Unit – 5
A Case Study
Q1) What are the design problems to design a document editor?
A1) We'll look at seven issues with Lexi's design:
● Document structure
Almost every aspect of Lexi's design is influenced by the document's internal representation. The representation will be traversed for all editing, formatting, displaying, and textual analysis. The way we organize this data will have an impact on the remainder of the app's design.
● Formatting
What is Lexi's method for dividing text and pictures into lines and columns? What objects are in charge of enforcing certain formatting policies? What is the relationship between these policies and the internal representation of the document?
● Embellishing the user interface
Scroll bars, borders, and drop shadows are included in Lexi's user interface, which complement the WYSIWYG document interface. As Lexi's user interface evolves, such embellishments are likely to change. As a result, it's critical to be able to easily add and delete embellishments without disrupting the rest of the programme.
● Supporting multiple look-and-feel standards
Lexi should be able to readily adapt to different look-and-feel standards like Motif and Presentation Manager (PM) without requiring large changes.
● Supporting multiple window systems
On different window systems, different look-and-feel standards are frequently implemented. Lexi's design should be as autonomous as possible from the window system.
● User operations
Lexi is controlled through a variety of user interfaces, such as buttons and pull-down menus. The functionality behind these interfaces is dispersed across the application's objects. The problem here is to provide a unified way for both accessing and removing this dispersed functionality.
● Spelling checking and hyphenation
Lexi's support for analytical procedures like checking for misspelled words and determining hyphenation spots is quite impressive. How can we reduce the number of classes that need to be changed in order to implement a new analytical operation?
Each challenge contains a set of objectives as well as limits on how we will reach those objectives.
Q2) What do you mean by document structure?
A2) In the end, a document is nothing more than a collection of basic graphical elements including characters, lines, polygons, and other shapes. These elements encompass the document's whole information content. Yet an author often views these elements not in graphical terms but in terms of the document's physical structure—lines, columns, figures, tables, and other substructures. In turn, these substructures have substructures of their own, and so on.
The user interface for Lexi should allow users to directly alter these substructures. For example, rather than treating a diagram as a collection of distinct graphical primitives, a user should be able to consider it as a single unit. A table should be able to be referred to as a whole, not as a jumble of text and visuals. This contributes to the interface's simplicity and intuitiveness. We'll choose an internal representation that matches the document's physical structure to provide Lexi's implementation similar properties.
Internal representation should, in particular, support the following:
● Maintaining the physical structure of the document, which includes the arranging of text and visuals into lines, columns, tables, and other structures.
● Visually creating and displaying the document.
● The mapping of display positions to items in the internal representation. When the user points to something in the visual depiction, Lexi can figure out what he's talking about.
There are additional limitations in addition to these objectives. To begin, we should treat text and visuals in the same way. The user interface of the application allows the user to freely incorporate text within visuals and vice versa. Otherwise, we'll wind up with redundant formatting and manipulation procedures if we regard graphics as a special instance of text or text as a special case of graphics. For both text and visuals, a single set of methods should be sufficient.
Second, in the internal representation, our implementation should not have to discriminate between single items and groups of components. Lexi should be able to treat basic and complex elements in the same way, enabling for the creation of arbitrarily complex documents. For example, the tenth element in line five of column two could be a single character or a complex graphic with numerous subelements. The complexity of this element has no influence on how and where it should appear on the page as long as we know it can draw itself and specify its dimensions.
The necessity to assess the text for things like spelling problems and probable hyphenation points, on the other hand, is in direct opposition to the second limitation. We don't always care if a line's element is a simple or complex item. However, an analysis might also be dependent on the things being analysed. Checking the spelling of a polygon or hyphenating it, for example, makes no sense. The internal representation's design should take this and other potentially conflicting constraints into account.
Recursive Composition
Recursive composition, which requires creating progressively complex pieces out of simpler ones, is a typical way to express hierarchically ordered information. We may use recursive composition to create a document out of simple graphical pieces. To begin, we can tile a series of characters and visuals from left to right in the document to construct a line. Then you may arrange several lines to make a column, multiple columns to make a page, and so on.
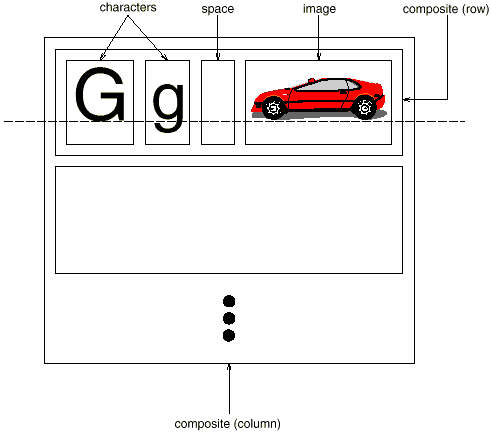
Fig 1: Recursive composition of text and graphics
We may express this physical structure by giving each important constituent its own object. This includes not just the visible elements like as text and graphics, but also the unseen structural elements such as lines and columns. The object structure illustrated in Figure is the end outcome.
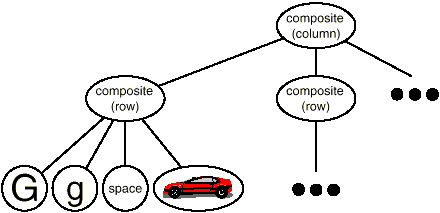
Fig 2: Object structure for recursive composition of text and graphics
We promote flexibility at the highest levels of Lexi's design by using an object for each character and graphical element in the page. Text and visuals can be treated the same way in terms of how they're produced, formatted, and embedded in one other. Lexi may be extended to handle additional character sets without affecting existing features. Lexi's object structure is based on the physical structure of the document.
Glyphs
For all items that can appear in a document structure, we'll create a Glyph abstract class. Its subclasses define both basic graphical elements (such as characters and images) as well as structural elements (like rows and columns). The fundamental glyph interface is presented in further depth using C++ notation in Table, which illustrates a typical component of the Glyph class hierarchy.
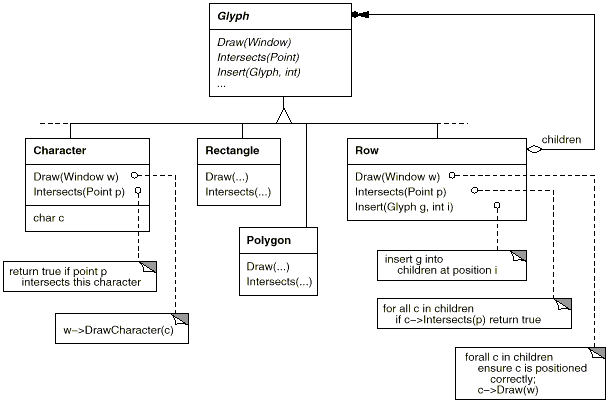
Fig 3: Partial Glyph class hierarchy
Responsibility | Operations |
Appearance | Virtual void Draw(Window*) Virtual void Bounds(Rect&) |
Hit detection | Virtual bool Intersects(const Point&) |
Structure | Virtual void Insert(Glyph*, int) Virtual void Remove(Glyph*) Virtual Glyph* Child(int) Virtual Glyph* Parent() |
Table: Basic glyph interface
Glyphs have three primary functions. They understand (1) how to sketch themselves, (2) how much space they take up, and (3) how to communicate with their children and parents.
Composite Pattern
More than simply documents benefit from recursive composition. It can be used to represent any hierarchical structure that is potentially complex. In object-oriented terms, the Composite pattern embodies the core of recursive composition. It's a good idea to go back to that pattern and examine it now, referring back to this instance as needed.
Q3) Describe formatting?
A3) We've decided on a way to represent the physical structure of the document. The next step is to figure out how to build a certain physical structure that matches to a correctly structured document. The terms "representation" and "formatting" are not interchangeable: The capacity to represent the physical structure of a document does not tell us how to get to that structure.
Lexi bears the brunt of this obligation. It must divide text into lines, lines into columns, and so on, taking the user's higher-level preferences into account. For example, the user would want to change the margin widths, indentation, and tabulation; single or double space; and presumably a variety of other formatting options. All of these must be taken into account by Lexi's formatting algorithm.
By the way, we'll define "formatting" as the process of dividing a group of glyphs into lines. In reality, we'll exchange the phrases "formatting" and "line breaking." The strategies we'll go over can be used to divide lines into columns as well as columns into pages.
Encapsulating the Formatting Algorithm
With all of its limits and complexities, the formatting process is difficult to automate. There are numerous approaches to the problem, and various formatting algorithms have been developed, each with its own set of strengths and limitations. Because Lexi is a WYSIWYG editor, the balance between formatting quality and formatting speed is a critical trade-off to consider. We want a positive response from the editor without jeopardizing the document's appearance. This trade-off is influenced by a number of variables, not all of which can be determined at compile time.
For instance, the user could be willing to put up with a somewhat slower response in return for better formatting. Because of this trade-off, a completely alternative formatting algorithm may be more suited than the existing one. Formatting speed and storage requirements are balanced in another, more implementation-driven trade-off: By caching additional data, it may be able to reduce formatting time.
Due to the complexity of formatting algorithms, it's best to make them self-contained or, better yet, fully independent of the document structure. In an ideal world, we'd be able to add a new type of Glyph subclass that didn't care about the formatting methodology. Adding a new formatting mechanism, on the other hand, should not necessitate changing existing glyphs.
These qualities suggest that we should design Lexi so that changing the formatting method is simple, at least at build time, if not at run time. Encapsulating the algorithm in an object allows us to isolate it while also making it easily changeable. We'll create a new class hierarchy for objects that encapsulate formatting algorithms in more detail. Each subclass will implement the interface to carry out a certain algorithm, with the root of the hierarchy defining an interface that supports a wide range of formatting algorithms. Then we can add a Glyph subclass that will automatically arrange its children using a provided algorithm object.
Compositor and Composition
For objects that can encapsulate a formatting algorithm, we'll define the Compositor class. The interface informs the compositor of which glyphs should be formatted and when they should be formatted. It formats glyphs that belong to a special Glyph subclass called Composition. When a composition is built, it receives an instance of the Compositor subclass (specialized for a specific line breaking algorithm) and instructs the compositor to Compose its glyphs as needed, such as when the user edits a document. The links between the Composition and Compositor classes are shown in the diagram.
Responsibility | Operations |
What to format | Void SetComposition(Composition*) |
When to format | Virtual void Compose() |
Table: Basic compositor interface
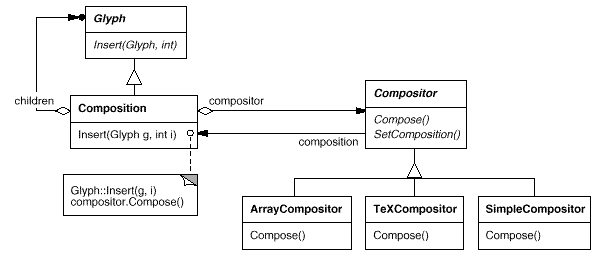
Fig 4: Composition and Compositor class relationships
Strategy Pattern
The Strategy pattern's goal is to encapsulate an algorithm in an object. Strategy objects (which encapsulate various algorithms) and the context in which they function are crucial actors in the pattern. Compositors are a type of strategy that encapsulates several formatting procedures. The context for a compositor strategy is composition.
Designing interfaces for the strategy and its surroundings that are generic enough to allow a variety of algorithms is the key to using the Strategy pattern. To support a new algorithm, you shouldn't have to update the strategy or the context interface. In our example, the Glyph interface's support for child access, insertion, and removal is broad enough to allow Compositor subclasses to modify the document's physical structure independent of the method they use. Similarly, the Compositor interface provides everything that compositions require to begin formatting.
Q4) What is Embellishing the User Interface?
A4) We look at two enhancements to Lexi's user interface. To demarcate the text page, the first inserts a border around the text editing area. The second adds scroll bars, which allow the user to examine various areas of the page. We shouldn't use inheritance to add these embellishments to the user interface because it makes it difficult to add and delete them (particularly at run-time). When other user interface items are unaware of the embellishments, we gain the most flexibility. This allows us to add and remove embellishments without having to change any other classes.
Transparent Enclosure
Enhancing the user interface from a programming standpoint entails expanding existing code. Using inheritance to achieve such extension prevents reordering embellishments at runtime, but an equally important issue is the expansion of classes that might occur from using inheritance.
We could give Composition a border by subclassing it to get the BorderedComposition class. Alternatively, we could create a ScrollableComposition by adding a scrolling interface in the same way. We could make a BorderedScrollableComposition if we want both scroll bars and a border, and so forth. We end up with a class for every potential combination of embellishments in the extreme, a strategy that quickly becomes untenable as the number of embellishments increases.
Object composition may provide a more practical and adaptable extension technique. But what are the objects that we put together? We could make the decoration an object because we're embellishing an existing glyph (say, an instance of class Border). The glyph and the border are the two choices for composition. The next stage is to figure out who will compose who. The glyph may be contained within the border, which makes sense considering that the border will surround the glyph on the screen. Alternatively, we could put the border inside the glyph, but this would necessitate changes to the relevant Glyph subclass to make it aware of the border. Our first choice, composing the glyph in the border, keeps the border-drawing code entirely in the Border class, leaving other classes alone.
Monoglyph
All glyphs that decorate other glyphs can benefit from the concept of translucent enclosure. To put this idea into practise, we'll create a MonoGlyph subclass of Glyph that will serve as an abstract class for "embellishment glyphs" like Border. MonoGlyph keeps track of a component's reference and routes all requests to it. By default, MonoGlyph is completely transparent to clients. MonoGlyph, for example, implements the Draw action as follows:
Void MonoGlyph::Draw (Window* w) {
_component->Draw(w);
}
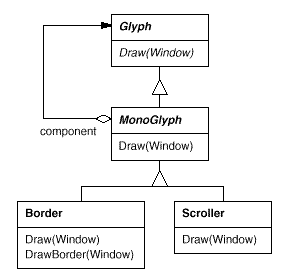
Fig 5: MonoGlyph class relationships
At least one of these forwarding procedures is reimplemented by MonoGlyph subclasses. For example, the parent class action is called first by Border::Draw. MonoGlyph:: Draw everything except the border on the component to allow the component to do its job. Then Border::Draw draws the border by invoking a private operation called DrawBorder, which we won't get into here:
Void Border::Draw (Window* w) {
MonoGlyph::Draw(w);
DrawBorder(w);
}
Take note of how Boundary::Draw extends the parent class's action to draw the border. In contrast, just replacing the parent class operation would result in the call to MonoGlyph::Draw being omitted.
Figure shows another MonoGlyph subclass. Scroller is a MonoGlyph that draws its component in various locations depending on the positions of two scroll bars it adds as embellishments. Scroller tells the graphics system to clip to its bounds when it draws its component. Clipping scrolled-out elements of the component prevents them from appearing on the screen.
We now have everything we need to give Lexi's text editing area a boundary and a scrolling interface. To add the scrolling interface, we compose the existing Composition instance in a Scroller instance, which we then compose in a Border instance. Figure shows the resulting object structure.
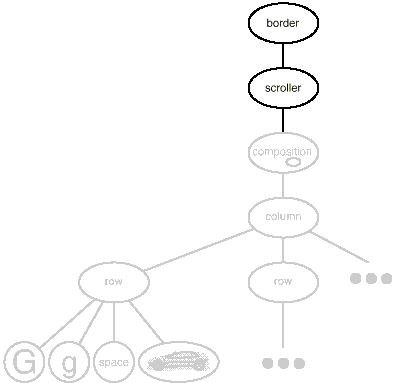
Fig 6: Embellished object structure
It's worth noting that we can change the composition order by adding the bordered composition into the Scroller instance. The border would scroll with the text in that situation, which may or may not be acceptable. The goal is that a transparent enclosure allows customers to experiment with various options while also keeping them free of decorative code.
Decorator Pattern
The Decorator pattern records class and object relationships that enable transparent enclosure decorating. The phrase "embellishment" has a broader definition than what we've looked at thus far. In the Decorator pattern, decoration refers to anything that gives an item more responsibility. Consider adding semantic actions to an abstract syntax tree, adding new transitions to a finite state automaton, or adding attribute tags to a network of persistent objects. Decorator generalizes the approach we used in Lexi so that it may be used more extensively.
Q5) Write about Supporting Multiple Look-and-Feel Standards?
A5) A fundamental challenge in system design is achieving portability between hardware and software platforms. It shouldn't need a huge change to retarget Lexi to a new platform, or it wouldn't be worth it. Porting should be as simple as feasible.
The variety of look-and-feel standards, which are designed to enforce conformity between apps, is one barrier to portability. These principles dictate how apps appear and interact with users. While current standards aren't all that dissimilar, consumers won't mistake one for the other—motif applications don't appear or feel the same as their counterparts on other platforms, and vice versa. An application that runs on many platforms must follow each platform's user interface style guide.
Abstracting Object Creation
Our design aims were to make Lexi comply to a variety of existing look-and-feel standards while also making it simple to add support for new standards when they (inevitably) emerge. We also want our design to allow us to change Lexi's appearance and feel at any time during the game.
In Lexi's user interface, everything we see and interact with is a glyph made up of other, unseen glyphs like Row and Column. The visible glyphs, such as Button and Character, are made up of invisible glyphs that lay them out appropriately. Style guides have a lot to say about how "widgets," or visible symbols like buttons, scroll bars, and menus that operate as controlling elements in a user interface, appear and feel.
We'll suppose we have two sets of widget glyph classes to work with in order to create multiple look-and-feel guidelines:
● Each kind of widget glyph has a set of abstract Glyph subclasses. ScrollBar, for example, is an abstract class that adds general scrolling operations to the basic glyph interface; Button is an abstract class that adds button-oriented activities; and so on.
● Each abstract subclass has a set of concrete subclasses that implement different look-and-feel standards. MotifScrollBar and PMScrollBar are two subclasses of ScrollBar that implement Motif and Presentation Manager-style scroll bars, respectively.
Lexi needs to be able to tell the difference between widget glyphs for different look-and-feel styles. When Lexi needs to add a button to its interface, for example, it must create a Glyph subclass for the appropriate button style (MotifButton, PMButton, MacButton, etc.).
It's clear that Lexi's implementation can't do this directly, say, using a constructor call in C++. This would hard-code a style's button, making it impossible to change the style at run-time. We'd also have to track down and change every such constructor call to port Lexi to another platform. Buttons are only one of the many widgets available in Lexi's user interface. Constructor calls to specialized look-and-feel classes litter our code, resulting in a maintenance nightmare—miss one, and you may end up with a Motif menu in the midst of your Mac project.
Lexi needs a mechanism to figure out what look-and-feel standard is being used so that she can make the proper widgets. We must not only avoid using explicit function Object() { [native code] } calls, but also be able to simply change a whole widget set. We can do both by abstracting the object-creation process. We'll provide an example to demonstrate what we're talking about.
Factories and Product Classes
Normally, we would use the following C++ code to produce a Motif scroll bar glyph:
ScrollBar* sb = new MotifScrollBar;
If you want Lexi's look-and-feel requirements to be as small as possible, avoid code like this. However, assume we set up sb as follows:
ScrollBar* sb = guiFactory->CreateScrollBar();
Where guiFactory is a MotifFactory class object. CreateScrollBar creates a new instance of the appropriate ScrollBar subclass for the desired look and feel, in this case Motif. In terms of clients, this has the same effect as calling the MotifScrollBar function Object() { [native code] } directly. However, there is one significant difference: the code no longer refers to Motif by name. The guiFactory object simplifies the process of making scroll bars for any look-and-feel standard, not only Motif. Also, guiFactory isn't just for making scroll bars. It can produce a wide variety of widget glyphs, such as scroll bars, buttons, entry fields, menus, and so on.
Because MotifFactory is a subclass of GUIFactory, an abstract class that specifies a general interface for producing widget glyphs, all of this is possible. CreateScrollBar and CreateButton are two actions that can be used to create various widget glyphs. These operations are implemented by GUIFactory subclasses to return glyphs like MotifScrollBar and PMButton that implement a certain look and feel. The resultant class hierarchy for guiFactory objects is shown in Figure.
