Unit - 3
Introduction of Big data and Hadoop Ecosystem
Q1) Define Big Data.
A1)
- Big Data is a collection of data that is huge in volume, yet growing exponentially with time. It is a data with so large size and complexity that none of traditional data management tools can store it or process it efficiently. Big data is also a data but with huge size.
2. Big data refers to the large, diverse sets of information that grow at ever-increasing rates. It encompasses the volume of information, the velocity or speed at which it is created and collected, and the variety or scope of the data points being covered (known as the "three v's" of big data). Big data often comes from data mining and arrives in multiple formats.
Q2) Explain the Elements of big data
A2)
- Culture: -
a) The ability to make data-driven decisions and implement enduring change across the organization is arguably the most important benefit of using big data and advanced analytics.
b) But in many instances, brilliant analytical insights cannot be transformed into business improvement because the organization is unable to incorporate them into process and behavior changes.
2. Expectations: -
a) The organization must have consistent expectations for its use of analytics to explain performance and facilitate decision-making.
b) There must be a shared vision of the insights that big data and analytics will yield and how they will impact decision-making.
3. Process: -
The organization must have processes for analysis and reporting, as well as an engagement model for helping transform business problems and managing analytics efforts that benefit the business.
4. Skills and tools: -
a) With the proliferation of systems and applications, organizations can easily acquire new technology before they are ready to use it.
b) In addition to a technology infrastructure, the organization must have employees with adequate skills to use the tools and interpret the results.
c) In the world of big data, these skills are not likely to reside in the marketing organization; they may exist in pockets across the company or in a centralized analytics function.
5. Data: -
a) Big or small, structured or unstructured, data fuels analytics efforts, and it requires an underlying infrastructure to support it.
b) Developing this infrastructure is often a significant challenge, because advanced analysis requires internal data from repositories across marketing, sales, services, training and finance, as well as external data from social media and other sources.
c) IT and marketing must work together with the same set of priorities to ensure that the data infrastructure is in place.
d) The promise of big data and analytics – and the insights they bring to light – are compelling. But it takes more than technology to transform insights into true business performance improvement.
e) For an organization to benefit from the much-hyped big data, it must have realistic expectations, obtain the resources to make it work, and be prepared to implement the changes that the insights indicate are needed.
Q3) State working of big data analytics?
A3)
- Big data analytics is the often-complex process of examining big data to uncover information -- such as hidden patterns, correlations, market trends and customer preferences -- that can help organizations make informed business decisions.
2. On a broad scale, data analytics technologies and techniques provide a means to analyze data sets and take away new information—which can help organizations make informed business decisions.
3. Business intelligence (BI) queries answer basic questions about business operations and performance.
4. Big data analytics is a form of advanced analytics, which involve complex applications with elements such as predictive models, statistical algorithms and what-if analysis powered by analytics systems.
5. In some cases, Hadoop clusters and NoSQL systems are used primarily as landing pads and staging areas for data.
6. This is before it gets loaded into a data warehouse or analytical database for analysis -- usually in a summarized form that is more conducive to relational structures.
7. More frequently, however, big data analytics users are adopting the concept of a Hadoop data lake that serves as the primary repository for incoming streams of raw data.
8. In such architectures, data can be analyzed directly in a Hadoop cluster or run through a processing engine like Spark. As in data warehousing, sound data management is a crucial first step in the big data analytics process.
9. Data being stored in the HDFS must be organized, configured and partitioned properly to get good performance out of both extract, transform and load (ETL) integration jobs and analytical queries.
10. Once the data is ready, it can be analyzed with the software commonly used for advanced analytics processes. That includes tools for:
a) data mining, which sift through data sets in search of patterns and relationships;
b) predictive analytics, which build models to forecast customer behavior and other future developments;
c) machine learning, which taps algorithms to analyze large data sets; and
d) deep learning, a more advanced offshoot of machine learning.
Q4) Explain the importance of big data analytics.
A4)
Big data analytics through specialized systems and software can lead to positive business-related outcomes:
- New revenue opportunities
2. More effective marketing
3. Better customer service
4. Improved operational efficiency
5. Competitive advantages over rivals
6. Big data analytics applications allow data analysts, data scientists, predictive modelers, statisticians and other analytics professionals to analyze growing volumes of structured transaction data, plus other forms of data that are often left untapped by conventional BI and analytics programs.
