Unit - 3
Linked List- Linked List as ADT
Q1) What is a single link list?
A1) In programming, it is the most widely used linked list. When we talk about a linked list, we're talking about a singly linked list. The singly linked list is a data structure that is divided into two parts: the data portion and the address part, which contains the address of the next or successor node. A pointer is another name for the address component of a node.
Assume we have three nodes with addresses of 100, 200, and 300, respectively. The following diagram depicts the representation of three nodes as a linked list:
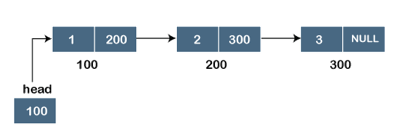
Fig 1: Singly linked list
In the diagram above, we can see three separate nodes with addresses of 100, 200, and 300, respectively. The first node has the address of the next node, which is 200, the second has the address of the last node, which is 300, and the third has the NULL value in its address portion because it does not point to any node. A head pointer is a pointer that stores the address of the first node.
Because there is just one link in the linked list depicted in the figure, it is referred to as a singly linked list. Just forward traversal is permitted in this list; we can't go backwards because there is only one link in the list.
Representation of the node in a singly linked list
Struct node
{
int data;
struct node *next;
}
In the above diagram, we've constructed a user-made structure called a node, which has two members: one is data of integer type, and the other is the node type's pointer (next).
Q2) Write the difference between malloc and calloc?
A2) Difference between malloc() and calloc()
Calloc() | Malloc() |
Calloc() sets the value of the allocated memory to zero. | Malloc() allocates memory and fills it with trash values. |
The total number of arguments is two. | There is just one argument. |
Syntax : (cast_type *)calloc(blocks , size_of_block); | Syntax : (cast_type *)malloc(Size_in_bytes); |
Q3) Define a double linked list?
A3) The doubly linked list, as its name implies, has two pointers. The doubly linked list can be described as a three-part linear data structure: the data component, the address part, and the other two address parts. A doubly linked list, in other terms, is a list with three parts in each node: one data portion, a pointer to the previous node, and a pointer to the next node.
Let's pretend we have three nodes with addresses of 100, 200, and 300, respectively. The representation of these nodes in a doubly-linked list is shown below:
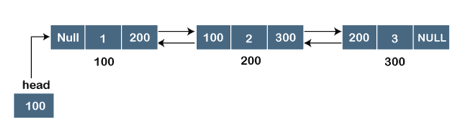
Fig 2: Doubly linked list
The node in a doubly-linked list contains two address portions, as shown in the diagram above; one part keeps the address of the next node, while the other half stores the address of the previous node. The address component of the first node in the doubly linked list is NULL, indicating that the prior node's address is NULL.
Representation of the node in a doubly linked list
Struct node
{
int data;
struct node *next;
Struct node *prev;
}
In the above representation, we've constructed a user-defined structure called a node, which has three members: one is data of integer type, and the other two are pointers of the node type, i.e. next and prev. The address of the next node is stored in the next pointer variable, whereas the address of the previous node is stored in the prev pointer variable. The type of both the pointers, i.e., next and prev is struct node as both the pointers are storing the address of the node of the struct node type.
Q4) Write short notes on a circular link list?
A4) Circular linked list
A singly linked list is a type of circular linked list. The sole difference between a singly linked list and a circular linked list is that the last node in a singly linked list does not point to any other node, therefore its link portion is NULL. The circular linked list, on the other hand, is a list in which the last node connects to the first node, and the address of the first node is stored in the link section of the last node.
There are no nodes at the beginning or finish of the circular linked list. We can travel in either way, backwards or forwards. The following is a diagrammatic illustration of the circular linked list:
Struct node
{
int data;
struct node *next;
}
A circular linked list is a collection of elements in which each node is linked to the next and the last node is linked to the first. The circular linked list will be represented similarly to the singly linked list, as demonstrated below:
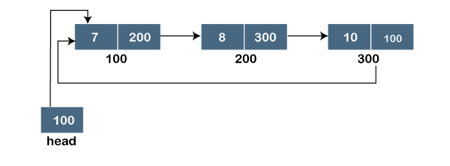
Fig 3: Circular linked list
Q5) Explain insertion operation of linked list?
