Unit - 5
Transaction concepts
Q1) What is a transaction in DBMS with examples?
A1) A transaction can be defined as a group of tasks. A single task is the minimum processing unit which cannot be divided further.
Let’s take an example of a simple transaction. Suppose a bank employee transfers Rs 500 from A's account to B's account. This very simple and small transaction involves several low-level tasks.
A’s Account
Open_Account(A)
Old_Balance = A.balance
New_Balance = Old_Balance - 500
A.balance = New_Balance
Close_Account(A)
B’s Account
Open_Account(B)
Old_Balance = B.balance
New_Balance = Old_Balance + 500
B.balance = New_Balance
Close_Account(B)
Q2) What are ACID properties in DBMS?
A2) ACID Properties
A transaction is a very small unit of a program and it may contain several low level tasks. A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity.
● Atomicity − This property states that a transaction must be treated as an atomic unit, that is, either all of its operations are executed or none. There must be no state in a database where a transaction is left partially completed. States should be defined either before the execution of the transaction or after the execution/abortion/failure of the transaction.
● Consistency − The database must remain in a consistent state after any transaction. No transaction should have any adverse effect on the data residing in the database. If the database was in a consistent state before the execution of a transaction, it must remain consistent after the execution of the transaction as well.
● Durability − The database should be durable enough to hold all its latest updates even if the system fails or restarts. If a transaction updates a chunk of data in a database and commits, then the database will hold the modified data. If a transaction commits but the system fails before the data could be written on to the disk, then that data will be updated once the system springs back into action.
● Isolation − In a database system where more than one transaction are being executed simultaneously and in parallel, the property of isolation states that all the transactions will be carried out and executed as if it is the only transaction in the system. No transaction will affect the existence of any other transaction.
Q3) What is Serializability?
A3) Serializability
When multiple transactions are being executed by the operating system in a multiprogramming environment, there are possibilities that instructions of one transactions are interleaved with some other transaction.
● Schedule − A chronological execution sequence of a transaction is called a schedule. A schedule can have many transactions in it, each comprising of a number of instructions/tasks.
● Serial Schedule − It is a schedule in which transactions are aligned in such a way that one transaction is executed first. When the first transaction completes its cycle, then the next transaction is executed. Transactions are ordered one after the other. This type of schedule is called a serial schedule, as transactions are executed in a serial manner.
In a multi-transaction environment, serial schedules are considered as a benchmark. The execution sequence of an instruction in a transaction cannot be changed, but two transactions can have their instructions executed in a random fashion. This execution does no harm if two transactions are mutually independent and working on different segments of data; but in case these two transactions are working on the same data, then the results may vary. This ever-varying result may bring the database to an inconsistent state.
To resolve this problem, we allow parallel execution of a transaction schedule, if its transactions are either serializable or have some equivalence relation among them.
Q4) What is an ACID property in DBMS explain in detail with examples?
A4) DBMS is the management of data that should remain integrated when any changes are done in it. It is because if the integrity of the data is affected, whole data will get disturbed and corrupted. Therefore, to maintain the integrity of the data, there are four properties described in the database management system, which are known as the ACID properties. The ACID properties are meant for the transaction that goes through a different group of tasks, and there we come to see the role of the ACID properties.
In this section, we will learn and understand about the ACID properties. We will learn what these properties stand for and what does each property is used for. We will also understand the ACID properties with the help of some examples.
ACID Properties
The expansion of the term ACID defines for:
Fig 1 - ACID Properties
1) Atomicity: The term atomicity defines that the data remains atomic. It means if any operation is performed on the data, either it should be performed or executed completely or should not be executed at all. It further means that the operation should not break in between or execute partially. In the case of executing operations on the transaction, the operation should be completely executed and not partially.
Example: If Remo has account A having $30 in his account from which he wishes to send $10 to Sheero's account, which is B. In account B, a sum of $ 100 is already present. When $10 will be transferred to account B, the sum will become $110. Now, there will be two operations that will take place. One is the amount of $10 that Remo wants to transfer will be debited from his account A, and the same amount will get credited to account B, i.e., into Sheero's account. Now, what happens - the first operation of debit executes successfully, but the credit operation, however, fails. Thus, in Remo's account A, the value becomes $20, and to that of Sheero's account, it remains $100 as it was previously present.
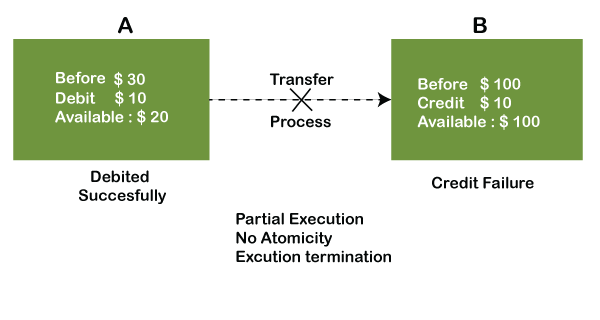
In the above diagram, it can be seen that after crediting $10, the amount is still $100 in account B. So, it is not an atomic transaction.
