Unit - 4
Database Design & Query Processing
Q.1) Describe functional dependency with types?
Ans: Functional dependency
Functional Dependency (FD) is a constraint in a database management system system that specifies the relationship of one attribute to another attribute (DBMS). Functional Dependency helps to maintain the database's data quality. Finding the difference between good and poor database design plays a critical role.
The arrow "→" signifies a functional dependence. X→ Y is defined by the functional dependence of X on Y.
Rules of functional dependencies
The three most important rules for Database Functional Dependence are below:
● Reflexive law—. X holds a value of Y if X is a set of attributes and Y is a subset of X.
● Augmentation rule: If x -> y holds, and c is set as an attribute, then ac -> by holds as well. That is to add attributes that do not modify the fundamental dependencies.
● Transitivity law: If x -> y holds and y -> z holds, this rule is very similar to the transitive rule in algebra, then x -> z also holds. X -> y is referred to as functionally evaluating y.
Types of functional dependency
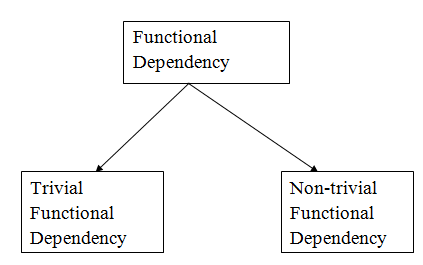
1. Trivial functional dependency
● A → B has trivial functional dependency if B is a subset of A.
● The following dependencies are also trivial like: A → A, B → B
Example
Consider a table with two columns Employee_Id and Employee_Name.
{Employee_id, Employee_Name} → Employee_Id is a trivial functional dependency as
Employee_Id is a subset of {Employee_Id, Employee_Name}.
Also, Employee_Id → Employee_Id and Employee_Name → Employee_Name are trivial dependencies too.
2. Non - trivial functional dependencies
● A → B has a non-trivial functional dependency if B is not a subset of A.
● When An intersection B is NULL, then A → B is called as complete non-trivial.
Example:
ID → Name,
Name → DOB
Q.2) Write the objectives of normalization?
Ans: Normalization
Normalization is the method of structuring and maintaining the data relationship to eliminate duplication in the relational table and prevent the database's unwanted anomaly properties, such as insertion, update and delete. This helps to break large database tables into smaller tables and to create a link between them. Redundant data can be removed and table fields can be easily added, manipulated or deleted.
For the relational table, a normalization sets out rules as to whether it follows the normal form. A normal form is a method that evaluates each relationship against specified criteria and eliminates from a relationship the multivalued, joined, functional and trivial dependence. If any data is modified, removed or added, database tables do not create any issues and help improve the consistency and performance of the relational table.
Objectives of Normalization
● It is used to delete redundant information and anomalies in the database from the relational table.
● Normalization improves by analyzing new data types used in the table to reduce consistency and complexity.
● Dividing the broad database table into smaller tables and connecting them using a relationship is helpful.
● This avoids duplicating data into a table or not repeating classes.
● It decreases the probability of anomalies in a database occurring.
Q.3) What do you mean by anomalies?
Ans: Anomalies
A relation that has redundant data may have update anomalies. These anomalies are
Classified as: -
1. Insertion Anomalies.
2. Deletion Anomalies.
3. Modification Anomalies.
Insertion Anomalies
These can be differentiated into two types: -
To insert new employee tuples in Emp_dept, we must enter values for dept or NULL if the employee does not work for the department.
Case I: -
To insert new employee record into Emp_Dept:
Ename=Kunal, Ssn=777, bdate=6/6/93, Address=Pune, Dno=21.
Now, Dno=21 is already existing in dept relation so, while inserting this into
Emp_dept
Dname must be IT.
Dmgr_Ssn must be 123.
If these values are incorrect, these will be consistency problem.
Case II: -
This problem will not occur if we consider employee and department relationship. Because for employee we will enter only dno=21, Remaining information of department will be recorded in dept relation only once. So, there will be no problem of consistency
To insert new department tuple in Emp_Dept relation this has
No employees as yet:
Dno=51, Dname=Civil, Dmgr_Ssn=321
Case I: -
To insert this into Emp_Dept, we’ve to set:
Ename=NULL
Ssn=NULL
Address=NULL
Dno=51
Dname=Civil
Dmgr_Ssn=321
But we cannot set Ssn=NULL as it is primary key of relation.
Case II: -
This problem will not occur if we consider Employee and department relation. Because dept is entered in department relation whether /not any employee works for it.
Deletion Anomalies
Case I: -
Consider, first row of Emp_Dept, where Dno=21. Digvijay is the only employee working for Dno=21. So, if we delete this line, the information regarding Dno=21 will get lost.
