UNIT 2
Processes, Thread, Process Scheduling
- The Text section is comprised of the compiled program code, read in from non-volatile storage when the program is launched.
- The Data section is made up of global and static variables, allotted and introduced before executing the primary.
- The Heap is utilized for the dynamic memory distribution, and is managed through calls to new, delete, malloc, free, and so on.
- The Stack is utilized for local variables. Space on the stack is saved for local variables when they are declared.
max
Stack |
|
Heap |
Data |
Text |
0
- I/O-Bound Process - An I/O-bound process is a process whose execution time is resolved principally by the measure of time it spends finishing I/O operations.
- CPU-Bound Process - A CPU-bound process is a process whose execution time is dictated by the speed of the CPU it keeps running on. A CPU-bound process can finish its execution quicker in the event that it is running on a quicker processor.
2. What is process control back and process state of an operating system?
Process Control Back (PCB)
- Process State- The present condition of the process i.e., regardless of whether it is ready, running, waiting or whatever.
- Process privileges- This is required to permit/deny access to system resources.
- Process ID- It kept the unique identification number for every process in the t system.
- Pointer- It keeps pointer to parent process.
- Program Counter- It is a pointer to the location of the next instruction that is to be executed by the process.
- CPU registers- Different CPU registers are used where process should be kept for execution in running state.
- CPU Scheduling Information- This keeps process priority and other scheduling information which is needed to schedule a process.
- Memory management information- This incorporates the data of page table, memory limits, Segment table based upon memory utilized by the operating system.
- Accounting information- This incorporates the amount of CPU utilized for process execution, time limits, execution ID and so forth.
- IO status information- This keeps a record of all the I/O devices assigned to the process.

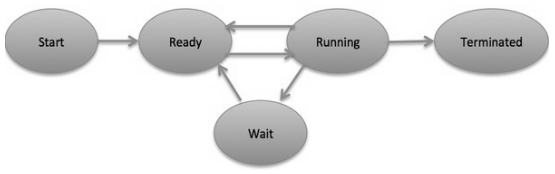
- Start- This is the underlying state when a process is first started/created.
- Ready- The process is waiting on to be assigned out to a processor. Ready processes are waiting on to have the processor dispensed to them by the operating system with the goal that they can run. Process may come into this state after Start state or while running it by however interrupted by the scheduler to appoint CPU to some different process.
- Running- When the process has been allotted to a processor by the OS scheduler, the process state is set to running and the processor executes its instructions.
- Waiting- Process moves into the waiting up state on the off chance that it needs to wait tight for a resource, for example, sitting waiting for user input, or waiting that a file will end up accessible.
- Terminated or Exit- When the process completes its execution, or it is ended by the operating system, it is moved to the terminate state where it waits back to be expelled from main memory.
3. What is Process Scheduling of an operating system?
- Job queue - The job queue is the arrangement of all processes on the system
- Ready queue - The ready queue has every processes that are loaded in main memory. These processes are ready and waiting for their chance to execute when the CPU will be available.
- Device queue - The set of processes waiting for an I/O device to end up accessible, for example, printer. This queue is otherwise called the Blocked Queue.
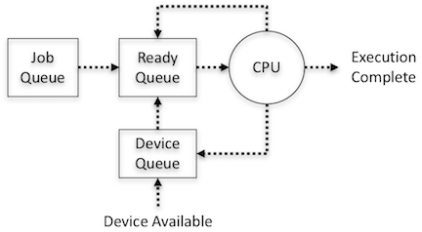
Flow of a process through the Scheduling Queues
4. What is the different Operation on process of an operating system?
- User request for process creation
- System initialization
- Execution of a process creation system call by a running process
- Batch job initialization
Process Pre-emption
5. What is Cooperating process of an operating system?
Cooperating processes are those that can affect or are affected by other processes running on the system. Cooperating processes may share data with each other.
Reasons for needing cooperating processes
There may be many reasons for the requirement of cooperating processes. Some of these are given as follows −
Modularity involves dividing complicated tasks into smaller subtasks. These subtasks can complete by different cooperating processes. This leads to faster and more efficient completion of the required tasks.
Sharing of information between multiple processes can be accomplished using cooperating processes. This may include access to the same files. A mechanism is required so that the processes can access the files in parallel to each other.
