Unit - 6
Advanced Databases
Q. 1) Write short notes on client server architecture?
Ans: Client - server Architecture
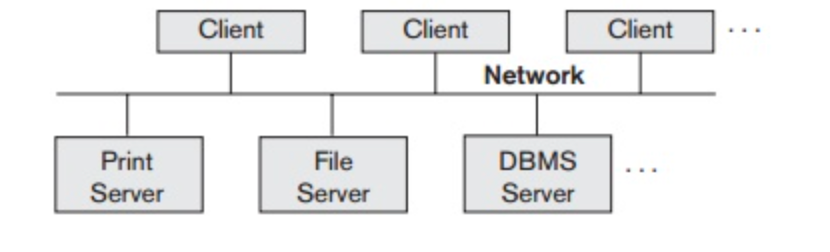
The client/server architecture has been built to deal with computer environments in which a large number of network-connected PCs, workstations, file servers, printers, database servers, web servers, email servers, and other software and devices are connected. The definition is to describe specialized servers with particular features. For example, a number of PCs or small workstations as clients can be linked to a file server that manages client machine files.
By being linked to various printers, another computer can be designated as a printer server; all print requests from the clients are forwarded to this machine. Web servers or e-mail servers often fall under the category of specialized servers. Several client machines can access the services offered by specialized servers.
The client machines provide the user with the necessary interfaces to use This principle can be transferred to other software packages, with specialized programs stored on specific server machines and made available to several clients, such as a CAD (computer-aided design) kit.
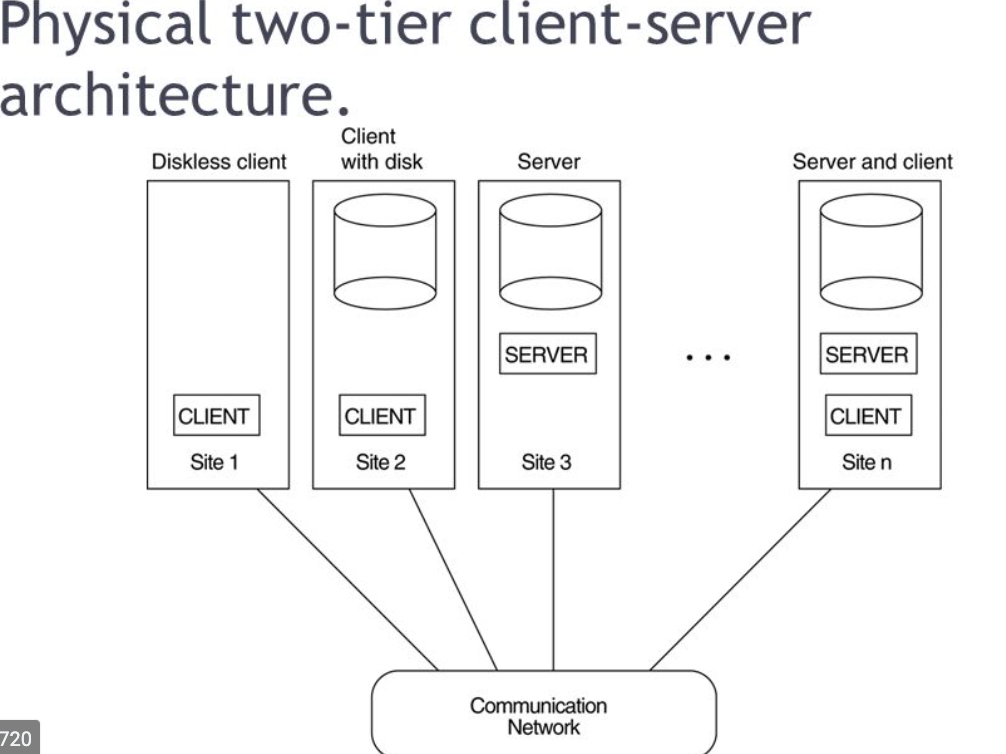
Some computers (for instance, diskless workstations or workstations/PCs with disk that only have client software installed) will be client sites only.
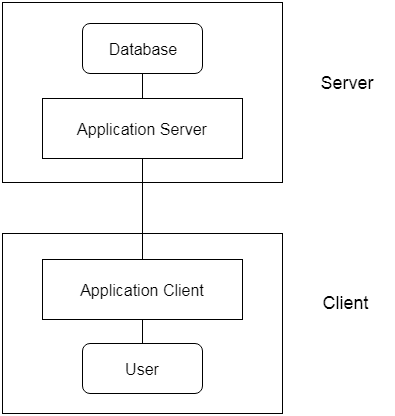
The client/server architecture principle implies an underlying structure consisting of several PCs and workstations, as well as a smaller number of mainframe machines, linked via LANs and other computer network types. A user computer that offers user interface functionality and local processing is usually a client in this framework. When a client requires access to additional functions that do not exist on that machine, such as database access, it connects to a server that provides the necessary functionality.
A server is a device that includes both hardware and software that can provide client machines with resources, such as access to files, printing, archiving, or access to databases. In general, some machines only install client software, others only server software, and still others, as shown in figure, can provide both client and server software. However, it is more common for client and server applications to run on different machines in general.
Q. 2) Explain different types of parallel database architecture?
Ans: Types of parallel database architecture
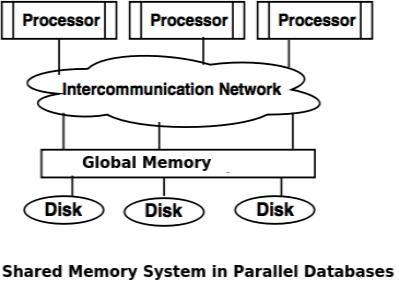
- Shared memory system
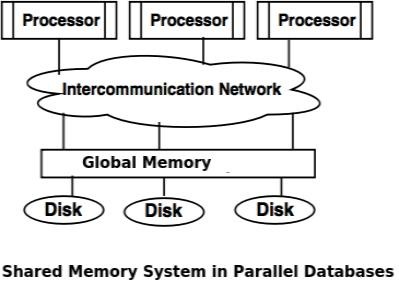
● The shared memory system uses multiple processors that are connected via an intercommunication channel or communication bus to a globally shared memory.
