Unit - 6
File System
Q1) What is a file?
A1) A file is a collection of correlated information which is recorded on secondary or non-volatile storage like magnetic disks, optical disks, and tapes. It is a method of data collection that is used as a medium for giving input and receiving output from that program.
In general, a file is a sequence of bits, bytes, or records whose meaning is defined by the file creator and user. Every File has a logical location where they are located for storage and retrieval.
Objective of File management System
Here are the main objectives of the file management system:
● It provides I/O support for a variety of storage device types.
● Minimizes the chances of lost or destroyed data
● Helps OS to standardized I/O interface routines for user processes.
● It provides I/O support for multiple users in a multiuser systems environment.
File structure
A File Structure needs to be predefined format in such a way that an operating system understands. It has an exclusively defined structure, which is based on its type.
Three types of files structure in OS:
● A text file: It is a series of characters that is organized in lines.
● An object file: It is a series of bytes that is organized into blocks.
● A source file: It is a series of functions and processes.
File Attributes
A file has a name and data. Moreover, it also stores meta information like file creation date and time, current size, last modified date, etc. All this information is called the attributes of a file system.
Here, are some important File attributes used in OS:
● Name: It is the only information stored in a human-readable form.
● Identifier: Every file is identified by a unique tag number within a file system known as an identifier.
● Location: Points to file location on device.
● Type: This attribute is required for systems that support various types of files.
● Size. Attribute used to display the current file size.
● Protection. This attribute assigns and controls the access rights of reading, writing, and executing the file.
● Time, date and security: It is used for protection, security, and also used for monitoring
Q2) Write the properties of the file?
A2) Here, are important properties of a file system:
● Files are stored on disk or other storage and do not disappear when a user logs off.
● Files have names and are associated with access permission that permits controlled sharing.
● Files could be arranged or more complex structures to reflect the relationship between them.
Q3) What are the functions of a file?
A3) Functions of File
● Create a file, find space on disk, and make an entry in the directory.
● Write to file, requires positioning within the file
● Read from file involves positioning within the file
● Delete directory entry, regain disk space.
● Reposition: move read/write position.
Q4) Write the different types of file?
A4) File Type
It refers to the ability of the operating system to differentiate various types of files like text files, binary, and source files. However, Operating systems like MS_DOS and UNIX has the following type of files:
Character Special File
It is a hardware file that reads or writes data character by character, like mouse, printer, and more.
Ordinary files
● These types of files stores user information.
● It may be text, executable programs, and databases.
● It allows the user to perform operations like add, delete, and modify.
Directory Files
● Directory contains files and other related information about those files. Its basically a folder to hold and organize multiple files.
Special Files
● These files are also called device files. It represents physical devices like printers, disks, networks, flash drive, etc.
Q5) Describe the file access method?
A5) Let's look at various ways to access files stored in secondary memory.
Sequential Access

Fig 1: Sequential access
Most of the operating systems access the file sequentially. In other words, we can say that most of the files need to be accessed sequentially by the operating system.
In sequential access, the OS read the file word by word. A pointer is maintained which initially points to the base address of the file. If the user wants to read first word of the file then the pointer provides that word to the user and increases its value by 1 word. This process continues till the end of the file.
Modern word systems do provide the concept of direct access and indexed access but the most used method is sequential access due to the fact that most of the files such as text files, audio files, video files, etc need to be sequentially accessed.
Direct Access
The Direct Access is mostly required in the case of database systems. In most of the cases, we need filtered information from the database. The sequential access can be very slow and inefficient in such cases.
Suppose every block of the storage stores 4 records and we know that the record we needed is stored in 10th block. In that case, the sequential access will not be implemented because it will traverse all the blocks in order to access the needed record.
Direct access will give the required result despite of the fact that the operating system has to perform some complex tasks such as determining the desired block number. However, that is generally implemented in database applications.

Fig 2: Database system
Indexed Access
If a file can be sorted on any of the filed, then an index can be assigned to a group of certain records. However, A particular record can be accessed by its index. The index is nothing but the address of a record in the file.
In index accessing, searching in a large database became very quick and easy but we need to have some extra space in the memory to store the index value.
Q6) Explain directory structure?
A6) The directory can be defined as the listing of the related files on the disk. The directory may store some or the entire file attributes.
To get the benefit of different file systems on the different operating systems, A hard disk can be divided into some partitions of different sizes. The partitions are also called volumes or minidisks.
Each partition must have at least one directory in which, all the files of the partition can be listed. A directory entry is maintained for each file in the directory which stores all the information related to that file.

Fig 3: Example
A directory can be viewed as a file that contains the Metadata of a bunch of files.
Every Directory supports many common operations on the file:
- File Creation
- Search for the file
- File deletion
- Renaming the file
- Traversing Files
- Listing of files
Single Level Directory
The simplest method is to have one big list of all the files on the disk. The entire system will contain only one directory which is supposed to mention all the files present in the file system. The directory contains one entry per each file present on the file system.
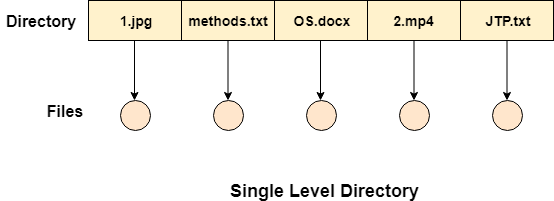
Fig 4: Single level directory
This type of directories can be used for a simple system.
Advantages
- Implementation is very simple.
- If the sizes of the files are very small then the searching becomes faster.