Case II: -
This is not the case for relation employees Department. If we delete record from
Employee (Dno=21) Digvijay, the dept info will remain in table department separately.
Modification Anomalies
In Emp_Dept, if we change the value of one of the attributes of a particular depths
Manager for dept_no.31 i.e., we change Dmgr_Ssn (456 to 765), then we must update the tuples of all employees who work in that dept, otherwise database will become
Inconsistent.
A database should be designed so that it has no insertion, deletion or modification
Anomalies. A database without any anomaly will work correctly and it will be consistent.
Q.4) How to measure a query cost?
Ans: Measure a query cost
The cost of query evaluation can be measured in terms of number of different resources used, including disk accesses, CPU time to execute given query, and, in a distributed database or parallel database system. In large database systems, however, the cost to access data from disk is usually the most important cost, since disk accesses are slow compared to in-memory operations.
Moreover, CPU speeds have been improving much faster than have disk speeds. The CPU time taken for a task is harder to estimate since it depends on low-level details of the execution.
The time taken by CPU is negligible in most systems when compared with the number of disk accesses.
If we consider the number of block transfers as the main component in calculating the cost of a query, it would include more sub-components. Those are as below:
Rotational latency – time taken to bring and turn the required data under the read-write head of the disk.
Seek time – It is the time taken to position the read-write head over the required track or cylinder.
Sequential I/O – reading data that are stored in contiguous blocks of the disk
Random I/O – reading data that are stored in different blocks of the disk that are not
Contiguous.
From these sub-components, we would list the components of a more accurate measure as follows;
● The number of seek operations performed
● The number of blocks read operations performed
● The number of blocks written operations performed
Hence, the total query cost can be written as follows;
Query cost = (Number of seek operations X average seek time) +
(Number of blocks read X average transfer time for reading a block) +
(Number of blocks written X average transfer time for writing a block).
Q.5) What is the 1NF ?
Ans: 1NF normal forms
A relation r is in 1NF if and only if every tuple contains only atomic attributes means exactly one value for each attribute. As per the rule of first normal form, an attribute of a table cannot hold multiple values. It should hold only atomic values.
Example: suppose Company has created an employee table to store name, address and mobile number of employees.
Emp_id | Emp_name | Emp_address | Emp_mobile |
101 | Rachel | Mumbai | 9817312390 |
102 | John | Pune | 7812324252, 9890012244 |
103 | Kim | Chennai | 9878381212 |
104 | Mary | Bangalore | 9895000123, 7723455987 |
In above table, two employees John, Mary has two mobile numbers. So, the attribute,
Emp_mobile is Multivalued attribute.
So, this table is not in 1NF as the rule says, “Each attribute of a table must have atomic
Values”. But in above table the the attribute, emp_mobile, is not atomic attribute as it
Contains multiple values. So, it violates the rule of 1 NF.
Following solution brings employee table in 1NF.
Emp_id | Emp_name | Emp_address | Emp_mobile |
101 | Rachel | Mumbai | 9817312390 |
102 | John | Pune | 7812324252 |
102 | John | Pune | 9890012244 |
103 | Kim | Chennai | 9878381212 |
104 | Mary | Bangalore | 9895000123 |
104 | Mary | Bangalore | 7723455987 |
Q.6) What is the Boyce Codd normal form (BCNF)?
Ans: Boyce Codd normal form (BCNF)
It is an advance version of 3NF. BCNF is stricter than 3NF. A table complies with BCNF if it is in 3NF and for every functional dependency X-> Y, X should be the super key of the table.
Example: Suppose there is a company wherein employees work in more than one
Department. They store the data like this:
Emp_id | Emp_nationality | Emp_dept | Dept_type | Dept_no_of_emp |
101 | Indian | Planning | D01 | 100 |
101 | Indian | Accounting | D01 | 50 |
102 | Japanese | Technical support | D14 | 300 |
102 | Japanese | Sales | D14 | 100 |
Functional dependencies in the table above:
Emp_id ->emp_nationality
Emp_dept -> {dept_type, dept_no_of_emp}
Candidate key: {emp_id, emp_dept}
The table is not in BCNF as neither emp_id nor emp_dept alone are keys. To bring this table in BCNF we can break this table in three tables like:
Emp_nationality table:
Emp_id | Emp_nationality |
101 | Indian |
102 | Japanese |
Emp_dept table:
Emp_dept | Dept_type | Dept_no_of_emp |
Planning | D01 | 100 |
Accounting | D01 | 50 |
Technical support | D14 | 300 |
Sales | D14 | 100 |
Emp_dept_mapping table:
Emp_id | Emp_dept |
101 | Planning |
101 | Accounting |
102 | Technical support |
102 | Sales |
Functional dependencies:
Emp_id ->; emp_nationality
Emp_dept -> {dept_type, dept_no_of_emp}
Candidate keys:
For first table: emp_id
For second table: emp_dept
For third table: {emp_id, emp_dept}
This is now in BCNF as in both functional dependencies left side is a key.
