MODULE 1
Introduction
Data : Data are simply values or set of values
Data Items : It refers to single unit of values.
Data items are divided into sub-items called Group items.
Ex: Employee Name may be divided into three subitems
First name, Middle name , Last name.
Data items that are not further divided into sub items are called Elementary items.
Entity: An entity is something that has attributes or properties which may be assigned values. The values may be numeric or non-numeric.
Ex: Attributes Names Age Sex SSN
Values Rohland Gail 34 F 134-34-5533
Entities with similar attributes form entity set. Each attribute of an entity set has range of values the set of all possible values that could be assigned to particular attribute.
Field : is a single elementary unit of information representing an attribute of an entity.
Record : It is a collection of field values of the given entity.
File : is the collection of records of entities in a given entity set.
Each record in a file may contain field items but the value in a certain field may uniquely determine the record in the file. Such a field k is called the primary key and the values k1,k2….kn are called the keys or key values.
Records may also be classified according to length
A file can have fixed-length records or variable length records.
In fixed length records all the records contain the same data items with the same amount of space assigned to each data item.
In variable length records the file records may contain different lengths.
Example:
Student records have variable lengths since different students take different number of courses. Variable length records have a minimum and maximum length
The above organization of data into fields , records and files may not be complex enough to maintain and efficiently process certain collections of data. For this reason data are also organized into more complex types of structures.
2. Explain data structure operations?
Insertion Operation
Insert operation is to insert one or more data elements into an array. Based on the requirement, a new element can be added at the beginning, end, or any given index of array.
Here, we see a practical implementation of insertion operation, where we add data at the end of the array −
Example
Following is the implementation of the above algorithm −
#include <stdio.h>
main() {
int LA[] = {1,3,5,7,8};
int item = 10, k = 3, n = 5;
int i = 0, j = n;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
n = n + 1;
while( j >= k) {
LA[j+1] = LA[j];
j = j - 1;
}
LA[k] = item;
printf("The array elements after insertion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}
When we compile and execute the above program, it produces the following result −
Output
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after insertion :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 10
LA[4] = 7
LA[5] = 8
Deletion Operation
Deletion refers to removing an existing element from the array and re-organizing all elements of an array.
Algorithm
Consider LA is a linear array with N elements and K is a positive integer such that K<=N. Following is the algorithm to delete an element available at the Kth position of LA.
1. Start
2. Set J = K
3. Repeat steps 4 and 5 while J < N
4. Set LA[J] = LA[J + 1]
5. Set J = J+1
6. Set N = N-1
7. Stop
Example
Following is the implementation of the above algorithm −
#include <stdio.h>
void main() {
int LA[] = {1,3,5,7,8};
int k = 3, n = 5;
int i, j;
printf("The original array elements are :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
j = k;
while( j < n) {
LA[j-1] = LA[j];
j = j + 1;
}
n = n -1;
printf("The array elements after deletion :\n");
for(i = 0; i<n; i++) {
printf("LA[%d] = %d \n", i, LA[i]);
}
}
When we compile and execute the above program, it produces the following result −
Output
The original array elements are :
LA[0] = 1
LA[1] = 3
LA[2] = 5
LA[3] = 7
LA[4] = 8
The array elements after deletion :
LA[0] = 1
LA[1] = 3
LA[2] = 7
LA[3] = 8
3. Explain the analysis of an algorithm?
There are three ways to analyze an algorithm which are stated as below.
1. Worst case: In worst case analysis of an algorithm, upper bound of an algorithm is calculated. This case considers the maximum number of operation on algorithm. For example if user want to search a word in English dictionary which is not present in the dictionary. In this case user has to check all the words in dictionary for desired word.
2. Best case : In best case analysis of an algorithm, lower bound of an algorithm is calculated. This case considers the minimum number of operation on algorithm. For example if user want to search a word in English dictionary which is found at the first attempt. In this case there is no need to check other words in dictionary.
3. Average case : In average case analysis of an algorithm, all possible inputs are consider and computing time is calculated for all inputs. Average case analysis is performed by summation of all calculated value which is divided by total number of inputs. In average case analysis user must be aware about the all types of input so average case analysis are very rarely used in practical cases.
4. Explain Big-oh notation?
Big-oh notation : Big-oh notations can be express by using ‘o’ symbol. This notation indicates the maximum number of steps required to solve the problem. This notation expresses the worst case growth of an algorithm. Consider the following diagram in which there are two functions f(x) and g(x). f(x) is more complex than the function g(x).