The below image shows that both debit and credit operations are done successfully. Thus the transaction is atomic.
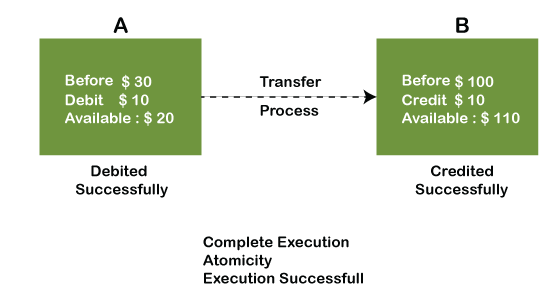
Thus, when the amount loses atomicity, then in the bank systems, this becomes a huge issue, and so the atomicity is the main focus in the bank systems.
2) Consistency: The word consistency means that the value should remain preserved always. In DBMS, the integrity of the data should be maintained, which means if a change in the database is made, it should remain preserved always. In the case of transactions, the integrity of the data is very essential so that the database remains consistent before and after the transaction. The data should always be correct.
Example:
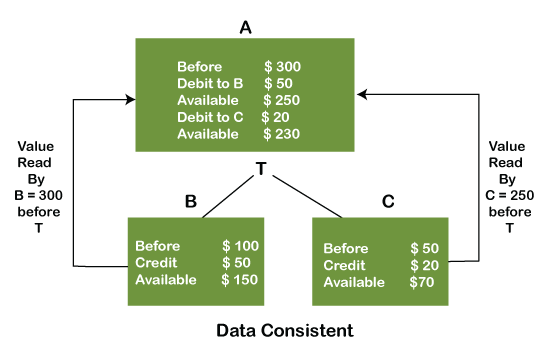
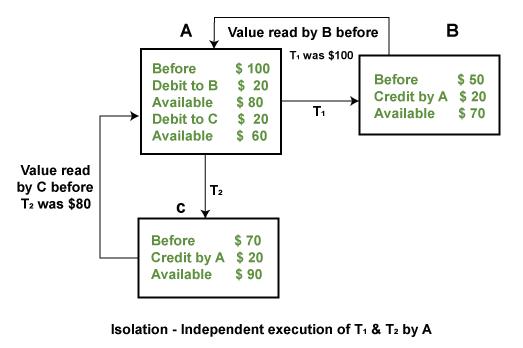
In the above figure, there are three accounts, A, B, and C, where A is making a transaction T one by one to both B & C. There are two operations that take place, i.e., Debit and Credit. Account A firstly debits $50 to account B, and the amount in account A is read $300 by B before the transaction. After the successful transaction T, the available amount in B becomes $150.
Now, A debits $20 to account C, and that time, the value read by C is $250 (that is correct as a debit of $50 has been successfully done to B). The debit and credit operation from account A to C has been done successfully. We can see that the transaction is done successfully, and the value is also read correctly. Thus, the data is consistent. In case the value read by B and C is $300, which means that data is inconsistent because when the debit operation executes, it will not be consistent.
3) Isolation: The term 'isolation' means separation. In DBMS, Isolation is the property of a database where no data should affect the other one and may occur concurrently. In short, the operation on one database should begin when the operation on the first database gets complete. It means if two operations are being performed on two different databases, they may not affect the value of one another. In the case of transactions, when two or more transactions occur simultaneously, the consistency should remain maintained. Any changes that occur in any particular transaction will not be seen by other transactions until the change is not committed in the memory.
Example: If two operations are concurrently running on two different accounts, then the value of both accounts should not get affected. The value should remain persistent. As you can see in the below diagram, account A is making T1 and T2 transactions to account B and C, but both are executing independently without affecting each other. It is known as Isolation.
4) Durability: Durability ensures the permanency of something. In DBMS, the term durability ensures that the data after the successful execution of the operation becomes permanent in the database. The durability of the data should be so perfect that even if the system fails or leads to a crash, the database still survives. However, if gets lost, it becomes the responsibility of the recovery manager for ensuring the durability of the database. For committing the values, the COMMIT command must be used every time we make changes.
Therefore, the ACID property of DBMS plays a vital role in maintaining the consistency and availability of data in the database.
Q5) Explain Implementation of atomicity, Isolation and Durability?
A5) The transaction has the four properties. These are used to maintain consistency in a database, before and after the transaction.
Property of Transaction
- Atomicity
- Consistency
- Isolation
- Durability
Fig 2 - Property of Transaction
Atomicity
● It states that all operations of the transaction take place at once if not, the transaction is aborted.
● There is no midway, i.e., the transaction cannot occur partially. Each transaction is treated as one unit and either run to completion or is not executed at all.
Atomicity involves the following two operations:
Abort: If a transaction aborts then all the changes made are not visible.
Commit: If a transaction commits then all the changes made are visible.
Example: Let's assume that following transaction T consisting of T1 and T2. A consists of Rs 600 and B consists of Rs 300. Transfer Rs 100 from account A to account B.