- File creation, searching, deletion is very simple since we have only one directory.
Disadvantages
- We cannot have two files with the same name.
- The directory may be very big therefore searching for a file may take so much time.
- Protection cannot be implemented for multiple users.
- There are no ways to group the same kind of files.
- Choosing the unique name for every file is a bit complex and limits the number of files in the system because most of the Operating System limits the number of characters used to construct the file name.
Two Level Directory
In two-level directory systems, we can create a separate directory for each user. There is one master directory that contains separate directories dedicated to each user. For each user, there is a different directory present at the second level, containing a group of user's files. The system doesn't let a user enter the other user's directory without permission.
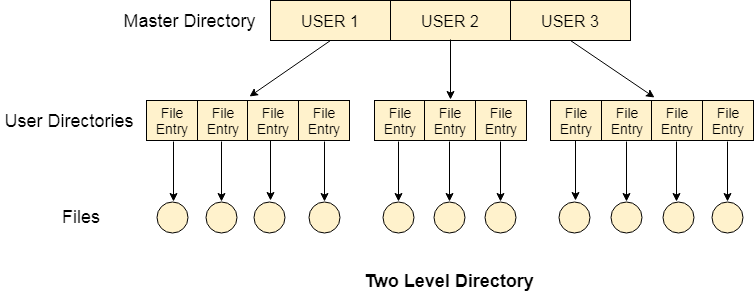
Fig 5: Two-Level Directory
Characteristics of the two-level directory system
- Each file has a pathname as /User-name/directory-name/
- Different users can have the same file name.
- Searching becomes more efficient as only one user's list needs to be traversed.
- The same kind of files cannot be grouped into a single directory for a particular user.
Every Operating System maintains a variable as PWD which contains the present directory name (present user name) so that the searching can be done appropriately.
Q7) What do you mean by file system mounting?
A7) You need to install a file system before you can access files on a filesystem. Mounting a file system connects to a directory (mount point) the file system and makes it open to the system. For all times, the root (/) file system is installed. It is possible to link or disconnect some other file system from the root file system (/).
When you install a file system, and as long as the file system is installed, all data or folders in the underlying mount point directory are inaccessible. These files are not permanently impacted by the mounting process, and when the file system is unmounted, they become usable again. Usually, mount directories are bare, though, so you don't generally want to obscure existing data.
For example, the figure below shows a local file system, starting with a root (/) file system, sbin, etc, and opt-in subdirectories.
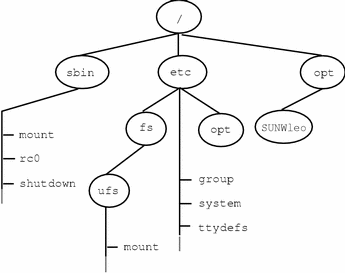
Now, say you wanted to access a local file system that contains a set of unbundled products from the /opt file system.
First, you need to create a directory to be used as a mount point, such as /opt/unbundled, for the file system that you want to mount. You can mount the file system once the mount point is generated (using the mount command), which makes all the files and directories in /opt/unbundled open, as seen in the following figure.
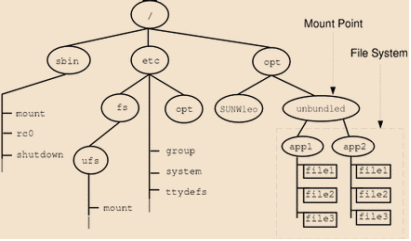
The /etc/mnttab (mount table) file is modified with a list of currently mounted file systems whenever you mount or unmount a file system. With a cat or more commands, you can show the contents of this file, but you can't modify it. Here is an example of the following file: /etc/mnttab
Syntax:
Int dup (int oldfd);
Oldfd: old file descriptor whose copy is to be created.
Q8) What is file sharing?
A8) File sharing is the observation of sharing or providing access to digital info or resources, as well as documents, multimedia systems (audio/video), graphics, pc programs, pictures, and e-books. It's the non-public or public distribution of information or resources in an exceedingly large network with totally different levels of sharing privileges.
File sharing is often done exploitation in many ways. The foremost common techniques for file storage, distribution, and transmission embody the following:
● Removable storage devices
● Centralized file hosting server installations on networks
● World Wide Web-oriented hyperlinked documents
● Distributed peer-to-peer networks
File Sharing
File sharing could be a utile pc service feature that evolved from removable media via network protocols, like File Transfer Protocol (FTP). Starting within the Nineties, several remote file-sharing mechanisms were introduced, as well as FTP, hotline, and net relay chat (IRC).
Operating systems conjointly offer file-sharing ways, like network file sharing (NFS). Most file-sharing tasks use 2 basic sets of network criteria, as follows:
● Peer-to-Peer (P2P) File Sharing: this can be the foremost common, however polemical, technique of file-sharing as a result of the employment of peer-to-peer computer code. Network pc users find shared information with third-party computer code. P2P file sharing permits users to directly access, transfer, and edit files. Some third-party computer code facilitates P2P sharing by aggregation and segmenting massive files into smaller items.
● File Hosting Services: This P2P file-sharing various provides a broad choice of common on-line material. These services area unit very often used with net collaboration ways, as well as email, blogs, forums, or alternative mediums, wherever direct transfer links from the file hosting services are often enclosed. These service websites sometimes host files to alter users to transfer them.
Once users transfer or create use of a file employing a file-sharing network, their PC conjointly becomes a region of that network, permitting alternative users to transfer files from the user's pc. File sharing is usually ill-gotten, except for sharing material that's not proprietary or proprietary. Another issue with file-sharing applications is the downside of spyware or adware, as some file-sharing websites have placed spyware programs on their websites. These spyware programs area unit typically put in on users' computers while not their consent and awareness.