● There is a significant amount of cache memory on each processor in the shared memory scheme, so referencing the shared memory is avoided.
● If a processor conducts a memory location writing operation, the data should be modified or deleted from that location.
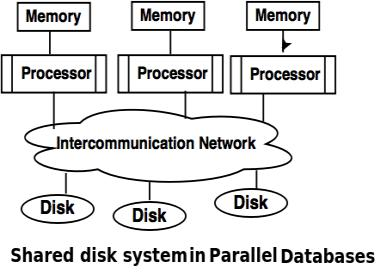
2. Shared disk system
● The shared disc system uses multiple processors that are accessible via the intercommunication channel to multiple discs, and each processor has local memory.
● Each processor has its own memory, so it is efficient to share data.
● As clusters, the structure developed around this system is referred to.
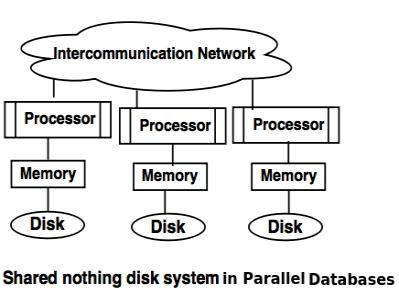
3. Shared nothing disk system
● Each processor has its own local memory and local disc in the shared nothing scheme.
● Via intercommunication channels, processors can communicate with one another.
● Any processor can serve as a server for the data stored on the local disc.
4. Hierarchical System or Non-Uniform Memory Architecture
● The hierarchical model system is a hybrid system of shared memory, shared disc, and shared nothing.
● Also known as Non-Uniform Memory Architecture, the hierarchical model is (NUMA).
● Each group of processors in this system has a local memory. But processors from other groups can access memory which is coherently linked to the other group.
● NUMA (Memory from another group) uses local and remote memory, so it will take longer to communicate with each other.
Q. 3) Describe the key elements of parallel database processing?
Ans: Key elements of parallel database processing
❏ Speedup and scaleup
❏ Synchronization
❏ Looking
❏ Messaging
- Speedup and scaleup:
In terms of two significant properties, you can measure the performance objectives of parallel processing:
Speedup:
Speedup is the extent to which more hardware than the original system can perform the same task in less time. Speedup keeps the job constant with additional hardware and calculates time savings. The figure demonstrates how half of the original task is carried out by each parallel hardware system in half the time it takes to execute it on a single system.
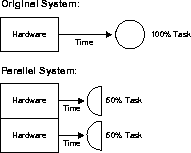
Additional processors minimize system reaction time with a good speedup. Using this formula, you can test speedup
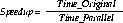
Were,
Time _parallel - Is the elapsed time spent on the specified task by a larger, parallel method.
Scaleup:
Scaleup is the factor m that shows how much more work can be performed by a machine n times larger in the same time span. A scale-up formula keeps the time constant with additional hardware, and calculates the increased size of the job that can be completed.
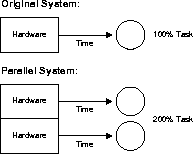
With good scale-up, by adding hardware resources such as CPUs, you can keep response time constant if transaction volumes rise.
Using this formula, you can calculate the scale: 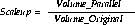
Were,
Volume _parallel - is the number of transactions performed on a parallel system in a given period of time.
2. Synchronization
Concurrent task management is called synchronization. For correctness, synchronization is important. The secret to efficient parallel processing is to break tasks such that very little synchronization is required. The less synchronization is needed, the better the pace and scale-up.
A high-speed interconnection between the parallel processors is necessary for parallel processing between nodes. If a lot of inter-node communication is needed, the overhead of this synchronization can be very costly. Messaging is not mandatory for parallel processing within a node: shared memory is used instead. The Integrated Distributed Lock Manager manages communicating and locking between nodes.
The level of synchronization depends on the number of resources and the number of resource-operating users and tasks. In order to organize a small number of concurrent tasks, little synchronization may be required, but to coordinate several concurrent tasks, a lot of synchronization may be essential.
3. Looking
Locks are fundamentally a way for activities to be coordinated. To allow the synchronization of tasks needed by parallel processing, several different locking mechanisms are necessary.
The Integrated Distributed Lock Manager (Integrated DLM or IDLM) is the Oracle Parallel Server internal locking facility. It coordinates the sharing of resources among nodes running a parallel server. Parallel server instances use the Integrated Distributed Lock Manager to communicate with each other and to organize database resource modifications. Each node, even when contending for the same resource, operates independently of other nodes.
The IDLM enables applications to synchronize access to resources such as data, software, and peripheral devices, so that applications running on different nodes can coordinate concurrent requests for the same resource.
For applications, the IDLM operates the following services:
● Keeps track of a resource's current "ownership"
● Accepts lock requests from application processes for services
● Notifies the requesting process when a lock is available on a resource
● Receives access to a framework for a process
4. Messaging
Parallel processing requires fast and effective communication between nodes: a high bandwidth and low latency device that communicates with the IDLM effectively.
Bandwidth is the cumulative size per second of messages that can be sent. Latency is the time it takes to put a message on the interconnection (in seconds). Thus, latency means the number of messages per second that can be placed on the interconnect. A high bandwidth interconnection is like a long road with several lanes to handle heavy traffic: the number of lanes influences the speed at which traffic can pass.
A low latency interconnection is like a road with an entrance ramp that allows vehicles to enter without delay: the cost of getting on the highway is low.
Networks that have relatively high bandwidth are planned for most MPP systems and clusters. On the other hand, latency is an operating system problem that mostly has to do with applications. MPP systems and most clusters characteristically use high bandwidth and low latency interconnects; other clusters can use comparatively low bandwidth and high latency Ethernet connections.
Q. 4) Write short notes on the Distributed database?
Ans: Distributed database
● A distributed database is a framework that does not link storage devices to a common processing unit.
● The Distributed Database Management System manages the database and data can be stored at the same location or distributed over an interconnected network. It is a system that is loosely coupled.
● In distributed databases, shared architecture is used for nothing.