T1 | T2 |
Read(A) | Read(B) |
After completion of the transaction, A consists of Rs 500 and B consists of Rs 400.
If the transaction T fails after the completion of transaction T1 but before completion of transaction T2, then the amount will be deducted from a but not added to B. This shows the inconsistent database state. In order to ensure correctness of database state, the transaction must be executed in entirety.
Consistency
● The integrity constraints are maintained so that the database is consistent before and after the transaction.
● The execution of a transaction will leave a database in either its prior stable state or a new stable state.
● The consistent property of database states that every transaction sees a consistent database instance.
● The transaction is used to transform the database from one consistent state to another consistent state.
For example: The total amount must be maintained before or after the transaction.
- Total before T occurs = 600+300=900
- Total after T occurs= 500+400=900
Therefore, the database is consistent. In the case when T1 is completed but T2 fails, then inconsistency will occur.
Isolation
● It shows that the data which is used at the time of execution of a transaction cannot be used by the second transaction until the first one is completed.
● In isolation, if the transaction T1 is being executed and using the data item X, then that data item can't be accessed by any other transaction T2 until the transaction T1 ends.
● The concurrency control subsystem of the DBMS enforced the isolation property.
Durability
● The durability property is used to indicate the performance of the database's consistent state. It states that the transaction made the permanent changes.
● They cannot be lost by the erroneous operation of a faulty transaction or by the system failure. When a transaction is completed, then the database reaches a state known as the consistent state. That consistent state cannot be lost, even in the event of a system's failure.
● The recovery subsystem of the DBMS has the responsibility of Durability property.
Q6) Explain testing of serializability in detail in DBMS?
A6) Testing of Serializability
Serialization Graph is used to test the Serializability of a schedule.
Assume a schedule S. For S, we construct a graph known as precedence graph. This graph has a pair G = (V, E), where V consists a set of vertices, and E consists a set of edges. The set of vertices is used to contain all the transactions participating in the schedule. The set of edges is used to contain all edges Ti ->Tj for which one of the three conditions holds:
- Create a node Ti → Tj if Ti executes write (Q) before Tj executes read (Q).
- Create a node Ti → Tj if Ti executes read (Q) before Tj executes write (Q).
- Create a node Ti → Tj if Ti executes write (Q) before Tj executes write (Q).
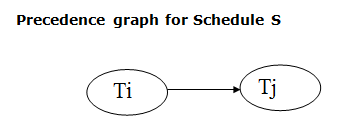
Fig 3 – Precedence Graph
● If a precedence graph contains a single edge Ti → Tj, then all the instructions of Ti are executed before the first instruction of Tj is executed.
● If a precedence graph for schedule S contains a cycle, then S is non-serializable. If the precedence graph has no cycle, then S is known as serializable.
For example:
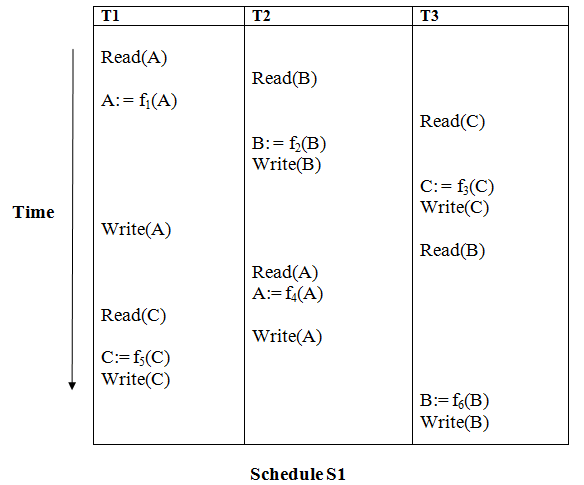
Explanation:
Read(A): In T1, no subsequent writes to A, so no new edges
Read(B): In T2, no subsequent writes to B, so no new edges
Read(C): In T3, no subsequent writes to C, so no new edges
Write(B): B is subsequently read by T3, so add edge T2 → T3
Write(C): C is subsequently read by T1, so add edge T3 → T1
Write(A): A is subsequently read by T2, so add edge T1 → T2
Write(A): In T2, no subsequent reads to A, so no new edges
Write(C): In T1, no subsequent reads to C, so no new edges
Write(B): In T3, no subsequent reads to B, so no new edges
Precedence graph for schedule S1:
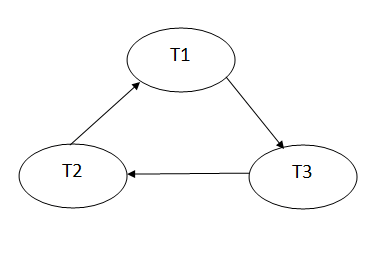
Fig 4 – Precedence graph
The precedence graph for schedule S1 contains a cycle that's why Schedule S1 is non-serializable.
