Unit - 4
Multiprocessors and multi-computers
Q1) What is a multiprocessor?
A1) A multiprocessor is a computer system that has two or more central processing units (CPUs) that all have full access to the same RAM. The primary goal of using a multiprocessor is to increase the system's execution speed, with fault tolerance and application matching as secondary goals.
Multiprocessors are divided into two types: shared memory multiprocessors and distributed memory multiprocessors. Each CPU in a shared memory multiprocessor shares the common memory, but each CPU in a distributed memory multiprocessor has its own private memory.
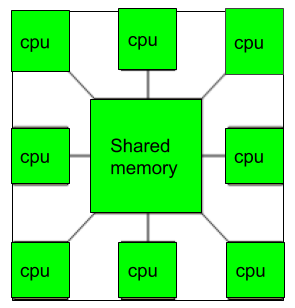
Fig 1: Multiprocessors
Application
● As a single-instruction, single-data-stream uniprocessor (SISD).
● Single instruction, multiple data stream (SIMD) multiprocessors are commonly employed for vector processing.
● Multiple sequence of instructions in a single view, such as multiple instruction, single data stream (MISD), is a term used to describe hyper-threading or pipelined processors.
● Several, individual series of instructions in multiple viewpoints, such as multiple instruction, multiple data stream, are executed within a single system (MIMD).
Advantages of using multiprocessors
● Performance has improved.
● There are numerous applications.
● Within an application, multitasking is possible.
● High throughput and quick response.
● CPUs can share hardware.
Q2) Write about Multi-computers?
A2) A multicomputer system is a computer having several processors that work together to solve a problem. Each CPU has its own memory, which it can access, and the processors can communicate with one another over an interconnection network.
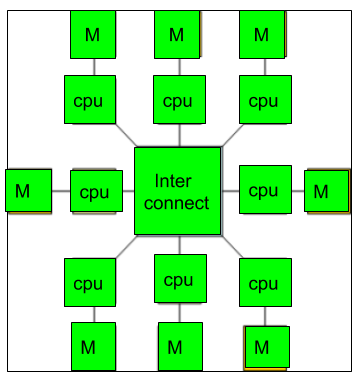
Fig 2: Multi-computers
Because the multicomputer allows messages to move between the processors, the task can be divided among the processors to be completed. As a result, a distributed computing system can be implemented using a multicomputer. A multicomputer is more cost-effective and easy to construct than a multiprocessor.
Q3) Difference between multiprocessors and multi-computers?
A3) Difference between multiprocessors and multi-computers
● A multiprocessor is a computer that has two or more central processing units (CPUs) that can execute numerous tasks, whereas a multicomputer is a computer that has several processors connected via an interconnection network to conduct a calculation task.
● A multiprocessor system is a single computer with many CPUs, whereas a multicomputer system is a collection of computers that work together as one.
● A multicomputer is simpler and less expensive to build than a multiprocessor.
● Programs in multiprocessor systems are typically easier, whereas programs in multicomputer systems are typically more challenging.
● Multiprocessor supports parallel computing, Multicomputer supports distributed computing.
Q4) Define process and thread in the context of multi-processors?
A4) With an MIMD, each processor is executing its own instruction stream. In many cases, each processor executes a different process. A process is a segment of code that may be run independently; the state of the process contains all the information necessary to execute that program on a processor. In a multi-programmed environment, where the processors may be running independent tasks, each process is typically independent of other processes.
It is also useful to be able to have multiple processors executing a single program and sharing the code and most of their address space. When multiple processes share code and data in this way, they are often called threads. Today, the term thread is often used in a casual way to refer to multiple loci of execution that may run on different processors, even when they do not share an address space. For example, a multithreaded architecture actually allows the simultaneous execution of multiple processes, with potentially separate address spaces, as well as multiple threads that share the same address space.
Q5) What is SIMD?
A5) The acronym SIMD stands for 'Single Instruction, Multiple Data Stream.' It symbolizes a company with a large number of processing units overseen by a central control unit.
In SIMD computers, the ‘N’ number of processors are connected to a control unit and all the processors have their memory units. All the processors are connected by an interconnection network.