Q.7) Explain selection and join operation?
Ans: Selection operation
Algorithm A1 (linear search):
It Scans each file block and test all records to see whether they satisfy the selection
Condition. Following factors are considered in this algorithm:
● Cost estimate (number of disk blocks scanned) = br. Br denotes number of blocks containing records from relation r.
● If selection is on a key attribute, cost = (br /2) “stop on finding record.
● Linear search can be applied regardless of " selection condition” or “ordering of records in the file”, or “availability of indices”
Algorithm A2 (binary search):
It is applicable if selection is an equality comparison on the attribute on which file is ordered.
Assume that the blocks of a relation are stored contiguously. Following factors are
Considered in this algorithm:
Cost estimate (number of disk blocks to be scanned): log2(br) — cost of locating the first tuple by a binary search on the blocks plus number of blocks containing records that satisfy selection condition.
Join Operations:
There are several different algorithms that can be used to implement joins (natural-, equi-, condition-join) like:
● Nested-Loop Join
● Block Nested-Loop Join
● Index Nested-Loop Join
● Sort-Merge Join
● Hash-Join
Choice of a particular algorithm is based on cost estimate. For this, join size estimates are required and in particular cost estimates for outer-level operations in a relational algebra expression.
Example:
Assume the query CUSTOMERS ✶ ORDERS (with join attribute only being CName)
NCUSTOMERS = 5,000 tuples
FCUSTOMERS = 20
BCUSTOMERS = 5,000/20 = 250 blocks
NORDERS = 10,000 tuples
FORDERS = 25, i.e., BORDERS = 400 blocks
V (CName, ORDERS) = 2,500, meaning that in this relation, on average, each customer has four orders – Also assume that CName in ORDERS is a foreign key on CUSTOMERS
Q.8) What do you mean by 3NF?
Ans: 3NF (Third Normal Forms)
A table design is said to be in 3NF if both the following conditions hold:
● Table must be in 2NF.
● Transitive functional dependency from the relation must be removed.
So, it can be stated that, a table is in 3NF if it is in 2NF and for each functional dependency
P->Q at least one of the following conditions hold:
● P is a super key of table
● Q is a prime attribute of table
An attribute that is a part of one of the candidate keys is known as prime attribute.
Transitive functional dependency:
A functional dependency is said to be transitive if it is indirectly formed by two functional dependencies.
For example:
P->R is a transitive dependency if the following three functional dependencies hold true:
1) P->Q and
2) Q->R
Example: suppose a company wants to store information about employees. Then the table Employee_Details looks like this:
Emp_id | Emp_name | Manager_id | Mgr_Dept | Mgr_Name |
E1 | Hary | M1 | IT | William |
E2 | John | M1 | IT | William |
E3 | Nil | M2 | SALES | Stephen |
E4 | Mery | M3 | HR | Johnson |
E5 | Steve | M2 | SALSE | Stephen |
Super keys: {emp_id}, {emp_id, emp_name}, {emp_id, emp_name, Manager_id}
Candidate Key: {emp_id}
Non-prime attributes: All attributes except emp_id is non-prime as they are not subpart part of any candidate keys.
Here, Mgr_Dept, Mgr_Name dependent on Manager_id. And, Manager_id is dependent on emp_id that makes non-prime attributes (Mgr_Dept, Mgr_Name) transitively dependent on super key (emp_id). This violates the rule of 3NF.
To bring this table in 3NF we have to break into two tables to remove transitive dependency.
Employee_Details table:
Emp_id | Emp_name | Manager_id |
E1 | Hary | M1 |
E2 | John | M1 |
E3 | Nil | M2 |
E4 | Mery | M3 |
E5 | Steve | M2 |
Manager_Details table:
Manager_id | Mgr_Dept | Mgr_Name |
M1 | IT | William |
M2 | SALSE | Stephen |
M3 | HR | Johnson |
Q.9) What do you mean by query processing?
Ans: Query Processing
Query processing is nothing but steps involved in retrieving data from database. These activities include translation of queries written high level database language into expressions that can be understood at the physical level of the file system. It also includes a variety of query optimizing transformations and actual evaluations of queries.
