Unit-4
Software Testing
Q1) Write objective of testing?
A1) Testing Objectives
Once the source code has been developed testing is required to uncover the errors before it is implemented. In order to perform software testing a series of test case is designed.
Definition of Testing
● According to IEEE – “Testing means the process of analyzing a software item to detect the differences between existing and required conditions (i.e. bugs) and to evaluate the feature of the software item”.
● According to Myers – “Testing is the process of analyzing a program with the intent of finding an error”.
Primary objectives of Software Testing
According to Glen Myers the primary objectives of testing are:
● Testing is a process of executing a program with the intent of finding an error.
● A good test case is one that has a high probability of finding and as yet undiscovered error.
● A successful test is one that uncovers an yet undiscovered error. Testing cannot show the absence of errors and defects, it can show only error and detects present. Hence, the objective of testing is to design tests that systematically uncover different errors and to do so with a minimum amount of time and effort.
ERRORS, FAULT AND FAILURE
● Error – The term error is used to refer to the discrepancy between computed, observed or measured value and the specified value. In other terms errors can be defined as the difference between actual output of software and correct output.
● Fault – It is a condition that causes a system to fail in performing its required function.
● Failure – A software failure occurs if the behavior of the software is different from specified behavior. It is a stage when a system becomes unable to perform a required function according to the specification mentioned.
Q2) Describe unit testing?
A2) Unit Testing
Unit testing focuses verification effort on the smallest unit of software design—the software component or module. Using the component- level design description as a guide, important control paths are tested to uncover errors within the boundary of the module. The relative complexity of tests and uncovered errors is limited by the constrained scope established for unit testing. The unit test is white-box oriented, and the step can be conducted in parallel for multiple components.
Unit Test Considerations
The tests that occur as part of unit tests are illustrated schematically in Figure below. The module interface is tested to ensure that information properly flows into and out of the program unit under test. The local data structure is examined to ensure that data stored temporarily maintains its integrity during all steps in an algorithm's execution. Boundary conditions are tested to ensure that the module operates properly at boundaries established to limit or restrict processing. All independent paths (basis paths) through the control structure are exercised to ensure that all statements in a module have been executed at least once. And finally, all error handling paths are tested.

Fig 1: Unit Test
Tests of data flow across a module interface are required before any other test is initiated. If data does not enter and exit properly, all other tests are moot. In addition, local data structures should be exercised and the local impact on global data should be ascertained (if possible) during unit testing.
Selective testing of execution paths is an essential task during the unit test. Test cases should be designed to uncover errors due to erroneous computations, incorrect comparisons, or improper control flow. Basis path and loop testing are effective techniques for uncovering a broad array of path errors.
Among the more common errors in computation are
● Misunderstood or incorrect arithmetic precedence,
● Mixed mode operations,
● Incorrect initialization,
● Precision inaccuracy,
● Incorrect symbolic representation of an expression.
Comparison and control flow are closely coupled to one another (i.e., change of flow frequently occurs after a comparison). Test cases should uncover errors such as
- Comparison of different data types,
- Incorrect logical operators or precedence,
- Expectation of equality when precision error makes equality unlikely,
- Incorrect comparison of variables,
- Improper or nonexistent loop termination,
- Failure to exit when divergent iteration is encountered, and
- Improperly modified loop variables.
Among the potential errors that should be tested when error handling is evaluated are
● Error description is unintelligible.
● Error noted does not correspond to error encountered.
● Error condition causes system intervention prior to error handling.
● Exception-condition processing is incorrect.
● Error description does not provide enough information to assist in the location of the cause of the error.
Boundary testing is the last (and probably most important) task of the unit test step. Software often fails at its boundaries. That is, errors often occur when the nth element of an n-dimensional array is processed, when the ith repetition of a loop with i passes is invoked, when the maximum or minimum allowable value is encountered. Test cases that exercise data structure, control flow, and data values just below, at, and just above maxima and minima are very likely to uncover errors.
Unit Test Procedures
Unit testing is normally considered as an adjunct to the coding step. After source level code has been developed, reviewed, and verified for correspondence to component level design, unit test case design begins. A review of design information provides guidance for establishing test cases that are likely to uncover errors in each of the categories discussed earlier. Each test case should be coupled with a set of expected results.