A5) Insertion
When placing a node into a linked list, there are three possible scenarios:
● Insertion at the beginning
● Insertion at the end. (Append)
● Insertion after a given node
Insertion at the beginning
There's no need to look for the end of the list. If the list is empty, the new node becomes the list's head. Otherwise, we must connect the new node to the existing list's head and make the new node the list's head.
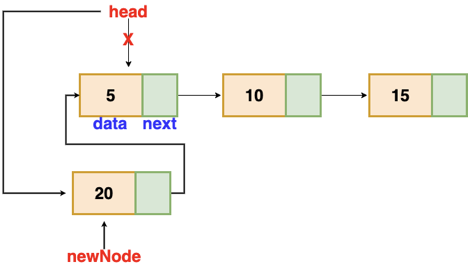
Fig 4: Insertion at beginning
// function is returning the head of the singly linked-list
Node insertAtBegin(Node head, int val)
{
newNode = new Node(val) // creating new node of linked list
if(head == NULL) // check if linked list is empty
return newNode
else // inserting the node at the beginning
{
newNode.next = head
return newNode
}
}
Insertion at the end
We'll go through the list till we reach the last node. The new node is then appended to the end of the list. It's worth noting that there are some exceptions, such as when the list is empty.
We will return the updated head of the linked list if the list is empty, because the inserted node is both the first and end node of the linked list in this case.
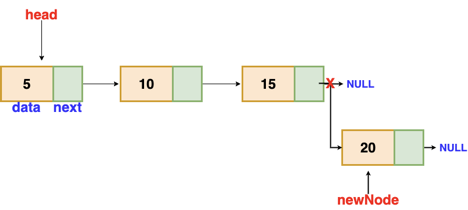
Fig 5: Insertion at end
// the function is returning the head of the singly linked list
Node insertAtEnd(Node head, int val)
{
if( head == NULL ) // handing the special case
{
newNode = new Node(val)
head = newNode
return head
}
Node temp = head
// traversing the list to get the last node
while( temp.next != NULL )
{
temp = temp.next
}
newNode = new Node(val)
temp.next = newNode
return head
}
Insertion after a given node
The reference to a node is passed to us, and the new node is put after it.
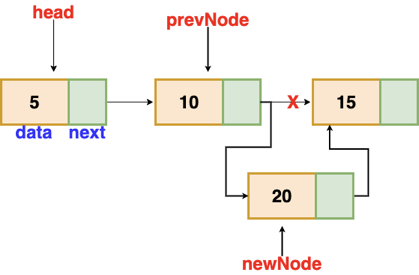
Fig 6: Insertion after given node
Void insertAfter(Node prevNode, int val)
{
newNode = new Node(val)
newNode.next = prevNode.next
prevNode.next = newNode
}
Q6) How deletion operation works on linked list?
A6) Deletion
These are the procedures to delete a node from a linked list.
● Find the previous node of the node to be deleted.
● Change the next pointer of the previous node
● Free the memory of the deleted node.
There is a specific circumstance in which the first node is removed upon deletion. We must update the connected list's head in this case.
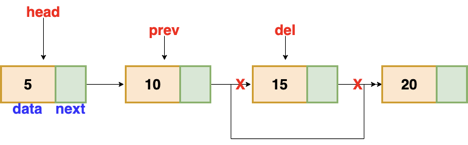
Fig 7: Deleting a node in linked list
// this function will return the head of the linked list
Node deleteLL(Node head, Node del)
{
if(head == del) // if the node to be deleted is the head node
{
return head.next // special case for the first Node
}
Node temp = head
while( temp.next != NULL )
{
if(temp.next == del) // finding the node to be deleted
{
temp.next = temp.next.next
delete del // free the memory of that Node
return head
}
temp = temp.next
}
return head // if no node matches in the Linked List
}
Q7) How to traverse a linked list?