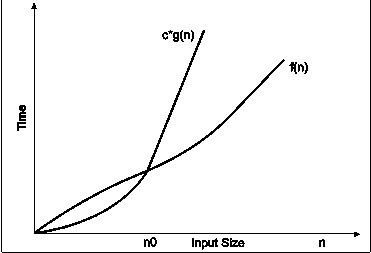
Fig. 3.7
In the above diagram out of two function f(n) and g(n), more complex function is f(n), so need to relate its growth as compare to simple function g(n). More specifically we need one constant function c(n) which bound function f(n) at some point n0. Beyond the point ‘n0’ function c*g(n) is always greater than f(n).
Now f(n)=Og(n)if there is some constant ‘c’ and some initial value ‘n0’. such that f(n)<=c*g(n) for all n>n0
In the above expression ‘n’ represents the input size
f(n) represents the time that algorithm will take
f(n) and g(n) are non-negative functions.
Consider the following example
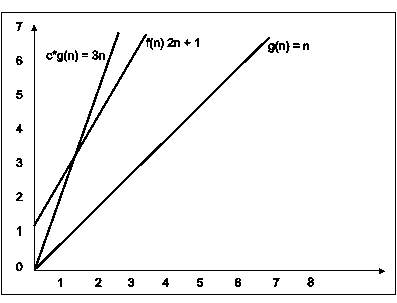
Fig. 3.8
In the above example g(n) is ‘’n’ and f(n) is ‘2n+1’ and value of constant is 3. The point where c*g(n) and f(n) intersect is ‘’n0’. Beyond ‘n0’ c*g(n) is always greater than f(n) for constant ‘3’. We can write the conclusion as follows
f(n)=O g(n) for constant ‘c’ =3 and ‘n0’=1
such that f(n)<=c*g(n) for all n>n0
5. Explain Big-omega notation?
Big-omega notation : Big-omega notations can be express by using ‘Ω’ symbol. This notation indicates the minimum number of steps required to solve the problem. This notation expresses the best case growth of an algorithm. Consider the following diagram in which there are two functions f(n) and g(n). f(n) is more complex than the function g(n).
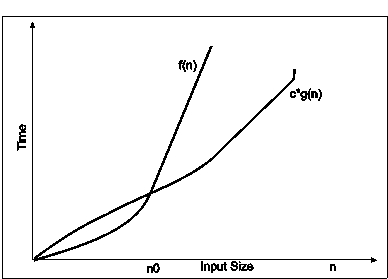
Fig. 3.9
In the above diagram out of two function f(n) and g(n), more complex function is f(n), so need to relate its growth as compare to simple function g(n). More specifically we need one constant function c(n) which bound function f(n) at some point n0. Beyond the point ‘n0’ function c*g(n) is always smaller than f(n).
Now f(n)=Ωg(n)if there is some constant ‘c’ and some initial value ‘n0’. such that c*g(n) <= f(n)for all n>n0
In the above expression ‘n’ represents the input size
f(n) represents the time that algorithm will take
f(n) and g(n) are non-negative functions.
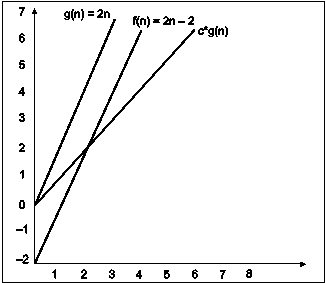
Consider the following example
In the above example g(n) is ‘2n’ and f(n) is ‘2n-2’ and value of constant is 0.5. The point where c*g(n) and f(n) intersect is ‘’n0’. Beyond ‘n0’ c*g(n) is always smaller than f(n) for constant ‘0.5’. We can write the conclusion as follows
f(n) = Ω g(n) for constant ‘c’ =0.5 and ‘n0’=2
such that c*g(n)<= f(n) for all n>n0
6. Explain Big-theta notation?
Big-theta notation : Big-theta notations can be express by using ‘Ɵ’ symbol. This notation indicates the exact number of steps required to solve the problem. This notation expresses the average case growth of an algorithm. Consider the following diagram in which there are two functions f(n) and g(n). f(n) is more complex than the function g(n).