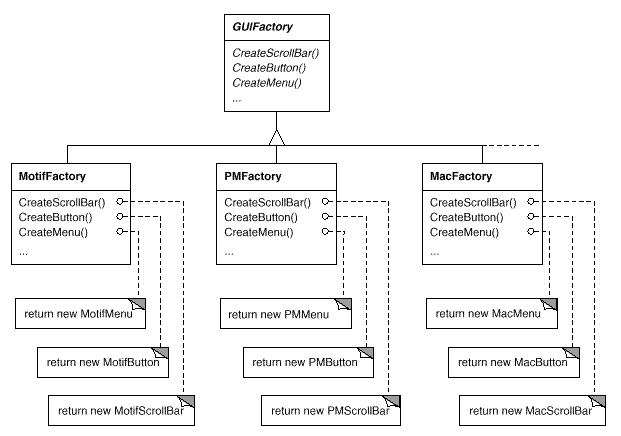
Fig 7: GUI Factory class hierarchy
We refer to factories as "factories that make product objects." Furthermore, a factory's products are linked to one another; in this case, the products are all widgets with the same appearance and feel. Figure depicts some of the product classes required to make widget glyph factories work.
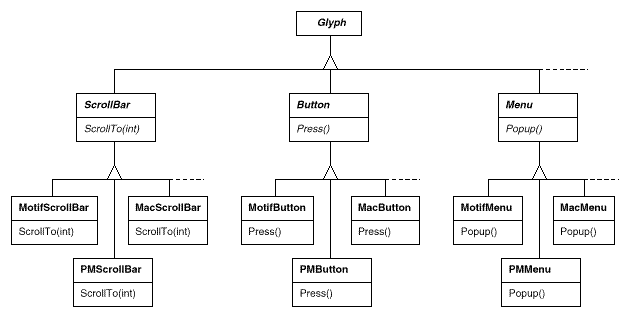
Fig 8: Abstract product classes and concrete subclasses
The last thing we need to figure out is where the GUIFactory instance came from. Anywhere that is convenient is the answer. If the entire user interface is produced within one class or function, the variable guiFactory could be a global variable, a static member of a well-known class, or even a local variable. For managing well-known, one-of-a-kind items like this, there's even a design pattern called Singleton. The crucial thing is to initialize guiFactory before it's used to produce widgets, but after it's clear which look and feel is needed.
GuiFactory can be initialized with a simple assignment of a new factory instance at the start of the programme if the look and feel is known at build time:
GUIFactory* guiFactory = new MotifFactory;
If the user can define the look and feel using a string name at startup, the factory code could be simpler.
GUIFactory* guiFactory;
const char* styleName = getenv("LOOK_AND_FEEL");
// user or environment supplies this at startup
if (strcmp(styleName, "Motif") == 0) {
guiFactory = new MotifFactory;
} else if (strcmp(styleName, "Presentation_Manager") == 0) {
guiFactory = new PMFactory;
} else {
guiFactory = new DefaultGUIFactory;
}
Abstract Factory Pattern
The essential players in the Abstract Factory pattern are factories and products. This pattern describes how to generate families of related product objects without having to directly instantiate classes. It's most appropriate when the number and general types of product objects remain consistent but specific product families differ. We pick between families by creating a concrete factory and using it to make things continuously after that. We may even replace the concrete factory with an instance of a different one to switch entire families of products. The Abstract Factory design differs from other creational patterns in that it focuses on product families rather than a single type of product item.
Q6) How to support multiple window system?
A6) One of the numerous challenges with portability is the appearance. Another factor is Lexi's running environment, which is a windowing environment. On a bitmapped display, the window system of a platform produces the illusion of several overlapping windows. It allocates screen space to windows and channels keyboard and mouse input to them. Today, there are a number of important and largely incompatible window systems (e.g., Macintosh, Presentation Manager, Windows, X). For the same reasons that we support many look-and-feel standards, we'd like Lexi to run on as many of them as possible.
Encapsulating Implementation Dependencies
A Window class was developed to display a glyph or glyph structure on the screen. We didn't indicate which window system this item worked with because, in reality, it doesn't come from any one window system. The Window class captures the common behaviours of windows in different window systems:
● They give you the tools you need to draw simple geometric forms.
● They have the ability to iconize and de-iconize themselves.
● They have the ability to resize themselves.
● When they are de-iconified or a section of their screen area that is overlapped and concealed is exposed, they can (re)draw their contents on demand.
The functionality of windows from various window systems must be covered by the Window class. Consider the following two extreme philosophies:
● Intersection of functionality: Only functionality that is common to all window systems is provided by the Window class interface. The difficulty with this technique is that we end up with a window interface that is only as powerful as the weakest window system. Even though most (but not all) window systems support sophisticated features, we are unable to use them.
● Union of functionality: Create a user interface that includes all of the existing systems' features. The problem is that the resulting interface could be massive and incomprehensible. Besides, whenever a vendor changes its window system interface, we'll have to change it (and Lexi, which is dependent on it).
Because neither extreme is a feasible option, we'll develop something in the middle. The Window class will provide a user-friendly interface with the most often used windowing functionality. Because Lexi will interact directly with this class, the Window class must likewise offer the features Lexi is familiar with, particularly glyphs. That means the interface for Windows must have a minimal set of graphics operations that allow glyphs to draw themselves in the window. The table below shows a sample of the operations available in the Window class interface.
Responsibility | Operations |
Window management | Virtual void Redraw() Virtual void Raise() Virtual void Lower() Virtual void Iconify() Virtual void Deiconify() ... |
Graphics | Virtual void DrawLine(...) Virtual void DrawRect(...) Virtual void DrawPolygon(...) Virtual void DrawText(...) ... |
Windows is a generic type. Windows concrete subclasses support the various types of windows that users encounter. Application windows, icons, and warning dialogues, for example, are all windows, but they behave differently. To capture these distinctions, we can define subclasses such as ApplicationWindow, IconWindow, and DialogWindow. The resulting class hierarchy provides a uniform and intuitive windowing abstraction to programmes like Lexi that is independent of any one vendor's window system:
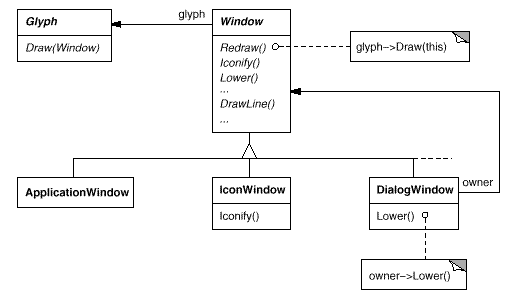
Window and WindowImp
To disguise distinct window system implementations, we'll create a separate WindowImp class hierarchy. WindowImp is an abstract class that encapsulates window system-specific code in objects. We configure each window object with an instance of a WindowImp subclass for that system to make Lexi work on that system. The relationship between the Window and WindowImp hierarchies is depicted in the diagram below:
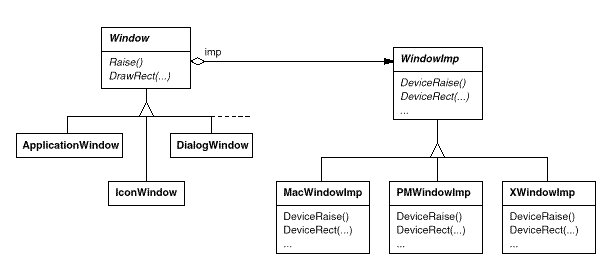
We avoid cluttering the Window classes with window system dependencies by hiding the implementations in WindowImp classes, which makes the Window class hierarchy fairly short and stable. Meanwhile, we can easily add new window systems to the implementation hierarchy.
WindowImp Subclasses
WindowImp subclasses translate requests into window system-specific operations. The Rectangle was defined as follows: Draw in terms of the Window instance's DrawRect operation:
Void Rectangle::Draw (Window* w) {
w->DrawRect(_x0, _y0, _x1, _y1);
}
The default implementation of DrawRect uses the abstract procedure specified by WindowImp for drawing rectangles:
Void Window::DrawRect (
Coord x0, Coord y0, Coord x1, Coord y1
) {
_imp->DeviceRect(x0, y0, x1, y1);
}
Where _imp is a Window member variable that holds the WindowImp that the Window is configured with. The instance of the WindowImp subclass that _imp points to defines the window implementation. The DeviceRect implementation for an XWindowImp (that is, a WindowImp subclass for the X Window System) would look like this.
Void XWindowImp::DeviceRect (
Coord x0, Coord y0, Coord x1, Coord y1
) {
int x = round(min(x0, x1));
int y = round(min(y0, y1));
int w = round(abs(x0 - x1));
int h = round(abs(y0 - y1));
XDrawRectangle(_dpy, _winid, _gc, x, y, w, h);
}
Because XDrawRectangle (the X interface for drawing a rectangle) defines a rectangle in terms of its lower left corner, width, and height, DeviceRect is defined in this way. These values must be computed by DeviceRect using the values supplied. It calculates the width and height after determining the lower left corner (because (x0, y0) might be any of the rectangle's four corners).
PMWindowImp (a Presentation Manager subclass of WindowImp) would specify DeviceRect differently:
Void PMWindowImp::DeviceRect (
Coord x0, Coord y0, Coord x1, Coord y1
) {
Coord left = min(x0, x1);
Coord right = max(x0, x1);
Coord bottom = min(y0, y1);
Coord top = max(y0, y1);
PPOINTL point[4];
point[0].x = left; point[0].y = top;
point[1].x = right; point[1].y = top;
point[2].x = right; point[2].y = bottom;
point[3].x = left; point[3].y = bottom;
if (
(GpiBeginPath(_hps, 1L) == false) ||
(GpiSetCurrentPosition(_hps, &point[3]) == false) ||
(GpiPolyLine(_hps, 4L, point) == GPI_ERROR) ||
(GpiEndPath(_hps) == false)
) {
// report error
} else {
GpiStrokePath(_hps, 1L, 0L);
}
}
Configuring Windows with WindowImps
How a window is equipped with the right WindowImp subclass in the first place is a critical issue we haven't addressed. To put it another way, when is _imp initialised, and who knows what window system (and hence which WindowImp subclass) is currently in use? Before it can do anything interesting, the window will require some type of WindowImp.
There are a several options, but we'll concentrate on one that employs the Abstract Factory pattern. WindowSystemFactory is an abstract factory class that provides an interface for producing many types of window system-dependent implementation objects:
Class WindowSystemFactory {
public:
virtual WindowImp* CreateWindowImp() = 0;
virtual ColorImp* CreateColorImp() = 0;
virtual FontImp* CreateFontImp() = 0;
// a "Create..." operation for all window system resources
};
For each window system, we can now define a concrete factory:
Class PMWindowSystemFactory : public WindowSystemFactory {
virtual WindowImp* CreateWindowImp()
{ return new PMWindowImp; }
// ...
};
class XWindowSystemFactory : public WindowSystemFactory {
virtual WindowImp* CreateWindowImp()
{ return new XWindowImp; }
// ...
};
The function Object() { [native code] } of the Window base class can utilize the WindowSystemFactory interface to initialize the _imp member with the appropriate WindowImp for the window system:
Window::Window () {
_imp = windowSystemFactory->CreateWindowImp();
}
The windowSystemFactory variable, like the guiFactory variable that defines the look and feel, is a well-known instance of a WindowSystemFactory subclass. In the same way, the windowSystemFactory variable can be set up.
Bridge Pattern
The WindowImp class defines an interface to common window system services, although it is designed differently than the Window interface. WindowImp's interface isn't something application programmers will interact with directly; they'll only deal with Window objects. As a result, unlike the Window class hierarchy and interface, WindowImp's interface does not need to reflect the application programmer's vision of the world. WindowImp's interface can more accurately reflect what modern window systems offer, flaws and all. It can be skewed toward an intersection of functionality or a union of functionality approach, depending on the target window systems.
The crucial thing to remember is that the Window interface is designed for application developers, whereas WindowImp is designed for window systems. We can implement and customize these interfaces independently by separating windowing functionality into Window and WindowImp hierarchies. These hierarchies' objects work together to allow Lexi to work on multiple window systems without modification.
Q7) What is user operations?
A7) The document's WYSIWYG representation provides access to some of Lexi's features. By pointing, clicking, and typing directly in the document, you can enter and delete text, modify the insertion point, and select text ranges. User operations in Lexi's pull-down menus, buttons, and keyboard accelerators provide indirect access to other functions. The features include operations like as
● generating a new document,
● opening, saving, and printing an existing document,
● copying and pasting selected text,
● altering the font and style of selected text,
● modifying the formatting of text,
● such as alignment and justification,
● exiting the application,
● and so on.
For these operations, Lexi offers a variety of user interfaces. However, we don't want to link a certain user activity to a specific user interface because we may need numerous user interfaces for the same task (you can turn the page using either a page button or a menu operation, for example). In the future, we may want to modify the interface.
These operations are also implemented in a variety of types. We want to be able to access our functionality without having to create a lot of dependencies between implementation and user interface classes. We'll wind up with a tightly connected implementation that's difficult to comprehend, extend, and maintain otherwise.
To make matters more complicated, we want Lexi to offer undo and redo8 of most, but not all, of its functions. We want to be able to undo document-modifying operations like remove, which can mistakenly erase a large amount of data. However, we should not attempt to reverse an action like saving a drawing or exiting the application. The undo procedure should be unaffected by these operations. We also don't want an arbitrary limit on how many levels of undo and redo can be used.
Support for user activities is evident throughout the application. The task at hand is to devise a simple and extendable method that meets all of these requirements.
Encapsulating a Request
To make matters more complicated, we want Lexi to offer undo and redo8 of most, but not all, of its functions. We want to be able to undo document-modifying operations like remove, which can mistakenly erase a large amount of data. However, we should not attempt to reverse an action like as saving a drawing or exiting the application. The undo procedure should be unaffected by these operations. We also don't want an arbitrary limit on how many levels of undo and redo can be used.
Support for user activities is evident throughout the application. The task at hand is to devise a simple and extendable method that meets all of these requirements.
Every user operation might have its own subclass of MenuItem, which would then be hard-coded to carry out the request. But that isn't really correct; we don't require a subclass of MenuItem for each request, any more than we require a subclass for each text string in a pull-down menu. Furthermore, this strategy ties the request to a specific user interface, making it difficult to fulfill it using an alternative user interface.
As an example, assume you could access the document's last page using both a MenuItem in a pull-down menu and a page icon at the bottom of Lexi's interface (which might be more convenient for short documents).
Command Class and Subclasses
To issue a request, we first construct a Command abstract class to provide an interface. The basic interface is made up of only one abstract operation called "Execute." Subclasses of Command implement Execute in a variety of ways to satisfy various needs. Other objects may be delegated some or all of the work by some subclasses. Other subclasses may be able to complete the request completely on their own. However, to the requester, a Command object is a Command object, and they are all regarded the same.
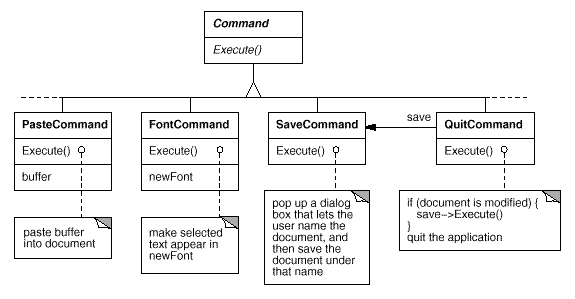
Fig 9: Partial Command class hierarchy
MenuItem now has the ability to contain a Command object that encapsulates a request. Just as we specify the text to appear in the menu item, we give each menu item object an instance of the Command subclass that's appropriate for that menu item. When a user selects a menu item, the MenuItem merely executes the request by using Execute on its Command object. It's worth noting that buttons and other widgets, such menu items, can employ instructions.
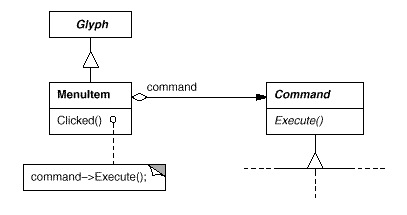
Fig 10: MenuItem-Command relationship
Undoability
In interactive applications, the ability to undo and redo is crucial. We add an Unexecute action to Command's interface to undo and redo commands. Unexecute reverses the effects of a previous Execute operation by using the undo information stored by Execute. In the instance of a FontCommand, for example, the Execute action would save both the original font and the region of text impacted by the font change (s). The Unexecute operation of FontCommand returns the range of text to its original font (s).
Undoability must sometimes be determined at runtime. If the text is already in that font, a request to change the font of a selection has no effect. Let's say a user selects some text and then asks for an illegitimate font change. What should happen if you make a second undo request? Should an insignificant modification result in an equally insignificant undo request? Most likely not. If the user makes the erroneous font change numerous times, he shouldn't have to undo the same number of times to return to the previous meaningful activity. There is no need for an undo request if the overall result of performing a command was nil.
So we add an abstract Reversible operation to the Command interface to see if a command is undoable. A Boolean value is returned by reversible. This procedure can be redefined by subclasses to return true or false depending on run-time criteria.
Q8) How to check spelling and Hyphenation?
A8) The final design issue is textual analysis, which entails looking for misspellings and inserting hyphenation points where necessary for proper formatting.
The limits are comparable to those we faced when dealing with the formatting design problem. There are multiple ways to check spelling and compute hyphenation points, just as there are multiple ways to break lines. As a result, we wish to enable multiple algorithms here as well. A broad set of algorithms can offer a variety of trade-offs in terms of space, time, and quality. We should also make it simple to add new algorithms.
In addition, we don't want to hardwire this capability into the document's structure. Because spelling checking and hyphenation are just two of the numerous types of analyses we could want Lexi to enable, this aim is far more crucial than it was in the formatting instance. Over time, we'll inevitably wish to improve Lexi's analytical skills. We may include features like searching, word counting, a calculator for adding up tabular values, grammar checking, and so on. However, we don't want to have to update the Glyph class and all of its subclasses every time we add new features.
This problem is actually made up of two parts: (1) obtaining the data to be analyzed, which is dispersed throughout the glyphs in the document structure, and (2) doing the analysis. We'll look at these two pieces separately.
Accessing Scattered Information
Many types of analysis necessitate character-by-character examination of the text. The text we'll be looking at is dispersed throughout a hierarchical network of glyph objects. We need an access mechanism that knows about the data structures in which objects are stored to evaluate text in such a structure. Some glyphs employ linked lists, some use arrays, and yet others use more complex data structures to hold their children. All of these possibilities must be accommodated by our access mechanism.
A further problem arises from the fact that various analyses access data in different ways. The majority of analysis will go over the entire book from beginning to end. Some, on the other hand, do the opposite—a reverse search, for example, must go backwards rather than forwards through the text. Evaluating algebraic expressions could require an inorder traversal. In order to evaluate algebraic expressions, an inorder traversal may be required.
As a result, our access method must handle a variety of data structures and traversals, including preorder, postorder, and inorder.
Encapsulating Access and Traversal
To refer to children, our glyph interface currently uses an integer index. While this may be appropriate for glyph classes that keep their children in an array, it may be inefficient for glyphs that use a linked list. The glyph abstraction plays a vital role in hiding the data structure in which children are stored. We can alter the data structure used by a glyph class without affecting other classes in this way.
As a result, only the glyph is aware of the data structure it employs. The graphic interface should not be biassed toward one data structure over another, as a corollary. It shouldn't, as it is today, be more suited to arrays than linked lists, for example.
We can address this problem while also supporting multiple alternative types of traversals. We can explicitly implement multiple access and traversal capabilities in the glyph classes and provide a means for users to choose between them, possibly by passing an enumerated constant as a parameter. During a traverse, the classes pass this parameter around to make sure they're all performing the same thing. They must share whatever information they have gathered during their journey.
To accommodate this method, we might add the following abstract operations to Glyph's interface:
Void First(Traversal kind)
void Next()
bool IsDone()
Glyph* GetCurrent()
void Insert(Glyph*)
The traversal is controlled by the operations First, Next, and IsDone. The traversal is first initialized. It takes an argument of type Traversal, an enumerated constant with values like CHILDREN (to traverse the glyph's immediate children only), PREORDER (to traverse the entire structure in preorder), POSTORDER, and INORDER (to traverse the entire structure in preorder). Next advances the traverse to the next glyph, and IsDone indicates if the traversal is complete or not.