A7) Traversal
The goal is to work your way through the list from start to finish. We might want to print the list or search for a certain node in it, for example.
The traversal algorithm for a list
● Start with the head of the list. Access the content of the head node if it is not null.
● Then go to the next node(if exists) and access the node information
● Continue until no more nodes (that is, you have reached the null node)
Void traverseLL(Node head) {
while(head != NULL)
{
print(head.data)
head = head.next
}
}
Q8) What do you mean by polynomial representation?
A8) Polynomials can be represented in a number of different ways. These are the following:
● By the use of arrays
● By the use of Linked List
Representation of polynomial using Arrays
There may be times when you need to evaluate a large number of polynomial expressions and execute fundamental arithmetic operations on them, such as addition and subtraction. You'll need a mechanism to express the polynomials for this. The simplest method is to express a polynomial of degree 'n' and store the coefficient of the polynomial's n+1 terms in an array. As a result, each array element will have two values:
● Coefficient and
● Exponent
Polynomial of representation using linked lists
An ordered list of non-zero terms can be thought of as a polynomial. Each non-zero word is a two-tuple, containing two pieces of data:
● The exponent part
● The coefficient part
Multiplication
To multiply two polynomials, multiply the terms of one polynomial by the terms of the other polynomial. Assume the two polynomials have n and m terms respectively. A polynomial with n times m terms will be created as a result of this method.
For example, we can construct a linked list by multiplying 2 – 4x + 5x2 and 1 + 2x – 3x3:

All of the terms we'll need to get the final outcome are in this linked list. The powers, on the other hand, do not sort it. It also has duplicate nodes with similar terms. We can merge sort the linked list depending on each node's power to get the final linked list:
After sorting, the nodes with similar terms are clustered together. Then, for the final multiplication result, we can combine each set of like terms:

Code for Polynomial addition, subtraction and multiplication in C
#include<stdio.h>
#include<conio.h>
#include "poly.h"void main()
{
clrscr();
Polynomial *p1,*p2,*sum,*sub,*mul;
printf("\nENTER THE FIRST POLYNOMIAL.");
p1=createPolynomial();
printf("\nENTER THE SECOND POLYNOMIAL.");
p2=createPolynomial();
clrscr();
printf("\nFIRST : ");
displayPolynomial(p1);
printf("\nSECOND : ");
displayPolynomial(p2);
printf("\n\nADDITION IS : ");
sum=addPolynomial(p1,p2);
displayPolynomial(sum);
printf("\n\nSUBTRACTION IS : ");
sub=subPolynomial(p1,p2);
displayPolynomial(sub);
printf("\n\nMULTIPLICATION IS : ");
mul=mulPolynomial(p1,p2);
displayPolynomial(mul);
getch();
}
Q9) Introduce trees?
A9) Trees
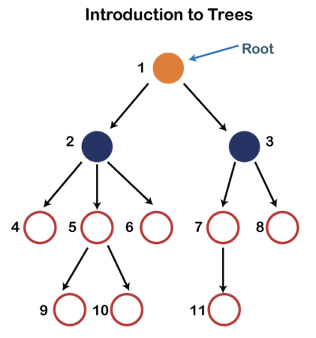
Fig 8: Tree
Each node in the above structure is labeled with a number. Each arrow in the diagram above represents a link between the two nodes.
Root - In a tree hierarchy, the root node is the highest node. To put it another way, the root node is the one that has no children. The root node of the tree is numbered 1 in the above structure. A parent-child relationship exists when one node is directly linked to another node.
Child node - If a node is a descendant of another node, it is referred to as a child node.
Parent - If a node has a sub-node, the parent of that sub-node is said to be that node.
Sibling - Sibling nodes are those that have the same parent.
Leaf node - A leaf node is a node in the tree that does not have any descendant nodes. A leaf node is the tree's bottommost node. In a generic tree, there can be any number of leaf nodes. External nodes are also known as leaf nodes.