Query processing procedure
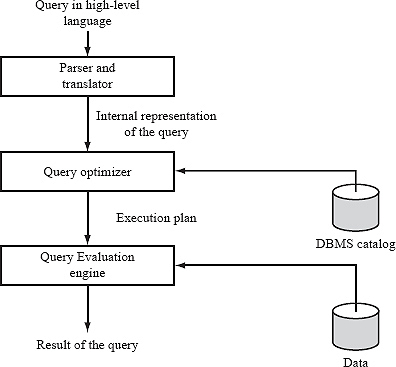
Basic steps in query processing are:
1. Parsing and translation
2. Optimization
3. Evaluation
At the beginning of query processing, the queries must be translated into a form which could be understood at the physical level of the system. A language like SQL is not suitable for the internal representation of a query. Relational algebra is the good option for internal representation of query.
So, the first step in query processing is to translate a given query into its internal
Representation. In generating internal form of a query, parser checks the syntax of the query written by user, verifies that the relation names appearing in the query really exists in the database and so on.
The system constructs a parse-tree of the query. Then this tree is translated into relational- algebra expressions. If the query was expressed in terms of a view, the translation phase replaces all uses of the view by the relational-algebra expression that defines the view.
One query can be answered in different ways. Relational-algebra representation of a query specifies only partially how to evaluate a query. There are different ways to evaluate relational-algebra expressions. Consider the query:
Select acc_balance from account where acc_balance<5000
This query can be translated into one of the following relational-algebra expressions:
1. σ acc_balance<5000 (Π acc_balance (account))
2. Πacc_balance (σ acc_balance <5000 (account))
Different algorithms are available to execute relational-algebra operation. To solve the above query, we can search every tuple in account to find the tuples having balance less than 5000. If a B + tree index is available on the balance attribute, we can use this index instead to search for the required tuples.
To specify how to evaluate a query, we need not only to provide the relational-algebra expression, but also to explain it with instructions specifying the procedure for evaluation of each operation.
Account_id | Cust_id | Acc_Balance |
Account Relation
Cust_id | Cust_Name |
Customer Relation
Πacc_balance
↓
σ acc_balance <5000; use index 1
↓
Account
A relational-algebra operation along with instructions on how to evaluate it is called an evaluation primitive. A sequence of primitive operations that can be used in the evaluation of a query is called a query execution plan or query evaluation plan. Above figure illustrates an evaluation plan for our example query, in which a particular index is specified for the selection operation from database. The query execution engine takes a query evaluation plan, executes that plan, and returns the answer to the query.
Different evaluation plans have different costs. It is the responsibility of the system to
Construct a query evaluation plan that minimizes the cost of query evaluation; this task is called Query Optimization. Once the query plan with minimum cost is chosen, the query is evaluated with the plan, and the result of the query is the output. In order to optimize a query, a query optimizer must know the cost of each operation.
Although the exact cost is hard to compute, it is possible to get a rough estimate of
Execution cost for each operation. Exact cost is hard for computation because it depends on many parameters such as actual memory available to execute the operation.
Q.10) Write short notes on pipelining algorithm?
Ans: Pipelining algorithm
The query evaluation cost is increased due to temporary relations. This increased cost can be minimized by reducing the number of temporary files that are produced. This reduction can be achieved by combining several relational operations into a pipeline of operations, in which the results of one operation are passed along to next operation in the pipeline. This kind of evaluation is called as a pipelined evaluation.
For example, in the previous expression tree, no need to store the result of intermediate select operation in temporary relation; instead, pass tuples directly to the join operation.
Similarly, do not store the result of join, but pass tuples directly to project operation.
So, the benefits of pipelining are:
● Pipelining is less costly than materialization.
● No need to store a temporary relation to disk.
For pipelining to be effective, use evaluation algorithms that generate output tuples even as tuples are received for inputs to the operation Pipelines can be executed in two ways:
● demand driven
● producer driven
Demand Driven:
In a demand driven pipeline, the system makes repeated requests for the tuples from the operation at the top of the pipeline. Each time that an operation receives a request for tuples, it computes the next tuple to be returned, and then returns that tuple. If the inputs of the operations are not pipelined, the next tuple to be returned can be computed from the input relations. If it has some pipelined inputs, the operation also makes requests for tuples from its pipelined inputs. Using the tuples received from its pipelined inputs, the operation computes tuples for its output, and passes them up to parent.
Produced Driven:
In a produced driven pipeline method, operations do not wait for requests to produce tuples, but instead generate the tuples eagerly. Each operation at the bottom of a pipeline continually generates output tuples, and puts them in its output buffer, until buffer is full. An operation at any other level of a pipeline generates output tuples when it gets input tuples from lower down in the pipeline, until its output buffer is full. Once the operation uses a tuple from a pipelined input, it removes the tuples from its input buffer. In either case, once the output buffer is full, the operation waits until its parent operation removes tuples from the buffer, so that the buffer has space for more tuples. At this point, the operation generates more tuples, until the buffer is full again. The operation repeats this process until all the
Output tuples have been generated.