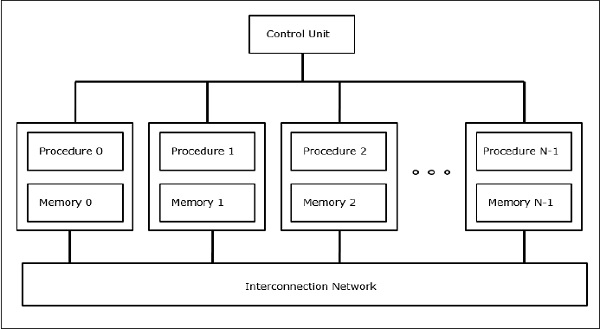
Fig 3: SIMD Supercomputers
The control unit sends the same instruction to all processors, but they work on separate data.
To connect with all of the processors at the same time, the shared memory unit must have numerous modules.
SIMD was created with array processing devices in mind. Vector processors, on the other hand, can be included in this category.
Q6) Write the advantages of SIMD?
A6) A SIMD-enabled application is one in which the same value is added to (or subtracted from) a large number of data points, as is common in many multimedia applications. Changing the brightness of an image is one example. The brightness of the red (R), green (G), and blue (B) elements of the color are represented by three values in each pixel of a picture. The R, G, and B values are read from memory, a value is added to (or subtracted from) them, and the resulting values are written back to memory to adjust the brightness. For volume control, audio DSPs would multiply both the Left and Right channels at the same time.
There are two advantages to using a SIMD processor in this operation. For one thing, the data is organized in blocks, thus a large number of values can be imported at once. A SIMD processor will have a single instruction that basically says "retrieve n pixels" instead of a sequence of instructions that say "retrieve this pixel, now retrieve the next pixel" (where n is a number that varies from design to design). This can take far less time than obtaining each pixel individually, as in a standard CPU design, for a variety of reasons.
Another benefit is that the instruction performs a single operation on all supplied data. To put it another way, if the SIMD system works by loading eight data points at once, the data add operation will affect all eight values at the same time. This parallelism is distinct from that offered by a superscalar processor; even on a non-superscalar processor, the eight values are processed in parallel, and a superscalar processor may be able to conduct many SIMD operations in parallel.
Q7) Write the disadvantages of SIMD?
A7) Benefits, the disadvantages of SIMD when employed for general-purpose computing cannot be overstated.
● Not all algorithms are easily vectorized. A flow-control-heavy operation like code parsing, for example, may not profit from SIMD; nonetheless, it is theoretically conceivable to vectorize comparisons and "batch flow" to achieve maximum cache optimality, but this strategy will necessitate additional intermediate state. Note that batch-pipeline systems (for example, GPUs or software rasterization pipelines) are best for cache control when built with SIMD intrinsics, although SIMD intrinsics are not required. Further complexity may appear to avoid reliance within series, such as code strings, although vectorization necessitates independence.
● Large register files increase power consumption and chip area requirements.
● Currently, most compilers do not produce SIMD instructions from a typical C program; for example, most compilers do not create SIMD instructions from a typical C program. In computer science, automatic vectorization in compilers is a hot topic.
Q8) Write about MIMD?
A8) Multiple Instruction and Multiple Data Stream' is the acronym for MIMD.
All processors of a parallel computer can execute distinct instructions and act on different data at the same time in this configuration.
Each processor in MIMD has its own program, and each program generates an instruction stream.
The MIMD architecture consists of a group of N tightly connected processors. Each CPU has memory that is shared by all processors but cannot be accessed directly by other processors.
The processors of the MIMD architecture work independently and asynchronously. Various processors may be performing various instructions on various pieces of data at any given time.
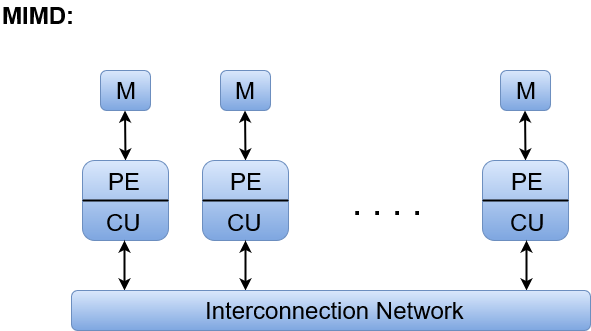
Fig 4: MIMD
Where, M = Memory Module, PE = Processing Element, and CU = Control Unit
Shared Memory MIMD architecture and Distributed Memory MIMD architecture are the two forms of MIMD architecture.