GetCurrent takes the place of Child and accesses the traversal's current glyph. Insert is a new operation that replaces the old one by inserting the specified glyph at the current position. To do a preorder traversal of a tree, an analysis would use the C++ code below.
Glyph* g;
for (g->First(PREORDER); !g->IsDone(); g->Next()) {
Glyph* current = g->GetCurrent();
// do some analysis
}
The integer index has been removed from the glyph interface. There's nothing in the interface now that favors one type of collection over another. We've also saved clients the trouble of having to develop typical traversals on their own.
However, there are still issues with this strategy. For one thing, it can't allow additional traversals unless the set of enumerated values is expanded or new operations are added. Let's say we needed a preorder traversal version that skipped non-textual glyphs automatically. We'd have to add something like TEXTUAL PREORDER to the Traversal enumeration.
Iterator Class and Subclasses
To provide an universal interface for access and traversal, we'll utilise an abstract class called Iterator. Concrete subclasses such as ArrayIterator and ListIterator provide the interface for accessing arrays and lists, respectively, while PreorderIterator, PostorderIterator, and others implement various traversals on specific structures. The structure traversed is referenced by each Iterator subclass. When a subclass instance is created, it is initialized with this reference. The Iterator class, as well as various subclasses, are shown in the diagram. To support iterators, we've added a CreateIterator abstract procedure to the Glyph class interface.
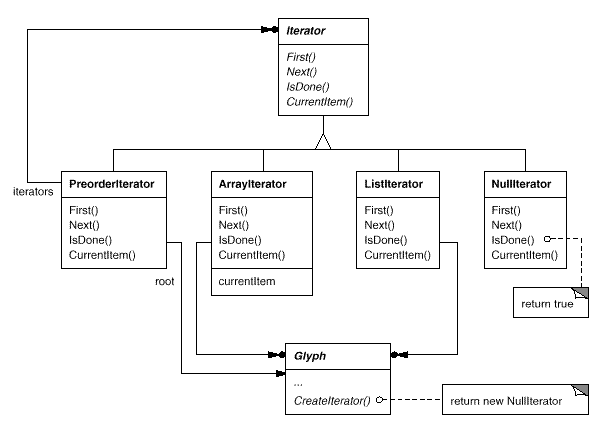
Fig 11: Iterator class and subclasses
For directing the traversal, the Iterator interface includes the functions First, Next, and IsDone. The ListIterator class implements First to point to the list's first element, and Next to advance the iterator to the list's next item. IsDone determines if the list pointer extends beyond the list's last element. CurrentItem returns the glyph that the iterator points to by dereferencing the iterator. An ArrayIterator class, on the other hand, would do the same thing with an array of glyphs.
Without knowing the representation of a glyph structure, we can now access its children:
Glyph* g;
Iterator<Glyph*>* i = g->CreateIterator();
for (i->First(); !i->IsDone(); i->Next()) {
Glyph* child = i->CurrentItem();
// do something with current child
}
By default, CreateIterator returns a NullIterator instance. For glyphs with no offspring, such as leaf glyphs, a NullIterator is a degenerate iterator. The IsDone action of a NullIterator always returns true.
CreateIterator will be overridden by a glyph subclass with children to return an instance of a different Iterator subclass. The structure that stores the children determines which subclass to use. If Glyphs Row subclass holds its offspring in a list called _children, the CreateIterator action would be as follows:
Iterator<Glyph*>* Row::CreateIterator () {
return new ListIterator<Glyph*>(_children);
}
Iterators for preorder and inorder traversals use glyph-specific iterators to implement their traversals. The root glyph in the structure they traverse is passed to the iterators for these traversals. They use a stack to keep track of the iterators created by calling CreateIterator on the structure's glyphs.
Iterator Pattern
These strategies for facilitating access and traversal over object structures are captured by the Iterator pattern. It can be applied to collections as well as composite architectures. It hides the internal structure of the objects it traverses by abstracting the traversal process. The Iterator pattern demonstrates how encapsulating the concept of variation aids us in gaining flexibility and reusability once again. Even still, the iteration problem is quite complex, and the Iterator pattern has far more complexities and trade-offs than we've covered here.
Traversal versus Traversal Actions
Now that we've figured out how to navigate the glyph hierarchy, we need to double-check the spelling and hyphenate the words. During the traversal, both analyses need gathering data.
First, we must identify where the responsibility for analysis will be assigned. We might include it in the Iterator classes, making analysis a necessary component of traversal. However, if we separate between traversal and the actions performed during traversal, we gain additional flexibility and opportunity for reuse. This is because various analyses frequently necessitate the same type of traversal. As a result, we can use the same set of iterators for many analyses. Preorder traversal, for example, is used in a variety of studies, including spelling check, hyphenation, forward search, and word count.
As a result, analysis and traversal should be handled separately. Where else could the responsibility for analysis be assigned? We are aware that there are numerous types of analyses that we may like to do. At different places during the traversal, each analysis will perform differently. Depending on the type of study, some glyphs are more relevant than others. Character glyphs, not graphical ones like lines and bitmapped pictures, should be considered when checking spelling or hyphenation. When designing color separations, we should think on visible glyphs rather than invisible ones. Various analyses will invariably look at different glyphs.
As a result, a given analysis must be able to discern between various glyph types. One apparent solution is to embed the analytical capacity directly into the glyph classes. We can add one or more abstract operations to the Glyph class for each analysis and have subclasses implement them according to their involvement in the analysis.
But the problem with that technique is that whenever we introduce a new type of analysis, we'll have to change every glyph class. In some circumstances, we can make this problem go away: We can provide a default implementation for the abstract operation in the Glyph class if only a few classes participate in the analysis or if most classes do the analysis in the same way. The common case would be covered by the default operation. As a result, alterations would be limited to the Glyph class and its subclasses that differ from the usual.
Encapsulating the Analysis
According to all indicators, we'll need to separate the analysis into its own object, as we've done many times previously. We could separate the analytical mechanism into its own class. An instance of this class could be used in conjunction with an appropriate iterator. Each glyph in the structure would be "carried" by the iterator. At each point in the traversal, the analysis object might conduct a portion of the analysis. As the traversal progresses, the analyzer collects information of interest (in this example, characters):
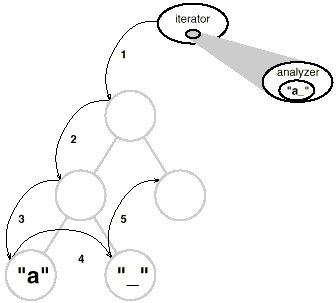
The key question with this method is how the analysis object distinguishes between different types of glyphs without using type checks or downcasts. We don't want a SpellingChecker class to have (false) code like this.
Void SpellingChecker::Check (Glyph* glyph) {
Character* c;
Row* r;
Image* i;
if (c = dynamic_cast<Character*>(glyph)) {
// analyze the character
} else if (r = dynamic_cast<Row*>(glyph)) {
// prepare to analyze r's children
} else if (i = dynamic_cast<Image*>(glyph)) {
// do nothing
}
}
This code is quite unsightly. It makes use of exotic features like type-safe casting. It's also difficult to extend. When the Glyph class hierarchy changes, we'll need to remember to alter the body of this method. In reality, object-oriented languages were designed to eliminate this type of programming.
We wish to avoid using such a forceful approach, but how can we do so? Consider what happens if we extend the Glyph class with the following abstract operation:
Void CheckMe(SpellingChecker&)
CheckMe is defined as follows in every Glyph subclass:
Void GlyphSubclass::CheckMe (SpellingChecker& checker) {
checker.CheckGlyphSubclass(this);
}
Where GlyphSubclass is replaced with the glyph subclass's name. Because we're in one of Glyph's processes, the precise Glyph subclass is known when CheckMe is invoked. For each Glyph subclass, the SpellingChecker class interface includes an operation called CheckGlyphSubclass:
Class SpellingChecker {
public:
SpellingChecker();
virtual void CheckCharacter(Character*);
virtual void CheckRow(Row*);
virtual void CheckImage(Image*);
// ... And so forth
List<char*>& GetMisspellings();
protected:
virtual bool IsMisspelled(const char*);
private:
char _currentWord[MAX_WORD_SIZE];
List<char*> _misspellings;
};
The checking operation for Character glyphs in SpellingChecker could look like this:
Void SpellingChecker::CheckCharacter (Character* c) {
const char ch = c->GetCharCode();
if (isalpha(ch)) {
// append alphabetic character to _currentWord
} else {
// we hit a nonalphabetic character
if (IsMisspelled(_currentWord)) {
// add _currentWord to _misspellings
_misspellings.Append(strdup(_currentWord));
}
_currentWord[0] = '\0';
// reset _currentWord to check next word
}
}
Visitor Class and Subclasses
The term "visitor" will be used to refer to classes of objects that "visit" other objects during a traversal and perform some action. 12 In this situation, a Visitor class can be defined to define an abstract interface for visiting glyphs in a structure.
Class Visitor {
public:
virtual void VisitCharacter(Character*) { }
virtual void VisitRow(Row*) { }
virtual void VisitImage(Image*) { }
// ... And so forth
};
Different Visitor subclasses execute different analyses. For example, a SpellingCheckingVisitor subclass may be used to check spelling, while a HyphenationVisitor subclass could be used to check hyphenation. SpellingCheckingVisitor would be implemented in the same way that SpellingChecker was, with the exception that the operation names would be changed to match the more general Visitor interface. CheckCharacter, for example, would be renamed VisitCharacter.
We'll call it CheckMe instead, because CheckMe isn't acceptable for visitors who don't check anything.
Accept. Its argument must also be changed to take a Visitor, indicating that it can accept any visitor. Now, all we have to do to add a new analysis is define a new subclass of Visitor—we don't have to change any of the glyph classes. By adding this single action to Glyph and its subclasses, we can support all future analysis.
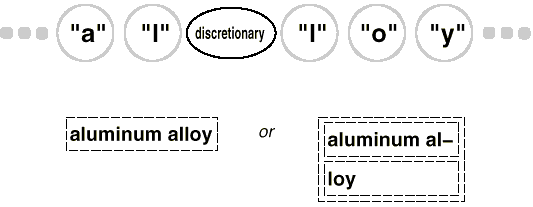
We've already shown how to use spell check. In HyphenationVisitor, we employ a similar strategy to collect text. However, after the Hyphenation Visitors VisitCharacter operation has completed a whole word, it behaves differently. Instead of checking for misspellings, it uses a hyphenation algorithm to assess whether the word has any potential hyphenation points. It then inserts a discretionary glyph into the composition at each hyphenation point. Discretionary glyphs are instances of the Glyph subclass Discretionary.
Depending on whether or not it is the last character on a line, a discretionary glyph can take one of two forms. If it's the last character of a line, the discretionary appears as a hyphen; if it's not the last character of a line, the discretionary has no appearance. The optional checks to determine if it is the last child of its parent (a Row object). When the discretionary is asked to draw or determine its borders, it performs this check. Discretionaries are treated the same as whitespace in the formatting technique, so they can be used to end a line. The diagram below depicts how an embedded discretionary might appear.
Visitor Pattern
This is an example of how the Visitor pattern can be used. The important actors in the pattern are the Visitor class and its subclasses defined earlier. The Visitor pattern encapsulates the method we used to allow an infinite number of glyph structural analyses without changing the glyph classes themselves. Visitors also have the advantage of being able to be applied to any object structure, not only composites like our glyph structures. Sets, lists, and even directed-acyclic graphs fall into this category. Furthermore, a visitor's classes do not have to be tied to one another through a shared parent class. As a result, visitors can collaborate with people from many walks of life.
Which class hierarchies change the most frequently? This is a crucial question to ask yourself before using the Visitor pattern. When you want to be able to do a variety of various things to objects with a consistent class structure, this pattern is ideal. There is no need to update the class structure when adding a new type of visitor, which is especially significant when the class structure is big. However, if you add a subclass to the structure, you'll need to change all of your visitor interfaces to include a Visit... Operation for that subclass as well. In our example, creating a new Glyph subclass called Foo will necessitate adding a VisitFoo action to Visitor and all of its subclasses.
Q9) Write the features of lexi design pattern?
A9) Lexi's design features eight different patterns:
● The physical structure of the document is represented by a composite.
● Allowing alternative formatting algorithms is a strategy.
● Decorator for adding flair to the user interface.
● Multiple look-and-feel standards are supported by Abstract Factory.
● Multiple windowing platforms can be accessed using a bridge.
● Undoable user operations command.
● Access and traverse object structures with this iterator.
● and Visitor for permitting an unlimited number of analytical capabilities while keeping the document structure simple to deploy.
None of these design flaws are unique to document editing software like Lexi. Indeed, many of these patterns will be used in most nontrivial applications, albeit for different purposes. Composite could be used in a financial analysis programme to define investment portfolios made up of sub portfolios and accounts of various types. The Strategy pattern can be used by a compiler to support alternative register allocation techniques for different target machines. Applications having a graphical user interface, like this one, will very certainly employ Decorator and Command.
Q10) What are the Entities of Service Locator Pattern?
A10) The entities of this design pattern are listed below.
● Service - This is the actual service that will handle the request. A reference to such a service can be found in the JNDI server.
● JNDI Context / Initial Context - The context contains a reference to the service that was utilized for the lookup.
● Service Locator - Using JNDI lookup caching, Service Locator provides a single point of contact for obtaining services.
● Cache - A cache is used to save service references so that they can be reused later.
● Client - The object that uses Service Locator to call the services.
Unit – 5
A Case Study
Q1) What are the design problems to design a document editor?
A1) We'll look at seven issues with Lexi's design:
● Document structure
Almost every aspect of Lexi's design is influenced by the document's internal representation. The representation will be traversed for all editing, formatting, displaying, and textual analysis. The way we organize this data will have an impact on the remainder of the app's design.
● Formatting
What is Lexi's method for dividing text and pictures into lines and columns? What objects are in charge of enforcing certain formatting policies? What is the relationship between these policies and the internal representation of the document?
● Embellishing the user interface
Scroll bars, borders, and drop shadows are included in Lexi's user interface, which complement the WYSIWYG document interface. As Lexi's user interface evolves, such embellishments are likely to change. As a result, it's critical to be able to easily add and delete embellishments without disrupting the rest of the programme.
● Supporting multiple look-and-feel standards
Lexi should be able to readily adapt to different look-and-feel standards like Motif and Presentation Manager (PM) without requiring large changes.
● Supporting multiple window systems
On different window systems, different look-and-feel standards are frequently implemented. Lexi's design should be as autonomous as possible from the window system.
● User operations
Lexi is controlled through a variety of user interfaces, such as buttons and pull-down menus. The functionality behind these interfaces is dispersed across the application's objects. The problem here is to provide a unified way for both accessing and removing this dispersed functionality.
● Spelling checking and hyphenation
Lexi's support for analytical procedures like checking for misspelled words and determining hyphenation spots is quite impressive. How can we reduce the number of classes that need to be changed in order to implement a new analytical operation?
Each challenge contains a set of objectives as well as limits on how we will reach those objectives.
Q2) What do you mean by document structure?
A2) In the end, a document is nothing more than a collection of basic graphical elements including characters, lines, polygons, and other shapes. These elements encompass the document's whole information content. Yet an author often views these elements not in graphical terms but in terms of the document's physical structure—lines, columns, figures, tables, and other substructures. In turn, these substructures have substructures of their own, and so on.
The user interface for Lexi should allow users to directly alter these substructures. For example, rather than treating a diagram as a collection of distinct graphical primitives, a user should be able to consider it as a single unit. A table should be able to be referred to as a whole, not as a jumble of text and visuals. This contributes to the interface's simplicity and intuitiveness. We'll choose an internal representation that matches the document's physical structure to provide Lexi's implementation similar properties.
Internal representation should, in particular, support the following:
● Maintaining the physical structure of the document, which includes the arranging of text and visuals into lines, columns, tables, and other structures.
● Visually creating and displaying the document.
● The mapping of display positions to items in the internal representation. When the user points to something in the visual depiction, Lexi can figure out what he's talking about.
There are additional limitations in addition to these objectives. To begin, we should treat text and visuals in the same way. The user interface of the application allows the user to freely incorporate text within visuals and vice versa. Otherwise, we'll wind up with redundant formatting and manipulation procedures if we regard graphics as a special instance of text or text as a special case of graphics. For both text and visuals, a single set of methods should be sufficient.
Second, in the internal representation, our implementation should not have to discriminate between single items and groups of components. Lexi should be able to treat basic and complex elements in the same way, enabling for the creation of arbitrarily complex documents. For example, the tenth element in line five of column two could be a single character or a complex graphic with numerous subelements. The complexity of this element has no influence on how and where it should appear on the page as long as we know it can draw itself and specify its dimensions.
The necessity to assess the text for things like spelling problems and probable hyphenation points, on the other hand, is in direct opposition to the second limitation. We don't always care if a line's element is a simple or complex item. However, an analysis might also be dependent on the things being analysed. Checking the spelling of a polygon or hyphenating it, for example, makes no sense. The internal representation's design should take this and other potentially conflicting constraints into account.
Recursive Composition
Recursive composition, which requires creating progressively complex pieces out of simpler ones, is a typical way to express hierarchically ordered information. We may use recursive composition to create a document out of simple graphical pieces. To begin, we can tile a series of characters and visuals from left to right in the document to construct a line. Then you may arrange several lines to make a column, multiple columns to make a page, and so on.
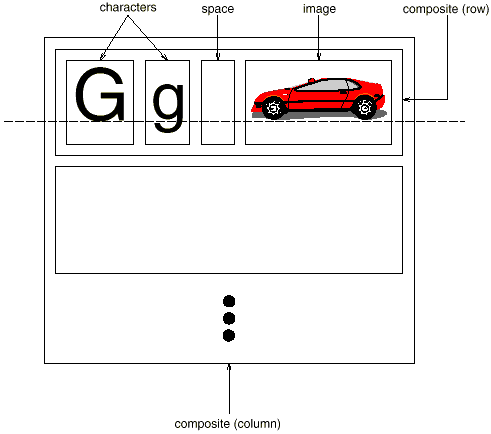
Fig 1: Recursive composition of text and graphics
We may express this physical structure by giving each important constituent its own object. This includes not just the visible elements like as text and graphics, but also the unseen structural elements such as lines and columns. The object structure illustrated in Figure is the end outcome.
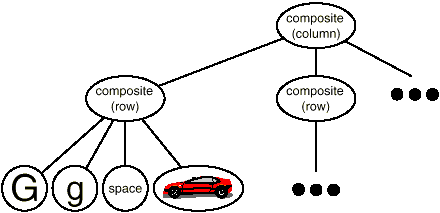
Fig 2: Object structure for recursive composition of text and graphics
We promote flexibility at the highest levels of Lexi's design by using an object for each character and graphical element in the page. Text and visuals can be treated the same way in terms of how they're produced, formatted, and embedded in one other. Lexi may be extended to handle additional character sets without affecting existing features. Lexi's object structure is based on the physical structure of the document.
Glyphs
For all items that can appear in a document structure, we'll create a Glyph abstract class. Its subclasses define both basic graphical elements (such as characters and images) as well as structural elements (like rows and columns). The fundamental glyph interface is presented in further depth using C++ notation in Table, which illustrates a typical component of the Glyph class hierarchy.
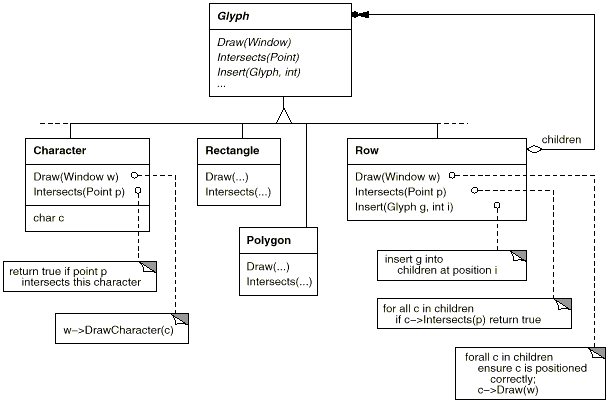
Fig 3: Partial Glyph class hierarchy
Responsibility | Operations |
Appearance | Virtual void Draw(Window*) Virtual void Bounds(Rect&) |
Hit detection | Virtual bool Intersects(const Point&) |
Structure | Virtual void Insert(Glyph*, int) Virtual void Remove(Glyph*) Virtual Glyph* Child(int) Virtual Glyph* Parent() |
Table: Basic glyph interface
Glyphs have three primary functions. They understand (1) how to sketch themselves, (2) how much space they take up, and (3) how to communicate with their children and parents.