7. This includes a mix of semi-structured and unstructured data.
8. For example, internet clickstream data, web server logs, social media content, text from customer emails and survey responses, mobile phone records, and machine data captured by sensors connected to the internet of things (IoT).
Q5) What are the uses of big data analytics?
A5)
- Big data analytics applications often include data from both internal systems and external sources, such as weather data or demographic data on consumers compiled by third-party information services providers.
2. In addition, streaming analytics applications are becoming common in big data environments as users look to perform real-time analytics on data fed into Hadoop systems through stream processing engines, such as Spark, Flink and Storm.
3. Early big data systems were mostly deployed on premises, particularly in large organizations that collected, organized and analyzed massive amounts of data.
4. But cloud platform vendors, such as Amazon Web Services (AWS) and Microsoft, have made it easier to set up and manage Hadoop clusters in the cloud.
5. The same goes for Hadoop suppliers such as Cloudera-Hortonworks, which supports the distribution of the big data framework on the AWS and Microsoft Azure clouds.
Q6) Explain Big Data Stack.
A6)
- The first step in the process is getting the data. We need to ingest big data and then store it in data stores (SQL or No SQL).
2. Once data has been ingested, after noise reduction and cleansing, big data is stored for processing.
3. There are two types of data processing, Map Reduce and Real Time.
4. Scripting languages are needed to access data or to start the processing of data. After processing, the data can be used in various fields. It may be used for analysis, machine learning, and can be presented in graphs and charts.
5. Earlier Approach – When this problem came to existence, Google™ tried to solve it by introducing GFS and Map Reduce process
6. These two are based on distributed file systems and parallel processing. The framework was very successful. Hadoop is an open source implementation of the MapReduce framework.
Q7) What are the big data virtualizations Applications?
A7)
- Application infrastructure virtualization provides an efficient way to manage applications in context with customer demand.
2. The application is encapsulated in a way that removes its dependencies from the underlying physical computer system. This helps to improve the overall manageability and portability of the application.
3. In addition, the application infrastructure virtualization software typically allows for codifying business and technical usage policies to make sure that each of your applications leverages virtual and physical resources in a predictable way.
4. Efficiencies are gained because you can more easily distribute IT resources according to the relative business value of your applications.
5. Application infrastructure virtualization used in combination with server virtualization can help to ensure that business service-level agreements are met. Server virtualization monitors CPU and memory usage, but does not account for variations in business priority when allocating resources.
Q8) What are the virtualization Approaches.
A8)
- While virtualization has been a part of the IT landscape for decades, it is only recently (in 1998) that VMware delivered the benefits of virtualization to industry-standard x86-based platforms, which now form the majority of desktop, laptop and server shipments.
2. A key benefit of virtualization is the ability to run multiple operating systems on a single physical system and share the underlying hardware resources – known as partitioning.
3. Today, virtualization can apply to a range of system layers, including hardware-level virtualization, operating system-level virtualization, and high-level language virtual machines.
4. Hardware-level virtualization was pioneered on IBM mainframes in the 1970s, and then more recently Unix/RISC system vendors began with hardware-based partitioning capabilities before moving on to software-based partitioning.
5. For Unix/RISC and industry-standard x86 systems, the two approaches typically used with software-based partitioning are hosted and hypervisor architectures).
6. A hosted approach provides partitioning services on top of a standard operating system and supports the broadest range of hardware configurations.
7. In contrast, hypervisor architecture is the first architecture is the first layer of software installed on a clean x86-based system (hence it is often referred to as a “bare metal” approach).
8. Since it has direct access to the hardware resources, a hypervisor is more efficient than hosted architectures, enabling greater scalability.