Q9) What is the need for file protection?
A9) Need for file protection
● When data is stored in a computer system, we want to ensure that it is protected from physical harm (reliability) and unauthorized access (protection).
Duplicate copies of files usually enhance reliability. Many computers include systems programs that copy disc files to tape at regular intervals (once per day, week, or month) to keep a copy in case a file system is mistakenly deleted (either automatically or with the help of a computer operator).
● Hardware issues (such as reading or writing mistakes), power surges or failures, head crashes, dirt, temperature extremes, and vandalism can all harm file systems. Files can be mistakenly erased. File contents can potentially be lost due to bugs in the file-system software.
● Protection can come in a variety of forms. We might establish safety for a tiny single-user system by physically removing the floppy discs and locking them in a desk drawer or file cabinet. Other techniques, on the other hand, are required in a multi-user system.
Access Control
● Assign an access-control list (ACL) to each file and directory, providing the user name and the categories of access allowed for each user.
● When a user asks for access to a file, the operating system first examines the access list for that file. The access is granted if that user is listed for the requested access. Otherwise, a protection violation occurs, and access to the file is forbidden to the user job.
● This method has two unfavorable outcomes:
○ Constructing such a list can be a time-consuming and unrewarding effort, especially if we don't know the system's user list ahead of time.
○ The directory entry, which was previously fixed in size, must now be variable in size, resulting in more difficult space management.
● Many systems recognise three types of users in relation with each file to reduce the length of the access control list:
○ Owner: The owner of a file is the user who generated it.
○ Group: A group, or work group, is a collection of people who are sharing a file and require similar access.
○ Universe: The universe is made up of all other users in the system.
Q10) Describe file system structure?
A10) The File System facilitates access to the disc by allowing data to be saved, located, and retrieved quickly. A file system must be capable of storing, locating, and retrieving files.
The majority of operating systems, including file systems, employ a layering strategy for all tasks. Some actions are performed by each layer of the file system.
The graphic below shows how the file system is separated into layers, as well as the functionality of each layer.
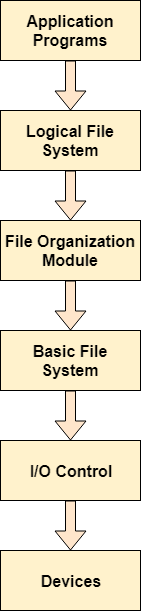
Fig 6: Structure of file system
● Application program - The first request for a file from an application programme is sent to the logical file system. The Meta data of the file and directory hierarchy is stored in the logical file system. This layer will throw an error if the application program does not have the requisite file permissions. The path of the file is also verified by logical file systems.
● File organization module - In most cases, files are separated into logical units. Files must be saved on the hard drive and retrieved from the hard drive. The tracks and sectors on a hard disc are separated into different groups. As a result, logical blocks must be translated to physical blocks in order to store and retrieve files. The File organisation module is in charge of this mapping. It is also in charge of managing open space.
● Basic file system - When the File organization module has determined which physical block the application programme requires, it informs the basic file system. The basic file system is in charge of sending commands to I/O control so that those blocks can be retrieved.
● I/O controls - I/O controls are the codes that allow it to access the hard disc. Device drivers are the names for these codes. Interrupt handling is also handled via I/O controllers.
Q11) What do you mean by directory implementation?
A11) There is the number of algorithms by which the directories can be implemented. However, the selection of an appropriate directory implementation algorithm may significantly affect the performance of the system.
The directory implementation algorithms are classified according to the data structure they are using. There are mainly two algorithms which are used these days.
1. Linear List
In this algorithm, all the files in a directory are maintained as singly lined list. Each file contains the pointers to the data blocks which are assigned to it and the next file in the directory.
Characteristics
● When a new file is created, then the entire list is checked whether the new file name is matching to a existing file name or not. In case, it doesn't exist, the file can be created at the beginning or at the end. Therefore, searching for a unique name is a big concern because traversing the whole list takes time.
● The list needs to be traversed in case of every operation (creation, deletion, updating, etc) on the files therefore the systems become inefficient.
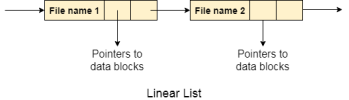
Fig 7: Linear list
2. Hash Table
To overcome the drawbacks of singly linked list implementation of directories, there is an alternative approach that is hash table. This approach suggests to use hash table along with the linked lists.
A key-value pair for each file in the directory gets generated and stored in the hash table. The key can be determined by applying the hash function on the file name while the key points to the corresponding file stored in the directory.
Now, searching becomes efficient due to the fact that now, entire list will not be searched on every operating. Only hash table entries are checked using the key and if an entry found then the corresponding file will be fetched using the value.
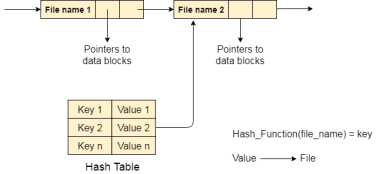
Fig 8 – Hash table
Q12) Explain allocation methods?
A12) There are various methods which can be used to allocate disk space to the files. Selection of an appropriate allocation method will significantly affect the performance and efficiency of the system. Allocation method provides a way in which the disk will be utilized and the files will be accessed.
There are following methods which can be used for allocation.
- Contiguous Allocation.