Q9) Write about shared memory architecture?
A9) Memories that shared MIMD architectural features include
● The creation of a cluster of memory modules and CPUs.
● Through an interconnectivity network, any CPU can access any memory module directly.
● The collection of memory modules defines a common universal address space for the CPUs.
The three most common shared memory multiprocessors models are −
Uniform Memory Access (UMA)
In this model, all the processors share the physical memory uniformly. All the processors have equal access time to all the memory words. Each processor may have a private cache memory. Same rule is followed for peripheral devices.
When all the processors have equal access to all the peripheral devices, the system is called a symmetric multiprocessor. When only one or a few processors can access the peripheral devices, the system is called an asymmetric multiprocessor.
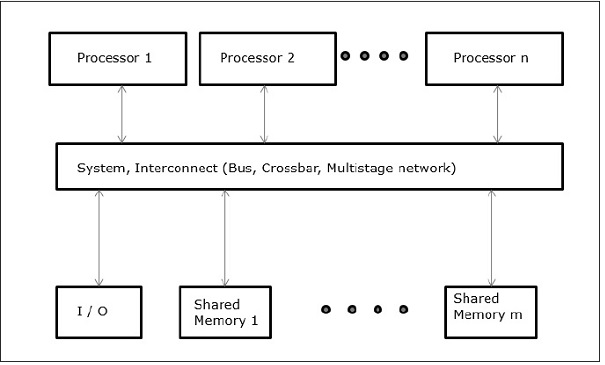
Fig 5: Uniform Memory Access
Non-uniform Memory Access (NUMA)
In the NUMA multiprocessor model, the access time varies with the location of the memory word. Here, the shared memory is physically distributed among all the processors, called local memories. The collection of all local memories forms a global address space that can be accessed by all the processors.
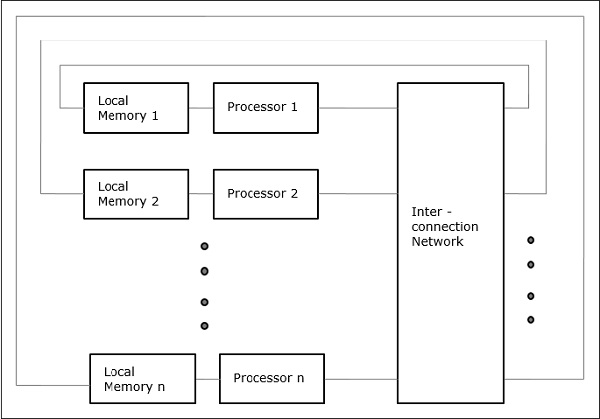
Fig 6: Non-uniform Memory Access
Cache Only Memory Architecture (COMA)
The COMA model is a special case of the NUMA model. Here, all the distributed main memories are converted to cache memories.
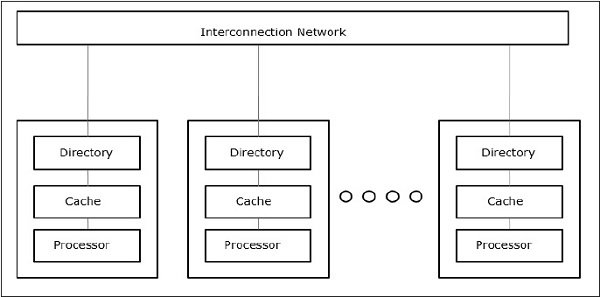
Fig 7: Cache Only Memory Architecture
Q10) Distributed memory multicomputer?
A10) A distributed memory multicomputer system consists of multiple computers, known as nodes, interconnected by a message-passing network. Each node acts as an autonomous computer having a processor, local memory, and sometimes I/O devices. In this case, all local memories are private and are accessible only to the local processors. This is why the traditional machines are called no-remote-memory-access (NORMA) machines.