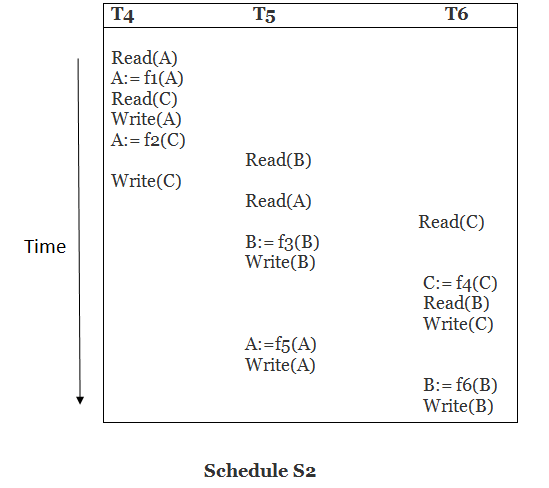
Explanation:
Read(A): In T4,no subsequent writes to A, so no new edges
Read(C): In T4, no subsequent writes to C, so no new edges
Write(A): A is subsequently read by T5, so add edge T4 → T5
Read(B): In T5,no subsequent writes to B, so no new edges
Write(C): C is subsequently read by T6, so add edge T4 → T6
Write(B): A is subsequently read by T6, so add edge T5 → T6
Write(C): In T6, no subsequent reads to C, so no new edges
Write(A): In T5, no subsequent reads to A, so no new edges
Write(B): In T6, no subsequent reads to B, so no new edges
Precedence graph for schedule S2:
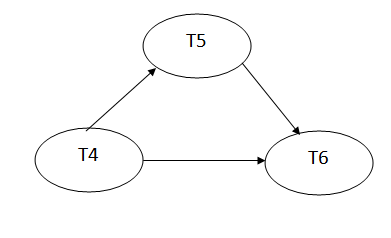
Fig 5 - Precedence graph
The precedence graph for schedule S2 contains no cycle that's why ScheduleS2 is serializable.
Q7) What do you mean by two phase commit protocol?
A7) Two phase commit
The vulnerability of one-phase commit protocols is reduced by distributed two-phase commits. The steps performed in the two phases are as follows −
Phase 1: Prepare Phase
- Each slave sends a "DONE" notification to the controlling site once it has completed its transaction locally. When all slaves have sent a "DONE" message to the controlling site, it sends a "Prepare" message to the slaves.
- The slaves vote on whether they still want to commit or not. If a slave wants to commit, it sends a “Ready” message.
- A slave who refuses to commit sends the message "Not Ready." When the slave has conflicting concurrent transactions or there is a timeout, this can happen.
Phase 2: Commit/Abort Phase
After all of the slaves have sent "Ready" messages to the controlling site,
- The slaves receive a "Global Commit" message from the controlling site.
- The slaves complete the transaction and send the controlling site a "Commit ACK" message.
- The transaction is considered committed when the controlling site receives "Commit ACK" messages from all slaves.
After any slave sends the first "Not Ready" notification to the controlling site,
- The slaves receive a "Global Abort" notification from the controlling site.
- The slaves abort the transaction and send the controlling site a "Abort ACK" message.
- The transaction is considered aborted when the controlling site receives "Abort ACK" messages from all slaves.
Q8) What is recovery and atomicity?
A8) When a system crashes, it may have several transactions being executed and various files opened for them to modify the data items. Transactions are made of various operations, which are atomic in nature. But according to ACID properties of DBMS, atomicity of transactions as a whole must be maintained, that is, either all the operations are executed or none.
When a DBMS recovers from a crash, it should maintain the following −
- It should check the states of all the transactions, which were being executed.
- A transaction may be in the middle of some operation; the DBMS must ensure the atomicity of the transaction in this case.
- It should check whether the transaction can be completed now or it needs to be rolled back.
- No transactions would be allowed to leave the DBMS in an inconsistent state.
There are two types of techniques, which can help a DBMS in recovering as well as maintaining the atomicity of a transaction −
- Maintaining the logs of each transaction, and writing them onto some stable storage before actually modifying the database.
- Maintaining shadow paging, where the changes are done on a volatile memory, and later, the actual database is updated.
Log-based Recovery
Log is a sequence of records, which maintains the records of actions performed by a transaction. It is important that the logs are written prior to the actual modification and stored on a stable storage media, which is failsafe.
Log-based recovery works as follows −
- The log file is kept on a stable storage media.
- When a transaction enters the system and starts execution, it writes a log about it.
<Tn, Start>
- When the transaction modifies an item X, it write logs as follows −
<Tn, X, V1, V2>
It reads Tn has changed the value of X, from V1 to V2.
- When the transaction finishes, it logs −
<Tn, commit>
The database can be modified using two approaches −
- Deferred database modification− All logs are written on to the stable storage and the database is updated when a transaction commits.
- Immediate database modification−Each log follows an actual database modification. That is, the database is modified immediately after every operation.
Recovery with Concurrent Transactions
When more than one transaction are being executed in parallel, the logs are interleaved. At the time of recovery, it would become hard for the recovery system to backtrack all logs, and then start recovering. To ease this situation, most modern DBMS use the concept of 'checkpoints'.