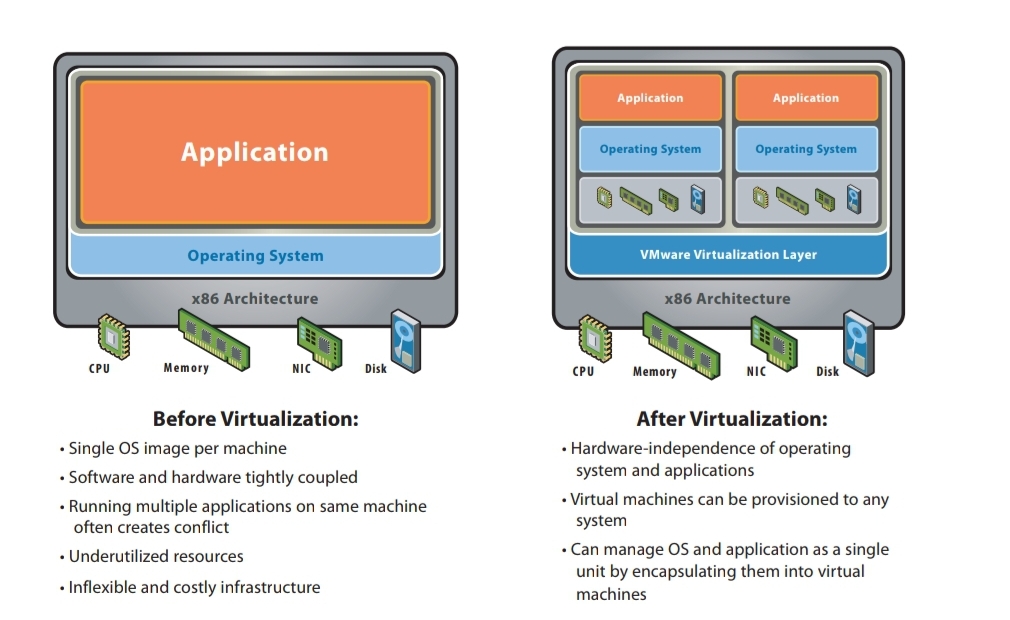
Figure 1: Data Visualization
Q9) Explain Hadoop Ecosystem.
A9)
- Hadoop Ecosystem is a platform or a suite which provides various services to solve the big data problems. It includes Apache projects and various commercial tools and solutions.
2. There are four major elements of Hadoop i.e. HDFS, MapReduce, YARN, and Hadoop Common. Most of the tools or solutions are used to supplement or support these major elements.
3. All these tools work collectively to provide services such as absorption, analysis, storage and maintenance of data etc.
4. Following are the components that collectively form a Hadoop ecosystem:
- HDFS: Hadoop Distributed File System
- YARN: Yet Another Resource Negotiator
- MapReduce: Programming based Data Processing
- Spark: In-Memory data processing
- PIG, HIVE: Query based processing of data services
- HBase: NoSQL Database
- Mahout, Spark MLLib : Machine Learning algorithm libraries
- Solar, Lucene: Searching and Indexing
- Zookeeper: Managing cluster
- Oozie: Job Scheduling
Q10) Explain the working of oozie.
A10)
- Oozie runs as a service in the cluster and clients submit workflow definitions for immediate or later processing.
2. Oozie workflow consists of action nodes and control-flow nodes.
3. An action node represents a workflow task, e.g., moving files into HDFS, running a MapReduce, Pig or Hive jobs, importing data using Sqoop or running a shell script of a program written in Java.
4. A control-flow node controls the workflow execution between actions by allowing constructs like conditional logic wherein different branches may be followed depending on the result of earlier action node.
5. Start Node, End Node, and Error Node fall under this category of nodes.
6. Start Node, designates the start of the workflow job.
7. End Node, signals end of the job.
8. Error Node designates the occurrence of an error and corresponding error message to be printed.
9. At the end of execution of a workflow, HTTP callback is used by Oozie to update the client with the workflow status. Entry-to or exit from an action node may also trigger the callback.