Unit - 4
Database Design & Query Processing
Q.1) Describe functional dependency with types?
Ans: Functional dependency
Functional Dependency (FD) is a constraint in a database management system system that specifies the relationship of one attribute to another attribute (DBMS). Functional Dependency helps to maintain the database's data quality. Finding the difference between good and poor database design plays a critical role.
The arrow "→" signifies a functional dependence. X→ Y is defined by the functional dependence of X on Y.
Rules of functional dependencies
The three most important rules for Database Functional Dependence are below:
● Reflexive law—. X holds a value of Y if X is a set of attributes and Y is a subset of X.
● Augmentation rule: If x -> y holds, and c is set as an attribute, then ac -> by holds as well. That is to add attributes that do not modify the fundamental dependencies.
● Transitivity law: If x -> y holds and y -> z holds, this rule is very similar to the transitive rule in algebra, then x -> z also holds. X -> y is referred to as functionally evaluating y.
Types of functional dependency
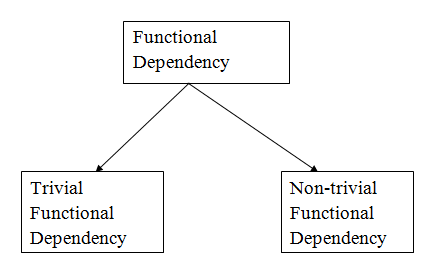
1. Trivial functional dependency
● A → B has trivial functional dependency if B is a subset of A.
● The following dependencies are also trivial like: A → A, B → B
Example
Consider a table with two columns Employee_Id and Employee_Name.
{Employee_id, Employee_Name} → Employee_Id is a trivial functional dependency as
Employee_Id is a subset of {Employee_Id, Employee_Name}.
Also, Employee_Id → Employee_Id and Employee_Name → Employee_Name are trivial dependencies too.
2. Non - trivial functional dependencies
● A → B has a non-trivial functional dependency if B is not a subset of A.
● When An intersection B is NULL, then A → B is called as complete non-trivial.
Example:
ID → Name,
Name → DOB
Q.2) Write the objectives of normalization?
Ans: Normalization
Normalization is the method of structuring and maintaining the data relationship to eliminate duplication in the relational table and prevent the database's unwanted anomaly properties, such as insertion, update and delete. This helps to break large database tables into smaller tables and to create a link between them. Redundant data can be removed and table fields can be easily added, manipulated or deleted.
For the relational table, a normalization sets out rules as to whether it follows the normal form. A normal form is a method that evaluates each relationship against specified criteria and eliminates from a relationship the multivalued, joined, functional and trivial dependence. If any data is modified, removed or added, database tables do not create any issues and help improve the consistency and performance of the relational table.
Objectives of Normalization
● It is used to delete redundant information and anomalies in the database from the relational table.
● Normalization improves by analyzing new data types used in the table to reduce consistency and complexity.
● Dividing the broad database table into smaller tables and connecting them using a relationship is helpful.
● This avoids duplicating data into a table or not repeating classes.
● It decreases the probability of anomalies in a database occurring.
Q.3) What do you mean by anomalies?
Ans: Anomalies
A relation that has redundant data may have update anomalies. These anomalies are
Classified as: -
1. Insertion Anomalies.
2. Deletion Anomalies.
3. Modification Anomalies.
Insertion Anomalies
These can be differentiated into two types: -
To insert new employee tuples in Emp_dept, we must enter values for dept or NULL if the employee does not work for the department.
Case I: -
To insert new employee record into Emp_Dept:
Ename=Kunal, Ssn=777, bdate=6/6/93, Address=Pune, Dno=21.
Now, Dno=21 is already existing in dept relation so, while inserting this into
Emp_dept
Dname must be IT.
Dmgr_Ssn must be 123.
If these values are incorrect, these will be consistency problem.
Case II: -
This problem will not occur if we consider employee and department relationship. Because for employee we will enter only dno=21, Remaining information of department will be recorded in dept relation only once. So, there will be no problem of consistency
To insert new department tuple in Emp_Dept relation this has
No employees as yet:
Dno=51, Dname=Civil, Dmgr_Ssn=321
Case I: -
To insert this into Emp_Dept, we’ve to set:
Ename=NULL
Ssn=NULL
Address=NULL
Dno=51
Dname=Civil
Dmgr_Ssn=321
But we cannot set Ssn=NULL as it is primary key of relation.
Case II: -
This problem will not occur if we consider Employee and department relation. Because dept is entered in department relation whether /not any employee works for it.
Deletion Anomalies
Case I: -
Consider, first row of Emp_Dept, where Dno=21. Digvijay is the only employee working for Dno=21. So, if we delete this line, the information regarding Dno=21 will get lost.