Composite Pattern
More than simply documents benefit from recursive composition. It can be used to represent any hierarchical structure that is potentially complex. In object-oriented terms, the Composite pattern embodies the core of recursive composition. It's a good idea to go back to that pattern and examine it now, referring back to this instance as needed.
Q3) Describe formatting?
A3) We've decided on a way to represent the physical structure of the document. The next step is to figure out how to build a certain physical structure that matches to a correctly structured document. The terms "representation" and "formatting" are not interchangeable: The capacity to represent the physical structure of a document does not tell us how to get to that structure.
Lexi bears the brunt of this obligation. It must divide text into lines, lines into columns, and so on, taking the user's higher-level preferences into account. For example, the user would want to change the margin widths, indentation, and tabulation; single or double space; and presumably a variety of other formatting options. All of these must be taken into account by Lexi's formatting algorithm.
By the way, we'll define "formatting" as the process of dividing a group of glyphs into lines. In reality, we'll exchange the phrases "formatting" and "line breaking." The strategies we'll go over can be used to divide lines into columns as well as columns into pages.
Encapsulating the Formatting Algorithm
With all of its limits and complexities, the formatting process is difficult to automate. There are numerous approaches to the problem, and various formatting algorithms have been developed, each with its own set of strengths and limitations. Because Lexi is a WYSIWYG editor, the balance between formatting quality and formatting speed is a critical trade-off to consider. We want a positive response from the editor without jeopardizing the document's appearance. This trade-off is influenced by a number of variables, not all of which can be determined at compile time.
For instance, the user could be willing to put up with a somewhat slower response in return for better formatting. Because of this trade-off, a completely alternative formatting algorithm may be more suited than the existing one. Formatting speed and storage requirements are balanced in another, more implementation-driven trade-off: By caching additional data, it may be able to reduce formatting time.
Due to the complexity of formatting algorithms, it's best to make them self-contained or, better yet, fully independent of the document structure. In an ideal world, we'd be able to add a new type of Glyph subclass that didn't care about the formatting methodology. Adding a new formatting mechanism, on the other hand, should not necessitate changing existing glyphs.
These qualities suggest that we should design Lexi so that changing the formatting method is simple, at least at build time, if not at run time. Encapsulating the algorithm in an object allows us to isolate it while also making it easily changeable. We'll create a new class hierarchy for objects that encapsulate formatting algorithms in more detail. Each subclass will implement the interface to carry out a certain algorithm, with the root of the hierarchy defining an interface that supports a wide range of formatting algorithms. Then we can add a Glyph subclass that will automatically arrange its children using a provided algorithm object.
Compositor and Composition
For objects that can encapsulate a formatting algorithm, we'll define the Compositor class. The interface informs the compositor of which glyphs should be formatted and when they should be formatted. It formats glyphs that belong to a special Glyph subclass called Composition. When a composition is built, it receives an instance of the Compositor subclass (specialized for a specific line breaking algorithm) and instructs the compositor to Compose its glyphs as needed, such as when the user edits a document. The links between the Composition and Compositor classes are shown in the diagram.
Responsibility | Operations |
What to format | Void SetComposition(Composition*) |
When to format | Virtual void Compose() |
Table: Basic compositor interface
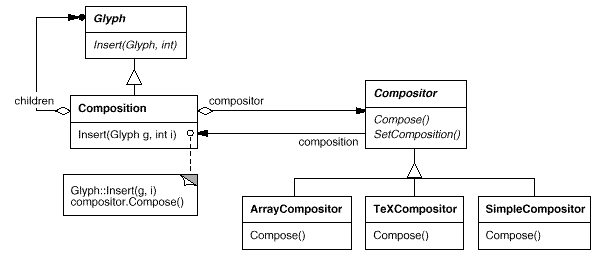
Fig 4: Composition and Compositor class relationships
Strategy Pattern
The Strategy pattern's goal is to encapsulate an algorithm in an object. Strategy objects (which encapsulate various algorithms) and the context in which they function are crucial actors in the pattern. Compositors are a type of strategy that encapsulates several formatting procedures. The context for a compositor strategy is composition.
Designing interfaces for the strategy and its surroundings that are generic enough to allow a variety of algorithms is the key to using the Strategy pattern. To support a new algorithm, you shouldn't have to update the strategy or the context interface. In our example, the Glyph interface's support for child access, insertion, and removal is broad enough to allow Compositor subclasses to modify the document's physical structure independent of the method they use. Similarly, the Compositor interface provides everything that compositions require to begin formatting.
Q4) What is Embellishing the User Interface?
A4) We look at two enhancements to Lexi's user interface. To demarcate the text page, the first inserts a border around the text editing area. The second adds scroll bars, which allow the user to examine various areas of the page. We shouldn't use inheritance to add these embellishments to the user interface because it makes it difficult to add and delete them (particularly at run-time). When other user interface items are unaware of the embellishments, we gain the most flexibility. This allows us to add and remove embellishments without having to change any other classes.
Transparent Enclosure
Enhancing the user interface from a programming standpoint entails expanding existing code. Using inheritance to achieve such extension prevents reordering embellishments at runtime, but an equally important issue is the expansion of classes that might occur from using inheritance.
We could give Composition a border by subclassing it to get the BorderedComposition class. Alternatively, we could create a ScrollableComposition by adding a scrolling interface in the same way. We could make a BorderedScrollableComposition if we want both scroll bars and a border, and so forth. We end up with a class for every potential combination of embellishments in the extreme, a strategy that quickly becomes untenable as the number of embellishments increases.
Object composition may provide a more practical and adaptable extension technique. But what are the objects that we put together? We could make the decoration an object because we're embellishing an existing glyph (say, an instance of class Border). The glyph and the border are the two choices for composition. The next stage is to figure out who will compose who. The glyph may be contained within the border, which makes sense considering that the border will surround the glyph on the screen. Alternatively, we could put the border inside the glyph, but this would necessitate changes to the relevant Glyph subclass to make it aware of the border. Our first choice, composing the glyph in the border, keeps the border-drawing code entirely in the Border class, leaving other classes alone.
Monoglyph
All glyphs that decorate other glyphs can benefit from the concept of translucent enclosure. To put this idea into practise, we'll create a MonoGlyph subclass of Glyph that will serve as an abstract class for "embellishment glyphs" like Border. MonoGlyph keeps track of a component's reference and routes all requests to it. By default, MonoGlyph is completely transparent to clients. MonoGlyph, for example, implements the Draw action as follows:
Void MonoGlyph::Draw (Window* w) {
_component->Draw(w);
}
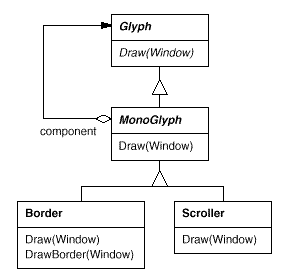
Fig 5: MonoGlyph class relationships
At least one of these forwarding procedures is reimplemented by MonoGlyph subclasses. For example, the parent class action is called first by Border::Draw. MonoGlyph:: Draw everything except the border on the component to allow the component to do its job. Then Border::Draw draws the border by invoking a private operation called DrawBorder, which we won't get into here:
Void Border::Draw (Window* w) {
MonoGlyph::Draw(w);
DrawBorder(w);
}
Take note of how Boundary::Draw extends the parent class's action to draw the border. In contrast, just replacing the parent class operation would result in the call to MonoGlyph::Draw being omitted.
Figure shows another MonoGlyph subclass. Scroller is a MonoGlyph that draws its component in various locations depending on the positions of two scroll bars it adds as embellishments. Scroller tells the graphics system to clip to its bounds when it draws its component. Clipping scrolled-out elements of the component prevents them from appearing on the screen.
We now have everything we need to give Lexi's text editing area a boundary and a scrolling interface. To add the scrolling interface, we compose the existing Composition instance in a Scroller instance, which we then compose in a Border instance. Figure shows the resulting object structure.
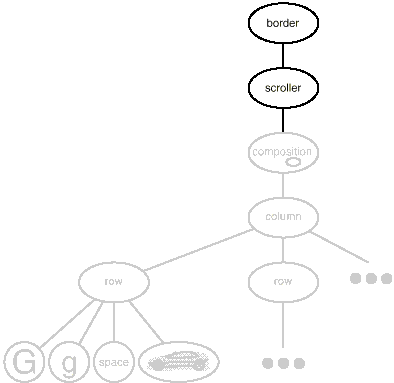
Fig 6: Embellished object structure
It's worth noting that we can change the composition order by adding the bordered composition into the Scroller instance. The border would scroll with the text in that situation, which may or may not be acceptable. The goal is that a transparent enclosure allows customers to experiment with various options while also keeping them free of decorative code.
Decorator Pattern
The Decorator pattern records class and object relationships that enable transparent enclosure decorating. The phrase "embellishment" has a broader definition than what we've looked at thus far. In the Decorator pattern, decoration refers to anything that gives an item more responsibility. Consider adding semantic actions to an abstract syntax tree, adding new transitions to a finite state automaton, or adding attribute tags to a network of persistent objects. Decorator generalizes the approach we used in Lexi so that it may be used more extensively.
Q5) Write about Supporting Multiple Look-and-Feel Standards?
A5) A fundamental challenge in system design is achieving portability between hardware and software platforms. It shouldn't need a huge change to retarget Lexi to a new platform, or it wouldn't be worth it. Porting should be as simple as feasible.
The variety of look-and-feel standards, which are designed to enforce conformity between apps, is one barrier to portability. These principles dictate how apps appear and interact with users. While current standards aren't all that dissimilar, consumers won't mistake one for the other—motif applications don't appear or feel the same as their counterparts on other platforms, and vice versa. An application that runs on many platforms must follow each platform's user interface style guide.
Abstracting Object Creation
Our design aims were to make Lexi comply to a variety of existing look-and-feel standards while also making it simple to add support for new standards when they (inevitably) emerge. We also want our design to allow us to change Lexi's appearance and feel at any time during the game.
In Lexi's user interface, everything we see and interact with is a glyph made up of other, unseen glyphs like Row and Column. The visible glyphs, such as Button and Character, are made up of invisible glyphs that lay them out appropriately. Style guides have a lot to say about how "widgets," or visible symbols like buttons, scroll bars, and menus that operate as controlling elements in a user interface, appear and feel.
We'll suppose we have two sets of widget glyph classes to work with in order to create multiple look-and-feel guidelines:
● Each kind of widget glyph has a set of abstract Glyph subclasses. ScrollBar, for example, is an abstract class that adds general scrolling operations to the basic glyph interface; Button is an abstract class that adds button-oriented activities; and so on.
● Each abstract subclass has a set of concrete subclasses that implement different look-and-feel standards. MotifScrollBar and PMScrollBar are two subclasses of ScrollBar that implement Motif and Presentation Manager-style scroll bars, respectively.
Lexi needs to be able to tell the difference between widget glyphs for different look-and-feel styles. When Lexi needs to add a button to its interface, for example, it must create a Glyph subclass for the appropriate button style (MotifButton, PMButton, MacButton, etc.).
It's clear that Lexi's implementation can't do this directly, say, using a constructor call in C++. This would hard-code a style's button, making it impossible to change the style at run-time. We'd also have to track down and change every such constructor call to port Lexi to another platform. Buttons are only one of the many widgets available in Lexi's user interface. Constructor calls to specialized look-and-feel classes litter our code, resulting in a maintenance nightmare—miss one, and you may end up with a Motif menu in the midst of your Mac project.
Lexi needs a mechanism to figure out what look-and-feel standard is being used so that she can make the proper widgets. We must not only avoid using explicit function Object() { [native code] } calls, but also be able to simply change a whole widget set. We can do both by abstracting the object-creation process. We'll provide an example to demonstrate what we're talking about.
Factories and Product Classes
Normally, we would use the following C++ code to produce a Motif scroll bar glyph:
ScrollBar* sb = new MotifScrollBar;
If you want Lexi's look-and-feel requirements to be as small as possible, avoid code like this. However, assume we set up sb as follows:
ScrollBar* sb = guiFactory->CreateScrollBar();
Where guiFactory is a MotifFactory class object. CreateScrollBar creates a new instance of the appropriate ScrollBar subclass for the desired look and feel, in this case Motif. In terms of clients, this has the same effect as calling the MotifScrollBar function Object() { [native code] } directly. However, there is one significant difference: the code no longer refers to Motif by name. The guiFactory object simplifies the process of making scroll bars for any look-and-feel standard, not only Motif. Also, guiFactory isn't just for making scroll bars. It can produce a wide variety of widget glyphs, such as scroll bars, buttons, entry fields, menus, and so on.
Because MotifFactory is a subclass of GUIFactory, an abstract class that specifies a general interface for producing widget glyphs, all of this is possible. CreateScrollBar and CreateButton are two actions that can be used to create various widget glyphs. These operations are implemented by GUIFactory subclasses to return glyphs like MotifScrollBar and PMButton that implement a certain look and feel. The resultant class hierarchy for guiFactory objects is shown in Figure.
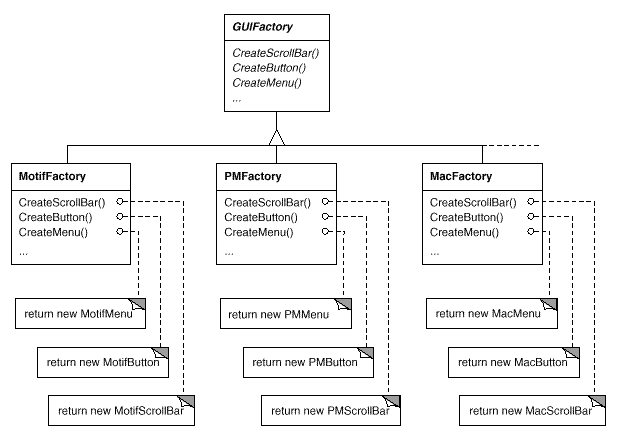
Fig 7: GUI Factory class hierarchy
We refer to factories as "factories that make product objects." Furthermore, a factory's products are linked to one another; in this case, the products are all widgets with the same appearance and feel. Figure depicts some of the product classes required to make widget glyph factories work.
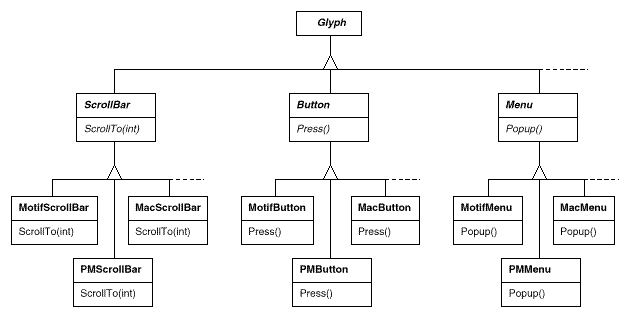
Fig 8: Abstract product classes and concrete subclasses
The last thing we need to figure out is where the GUIFactory instance came from. Anywhere that is convenient is the answer. If the entire user interface is produced within one class or function, the variable guiFactory could be a global variable, a static member of a well-known class, or even a local variable. For managing well-known, one-of-a-kind items like this, there's even a design pattern called Singleton. The crucial thing is to initialize guiFactory before it's used to produce widgets, but after it's clear which look and feel is needed.
GuiFactory can be initialized with a simple assignment of a new factory instance at the start of the programme if the look and feel is known at build time:
GUIFactory* guiFactory = new MotifFactory;
If the user can define the look and feel using a string name at startup, the factory code could be simpler.
GUIFactory* guiFactory;
const char* styleName = getenv("LOOK_AND_FEEL");
// user or environment supplies this at startup
if (strcmp(styleName, "Motif") == 0) {
guiFactory = new MotifFactory;
} else if (strcmp(styleName, "Presentation_Manager") == 0) {
guiFactory = new PMFactory;
} else {
guiFactory = new DefaultGUIFactory;
}
Abstract Factory Pattern
The essential players in the Abstract Factory pattern are factories and products. This pattern describes how to generate families of related product objects without having to directly instantiate classes. It's most appropriate when the number and general types of product objects remain consistent but specific product families differ. We pick between families by creating a concrete factory and using it to make things continuously after that. We may even replace the concrete factory with an instance of a different one to switch entire families of products. The Abstract Factory design differs from other creational patterns in that it focuses on product families rather than a single type of product item.
Q6) How to support multiple window system?
A6) One of the numerous challenges with portability is the appearance. Another factor is Lexi's running environment, which is a windowing environment. On a bitmapped display, the window system of a platform produces the illusion of several overlapping windows. It allocates screen space to windows and channels keyboard and mouse input to them. Today, there are a number of important and largely incompatible window systems (e.g., Macintosh, Presentation Manager, Windows, X). For the same reasons that we support many look-and-feel standards, we'd like Lexi to run on as many of them as possible.
Encapsulating Implementation Dependencies
A Window class was developed to display a glyph or glyph structure on the screen. We didn't indicate which window system this item worked with because, in reality, it doesn't come from any one window system. The Window class captures the common behaviours of windows in different window systems:
● They give you the tools you need to draw simple geometric forms.
● They have the ability to iconize and de-iconize themselves.
● They have the ability to resize themselves.
● When they are de-iconified or a section of their screen area that is overlapped and concealed is exposed, they can (re)draw their contents on demand.
The functionality of windows from various window systems must be covered by the Window class. Consider the following two extreme philosophies:
● Intersection of functionality: Only functionality that is common to all window systems is provided by the Window class interface. The difficulty with this technique is that we end up with a window interface that is only as powerful as the weakest window system. Even though most (but not all) window systems support sophisticated features, we are unable to use them.
● Union of functionality: Create a user interface that includes all of the existing systems' features. The problem is that the resulting interface could be massive and incomprehensible. Besides, whenever a vendor changes its window system interface, we'll have to change it (and Lexi, which is dependent on it).
Because neither extreme is a feasible option, we'll develop something in the middle. The Window class will provide a user-friendly interface with the most often used windowing functionality. Because Lexi will interact directly with this class, the Window class must likewise offer the features Lexi is familiar with, particularly glyphs. That means the interface for Windows must have a minimal set of graphics operations that allow glyphs to draw themselves in the window. The table below shows a sample of the operations available in the Window class interface.
Responsibility | Operations |
Window management | Virtual void Redraw() Virtual void Raise() Virtual void Lower() Virtual void Iconify() Virtual void Deiconify() ... |
Graphics | Virtual void DrawLine(...) Virtual void DrawRect(...) Virtual void DrawPolygon(...) Virtual void DrawText(...) ... |
Windows is a generic type. Windows concrete subclasses support the various types of windows that users encounter. Application windows, icons, and warning dialogues, for example, are all windows, but they behave differently. To capture these distinctions, we can define subclasses such as ApplicationWindow, IconWindow, and DialogWindow. The resulting class hierarchy provides a uniform and intuitive windowing abstraction to programmes like Lexi that is independent of any one vendor's window system:
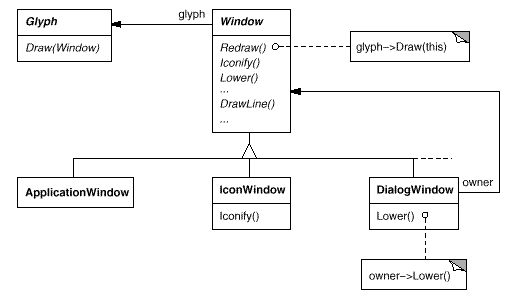
Window and WindowImp
To disguise distinct window system implementations, we'll create a separate WindowImp class hierarchy. WindowImp is an abstract class that encapsulates window system-specific code in objects. We configure each window object with an instance of a WindowImp subclass for that system to make Lexi work on that system. The relationship between the Window and WindowImp hierarchies is depicted in the diagram below:
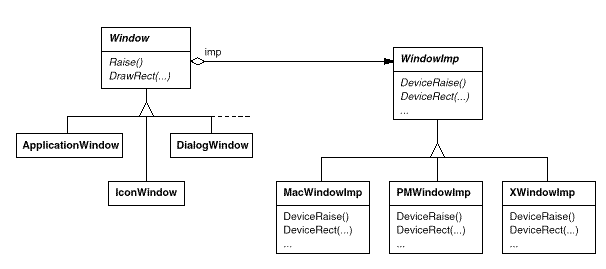
We avoid cluttering the Window classes with window system dependencies by hiding the implementations in WindowImp classes, which makes the Window class hierarchy fairly short and stable. Meanwhile, we can easily add new window systems to the implementation hierarchy.