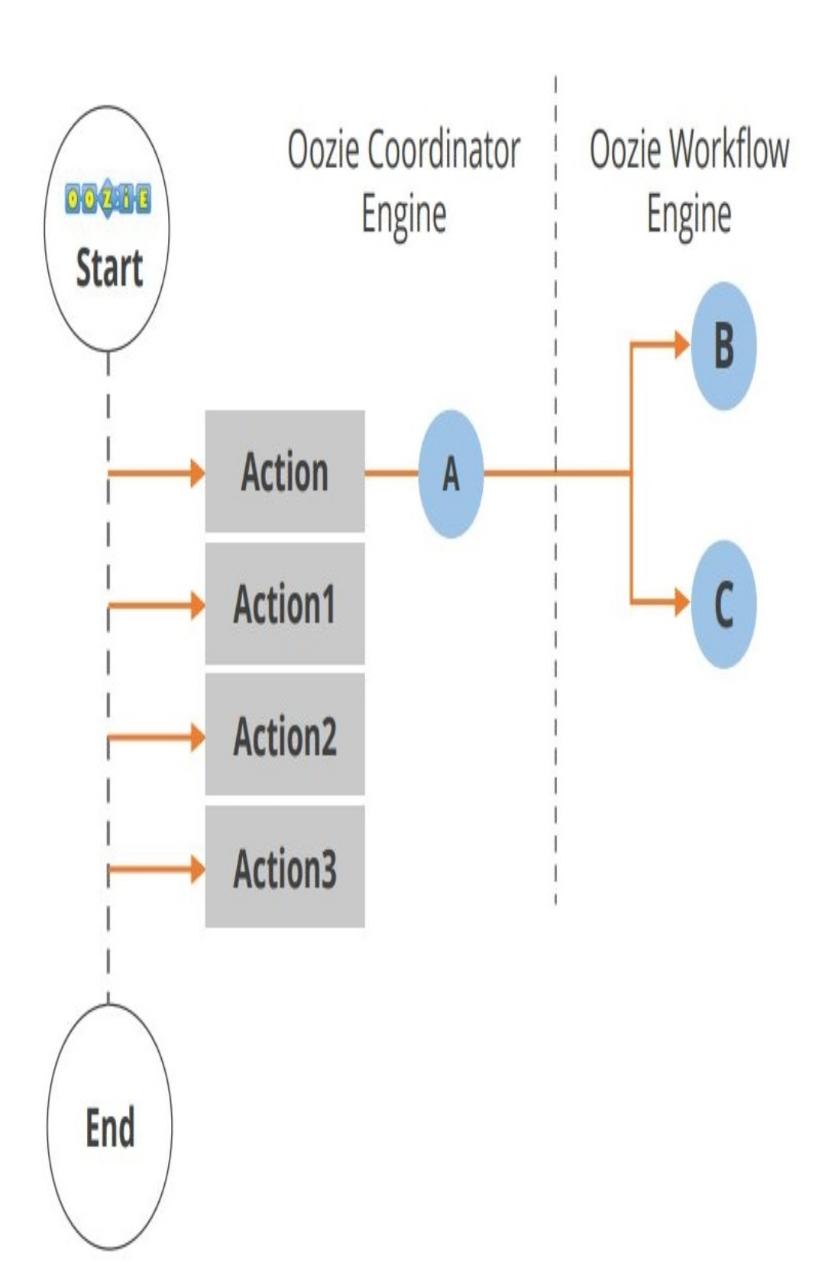
Figure 2: Oozie
Q11) What are the Features of flume?
A11)
- Flume has a flexible design based upon streaming data flows. It is fault tolerant and robust with multiple failovers and recovery mechanisms. Flume Big data has different levels of reliability to offer which includes 'best-effort delivery' and an 'end-to-end delivery'.
2. Best-effort delivery does not tolerate any Flume node failure whereas 'end-to-end delivery' mode guarantees delivery even in the event of multiple node failures.
3. Flume carries data between sources and sinks. This gathering of data can either be scheduled or event-driven. Flume has its own query processing engine which makes it easy to transform each new batch of data before it is moved to the intended sink.
4. Possible Flume sinks include HDFS and HBase. Flume Hadoop can also be used to transport event data including but not limited to network traffic data, data generated by social media websites and email messages.
Q12) Explain Zookeeper in detail.
A12)
- There was a huge issue of management of coordination and synchronization among the resources or the components of Hadoop which resulted in inconsistency, often.
2. Zookeeper overcame all the problems by performing synchronization, inter-component-based communication, grouping, and maintenance.