Case II: -
This is not the case for relation employees Department. If we delete record from
Employee (Dno=21) Digvijay, the dept info will remain in table department separately.
Modification Anomalies
In Emp_Dept, if we change the value of one of the attributes of a particular depths
Manager for dept_no.31 i.e., we change Dmgr_Ssn (456 to 765), then we must update the tuples of all employees who work in that dept, otherwise database will become
Inconsistent.
A database should be designed so that it has no insertion, deletion or modification
Anomalies. A database without any anomaly will work correctly and it will be consistent.
Q.4) How to measure a query cost?
Ans: Measure a query cost
The cost of query evaluation can be measured in terms of number of different resources used, including disk accesses, CPU time to execute given query, and, in a distributed database or parallel database system. In large database systems, however, the cost to access data from disk is usually the most important cost, since disk accesses are slow compared to in-memory operations.
Moreover, CPU speeds have been improving much faster than have disk speeds. The CPU time taken for a task is harder to estimate since it depends on low-level details of the execution.
The time taken by CPU is negligible in most systems when compared with the number of disk accesses.
If we consider the number of block transfers as the main component in calculating the cost of a query, it would include more sub-components. Those are as below:
Rotational latency – time taken to bring and turn the required data under the read-write head of the disk.
Seek time – It is the time taken to position the read-write head over the required track or cylinder.
Sequential I/O – reading data that are stored in contiguous blocks of the disk
Random I/O – reading data that are stored in different blocks of the disk that are not
Contiguous.
From these sub-components, we would list the components of a more accurate measure as follows;
● The number of seek operations performed
● The number of blocks read operations performed
● The number of blocks written operations performed
Hence, the total query cost can be written as follows;
Query cost = (Number of seek operations X average seek time) +
(Number of blocks read X average transfer time for reading a block) +
(Number of blocks written X average transfer time for writing a block).
Q.5) What is the 1NF ?
Ans: 1NF normal forms
A relation r is in 1NF if and only if every tuple contains only atomic attributes means exactly one value for each attribute. As per the rule of first normal form, an attribute of a table cannot hold multiple values. It should hold only atomic values.
Example: suppose Company has created an employee table to store name, address and mobile number of employees.
Emp_id | Emp_name | Emp_address | Emp_mobile |
101 | Rachel | Mumbai | 9817312390 |
102 | John | Pune | 7812324252, 9890012244 |
103 | Kim | Chennai | 9878381212 |
104 | Mary | Bangalore | 9895000123, 7723455987 |
In above table, two employees John, Mary has two mobile numbers. So, the attribute,
Emp_mobile is Multivalued attribute.
So, this table is not in 1NF as the rule says, “Each attribute of a table must have atomic
Values”. But in above table the the attribute, emp_mobile, is not atomic attribute as it
Contains multiple values. So, it violates the rule of 1 NF.
Following solution brings employee table in 1NF.
Emp_id | Emp_name | Emp_address | Emp_mobile |
101 | Rachel | Mumbai | 9817312390 |
102 | John | Pune | 7812324252 |
102 | John | Pune | 9890012244 |
103 | Kim | Chennai | 9878381212 |
104 | Mary | Bangalore | 9895000123 |
104 | Mary | Bangalore | 7723455987 |
Q.6) What is the Boyce Codd normal form (BCNF)?
Ans: Boyce Codd normal form (BCNF)
It is an advance version of 3NF. BCNF is stricter than 3NF. A table complies with BCNF if it is in 3NF and for every functional dependency X-> Y, X should be the super key of the table.
Example: Suppose there is a company wherein employees work in more than one
Department. They store the data like this:
Emp_id | Emp_nationality | Emp_dept | Dept_type | Dept_no_of_emp |
101 | Indian | Planning | D01 | 100 |
101 | Indian | Accounting | D01 | 50 |
102 | Japanese | Technical support | D14 | 300 |
102 | Japanese | Sales | D14 | 100 |
Functional dependencies in the table above:
Emp_id ->emp_nationality
Emp_dept -> {dept_type, dept_no_of_emp}
Candidate key: {emp_id, emp_dept}
The table is not in BCNF as neither emp_id nor emp_dept alone are keys. To bring this table in BCNF we can break this table in three tables like:
Emp_nationality table:
Emp_id | Emp_nationality |
101 | Indian |
102 | Japanese |
Emp_dept table:
Emp_dept | Dept_type | Dept_no_of_emp |
Planning | D01 | 100 |
Accounting | D01 | 50 |
Technical support | D14 | 300 |
Sales | D14 | 100 |
Emp_dept_mapping table:
Emp_id | Emp_dept |
101 | Planning |
101 | Accounting |
102 | Technical support |
102 | Sales |
Functional dependencies:
Emp_id ->; emp_nationality
Emp_dept -> {dept_type, dept_no_of_emp}
Candidate keys:
For first table: emp_id
For second table: emp_dept
For third table: {emp_id, emp_dept}
This is now in BCNF as in both functional dependencies left side is a key.