- Extents
- Linked Allocation
- Clustering
- FAT
- Indexed Allocation
- Linked Indexed Allocation
- Multilevel Indexed Allocation
- Inode
Contiguous Allocation
If the blocks are allocated to the file in such a way that all the logical blocks of the file get the contiguous physical block in the hard disk then such allocation scheme is known as contiguous allocation.
In the image shown below, there are three files in the directory. The starting block and the length of each file are mentioned in the table. We can check in the table that the contiguous blocks are assigned to each file as per its need.

Fig 9: Contiguous allocation
Advantages
- It is simple to implement.
- We will get Excellent read performance.
- Supports Random Access into files.
Disadvantages
- The disk will become fragmented.
- It may be difficult to have a file grow.
Linked List Allocation
Linked List allocation solves all problems of contiguous allocation. In linked list allocation, each file is considered as the linked list of disk blocks. However, the disks blocks allocated to a particular file need not to be contiguous on the disk. Each disk block allocated to a file contains a pointer which points to the next disk block allocated to the same file.
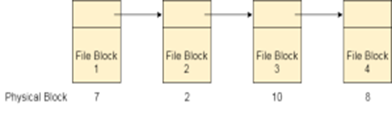
Fig 10: Linked list allocation
Advantages
- There is no external fragmentation with linked allocation.
- Any free block can be utilized in order to satisfy the file block requests.
- File can continue to grow as long as the free blocks are available.
- Directory entry will only contain the starting block address.
Disadvantages
- Random Access is not provided.
- Pointers require some space in the disk blocks.
- Any of the pointers in the linked list must not be broken otherwise the file will get corrupted.
- Need to traverse each block.
Indexed Allocation
Limitation of FAT
Limitation in the existing technology causes the evolution of a new technology. Till now, we have seen various allocation methods; each of them was carrying several advantages and disadvantages.
File allocation table tries to solve as many problems as possible but leads to a drawback. The more the number of blocks, the more will be the size of FAT.
Therefore, we need to allocate more space to a file allocation table. Since, file allocation table needs to be cached therefore it is impossible to have as many space in cache. Here we need a new technology which can solve such problems.
Indexed Allocation Scheme
Instead of maintaining a file allocation table of all the disk pointers, Indexed allocation scheme stores all the disk pointers in one of the blocks called as indexed block. Indexed block doesn't hold the file data, but it holds the pointers to all the disk blocks allocated to that particular file. Directory entry will only contain the index block address.
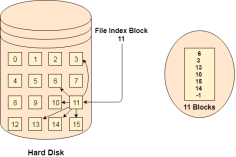
Fig 11: Index allocation
Advantages
- Supports direct access
- A bad data block causes the lost of only that block.
Disadvantages
- A bad index block could cause the lost of entire file.
- Size of a file depends upon the number of pointers, a index block can hold.
- Having an index block for a small file is totally wastage.
- More pointer overhead
Q13) Define free space management?
A13) The system keeps tracks of the free disk blocks for allocating space to files when they are created. Also, to reuse the space released from deleting the files, free space management becomes crucial. The system maintains a free space list which keeps track of the disk blocks that are not allocated to some file or directory. The free space list can be implemented mainly as:
Bitmap or Bit vector –
A Bitmap or Bit Vector is series or collection of bits where each bit corresponds to a disk block. The bit can take two values: 0 and 1: 0 indicates that the block is allocated and 1 indicates a free block.
The given instance of disk blocks on the disk in Figure 1 (where green blocks are allocated) can be represented by a bitmap of 16 bits as: 0000111000000110.

Fig 12: Example
Advantages –
- Simple to understand.
- Finding the first free block is efficient. It requires scanning the words (a group of 8 bits) in a bitmap for a non-zero word. (A 0-valued word has all bits 0). The first free block is then found by scanning for the first 1 bit in the non-zero word.
The block number can be calculated as:
(number of bits per word) *(number of 0-values words) + offset of bit first bit 1 in the non-zero word.
For the Figure-1, we scan the bitmap sequentially for the first non-zero word.
The first group of 8 bits (00001110) constitute a non-zero word since all bits are not 0. After the non-0 word is found, we look for the first 1 bit. This is the 5th bit of the non-zero word. So, offset = 5.
Therefore, the first free block number = 8*0+5 = 5.
Linked List –
In this approach, the free disk blocks are linked together i.e. a free block contains a pointer to the next free block. The block number of the very first disk block is stored at a separate location on disk and is also cached in memory.

Fig 13: Example
In Figure, the free space list head points to Block 5 which points to Block 6, the next free block and so on. The last free block would contain a null pointer indicating the end of free list. A drawback of this method is the I/O required for free space list traversal.
Grouping –
This approach stores the address of the free blocks in the first free block. The first free block stores the address of some, say n free blocks. Out of these n blocks, the first n-1 blocks are actually free and the last block contains the address of next free n blocks. An advantage of this approach is that the addresses of a group of free disk blocks can be found easily.
Counting –
This approach stores the address of the first free disk block and a number n of free contiguous disk blocks that follow the first block.
Every entry in the list would contain:
- Address of first free disk block
- A number n
For example, in Figure, the first entry of the free space list would be: ([Address of Block 5], 2), because 2 contiguous free blocks follow block 5.
Q14) What do you mean by efficiency?
A14) Now that we have discussed various block-allocation and directory management options, we can further consider their effect on performance and efficient disk use. Disks tend to represent a major bottleneck in system performance, since they are the slowest main computer component. In this section, we discuss a variety of techniques used to improve the efficiency and performance of secondary storage.