Internal node - An internal node is a node that has at least one child node.
Ancestor node - Any previous node on a path from the root to that node is an ancestor of that node. There are no ancestors for the root node. Nodes 1, 2, and 5 are the ancestors of node 10 in the tree depicted above.
Descendant node - A descendant of a node is the direct successor of the supplied node. In the diagram above, node 10 is a descendent of node 5.
Q10) Explain tree traversal?
A10) Traversal is a process to visit all the nodes of a tree and may print their values too. Because all nodes are connected via edges (links) we always start from the root (head) node. That is, we cannot randomly access a node in a tree. There are three ways which we use to traverse a tree −
● In-order Traversal
● Pre-order Traversal
● Post-order Traversal
Generally, we traverse a tree to search or locate a given item or key in the tree or to print all the values it contains.
In-order Traversal
In this traversal method, the left subtree is visited first, then the root and later the right subtree. We should always remember that every node may represent a subtree itself.
If a binary tree is traversed in-order, the output will produce sorted key values in an ascending order.
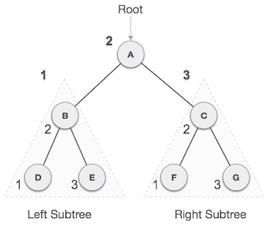
Fig 9: Inorder
We start from A, and following in-order traversal, we move to its left subtree B. B is also traversed in-order. The process goes on until all the nodes are visited. The output of inorder traversal of this tree will be −
D → B → E → A → F → C → G
Algorithm
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Visit root node.
Step 3 − Recursively traverse right subtree.
Pre-order Traversal
In this traversal method, the root node is visited first, then the left subtree and finally the right subtree.
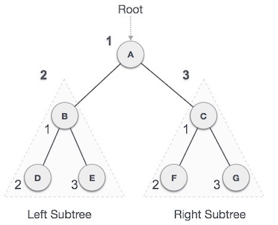
Fig 10: Pre order
We start from A, and following pre-order traversal, we first visit A itself and then move to its left subtree B. B is also traversed pre-order. The process goes on until all the nodes are visited. The output of pre-order traversal of this tree will be −
A → B → D → E → C → F → G
Algorithm
Until all nodes are traversed −
Step 1 − Visit root node.
Step 2 − Recursively traverse left subtree.
Step 3 − Recursively traverse right subtree.
Post-order Traversal
In this traversal method, the root node is visited last, hence the name. First we traverse the left subtree, then the right subtree and finally the root node.
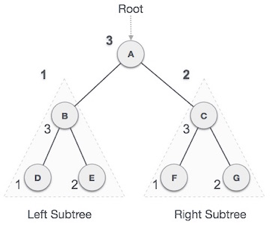
Fig 11: Post order
We start from A, and following Post-order traversal, we first visit the left subtree B. B is also traversed post-order. The process goes on until all the nodes are visited. The output of post-order traversal of this tree will be −
D → E → B → F → G → C → A
Algorithm
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Recursively traverse right subtree.
Step 3 − Visit root node.
Q11) Describe binary tree?
A11) The Binary tree means that the node can have a maximum of two children. Here, the binary name itself suggests 'two'; therefore, each node can have either 0, 1 or 2 children.
Let's understand the binary tree through an example.