WindowImp Subclasses
WindowImp subclasses translate requests into window system-specific operations. The Rectangle was defined as follows: Draw in terms of the Window instance's DrawRect operation:
Void Rectangle::Draw (Window* w) {
w->DrawRect(_x0, _y0, _x1, _y1);
}
The default implementation of DrawRect uses the abstract procedure specified by WindowImp for drawing rectangles:
Void Window::DrawRect (
Coord x0, Coord y0, Coord x1, Coord y1
) {
_imp->DeviceRect(x0, y0, x1, y1);
}
Where _imp is a Window member variable that holds the WindowImp that the Window is configured with. The instance of the WindowImp subclass that _imp points to defines the window implementation. The DeviceRect implementation for an XWindowImp (that is, a WindowImp subclass for the X Window System) would look like this.
Void XWindowImp::DeviceRect (
Coord x0, Coord y0, Coord x1, Coord y1
) {
int x = round(min(x0, x1));
int y = round(min(y0, y1));
int w = round(abs(x0 - x1));
int h = round(abs(y0 - y1));
XDrawRectangle(_dpy, _winid, _gc, x, y, w, h);
}
Because XDrawRectangle (the X interface for drawing a rectangle) defines a rectangle in terms of its lower left corner, width, and height, DeviceRect is defined in this way. These values must be computed by DeviceRect using the values supplied. It calculates the width and height after determining the lower left corner (because (x0, y0) might be any of the rectangle's four corners).
PMWindowImp (a Presentation Manager subclass of WindowImp) would specify DeviceRect differently:
Void PMWindowImp::DeviceRect (
Coord x0, Coord y0, Coord x1, Coord y1
) {
Coord left = min(x0, x1);
Coord right = max(x0, x1);
Coord bottom = min(y0, y1);
Coord top = max(y0, y1);
PPOINTL point[4];
point[0].x = left; point[0].y = top;
point[1].x = right; point[1].y = top;
point[2].x = right; point[2].y = bottom;
point[3].x = left; point[3].y = bottom;
if (
(GpiBeginPath(_hps, 1L) == false) ||
(GpiSetCurrentPosition(_hps, &point[3]) == false) ||
(GpiPolyLine(_hps, 4L, point) == GPI_ERROR) ||
(GpiEndPath(_hps) == false)
) {
// report error
} else {
GpiStrokePath(_hps, 1L, 0L);
}
}
Configuring Windows with WindowImps
How a window is equipped with the right WindowImp subclass in the first place is a critical issue we haven't addressed. To put it another way, when is _imp initialised, and who knows what window system (and hence which WindowImp subclass) is currently in use? Before it can do anything interesting, the window will require some type of WindowImp.
There are a several options, but we'll concentrate on one that employs the Abstract Factory pattern. WindowSystemFactory is an abstract factory class that provides an interface for producing many types of window system-dependent implementation objects:
Class WindowSystemFactory {
public:
virtual WindowImp* CreateWindowImp() = 0;
virtual ColorImp* CreateColorImp() = 0;
virtual FontImp* CreateFontImp() = 0;
// a "Create..." operation for all window system resources
};
For each window system, we can now define a concrete factory:
Class PMWindowSystemFactory : public WindowSystemFactory {
virtual WindowImp* CreateWindowImp()
{ return new PMWindowImp; }
// ...
};
class XWindowSystemFactory : public WindowSystemFactory {
virtual WindowImp* CreateWindowImp()
{ return new XWindowImp; }
// ...
};
The function Object() { [native code] } of the Window base class can utilize the WindowSystemFactory interface to initialize the _imp member with the appropriate WindowImp for the window system:
Window::Window () {
_imp = windowSystemFactory->CreateWindowImp();
}
The windowSystemFactory variable, like the guiFactory variable that defines the look and feel, is a well-known instance of a WindowSystemFactory subclass. In the same way, the windowSystemFactory variable can be set up.
Bridge Pattern
The WindowImp class defines an interface to common window system services, although it is designed differently than the Window interface. WindowImp's interface isn't something application programmers will interact with directly; they'll only deal with Window objects. As a result, unlike the Window class hierarchy and interface, WindowImp's interface does not need to reflect the application programmer's vision of the world. WindowImp's interface can more accurately reflect what modern window systems offer, flaws and all. It can be skewed toward an intersection of functionality or a union of functionality approach, depending on the target window systems.
The crucial thing to remember is that the Window interface is designed for application developers, whereas WindowImp is designed for window systems. We can implement and customize these interfaces independently by separating windowing functionality into Window and WindowImp hierarchies. These hierarchies' objects work together to allow Lexi to work on multiple window systems without modification.
Q7) What is user operations?
A7) The document's WYSIWYG representation provides access to some of Lexi's features. By pointing, clicking, and typing directly in the document, you can enter and delete text, modify the insertion point, and select text ranges. User operations in Lexi's pull-down menus, buttons, and keyboard accelerators provide indirect access to other functions. The features include operations like as
● generating a new document,
● opening, saving, and printing an existing document,
● copying and pasting selected text,
● altering the font and style of selected text,
● modifying the formatting of text,
● such as alignment and justification,
● exiting the application,
● and so on.
For these operations, Lexi offers a variety of user interfaces. However, we don't want to link a certain user activity to a specific user interface because we may need numerous user interfaces for the same task (you can turn the page using either a page button or a menu operation, for example). In the future, we may want to modify the interface.
These operations are also implemented in a variety of types. We want to be able to access our functionality without having to create a lot of dependencies between implementation and user interface classes. We'll wind up with a tightly connected implementation that's difficult to comprehend, extend, and maintain otherwise.
To make matters more complicated, we want Lexi to offer undo and redo8 of most, but not all, of its functions. We want to be able to undo document-modifying operations like remove, which can mistakenly erase a large amount of data. However, we should not attempt to reverse an action like saving a drawing or exiting the application. The undo procedure should be unaffected by these operations. We also don't want an arbitrary limit on how many levels of undo and redo can be used.
Support for user activities is evident throughout the application. The task at hand is to devise a simple and extendable method that meets all of these requirements.
Encapsulating a Request
To make matters more complicated, we want Lexi to offer undo and redo8 of most, but not all, of its functions. We want to be able to undo document-modifying operations like remove, which can mistakenly erase a large amount of data. However, we should not attempt to reverse an action like as saving a drawing or exiting the application. The undo procedure should be unaffected by these operations. We also don't want an arbitrary limit on how many levels of undo and redo can be used.
Support for user activities is evident throughout the application. The task at hand is to devise a simple and extendable method that meets all of these requirements.
Every user operation might have its own subclass of MenuItem, which would then be hard-coded to carry out the request. But that isn't really correct; we don't require a subclass of MenuItem for each request, any more than we require a subclass for each text string in a pull-down menu. Furthermore, this strategy ties the request to a specific user interface, making it difficult to fulfill it using an alternative user interface.
As an example, assume you could access the document's last page using both a MenuItem in a pull-down menu and a page icon at the bottom of Lexi's interface (which might be more convenient for short documents).
Command Class and Subclasses
To issue a request, we first construct a Command abstract class to provide an interface. The basic interface is made up of only one abstract operation called "Execute." Subclasses of Command implement Execute in a variety of ways to satisfy various needs. Other objects may be delegated some or all of the work by some subclasses. Other subclasses may be able to complete the request completely on their own. However, to the requester, a Command object is a Command object, and they are all regarded the same.
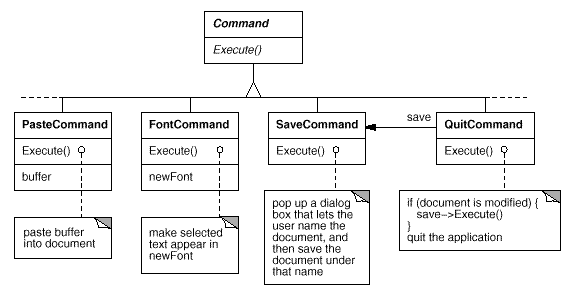
Fig 9: Partial Command class hierarchy
MenuItem now has the ability to contain a Command object that encapsulates a request. Just as we specify the text to appear in the menu item, we give each menu item object an instance of the Command subclass that's appropriate for that menu item. When a user selects a menu item, the MenuItem merely executes the request by using Execute on its Command object. It's worth noting that buttons and other widgets, such menu items, can employ instructions.
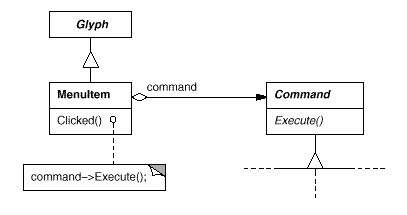
Fig 10: MenuItem-Command relationship
Undoability
In interactive applications, the ability to undo and redo is crucial. We add an Unexecute action to Command's interface to undo and redo commands. Unexecute reverses the effects of a previous Execute operation by using the undo information stored by Execute. In the instance of a FontCommand, for example, the Execute action would save both the original font and the region of text impacted by the font change (s). The Unexecute operation of FontCommand returns the range of text to its original font (s).
Undoability must sometimes be determined at runtime. If the text is already in that font, a request to change the font of a selection has no effect. Let's say a user selects some text and then asks for an illegitimate font change. What should happen if you make a second undo request? Should an insignificant modification result in an equally insignificant undo request? Most likely not. If the user makes the erroneous font change numerous times, he shouldn't have to undo the same number of times to return to the previous meaningful activity. There is no need for an undo request if the overall result of performing a command was nil.
So we add an abstract Reversible operation to the Command interface to see if a command is undoable. A Boolean value is returned by reversible. This procedure can be redefined by subclasses to return true or false depending on run-time criteria.
Q8) How to check spelling and Hyphenation?
A8) The final design issue is textual analysis, which entails looking for misspellings and inserting hyphenation points where necessary for proper formatting.
The limits are comparable to those we faced when dealing with the formatting design problem. There are multiple ways to check spelling and compute hyphenation points, just as there are multiple ways to break lines. As a result, we wish to enable multiple algorithms here as well. A broad set of algorithms can offer a variety of trade-offs in terms of space, time, and quality. We should also make it simple to add new algorithms.
In addition, we don't want to hardwire this capability into the document's structure. Because spelling checking and hyphenation are just two of the numerous types of analyses we could want Lexi to enable, this aim is far more crucial than it was in the formatting instance. Over time, we'll inevitably wish to improve Lexi's analytical skills. We may include features like searching, word counting, a calculator for adding up tabular values, grammar checking, and so on. However, we don't want to have to update the Glyph class and all of its subclasses every time we add new features.
This problem is actually made up of two parts: (1) obtaining the data to be analyzed, which is dispersed throughout the glyphs in the document structure, and (2) doing the analysis. We'll look at these two pieces separately.
Accessing Scattered Information
Many types of analysis necessitate character-by-character examination of the text. The text we'll be looking at is dispersed throughout a hierarchical network of glyph objects. We need an access mechanism that knows about the data structures in which objects are stored to evaluate text in such a structure. Some glyphs employ linked lists, some use arrays, and yet others use more complex data structures to hold their children. All of these possibilities must be accommodated by our access mechanism.
A further problem arises from the fact that various analyses access data in different ways. The majority of analysis will go over the entire book from beginning to end. Some, on the other hand, do the opposite—a reverse search, for example, must go backwards rather than forwards through the text. Evaluating algebraic expressions could require an inorder traversal. In order to evaluate algebraic expressions, an inorder traversal may be required.
As a result, our access method must handle a variety of data structures and traversals, including preorder, postorder, and inorder.
Encapsulating Access and Traversal
To refer to children, our glyph interface currently uses an integer index. While this may be appropriate for glyph classes that keep their children in an array, it may be inefficient for glyphs that use a linked list. The glyph abstraction plays a vital role in hiding the data structure in which children are stored. We can alter the data structure used by a glyph class without affecting other classes in this way.
As a result, only the glyph is aware of the data structure it employs. The graphic interface should not be biassed toward one data structure over another, as a corollary. It shouldn't, as it is today, be more suited to arrays than linked lists, for example.
We can address this problem while also supporting multiple alternative types of traversals. We can explicitly implement multiple access and traversal capabilities in the glyph classes and provide a means for users to choose between them, possibly by passing an enumerated constant as a parameter. During a traverse, the classes pass this parameter around to make sure they're all performing the same thing. They must share whatever information they have gathered during their journey.
To accommodate this method, we might add the following abstract operations to Glyph's interface:
Void First(Traversal kind)
void Next()
bool IsDone()
Glyph* GetCurrent()
void Insert(Glyph*)
The traversal is controlled by the operations First, Next, and IsDone. The traversal is first initialized. It takes an argument of type Traversal, an enumerated constant with values like CHILDREN (to traverse the glyph's immediate children only), PREORDER (to traverse the entire structure in preorder), POSTORDER, and INORDER (to traverse the entire structure in preorder). Next advances the traverse to the next glyph, and IsDone indicates if the traversal is complete or not.
GetCurrent takes the place of Child and accesses the traversal's current glyph. Insert is a new operation that replaces the old one by inserting the specified glyph at the current position. To do a preorder traversal of a tree, an analysis would use the C++ code below.
Glyph* g;
for (g->First(PREORDER); !g->IsDone(); g->Next()) {
Glyph* current = g->GetCurrent();
// do some analysis
}
The integer index has been removed from the glyph interface. There's nothing in the interface now that favors one type of collection over another. We've also saved clients the trouble of having to develop typical traversals on their own.
However, there are still issues with this strategy. For one thing, it can't allow additional traversals unless the set of enumerated values is expanded or new operations are added. Let's say we needed a preorder traversal version that skipped non-textual glyphs automatically. We'd have to add something like TEXTUAL PREORDER to the Traversal enumeration.
Iterator Class and Subclasses
To provide an universal interface for access and traversal, we'll utilise an abstract class called Iterator. Concrete subclasses such as ArrayIterator and ListIterator provide the interface for accessing arrays and lists, respectively, while PreorderIterator, PostorderIterator, and others implement various traversals on specific structures. The structure traversed is referenced by each Iterator subclass. When a subclass instance is created, it is initialized with this reference. The Iterator class, as well as various subclasses, are shown in the diagram. To support iterators, we've added a CreateIterator abstract procedure to the Glyph class interface.
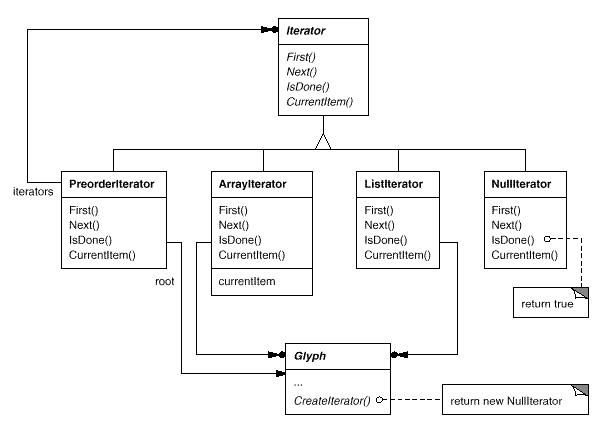
Fig 11: Iterator class and subclasses
For directing the traversal, the Iterator interface includes the functions First, Next, and IsDone. The ListIterator class implements First to point to the list's first element, and Next to advance the iterator to the list's next item. IsDone determines if the list pointer extends beyond the list's last element. CurrentItem returns the glyph that the iterator points to by dereferencing the iterator. An ArrayIterator class, on the other hand, would do the same thing with an array of glyphs.
Without knowing the representation of a glyph structure, we can now access its children:
Glyph* g;
Iterator<Glyph*>* i = g->CreateIterator();
for (i->First(); !i->IsDone(); i->Next()) {
Glyph* child = i->CurrentItem();
// do something with current child
}
By default, CreateIterator returns a NullIterator instance. For glyphs with no offspring, such as leaf glyphs, a NullIterator is a degenerate iterator. The IsDone action of a NullIterator always returns true.
CreateIterator will be overridden by a glyph subclass with children to return an instance of a different Iterator subclass. The structure that stores the children determines which subclass to use. If Glyphs Row subclass holds its offspring in a list called _children, the CreateIterator action would be as follows:
Iterator<Glyph*>* Row::CreateIterator () {
return new ListIterator<Glyph*>(_children);
}
Iterators for preorder and inorder traversals use glyph-specific iterators to implement their traversals. The root glyph in the structure they traverse is passed to the iterators for these traversals. They use a stack to keep track of the iterators created by calling CreateIterator on the structure's glyphs.
Iterator Pattern
These strategies for facilitating access and traversal over object structures are captured by the Iterator pattern. It can be applied to collections as well as composite architectures. It hides the internal structure of the objects it traverses by abstracting the traversal process. The Iterator pattern demonstrates how encapsulating the concept of variation aids us in gaining flexibility and reusability once again. Even still, the iteration problem is quite complex, and the Iterator pattern has far more complexities and trade-offs than we've covered here.
Traversal versus Traversal Actions
Now that we've figured out how to navigate the glyph hierarchy, we need to double-check the spelling and hyphenate the words. During the traversal, both analyses need gathering data.
First, we must identify where the responsibility for analysis will be assigned. We might include it in the Iterator classes, making analysis a necessary component of traversal. However, if we separate between traversal and the actions performed during traversal, we gain additional flexibility and opportunity for reuse. This is because various analyses frequently necessitate the same type of traversal. As a result, we can use the same set of iterators for many analyses. Preorder traversal, for example, is used in a variety of studies, including spelling check, hyphenation, forward search, and word count.
As a result, analysis and traversal should be handled separately. Where else could the responsibility for analysis be assigned? We are aware that there are numerous types of analyses that we may like to do. At different places during the traversal, each analysis will perform differently. Depending on the type of study, some glyphs are more relevant than others. Character glyphs, not graphical ones like lines and bitmapped pictures, should be considered when checking spelling or hyphenation. When designing color separations, we should think on visible glyphs rather than invisible ones. Various analyses will invariably look at different glyphs.
As a result, a given analysis must be able to discern between various glyph types. One apparent solution is to embed the analytical capacity directly into the glyph classes. We can add one or more abstract operations to the Glyph class for each analysis and have subclasses implement them according to their involvement in the analysis.
But the problem with that technique is that whenever we introduce a new type of analysis, we'll have to change every glyph class. In some circumstances, we can make this problem go away: We can provide a default implementation for the abstract operation in the Glyph class if only a few classes participate in the analysis or if most classes do the analysis in the same way. The common case would be covered by the default operation. As a result, alterations would be limited to the Glyph class and its subclasses that differ from the usual.
Encapsulating the Analysis
According to all indicators, we'll need to separate the analysis into its own object, as we've done many times previously. We could separate the analytical mechanism into its own class. An instance of this class could be used in conjunction with an appropriate iterator. Each glyph in the structure would be "carried" by the iterator. At each point in the traversal, the analysis object might conduct a portion of the analysis. As the traversal progresses, the analyzer collects information of interest (in this example, characters):
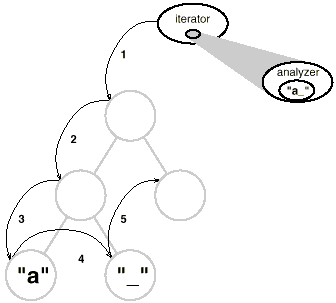
The key question with this method is how the analysis object distinguishes between different types of glyphs without using type checks or downcasts. We don't want a SpellingChecker class to have (false) code like this.