Checkpoint
Keeping and maintaining logs in real time and in real environment may fill out all the memory space available in the system. As time passes, the log file may grow too big to be handled at all. Checkpoint is a mechanism where all the previous logs are removed from the system and stored permanently in a storage disk. Checkpoint declares a point before which the DBMS was in consistent state, and all the transactions were committed.
Recovery
When a system with concurrent transactions crashes and recovers, it behaves in the following manner −

Fig 6: Recovery
- The recovery system reads the logs backwards from the end to the last checkpoint.
- It maintains two lists, an undo-list and a redo-list.
- If the recovery system sees a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, it puts the transaction in the redo-list.
- If the recovery system sees a log with <Tn, Start> but no commit or abort log found, it puts the transaction in undo-list.
All the transactions in the undo-list are then undone and their logs are removed. All the transactions in the redo-list and their previous logs are removed and then redone before saving their logs.
Q9) Define log based recovery?
A9) The log is made up of a series of records. Each transaction is logged and stored in a secure location so that it may be recovered in the event of a failure.
Any operation that is performed on the database is documented in the log.
However, before the actual transaction is applied to the database, the procedure of saving the logs should be completed.
Let's pretend there's a transaction to change a student's city. This transaction generates the following logs.
- When a transaction is started, the start' log is written.
<Tn, Start>
- Another log is written to the file when the transaction changes the City from 'Noida' to 'Bangalore.'
<Tn, City, 'Noida', 'Bangalore' >
- When the transaction is completed, it writes another log to mark the transaction's completion.
<Tn, Commit>
The database can be modified in two ways:
1. Deferred database modification:
If a transaction does not affect the database until it has committed, it is said to use the postponed modification strategy. When a transaction commits, the database is updated, and all logs are created and stored in the stable storage.
2. Immediate database modification:
If a database change is made while the transaction is still running, the Immediate modification approach is used.
The database is changed immediately after each action in this method. It occurs after a database change has been made.
Recovery using Log records
When a system crashes, the system reads the log to determine which transactions must be undone and which must be redone.
- The Transaction Ti must be redone if the log contains the records <Ti, Start> and <Ti, Commit> or <Ti, Commit>.
- If the log contains the record <Tn, Start> but not the records <Ti, commit> or <Ti, abort>, then the Transaction Ti must be undone.
Q10) Explain deadlock?
A10) A deadlock occurs when two or more transactions are stuck waiting for one another to release locks indefinitely. Deadlock is regarded to be one of the most dreaded DBMS difficulties because no work is ever completed and remains in a waiting state indefinitely.
For example, transaction T1 has a lock on some entries in the student table and needs to update some rows in the grade table. At the same time, transaction T2 is holding locks on some rows in the grade table and needs to update the rows in the Student table that Transaction T1 is holding.
The primary issue now arises. T1 is currently waiting for T2 to release its lock, and T2 is currently waiting for T1 to release its lock. All actions come to a complete halt and remain in this state. It will remain at a halt until the database management system (DBMS) recognizes the deadlock and aborts one of the transactions.

Fig 7: Deadlock
Deadlock Avoidance
When a database becomes stuck in a deadlock condition, it is preferable to avoid the database rather than abort or restate it. This is a waste of both time and money.
Any deadlock condition is detected in advance using a deadlock avoidance strategy. For detecting deadlocks, a method such as "wait for graph" is employed, although this method is only effective for smaller databases. A deadlock prevention strategy can be utilized for larger databases.
Deadlock Detection
When a transaction in a database waits endlessly for a lock, the database management system (DBMS) should determine whether the transaction is in a deadlock or not. The lock management keeps a Wait for the graph to detect the database's deadlock cycle.
Wait for Graph
This is the best way for detecting deadlock. This method generates a graph based on the transaction and its lock. There is a deadlock if the constructed graph has a cycle or closed loop.
The system maintains a wait for the graph for each transaction that is awaiting data from another transaction. If there is a cycle in the graph, the system will keep checking it.
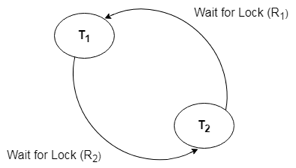
Fig 8: Wait for a graph
Deadlock Prevention
A huge database can benefit from a deadlock prevention strategy. Deadlock can be avoided if resources are distributed in such a way that deadlock never arises.
The database management system examines the transaction's operations to see if they are likely to cause a deadlock. If they do, the database management system (DBMS) never allows that transaction to be completed.
Time stamping Methods
- Time stamp is a unique identifier created by the DBMS to identify a transaction.
- These values are assigned, in the order in which the transactions are submitted to the system, so timestamp can be thought of as the transaction start time.
- It is denoted as Ts(T).
- Note: - Concurrency control techniques based on timestamp ordering do not use locks, here deadlock cannot occur.