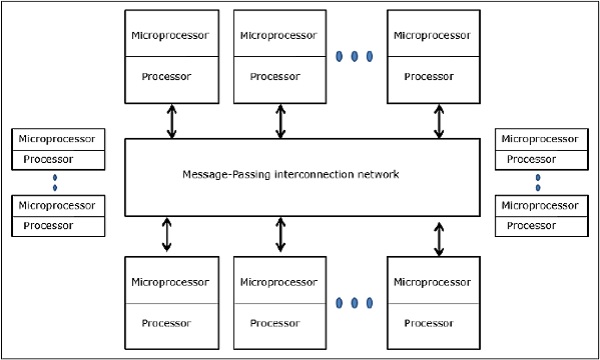
Fig 8: Distributed - Memory Multi-computers
Q11) Describe vector architecture?
A11) Vector architecture entails adding instruction set extensions to an ISA to enable highly pipelined vector operations.
Vector registers, which are a xed-length bank of registers, are used for vector operations.
Between a vector register and the memory system, data is exchanged.
Vector registers or a vector register and a scalar value are used as input for each vector operation.
Only applications with considerable data level parallelism can benefit from vector architecture (DLP). The benefits of vector processing considerably lower the dynamic instruction bandwidth. In general, execution time is lowered as a result of
(1) Eliminating loop overhead
(2) Stalls occuring only on the first vector element rather than on each vector member
(3) Vector operations being performed in parallel
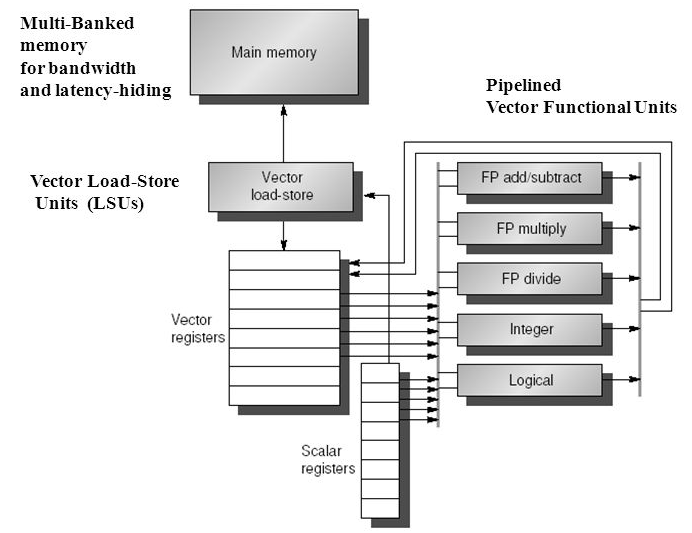
Fig 9: Vector architecture
Basic idea:
● Read sets of data elements into “vector registers”
● Operate on those registers
● Disperse the results back into memory
Registers are controlled by compiler
● Register files act as compiler controlled buffers
● Used to hide memory latency
● Leverage memory bandwidth
Vector loads/stores deeply pipelined
● Pay for memory latency once per vector load/store
Regular loads/stores
● Pay for memory latency for each vector element
Components of vector architecture
Vector register
● Each register hold a 64 element 64 bits per element vector
● register file has 16 read ports and 8 write ports
Vector functional units
● Fully pipelined
● Data and control hazard are detected
Vector load - store unit
● Fully pipelined
● Words move between register
● One word per clock cycle after initial latency
Scalar register
● 32 general purpose registers
● 32 floating point registers
Vector Supercomputers
In a vector computer, a vector processor is attached to the scalar processor as an optional feature. The host computer first loads program and data to the main memory. Then the scalar control unit decodes all the instructions. If the decoded instructions are scalar operations or program operations, the scalar processor executes those operations using scalar functional pipelines.
On the other hand, if the decoded instructions are vector operations then the instructions will be sent to the vector control unit.