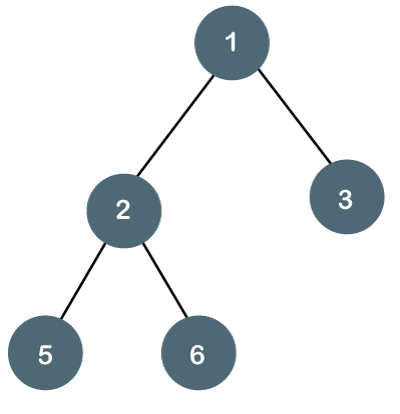
Fig 12: Example
The above tree is a binary tree because each node contains the utmost two children. The logical representation of the above tree is given below:
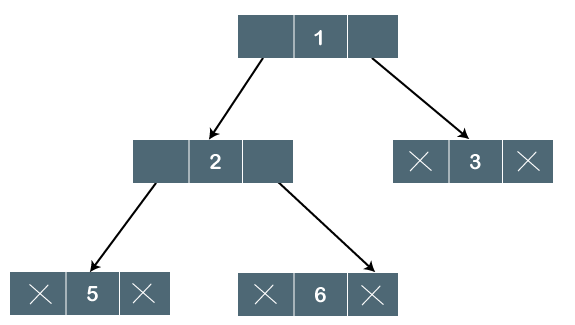
Fig 13: Logical representation
In the above tree, node 1 contains two pointers, i.e., left and a right pointer pointing to the left and right node respectively. The node 2 contains both the nodes (left and right node); therefore, it has two pointers (left and right). The nodes 3, 5 and 6 are the leaf nodes, so all these nodes contain NULL pointer on both left and right parts.
If there are 'n' number of nodes in the binary tree.
The minimum height can be computed as:
As we know that,
n = 2h+1 -1
n+1 = 2h+1
Taking log on both the sides,
Log2(n+1) = log2(2h+1)
Log2(n+1) = h+1
h = log2(n+1) - 1
The maximum height can be computed as:
As we know that,
n = h+1
h= n-1
Types of Binary Tree
There are four types of Binary tree:
● Full/ proper/ strict Binary tree
● Complete Binary tree
● Perfect Binary tree
● Degenerate Binary tree
● Balanced Binary tree
Q12) Write the properties of binary trees?
A12) Properties of Binary Tree
● At each level of i, the maximum number of nodes is 2i.
● The height of the tree is defined as the longest path from the root node to the leaf node. The tree which is shown above has a height equal to 3. Therefore, the maximum number of nodes at height 3 is equal to (1+2+4+8) = 15. In general, the maximum number of nodes possible at height h is (20 + 21 + 22+….2h) = 2h+1 -1.
● The minimum number of nodes possible at height h is equal to h+1.
● If the number of nodes is minimum, then the height of the tree would be maximum. Conversely, if the number of nodes is maximum, then the height of the tree would be minimum.
Q13) What is BST?
A13) A binary search tree is a type of binary tree in which the nodes are organized in a predetermined sequence. This is referred to as an ordered binary tree.
The value of all nodes in the left sub-tree is less than the value of the root in a binary search tree. Similarly, the value of all nodes in the right subtree is larger than or equal to the root's value. This rule will be applied recursively to all of the root's left and right subtrees.
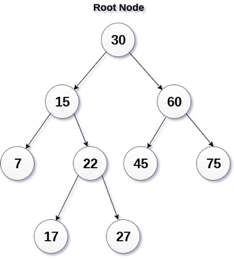
Fig 14: Binary search tree
A Binary Search Tree (BST) is a tree in which all nodes have the properties listed below.
● The key of the left subtree has a lower value than the key of its parent (root) node.
● The value of the right subkey tree's is larger than or equal to the value of the key of its parent (root) node.
● As a result, BST separates all of its sub-trees into two segments: the left and right subtrees, and can be characterized as
Left_subtree (keys) < node (key) ≤ right_subtree (keys)
Q14) What is insertion in BST?
A14) Insertion
The insertion operation in a binary search tree takes O(log n) time to complete. A new node is always added as a leaf node in a binary search tree. The following is how the insertion procedure is carried out...
Step 1: Create a newNode with the specified value and NULL left and right.
Step 2: Make sure the tree isn't empty.
Step 3 - Set root to newNode if the tree is empty.
Step 4 - If the tree isn't empty, see if newNode's value is smaller or larger than the node's value (here it is root node).
Step 5 - Go to the node's left child if newNode is smaller or equal to it. Move to new Nodes right child if the newNode is larger than the node.
Step 6- Continue in this manner until we reach the leaf node (i.e., reaches to NULL).
Step 7 - Once you've reached the leaf node, insert the newNode as a left child if it's smaller or equal to the leaf node, or as a right child otherwise.