Void SpellingChecker::Check (Glyph* glyph) {
Character* c;
Row* r;
Image* i;
if (c = dynamic_cast<Character*>(glyph)) {
// analyze the character
} else if (r = dynamic_cast<Row*>(glyph)) {
// prepare to analyze r's children
} else if (i = dynamic_cast<Image*>(glyph)) {
// do nothing
}
}
This code is quite unsightly. It makes use of exotic features like type-safe casting. It's also difficult to extend. When the Glyph class hierarchy changes, we'll need to remember to alter the body of this method. In reality, object-oriented languages were designed to eliminate this type of programming.
We wish to avoid using such a forceful approach, but how can we do so? Consider what happens if we extend the Glyph class with the following abstract operation:
Void CheckMe(SpellingChecker&)
CheckMe is defined as follows in every Glyph subclass:
Void GlyphSubclass::CheckMe (SpellingChecker& checker) {
checker.CheckGlyphSubclass(this);
}
Where GlyphSubclass is replaced with the glyph subclass's name. Because we're in one of Glyph's processes, the precise Glyph subclass is known when CheckMe is invoked. For each Glyph subclass, the SpellingChecker class interface includes an operation called CheckGlyphSubclass:
Class SpellingChecker {
public:
SpellingChecker();
virtual void CheckCharacter(Character*);
virtual void CheckRow(Row*);
virtual void CheckImage(Image*);
// ... And so forth
List<char*>& GetMisspellings();
protected:
virtual bool IsMisspelled(const char*);
private:
char _currentWord[MAX_WORD_SIZE];
List<char*> _misspellings;
};
The checking operation for Character glyphs in SpellingChecker could look like this:
Void SpellingChecker::CheckCharacter (Character* c) {
const char ch = c->GetCharCode();
if (isalpha(ch)) {
// append alphabetic character to _currentWord
} else {
// we hit a nonalphabetic character
if (IsMisspelled(_currentWord)) {
// add _currentWord to _misspellings
_misspellings.Append(strdup(_currentWord));
}
_currentWord[0] = '\0';
// reset _currentWord to check next word
}
}
Visitor Class and Subclasses
The term "visitor" will be used to refer to classes of objects that "visit" other objects during a traversal and perform some action. 12 In this situation, a Visitor class can be defined to define an abstract interface for visiting glyphs in a structure.
Class Visitor {
public:
virtual void VisitCharacter(Character*) { }
virtual void VisitRow(Row*) { }
virtual void VisitImage(Image*) { }
// ... And so forth
};
Different Visitor subclasses execute different analyses. For example, a SpellingCheckingVisitor subclass may be used to check spelling, while a HyphenationVisitor subclass could be used to check hyphenation. SpellingCheckingVisitor would be implemented in the same way that SpellingChecker was, with the exception that the operation names would be changed to match the more general Visitor interface. CheckCharacter, for example, would be renamed VisitCharacter.
We'll call it CheckMe instead, because CheckMe isn't acceptable for visitors who don't check anything.
Accept. Its argument must also be changed to take a Visitor, indicating that it can accept any visitor. Now, all we have to do to add a new analysis is define a new subclass of Visitor—we don't have to change any of the glyph classes. By adding this single action to Glyph and its subclasses, we can support all future analysis.
We've already shown how to use spell check. In HyphenationVisitor, we employ a similar strategy to collect text. However, after the Hyphenation Visitors VisitCharacter operation has completed a whole word, it behaves differently. Instead of checking for misspellings, it uses a hyphenation algorithm to assess whether the word has any potential hyphenation points. It then inserts a discretionary glyph into the composition at each hyphenation point. Discretionary glyphs are instances of the Glyph subclass Discretionary.
Depending on whether or not it is the last character on a line, a discretionary glyph can take one of two forms. If it's the last character of a line, the discretionary appears as a hyphen; if it's not the last character of a line, the discretionary has no appearance. The optional checks to determine if it is the last child of its parent (a Row object). When the discretionary is asked to draw or determine its borders, it performs this check. Discretionaries are treated the same as whitespace in the formatting technique, so they can be used to end a line. The diagram below depicts how an embedded discretionary might appear.
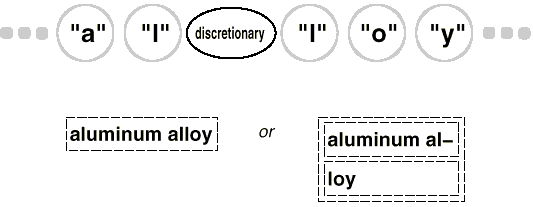
Visitor Pattern
This is an example of how the Visitor pattern can be used. The important actors in the pattern are the Visitor class and its subclasses defined earlier. The Visitor pattern encapsulates the method we used to allow an infinite number of glyph structural analyses without changing the glyph classes themselves. Visitors also have the advantage of being able to be applied to any object structure, not only composites like our glyph structures. Sets, lists, and even directed-acyclic graphs fall into this category. Furthermore, a visitor's classes do not have to be tied to one another through a shared parent class. As a result, visitors can collaborate with people from many walks of life.
Which class hierarchies change the most frequently? This is a crucial question to ask yourself before using the Visitor pattern. When you want to be able to do a variety of various things to objects with a consistent class structure, this pattern is ideal. There is no need to update the class structure when adding a new type of visitor, which is especially significant when the class structure is big. However, if you add a subclass to the structure, you'll need to change all of your visitor interfaces to include a Visit... Operation for that subclass as well. In our example, creating a new Glyph subclass called Foo will necessitate adding a VisitFoo action to Visitor and all of its subclasses.
Q9) Write the features of lexi design pattern?
A9) Lexi's design features eight different patterns:
● The physical structure of the document is represented by a composite.
● Allowing alternative formatting algorithms is a strategy.
● Decorator for adding flair to the user interface.
● Multiple look-and-feel standards are supported by Abstract Factory.
● Multiple windowing platforms can be accessed using a bridge.
● Undoable user operations command.
● Access and traverse object structures with this iterator.
● and Visitor for permitting an unlimited number of analytical capabilities while keeping the document structure simple to deploy.
None of these design flaws are unique to document editing software like Lexi. Indeed, many of these patterns will be used in most nontrivial applications, albeit for different purposes. Composite could be used in a financial analysis programme to define investment portfolios made up of sub portfolios and accounts of various types. The Strategy pattern can be used by a compiler to support alternative register allocation techniques for different target machines. Applications having a graphical user interface, like this one, will very certainly employ Decorator and Command.
Q10) What are the Entities of Service Locator Pattern?
A10) The entities of this design pattern are listed below.
● Service - This is the actual service that will handle the request. A reference to such a service can be found in the JNDI server.
● JNDI Context / Initial Context - The context contains a reference to the service that was utilized for the lookup.
● Service Locator - Using JNDI lookup caching, Service Locator provides a single point of contact for obtaining services.
● Cache - A cache is used to save service references so that they can be reused later.
● Client - The object that uses Service Locator to call the services.
Unit – 5
A Case Study
Q1) What are the design problems to design a document editor?
A1) We'll look at seven issues with Lexi's design:
● Document structure
Almost every aspect of Lexi's design is influenced by the document's internal representation. The representation will be traversed for all editing, formatting, displaying, and textual analysis. The way we organize this data will have an impact on the remainder of the app's design.
● Formatting
What is Lexi's method for dividing text and pictures into lines and columns? What objects are in charge of enforcing certain formatting policies? What is the relationship between these policies and the internal representation of the document?
● Embellishing the user interface
Scroll bars, borders, and drop shadows are included in Lexi's user interface, which complement the WYSIWYG document interface. As Lexi's user interface evolves, such embellishments are likely to change. As a result, it's critical to be able to easily add and delete embellishments without disrupting the rest of the programme.
● Supporting multiple look-and-feel standards
Lexi should be able to readily adapt to different look-and-feel standards like Motif and Presentation Manager (PM) without requiring large changes.
● Supporting multiple window systems
On different window systems, different look-and-feel standards are frequently implemented. Lexi's design should be as autonomous as possible from the window system.
● User operations
Lexi is controlled through a variety of user interfaces, such as buttons and pull-down menus. The functionality behind these interfaces is dispersed across the application's objects. The problem here is to provide a unified way for both accessing and removing this dispersed functionality.
● Spelling checking and hyphenation
Lexi's support for analytical procedures like checking for misspelled words and determining hyphenation spots is quite impressive. How can we reduce the number of classes that need to be changed in order to implement a new analytical operation?
Each challenge contains a set of objectives as well as limits on how we will reach those objectives.
Q2) What do you mean by document structure?
A2) In the end, a document is nothing more than a collection of basic graphical elements including characters, lines, polygons, and other shapes. These elements encompass the document's whole information content. Yet an author often views these elements not in graphical terms but in terms of the document's physical structure—lines, columns, figures, tables, and other substructures. In turn, these substructures have substructures of their own, and so on.
The user interface for Lexi should allow users to directly alter these substructures. For example, rather than treating a diagram as a collection of distinct graphical primitives, a user should be able to consider it as a single unit. A table should be able to be referred to as a whole, not as a jumble of text and visuals. This contributes to the interface's simplicity and intuitiveness. We'll choose an internal representation that matches the document's physical structure to provide Lexi's implementation similar properties.
Internal representation should, in particular, support the following:
● Maintaining the physical structure of the document, which includes the arranging of text and visuals into lines, columns, tables, and other structures.
● Visually creating and displaying the document.
● The mapping of display positions to items in the internal representation. When the user points to something in the visual depiction, Lexi can figure out what he's talking about.
There are additional limitations in addition to these objectives. To begin, we should treat text and visuals in the same way. The user interface of the application allows the user to freely incorporate text within visuals and vice versa. Otherwise, we'll wind up with redundant formatting and manipulation procedures if we regard graphics as a special instance of text or text as a special case of graphics. For both text and visuals, a single set of methods should be sufficient.
Second, in the internal representation, our implementation should not have to discriminate between single items and groups of components. Lexi should be able to treat basic and complex elements in the same way, enabling for the creation of arbitrarily complex documents. For example, the tenth element in line five of column two could be a single character or a complex graphic with numerous subelements. The complexity of this element has no influence on how and where it should appear on the page as long as we know it can draw itself and specify its dimensions.
The necessity to assess the text for things like spelling problems and probable hyphenation points, on the other hand, is in direct opposition to the second limitation. We don't always care if a line's element is a simple or complex item. However, an analysis might also be dependent on the things being analysed. Checking the spelling of a polygon or hyphenating it, for example, makes no sense. The internal representation's design should take this and other potentially conflicting constraints into account.
Recursive Composition
Recursive composition, which requires creating progressively complex pieces out of simpler ones, is a typical way to express hierarchically ordered information. We may use recursive composition to create a document out of simple graphical pieces. To begin, we can tile a series of characters and visuals from left to right in the document to construct a line. Then you may arrange several lines to make a column, multiple columns to make a page, and so on.
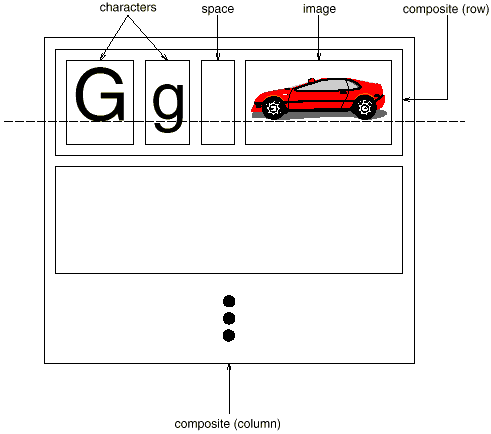
Fig 1: Recursive composition of text and graphics
We may express this physical structure by giving each important constituent its own object. This includes not just the visible elements like as text and graphics, but also the unseen structural elements such as lines and columns. The object structure illustrated in Figure is the end outcome.
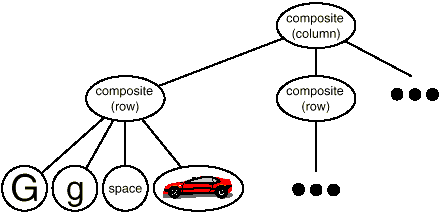
Fig 2: Object structure for recursive composition of text and graphics
We promote flexibility at the highest levels of Lexi's design by using an object for each character and graphical element in the page. Text and visuals can be treated the same way in terms of how they're produced, formatted, and embedded in one other. Lexi may be extended to handle additional character sets without affecting existing features. Lexi's object structure is based on the physical structure of the document.
Glyphs
For all items that can appear in a document structure, we'll create a Glyph abstract class. Its subclasses define both basic graphical elements (such as characters and images) as well as structural elements (like rows and columns). The fundamental glyph interface is presented in further depth using C++ notation in Table, which illustrates a typical component of the Glyph class hierarchy.
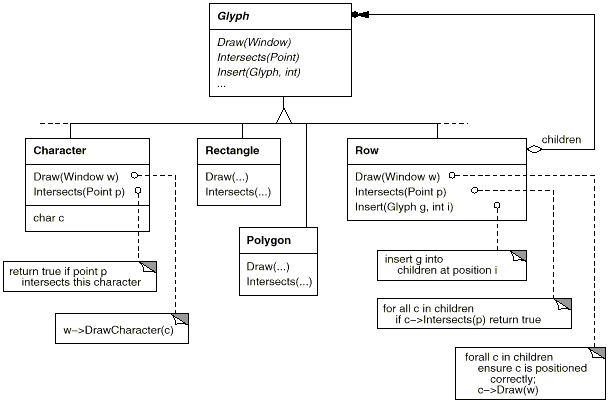
Fig 3: Partial Glyph class hierarchy
Responsibility | Operations |
Appearance | Virtual void Draw(Window*) Virtual void Bounds(Rect&) |
Hit detection | Virtual bool Intersects(const Point&) |
Structure | Virtual void Insert(Glyph*, int) Virtual void Remove(Glyph*) Virtual Glyph* Child(int) Virtual Glyph* Parent() |
Table: Basic glyph interface
Glyphs have three primary functions. They understand (1) how to sketch themselves, (2) how much space they take up, and (3) how to communicate with their children and parents.
Composite Pattern
More than simply documents benefit from recursive composition. It can be used to represent any hierarchical structure that is potentially complex. In object-oriented terms, the Composite pattern embodies the core of recursive composition. It's a good idea to go back to that pattern and examine it now, referring back to this instance as needed.
Q3) Describe formatting?
A3) We've decided on a way to represent the physical structure of the document. The next step is to figure out how to build a certain physical structure that matches to a correctly structured document. The terms "representation" and "formatting" are not interchangeable: The capacity to represent the physical structure of a document does not tell us how to get to that structure.
Lexi bears the brunt of this obligation. It must divide text into lines, lines into columns, and so on, taking the user's higher-level preferences into account. For example, the user would want to change the margin widths, indentation, and tabulation; single or double space; and presumably a variety of other formatting options. All of these must be taken into account by Lexi's formatting algorithm.
By the way, we'll define "formatting" as the process of dividing a group of glyphs into lines. In reality, we'll exchange the phrases "formatting" and "line breaking." The strategies we'll go over can be used to divide lines into columns as well as columns into pages.
Encapsulating the Formatting Algorithm
With all of its limits and complexities, the formatting process is difficult to automate. There are numerous approaches to the problem, and various formatting algorithms have been developed, each with its own set of strengths and limitations. Because Lexi is a WYSIWYG editor, the balance between formatting quality and formatting speed is a critical trade-off to consider. We want a positive response from the editor without jeopardizing the document's appearance. This trade-off is influenced by a number of variables, not all of which can be determined at compile time.
For instance, the user could be willing to put up with a somewhat slower response in return for better formatting. Because of this trade-off, a completely alternative formatting algorithm may be more suited than the existing one. Formatting speed and storage requirements are balanced in another, more implementation-driven trade-off: By caching additional data, it may be able to reduce formatting time.
Due to the complexity of formatting algorithms, it's best to make them self-contained or, better yet, fully independent of the document structure. In an ideal world, we'd be able to add a new type of Glyph subclass that didn't care about the formatting methodology. Adding a new formatting mechanism, on the other hand, should not necessitate changing existing glyphs.
These qualities suggest that we should design Lexi so that changing the formatting method is simple, at least at build time, if not at run time. Encapsulating the algorithm in an object allows us to isolate it while also making it easily changeable. We'll create a new class hierarchy for objects that encapsulate formatting algorithms in more detail. Each subclass will implement the interface to carry out a certain algorithm, with the root of the hierarchy defining an interface that supports a wide range of formatting algorithms. Then we can add a Glyph subclass that will automatically arrange its children using a provided algorithm object.
Compositor and Composition
For objects that can encapsulate a formatting algorithm, we'll define the Compositor class. The interface informs the compositor of which glyphs should be formatted and when they should be formatted. It formats glyphs that belong to a special Glyph subclass called Composition. When a composition is built, it receives an instance of the Compositor subclass (specialized for a specific line breaking algorithm) and instructs the compositor to Compose its glyphs as needed, such as when the user edits a document. The links between the Composition and Compositor classes are shown in the diagram.
Responsibility | Operations |
What to format | Void SetComposition(Composition*) |
When to format | Virtual void Compose() |
Table: Basic compositor interface
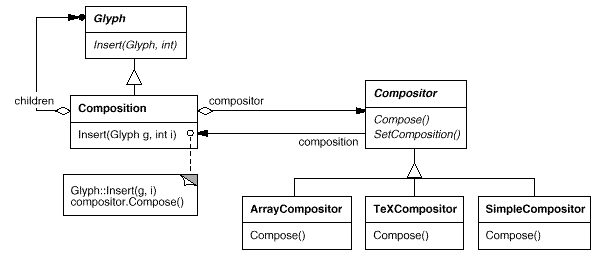
Fig 4: Composition and Compositor class relationships
Strategy Pattern
The Strategy pattern's goal is to encapsulate an algorithm in an object. Strategy objects (which encapsulate various algorithms) and the context in which they function are crucial actors in the pattern. Compositors are a type of strategy that encapsulates several formatting procedures. The context for a compositor strategy is composition.
Designing interfaces for the strategy and its surroundings that are generic enough to allow a variety of algorithms is the key to using the Strategy pattern. To support a new algorithm, you shouldn't have to update the strategy or the context interface. In our example, the Glyph interface's support for child access, insertion, and removal is broad enough to allow Compositor subclasses to modify the document's physical structure independent of the method they use. Similarly, the Compositor interface provides everything that compositions require to begin formatting.
Q4) What is Embellishing the User Interface?
A4) We look at two enhancements to Lexi's user interface. To demarcate the text page, the first inserts a border around the text editing area. The second adds scroll bars, which allow the user to examine various areas of the page. We shouldn't use inheritance to add these embellishments to the user interface because it makes it difficult to add and delete them (particularly at run-time). When other user interface items are unaware of the embellishments, we gain the most flexibility. This allows us to add and remove embellishments without having to change any other classes.
Transparent Enclosure
Enhancing the user interface from a programming standpoint entails expanding existing code. Using inheritance to achieve such extension prevents reordering embellishments at runtime, but an equally important issue is the expansion of classes that might occur from using inheritance.
We could give Composition a border by subclassing it to get the BorderedComposition class. Alternatively, we could create a ScrollableComposition by adding a scrolling interface in the same way. We could make a BorderedScrollableComposition if we want both scroll bars and a border, and so forth. We end up with a class for every potential combination of embellishments in the extreme, a strategy that quickly becomes untenable as the number of embellishments increases.
Object composition may provide a more practical and adaptable extension technique. But what are the objects that we put together? We could make the decoration an object because we're embellishing an existing glyph (say, an instance of class Border). The glyph and the border are the two choices for composition. The next stage is to figure out who will compose who. The glyph may be contained within the border, which makes sense considering that the border will surround the glyph on the screen. Alternatively, we could put the border inside the glyph, but this would necessitate changes to the relevant Glyph subclass to make it aware of the border. Our first choice, composing the glyph in the border, keeps the border-drawing code entirely in the Border class, leaving other classes alone.
