UNIT-5
Association Rules and Clustering
Q1) Explain the structure of Association Rule.
A1)
- Association rule mining finds interesting associations and relationships among large sets of data items. This rule shows how frequently a itemset occurs in a transaction. A typical example is Market Based Analysis.
2. Market Based Analysis is one of the key techniques used by large relations to show associations between items. It allows retailers to identify relationships between the items that people buy together frequently.
3. Given a set of transactions, we can find rules that will predict the occurrence of an item based on the occurrences of other items in the transaction.
TID | ITEAMs |
1 | Bread, Milk |
2 | Bread, Diaper, Beer, Eggs |
3 | Milk, Diaper, Beer, Coke |
4 | Bread, Milk, Diaper, Beer |
5 | Bread, Milk, Diaper, Coke |
4. Support Count (): – Frequency of occurrence of an itemset.
Here ({Milk, Bread, Diaper}) =2
5. Frequent Itemset: – An itemset whose support is greater than or equal to minsup threshold.
6. Association Rule: – An implication expression of the form X -> Y, where X and Y are any 2 item sets.
Example: {Milk, Diaper}->{Beer}
Q2) Explain Apriori Algorithm.
A2)
- Apriori is the best-known algorithm to mine association rules. It uses a breadth-first search strategy to count the support of item sets and uses a candidate generation function which exploits the downward closure property of support.
2. Apriori is a classic algorithm for learning association rules. Apriori is designed to operate on databases containing transactions (for example, collections of items bought by customers, or details of a website frequentation).
3. Other algorithms are designed for finding association rules in data having no transactions (Winepi and Minepi), or having no timestamps (DNA sequencing).
4. As is common in association rule mining, given a set of itemsets (for instance, sets of retail transactions, each listing individual items purchased), the algorithm attempts to find subsets which are common to at least a minimum number C of the item sets.
5. Apriori uses a “bottom up” approach, where frequent subsets are extended one item at a time (a step known as candidate generation), and groups of candidates are tested against the data.
6. The algorithm terminates when no further successful extensions are found.
7. The purpose of the Apriori Algorithm is to find associations between different sets of data. It is sometimes referred to as “Market Basket Analysis”. Each set of data has a number of items and is called a transaction.
8. The output of Apriori is sets of rules that tell us how often items are contained in sets of data. Here is an example
9. Each line is a set of time
Create table:
Alpha | Beta | Gamma |
Alpha | Beta | Theta |
Alpha | Beta | Epsilon |
Alpha | Beta | Theta |
10. Apriori, while historically significant, suffers from a number of inefficiencies or trade-offs, which have spawned other algorithms.
11. Candidate generation generates large numbers of subsets (the algorithm attempts to load up the candidate set with as many as possible before each scan).
12. Bottom-up subset exploration (essentially a breadth-first traversal of the subset lattice) finds any maximal subset S only after all 2(rais to s)-1 of its proper
Q3) Note on General Association rule
A3)
- Association rule mining finds interesting associations and relationships among large sets of data items. This rule shows how frequently a itemset occurs in a transaction. A typical example is Market Based Analysis.
2. Association rules are usually required to satisfy a user-specified minimum support and a user-specified minimum confidence at the same time. Association rule generation is usually split up into two separate steps
3. A minimum support threshold is applied to find all frequent itemsets in a database.
4. A minimum confidence constraint is applied to these frequent itemsets in order to form rules.
5. While the second step is straightforward, the first step needs more attention.
6. Finding all frequent itemsets in a database is difficult since it involves searching all possible itemsets (item combinations).
7. The set of possible itemsets is the powerset over and has size (excluding the empty set which is not a valid itemset).
8. Although the size of the power-set grows exponentially in the number of items in , efficient search is possible using the downward-closure property of support (also called anti-monotonicity) which guarantees that for a frequent itemset, all its subsets are also frequent and thus no infrequent itemset can be a subset of a frequent itemset.
9. Exploiting this property, efficient algorithms (e.g., Apriori\and Eclat) can find all frequent itemsets.
Q4) What is Clustering?