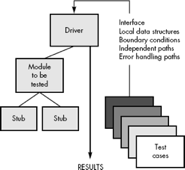
Fig 2: Unit Test Environment
Because a component is not a stand-alone program, driver and/or stub software must be developed for each unit test. The unit test environment is illustrated in Figure above. In most applications a driver is nothing more than a "main program" that accepts test case data, passes such data to the component (to be tested), and prints relevant results. Stubs serve to replace modules that are subordinate (called by) the component to be tested.
A stub or "dummy subprogram" uses the subordinate module's interface, may do minimal data manipulation, prints verification of entry, and returns control to the module undergoing testing. Drivers and stubs represent overhead. That is, both are software that must be written (formal design is not commonly applied) but that is not delivered with the final software product. If drivers and stubs are kept simple, actual overhead is relatively low. Unfortunately, many components cannot be adequately unit tested with "simple" overhead software. In such cases, complete testing can be postponed until the integration test step (where drivers or stubs are also used).
Unit testing is simplified when a component with high cohesion is designed. When only one function is addressed by a component, the number of test cases is reduced and errors can be more easily predicted and uncovered.
Q3) Write the advantages and disadvantages of unit testing?
A3) Advantages of Unit testing
● Can be applied directly to object code and does not require processing source code.
● Performance profilers commonly implement this measure.
Disadvantages of Unit Testing
● Insensitive to some control structures (number of iterations)
● Does not report whether loops reach their termination condition
● Statement coverage is completely insensitive to the logical operators (|| and &&).
Q4) Write short notes on integration testing?
A4) Integration testing
Integration testing is a systematic technique for constructing the program structure while at the same time conducting tests to uncover errors associated with interfacing. The objective is to take unit tested components and build a program structure that has been dictated by design.
There is often a tendency to attempt non-incremental integration; that is, to construct the program using a "big bang" approach. All components are combined in advance. The entire program is tested as a whole. And chaos usually results! A set of errors is encountered.
Correction is difficult because isolation of causes is complicated by the vast expanse of the entire program. Once these errors are corrected, new ones appear and the process continues in a seemingly endless loop.
Incremental integration is the antithesis of the big bang approach. The program is constructed and tested in small increments, where errors are easier to isolate and correct; interfaces are more likely to be tested completely; and a systematic test approach may be applied.
Q5) What is top-down integration?
A5) Top-down integration testing is an incremental approach to construction of program structure. Modules are integrated by moving downward through the control hierarchy, beginning with the main control module (main program). Modules subordinate (and ultimately subordinate) to the main control module are incorporated into the structure in either a depth-first or breadth-first manner.
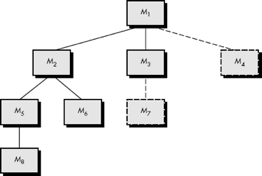
Fig 3: Top down integration
Referring to Figure above, depth-first integration would integrate all components on a major control path of the structure. Selection of a major path is somewhat arbitrary and depends on application-specific characteristics. For example, selecting the left-hand path, components M1, M2, M5 would be integrated first. Next, M8 or (if necessary for proper functioning of M2) M6 would be integrated.
Then, the central and right-hand control paths are built. Breadth-first integration incorporates all components directly subordinate at each level, moving across the structure horizontally. From the figure, components M2, M3, and M4 (a replacement for stub S4) would be integrated first. The next control level, M5, M6, and so on, follows.
The integration process is performed in a series of five steps:
● The main control module is used as a test driver and stubs are substituted for all components directly subordinate to the main control module.
● Depending on the integration approach selected (i.e., depth or breadth first), subordinate stubs are replaced one at a time with actual components.
● Tests are conducted as each component is integrated.
● On completion of each set of tests, another stub is replaced with the real component.
● Regression testing may be conducted to ensure that new errors have not been introduced. The process continues from step 2 until the entire program structure is built.
The top-down integration strategy verifies major control or decision points early in the test process. In a well-factored program structure, decision making occurs at upper levels in the hierarchy and is therefore encountered first. If major control problems do exist, early recognition is essential. If depth-first integration is selected, a complete function of the software may be implemented and demonstrated.
For example, consider a classic transaction structure in which a complex series of interactive inputs is requested, acquired, and validated via an incoming path. The incoming path may be integrated in a top-down manner. All input processing (for subsequent transaction dispatching) may be demonstrated before other elements of the structure have been integrated. Early demonstration of functional capability is a confidence builder for both the developer and the customer.