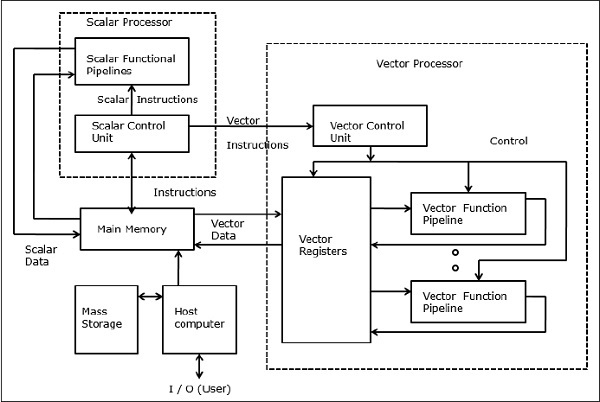
Fig 10: Vector Supercomputers
Q12) Describe Multicore architecture
CPUs used to have only one heart. This meant that the actual CPU only had one central processing unit. Manufacturers add more "cores," or central processing units, to boost performance. Since a dual-core CPU has two central processing units, the operating system sees it as two CPUs. For example, a CPU with two cores might run two separate processes at the same time. Since your machine can do many tasks at once, this speeds up your system.
There are no tricks here, unlike hyper-threading: a dual - core CPU has two central processing units on the same chip. A quad - core CPU has four central processing units, while an octa- core CPU has eight. This improves performance significantly while keeping the physical CPU unit small enough to fit in a single socket. There should only be one CPU socket with one CPU unit inserted into it, rather than four CPU sockets with four different CPUs, each requiring its own power, cooling, and other hardware. Since the cores are all on the same chip, they can interact more easily, resulting in less latency.
The Task Manager in Windows is a good example of this. You will see that this machine has one real CPU (socket) and four cores, for example. Because of hyper-threading, each core appears to the operating system as two CPUs, resulting in eight logical processors.
Multicore designs, which consist of a number of processing cores, are used in modern microprocessors. Each core typically has its own instruction and data memory (L1 caches), with all cores sharing a second level (L2) on-chip cache. Figure 1 shows a block diagram of a typical multicore (in this example, quad-core) CPU computing system with an L2 cache shared by all cores. The CPU is also linked to external memory and has link controllers for interacting with other system components.
However, there are multicore architectures in which a subset of cores shares a single L2 cache (e.g., each L2 cache is shared by two cores in a quad-core, or is shared by four cores in an octa-core CPU). This is a common occurrence in computer systems with several memory tiers. External memories are frequently organized in numerous tiers and employ a variety of storage technologies. The first level is usually structured using SRAM devices, whereas the second level is usually organized using DDRAMs.
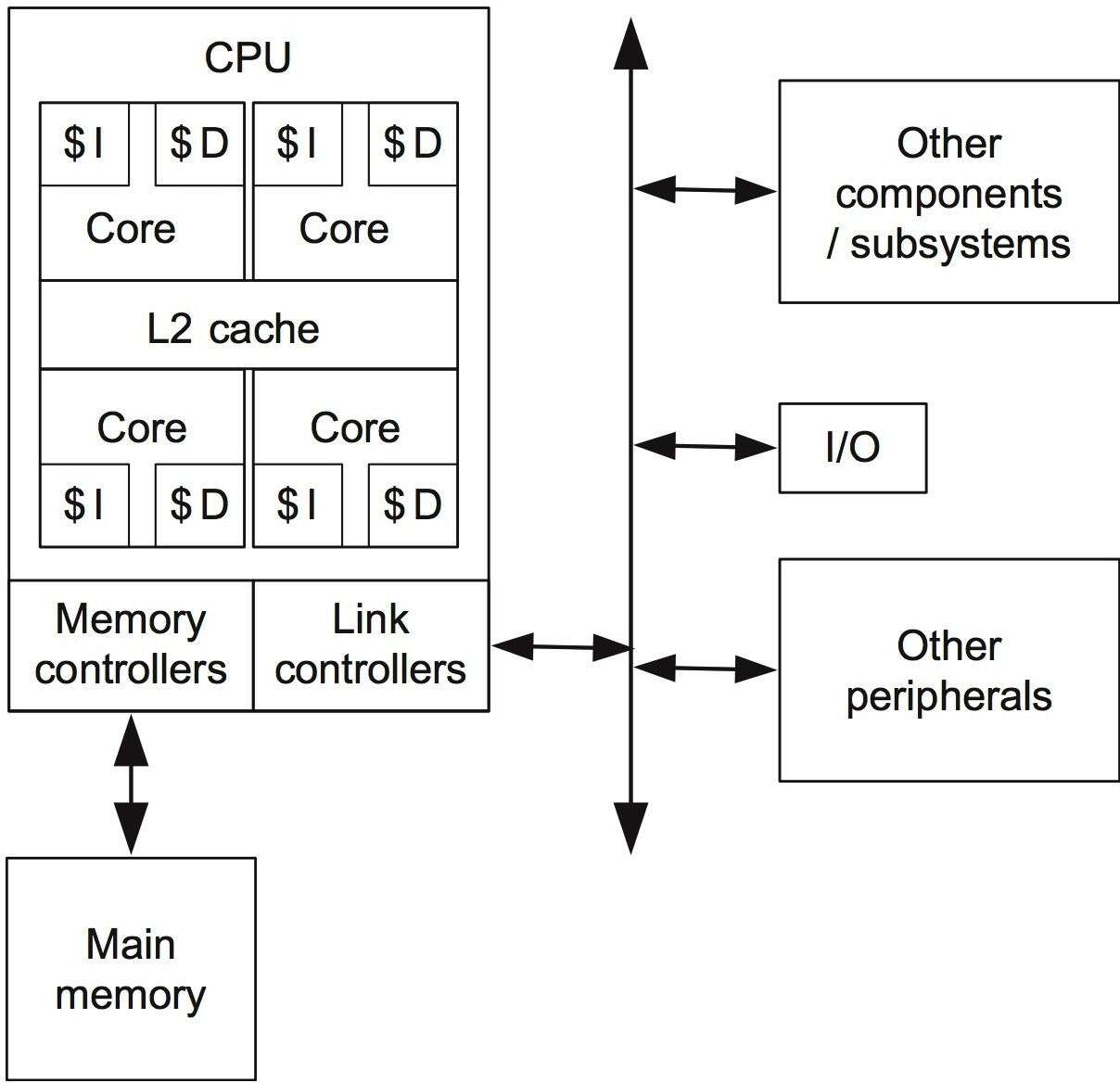
Fig 11: Block diagram of a typical multicore architecture
Q13) Which protocol is more suited for distributed shared memory architecture with a large number of processors. Why?