Q.7) Explain selection and join operation?
Ans: Selection operation
Algorithm A1 (linear search):
It Scans each file block and test all records to see whether they satisfy the selection
Condition. Following factors are considered in this algorithm:
● Cost estimate (number of disk blocks scanned) = br. Br denotes number of blocks containing records from relation r.
● If selection is on a key attribute, cost = (br /2) “stop on finding record.
● Linear search can be applied regardless of " selection condition” or “ordering of records in the file”, or “availability of indices”
Algorithm A2 (binary search):
It is applicable if selection is an equality comparison on the attribute on which file is ordered.
Assume that the blocks of a relation are stored contiguously. Following factors are
Considered in this algorithm:
Cost estimate (number of disk blocks to be scanned): log2(br) — cost of locating the first tuple by a binary search on the blocks plus number of blocks containing records that satisfy selection condition.
Join Operations:
There are several different algorithms that can be used to implement joins (natural-, equi-, condition-join) like:
● Nested-Loop Join
● Block Nested-Loop Join
● Index Nested-Loop Join
● Sort-Merge Join
● Hash-Join
Choice of a particular algorithm is based on cost estimate. For this, join size estimates are required and in particular cost estimates for outer-level operations in a relational algebra expression.
Example:
Assume the query CUSTOMERS ✶ ORDERS (with join attribute only being CName)
NCUSTOMERS = 5,000 tuples
FCUSTOMERS = 20
BCUSTOMERS = 5,000/20 = 250 blocks
NORDERS = 10,000 tuples
FORDERS = 25, i.e., BORDERS = 400 blocks
V (CName, ORDERS) = 2,500, meaning that in this relation, on average, each customer has four orders – Also assume that CName in ORDERS is a foreign key on CUSTOMERS
Q.8) What do you mean by 3NF?
Ans: 3NF (Third Normal Forms)
A table design is said to be in 3NF if both the following conditions hold:
● Table must be in 2NF.
● Transitive functional dependency from the relation must be removed.
So, it can be stated that, a table is in 3NF if it is in 2NF and for each functional dependency
P->Q at least one of the following conditions hold:
● P is a super key of table
● Q is a prime attribute of table
An attribute that is a part of one of the candidate keys is known as prime attribute.
Transitive functional dependency:
A functional dependency is said to be transitive if it is indirectly formed by two functional dependencies.
For example:
P->R is a transitive dependency if the following three functional dependencies hold true:
1) P->Q and
2) Q->R
Example: suppose a company wants to store information about employees. Then the table Employee_Details looks like this:
Emp_id | Emp_name | Manager_id | Mgr_Dept | Mgr_Name |
E1 | Hary | M1 | IT | William |
E2 | John | M1 | IT | William |
E3 | Nil | M2 | SALES | Stephen |
E4 | Mery | M3 | HR | Johnson |
E5 | Steve | M2 | SALSE | Stephen |
Super keys: {emp_id}, {emp_id, emp_name}, {emp_id, emp_name, Manager_id}
Candidate Key: {emp_id}
Non-prime attributes: All attributes except emp_id is non-prime as they are not subpart part of any candidate keys.
Here, Mgr_Dept, Mgr_Name dependent on Manager_id. And, Manager_id is dependent on emp_id that makes non-prime attributes (Mgr_Dept, Mgr_Name) transitively dependent on super key (emp_id). This violates the rule of 3NF.
To bring this table in 3NF we have to break into two tables to remove transitive dependency.
Employee_Details table:
Emp_id | Emp_name | Manager_id |
E1 | Hary | M1 |
E2 | John | M1 |
E3 | Nil | M2 |
E4 | Mery | M3 |
E5 | Steve | M2 |
Manager_Details table:
Manager_id | Mgr_Dept | Mgr_Name |
M1 | IT | William |
M2 | SALSE | Stephen |
M3 | HR | Johnson |
Q.9) What do you mean by query processing?
Ans: Query Processing
Query processing is nothing but steps involved in retrieving data from database. These activities include translation of queries written high level database language into expressions that can be understood at the physical level of the file system. It also includes a variety of query optimizing transformations and actual evaluations of queries.