● A common example of a distributed database system is the below diagram, in which the communication channel is used to communicate with the various locations and each system has its own memory and database.
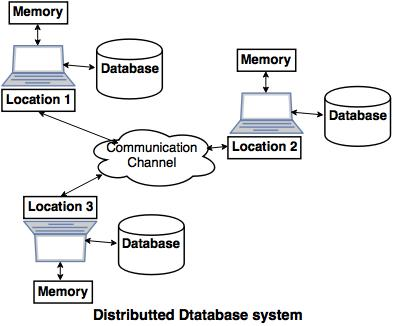
Goal of the distributed database system
The definition of distributed databases was developed with the aim of improving:
❏ Reliability
In a distributed database system, another system may complete the task if one system fails or stops running for some time.
❏ Availability
Reliability in the distributed database system can be achieved even though serious failures occur. To satisfy a client request, another framework is available.
❏ Performance
By spreading databases across multiple locations, efficiency can be achieved. The databases are therefore available for any easy-to-maintain venue.
Q. 5) What are the design techniques of distributed database?
Ans: Distributed database design technique
It is possible to split the design techniques widely into replication and fragmentation. A mixture of the two is, however, used in most situations.
Data replication
The method of storing separate copies of the database at two or more locations is data duplication. It is a popular distributed database fault tolerance technique.
Some commonly used replication techniques are −
● Snapshot replication
● Near-real-time replication
● Pull replication
Fragmentation
The process of splitting a table into a number of smaller tables is fragmentation. The table's subsets are called fragments. There may be three kinds of fragmentation: horizontal, vertical and mixed (combination of horizontal and vertical). It is further possible to divide horizontal fragmentation into two techniques: primary horizontal fragmentation and derived horizontal fragmentation.
In order for the original table to be rebuilt from the fragments, fragmentation should be done in a way. This is done so that the original table can be restored whenever possible from the fragments. This demand is referred to as "reconstructiveness."
➢ Vertical fragmentation
The fields or columns of a table are divided into fragments during vertical fragmentation. Each fragment should contain the primary key field(s) of the table to preserve reconstructiveness. To implement information protection, vertical fragmentation can be used.
For example, let us consider that in a student table with the following scheme, a university database keeps records of all registered students.
STUDENT
Regd_No | Name | Course | Address | Semester | Fees | Marks |
Now, in the accounts section, the fee details are preserved. The designer will fragment the database in this case as follows-
CREATE TABLE STD_FEES AS
SELECT Regd_No, Fees
FROM STUDENT;
➢ Horizontal Fragmentation
Horizontal fragmentation classifies the table's tuples according to the values of one or more fields. The reconstructiveness law should also be verified by horizontal fragmentation. Each horizontal fragment must contain all of the original base table columns.
In the student scheme, for example, if the records of all computer science students need to be stored at the School of Computer Science, the designer will fragment the database horizontally as follows.
CREATE COMP_STD AS
SELECT * FROM STUDENT
WHERE COURSE = "Computer Science";
➢ Hybrid fragmentation
A mixture of horizontal and vertical fragmentation methods is used in hybrid fragmentation. This is the most versatile technique of fragmentation because fragments with minimal extraneous information are produced. Reconstruction of the initial table, however, is always a costly process.
It is possible to do hybrid fragmentation in two alternative ways:
● Generate a sequence of horizontal fragments first, and then generate vertical fragments from one or more horizontal fragments.
● Generate a sequence of vertical fragments first, then generate horizontal fragments from one or more of the vertical fragments.
Q. 6) Explain the architecture of distributed database?
Ans: Architecture of distributed database
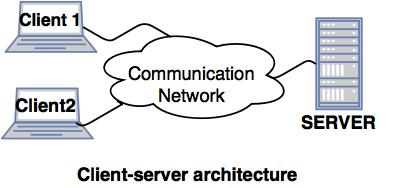
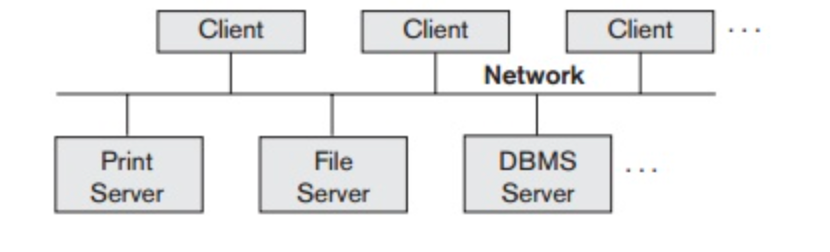
1. Client-server architecture of Distributed system
● The architecture of a client server has a number of clients linked to a network and a few servers.
● A client sends one of the servers a query. It is solved by the earliest available server and reacts.
● Because of the centralized server system, the client-server architecture is easy to implement and execute.
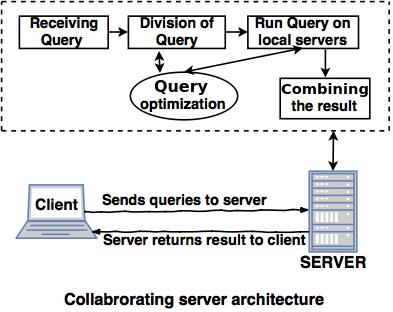
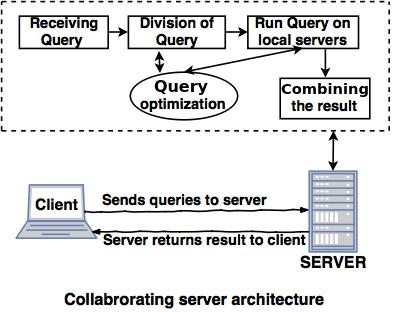
2. Collaborating server architecture
● The Collaborating Server Architecture is designed for multiple servers to perform a single query.
● Servers split several small queries into one single query and the response is submitted to the client.
● There is a collection of database servers in the Collaborating Server Architecture. Each server is capable of executing current database transactions.
3. Middleware architecture
● Middleware architectures are built in such a way that multiple servers perform a single query.
● Only one server that can handle queries and transactions from multiple servers is required for this framework.