Generation of timestamp:
Timestamps can be generated in several ways like:
- Use a counter that is incremental each time its value is assigned to a transaction. Transaction timestamps are numbered 1,2, 3, in this scheme. The system must periodically reset the counter to zero when no transactions are executing for some short period of time.
- Another way is to use the current date/time of the system lock.
- Two timestamp values are associated with each database item X: -
1) Read-Ts(X): -
i. Read timestamp of X.
Ii. Read –Ts(X) = Ts(T)
Where T is the youngest transaction that has read X successfully.
2) Write-Ts(X): -
i. Write timestamp of X.
Ii.Write-Ts(X) = Ts(T),
Where T is the youngest transaction that has written X successfully.
These timestamps are updated whenever a new read(X) or write(X) instruction is executed.
Timestamp Ordering Algorithm:
a. Whenever some transaction T issues a Read(X) or Write(X) operation, the algorithm compares Ts(T) with Read-Ts(X) & Write-Ts(X) to ensure that the timestamp order of execution is not violated.
b. If violate, transaction is aborted & resubmitted to system as a new transaction with new timestamp.
c. If T is aborted & rolled back, any transaction T1 that may have used a value written by T must also be rolled back.
d. Similarly, any transaction T2 that may have used a value written by T1 must also be rolled back & so on.
So, cascading rollback problems is associated with this algorithm.
Algorithm: -
1) If transaction T issues a written(X) operation: -
a) If Read-Ts(X) > Ts(T)
OR
Write-Ts(X) > Ts(T)
Then abort & rollback T & reject the operation.
This is done because some younger transaction with a timestamp greater than Ts(T) has already read/written the value of X before T had a chance to write(X), thus violating timestamp ordering.
b) If the condition in (a) does not occur then execute write (X) operation of T & set write-Ts(X) to Ts(T).
2) If a transaction T issues a read(X) operation.
a. If write-Ts(X) > Ts(T), then abort & Rollback T & reject the operation.
This should be done because some younger transaction with timestamp greater than Ts(T) has already written the value of X before T had a chance to read X.
b. If Write-Ts(X) ≤ Ts(T), then execute the read(X) operation of T & set read-Ts(X) to the larger of Ts(T) & current read-Ts(X).
Q11) Write the advantages and disadvantages of deadlock?
A11) Advantages: -
1. Timestamp ordering protocol ensures conflict serializability. This is because conflicting order.
2. The protocol ensures freedom from deadlock, since no transaction ever waits.
Disadvantages: -
1. There is a possibility of starvation of long transactions if a sequence of conflicting short transaction causes repeated restarting of long transaction.
2. The protocol can generate schedules that are not recoverable.
Q12) Write short notes on two phase locking protocol?
A12) Two-Phase Locking Protocol: -
- Each transaction in the system should follow a set of rules, called locking protocol.
- A transaction is said to follow the two-phase locking protocol, if all locking operation (shared, exclusive protocol) precede the first unlock operation.
- Such a transaction can be divided into two phases: Growing & shrinking phase.
- During Expanding / Growing phase, new locks on items can be acquired but no one can be released.
- During a shrinking phase, existing locks can be released but no new locks can be acquired.
- If every transaction in a schedule follows the two-phase locking protocol, the schedule is guaranteed to be serialization, obviating the need to test for Serializability.
- Consider the following schedules S11, S12. S11 does not follow two-phase locking &S12 follows two-phase locking protocol.
T1
Lock_S(Y) R(Y) Unlock(Y) Lock_X(Q) R(Q) Unlock(Q) Q: = Q + Y; W(Q); Unlock(Q)
|
This schedule does not follow two phase locking because 3 rd instruction lock-X(Q) appears after unlock(Y) instruction.
T1
Lock_S(Y) R(Y) Lock_X(Q) R(Q) Q: = Q + Y; W(Q); Unlock(Q); Unlock(Y); |
This schedule follows two-phase locking because all lock instructions appear before first unlock instruction.
Q13) Define isolation?
A13) As we all know, a database must adhere to ACID properties in order to maintain consistency. Isolation affects how transaction integrity is observable to other users and systems among these four properties (Atomicity, Consistency, Isolation, and Durability). It indicates that a transaction should occur in a system in such a way that it is the sole transaction that accesses the database system's resources.
The degree to which a transaction must be isolated from data updates performed by any other transaction in the database system is defined by isolation levels.
Isolation influences how transaction integrity is visible to other users and systems in database systems.
Lowering the isolation level allows more users to access the same data at the same time, but it also increases the number of concurrent effects (such as dirty reads or lost updates) that users may experience. A higher isolation level, on the other hand, reduces the types of concurrency effects that users may encounter while also requiring more system resources and increasing the likelihood that one transaction would block another.
Isolation is usually described at the database level as a property that specifies how or when[clarification needed] the changes produced by one activity become apparent to other operations. It may be implemented systematically on older systems, such as by the usage of temporary tables.