There are many tasks that a user needs to do such as compiling, printing, editing etc. It is convenient if these tasks can be managed by cooperating processes.
Subtasks of a single task can be performed parallelly using cooperating processes. This increases the computation speedup as the task can be executed faster. However, this is only possible if the system has multiple processing elements.
Methods of Cooperation
Cooperating processes can coordinate with each other using shared data or messages. Details about these are given as follows −
The cooperating processes can cooperate with each other using shared data such as memory, variables, files, databases etc. Critical section is used to provide data integrity and writing is mutually exclusive to prevent inconsistent data.
A diagram that demonstrates cooperation by sharing is given as follows −
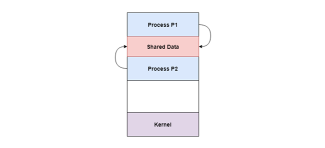
In the above diagram, Process P1 and P2 can cooperate with each other using shared data such as memory, variables, files, databases etc.
The cooperating processes can cooperate with each other using messages. This may lead to deadlock if each process is waiting for a message from the other to perform a operation. Starvation is also possible if a process never receives a message.
A diagram that demonstrates cooperation by communication is given as follows −
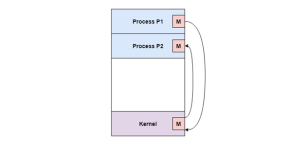
In the above diagram, Process P1 and P2 can cooperate with each other using messages to communicate.
6. What is Threads in an operating system?
- A program counter
- A register set
- A stack space
7. Why Threads in an operating system?
- A process with various threads make an incredible server for instance printer server.
- Since threads can share regular data, they don't have to utilize inter process communication.
- As a result of the very nature, threads can make use of multiprocessors.
- They just need a stack and storage for registers subsequently, threads are cheap to make.
- Threads utilize almost no resources of an operating system where they are working. That is, threads needn't bother with new address space, worldwide data, program code or operating system resources.
- Context switching are quick when working with threads. The reason is that we just need to spare and additionally re-establish computer, SP and registers.
8. What are the benefits of threads in an operating system?
Benefits of Threads
In a non multi-threaded environment, a server listens to the port for some request and when the request comes, it processes the request and after that resume listening to another request. The time taken while processing of request makes different users hold up superfluously. Rather a superior methodology is passing the request to a worker thread and keep listening to the port. In the event that the process is partitioned into different thread, if one of the threads finishes its execution, at that point its output can be quickly returned.
2. Quicker context switch: Threads are economical to make and wreck, and they are modest to represent. For instance, they expect space to store, the PC, the SP, and the general purpose registers, however they don't expect space to share memory data, information about open files of I/O devices being used, and so forth. With so little context, it is a lot quicker to switch between threads. At the end of the day, it is moderately simpler for a context switch utilizing strings.
3. Effective use of multiprocessor system: If we have various threads in a single process, at that point we can plan numerous threads on different processor. This will make process execution quicker.
4. Resource sharing: Processes may share resources just through strategies, as,
Such strategies must be expressly sorted out by developer. In any case, threads share the memory and the resources of the process to which they have a place of course.
The advantage of sharing code and data is that it enables an application to have a few threads of activity inside same location space.
5. Communication: Communication between various threads is simpler, as the threads shares same location space, while in process we need to pursue some particular communication method for communication between two process.
Upgraded throughput of the system: If a process is separated into numerous threads, and each thread function is considered as one job, at that point the quantity of job finished per unit of time is expanded, in this way expanding the throughput of the system.
9. What is Inter process communication (Algorithm evaluation) of an operating system?
- Data sharing: Since certain users might be interested in a similar piece of data (for instance, a shared file), you should give a circumstance to enabling simultaneous access to that data.
- Computation speedup: If you need a specific work to run quick, you should break it into sub-tasks where every one of them will get executed in parallel with other tasks. Note that such an accelerate can be achieved just when the computer has compound or different processing components like CPUs or I/O channels.
- Modularity: You might need to build the system in a modular manner by partitioning the system functions into split processes or threads.
- Convenience: Even a single user will be able to work on many tasks simultaneously. For instance, a user might be editing, formatting, printing, and compiling in parallel.
- Shared memory and
- Message passing.