● The architecture of middleware uses local servers to deal with local requests and transactions.
● The software is used as middleware for the execution of queries and transactions through one or more separate database servers.
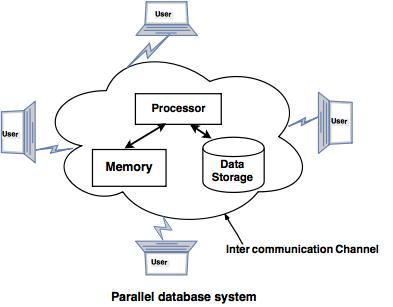
Q. 7) Define parallel database?
Ans: Parallel database
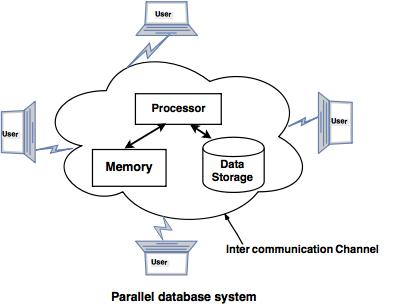
With a high data transfer rate, companies need to manage massive quantities of data. The client server and the centralized system are not very good. The idea of Parallel Databases gave birth to the need to increase performance.
The parallel database architecture enhances data processing performance using multiple parallel resources, such as multiple CPUs and parallel disks.
It also performs several parallelization tasks, such as loading data and processing queries.
Goal of parallel database
The Parallel Database concept was developed with the objective of:
● Improve performance
By connecting many CPUs and discs in parallel, the performance of the device can be improved. It is also possible to connect several small processors in parallel.
● Improve availability of data
To increase the availability of data, data can be copied to different locations.
For example, if a module includes a relationship that is inaccessible (table in the database), then it is necessary to make it accessible from another module.
● Improve reliability
System reliability is strengthened by data completeness, consistency and availability.
● Provide distributed access of data
With the assistance of a parallel database system, companies with several branches in different cities can access data.
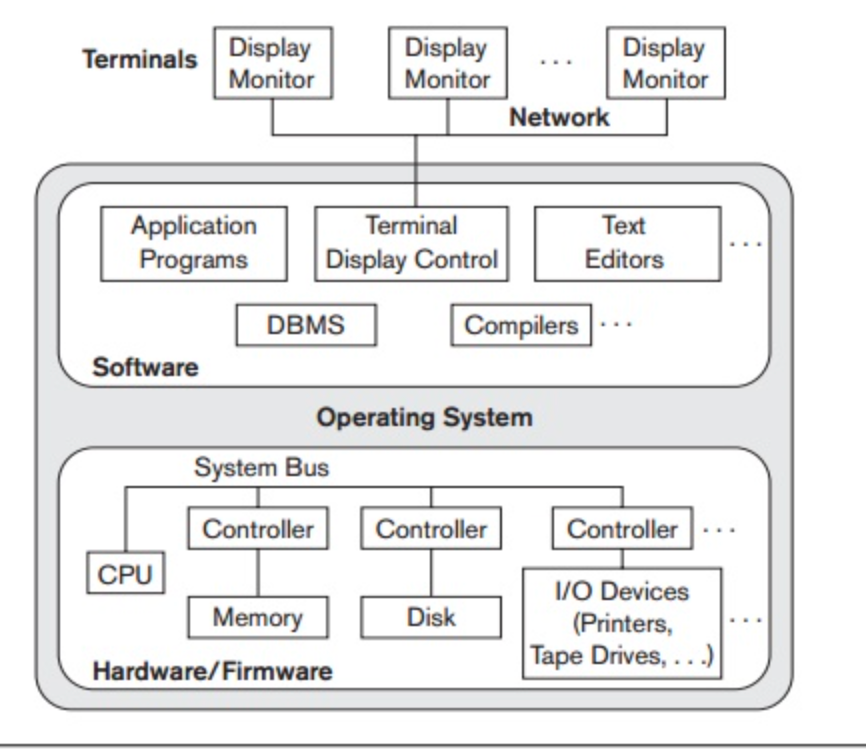
Q. 8) Describe centralized architecture?
Ans: Centralized architecture
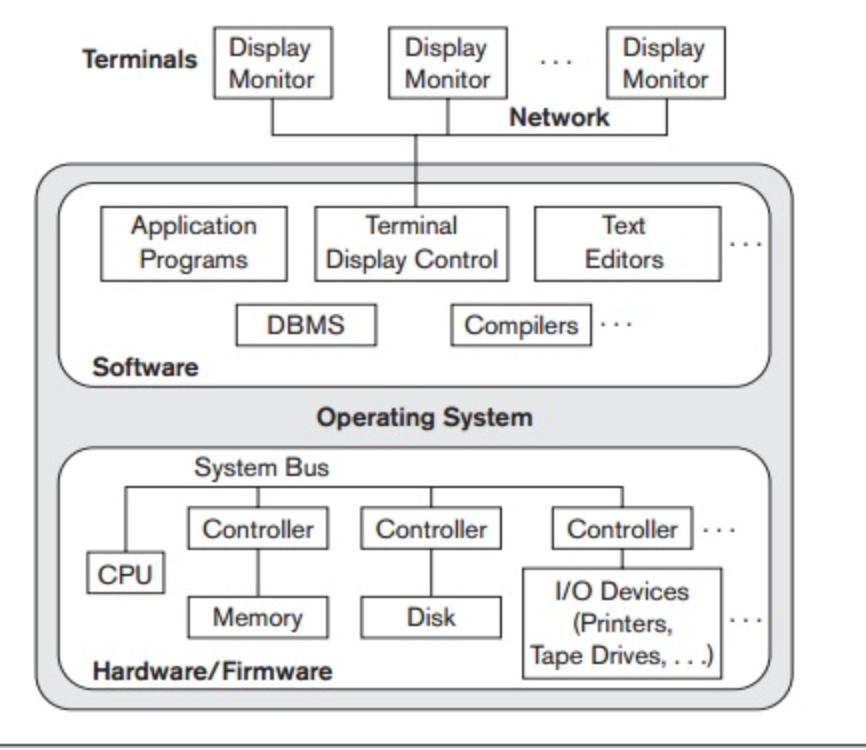
Trends similar to those for general computer system architectures have been followed by architectures for DBMSs. Earlier architectures used mainframe computers, including user application programs and user interface programs, as well as all DBMS features, to provide the main processing for all device functions. The explanation was that, through computer terminals that did not have processing power and only had display capabilities, most users accessed such systems.