Efficiency
The efficient use of disk space depends heavily on the disk allocation and directory algorithms in use. For instance, UNIX inodes are pre allocated on a volume. Even an "empty" disk has a percentage of its space lost to inodes. However, by pre allocating the inodes and. Spreading them across the volume, we improve the file system's performance. This improved performance results from the UNIX allocation and free-space algorithms, which try to keep a file's data blocks near that file's inode block to reduce seek time.
To reduce this fragmentation, BSD UNIX varies the cluster size as a file grows. Large clusters are used where they can be filled, and small clusters are used for small files and the last cluster of a file. This system is described in Appendix A. The types of data normally kept in a file's directory (or inode) entry also require consideration. Commonly, a 'last write date" is recorded to supply information to the user and, to determine whether the file needs to be backed up. Some systems also keep a "last access date," so that a user can determine when the file was last read.
The result of keeping this information is that, whenever the file is read, a field in the directory structure must be written to. That means the block must be read into memory, a section changed, and the block written back out to disk, because operations on disks occur only in block (or cluster) chunks. So any time a file is opened for reading, its directory entry must be read and written as well. This requirement can be inefficient for frequently accessed files, so we must weigh its benefit against its performance cost when designing a file system. Generally, every data item associated with a file needs to be considered for its effect on efficiency and performance.
As an example, consider how efficiency is affected by the size of the pointers used to access data. Most systems use either 16- or 32-bit pointers throughout the operating system. These pointer sizes limit the length of a file to either 2 16 (64 KB) or 232 bytes (4 GB). Some systems implement 64-bit pointers to increase this limit to 264 bytes, which is a very large number indeed. However, 64-bit pointers take more space to store and in turn make the allocation and free-space-management methods (linked lists, indexes, and so on) use more disk space. One of the difficulties in choosing a pointer size, or indeed any fixed allocation size within an operating system, is planning for the effects of changing technology. Consider that the IBM PC XT had a 10-MB hard drive and an MS-DOS file system that could support only 32 MB. (Each FAT entry was 12 bits, pointing to an 8-KB cluster.)
As disk capacities increased, larger disks had to be split into 32-MB partitions, because the file system could not track blocks beyond 32 MB. As hard disks with capacities of over 100 MB became common, most disk controllers include local memory to form an on-board cache that is large enough to store entire tracks at a time. Once a seek is performed, the track is read into the disk cache starting at the sector under the disk head (reducing latency time).
The disk controller then transfers any sector requests to the operating system. Once blocks make it from the disk controller into main memory, the operating system may cache the blocks there. Some systems maintain a separate section of main memory for a buffer cache, where blocks are kept under the assumption that they will be used again shortly. Other systems cache file data using a page cache.
The page cache uses virtual memory techniques to cache file data as pages rather than as file-system-oriented blocks. Caching file data using virtual addresses is far more efficient than caching through physical disk blocks, as accesses interface with virtual memory rather than the file system.
Several systems—including Solaris, Linux, and Windows NT, 2000, and XP—use page caching to cache both process pages and file data. This is known as unified virtual memory. Some versions of UNIX and Linux provide a unified buffer cache. To illustrate the benefits of the unified buffer cache, consider the two alternatives for opening and accessing a file. One approach is to use memory mapping; the second is to use the standard system calls read 0 and write 0. Without a unified buffer cache, we have a situation similar to Figure.
Here, the read() and write () system calls go through the buffer cache. The memory-mapping call, however, requires using two caches—the page cache and the buffer cache. A memory mapping proceeds by reading in disk blocks from the file system and storing them in the buffer cache. Because the virtual memory system does not interface with the buffer cache, the contents of the file in the buffer cache must be copied into the page cache. This situation is known as double caching and requires caching file-system data twice. Not only does it waste memory but it also wastes significant CPU and I/O cycles due to the extra data movement within, system memory.
In addition, inconsistencies between the two caches can result in corrupt files. In contrast, when a unified the disk data structures and algorithms in MS-DOS had to be modified to allow larger file systems. (Each FAT entry was expanded to 16 bits and later to 32 bits.) The initial file-system decisions were made for efficiency reasons; however, with the advent of MS-DOS version 4, millions of computer users were inconvenienced when they had to switch to the new, larger file system. Sun's ZFS file system uses 128-bit pointers, which theoretically should never need to be extended. (The minimum mass of a device capable of storing 2'2S bytes using atomic-level storage would be about 272 trillion kilograms.) As another example, consider the evolution of Sun's Solaris operating system.
Originally, many data structures were of fixed length, allocated at system start-up. These structures included the process table and the open-file table. When the process table became full, no more processes could be created. When the file table became full, no more files could be opened. The system would fail to provide services to users. Table sizes could be increased only by recompiling the kernel and rebooting the system. Since the release of Solaris 2, almost all kernel structures have been allocated dynamically, eliminating these artificial limits on system performance. Of course, the algorithms that manipulate these tables are more complicated, and the operating system is a little slower because it must dynamically allocate and deallocate table entries; but that price is the usual one for more general, functionality.
Q15) Write about performance?
A15) Performance
Even after the basic file-system algorithms have been selected, we can still improve performance in several ways. As will be discussed in Chapter 13, most disk controllers include local memory to form an on-board cache that is large enough to store entire tracks at a time. Once a seek is performed, the track is read into the disk cache starting at the sector under the disk head (reducing latency time).
The disk controller then transfers any sector requests to the operating system. Once blocks make it from the disk controller into main memory, the operating system may cache the blocks there. Some systems maintain a separate section of main memory for a buffer cache, where blocks are kept under the assumption that they will be used again shortly. Other systems cache file data using a page cache.
