UNIT 5
Data base Management System & Cloud computing
- What is DBMS?
Database is a nothing but collection of related data. Data is a collection of facts and figures which is used to produce information.
For example, if we have data about examination. It contains marks and name of student. So using this data, we can then find the topper in the class, percentage wise result of each student and so on.
A Database Management System stores data in efficient way so that it becomes easier to retrieve, manipulate, and produce required result in terms of information. The design of DBMS depends on its architecture. The architecture of DBMS can be seen as either single tier or multi-tier. N tier architecture divides the whole system into related but independent n models, which can be independently modified, altered, changed, or replaced.
In 1-tier architecture, the database system is the only entity where the user directly interacts with the DBMS and uses it. Any changes made by user here will directly be done on the DBMS itself. Database designers and programmers normally prefer to use one-tier architecture as it is easy to access.
If the architecture of DBMS is 2-tier, Application layer lies on the top of the through which the DBMS can be accessed. Programmer design application and uses 2-tier architecture where they access the DBMS.
3-tier architecture separates each tier from each other based on the complexity of the users and how they use the data present in the database. It is the most widely used architecture to design a DBMS.
Database (Data) Tier: This tier contains relations which contains data and the integrity constraints. At this tier, the database resides along with its query processing languages.
Application (Middle) Tier: For a user, this application tier gives an abstract view of the database. They are just unaware about the database which exists beyond the application which they are using. Also, the database tier is unaware about the users beyond the application tier. Hence the application layer is in the middle and acts as a mediator between the end-user using application and the database behind it.
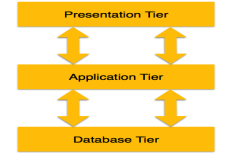
Fig.1.1. 3-tier Architecture of DBMS
User (Presentation) Tier: End-users operate on this tier and they know nothing about any existence of the database beyond this layer. At this layer database can be viewed by many users. Each user has own perspective. All views as per user are generated at this layer.
2. Explain File oriented approach
File Oriented Approach:-
A traditional File Oriented Approach was based on the following:
- Information stored in files.
- An application program to access information stored in file.
Disadvantages of File Oriented Approach:
- Data Dependency:-
A traditional program is linked to:
- Structure of record.
- Size of each field inside a record.
- Type of each field.
- Position of field in the record.
A program writes to access the master file must be changed whenever new field is added, deleted/modified.
2. Data Redundancy:-
Same piece of information may be stored in different files.
Eg. Student name and one can appear in college file also and in department file also.
3. Data Inconsistency:-
Data duplication leads to inconsistency.
Eg. Name can be changed in department file but not in college file.
4. Lack of flexibility:-
- There is strong coupling between program and data. Every type of result to be generated should be programmed.
- Programming for a new record may require modification of existing record structure which may be difficult.
5. Data Isolation:-
- Data may be scattered in different files. Each file may have different format.
- It is difficult to combine because these files are created without any consideration of relation among data items.
6. Integrity Problems:-
- Data should be satisfy certain integrity constraints.
- Eg. Roll No. Must be unique.
- In traditional approach, code is added in application program to enforce integrity constraints.
- It is difficult to add new/modify existing constraints.
7. Atomicity Problem:-
- A computer system may fail at any time.
- Consider a transaction to x for 1000 Rs. From account A to B.
- System consistency require either both the credit and debit occur, and neither should occur.
- It is difficult to ensure atomicity in FOA.
8. Concurrent Access Problem:-
- In Client-Server, system allows multiple users to update data simultaneously.
- Concurrent programs are difficult to write. It requires knowledge of synchronization, semaphores etc.
9. Security Problems:-
- Every user cannot be allowed to have access to all the data.
- Access can be limited by login and password.
- In application programs it is difficult to enforce security constraint.
3. Explain database approach
Database Approach:
- Insulation between programs and data:-
- Structure of data files is maintained by DBMS.
- Programs look at data at logical level without being concerned about its physical representation.
- Programs need not to be changed if new fields are added.
- This allows data independence. Also called as data abstraction.
2. Data Integrity:-
Integrity rules can be defined and its responsibility lies with DBMS.
3. Enforcing Standard:-
- It is easy to enforce standards in a centralized database environment.
- Required for every communication.
Eg. Display formats, report structure.
4. Reduced Application Development time:-
- DBMS provides many standard functions that the programmer will have to use.
- Program for data retrieval using SQL takes very little time to write.
- It is easy to design forms, report generation.