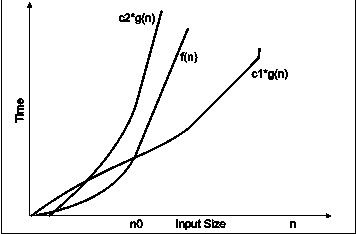
Fig. 3.11
In the above diagram out of two function f(n) and g(n), more complex function is f(n), so need to relate its growth as compare to simple function g(n). More specifically we need one constant function c1 and c2 which bound function f(n) at some point n0. Beyond the point ‘n0’ function c1*g(n) is always smaller than f(n) and c2*g(n) is always greater than f(n).
Now f(n) = g(n) if there is some constant ‘c1 and c2’ and some initial value ‘n0’. such that c1*g(n) <= f(n)<=c2*g(n)for all n>n0
In the above expression ‘n’ represents the input size
f(n) represents the time that algorithm will take
f(n) and g(n) are non-negative functions.
f(n) = g(n) if and only if f(n)=O g(n) and f(n)=Ω g(n)
Consider the following example
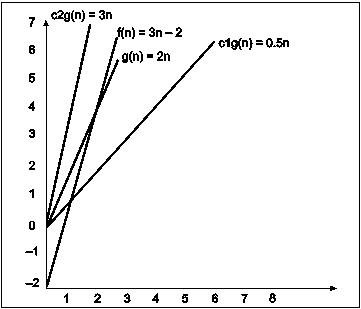
Fig. 3.12
In the above example g(n) is ‘2n’ and f(n) is ‘3n-2’ and value of constant c1 is 0.5 and c2 is 2. The point where c*g(n) and f(n) intersect is ‘’n0’. Beyond ‘n0’ c1*g(n) is always smaller than f(n) for constant ‘0.5’ and c2*g(n) is always greater than f(n) for constant ‘2’. We can write the conclusion as follows
f(n)=Ω g(n) for constant ‘c1’ =0.5 , ‘c2’ = 2 and ‘n0’=2
such that c1*g(n)<= f(n)<=c2*g(n) for all n>n0
7. What is complexity?
Complexity of an algorithm is the function which gives the running time and space requirement of an algorithm in terms of size of input data. Frequency count refers to the number of times particular instructions executed in a block of code. Frequency count plays important role in the performance analysis of an algorithm. Each instruction in algorithm is incremented by one as its execution. Frequency count analysis is the form of priori analysis. Frequency count analysis produces output in terms of time complexity and space complexity.
8. What are the types of complexity?
9. Explain frequency count analysis ?
Frequency count analysis for this code is as follows
Sr. No. | Instructions | Frequency count |
#include<stdio.h> |
| |
2. | #include<conio.h> |
|
3. | void main() { |
|
4. | int marks; |
|
5. | printf(“enter a marks”); | add 1 to the time count |
6. | scanf(“%d”,&marks); | add 1 to the space count |
7. | printf(“your marks is %d”,marks); | add 1 to the time count |
8. | getch(); } |
|
In the above example, for the first four instructions there is no frequency count. For data declaration and the inclusion of header file there is no frequency count. So, for this example has a frequency count for time is 2 and a frequency count for space is 1. So, total frequency count is 3.
10.Find the frequency count for the following program?
Sr. No. | Instructions | Frequency count |
1. | #include<stdio.h> |
|
2. | #include<conio.h> |
|
3. | void main() { |
|
4. | int a[2][3],b[2][3],c[2][3]] |
|
5. | for(i=0;i<m;i++) | m+1 |
6. | { |
|
7. | for(j=0;j<n;j++) | m(n+1) |
8. | { |
|
9. | c[i][j]=a[i][j]*b[i][j]; | m.n |
10. | }} |
|
11. | getch(); } |
|
: In the above example, in instruction five value of ‘i’ is check from 0 to ‘m’ so frequency count is ‘m+1’ for fifth instruction. In instruction five value of ‘j’ is check from 0 to ‘n’ so frequency count is ‘n+1’ but this instruction is in the for loop which execute for ‘m’ times, so for seventh instruction is m*(n+1). Ninth instruction is in the two for loops, out of which first for loop execute for m times and second ‘for’ loop execute for ‘n’ times. So for ninth instruction frequency count is m*n. The total frequency count for the above program is (m+1)+m(n+1)+mn=2m+2mn+1=2m(1+n)+1.