All processing was therefore carried out on the computer system remotely, and only display information and controls were transmitted from the computer to the display terminals connected to the central computer via different types of communication networks.
As hardware prices decreased, most users replaced PCs and workstations with their terminals. At first, these machines were used by database systems in a similar way to how they used display terminals, such that the DBMS itself was still a centralized DBMS in which all the DBMS features, execution of the application software, and processing of the user interface were carried out on one machine.
In a centralized system, the figure shows the physical components. Gradually, DBMS systems began to leverage the user-side computing power available, leading to DBMS client/server architectures.
Q. 9) Describe the SQLite database and XML database?
Ans: SQLite database
SQLite is a library of software that implements a transactional SQL database engine that is self-contained, serverless, zero-configuration. SQLite is one of the fastest growing database engines around, but in terms of popularity, that's growth, not anything related to its size. SQLite's source code is in the public domain.
SQLite is an in-process library that implements a transactional SQL database engine which is self-contained, serverless, zero-configuration. It is a zero-configured database, which means you do not need to configure it on your system, like other databases.
Like other databases, the SQLite engine is not a standalone process, you can link it with your application statically or dynamically as per your requirement. SQLite directly accesses its storage files.
Why SQLite?
● SQLite does not require a separate system or server process to function (serverless).
● SQLite comes with zero-configuration, meaning no need for setup or administration.
● In a single cross-platform disc file, a full SQLite database is stored.
● SQLite is very compact and lightweight, fully installed at less than 400KiB or less than 250KiB with omitted optional features.
● SQLite, meaning no external dependencies, is self-contained.
XML databases
The XML Database is used to store an immense amount of XML format information. As the use of XML in every field is growing, it is important to have a safe place to store XML documents. The data stored in the database can be queried, serialized, and exported to a desired format using XQuery.
XML database types:
- XML - enabled database
The XML allowed database is nothing more than an extension given for XML document conversion. This is a relational database where tables consisting of rows and columns store data. Tables comprise a collection of records consisting, in turn, of fields.
2. Native XML database
The native XML database is built on the format of a container instead of a table. Large quantities of XML documents and data can be stored. XPath-expressions are queried by the native XML database.
A benefit over the XML-enabled database is the native XML database. In addition to the XML-enabled database, it is highly capable of storing, querying and maintaining an XML document.
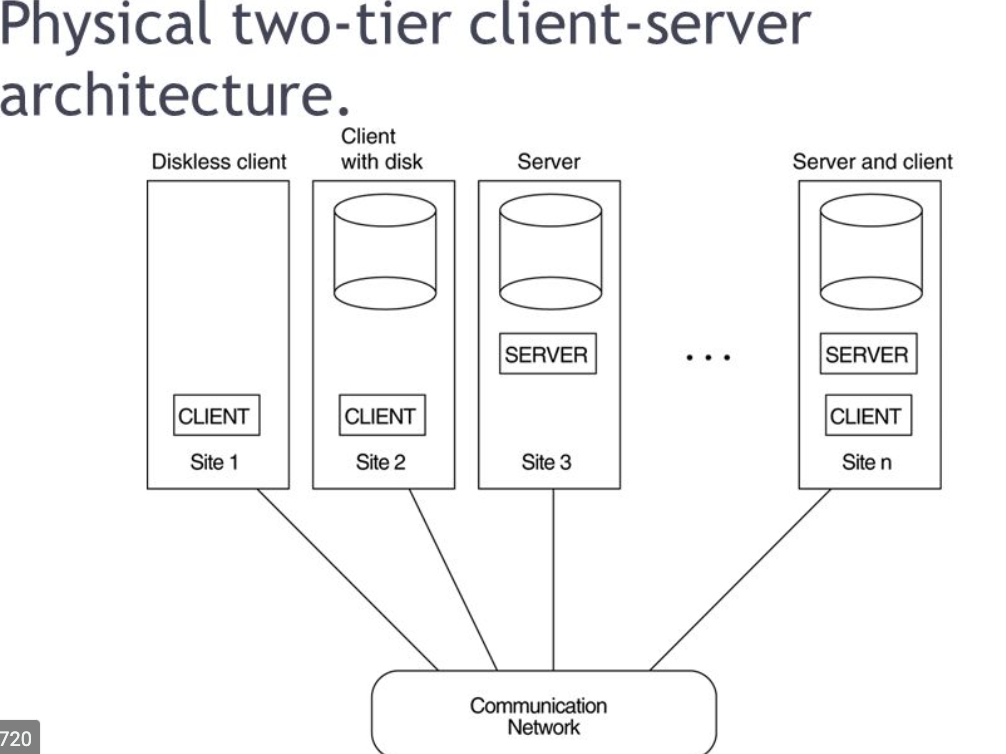
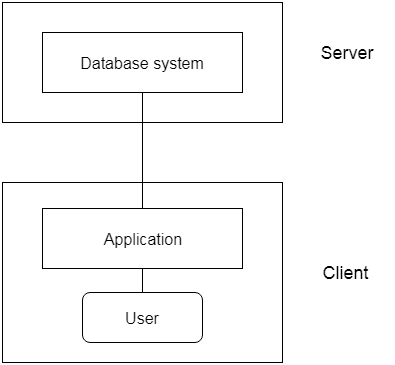
Q. 10) Explain 2 -tier and 3 - tier architecture?
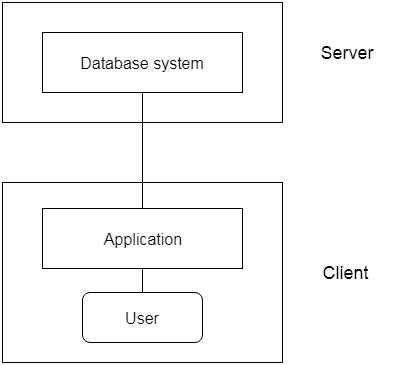
Ans: 2 - tier architecture
● The 2-Tier architecture is similar to the client-server base. Applications on the client end will interact directly with the database on the server side inside the two-tier architecture. For this interaction, APIs are used as follows: ODBC, JDBC.
