two operations:
● Send (message)- message size fixed or variable
● Received (message)
Message Queues:
A message queue is a linked list of messages stored within the kernel. It is identified by a message queue identifier. This method offers communication between single or multiple processes with full-duplex capacity.
Direct Communication:
In this type of inter-process communication process, should name each other explicitly. In this method, a link is established between one pair of communicating processes, and between each pair, only one link exists.
Indirect Communication:
Indirect communication establishes like only when processes share a common mailbox each pair of processes sharing several communication links. A link can communicate with many processes. The link may be bi-directional or unidirectional.
Shared Memory:
Shared memory is a memory shared between two or more processes that are established using shared memory between all the processes. This type of memory requires to protected from each other by synchronizing access across all the processes.
FIFO:
Communication between two unrelated processes. It is a full-duplex method, which means that the first process can communicate with the second process, and the opposite can also happen.
Q14) Write about user level thread?
A14) User-level thread
The software doesn't acknowledge the user-level thread. User threads may be simply enforced and it's enforced by the user. If a user performs a user-level thread obstruction operation, the complete method is blocked. The kernel level thread doesn't have an unskilled person regarding the user level thread. The kernel-level thread manages user-level threads as if they're single-threaded processes?
Examples: Java thread, POSIX threads, etc.
Advantages of User-level threads
- The user threads may be simply enforced than the kernel thread.
- User-level threads may be applied to such sorts of in operation systems that don't support threads at the kernel-level.
- It's quicker and economical.
- Context switch time is shorter than the kernel-level threads.
- It doesn't need modifications of the software.
- User-level threads illustration is extremely easy. The register, PC, stack, and mini thread management blocks square measure hold on within the address house of the user-level method.
- It's easy to form, switch, and synchronize threads while not the intervention of the method.
Disadvantages of User-level threads
- User-level threads lack coordination between the thread and therefore the kernel.
- If a thread causes a page fault, the whole method is blocked.
Q15) What is kernel level thread?
A15) Kernel level thread
The kernel thread acknowledges the software. There square measure a thread management block and method management block within the system for every thread and method within the kernel-level thread. The kernel-level thread is enforced by the software. The kernel is aware of regarding all the threads and manages them. The kernel-level thread offers a supervisor call instruction to form and manage the threads from user-space. The implementation of kernel threads is troublesome than the user thread. Context switch time is longer within the kernel thread. If a kernel thread performs an obstruction operation, the Banky thread execution will continue.
Example: Window Solaris.
Advantages of Kernel-level threads
- Kernel can schedule many threads from the same process on numerous processes at the same time.
- If a process's main thread is stalled, the Kernel can schedule another process's main thread.
- Kernel routines can be multithreaded as well.
Disadvantages of Kernel-level threads
- Kernel threads are more difficult to establish and maintain than user threads.
- A mode switch to the Kernel is required to transfer control from one thread to another within the same process.
Q16) What are the benefits of thread?
A16) Benefits of Threads
● Enhanced outturn of the system: once the method is split into several threads, and every thread is treated as employment, the quantity of jobs worn out the unit time will increase. That's why the outturn of the system additionally will increase.
● Effective Utilization of digital computer system: after you have quite one thread in one method, you'll be able to schedule quite one thread in additional than one processor.\
● Faster context switch: The context shift amount between threads is a smaller amount than the method context shift. The method context switch suggests that additional overhead for the hardware.
● Responsiveness: once the method is split into many threads, and once a thread completes its execution, that method may be suffered as before long as doable.
● Communication: Multiple-thread communication is easy as a result of the threads share an equivalent address house, whereas in method, we have a tendency to adopt simply some exclusive communication methods for communication between 2 processes.
● Resource sharing: Resources may be shared between all threads at intervals a method, like code, data, and files. Note: The stack and register can't be shared between threads. There square measure a stack and register for every thread.
Q17) Describe the thread life cycle?
A17) Thread life cycle
Appearing on your screen may be a thread state diagram. Let's take a more in-depth explore the various states shown on the diagram.
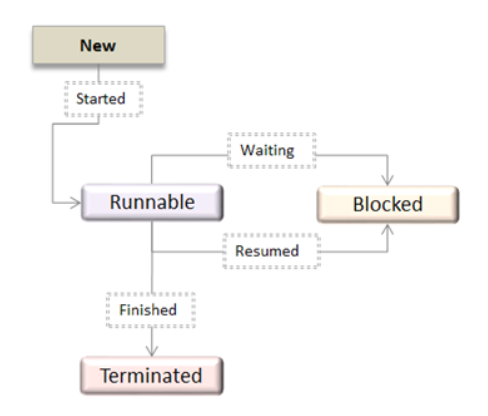
Fig 9: OS Thread State Diagram
A thread is within the new state once it's been created. It does not take any hardware resources till it's really running. Now, the method is taking on hardware resources as a result of it's able to run. However, it's in an exceedingly runnable state as a result of it might be looking forward to another thread to run and then it's to attend for its flip.