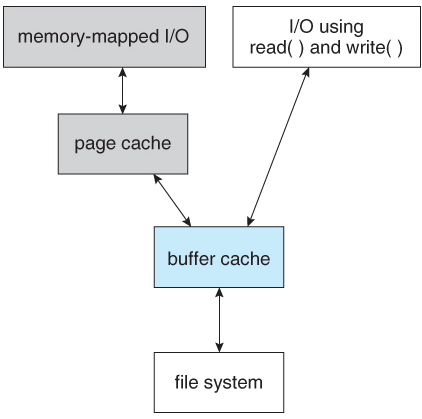
Fig 14: I/O without a unified buffer cache
The page cache uses virtual memory techniques to cache file data as pages rather than as file-system-oriented blocks. Caching file data using virtual addresses is far more efficient than caching through physical disk blocks, as accesses interface with virtual memory rather than the file system. Several systems—including Solaris, Linux, and Windows NT, 2000, and XP—use page caching to cache both process pages and file data. This is known as unified virtual memory. Some versions of UNIX and Linux provide a unified buffer cache.
To illustrate the benefits of the unified buffer cache, consider the two alternatives for opening and accessing a file. One approach is to use memory mapping; the second is to use the standard system calls read 0 and write 0.
Without a unified buffer cache, we have a situation similar to Figure. Here, the read() and write () system calls go through the buffer cache. The memory-mapping call, however, requires using two caches—the page cache and the buffer cache. A memory mapping proceeds by reading in disk blocks from the file system and storing them in the buffer cache. Because the virtual memory system does not interface with the buffer cache, the contents of the file in the buffer cache must be copied into the page cache.
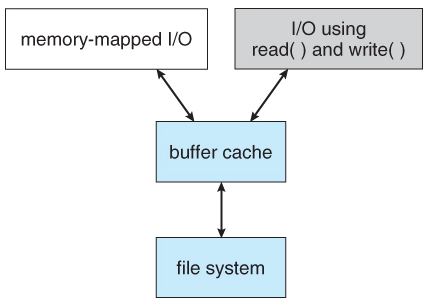
Fig 15: I/O using a unified buffer cache
This situation is known as double caching and requires caching file-system data twice. Not only does it waste memory but it also wastes significant CPU and I/O cycles due to the extra data movement within, system memory. In add ition, inconsistencies between the two caches can result in corrupt files. In contrast, when a unified buffer cache is provided, both memory mapping and the read () and write () system calls use the same page cache. This has the benefit of avoiding double caching, and it allows the virtual memory system to manage file-system data. The unified buffer cache is shown in Figure. Regardless of whether we are caching disk blocks or pages (or both), LEU seems a reasonable general-purpose algorithm for block or page replacement. However, the evolution of the Solaris page-caching algorithms reveals the difficulty in choosing an algorithm. Solaris allows processes and the page cache to share unused memory.
Versions earlier than Solaris 2.5.1 made no distinction between allocating pages to a process and allocating them to the page cache. As a result, a system performing many I/O operations used most of the available memory for caching pages. Because of the high rates of I/O, the page scanner reclaimed pages from processes— rather than from the page cache—when free memory ran low. Solaris 2.6 and Solaris 7 optionally implemented priority paging, in which the page scanner gives priority to process pages over the page cache. Solaris 8 applied a fixed limit to process pages and the file-system page cache, preventing either from forcing the other out of memory. Solaris 9 and 10 again changed the algorithms to maximize memory use and minimize thrashing. This real-world example shows the complexities of performance optimizing and caching.
There are other issues that can affect the performance of I/O such as whether writes to the file system occur synchronously or asynchronously. Synchronous writes occur in the order in which the disk subsystem receives them, and the writes are not buffered. Thus, the calling routine must wait for the data to reach the disk drive before it can proceed. Asynchronous writes are done the majority of the time. In an asynchronous write, the data are stored in the cache, and control returns to the caller. Metadata writes, among others, can be synchronous.
Operating systems frequently include a flag in the open system call to allow a process to request that writes be performed synchronously. For example, databases use this feature for atomic transactions, to assure that data reach stable storage in the required order. Some systems optimize their page cache by using different replacement algorithms, depending on the access type of the file.
A file being read or written sequentially should not have its pages replaced in LRU order, because the most 11.7 Recovery 435 recently used page will be used last, or perhaps never again. Instead, sequential access can be optimized by techniques known as free-behind and read-ahead. Free-behind removes a page from the buffer as soon as the next page is requested. The previous pages are not likely to be used again and waste buffer space. With read-ahead, a requested page and several subsequent pages are read and cached. These pages are likely to be requested after the current page is processed.
Retrieving these data from the disk in one transfer and caching them saves a considerable amount of time. One might think a track cache on the controller eliminates the need for read-ahead on a multiprogrammed system. However, because of the high latency and overhead involved in making many small transfers from the track cache to main memory, performing a read-ahead remains beneficial. The page cache, the file system, and the disk drivers have some interesting interactions. When data are written to a disk file, the pages are buffered in the cache, and the disk driver sorts its output queue according to disk address. These two actions allow the disk driver to minimize disk-head seeks and to write data at times optimized for disk rotation.
Unless synchronous writes are required, a process writing to disk simply writes into the cache, and the system asynchronously writes the data to disk when convenient. The user process sees very fast writes. When data are read from a disk file, the block I/O system does some read-ahead; however, writes are much more nearly asynchronous than are reads. Thus, output to the disk through the file system is often faster than is input for large transfers, counter to intuition.