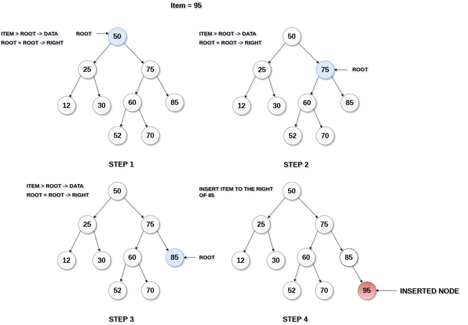
Fig 15: Example of insertion
Q15) Create a Binary Search Tree by adding the integers in the following order… 10,12,5,4,20,8,7,15 and 13?
A15) The following items are added into a Binary Search Tree in the following order...
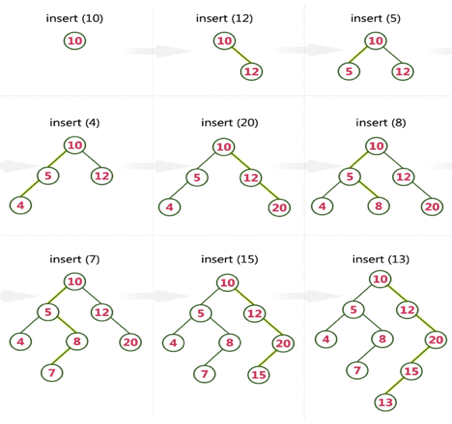
Q16) Define expression tree?
A16) Expression trees are one of the most effective methods for representing language-level code as data stored in a tree-like structure. An expression tree is a representation of a lambda expression in memory. The tree clarifies and transparentes the structure holding the lambda expression. The expression tree was designed to turn code into strings that may be supplied as inputs to other processes. It contains the query's actual elements, rather than the query's actual result.
One of the most essential characteristics of expression trees is that they are immutable, which means that altering an existing expression tree requires creating a new expression tree by copying and updating the existing tree expression. In programming, an expression tree is commonly constructed using postfix expressions, which read one symbol at a time. A one-node tree is formed and a pointer to it is pushed into a stack if the symbol is an operand.
The expression tree is a type of tree that is used to represent different types of expressions. The expressional assertions are represented using a tree data structure. The operators are always represented by the internal node in this tree.
● The operands are always denoted by the leaf nodes.
● These operands are always used in the operations.
● The operator in the deepest part of the tree is always given priority.
● The operator who is not very deep in the tree is always given the lowest priority compared to the operators who are very deep in the tree.
● The operand will always be present at a depth of the tree, making it the most important of all the operators.
● In summary, as compared to the other operators at the top of the tree, the value existing at a depth of the tree has the most importance.
● These expression trees are primarily used to assess, analyse, and modify a variety of expressions.
● It's also utilised to determine each operator's associativity in the phrase.
● The + operator, for example, is left-associative, while the / operator is right-associative.
● Using expression trees, the conundrum of this associativity has been solved.
● A context-free grammar is used to create these expression trees.
● In context-free grammars, we've put a rule in front of each grammar production.
● These rules are also known as semantic rules, and we can easily design expression trees using these semantic rules.
● It is part of the semantic analysis process and is one of the most important aspects of compiler design.
● We will employ syntax-directed translations in our semantic analysis, and we will create an annotated parse tree as output.
● The basic parse associated with the type property and each production rule makes up an annotated parse tree.
● The fundamental goal of using expression trees is to create complex expressions that can be easily evaluated using these trees.
● It's immutable, which means that once we've generated an expression tree, we can't change or modify it.
● It is necessary to completely construct the new expression tree in order to make more changes.
● It's also used to evaluate expressions with postfixes, prefixes, and infixes.
Expression trees are extremely useful for encoding language-level code in the form of data, which is mostly kept in a tree-like structure. It's also used in the lambda expression's memory representation. We can represent the lambda expression more openly and explicitly using the tree data structure. It is first constructed to transform the code segment to the data segment, allowing the expression to be evaluated quickly.