A thread that isn't allowed to continue remains in an exceedingly blocked state. Parenthetically that a thread is looking forward to input/output (I/O), however it ne'er gets those resources, therefore it'll stay in an exceedingly blocked state. The great news is that a blocked thread will not use hardware resources. The thread is not stopped forever. For instance, if you permit emergency vehicles to pass, it doesn't mean that you just square measure forever barred from your final destination. Similarly, those threads (emergency vehicles) that have the next priority square measure processed prior to you.
If a thread becomes blocked, another thread moves to the front of the road. However, this is often accomplished is roofed within the next section regarding programming and context shift.
Finally, a thread is terminated if it finishes a task with success or abnormally. At this time, no hardware resources square measure used.
Q18) Consider the following set of three processes with the following arrival and burst times:
Process Id | Arrival time | Burst time |
P1 | 0 | 2 |
P2 | 3 | 1 |
P3 | 5 | 6 |
Calculate the average waiting time and average turn around time if the CPU scheduling policy is FCFS.
A18) Gantt chart

As we know -
Turn Around time = Exit time – Arrival time
Waiting time = Turn Around time – Burst time
Process Id | Exit time | Turn Around time | Waiting time |
P1 | 2 | 2 – 0 = 2 | 2 – 2 = 0 |
P2 | 4 | 4 – 3 = 1 | 1 – 1 = 0 |
P3 | 11 | 11- 5 = 6 | 6 – 6 = 0 |
Now,
Average Turn Around time = (2 + 1 + 6) / 3
= 9 / 3
= 3 unit
Average waiting time = (0 + 0 + 0) / 3
= 0 / 3
= 0 unit
Q19) Solve this using a round robin algorithm?
Process | Burst Time (in ms) | Time Quantum = 2 ms |
P1 | 3 | |
P2 | 6 | |
P3 | 4 | |
P4 | 2 |
A19) According to RR scheduling, the sequence of process execution will be as shown below in the Gantt chart:
Gantt chart
P1 | P2 | P3 | P4 | P1 | P2 | P3 | P2 |
0 2 4 6 8 9 11 13 15
Average waiting time = (6 + 9 + 9 + 6) / 4
= 7.5 ms
Average turnaround time = (9 + 15 + 13 + 8) / 4
= 11.25 ms
Q20) Describe Multiple - Level feedback Queues Scheduling?
A20) However, multilevel feedback queue scheduling enables a process to switch across queues. The concept is to divide processes based on their CPU-burst characteristics. A process will be shifted to a lower-priority queue if it consumes too much CPU time. A process that has been waiting in a lower-priority queue for too long may be shifted to a higher-priority queue. This type of ageing keeps you from going hungry.
The following parameters constitute a multilevel feedback queue scheduler in general:
● The number of queues.
● The scheduling algorithm for each queue.
● The procedure for determining when a process should be moved to a higher-priority queue.
● The procedure for determining when a process should be moved to a higher-priority queue.
● The procedure for determining whether a process should be demoted to a lower-priority queue.
A multilevel feedback queue scheduler is the most general CPU scheduling algorithm due to its formulation. It can be tailored to a specific system under development. Unfortunately, defining the optimum scheduler also necessitates some method of selecting values for all of the parameters. The most broad method is a multilevel feedback queue, but it is also the most difficult.

Fig 10: Example of multilevel feedback queue scheduling
Needs
The following are some elements to consider in order to comprehend the need for such complicated scheduling:
● This scheduling method is more adaptable than the multilevel queue scheduling method.
● This algorithm aids in response time reduction.
● The SJF method, which basically requires the running time of operations in order to schedule them, is required to optimise the turnaround time. As we all know, the length of time it takes for a procedure to complete is unknown in advance. Furthermore, this scheduling mostly runs a process for a time quantum before changing the process' priority if the process is lengthy. As a result, our scheduling algorithm primarily learns from past process behaviour and then predicts future process behaviour. In this way, MFQS tries to run a shorter process first which in return leads to optimize the turnaround time.
Advantages
● This is a Scheduling Algorithm with a lot of flexibility.
● Separate processes can travel between different queues using this scheduling approach.
● A process that waits too long in a lower priority queue may be shifted to a higher priority queue using this approach, which helps to avoid starvation.
Disadvantages
● This algorithm is too complicated.
● As processes move through different queues, more CPU overheads are produced.
● This approach requires some other means to choose the values in order to find the optimum scheduler.