5. Flexibility:-
- DBMS allows changes to the structure of database without affecting existing data/existing application programs.
6. Self describing nature of database system:-
A database system contains Database, Database Structure, Constraints.
Structure of database is maintained in the system catalog which contains information about database structure. This catalog can be used by a program to extract information about database structure.
7. Sharing of data:-
- DBMS allows sharing of data by any number of users/programs.
- Multiple users can access data at the same time.
- New applications can be build on the existing data.
- Concurrency control mechanism is required for updates to be correct.
- DBMS ensures that concurrent processing operate correctly.
8. No data redundancy/inconsistency:-
- Database approach eliminates redundancy by integrating the files so that the multiple copies of same data are not stored.
- In DBMS, there is only copy of data item. Thus no problem of data inconsistency.
4. Explain data models
Data models are used to describe the design of a database at the logical level.
Some of the data models are:-
 Entity-Relationship Model Object Based Logical Model
Entity-Relationship Model Object Based Logical Model Relational Model
Relational Model- Hierarchical Model
 Network Model Record Based Logical Model
Network Model Record Based Logical Model- Object Relational Model
Entity-Relationship(E-R) Model:-
The logical structure of a database can be expressed by an E-R diagram. The mainComponents of ER Diagram are:-
a) Rectangles Entity Sets
b) Ellipses Attributes
c) Diamond Relation among entity sets
d) Lines Connects attributes to entity sets and entity sets to relationships.
Example:-
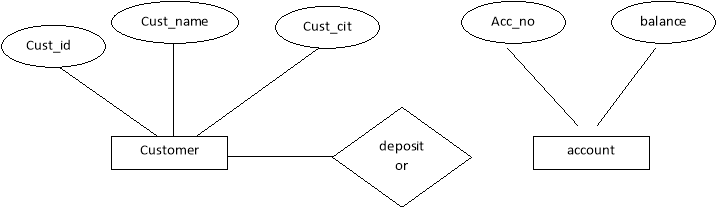

Fig. 1.1 ER diagram
The above E-R diagram has two entities: customer and account .
Customer entity has three attributes:
cust_id
cust_name
cust_city
Account entity has two attributes:-
acc_no
balance
Relation depositor gives relationship between customers account.
Eg. Account A-101 is held by customer John.
Relationship can be of the type:
 1:1 One to one
1:1 One to one
 1:M One to many
1:M One to many
 M:1 Many to one
M:1 Many to one
 M:M Many to many
M:M Many to many
Database design in E-R model is converted to design in Relational model.
Relational Model:-
Relational model uses a collection of tables to represent both data and the relationships among those data.
Sample Relational Database:-
Cust-id | Cust_name | Cust_city |
19212 | John | Harrison |
19213 | Smith | Stamford |
20102 | Turner | Rye |
01234 | Jones | Pittsfield |
19212 | John | Harrison |
(a) Customer Table
Acc_no | Balance |
A-101 | 500 |
A-305 | 700 |
A-117 | 1000 |
A-102 | 100 |
A-219 | 1200 |
(b) Account table
Cust_id | Acc_no |
19212 | A-101 |
19213 | A-305 |
20102 | A-117 |
01234 | A-102 |
19212 | A-219 |
(c) Depositor table
Hierarchical Model:-
A Hierarchical model uses tree structure to represent relationship among entities. An Institute can offer many programs. Each program may have a number of courses. A number of students are registered in each course.



 1
1

 M
M
1
M
1
M
Network Model:-
Network model uses two different data structures:-
a) A record type is used to represent as entity set.
b) A set type is used to represent a directed relationship between two record type. It specifies 1:M relationship between owner record type and member record type.




Dept_employeeRecord type
Set type
Object Relational Model:-
There are two types of ORM:-
- Object-Oriented Data Model (OODM)
- Object-Relational Data Model (ORDM)
These models are used to handle objects:
1) To provide support for complex objects.
2) To provide user extensibility for data types operators and access methods.
3) There should be mechanism to support:
a) Abstract data type.
b) Data of type ‘procedure’.
c) Rules.
Advantages of ORDM:-
- Reuse of sharing standard functions can be implemented centrally, rather than coding it in each application.
- It preserves the existing relational applications.