Query processing procedure
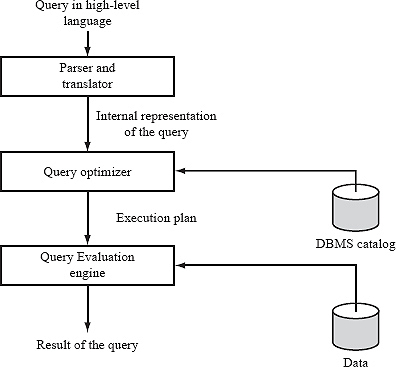
Basic steps in query processing are:
1. Parsing and translation
2. Optimization
3. Evaluation
At the beginning of query processing, the queries must be translated into a form which could be understood at the physical level of the system. A language like SQL is not suitable for the internal representation of a query. Relational algebra is the good option for internal representation of query.
So, the first step in query processing is to translate a given query into its internal
Representation. In generating internal form of a query, parser checks the syntax of the query written by user, verifies that the relation names appearing in the query really exists in the database and so on.
The system constructs a parse-tree of the query. Then this tree is translated into relational- algebra expressions. If the query was expressed in terms of a view, the translation phase replaces all uses of the view by the relational-algebra expression that defines the view.
One query can be answered in different ways. Relational-algebra representation of a query specifies only partially how to evaluate a query. There are different ways to evaluate relational-algebra expressions. Consider the query:
Select acc_balance from account where acc_balance<5000
This query can be translated into one of the following relational-algebra expressions:
1. σ acc_balance<5000 (Π acc_balance (account))
2. Πacc_balance (σ acc_balance <5000 (account))
Different algorithms are available to execute relational-algebra operation. To solve the above query, we can search every tuple in account to find the tuples having balance less than 5000. If a B + tree index is available on the balance attribute, we can use this index instead to search for the required tuples.
To specify how to evaluate a query, we need not only to provide the relational-algebra expression, but also to explain it with instructions specifying the procedure for evaluation of each operation.
Account_id | Cust_id | Acc_Balance |
Account Relation
Cust_id | Cust_Name |
Customer Relation
Πacc_balance
↓
σ acc_balance <5000; use index 1
↓
Account
A relational-algebra operation along with instructions on how to evaluate it is called an evaluation primitive. A sequence of primitive operations that can be used in the evaluation of a query is called a query execution plan or query evaluation plan. Above figure illustrates an evaluation plan for our example query, in which a particular index is specified for the selection operation from database. The query execution engine takes a query evaluation plan, executes that plan, and returns the answer to the query.
Different evaluation plans have different costs. It is the responsibility of the system to
Construct a query evaluation plan that minimizes the cost of query evaluation; this task is called Query Optimization. Once the query plan with minimum cost is chosen, the query is evaluated with the plan, and the result of the query is the output. In order to optimize a query, a query optimizer must know the cost of each operation.
Although the exact cost is hard to compute, it is possible to get a rough estimate of
Execution cost for each operation. Exact cost is hard for computation because it depends on many parameters such as actual memory available to execute the operation.
Q.10) Write short notes on pipelining algorithm?
Ans: Pipelining algorithm
The query evaluation cost is increased due to temporary relations. This increased cost can be minimized by reducing the number of temporary files that are produced. This reduction can be achieved by combining several relational operations into a pipeline of operations, in which the results of one operation are passed along to next operation in the pipeline. This kind of evaluation is called as a pipelined evaluation.
For example, in the previous expression tree, no need to store the result of intermediate select operation in temporary relation; instead, pass tuples directly to the join operation.
Similarly, do not store the result of join, but pass tuples directly to project operation.
So, the benefits of pipelining are:
● Pipelining is less costly than materialization.
● No need to store a temporary relation to disk.
For pipelining to be effective, use evaluation algorithms that generate output tuples even as tuples are received for inputs to the operation Pipelines can be executed in two ways:
● demand driven
● producer driven
Demand Driven:
In a demand driven pipeline, the system makes repeated requests for the tuples from the operation at the top of the pipeline. Each time that an operation receives a request for tuples, it computes the next tuple to be returned, and then returns that tuple. If the inputs of the operations are not pipelined, the next tuple to be returned can be computed from the input relations. If it has some pipelined inputs, the operation also makes requests for tuples from its pipelined inputs. Using the tuples received from its pipelined inputs, the operation computes tuples for its output, and passes them up to parent.
Produced Driven:
In a produced driven pipeline method, operations do not wait for requests to produce tuples, but instead generate the tuples eagerly. Each operation at the bottom of a pipeline continually generates output tuples, and puts them in its output buffer, until buffer is full. An operation at any other level of a pipeline generates output tuples when it gets input tuples from lower down in the pipeline, until its output buffer is full. Once the operation uses a tuple from a pipelined input, it removes the tuples from its input buffer. In either case, once the output buffer is full, the operation waits until its parent operation removes tuples from the buffer, so that the buffer has space for more tuples. At this point, the operation generates more tuples, until the buffer is full again. The operation repeats this process until all the
Output tuples have been generated.