To ensure isolation in two-tier systems, a transaction processing (TP) manager is required. To commit the booking and transmit confirmation to the consumer in n-tier systems (such as many websites attempting to reserve the final ticket on a flight), a combination of stored procedures and transaction management is necessary.
Along with atomicity, consistency, and durability, isolation is one of the four ACID qualities.
It determines the visibility of other systems' transactions. Every user has access to the same data at a lower level. As a result, there is a considerable danger of data privacy and system security. Higher isolation levels, on the other hand, reduce the type of concurrency over the data, but they demand more resources and are slower than lower isolation levels.
Isolation methods help protect data from unauthorised transactions. They ensure data integrity by defining how and when changes made by one process become visible to others.
Levels of isolation
Isolations are classified into four levels, which are described below.
● Read Uncommitted − It's the most isolated state possible. Dirty reads are allowed at this level, which means that one can read the uncommitted changes done by another.
● Read committed − There are no dirty reads allowed, and any uncommitted data is now committed after it is read.
● Repeatable Read − This is the most severe form of isolation. The transaction has read locks on all the rows it references, as well as write locks on the rows it updates, inserts, or deletes. As a result, there is no risk of non-repeatable readings.
● Serializable − The pinnacle of civilization. It specifies that all concurrent transactions should be processed in a sequential order.
Q14) What is Failure classification in DBMS?
A14) To find that where the problem has occurred, we generalize a failure into the following categories:
- Transaction failure
- System crash
- Disk failure
1. Transaction failure
The transaction failure occurs when it fails to execute or when it reaches a point from where it can't go any further. If a few transaction or process is hurt, then this is called as transaction failure.
Reasons for a transaction failure could be -
- Logical errors: If a transaction cannot complete due to some code error or an internal error condition, then the logical error occurs.
- Syntax error: It occurs where the DBMS itself terminates an active transaction because the database system is not able to execute it. For example, The system aborts an active transaction, in case of deadlock or resource unavailability.
2. System Crash
- System failure can occur due to power failure or other hardware or software failure. Example: Operating system error.
- Fail-stop assumption: In the system crash, non-volatile storage is assumed not to be corrupted.
3. Disk Failure
● It occurs where hard-disk drives or storage drives used to fail frequently. It was a common problem in the early days of technology evolution.
● Disk failure occurs due to the formation of bad sectors, disk head crash, and unreachability to the disk or any other failure, which destroy all or part of disk storage.
Q15) What is Crash Recovery in DBMS explain in detail?
A15) DBMS is a highly complex system with hundreds of transactions being executed every second. The durability and robustness of a DBMS depends on its complex architecture and its underlying hardware and system software. If it fails or crashes amid transactions, it is expected that the system would follow some sort of algorithm or techniques to recover lost data.
Failure Classification
To see where the problem has occurred, we generalize a failure into various categories, as follows −
Transaction failure
A transaction has to abort when it fails to execute or when it reaches a point from where it can’t go any further. This is called transaction failure where only a few transactions or processes are hurt.
Reasons for a transaction failure could be −
● Logical errors − Where a transaction cannot complete because it has some code error or any internal error condition.
● System errors − Where the database system itself terminates an active transaction because the DBMS is not able to execute it, or it has to stop because of some system condition. For example, in case of deadlock or resource unavailability, the system aborts an active transaction.
System Crash
There are problems − external to the system − that may cause the system to stop abruptly and cause the system to crash. For example, interruptions in power supply may cause the failure of underlying hardware or software failure.
Examples may include operating system errors.
Disk Failure
In early days of technology evolution, it was a common problem where hard-disk drives or storage drives used to fail frequently.
Disk failures include formation of bad sectors, unreachability to the disk, disk head crash or any other failure, which destroys all or a part of disk storage.
Storage Structure
We have already described the storage system. In brief, the storage structure can be divided into two categories −
● Volatile storage − As the name suggests, a volatile storage cannot survive system crashes. Volatile storage devices are placed very close to the CPU; normally they are embedded onto the chipset itself. For example, main memory and cache memory are examples of volatile storage. They are fast but can store only a small amount of information.
● Non-volatile storage − These memories are made to survive system crashes. They are huge in data storage capacity, but slower in accessibility. Examples may include hard-disks, magnetic tapes, flash memory, and non-volatile (battery backed up) RAM.
Q16) What is Log-based Recovery?
A16) Log is a sequence of records, which maintains the records of actions performed by a transaction. It is important that the logs are written prior to the actual modification and stored on a stable storage media, which is failsafe.
Log-based recovery works as follows −
● The log file is kept on a stable storage media.
● When a transaction enters the system and starts execution, it writes a log about it.
<Tn, Start>
● When the transaction modifies an item X, it write logs as follows −
<Tn, X, V1, V2>
It reads Tn has changed the value of X, from V1 to V2.
● When the transaction finishes, it logs −
<Tn, commit>
The database can be modified using two approaches −
● Deferred database modification − All logs are written on to the stable storage and the database is updated when a transaction commits.
● Immediate database modification − Each log follows an actual database modification. That is, the database is modified immediately after every operation.