5. Explain Database System Architecture
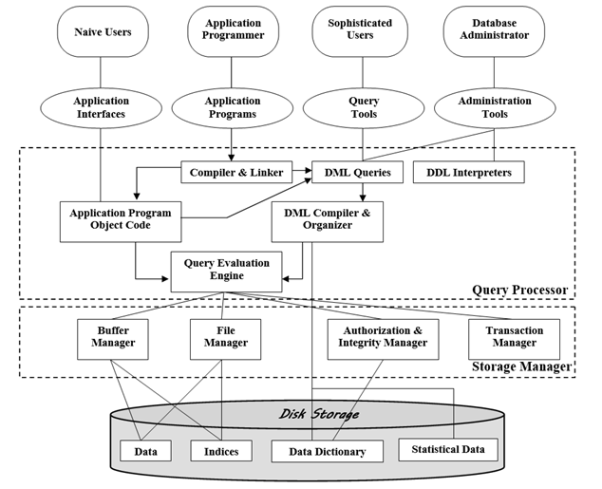
Database system architecture is shown in above diagram. It contains functional components like storage manager and query processor. It also shows different database users.
Storage Manager:
A storage manager is a module which provides the interface between data stored in database, application programs used by user and the queries submitted to get the required results. Storage manager is responsible for the tasks like interaction with file manager, query processing which converts DML statements into low-level file system commands. It is also responsible for storing and updating data in the database.
The various components of storage manager are:
- Authorization and integrity manager: It checks different integrity constraints applied to database. It also checks authority of users accessing database.
- Transaction manager: It takes care of ACID properties of transaction. It means, transaction manager ensures that database will remain in consistent state irrespective of software or hardware failure. It also resolves conflictions in concurrent execution.
- File manager: It manages the space allocation on disk storage and different data structures used to represent information stored on disk.
- Buffer manager: It is responsible for fetching data from disk storage into main memory and detecting what data to cache in main memory.
- Data dictionary: It contains metadata. Metadata means data about data. The schema of a relation is an example of metadata.
6. What is query processor?
Query Processor:
Query processor is an important component of the database system. Database system takes help of query processor to simplify and provide access to data. The Query processor components include:
- DDL Interpreter: It takes DDL statements as input. Then relation schema that is definition of relation is recorded in the data dictionary.
- DML Compiler: It translates DML statements like delete, update in a query language into an evaluation plan. Evaluation plan consists of low-level instructions which can be understood by the query evaluation engine. It also performs query optimization. Query optimization picks up the lowest cost evaluation plan among the alternatives.
- Query Evaluation Engine: it takes low-level instructions generated by the DML Compilers as a input and executes it.
Database users:-
Users are differentiated by the way they interact with the system.
- Application Programmers:- Interact with the system through DML system calls embedded with host language. RAD (Rapid Application Development) tools are tools that enable application programmer to construct forms and reports without writing a code.
- Sophisticated users:- Forms a request in a database by using Query Language. They interact with system without writing a program. They submit query to query processor; whose functions are to break down DML statements into instructions that storage manager understands. OLAP and data mining tools simplify their task by letting them view summaries of data.
- Specialized users:-Write Specialized database applications that do not fit into the traditional data processing framework.
- Naïve users:-Invoke one of the permanent applications programs that have been written previously.
Eg. People accessing database over the web, clerical staff etc.
7. What is DBA?
- Role of DBMS is to have control of both data and program accessing that data. The person having such control over the system is called DBA.
- DBA manages three levels of abstraction.
- DBA specifies the external view of the various users and applications.
- DBA is responsible for the definitions and implementation of the internal level including storage structure.
- Various mappings are defined by the DBA:-
- Mapping between internal and conceptual level.
- Mapping between conceptual and external level.
Vi. DBA ensures integrity of the database.
Vii. DBA stores profile of each user. It is used to stop database access by unauthorized user.
Viii. DBA is responsible for defining procedures to recover database from failures. It enables organization to continue to function without interruption.
Functions of DBA are summarized:-
- Schema definition.
- Storage structures and access method definition.
- Schema and physical organization modification.
- Granting of authorization for data access.
- Integrity constraint specification.
- Recovery of database on failures.
The functional components of database can be broadly classified into:- query processor components and storage manager components.
- DBA creates original database by execution of DDL statement.
- Carries out changes to schema. Alter the physical organization to improve the performance.
- Authorization information is kept in a special system structure that database consults whenever someone attempts to access database.
8. What is Data independence?
If a database system is not multi-layered, then it becomes difficult to make any changes in the database system. Database systems are designed in multi-layers as we learnt earlier.