Monoglyph
All glyphs that decorate other glyphs can benefit from the concept of translucent enclosure. To put this idea into practise, we'll create a MonoGlyph subclass of Glyph that will serve as an abstract class for "embellishment glyphs" like Border. MonoGlyph keeps track of a component's reference and routes all requests to it. By default, MonoGlyph is completely transparent to clients. MonoGlyph, for example, implements the Draw action as follows:
Void MonoGlyph::Draw (Window* w) {
_component->Draw(w);
}
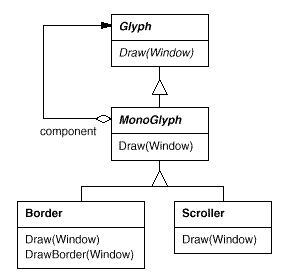
Fig 5: MonoGlyph class relationships
At least one of these forwarding procedures is reimplemented by MonoGlyph subclasses. For example, the parent class action is called first by Border::Draw. MonoGlyph:: Draw everything except the border on the component to allow the component to do its job. Then Border::Draw draws the border by invoking a private operation called DrawBorder, which we won't get into here:
Void Border::Draw (Window* w) {
MonoGlyph::Draw(w);
DrawBorder(w);
}
Take note of how Boundary::Draw extends the parent class's action to draw the border. In contrast, just replacing the parent class operation would result in the call to MonoGlyph::Draw being omitted.
Figure shows another MonoGlyph subclass. Scroller is a MonoGlyph that draws its component in various locations depending on the positions of two scroll bars it adds as embellishments. Scroller tells the graphics system to clip to its bounds when it draws its component. Clipping scrolled-out elements of the component prevents them from appearing on the screen.
We now have everything we need to give Lexi's text editing area a boundary and a scrolling interface. To add the scrolling interface, we compose the existing Composition instance in a Scroller instance, which we then compose in a Border instance. Figure shows the resulting object structure.
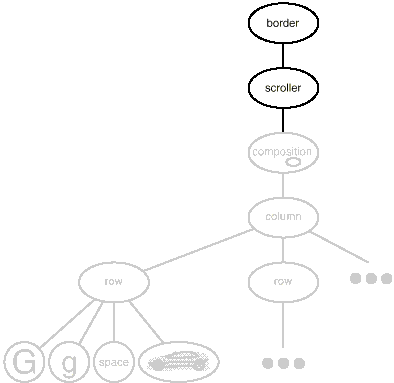
Fig 6: Embellished object structure
It's worth noting that we can change the composition order by adding the bordered composition into the Scroller instance. The border would scroll with the text in that situation, which may or may not be acceptable. The goal is that a transparent enclosure allows customers to experiment with various options while also keeping them free of decorative code.
Decorator Pattern
The Decorator pattern records class and object relationships that enable transparent enclosure decorating. The phrase "embellishment" has a broader definition than what we've looked at thus far. In the Decorator pattern, decoration refers to anything that gives an item more responsibility. Consider adding semantic actions to an abstract syntax tree, adding new transitions to a finite state automaton, or adding attribute tags to a network of persistent objects. Decorator generalizes the approach we used in Lexi so that it may be used more extensively.
Q5) Write about Supporting Multiple Look-and-Feel Standards?
A5) A fundamental challenge in system design is achieving portability between hardware and software platforms. It shouldn't need a huge change to retarget Lexi to a new platform, or it wouldn't be worth it. Porting should be as simple as feasible.
The variety of look-and-feel standards, which are designed to enforce conformity between apps, is one barrier to portability. These principles dictate how apps appear and interact with users. While current standards aren't all that dissimilar, consumers won't mistake one for the other—motif applications don't appear or feel the same as their counterparts on other platforms, and vice versa. An application that runs on many platforms must follow each platform's user interface style guide.
Abstracting Object Creation
Our design aims were to make Lexi comply to a variety of existing look-and-feel standards while also making it simple to add support for new standards when they (inevitably) emerge. We also want our design to allow us to change Lexi's appearance and feel at any time during the game.
In Lexi's user interface, everything we see and interact with is a glyph made up of other, unseen glyphs like Row and Column. The visible glyphs, such as Button and Character, are made up of invisible glyphs that lay them out appropriately. Style guides have a lot to say about how "widgets," or visible symbols like buttons, scroll bars, and menus that operate as controlling elements in a user interface, appear and feel.
We'll suppose we have two sets of widget glyph classes to work with in order to create multiple look-and-feel guidelines:
● Each kind of widget glyph has a set of abstract Glyph subclasses. ScrollBar, for example, is an abstract class that adds general scrolling operations to the basic glyph interface; Button is an abstract class that adds button-oriented activities; and so on.
● Each abstract subclass has a set of concrete subclasses that implement different look-and-feel standards. MotifScrollBar and PMScrollBar are two subclasses of ScrollBar that implement Motif and Presentation Manager-style scroll bars, respectively.
Lexi needs to be able to tell the difference between widget glyphs for different look-and-feel styles. When Lexi needs to add a button to its interface, for example, it must create a Glyph subclass for the appropriate button style (MotifButton, PMButton, MacButton, etc.).
It's clear that Lexi's implementation can't do this directly, say, using a constructor call in C++. This would hard-code a style's button, making it impossible to change the style at run-time. We'd also have to track down and change every such constructor call to port Lexi to another platform. Buttons are only one of the many widgets available in Lexi's user interface. Constructor calls to specialized look-and-feel classes litter our code, resulting in a maintenance nightmare—miss one, and you may end up with a Motif menu in the midst of your Mac project.
Lexi needs a mechanism to figure out what look-and-feel standard is being used so that she can make the proper widgets. We must not only avoid using explicit function Object() { [native code] } calls, but also be able to simply change a whole widget set. We can do both by abstracting the object-creation process. We'll provide an example to demonstrate what we're talking about.
Factories and Product Classes
Normally, we would use the following C++ code to produce a Motif scroll bar glyph:
ScrollBar* sb = new MotifScrollBar;
If you want Lexi's look-and-feel requirements to be as small as possible, avoid code like this. However, assume we set up sb as follows:
ScrollBar* sb = guiFactory->CreateScrollBar();
Where guiFactory is a MotifFactory class object. CreateScrollBar creates a new instance of the appropriate ScrollBar subclass for the desired look and feel, in this case Motif. In terms of clients, this has the same effect as calling the MotifScrollBar function Object() { [native code] } directly. However, there is one significant difference: the code no longer refers to Motif by name. The guiFactory object simplifies the process of making scroll bars for any look-and-feel standard, not only Motif. Also, guiFactory isn't just for making scroll bars. It can produce a wide variety of widget glyphs, such as scroll bars, buttons, entry fields, menus, and so on.
Because MotifFactory is a subclass of GUIFactory, an abstract class that specifies a general interface for producing widget glyphs, all of this is possible. CreateScrollBar and CreateButton are two actions that can be used to create various widget glyphs. These operations are implemented by GUIFactory subclasses to return glyphs like MotifScrollBar and PMButton that implement a certain look and feel. The resultant class hierarchy for guiFactory objects is shown in Figure.
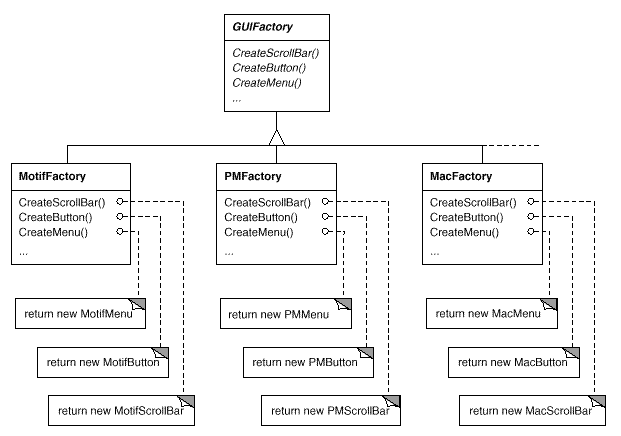
Fig 7: GUI Factory class hierarchy
We refer to factories as "factories that make product objects." Furthermore, a factory's products are linked to one another; in this case, the products are all widgets with the same appearance and feel. Figure depicts some of the product classes required to make widget glyph factories work.
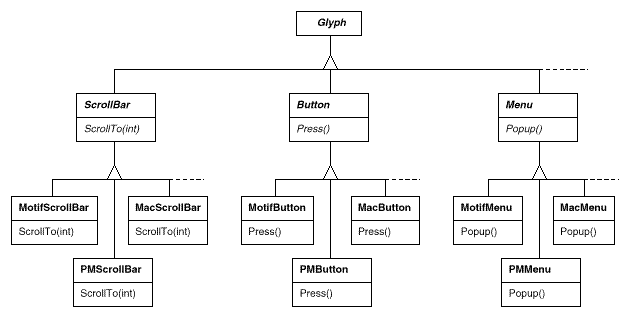
Fig 8: Abstract product classes and concrete subclasses
The last thing we need to figure out is where the GUIFactory instance came from. Anywhere that is convenient is the answer. If the entire user interface is produced within one class or function, the variable guiFactory could be a global variable, a static member of a well-known class, or even a local variable. For managing well-known, one-of-a-kind items like this, there's even a design pattern called Singleton. The crucial thing is to initialize guiFactory before it's used to produce widgets, but after it's clear which look and feel is needed.
GuiFactory can be initialized with a simple assignment of a new factory instance at the start of the programme if the look and feel is known at build time:
GUIFactory* guiFactory = new MotifFactory;
If the user can define the look and feel using a string name at startup, the factory code could be simpler.
GUIFactory* guiFactory;
const char* styleName = getenv("LOOK_AND_FEEL");
// user or environment supplies this at startup
if (strcmp(styleName, "Motif") == 0) {
guiFactory = new MotifFactory;
} else if (strcmp(styleName, "Presentation_Manager") == 0) {
guiFactory = new PMFactory;
} else {
guiFactory = new DefaultGUIFactory;
}
Abstract Factory Pattern
The essential players in the Abstract Factory pattern are factories and products. This pattern describes how to generate families of related product objects without having to directly instantiate classes. It's most appropriate when the number and general types of product objects remain consistent but specific product families differ. We pick between families by creating a concrete factory and using it to make things continuously after that. We may even replace the concrete factory with an instance of a different one to switch entire families of products. The Abstract Factory design differs from other creational patterns in that it focuses on product families rather than a single type of product item.
Q6) How to support multiple window system?
A6) One of the numerous challenges with portability is the appearance. Another factor is Lexi's running environment, which is a windowing environment. On a bitmapped display, the window system of a platform produces the illusion of several overlapping windows. It allocates screen space to windows and channels keyboard and mouse input to them. Today, there are a number of important and largely incompatible window systems (e.g., Macintosh, Presentation Manager, Windows, X). For the same reasons that we support many look-and-feel standards, we'd like Lexi to run on as many of them as possible.
Encapsulating Implementation Dependencies
A Window class was developed to display a glyph or glyph structure on the screen. We didn't indicate which window system this item worked with because, in reality, it doesn't come from any one window system. The Window class captures the common behaviours of windows in different window systems:
● They give you the tools you need to draw simple geometric forms.
● They have the ability to iconize and de-iconize themselves.
● They have the ability to resize themselves.
● When they are de-iconified or a section of their screen area that is overlapped and concealed is exposed, they can (re)draw their contents on demand.
The functionality of windows from various window systems must be covered by the Window class. Consider the following two extreme philosophies:
● Intersection of functionality: Only functionality that is common to all window systems is provided by the Window class interface. The difficulty with this technique is that we end up with a window interface that is only as powerful as the weakest window system. Even though most (but not all) window systems support sophisticated features, we are unable to use them.
● Union of functionality: Create a user interface that includes all of the existing systems' features. The problem is that the resulting interface could be massive and incomprehensible. Besides, whenever a vendor changes its window system interface, we'll have to change it (and Lexi, which is dependent on it).
Because neither extreme is a feasible option, we'll develop something in the middle. The Window class will provide a user-friendly interface with the most often used windowing functionality. Because Lexi will interact directly with this class, the Window class must likewise offer the features Lexi is familiar with, particularly glyphs. That means the interface for Windows must have a minimal set of graphics operations that allow glyphs to draw themselves in the window. The table below shows a sample of the operations available in the Window class interface.
Responsibility | Operations |
Window management | Virtual void Redraw() Virtual void Raise() Virtual void Lower() Virtual void Iconify() Virtual void Deiconify() ... |
Graphics | Virtual void DrawLine(...) Virtual void DrawRect(...) Virtual void DrawPolygon(...) Virtual void DrawText(...) ... |
Windows is a generic type. Windows concrete subclasses support the various types of windows that users encounter. Application windows, icons, and warning dialogues, for example, are all windows, but they behave differently. To capture these distinctions, we can define subclasses such as ApplicationWindow, IconWindow, and DialogWindow. The resulting class hierarchy provides a uniform and intuitive windowing abstraction to programmes like Lexi that is independent of any one vendor's window system:
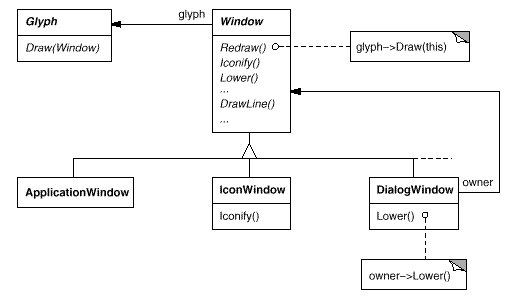
Window and WindowImp
To disguise distinct window system implementations, we'll create a separate WindowImp class hierarchy. WindowImp is an abstract class that encapsulates window system-specific code in objects. We configure each window object with an instance of a WindowImp subclass for that system to make Lexi work on that system. The relationship between the Window and WindowImp hierarchies is depicted in the diagram below:
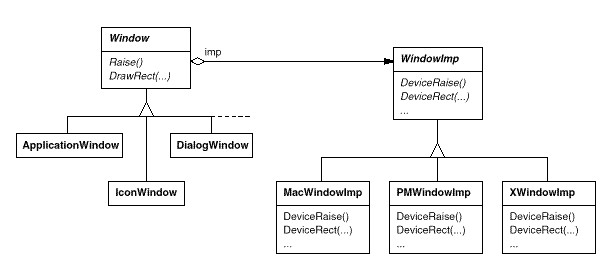
We avoid cluttering the Window classes with window system dependencies by hiding the implementations in WindowImp classes, which makes the Window class hierarchy fairly short and stable. Meanwhile, we can easily add new window systems to the implementation hierarchy.
WindowImp Subclasses
WindowImp subclasses translate requests into window system-specific operations. The Rectangle was defined as follows: Draw in terms of the Window instance's DrawRect operation:
Void Rectangle::Draw (Window* w) {
w->DrawRect(_x0, _y0, _x1, _y1);
}
The default implementation of DrawRect uses the abstract procedure specified by WindowImp for drawing rectangles:
Void Window::DrawRect (
Coord x0, Coord y0, Coord x1, Coord y1
) {
_imp->DeviceRect(x0, y0, x1, y1);
}
Where _imp is a Window member variable that holds the WindowImp that the Window is configured with. The instance of the WindowImp subclass that _imp points to defines the window implementation. The DeviceRect implementation for an XWindowImp (that is, a WindowImp subclass for the X Window System) would look like this.
Void XWindowImp::DeviceRect (
Coord x0, Coord y0, Coord x1, Coord y1
) {
int x = round(min(x0, x1));
int y = round(min(y0, y1));
int w = round(abs(x0 - x1));
int h = round(abs(y0 - y1));
XDrawRectangle(_dpy, _winid, _gc, x, y, w, h);
}
Because XDrawRectangle (the X interface for drawing a rectangle) defines a rectangle in terms of its lower left corner, width, and height, DeviceRect is defined in this way. These values must be computed by DeviceRect using the values supplied. It calculates the width and height after determining the lower left corner (because (x0, y0) might be any of the rectangle's four corners).
PMWindowImp (a Presentation Manager subclass of WindowImp) would specify DeviceRect differently:
Void PMWindowImp::DeviceRect (
Coord x0, Coord y0, Coord x1, Coord y1
) {
Coord left = min(x0, x1);
Coord right = max(x0, x1);
Coord bottom = min(y0, y1);
Coord top = max(y0, y1);
PPOINTL point[4];
point[0].x = left; point[0].y = top;
point[1].x = right; point[1].y = top;
point[2].x = right; point[2].y = bottom;
point[3].x = left; point[3].y = bottom;
if (
(GpiBeginPath(_hps, 1L) == false) ||
(GpiSetCurrentPosition(_hps, &point[3]) == false) ||
(GpiPolyLine(_hps, 4L, point) == GPI_ERROR) ||
(GpiEndPath(_hps) == false)
) {
// report error
} else {
GpiStrokePath(_hps, 1L, 0L);
}
}
Configuring Windows with WindowImps
How a window is equipped with the right WindowImp subclass in the first place is a critical issue we haven't addressed. To put it another way, when is _imp initialised, and who knows what window system (and hence which WindowImp subclass) is currently in use? Before it can do anything interesting, the window will require some type of WindowImp.
There are a several options, but we'll concentrate on one that employs the Abstract Factory pattern. WindowSystemFactory is an abstract factory class that provides an interface for producing many types of window system-dependent implementation objects:
Class WindowSystemFactory {
public:
virtual WindowImp* CreateWindowImp() = 0;
virtual ColorImp* CreateColorImp() = 0;
virtual FontImp* CreateFontImp() = 0;
// a "Create..." operation for all window system resources
};
For each window system, we can now define a concrete factory:
Class PMWindowSystemFactory : public WindowSystemFactory {
virtual WindowImp* CreateWindowImp()
{ return new PMWindowImp; }
// ...
};
class XWindowSystemFactory : public WindowSystemFactory {
virtual WindowImp* CreateWindowImp()
{ return new XWindowImp; }
// ...
};
The function Object() { [native code] } of the Window base class can utilize the WindowSystemFactory interface to initialize the _imp member with the appropriate WindowImp for the window system:
Window::Window () {
_imp = windowSystemFactory->CreateWindowImp();
}
The windowSystemFactory variable, like the guiFactory variable that defines the look and feel, is a well-known instance of a WindowSystemFactory subclass. In the same way, the windowSystemFactory variable can be set up.
Bridge Pattern
The WindowImp class defines an interface to common window system services, although it is designed differently than the Window interface. WindowImp's interface isn't something application programmers will interact with directly; they'll only deal with Window objects. As a result, unlike the Window class hierarchy and interface, WindowImp's interface does not need to reflect the application programmer's vision of the world. WindowImp's interface can more accurately reflect what modern window systems offer, flaws and all. It can be skewed toward an intersection of functionality or a union of functionality approach, depending on the target window systems.
The crucial thing to remember is that the Window interface is designed for application developers, whereas WindowImp is designed for window systems. We can implement and customize these interfaces independently by separating windowing functionality into Window and WindowImp hierarchies. These hierarchies' objects work together to allow Lexi to work on multiple window systems without modification.
Q7) What is user operations?
A7) The document's WYSIWYG representation provides access to some of Lexi's features. By pointing, clicking, and typing directly in the document, you can enter and delete text, modify the insertion point, and select text ranges. User operations in Lexi's pull-down menus, buttons, and keyboard accelerators provide indirect access to other functions. The features include operations like as
● generating a new document,
● opening, saving, and printing an existing document,
● copying and pasting selected text,
● altering the font and style of selected text,
● modifying the formatting of text,
● such as alignment and justification,
● exiting the application,
● and so on.
For these operations, Lexi offers a variety of user interfaces. However, we don't want to link a certain user activity to a specific user interface because we may need numerous user interfaces for the same task (you can turn the page using either a page button or a menu operation, for example). In the future, we may want to modify the interface.
These operations are also implemented in a variety of types. We want to be able to access our functionality without having to create a lot of dependencies between implementation and user interface classes. We'll wind up with a tightly connected implementation that's difficult to comprehend, extend, and maintain otherwise.
To make matters more complicated, we want Lexi to offer undo and redo8 of most, but not all, of its functions. We want to be able to undo document-modifying operations like remove, which can mistakenly erase a large amount of data. However, we should not attempt to reverse an action like saving a drawing or exiting the application. The undo procedure should be unaffected by these operations. We also don't want an arbitrary limit on how many levels of undo and redo can be used.
Support for user activities is evident throughout the application. The task at hand is to devise a simple and extendable method that meets all of these requirements.