Q16) Describe mass storage structure?
A16) A broad review of secondary and tertiary storage devices' physical structures.
Magnetic Disks
Magnetic disks make up the majority of secondary storage in today's computers. Disks are a rather straightforward concept. Each disk platter is shaped like a CD and has a flat circular shape. The diameters of most platters range from 1.8 to 5.25 inches. A magnetic substance is applied to the two surfaces of a platter. We keep information on platters by recording it magnetically.
Every platter has a read-write head that "flies" slightly over the surface. The heads are connected to a disk arm that moves all of them together. A platter's surface is divided logically into circular tracks, which are further separated by sectors. A cylinder is formed by a set of tracks in one arm position. A disk drive can have thousands of concentric cylinders, with each track containing hundreds of sectors. Gigabytes are the unit of measurement for the storage capacity of popular disk drives. A drive motor rotates the disk at a high speed when it is in use.
The majority of drives revolve at a rate of 60 to 200 times per second. There are two aspects to disk speed. The transfer rate is the speed at which data is transferred from the hard drive to the computer. The seek time, also known as the random-access time, is the time it takes for the disk arm to travel to the requested cylinder, while the rotational latency is the time it takes for the desired sector to rotate to the disk head. Typical drives have search times and rotational latencies of several milliseconds and can transport several megabytes of data per second. The disk head flies on an incredibly thin cushion of air (measured in microns), thus there's a chance it'll collide with the disk surface.
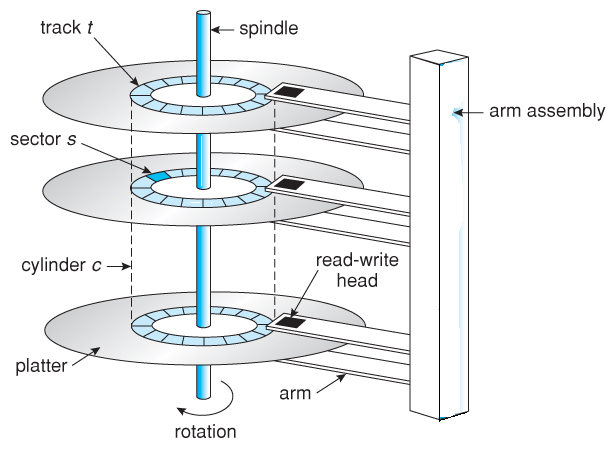
Fig 16: Moving head disk mechanism
Magnetic Tapes
Magnetic tape was employed as a supplemental storage media in the early days. Although it is very permanent and capable of storing vast amounts of data, it has a slow access time when compared to main memory and magnetic disk. Furthermore, because random access to magnetic tape is a thousand times slower than random access to magnetic disk, tapes are ineffective as supplementary storage. Tapes are mostly used for backup, archiving infrequently used data, and transferring data from one system to another. A tape is wound or rewound past a read-write head and retained on a spool.
It can take minutes to get to the right point on a tape, but once there, tape drives can write data at speeds comparable to disk drives. Tape capacity varies substantially depending on the type of tape drive used. They typically store 20 GB to 200 GB of data. Some come with built-in compression, which can more than double the amount of storage available. Tapes and their drivers are often divided into four width categories: 4, 8, and 19 millimeters, as well as 1/4 and 1/2 inch.
Q17) Define disk structure?
A17) Modern disk drives are addressed as large one-dimensional arrays of logical blocks, where the logical block is the smallest unit of transfer. The size of a logical block is usually 512 bytes, although some disks can be low-level formatted to have a different logical block size, such as 1,024 bytes. The one-dimensional array of logical blocks is mapped onto the sectors of the disk sequentially. Sector 0 is the first sector of the first track on the outermost cylinder.
The mapping proceeds in order through that track, then through the rest of the tracks in that cylinder, and then through the rest of the cylinders from outermost to innermost. By using this mapping, we can—at least in theory—convert a logical block number into an old-style disk address that consists of a cylinder number, a track number within that cylinder, and a sector number within that track. In practice, it is difficult to perform, this translation, for two reasons. First, most disks have some defective sectors, but the mapping hides this by substituting spare sectors from elsewhere on the disk. Second, the number of sectors per track is not a constant on some drives.
Let's look more closely at the second reason. On media that use constant linear velocity (CLV), the density of bits per track is uniform. The farther a track is from the centre of the disk, the greater its length, so the more sectors it can hold. As we move from outer zones to inner zones, the number of sectors per track decreases. Tracks in the outermost zone typically hold 40 percent more sectors than do tracks in the innermost zone. The drive increases its rotation speed as the head moves from the outer to the inner tracks to keep the same rate of data moving under the head.
This method is used in CD-ROM and DVD-ROM drives. Alternatively, the disk rotation speed can stay constant, and the density of bits decreases from inner tracks to outer tracks to keep the data rate constant. This method is used in hard disks and is known as constant angular velocity (CAV). The number of sectors per track has been increasing as disk technology improves, and the outer zone of a disk usually has several hundred sectors per track. Similarly, the number of cylinders per disk has been increasing; large disks have tens of thousands of cylinders.
Q18) What is a disk scheduling algorithm?
A18) As we know, a process needs two type of time, CPU time and IO time. For I/O, it requests the Operating system to access the disk.
However, the operating system must be fair enough to satisfy each request and at the same time, operating system must maintain the efficiency and speed of process execution.
The technique that operating system uses to determine the request which is to be satisfied next is called disk scheduling.
Let's discuss some important terms related to disk scheduling.
