Unit - 5
Genetic Algorithms
Q1) Explain FOIL in brief.
A1)
FOIL extends the SEQUENTIAL-COVERING and LEARN-ONE-RULE algorithms for propositional rule learning to first-order rule learning
- FOIL learns in two phases:
– an outer loop which acquires a disjunction of Horn clause-like rules which together cover the positive examples
– an inner loop that constructs individual rules by progressive specialization of a rule through adding new literals selected according to the FOIL-gain measure until no negative examples are covered
- The literals introduced in the rule preconditions are drawn from the attributes used in describing the training examples
– Variables used in new literals maybe those occurring already in the rule pre-/postconditions, or they may be new
– If the new literal is allowed to use the target predicate then recursive rules may be learned In this case special care must be taken to avoid learning rule sets that produce infinite recursion.
Q2) What is the fitness function? Write its characteristics
A2)
The fitness function can be defined as a function that takes a candidate solution to the problem as input and produces as output how “fit” our how “good” the solution is with respect to the problem in consideration.
Calculation of fitness value is done repeatedly in a GA and therefore it should be sufficiently fast. A slow computation of the fitness value can adversely affect a GA and make it exceptionally slow. The fitness function and the objective function are the same as the objective is to either maximize or minimize the given objective function. However, for more complex problems with multiple objectives and constraints, an Algorithm Designer might choose to have a different fitness function.
A fitness function possess the following characteristics −
- The fitness function should be sufficiently fast to compute.
- It must quantitatively measure how to fit a given solution is or how to fit individuals can be produced from the given solution.
Q3) Write a short note on GA based machine learning.
A3)
Genetic Algorithms Based Machine Learning (ML) is the application of GA in Machine Learning. Classifier systems are a form of genetics-based machine learning (GBML) system that is frequently used in the field of machine learning. GBML methods are a good approach to ML.
There are two forms of GBML systems −
- The Pittsburg Approach − In this approach, one chromosome encoded one solution, and so fitness is assigned to solutions.
- The Michigan Approach − one solution is typically represented by many chromosomes and so fitness is assigned to partial solutions.
Point to be noted: crossover, mutation, Lamarckian or Darwinian, etc. are also present in the GBML systems.
Q4) Write FOIL algorithm
A4)
FOIL (Target_predicate, Predicates, Examples)
- Pos ← positive Examples
- Neg ← negative Examples
- Learned_rules ← {}
- While Pos, do
Learn a NewRule
- NewRule ← most general rule possible (no preconditions)
- NewRuleNeg ← Neg
- while NewRuleNeg, do
Add a new literal to specialize NewRule
- Candidate_literals ← generate candidates based on Predicates
- Best_literal ←
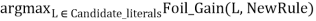
- Add Best_literal to NewRule preconditions
- NewRuleNeg ← subset of NewRuleNeg that satisfies NewRule preconditions
- Learned_rules ← Learned_rules + NewRule
- Pos ← Pos – {members of Pos covered by NewRule}
- Return Learned_rules
Q5) Differentiate between the Lamarckian model & Baldwinian Model
A5)
Lamarckian Model | Baldwinian Model |
The Lamarckian Model essentially says that the traits which an individual acquires in his/her life can be passed on to his offspring. It is named after French biologist Jean-Baptiste Lamarck. Even though, natural biology has completely disregarded Lamarckism as we all know that only the information in the genotype can be transmitted. However, from a computation viewpoint, it has been shown that adopting the Lamarckian model gives good results for some of the problems. In the Lamarckian model, a local search operator examines the neighborhood (acquiring new traits), and if a better chromosome is found, it becomes the offspring. .
| The Baldwinian model is an intermediate idea named after James Mark Baldwin. In the Baldwin model, the chromosomes can encode a tendency of learning beneficial behaviors. This means, that unlike the Lamarckian model, we don’t transmit the acquired traits to the next generation, and neither do we completely ignore the acquired traits like in the Darwinian Model. The Baldwin Model is in the middle of these two extremes, wherein the tendency of an individual to acquire certain traits is encoded rather than the traits themselves. In this Baldwinian Model, a local search operator examines the neighborhood (acquiring new traits), and if a better chromosome is found, it only assigns the improved fitness to the chromosome and does not modify the chromosome itself. The change in fitness signifies the chromosomes capability to “acquire the trait”, even though it is not passed directly to the future generations |
Q6) What is the population in GA?
A6)
The population is a subset of solutions in the current generation. It can also be defined as a set of chromosomes.
There are several things to be kept in mind when dealing with the GA population−
- The diversity of the population should be maintained otherwise it might lead to premature convergence.
- The population size should not be kept very large as it can cause a GA to slow down, while a smaller population might not be enough for a good mating pool. Therefore, an optimal population size needs to be decided by trial and error.