A4)
- Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group than those in other groups.
2. In simple words, the aim is to segregate groups with similar traits and assign them into clusters.
3. Let’s understand this with an example. Suppose, you are the head of a rental store and wish to understand preferences of your costumers to scale up your business.
4. Is it possible for you to look at details of each costumer and devise a unique business strategy for each one of them? Definitely not.
5. But, what you can do is to cluster all of your costumers into say 10 groups based on their purchasing habits and use a separate strategy for costumers in each of these 10 groups. And this is what we call clustering.
Q5) Explain Clustering Method.
A5)
Broadly speaking, clustering can be divided into two subgroups:
- Hard Clustering: -
In hard clustering, each data point either belongs to a cluster completely or not. For example, in the above example each customer is put into one group out of the 10 groups.
2. Soft Clustering:
In soft clustering, instead of putting each data point into a separate cluster, a probability or likelihood of that data point to be in those clusters is assigned. For example, from the above scenario each costumer is assigned a probability to be in either of 10 clusters of the retail store.
Q6) Explain type of clustering algorithms.
A6)
Since the task of clustering is subjective, the means that can be used for achieving this goal are plenty. Every methodology follows a different set of rules for defining the ‘similarity’ among data points. In fact, there are more than 100 clustering algorithms known. But few of the algorithms are used popularly, let’s look at them in detail:
- Connectivity models: -
a) As the name suggests, these models are based on the notion that the data points closer in data space exhibit more similarity to each other than the data points lying farther away.
b) These models can follow two approaches. In the first approach, they start with classifying all data points into separate clusters & then aggregating them as the distance decreases.
c) In the second approach, all data points are classified as a single cluster and then partitioned as the distance increases. Also, the choice of distance function is subjective.
d) These models are very easy to interpret but lacks scalability for handling big datasets. Examples of these models are hierarchical clustering algorithm and its variants.
2. Centroid models: -
a) These are iterative clustering algorithms in which the notion of similarity is derived by the closeness of a data point to the centroid of the clusters.
b) K-Means clustering algorithm is a popular algorithm that falls into this category.
c) In these models, the no. Of clusters required at the end have to be mentioned beforehand, which makes it important to have prior knowledge of the dataset. These models run iteratively to find the local optima.
3. Distribution models: -
a) These clustering models are based on the notion of how probable is it that all data points in the cluster belong to the same distribution (For example: Normal, Gaussian).
b) These models often suffer from overfitting. A popular example of these models is Expectation-maximization algorithm which uses multivariate normal distributions.
4. Density Models: -
a) These models search the data space for areas of varied density of data points in the data space.
b) It isolates various different density regions and assign the data points within these regions in the same cluster. Popular examples of density models are DBSCAN and OPTICS.
Q7) What is Partitioning Clustering?
A7)
- In this method, let us say that “m” partition is done on the “p” objects of the database. A cluster will be represented by each partition and m < p. K is the number of groups after the classification of objects. There are some requirements which need to be satisfied with this.
2. Partitioning Clustering Method are: –
a) One objective should only belong to only one group.
b) There should be no group without even a single purpose.
3. There are some points which should be remembered in this type of Partitioning Clustering Method which are:
a) There will be an initial partitioning if we already give no. Of a partition (say m).
b) There is one technique called iterative relocation, which means the object will be moved from one group to another to improve the partitioning.
Q8) What is Hierarchical Clustering?
A8)
- A Hierarchical clustering method works via grouping data into a tree of clusters. Hierarchical clustering begins by treating every data point as a separate cluster. Then, it repeatedly executes the subsequent steps:
2. Identify the 2 clusters which can be closest together, and
3. Merge the 2 maximum comparable clusters. We need to continue these steps until all the clusters are merged together.
4. In Hierarchical Clustering, the aim is to produce a hierarchical series of nested clusters.
5. A diagram called Dendrogram (A Dendrogram is a tree-like diagram that statistics the sequences of merges or splits) graphically represents this hierarchy and is an inverted tree that describes the order in which factors are merged (bottom-up view) or cluster are break up (top-down view).