● On the client side, the user interfaces and application programs are run.
● The server side is responsible for providing functionality such as query processing and handling of transactions.
● Client-side software creates a connection to the server side to interact with the DBMS.
3- Tier Architecture
● Another layer between the client and the server is contained in the 3-Tier architecture. In this architecture, the client is unable to communicate with the server directly.
● The client-end program me interacts with an application server that communicates further with the database system.
● The end user has no knowledge of the life of the database outside the server of the application. There is also no idea of any other users outside the program me in the database.
● For wide web applications, the 3-Tier architecture is used.
Unit - 6
Advanced Databases
Q. 1) Write short notes on client server architecture?
Ans: Client - server Architecture
The client/server architecture has been built to deal with computer environments in which a large number of network-connected PCs, workstations, file servers, printers, database servers, web servers, email servers, and other software and devices are connected. The definition is to describe specialized servers with particular features. For example, a number of PCs or small workstations as clients can be linked to a file server that manages client machine files.
By being linked to various printers, another computer can be designated as a printer server; all print requests from the clients are forwarded to this machine. Web servers or e-mail servers often fall under the category of specialized servers. Several client machines can access the services offered by specialized servers.
The client machines provide the user with the necessary interfaces to use This principle can be transferred to other software packages, with specialized programs stored on specific server machines and made available to several clients, such as a CAD (computer-aided design) kit.
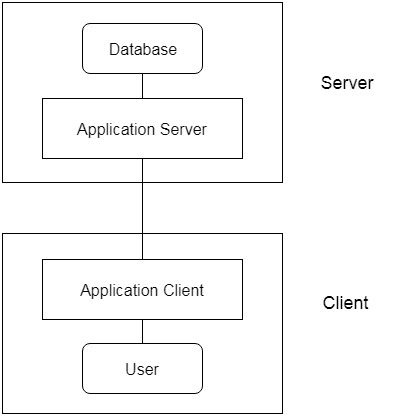
Some computers (for instance, diskless workstations or workstations/PCs with disk that only have client software installed) will be client sites only.
The client/server architecture principle implies an underlying structure consisting of several PCs and workstations, as well as a smaller number of mainframe machines, linked via LANs and other computer network types. A user computer that offers user interface functionality and local processing is usually a client in this framework. When a client requires access to additional functions that do not exist on that machine, such as database access, it connects to a server that provides the necessary functionality.
A server is a device that includes both hardware and software that can provide client machines with resources, such as access to files, printing, archiving, or access to databases. In general, some machines only install client software, others only server software, and still others, as shown in figure, can provide both client and server software. However, it is more common for client and server applications to run on different machines in general.
Q. 2) Explain different types of parallel database architecture?
Ans: Types of parallel database architecture
- Shared memory system
● The shared memory system uses multiple processors that are connected via an intercommunication channel or communication bus to a globally shared memory.
● There is a significant amount of cache memory on each processor in the shared memory scheme, so referencing the shared memory is avoided.
● If a processor conducts a memory location writing operation, the data should be modified or deleted from that location.
2. Shared disk system
● The shared disc system uses multiple processors that are accessible via the intercommunication channel to multiple discs, and each processor has local memory.
● Each processor has its own memory, so it is efficient to share data.
● As clusters, the structure developed around this system is referred to.
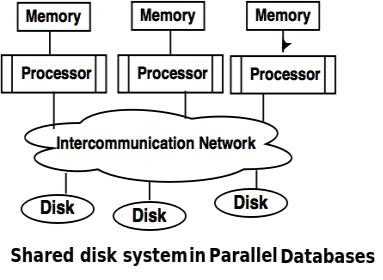
3. Shared nothing disk system
● Each processor has its own local memory and local disc in the shared nothing scheme.
● Via intercommunication channels, processors can communicate with one another.
● Any processor can serve as a server for the data stored on the local disc.
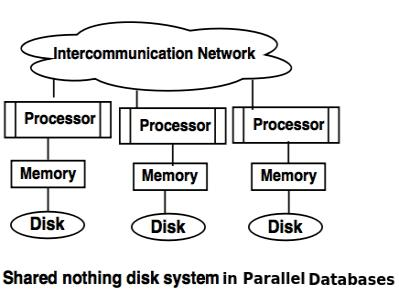
4. Hierarchical System or Non-Uniform Memory Architecture
● The hierarchical model system is a hybrid system of shared memory, shared disc, and shared nothing.
● Also known as Non-Uniform Memory Architecture, the hierarchical model is (NUMA).
● Each group of processors in this system has a local memory. But processors from other groups can access memory which is coherently linked to the other group.
● NUMA (Memory from another group) uses local and remote memory, so it will take longer to communicate with each other.
Q. 3) Describe the key elements of parallel database processing?
Ans: Key elements of parallel database processing
❏ Speedup and scaleup
❏ Synchronization
❏ Looking
❏ Messaging
- Speedup and scaleup:
In terms of two significant properties, you can measure the performance objectives of parallel processing:
Speedup:
Speedup is the extent to which more hardware than the original system can perform the same task in less time. Speedup keeps the job constant with additional hardware and calculates time savings. The figure demonstrates how half of the original task is carried out by each parallel hardware system in half the time it takes to execute it on a single system.
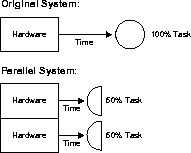
Additional processors minimize system reaction time with a good speedup. Using this formula, you can test speedup
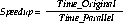
Were,
Time _parallel - Is the elapsed time spent on the specified task by a larger, parallel method.
Scaleup:
Scaleup is the factor m that shows how much more work can be performed by a machine n times larger in the same time span. A scale-up formula keeps the time constant with additional hardware, and calculates the increased size of the job that can be completed.