Seek Time
Seek time is the time taken in locating the disk arm to a specified track where the read/write request will be satisfied.
Rotational Latency
It is the time taken by the desired sector to rotate itself to the position from where it can access the R/W heads.
Transfer Time
It is the time taken to transfer the data.
Disk Access Time
Disk access time is given as,
Disk Access Time = Rotational Latency + Seek Time + Transfer Time
Disk Response Time
It is the average of time spent by each request waiting for the IO operation.
Purpose of Disk Scheduling
The main purpose of disk scheduling algorithm is to select a disk request from the queue of IO requests and decide the schedule when this request will be processed.
Goal of Disk Scheduling Algorithm
- Fairness
- High throughout
- Minimal traveling head time
Disk Scheduling Algorithms
The list of various disks scheduling algorithm is given below. Each algorithm is carrying some advantages and disadvantages. The limitation of each algorithm leads to the evolution of a new algorithm.
- FCFS scheduling algorithm
- SSTF (shortest seek time first) algorithm
- SCAN scheduling
- C-SCAN scheduling
- LOOK Scheduling
- C-LOOK scheduling
Q19) Explain FCFS and SSTF algorithm with example?
A19) FCFS Scheduling Algorithm
It is the simplest Disk Scheduling algorithm. It services the IO requests in the order in which they arrive. There is no starvation in this algorithm, every request is serviced.
Disadvantages
- The scheme does not optimize the seek time.
- The request may come from different processes therefore there is the possibility of inappropriate movement of the head.
Example
Consider the following disk request sequence for a disk with 100 tracks 45, 21, 67, 90, 4, 50, 89, 52, 61, 87, 25
Head pointer starting at 50 and moving in left direction. Find the number of head movements in cylinders using FCFS scheduling.
Solution
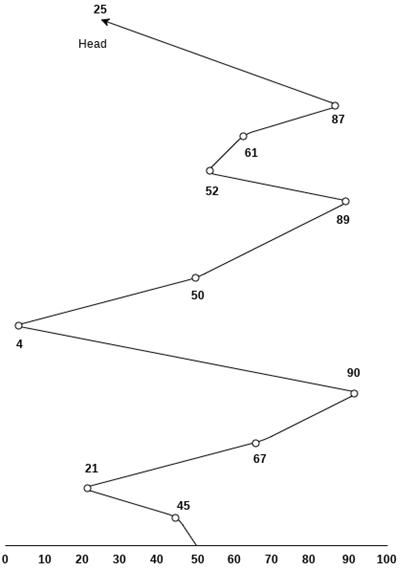
Number of cylinders moved by the head
= (50-45)+(45-21)+(67-21)+(90-67)+(90-4)+(50-4)+(89-50)+(61-52)+(87-61)+(87-25)
= 5 + 24 + 46 + 23 + 86 + 46 + 49 + 9 + 26 + 62
= 376
SSTF Scheduling Algorithm
Shortest seek time first (SSTF) algorithm selects the disk I/O request which requires the least disk arm movement from its current position regardless of the direction. It reduces the total seek time as compared to FCFS.
It allows the head to move to the closest track in the service queue.
Disadvantages
- It may cause starvation for some requests.
- Switching direction on the frequent basis slows the working of algorithm.
- It is not the most optimal algorithm.
Example
Consider the following disk request sequence for a disk with 100 tracks
45, 21, 67, 90, 4, 89, 52, 61, 87, 25
Head pointer starting at 50. Find the number of head movements in cylinders using SSTF scheduling.
Solution:

Number of cylinders = 5 + 7 + 9 + 6 + 20 + 2 + 1 + 65 + 4 + 17 = 136
Q20) Describe scan and c-scan algorithm with example?
A20) Scan Algorithm
It is also called as Elevator Algorithm. In this algorithm, the disk arm moves into a particular direction till the end, satisfying all the requests coming in its path and then it turns back and moves in the reverse direction satisfying requests coming in its path.
It works in the way an elevator works, elevator moves in a direction completely till the last floor of that direction and then turns back.
Example
Consider the following disk request sequence for a disk with 100 tracks
98, 137, 122, 183, 14, 133, 65, 78
Head pointer starting at 54 and moving in left direction. Find the number of head movements in cylinders using SCAN scheduling.
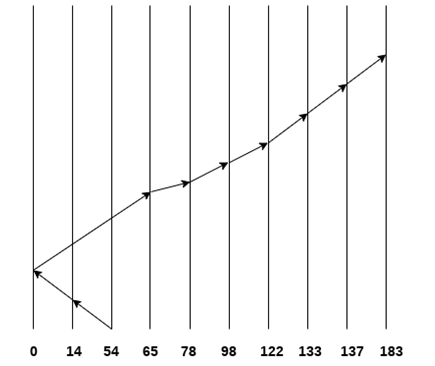
Number of Cylinders = 40 + 14 + 65 + 13 + 20 + 24 + 11 + 4 + 46 = 237
C-SCAN algorithm
In C-SCAN algorithm, the arm of the disk moves in a particular direction servicing requests until it reaches the last cylinder, then it jumps to the last cylinder of the opposite direction without servicing any request then it turns back and start moving in that direction servicing the remaining requests.
Example
Consider the following disk request sequence for a disk with 100 tracks
98, 137, 122, 183, 14, 133, 65, 78
Head pointer starting at 54 and moving in left direction. Find the number of head movements in cylinders using C-SCAN scheduling.

No. Of cylinders crossed = 40 + 14 + 199 + 16 + 46 + 4 + 11 + 24 + 20 + 13 = 387