The expression tree is a binary tree in which the operand is represented by the exterior or leaf node and the operators are represented by the internal or parent node. For example, the expression tree for 7 + ((1+8)*3) would be:
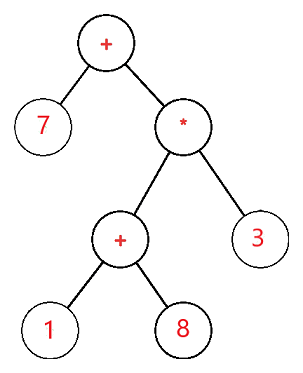
Q17) Write the use of expression tree?
A17) Use of Expression tree
● The fundamental goal of using expression trees is to create complex expressions that can be easily evaluated using these trees.
● It's also used to determine each operator's associativity in the phrase.
● It's also used to evaluate expressions with postfixes, prefixes, and infixes.
Q18) Describe AVL tree?
A18) AVL Tree was invented by GM Adelson - Velsky and EM Landis in 1962. The tree is named AVL in honor of its inventors.
AVL Tree can be defined as a height balanced binary search tree in which each node is associated with a balance factor which is calculated by subtracting the height of its right subtree from that of its left sub-tree.
Tree is said to be balanced if the balance factor of each node is in between -1 to 1, otherwise, the tree will be unbalanced and need to be balanced.
Balance Factor (k) = height (left(k)) - height (right(k))
If balance factor of any node is 1, it means that the left sub-tree is one level higher than the right subtree.
If balance factor of any node is 0, it means that the left subtree and right subtree contain equal height.
If balance factor of any node is -1, it means that the left sub-tree is one level lower than the right subtree.
An AVL tree is given in the following figure. We can see that, balance factor associated with each node is in between -1 and +1. Therefore, it is an example of AVL tree.
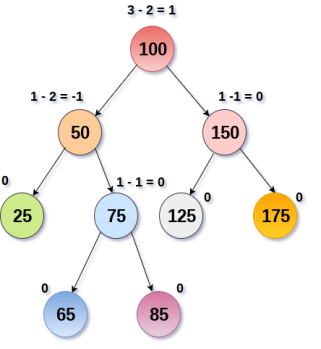
Fig 16 – AVL Tree
Complexity
Algorithm | Average case | Worst case |
Space | o(n) | o(n) |
Search | o(log n) | o(log n) |
Insert | o(log n) | o(log n) |
Delete | o(log n) | o(log n) |
Q19) Describe a heap tree?
A19) A binary heap is a data structure that resembles a complete binary tree in appearance. The ordering features of the heap data structure are explained here. A Heap is often represented by an array. We'll use H to represent a heap.
Because the elements of a heap are kept in an array, the position of the parent node of the ith element can be located at i/2 if the starting index is 1. Position 2i and 2i + 1 are the left and right children of the ith node, respectively.
Based on the ordering property, a binary heap can be classed as a max-heap or a min-heap.
Max Heap
A node's key value is larger than or equal to the key value of the highest child in this heap.
Hence, H[Parent(i)] ≥ H[i]

Fig 17: Max heap
Max Heap Construction Algorithm
The technique for creating Min Heap is similar to that for creating Max Heap, only we use min values instead of max values.
By inserting one element at a time, we will derive a method for max heap. The property of a heap must be maintained at all times. We also presume that we are inserting a node into an already heapify tree while inserting.
● Step 1: Make a new node at the bottom of the heap.
● Step 2: Give the node a new value.
● Step 3: Compare this child node's value to that of its parent.
● Step 4: If the parent's value is smaller than the child's, swap them.
● Step 5: Repeat steps 3 and 4 until the Heap property is maintained.
Min Heap
In mean-heap, a node's key value is less than or equal to the lowest child's key value.
Hence, H[Parent(i)] ≤ H[i]
Basic operations with respect to Max-Heap are shown below in this context. The insertion and deletion of elements in and out of heaps necessitates element reordering. As a result, the Heapify function must be used.