The population is usually defined as a two-dimensional array of – size population, size x, chromosome size.
Population Initialization
There are two primary methods to initialize a population in a GA.
They are −
- Random Initialization − Populate the initial population with completely random solutions.
- Heuristic initialization − Populate the initial population using a known heuristic for the problem.
Q7) Explain the update q function briefly.
A7)
In the update q function there are a couple of variables used to do the following tasks:
- Adjust our q-values based on the difference between the discounted new values and old values.
- Discount the new values using the gamma and we adjust our step size using learning rate (LR). Below are some references.
Learning Rate: LR or learning rate, often referred to as alpha or α, can simply be defined as how much you accept the new value vs the old value. Above we are taking the difference between new and old and then multiplying that value by the learning rate. This value then gets added to our previous q-value which essentially moves it in the direction of our latest update.
Gamma: gamma or γ is a discount factor. It’s used to balance immediate and future rewards. From our update rule above you can see that we apply the discount to the future reward. Typically this value can range anywhere from 0.8 to 0.99.
Reward: reward is the value received after completing a certain action at a given state. A reward can happen at any given time step or only at the terminal time step.
Max: np.max() uses the NumPy library and is taking the maximum of the future reward and applying it to the reward for the current state. What this does is impact the current action by the possible future reward. This is the beauty of q-learning. We’re allocating future rewards to current actions to help the agent select the highest return action at any given state.
Q8) What are the different types of Reinforcement learning?
A8)
There are two types of Reinforcement:
Positive
Positive Reinforcement is defined as when an event, occurs due to a particular behavior, increases the strength and the frequency of the behavior. In other words, it has a positive effect on behavior.
Advantages:
- Maximizes Performance
- Sustain Change for a long period
- Disadvantages of reinforcement learning:
- Too much Reinforcement can lead to an overload of states which can diminish the results
Negative
Negative Reinforcement is defined as strengthening of behavior because a negative condition is stopped or avoided.
Advantages:
- Increases Behavior
- Provide defiance to a minimum standard of performance
- Disadvantages of reinforcement learning:
- It Only provides enough to meet up the minimum behavior
Various Practical applications of Reinforcement Learning –
RL can be used in robotics for industrial automation.
RL can be used in machine learning and data processing
RL can be used to create training systems that provide custom instruction and materials according to the requirement of students.
RL can be used in large environments in the following situations:
A model of the environment is known, but an analytic solution is not available;
Only a simulation model of the environment is given (the subject of simulation-based optimization)
The only way to collect information about the environment is to interact with it.
Q9) Explain GA and its importance.
A9)
A GA has most commonly been applied to optimization problems outside machine learning, such as design optimization problems. When applied to learning tasks, GA is especially suited to tasks in which hypotheses are complex (e.g., sets of rules for robot control, or computer programs), and in which the objects to be optimized may be an indirect function of the hypothesis (e.g., that the set of acquired rules successfully controls a robot).
Genetic programming is a variant of genetic algorithms in which the hypotheses being manipulated are computer programs rather than bit strings. Operations such as crossover and mutation are generalized to apply to programs rather than bit strings. Genetic programming has been demonstrated to learn programs for tasks such as simulated robot control and recognizing objects in visual scenes
Q10) Describe the process of hypothesis space search.
A10)
GA employs a randomized beam search method to seek a maximally fit hypothesis. This search is quite different from that of other learning methods. To contrast the hypothesis space search of GA with that of neural network BACKPROPAGATION, for example, the gradient descent search propagates smoothly from one hypothesis to a new hypothesis that is very similar. In contrast, the GA search can move much more abruptly, replacing a parent hypothesis with an offspring that may be radically different from the parent.
Note the GA search is therefore less likely to fall into the same kind of local minima that can plague gradient descent methods. One practical difficulty in some GA applications is the problem of crowding. Crowding is a phenomenon in which some individual that is more highly fit than others in the population quickly reproduces so that copies of this individual and very similar individuals take over a large fraction of the population.
The negative impact of crowding is that it reduces the diversity of the population, thereby slowing further progress by the GA. Several strategies have been explored for reducing crowding. One approach is to alter the selection function, using criteria such as tournament selection or rank selection in place of fitness proportionate roulette wheel selection. A related strategy is "fitness sharing," in which the measured fitness of an individual is reduced by the presence of other, similar individuals in the population.
A third approach is to restrict the kinds of individuals allowed to recombine to form offspring. For example, by allowing only the most similar individuals to recombine, we can encourage the formation of clusters of similar individuals, or multiple "subspecies" within the population.
A related approach is to spatially distribute individuals and allow only nearby individuals to recombine. Many of these techniques are inspired by the analogy to biological evolution.