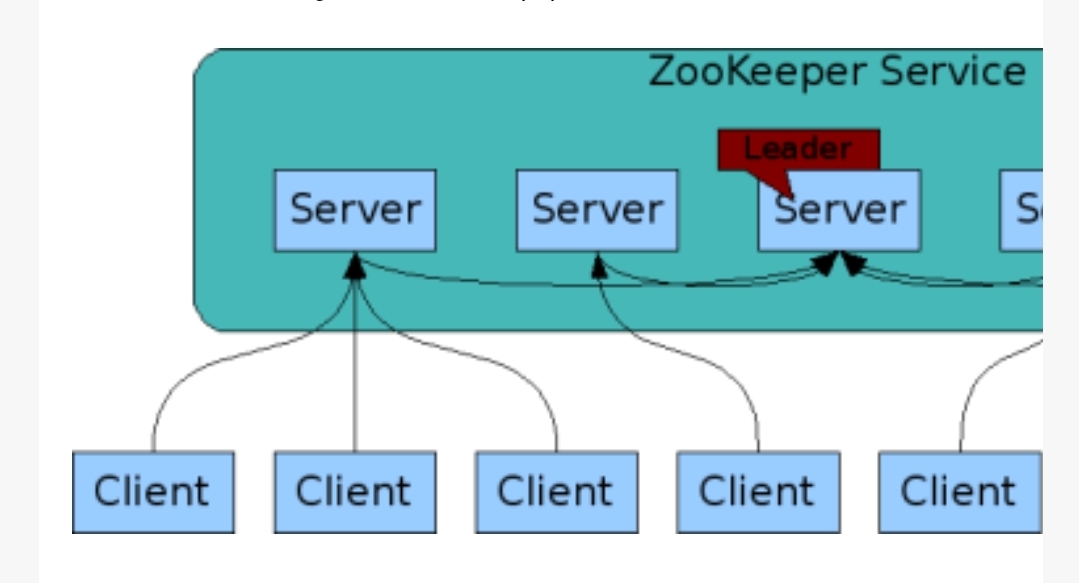
Figure 3: Zookeeper
3. Benefits of Zookeeper:
Zookeeper provides a very simple interface and services. Zookeeper brings these key benefits:
- Fast. Zookeeper is especially fast with workloads where reads to the data are more common than writes. The ideal read/write ratio is about 10:1.
2. Reliable. Zookeeper is replicated over a set of hosts (called an ensemble) and the servers are aware of each other. As long as a critical mass of servers is available, the Zookeeper service will also be available. There is no single point of failure.
3. Simple. Zookeeper maintains a standard hierarchical name space, similar to files and directories.
4. Ordered. The service maintains a record of all transactions, which can be used for higher-level abstractions, like synchronization primitives.
Q13) Explain Storage mechanism in HBase
A13)
HBase is a column-oriented database and the tables in it are sorted by row. The table schema defines only column families, which are the key value pairs.
A table have multiple column families and each column family can have any number of columns. Subsequent column values are stored contiguously on the disk. Each cell value of the table has a timestamp. In short, in an HBase:
a) Table is a collection of rows.
b) Row is a collection of column families.
c) Column family is a collection of columns.
d) Column is a collection of key value pairs.
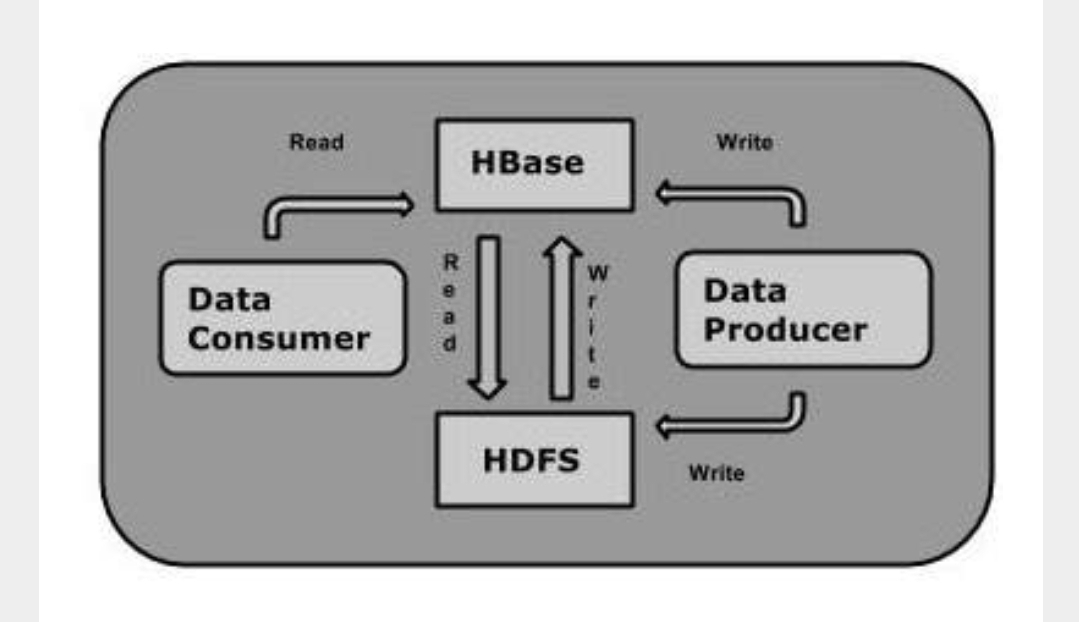
Figure 4: HBase