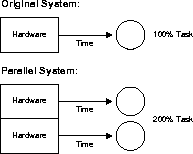
With good scale-up, by adding hardware resources such as CPUs, you can keep response time constant if transaction volumes rise.
Using this formula, you can calculate the scale: 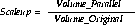
Were,
Volume _parallel - is the number of transactions performed on a parallel system in a given period of time.
2. Synchronization
Concurrent task management is called synchronization. For correctness, synchronization is important. The secret to efficient parallel processing is to break tasks such that very little synchronization is required. The less synchronization is needed, the better the pace and scale-up.
A high-speed interconnection between the parallel processors is necessary for parallel processing between nodes. If a lot of inter-node communication is needed, the overhead of this synchronization can be very costly. Messaging is not mandatory for parallel processing within a node: shared memory is used instead. The Integrated Distributed Lock Manager manages communicating and locking between nodes.
The level of synchronization depends on the number of resources and the number of resource-operating users and tasks. In order to organize a small number of concurrent tasks, little synchronization may be required, but to coordinate several concurrent tasks, a lot of synchronization may be essential.
3. Looking
Locks are fundamentally a way for activities to be coordinated. To allow the synchronization of tasks needed by parallel processing, several different locking mechanisms are necessary.
The Integrated Distributed Lock Manager (Integrated DLM or IDLM) is the Oracle Parallel Server internal locking facility. It coordinates the sharing of resources among nodes running a parallel server. Parallel server instances use the Integrated Distributed Lock Manager to communicate with each other and to organize database resource modifications. Each node, even when contending for the same resource, operates independently of other nodes.
The IDLM enables applications to synchronize access to resources such as data, software, and peripheral devices, so that applications running on different nodes can coordinate concurrent requests for the same resource.
For applications, the IDLM operates the following services:
● Keeps track of a resource's current "ownership"
● Accepts lock requests from application processes for services
● Notifies the requesting process when a lock is available on a resource
● Receives access to a framework for a process
4. Messaging
Parallel processing requires fast and effective communication between nodes: a high bandwidth and low latency device that communicates with the IDLM effectively.
Bandwidth is the cumulative size per second of messages that can be sent. Latency is the time it takes to put a message on the interconnection (in seconds). Thus, latency means the number of messages per second that can be placed on the interconnect. A high bandwidth interconnection is like a long road with several lanes to handle heavy traffic: the number of lanes influences the speed at which traffic can pass.
A low latency interconnection is like a road with an entrance ramp that allows vehicles to enter without delay: the cost of getting on the highway is low.
Networks that have relatively high bandwidth are planned for most MPP systems and clusters. On the other hand, latency is an operating system problem that mostly has to do with applications. MPP systems and most clusters characteristically use high bandwidth and low latency interconnects; other clusters can use comparatively low bandwidth and high latency Ethernet connections.
Q. 4) Write short notes on the Distributed database?
Ans: Distributed database
● A distributed database is a framework that does not link storage devices to a common processing unit.
● The Distributed Database Management System manages the database and data can be stored at the same location or distributed over an interconnected network. It is a system that is loosely coupled.
● In distributed databases, shared architecture is used for nothing.
● A common example of a distributed database system is the below diagram, in which the communication channel is used to communicate with the various locations and each system has its own memory and database.
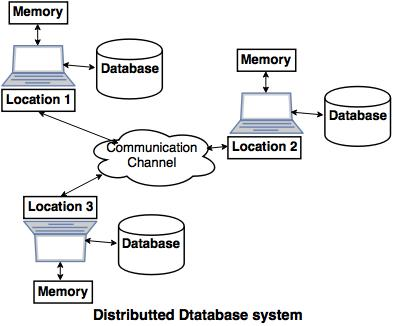
Goal of the distributed database system
The definition of distributed databases was developed with the aim of improving:
❏ Reliability
In a distributed database system, another system may complete the task if one system fails or stops running for some time.
❏ Availability
Reliability in the distributed database system can be achieved even though serious failures occur. To satisfy a client request, another framework is available.
❏ Performance
By spreading databases across multiple locations, efficiency can be achieved. The databases are therefore available for any easy-to-maintain venue.
Q. 5) What are the design techniques of distributed database?
Ans: Distributed database design technique
It is possible to split the design techniques widely into replication and fragmentation. A mixture of the two is, however, used in most situations.
Data replication
The method of storing separate copies of the database at two or more locations is data duplication. It is a popular distributed database fault tolerance technique.
Some commonly used replication techniques are −
● Snapshot replication
● Near-real-time replication
● Pull replication
Fragmentation
The process of splitting a table into a number of smaller tables is fragmentation. The table's subsets are called fragments. There may be three kinds of fragmentation: horizontal, vertical and mixed (combination of horizontal and vertical). It is further possible to divide horizontal fragmentation into two techniques: primary horizontal fragmentation and derived horizontal fragmentation.
In order for the original table to be rebuilt from the fragments, fragmentation should be done in a way. This is done so that the original table can be restored whenever possible from the fragments. This demand is referred to as "reconstructiveness."
➢ Vertical fragmentation
The fields or columns of a table are divided into fragments during vertical fragmentation. Each fragment should contain the primary key field(s) of the table to preserve reconstructiveness. To implement information protection, vertical fragmentation can be used.
For example, let us consider that in a student table with the following scheme, a university database keeps records of all registered students.
STUDENT
Regd_No | Name | Course | Address | Semester | Fees | Marks |
Now, in the accounts section, the fee details are preserved. The designer will fragment the database in this case as follows-
CREATE TABLE STD_FEES AS
SELECT Regd_No, Fees
FROM STUDENT;
➢ Horizontal Fragmentation
Horizontal fragmentation classifies the table's tuples according to the values of one or more fields. The reconstructiveness law should also be verified by horizontal fragmentation. Each horizontal fragment must contain all of the original base table columns.
In the student scheme, for example, if the records of all computer science students need to be stored at the School of Computer Science, the designer will fragment the database horizontally as follows.