Q9) What are steps of Agglomerative with the help of diagram?
A9)
- Initially consider every data point as an individual Cluster and at every step, merge the nearest pairs of the cluster. (It is a bottom-up method).
2. At first every data set is considered as individual entity or cluster. At every iteration, the clusters merge with different clusters until one cluster is formed.
3. Algorithm for Agglomerative Hierarchical Clustering is:
- Calculate the similarity of one cluster with all the other clusters (calculate proximity matrix)
- Consider every data point as a individual cluster
- Merge the clusters which are highly similar or close to each other.
- Recalculate the proximity
- Matrix for each cluster
- Repeat Step 3 and 4 until only a single cluster remains.
- Let’s see the graphical representation of this algorithm using a dendrogram.
Note: -
This is just a demonstration of how the actual algorithm works no calculation has been performed below all the proximity among the clusters are assumed.
Let’s say we have six data points A, B, C, D, E, F.
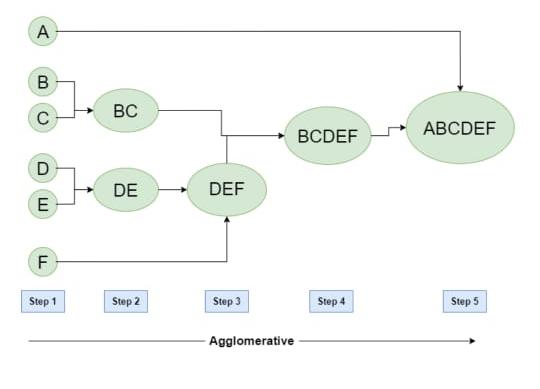
Fig 1: Example of Agglomerative
• Step-1: -
Consider each alphabet as a single cluster and calculate the distance of one cluster from all the other clusters.
• Step-2: -
In the second step comparable clusters are merged together to form a single cluster. Let’s say cluster (B) and cluster (C) are very similar to each other therefore we merge them in the second step similarly with cluster (D) and (E) and at last, we get the clusters
[(A), (BC), (DE), (F)]
• Step-3: -
We recalculate the proximity according to the algorithm and merge the two nearest clusters ([(DE), (F)]) together to form new clusters as [(A), (BC), (DEF)]
• Step-4: -
Repeating the same process; the clusters DEF and BC are comparable and merged together to form a new cluster. We’re now left with clusters [(A), (BCDEF)].
• Step-5: -
At last, the two remaining clusters are merged together to form a single cluster [(ABCDEF)].
Q10) Explain Rule Evaluation Metrics and its Example.
A10)
- Support(s): –
The number of transactions that include items in the {X} and {Y} parts of the rule as a percentage of the total number of transactions. It is a measure of how frequently the collection of items occurs together as a percentage of all transactions.
Support = sigma (X+Y) /total
It is interpreted as fraction of transactions that contain both X and Y.
2. Confidence(c): -
It is the ratio of the no of transactions that includes all items in {B} as well as the no of transactions that includes all items in {A} to the no of transactions that includes all items in {A}.
Conf(X=>Y) = Supp (XUY)÷Supp(X) –
It measures how often each item in Y appears in transactions that contains items in X also.
3. Lift(l): –
The lift of the rule X=>Y is the confidence of the rule divided by the expected confidence, assuming that the itemsets X and Y are independent of each other.The expected confidence is the confidence divided by the frequency of {Y}.
Lift(X=>Y) = Conf(X=>Y) Supp(Y) –
Lift value near 1 indicates X and Y almost often appear together as expected, greater than 1 means they appear together more than expected and less than 1 means they appear less than expected. Greater lift values indicate stronger association.
Example – From the above table, {Milk, Diaper} => {Beer}
The Association rule is very useful in analyzing datasets. The data is collected using bar-code scanners in supermarkets. Such database consists of a large number of transaction records which list all items bought by a customer on a single purchase.
So the manager could know if certain groups of items are consistently purchased together and use this data for adjusting store layouts, cross-selling, promotions based on statistics.