Q17) Explain Recovery with Concurrent Transactions in DBMS
A17) When more than one transaction are being executed in parallel, the logs are interleaved. At the time of recovery, it would become hard for the recovery system to backtrack all logs, and then start recovering. To ease this situation, most modern DBMS use the concept of 'checkpoints'.
Checkpoint
Keeping and maintaining logs in real time and in real environment may fill out all the memory space available in the system. As time passes, the log file may grow too big to be handled at all. Checkpoint is a mechanism where all the previous logs are removed from the system and stored permanently in a storage disk. Checkpoint declares a point before which the DBMS was in consistent state, and all the transactions were committed.
Recovery
When a system with concurrent transactions crashes and recovers, it behaves in the following manner −

Fig 9 - Recovery
● The recovery system reads the logs backwards from the end to the last checkpoint.
● It maintains two lists, an undo-list and a redo-list.
● If the recovery system sees a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>, it puts the transaction in the redo-list.
● If the recovery system sees a log with <Tn, Start> but no commit or abort log found, it puts the transaction in undo-list.
All the transactions in the undo-list are then undone and their logs are removed. All the transactions in the redo-list and their previous logs are removed and then redone before saving their logs.
Q18) Explain in detail log based recovery in DBMS?
A18) Log based recovery
● The log is a sequence of records. Log of each transaction is maintained in some stable storage so that if any failure occurs, then it can be recovered from there.
● If any operation is performed on the database, then it will be recorded in the log.
● But the process of storing the logs should be done before the actual transaction is applied in the database.
Let's assume there is a transaction to modify the City of a student. The following logs are written for this transaction.
● When the transaction is initiated, then it writes 'start' log.
- <Tn, Start>
● When the transaction modifies the City from 'Noida' to 'Bangalore', then another log is written to the file.
- <Tn, City, 'Noida', 'Bangalore' >
● When the transaction is finished, then it writes another log to indicate the end of the transaction.
- <Tn, Commit>
There are two approaches to modify the database:
1. Deferred database modification:
● The deferred modification technique occurs if the transaction does not modify the database until it has committed.
● In this method, all the logs are created and stored in the stable storage, and the database is updated when a transaction commits.
2. Immediate database modification:
● The Immediate modification technique occurs if database modification occurs while the transaction is still active.
● In this technique, the database is modified immediately after every operation. It follows an actual database modification.
Recovery using Log records
When the system is crashed, then the system consults the log to find which transactions need to be undone and which need to be redone.
- If the log contains the record <Ti, Start> and <Ti, Commit> or <Ti, Commit>, then the Transaction Ti needs to be redone.
- If log contains record<Tn, Start> but does not contain the record either <Ti, commit> or <Ti, abort>, then the Transaction Ti needs to be undone.
Q19) Explain Checkpoints in DBMS?
A19) Checkpoints
● The checkpoint is a type of mechanism where all the previous logs are removed from the system and permanently stored in the storage disk.
● The checkpoint is like a bookmark. While the execution of the transaction, such checkpoints are marked, and the transaction is executed then using the steps of the transaction, the log files will be created.
● When it reaches to the checkpoint, then the transaction will be updated into the database, and till that point, the entire log file will be removed from the file. Then the log file is updated with the new step of transaction till next checkpoint and so on.
● The checkpoint is used to declare a point before which the DBMS was in the consistent state, and all transactions were committed.
Recovery using Checkpoint
In the following manner, a recovery system recovers the database from this failure:
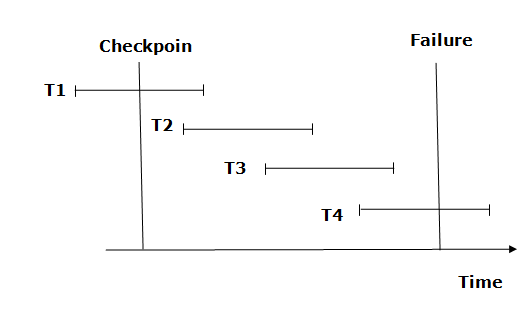
Fig 10 – Recovery using checkpoint
● The recovery system reads log files from the end to start. It reads log files from T4 to T1.
● Recovery system maintains two lists, a redo-list, and an undo-list.
● The transaction is put into redo state if the recovery system sees a log with <Tn, Start> and <Tn, Commit> or just <Tn, Commit>. In the redo-list and their previous list, all the transactions are removed and then redone before saving their logs.
● For example: In the log file, transaction T2 and T3 will have <Tn, Start> and <Tn, Commit>. The T1 transaction will have only <Tn, commit> in the log file. That's why the transaction is committed after the checkpoint is crossed. Hence it puts T1, T2 and T3 transaction into redo list.
● The transaction is put into undo state if the recovery system sees a log with <Tn, Start> but no commit or abort log found. In the undo-list, all the transactions are undone, and their logs are removed.
● For example: Transaction T4 will have <Tn, Start>. So T4 will be put into the undo list since this transaction is not yet complete and failed amid.