Top-down strategy sounds relatively uncomplicated, but in practice, logistical problems can arise. The most common of these problems occurs when processing at low levels in the hierarchy is required to adequately test upper levels. Stubs replace low-level modules at the beginning of top-down testing; therefore, no significant data can flow upward in the program structure. The tester is left with three choices:
● Delay many tests until stubs are replaced with actual modules,
● Develop stubs that perform limited functions that simulate the actual module, or
● Integrate the software from the bottom of the hierarchy upward.
The first approach (delay tests until stubs are replaced by actual modules) causes us to lose some control over correspondence between specific tests and incorporation of specific modules. This can lead to difficulty in determining the cause of errors and tends to violate the highly constrained nature of the top-down approach. The second approach is workable but can lead to significant overhead, as stubs become more and more complex.
Q6) Write about bottom-up integration?
A6) Bottom-up Integration
Bottom-up integration testing, as its name implies, begins construction and testing with atomic modules (i.e., components at the lowest levels in the program structure). Because components are integrated from the bottom up, processing required for components subordinate to a given level is always available and the need for stubs is eliminated.
A bottom-up integration strategy may be implemented with the following steps:
- Low-level components are combined into clusters (sometimes called builds) that perform a specific software sub-function.
- A driver (a control program for testing) is written to coordinate test case input and output.
- The cluster is tested.
- Drivers are removed and clusters are combined moving upward in the program structure.
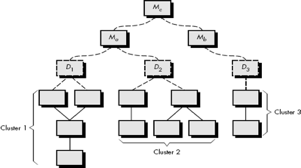
Fig 4: Bottom up integration
Integration follows the pattern illustrated in Figure above. Components are combined to form clusters 1, 2, and 3. Each of the clusters is tested using a driver (shown as a dashed block). Components in clusters 1 and 2 are subordinate to Ma. Drivers D1 and D2 are removed and the clusters are interfaced directly to Ma. Similarly, driver D3 for cluster 3 is removed prior to integration with module Mb. Both Ma and Mb will ultimately be integrated with component Mc, and so forth.
As integration moves upward, the need for separate test drivers lessens. In fact, if the top two levels of program structure are integrated top down, the number of drivers can be reduced substantially and integration of clusters is greatly simplified.
Q7) Describe acceptance testing?
A7) Acceptance Testing
Acceptance Testing is a form of software testing in which the acceptability of a system is assessed. The main goal of this test is to determine if the device complies with the business requirements and if it is suitable for delivery.
Standard Definition of Acceptance Testing:
It is a formal testing according to user needs, requirements and business processes conducted to determine whether a system satisfies the acceptance criteria or not and to enable the users, customers or other authorized entities to determine whether to accept the system or not.
After System Testing and before making the system ready for practical use, Acceptance Testing is the final step of software testing.
Fig 5: acceptance testing
When the software is ready to hand over to the customer it has to go through the last phase of testing where it is tested for user-interaction and response. This is important because even if the software matches all user requirements and if the user does not like the way it appears or works, it may be rejected.
Q8) Write the use of acceptance testing?
A8) Use of Acceptance Testing
● To locate defects that were overlooked during the functional testing process.
● The quality of the product's growth.
● A commodity is what the customers actually want.
● The output of the product and the user experience will also benefit from feedback.
● Reduce or remove problems that arise during development.
Q9) What do you mean by regression testing?
A9) Regression Testing
Whenever a software product is updated with new code, feature or functionality, it is tested thoroughly to detect if there is any negative impact of the added code. This is known as regression testing.
Testing standards
- IEEE 829- A standard for the format of documents used in different stages of software testing.
- IEEE 1008-A standard for unit testing.
- IEEE 1059-Guide for Software Verification and Validation Plans.
- IEEE 1044-A standard for the classification of software anomalies.
- IEEE 1044-1- A guide for the classification of software anomalies.
- BS 7925-1- A vocabulary of terms used in software testing.
- BS 7925-2-A standard for software component testing.
Q10) Explain functional testing?
A10) Functional Testing
FUNCTIONAL TESTING is a form of software testing that verifies that the software system meets the functional requirements. Functional tests are used to validate the performance of a software application by supplying sufficient data and comparing it to the functional specifications.
Functional research is mostly concerned with black box testing and is not concerned with the application's source code. This research examines the Application Under Test's user interface, APIs, database, security, client/server communication, and other features. Testing can be carried out manually or automatically.
Functional Testing Process
The following are the steps involved in functional testing:
● Determine the role to be performed.
● Create input data based on the function's requirements.