Data Independence
A database system normally contains a lot of data in addition to users’ data. For example, it stores data about data, known as metadata, to locate and retrieve data easily. It is rather difficult to modify or update a set of metadata once it is stored in the database. But as a DBMS expands, it needs to change over time to satisfy the requirements of the users. If the entire data is dependent, it would become a tedious and highly complex job.
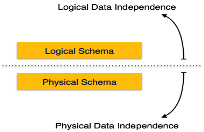
Metadata itself follows a layered architecture, so that when we change data at one layer, it does not affect the data at another level. This data is independent but mapped to each other.
Logical Data Independence
Logical data is data about database, that is, it stores information about how data is managed inside. For example, a table (relation) stored in the database and all its constraints, applied on that relation.
Logical data independence is a kind of mechanism, which liberalizes itself from actual data stored on the disk. If we do some changes on table format, it should not change the data residing on the disk.
Physical Data Independence
All the schemas are logical, and the actual data is stored in bit format on the disk. Physical data independence is the power to change the physical data without impacting the schema or logical data.
For example, in case we want to change or upgrade the storage system itself − suppose we want to replace hard-disks with SSD − it should not have any impact on the logical data or schemas.
9. What is data dictionary?
Data Dictionary
A data dictionary contains metadata i.e data about the database. The data dictionary is very important as it contains information such as what is in the database, who is allowed to access it, where is the database physically stored etc. The users of the database normally don't interact with the data dictionary, it is only handled by the database administrators.
The data dictionary in general contains information about the following −
- Names of all the database tables and their schemas.
- Details about all the tables in the database, such as their owners, their security constraints, when they were created etc.
- Physical information about the tables such as where they are stored and how.
- Table constraints such as primary key attributes, foreign key information etc.
- Information about the database views that are visible.
This is a data dictionary describing a table that contains employee details.
Field Name | Data Type | Field Size for display | Description | Example |
Employee | Integer | 10 | Unique ID of each employee | 1645000001 |
Name | Text | 20 | Name of the employee | David Heston |
Date of Birth | Date/Time | 10 | DOB of Employee | 08/03/1995 |
Phone Number | Integer | 10 | Phone number of employee | 6583648648 |
The different types of data dictionary are −
Active Data Dictionary
If the structure of the database or its specifications change at any point of time, it should be reflected in the data dictionary. This is the responsibility of the database management system in which the data dictionary resides.
So, the data dictionary is automatically updated by the database management system when any changes are made in the database. This is known as an active data dictionary as it is self updating.
Passive Data Dictionary
This is not as useful or easy to handle as an active data dictionary. A passive data dictionary is maintained separately to the database whose contents are stored in the dictionary. That means that if the database is modified the database dictionary is not automatically updated as in the case of Active Data Dictionary.
So, the passive data dictionary has to be manually updated to match the database. This needs careful handling or else the database and data dictionary are out of sync.
10 What is primary key?
Primary Key
A primary key is a field in a table which uniquely identifies each row/record in a database table. Primary keys must contain unique values. A primary key column cannot have NULL values.
A table can have only one primary key, which may consist of single or multiple fields. When multiple fields are used as a primary key, they are called a composite key.
If a table has a primary key defined on any field(s), then you cannot have two records having the same value of that field(s).
Note − You would use these concepts while creating database tables.
Create Primary Key
Here is the syntax to define the ID attribute as a primary key in a CUSTOMERS table.
CREATE TABLE CUSTOMERS(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (25) ,
SALARY DECIMAL (18, 2),
PRIMARY KEY (ID)
);
To create a PRIMARY KEY constraint on the "ID" column when the CUSTOMERS table already exists, use the following SQL syntax −
ALTER TABLE CUSTOMER ADD PRIMARY KEY (ID);
NOTE − If you use the ALTER TABLE statement to add a primary key, the primary key column(s) should have already been declared to not contain NULL values (when the table was first created).
For defining a PRIMARY KEY constraint on multiple columns, use the SQL syntax given below.
CREATE TABLE CUSTOMERS(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS CHAR (25) ,
SALARY DECIMAL (18, 2),
PRIMARY KEY (ID, NAME)
);
To create a PRIMARY KEY constraint on the "ID" and "NAMES" columns when CUSTOMERS table already exists, use the following SQL syntax.
ALTER TABLE CUSTOMERS
ADD CONSTRAINT PK_CUSTID PRIMARY KEY (ID, NAME);
Delete Primary Key
You can clear the primary key constraints from the table with the syntax given below.
ALTER TABLE CUSTOMERS DROP PRIMARY KEY ;