Figure below exhibits the shared memory model and message passing model is shown below:
Models of Inter process Communication
Advantages of Shared Memory Model
Disadvantages of Shared Memory Model
Advantages of Messaging Passing Model
Disadvantage of Messaging Passing Model
10. What is Multiple processor scheduling in an operating system explain in detail?
In multiple-processor scheduling multiple CPU’s are available and hence Load Sharing becomes possible. However multiple processor scheduling is more complex as compared to single processor scheduling. In multiple processor scheduling there are cases when the processors are identical i.e. HOMOGENEOUS, in terms of their functionality, we can use any processor available to run any process in the queue.
Approaches to Multiple-Processor Scheduling –
One approach is when all the scheduling decisions and I/O processing are handled by a single processor which is called the Master Server and the other processors executes only the user code. This is simple and reduces the need of data sharing. This entire scenario is called Asymmetric Multiprocessing.
A second approach uses Symmetric Multiprocessing where each processor is self-scheduling. All processes may be in a common ready queue or each processor may have its own private queue for ready processes. The scheduling proceeds further by having the scheduler for each processor examine the ready queue and select a process to execute.
Processor Affinity –
Processor Affinity means a process has an affinity for the processor on which it is currently running.
When a process runs on a specific processor there are certain effects on the cache memory. The data most recently accessed by the process populate the cache for the processor and as a result successive memory access by the process are often satisfied in the cache memory. Now if the process migrates to another processor, the contents of the cache memory must be invalidated for the first processor and the cache for the second processor must be repopulated. Because of the high cost of invalidating and repopulating caches, most of the SMP(symmetric multiprocessing) systems try to avoid migration of processes from one processor to another and try to keep a process running on the same processor. This is known as PROCESSOR AFFINITY.
There are two types of processor affinity:
Load Balancing –
Load Balancing is the phenomena which keeps the workload evenly distributed across all processors in an SMP system. Load balancing is necessary only on systems where each processor has its own private queue of process which are eligible to execute. Load balancing is unnecessary because once a processor becomes idle it immediately extracts a runnable process from the common run queue. On SMP(symmetric multiprocessing), it is important to keep the workload balanced among all processors to fully utilize the benefits of having more than one processor else one or more processor will sit idle while other processors have high workloads along with lists of processors awaiting the CPU.
There are two general approaches to load balancing :
Multicore Processors –
In multicore processors multiple processor cores are places on the same physical chip. Each core has a register set to maintain its architectural state and thus appears to the operating system as a separate physical processor. SMP systems that use multicore processors are faster and consume less power than systems in which each processor has its own physical chip.
However multicore processors may complicate the scheduling problems. When processor accesses memory then it spends a significant amount of time waiting for the data to become available. This situation is called MEMORY STALL. It occurs for various reasons such as cache miss, which is accessing the data that is not in the cache memory. In such cases the processor can spend upto fifty percent of its time waiting for data to become available from the memory. To solve this problem recent hardware designs have implemented multithreaded processor cores in which two or more hardware threads are assigned to each core. Therefore, if one thread stalls while waiting for the memory, core can switch to another thread.
There are two ways to multithread a processor:
Virtualization and Threading –
In this type of multiple-processor scheduling even a single CPU system acts like a multiple-processor system. In a system with Virtualization, the virtualization presents one or more virtual CPU to each of virtual machines running on the system and then schedules the use of physical CPU among the virtual machines. Most virtualized environments have one host operating system and many guest operating systems. The host operating system creates and manages the virtual machines. Each virtual machine has a guest operating system installed and applications run within that guest. Each guest operating system may be assigned for specific use cases, applications or users including time sharing or even real-time operation. Any guest operating-system scheduling algorithm that assumes a certain amount of progress in a given amount of time will be negatively impacted by the virtualization. A time-sharing operating system tries to allot 100 milliseconds to each time slice to give users a reasonable response time. A given 100 millisecond time slices may take much more than 100 milliseconds of virtual CPU time. Depending on how busy the system is, the time slice may take a second or more which results in a very poor response time for users logged into that virtual machine. The net effect of such scheduling layering is that individual virtualized operating systems receive only a portion of the available CPU cycles, even though they believe they are receiving all cycles and that they are scheduling all of those cycles. Commonly, the time-of-day clocks in virtual machines are incorrect because timers take no longer to trigger than they would on dedicated CPU’s.
Virtualizations can thus undo the good scheduling-algorithm efforts of the operating systems within virtual machines.