● Determine the output dependent on the function's parameters.
● Carry out the test case.
● Compare the real and anticipated results.
Q11) Write the pros and cons of functional testing ?
A11) Pros and cons of Functional testing
Pros
● It ensures that the product is bug-free.
● It ensures that a high-quality product is delivered.
● There are no assumptions about the system's composition.
● The emphasis of this testing is on the requirements as they relate to customer use.
Cons
● There's a good chance you'll be doing redundant research.
● Logical flaws in the product can be overlooked.
● It becomes impossible to conduct this testing if the criteria is incomplete.
Q12) Define performance testing?
A12) Performance testing
Performance testing is a software testing method for evaluating a software application's speed, response time, consistency, reliability, scalability, and resource use under a specific workload. The key goal of performance testing is to find and remove performance bottlenecks in software applications. It is also known as "Perf Testing" and is a branch of performance engineering.
The aim of performance testing is to determine how well a software program performs:
● Speed - Determines whether the application responds quickly.
● Scalability - Determines maximum user load the software application can handle.
● Stability - Determines if the application is stable under varying loads.
Objectives of performance testing
● The aim of performance testing is to get rid of performance bottlenecks.
● It reveals what needs to be changed before a product is released to the market.
● The aim of performance testing is to make software more responsive.
● Quality testing is used to ensure the software is stable and accurate.
Q13) Explain white box testing?
A13) White box Testing
● In this testing technique the internal logic of software components is tested.
● It is a test case design method that uses the control structure of the procedural design test cases.
● It is done in the early stages of software development.
● Using this testing technique software engineer can derive test cases that:
● All independent paths within a module have been exercised at least once.
● Exercised true and false both the paths of logical checking.
● Execute all the loops within their boundaries.
● Exercise internal data structures to ensure their validity.
Advantages:
● As the knowledge of internal coding structure is prerequisite, it becomes very easy to find out which type of input/data can help in testing the application effectively.
● The other advantage of white box testing is that it helps in optimizing the code.
● It helps in removing the extra lines of code, which can bring in hidden defects.
● We can test the structural logic of the software.
● Every statement is tested thoroughly.
● Forces test developers to reason carefully about implementation.
● Approximate the partitioning done by execution equivalence.
● Reveals errors in "hidden" code.
Disadvantages:
● It does not ensure that the user requirements are fulfilled.
● As knowledge of code and internal structure is a prerequisite, a skilled tester is needed to carry out this type of testing, which increases the cost.
● It is nearly impossible to look into every bit of code to find hidden errors, which may create problems, resulting in failure of the application.
● The tests may not be applicable in a real world situation.
● Cases omitted in the code could be missed out.
Q14) Write black box testing?
A14) Black box testing
Functional Testing: It is a type of software testing which is used to verify the functionality of the software application, whether the function is working according to the requirement specification
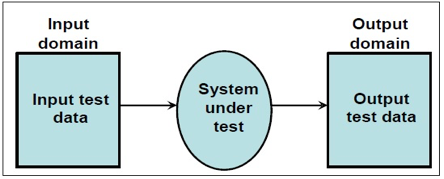
Fig 6: functional testing
Black-box testing
It is also known by “behavioural testing” which focuses on the functional requirements of the software, and is performed at later stages of testing process unlike white box which takes place at early stage. Black-box testing aims at functional requirements for a program to derive sets of input conditions which should be tested. Black box is not an alternative to white-box, rather, it is a complementary approach to find out a different class of errors other than white-box testing.
Black-box testing is emphasizing on different set of errors which falls under following categories:
- Incorrect or missing functions
- Interface errors
- Errors in data structures or external database access
- Behaviour or performance errors
- Initialization and termination errors.
- Boundary value analysis: The input is divided into higher and lower end values. If these values pass the test, it is assumed that all values in between may pass too.
- Equivalence class testing: The input is divided into similar classes. If one element of a class passes the test, it is assumed that all the class is passed.
c. Decision table testing: Decision table technique is one of the widely used case design techniques for black box testing. This is a systematic approach where various input combinations and their respective system behaviour are captured in a tabular form. That’s why it is also known as a cause-effect table. This technique is used to pick the test cases in a systematic manner; it saves the testing time and gives good coverage to the testing area of the software application. Decision table technique is appropriate for the functions that have a logical relationship between two and more than two inputs.
Advantages:
● More effective on larger units of code than glass box testing.