Encapsulating a Request
To make matters more complicated, we want Lexi to offer undo and redo8 of most, but not all, of its functions. We want to be able to undo document-modifying operations like remove, which can mistakenly erase a large amount of data. However, we should not attempt to reverse an action like as saving a drawing or exiting the application. The undo procedure should be unaffected by these operations. We also don't want an arbitrary limit on how many levels of undo and redo can be used.
Support for user activities is evident throughout the application. The task at hand is to devise a simple and extendable method that meets all of these requirements.
Every user operation might have its own subclass of MenuItem, which would then be hard-coded to carry out the request. But that isn't really correct; we don't require a subclass of MenuItem for each request, any more than we require a subclass for each text string in a pull-down menu. Furthermore, this strategy ties the request to a specific user interface, making it difficult to fulfill it using an alternative user interface.
As an example, assume you could access the document's last page using both a MenuItem in a pull-down menu and a page icon at the bottom of Lexi's interface (which might be more convenient for short documents).
Command Class and Subclasses
To issue a request, we first construct a Command abstract class to provide an interface. The basic interface is made up of only one abstract operation called "Execute." Subclasses of Command implement Execute in a variety of ways to satisfy various needs. Other objects may be delegated some or all of the work by some subclasses. Other subclasses may be able to complete the request completely on their own. However, to the requester, a Command object is a Command object, and they are all regarded the same.
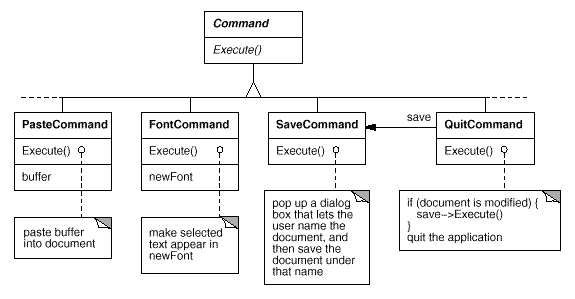
Fig 9: Partial Command class hierarchy
MenuItem now has the ability to contain a Command object that encapsulates a request. Just as we specify the text to appear in the menu item, we give each menu item object an instance of the Command subclass that's appropriate for that menu item. When a user selects a menu item, the MenuItem merely executes the request by using Execute on its Command object. It's worth noting that buttons and other widgets, such menu items, can employ instructions.
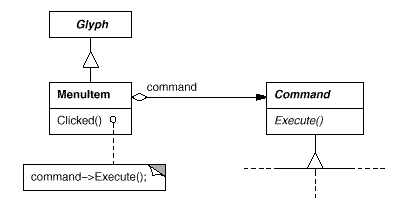
Fig 10: MenuItem-Command relationship
Undoability
In interactive applications, the ability to undo and redo is crucial. We add an Unexecute action to Command's interface to undo and redo commands. Unexecute reverses the effects of a previous Execute operation by using the undo information stored by Execute. In the instance of a FontCommand, for example, the Execute action would save both the original font and the region of text impacted by the font change (s). The Unexecute operation of FontCommand returns the range of text to its original font (s).
Undoability must sometimes be determined at runtime. If the text is already in that font, a request to change the font of a selection has no effect. Let's say a user selects some text and then asks for an illegitimate font change. What should happen if you make a second undo request? Should an insignificant modification result in an equally insignificant undo request? Most likely not. If the user makes the erroneous font change numerous times, he shouldn't have to undo the same number of times to return to the previous meaningful activity. There is no need for an undo request if the overall result of performing a command was nil.
So we add an abstract Reversible operation to the Command interface to see if a command is undoable. A Boolean value is returned by reversible. This procedure can be redefined by subclasses to return true or false depending on run-time criteria.
Q8) How to check spelling and Hyphenation?
A8) The final design issue is textual analysis, which entails looking for misspellings and inserting hyphenation points where necessary for proper formatting.
The limits are comparable to those we faced when dealing with the formatting design problem. There are multiple ways to check spelling and compute hyphenation points, just as there are multiple ways to break lines. As a result, we wish to enable multiple algorithms here as well. A broad set of algorithms can offer a variety of trade-offs in terms of space, time, and quality. We should also make it simple to add new algorithms.
In addition, we don't want to hardwire this capability into the document's structure. Because spelling checking and hyphenation are just two of the numerous types of analyses we could want Lexi to enable, this aim is far more crucial than it was in the formatting instance. Over time, we'll inevitably wish to improve Lexi's analytical skills. We may include features like searching, word counting, a calculator for adding up tabular values, grammar checking, and so on. However, we don't want to have to update the Glyph class and all of its subclasses every time we add new features.
This problem is actually made up of two parts: (1) obtaining the data to be analyzed, which is dispersed throughout the glyphs in the document structure, and (2) doing the analysis. We'll look at these two pieces separately.
Accessing Scattered Information
Many types of analysis necessitate character-by-character examination of the text. The text we'll be looking at is dispersed throughout a hierarchical network of glyph objects. We need an access mechanism that knows about the data structures in which objects are stored to evaluate text in such a structure. Some glyphs employ linked lists, some use arrays, and yet others use more complex data structures to hold their children. All of these possibilities must be accommodated by our access mechanism.
A further problem arises from the fact that various analyses access data in different ways. The majority of analysis will go over the entire book from beginning to end. Some, on the other hand, do the opposite—a reverse search, for example, must go backwards rather than forwards through the text. Evaluating algebraic expressions could require an inorder traversal. In order to evaluate algebraic expressions, an inorder traversal may be required.
As a result, our access method must handle a variety of data structures and traversals, including preorder, postorder, and inorder.
Encapsulating Access and Traversal
To refer to children, our glyph interface currently uses an integer index. While this may be appropriate for glyph classes that keep their children in an array, it may be inefficient for glyphs that use a linked list. The glyph abstraction plays a vital role in hiding the data structure in which children are stored. We can alter the data structure used by a glyph class without affecting other classes in this way.
As a result, only the glyph is aware of the data structure it employs. The graphic interface should not be biassed toward one data structure over another, as a corollary. It shouldn't, as it is today, be more suited to arrays than linked lists, for example.
We can address this problem while also supporting multiple alternative types of traversals. We can explicitly implement multiple access and traversal capabilities in the glyph classes and provide a means for users to choose between them, possibly by passing an enumerated constant as a parameter. During a traverse, the classes pass this parameter around to make sure they're all performing the same thing. They must share whatever information they have gathered during their journey.
To accommodate this method, we might add the following abstract operations to Glyph's interface:
Void First(Traversal kind)
void Next()
bool IsDone()
Glyph* GetCurrent()
void Insert(Glyph*)
The traversal is controlled by the operations First, Next, and IsDone. The traversal is first initialized. It takes an argument of type Traversal, an enumerated constant with values like CHILDREN (to traverse the glyph's immediate children only), PREORDER (to traverse the entire structure in preorder), POSTORDER, and INORDER (to traverse the entire structure in preorder). Next advances the traverse to the next glyph, and IsDone indicates if the traversal is complete or not.
GetCurrent takes the place of Child and accesses the traversal's current glyph. Insert is a new operation that replaces the old one by inserting the specified glyph at the current position. To do a preorder traversal of a tree, an analysis would use the C++ code below.
Glyph* g;
for (g->First(PREORDER); !g->IsDone(); g->Next()) {
Glyph* current = g->GetCurrent();
// do some analysis
}
The integer index has been removed from the glyph interface. There's nothing in the interface now that favors one type of collection over another. We've also saved clients the trouble of having to develop typical traversals on their own.
However, there are still issues with this strategy. For one thing, it can't allow additional traversals unless the set of enumerated values is expanded or new operations are added. Let's say we needed a preorder traversal version that skipped non-textual glyphs automatically. We'd have to add something like TEXTUAL PREORDER to the Traversal enumeration.
Iterator Class and Subclasses
To provide an universal interface for access and traversal, we'll utilise an abstract class called Iterator. Concrete subclasses such as ArrayIterator and ListIterator provide the interface for accessing arrays and lists, respectively, while PreorderIterator, PostorderIterator, and others implement various traversals on specific structures. The structure traversed is referenced by each Iterator subclass. When a subclass instance is created, it is initialized with this reference. The Iterator class, as well as various subclasses, are shown in the diagram. To support iterators, we've added a CreateIterator abstract procedure to the Glyph class interface.
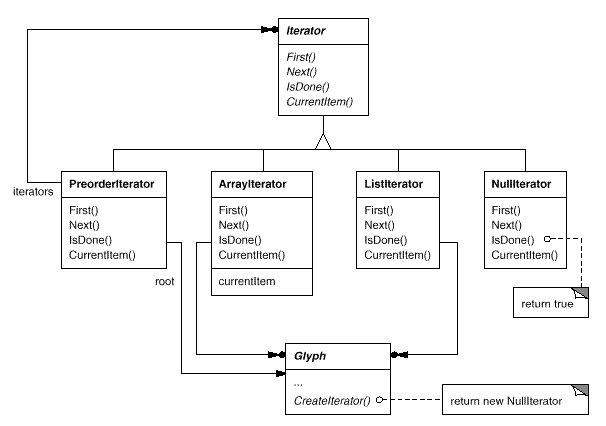
Fig 11: Iterator class and subclasses
For directing the traversal, the Iterator interface includes the functions First, Next, and IsDone. The ListIterator class implements First to point to the list's first element, and Next to advance the iterator to the list's next item. IsDone determines if the list pointer extends beyond the list's last element. CurrentItem returns the glyph that the iterator points to by dereferencing the iterator. An ArrayIterator class, on the other hand, would do the same thing with an array of glyphs.
Without knowing the representation of a glyph structure, we can now access its children:
Glyph* g;
Iterator<Glyph*>* i = g->CreateIterator();
for (i->First(); !i->IsDone(); i->Next()) {
Glyph* child = i->CurrentItem();
// do something with current child
}
By default, CreateIterator returns a NullIterator instance. For glyphs with no offspring, such as leaf glyphs, a NullIterator is a degenerate iterator. The IsDone action of a NullIterator always returns true.
CreateIterator will be overridden by a glyph subclass with children to return an instance of a different Iterator subclass. The structure that stores the children determines which subclass to use. If Glyphs Row subclass holds its offspring in a list called _children, the CreateIterator action would be as follows:
Iterator<Glyph*>* Row::CreateIterator () {
return new ListIterator<Glyph*>(_children);
}
Iterators for preorder and inorder traversals use glyph-specific iterators to implement their traversals. The root glyph in the structure they traverse is passed to the iterators for these traversals. They use a stack to keep track of the iterators created by calling CreateIterator on the structure's glyphs.
Iterator Pattern
These strategies for facilitating access and traversal over object structures are captured by the Iterator pattern. It can be applied to collections as well as composite architectures. It hides the internal structure of the objects it traverses by abstracting the traversal process. The Iterator pattern demonstrates how encapsulating the concept of variation aids us in gaining flexibility and reusability once again. Even still, the iteration problem is quite complex, and the Iterator pattern has far more complexities and trade-offs than we've covered here.
Traversal versus Traversal Actions
Now that we've figured out how to navigate the glyph hierarchy, we need to double-check the spelling and hyphenate the words. During the traversal, both analyses need gathering data.
First, we must identify where the responsibility for analysis will be assigned. We might include it in the Iterator classes, making analysis a necessary component of traversal. However, if we separate between traversal and the actions performed during traversal, we gain additional flexibility and opportunity for reuse. This is because various analyses frequently necessitate the same type of traversal. As a result, we can use the same set of iterators for many analyses. Preorder traversal, for example, is used in a variety of studies, including spelling check, hyphenation, forward search, and word count.
As a result, analysis and traversal should be handled separately. Where else could the responsibility for analysis be assigned? We are aware that there are numerous types of analyses that we may like to do. At different places during the traversal, each analysis will perform differently. Depending on the type of study, some glyphs are more relevant than others. Character glyphs, not graphical ones like lines and bitmapped pictures, should be considered when checking spelling or hyphenation. When designing color separations, we should think on visible glyphs rather than invisible ones. Various analyses will invariably look at different glyphs.
As a result, a given analysis must be able to discern between various glyph types. One apparent solution is to embed the analytical capacity directly into the glyph classes. We can add one or more abstract operations to the Glyph class for each analysis and have subclasses implement them according to their involvement in the analysis.
But the problem with that technique is that whenever we introduce a new type of analysis, we'll have to change every glyph class. In some circumstances, we can make this problem go away: We can provide a default implementation for the abstract operation in the Glyph class if only a few classes participate in the analysis or if most classes do the analysis in the same way. The common case would be covered by the default operation. As a result, alterations would be limited to the Glyph class and its subclasses that differ from the usual.
Encapsulating the Analysis
According to all indicators, we'll need to separate the analysis into its own object, as we've done many times previously. We could separate the analytical mechanism into its own class. An instance of this class could be used in conjunction with an appropriate iterator. Each glyph in the structure would be "carried" by the iterator. At each point in the traversal, the analysis object might conduct a portion of the analysis. As the traversal progresses, the analyzer collects information of interest (in this example, characters):
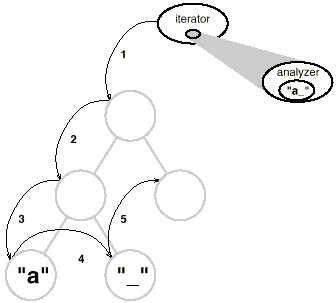
The key question with this method is how the analysis object distinguishes between different types of glyphs without using type checks or downcasts. We don't want a SpellingChecker class to have (false) code like this.
Void SpellingChecker::Check (Glyph* glyph) {
Character* c;
Row* r;
Image* i;
if (c = dynamic_cast<Character*>(glyph)) {
// analyze the character
} else if (r = dynamic_cast<Row*>(glyph)) {
// prepare to analyze r's children
} else if (i = dynamic_cast<Image*>(glyph)) {
// do nothing
}
}
This code is quite unsightly. It makes use of exotic features like type-safe casting. It's also difficult to extend. When the Glyph class hierarchy changes, we'll need to remember to alter the body of this method. In reality, object-oriented languages were designed to eliminate this type of programming.
We wish to avoid using such a forceful approach, but how can we do so? Consider what happens if we extend the Glyph class with the following abstract operation:
Void CheckMe(SpellingChecker&)
CheckMe is defined as follows in every Glyph subclass:
Void GlyphSubclass::CheckMe (SpellingChecker& checker) {
checker.CheckGlyphSubclass(this);
}
Where GlyphSubclass is replaced with the glyph subclass's name. Because we're in one of Glyph's processes, the precise Glyph subclass is known when CheckMe is invoked. For each Glyph subclass, the SpellingChecker class interface includes an operation called CheckGlyphSubclass:
Class SpellingChecker {
public:
SpellingChecker();
virtual void CheckCharacter(Character*);
virtual void CheckRow(Row*);
virtual void CheckImage(Image*);
// ... And so forth
List<char*>& GetMisspellings();
protected:
virtual bool IsMisspelled(const char*);
private:
char _currentWord[MAX_WORD_SIZE];
List<char*> _misspellings;
};
The checking operation for Character glyphs in SpellingChecker could look like this:
Void SpellingChecker::CheckCharacter (Character* c) {
const char ch = c->GetCharCode();
if (isalpha(ch)) {
// append alphabetic character to _currentWord
} else {
// we hit a nonalphabetic character
if (IsMisspelled(_currentWord)) {
// add _currentWord to _misspellings
_misspellings.Append(strdup(_currentWord));
}
_currentWord[0] = '\0';
// reset _currentWord to check next word
}
}
Visitor Class and Subclasses
The term "visitor" will be used to refer to classes of objects that "visit" other objects during a traversal and perform some action. 12 In this situation, a Visitor class can be defined to define an abstract interface for visiting glyphs in a structure.
Class Visitor {
public:
virtual void VisitCharacter(Character*) { }
virtual void VisitRow(Row*) { }
virtual void VisitImage(Image*) { }
// ... And so forth
};
Different Visitor subclasses execute different analyses. For example, a SpellingCheckingVisitor subclass may be used to check spelling, while a HyphenationVisitor subclass could be used to check hyphenation. SpellingCheckingVisitor would be implemented in the same way that SpellingChecker was, with the exception that the operation names would be changed to match the more general Visitor interface. CheckCharacter, for example, would be renamed VisitCharacter.
We'll call it CheckMe instead, because CheckMe isn't acceptable for visitors who don't check anything.
Accept. Its argument must also be changed to take a Visitor, indicating that it can accept any visitor. Now, all we have to do to add a new analysis is define a new subclass of Visitor—we don't have to change any of the glyph classes. By adding this single action to Glyph and its subclasses, we can support all future analysis.
We've already shown how to use spell check. In HyphenationVisitor, we employ a similar strategy to collect text. However, after the Hyphenation Visitors VisitCharacter operation has completed a whole word, it behaves differently. Instead of checking for misspellings, it uses a hyphenation algorithm to assess whether the word has any potential hyphenation points. It then inserts a discretionary glyph into the composition at each hyphenation point. Discretionary glyphs are instances of the Glyph subclass Discretionary.
Depending on whether or not it is the last character on a line, a discretionary glyph can take one of two forms. If it's the last character of a line, the discretionary appears as a hyphen; if it's not the last character of a line, the discretionary has no appearance. The optional checks to determine if it is the last child of its parent (a Row object). When the discretionary is asked to draw or determine its borders, it performs this check. Discretionaries are treated the same as whitespace in the formatting technique, so they can be used to end a line. The diagram below depicts how an embedded discretionary might appear.
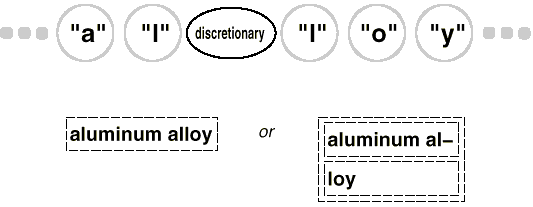
Visitor Pattern
This is an example of how the Visitor pattern can be used. The important actors in the pattern are the Visitor class and its subclasses defined earlier. The Visitor pattern encapsulates the method we used to allow an infinite number of glyph structural analyses without changing the glyph classes themselves. Visitors also have the advantage of being able to be applied to any object structure, not only composites like our glyph structures. Sets, lists, and even directed-acyclic graphs fall into this category. Furthermore, a visitor's classes do not have to be tied to one another through a shared parent class. As a result, visitors can collaborate with people from many walks of life.
Which class hierarchies change the most frequently? This is a crucial question to ask yourself before using the Visitor pattern. When you want to be able to do a variety of various things to objects with a consistent class structure, this pattern is ideal. There is no need to update the class structure when adding a new type of visitor, which is especially significant when the class structure is big. However, if you add a subclass to the structure, you'll need to change all of your visitor interfaces to include a Visit... Operation for that subclass as well. In our example, creating a new Glyph subclass called Foo will necessitate adding a VisitFoo action to Visitor and all of its subclasses.
Q9) Write the features of lexi design pattern?
A9) Lexi's design features eight different patterns:
● The physical structure of the document is represented by a composite.
● Allowing alternative formatting algorithms is a strategy.
● Decorator for adding flair to the user interface.
● Multiple look-and-feel standards are supported by Abstract Factory.
● Multiple windowing platforms can be accessed using a bridge.
● Undoable user operations command.
● Access and traverse object structures with this iterator.
● and Visitor for permitting an unlimited number of analytical capabilities while keeping the document structure simple to deploy.
None of these design flaws are unique to document editing software like Lexi. Indeed, many of these patterns will be used in most nontrivial applications, albeit for different purposes. Composite could be used in a financial analysis programme to define investment portfolios made up of sub portfolios and accounts of various types. The Strategy pattern can be used by a compiler to support alternative register allocation techniques for different target machines. Applications having a graphical user interface, like this one, will very certainly employ Decorator and Command.
Q10) What are the Entities of Service Locator Pattern?
A10) The entities of this design pattern are listed below.
● Service - This is the actual service that will handle the request. A reference to such a service can be found in the JNDI server.
● JNDI Context / Initial Context - The context contains a reference to the service that was utilized for the lookup.
● Service Locator - Using JNDI lookup caching, Service Locator provides a single point of contact for obtaining services.
● Cache - A cache is used to save service references so that they can be reused later.
● Client - The object that uses Service Locator to call the services.