A13) The protocols to maintain coherence for multiple processors are called cache coherence protocols. Key to implementing a cache coherence protocol is tracking the state of any sharing of a data block. There are two classes of protocols, which use different techniques to track the sharing status, in use:
- Directory based—The sharing status of a block of physical memory is kept in just one location, called the directory; Directory-based coherence has slightly higher implementation overhead than snooping, but it can scale to larger processor counts. The Sun Tl design uses directories, albeit with a central physical memory.
- Snooping—Every cache that has a copy of the data from a block of physical memory also has a copy of the sharing status of the block, but no centralized state is kept. The caches are all accessible via some broadcast medium (a bus or switch), and all cache controllers monitor or snoop on the medium to determine whether or not they have a copy of a block that is requested on a bus or switch access.
Q14) What are the advantages of multithreading?
A14) If a thread cannot use all the computing resources of the CPU (because instructions depend on each other's result), running another thread permits to not leave these idle. If several threads work on the same set of data, they can actually share its caching, leading to better cache usage or synchronization on its values.
If a thread gets a lot of cache misses, the other thread(s) can continue, taking advantage of the unused computing resources, which thus can lead to faster overall execution, as these resources would have been idle if only a single thread was executed.
Q15) Write the difference between SIMD and MIMD?
A15) Difference between SIMD and MIMD
BASIS FOR COMPARISON | SIMD | MIMD |
Expands to | Single Instruction Multiple Data | Multiple Instruction Multiple Data |
Memory requirements | Smaller | Larger |
Programming and debugging | Synchronous | Asynchronous |
Number of decoders | Single | Multiple |
Cost | Low | Medium |
Performance and complexity | Simple architecture and moderate performance | Complex and performs efficiently |
Synchronization | Implicit | Explicit |
Q16) Write the advantages of MIMD?
A16) Advantages of MIMD
● Provides high flexibility by employing multiple threads of control.
● Facilitates efficient execution of the conditional statements (i.e., if-then-else) because the processor is independent and can follow any random decision path.
● The asynchronous property of MIMD can speed up the execution rate of instructions which take an indefinite amount of time.
● Does not require additional CU and hence do not have supplementary cost