CREATE COMP_STD AS
SELECT * FROM STUDENT
WHERE COURSE = "Computer Science";
➢ Hybrid fragmentation
A mixture of horizontal and vertical fragmentation methods is used in hybrid fragmentation. This is the most versatile technique of fragmentation because fragments with minimal extraneous information are produced. Reconstruction of the initial table, however, is always a costly process.
It is possible to do hybrid fragmentation in two alternative ways:
● Generate a sequence of horizontal fragments first, and then generate vertical fragments from one or more horizontal fragments.
● Generate a sequence of vertical fragments first, then generate horizontal fragments from one or more of the vertical fragments.
Q. 6) Explain the architecture of distributed database?
Ans: Architecture of distributed database
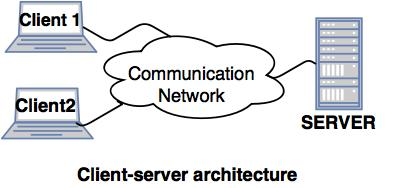
1. Client-server architecture of Distributed system
● The architecture of a client server has a number of clients linked to a network and a few servers.
● A client sends one of the servers a query. It is solved by the earliest available server and reacts.
● Because of the centralized server system, the client-server architecture is easy to implement and execute.
2. Collaborating server architecture
● The Collaborating Server Architecture is designed for multiple servers to perform a single query.
● Servers split several small queries into one single query and the response is submitted to the client.
● There is a collection of database servers in the Collaborating Server Architecture. Each server is capable of executing current database transactions.
3. Middleware architecture
● Middleware architectures are built in such a way that multiple servers perform a single query.
● Only one server that can handle queries and transactions from multiple servers is required for this framework.
● The architecture of middleware uses local servers to deal with local requests and transactions.
● The software is used as middleware for the execution of queries and transactions through one or more separate database servers.
Q. 7) Define parallel database?
Ans: Parallel database
With a high data transfer rate, companies need to manage massive quantities of data. The client server and the centralized system are not very good. The idea of Parallel Databases gave birth to the need to increase performance.
The parallel database architecture enhances data processing performance using multiple parallel resources, such as multiple CPUs and parallel disks.
It also performs several parallelization tasks, such as loading data and processing queries.
Goal of parallel database
The Parallel Database concept was developed with the objective of:
● Improve performance
By connecting many CPUs and discs in parallel, the performance of the device can be improved. It is also possible to connect several small processors in parallel.
● Improve availability of data
To increase the availability of data, data can be copied to different locations.
For example, if a module includes a relationship that is inaccessible (table in the database), then it is necessary to make it accessible from another module.
● Improve reliability
System reliability is strengthened by data completeness, consistency and availability.
● Provide distributed access of data
With the assistance of a parallel database system, companies with several branches in different cities can access data.
Q. 8) Describe centralized architecture?
Ans: Centralized architecture
Trends similar to those for general computer system architectures have been followed by architectures for DBMSs. Earlier architectures used mainframe computers, including user application programs and user interface programs, as well as all DBMS features, to provide the main processing for all device functions. The explanation was that, through computer terminals that did not have processing power and only had display capabilities, most users accessed such systems.
All processing was therefore carried out on the computer system remotely, and only display information and controls were transmitted from the computer to the display terminals connected to the central computer via different types of communication networks.
As hardware prices decreased, most users replaced PCs and workstations with their terminals. At first, these machines were used by database systems in a similar way to how they used display terminals, such that the DBMS itself was still a centralized DBMS in which all the DBMS features, execution of the application software, and processing of the user interface were carried out on one machine.
In a centralized system, the figure shows the physical components. Gradually, DBMS systems began to leverage the user-side computing power available, leading to DBMS client/server architectures.
Q. 9) Describe the SQLite database and XML database?
Ans: SQLite database
SQLite is a library of software that implements a transactional SQL database engine that is self-contained, serverless, zero-configuration. SQLite is one of the fastest growing database engines around, but in terms of popularity, that's growth, not anything related to its size. SQLite's source code is in the public domain.
SQLite is an in-process library that implements a transactional SQL database engine which is self-contained, serverless, zero-configuration. It is a zero-configured database, which means you do not need to configure it on your system, like other databases.
Like other databases, the SQLite engine is not a standalone process, you can link it with your application statically or dynamically as per your requirement. SQLite directly accesses its storage files.
Why SQLite?
● SQLite does not require a separate system or server process to function (serverless).
● SQLite comes with zero-configuration, meaning no need for setup or administration.
● In a single cross-platform disc file, a full SQLite database is stored.
● SQLite is very compact and lightweight, fully installed at less than 400KiB or less than 250KiB with omitted optional features.
● SQLite, meaning no external dependencies, is self-contained.
XML databases
The XML Database is used to store an immense amount of XML format information. As the use of XML in every field is growing, it is important to have a safe place to store XML documents. The data stored in the database can be queried, serialized, and exported to a desired format using XQuery.
XML database types:
- XML - enabled database
The XML allowed database is nothing more than an extension given for XML document conversion. This is a relational database where tables consisting of rows and columns store data. Tables comprise a collection of records consisting, in turn, of fields.
2. Native XML database
The native XML database is built on the format of a container instead of a table. Large quantities of XML documents and data can be stored. XPath-expressions are queried by the native XML database.
A benefit over the XML-enabled database is the native XML database. In addition to the XML-enabled database, it is highly capable of storing, querying and maintaining an XML document.
Q. 10) Explain 2 -tier and 3 - tier architecture?
Ans: 2 - tier architecture
● The 2-Tier architecture is similar to the client-server base. Applications on the client end will interact directly with the database on the server side inside the two-tier architecture. For this interaction, APIs are used as follows: ODBC, JDBC.
● On the client side, the user interfaces and application programs are run.
● The server side is responsible for providing functionality such as query processing and handling of transactions.
● Client-side software creates a connection to the server side to interact with the DBMS.
3- Tier Architecture
● Another layer between the client and the server is contained in the 3-Tier architecture. In this architecture, the client is unable to communicate with the server directly.
● The client-end program me interacts with an application server that communicates further with the database system.
● The end user has no knowledge of the life of the database outside the server of the application. There is also no idea of any other users outside the program me in the database.
● For wide web applications, the 3-Tier architecture is used.