● Testers need no knowledge of implementation, including specific programming languages.
● Testers and programmers are independent of each other.
● Tests are done from a user's point of view.
● Will help to expose any ambiguities or inconsistencies in the specifications.
● Test cases can be designed as soon as the specifications are complete.
Disadvantages:
● Only a small number of possible inputs can actually be tested, to test every possible input stream would take nearly forever.
● Without clear and concise specifications, test cases are hard to design.
● There may be unnecessary repetition of test inputs if the tester is not informed of test cases the programmer has already tried.
● May leave many program paths untested.
● Cannot be directed toward specific segments of code which may be very complex (and therefore more error prone).
● Most testing related research has been directed toward glass box testing.
Q15) Write about alpha testing with pros and cons?
A15) Alpha Testing
Alpha testing is a form of acceptance testing used to find different types of issues or vulnerabilities in software before making the build or executable available to the public or market. Via black box and white box testing techniques, this test type focuses on real users. The emphasis is kept on the task that a typical consumer might want or encounter.
When a product's production is nearing completion, alpha testing is conducted. Following the alpha test, minor design improvements may be made. The developers carry out this research technique in a lab environment. Developers look at the program from the perspective of the users and strive to find flaws.
Internal business or agency staff, or members of the research team, are the testers. Until beta testing, alpha testing is performed at the end of software development.
The team of developers themselves perform alpha testing by using the system as if it is being used in the work environment. They try to find out how users would react to some action in software and how the system should respond to inputs.
Advantages
● Provides a clearer picture of the software's stability at an early level.
● Simulates user behavior and environment in real time.
● Detects a large number of show-stopping or extreme mistakes.
● Ability to spot defects in design and functionality early on.
Disadvantages
● Since the program is still in progress, it is impossible to evaluate features in detail. The results of alpha testing can often dissatisfied developers and testers.
Q16) Describe Beta testing?
A16) Beta Testing
Beta testing is the second stage of product testing before release, in which a preview of the released product with the bare minimum of features and characteristics is sent to the intended audience for the purpose of trying out or briefly using it. Unlike an alpha test, the beta test is conducted by actual users in a real-world environment. This helps potential customers to learn more about the product's design, operation, interface, and features.
After the software is tested internally, it is handed over to the users to use it under their production environment only for testing purposes. This is not yet the delivered product. Developers expect that users at this stage will bring minute problems, which were skipped to attend.
Advantages
● Customer confirmation lowers the probability of product failure.
● An organization can use beta testing to test post-launch infrastructure.
● Customer feedback is used to improve product quality.
● As compared to other data collection techniques, this approach is less expensive.
● Increases customer loyalty and creates goodwill with consumers.
Disadvantages
● There is a problem with test management. Unlike other forms of testing, which are typically carried out inside an organization in a regulated environment, beta testing is carried out in the real world, where you seldom have control.
● Finding the right beta testers and keeping them on board might be difficult.
Q17) What are Coding Standards?
A17) Coding Standards
n the Coding process, different modules defined in the design document are coded according to the module specification. The main aim of the coding process is to use a high-level language to code from the design document created during the design phase, and then to unit test this code.
Coding standards are a well-defined and uniform style of coding that good software development companies want their programmers to follow. They typically create their own coding standards and guidelines based on what works best for their company and the types of applications they create. Maintaining coding standards is critical for programmers; otherwise, code would be rejected during code review.
Purpose of having coding standards
● A coding standard gives the codes written by various engineers a consistent appearance.
● It increases the code's readability and maintainability while also reducing its complexity.
● It aids in the reuse of code and the detection of errors.
● It encourages good programming habits and improves programmers' productivity.
The following are some of the coding standards:
- Limited use of global: These guidelines specify which types of data should be declared global and which cannot.
2. Avoid using a coding style that is too difficult to understand: The code should be simple to comprehend. Maintenance and debugging are complicated and costly due to the complex code.
3. Avoid using an identifier for multiple purposes: Each variable should have a descriptive and meaningful name that explains why it is being used. When an identifier is used for various purposes, this is not possible, and the reader can become confused. Furthermore, it makes potential upgrades more challenging.
4. Code should be well documented: The code should be well-commented so that it is easy to understand. The code is made more understandable by adding comments to the sentences.
5. Length of functions should not be very large: Lengthy functions are very difficult to understand. That’s why functions should be small enough to carry out small work and lengthy functions should be broken into small ones for completing small tasks.