Fig 18: Min heap
Max Heap Deletion Algorithm
Let's create an algorithm for deleting from the maximum heap. The root of the Max (or Min) Heap is always deleted to remove the maximum (or minimum) value.
● Step 1: Remove the root node first.
● Step 2: Move the last element from the previous level to the root.
● Step 3: Compare this child node's value to that of its parent.
● Step 4: If the parent's value is smaller than the child's, swap them.
● Step 5: Repeat steps 3 and 4 until the Heap property is maintained.
Q20) Explain AVL rotations?
A20) AVL Rotations
We perform rotation in AVL tree only in case if Balance Factor is other than -1, 0, and 1. There are basically four types of rotations which are as follows:
- L L rotation: Inserted node is in the left subtree of left subtree of A
- R R rotation: Inserted node is in the right subtree of right subtree of A
- L R rotation: Inserted node is in the right subtree of left subtree of A
- R L rotation: Inserted node is in the left subtree of right subtree of A
Where node A is the node whose balance Factor is other than -1, 0, 1.
The first two rotations LL and RR are single rotations and the next two rotations LR and RL are double rotations. For a tree to be unbalanced, minimum height must be at least 2.
Let us understand each rotation
1. RR Rotation
When BST becomes unbalanced, due to a node is inserted into the right subtree of the right subtree of A, then we perform RR rotation, RR rotation is an anticlockwise rotation, which is applied on the edge below a node having balance factor -2
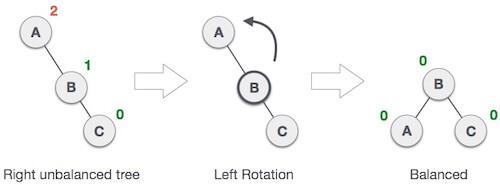
In above example, node A has balance factor -2 because a node C is inserted in the right subtree of A right subtree. We perform the RR rotation on the edge below A.
2. LL Rotation
When BST becomes unbalanced, due to a node is inserted into the left subtree of the left subtree of C, then we perform LL rotation, LL rotation is clockwise rotation, which is applied on the edge below a node having balance factor 2.
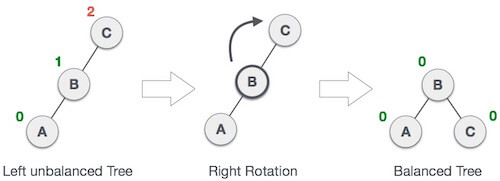
In above example, node C has balance factor 2 because a node A is inserted in the left subtree of C left subtree. We perform the LL rotation on the edge below A.
3. LR Rotation
Double rotations are bit tougher than single rotation which has already explained above. LR rotation = RR rotation + LL rotation, i.e., first RR rotation is performed on subtree and then LL rotation is performed on full tree, by full tree we mean the first node from the path of inserted node whose balance factor is other than -1, 0, or 1.
Let us understand each and every step very clearly:
State | Action |
 | A node B has been inserted into the right subtree of A the left subtree of C, because of which C has become an unbalanced node having balance factor 2. This case is L R rotation where: Inserted node is in the right subtree of left subtree of C |
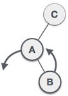 | As LR rotation = RR + LL rotation, hence RR (anticlockwise) on subtree rooted at A is performed first. By doing RR rotation, node A, has become the left subtree of B. |
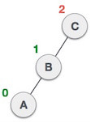 | After performing RR rotation, node C is still unbalanced, i.e., having balance factor 2, as inserted node A is in the left of left of C |
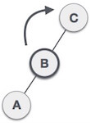 | Now we perform LL clockwise rotation on full tree, i.e. on node C. Node C has now become the right subtree of node B, A is left subtree of B |
 | Balance factor of each node is now either -1, 0, or 1, i.e. BST is balanced now. |
4. RL Rotation
As already discussed, that double rotations are bit tougher than single rotation which has already explained above. R L rotation = LL rotation + RR rotation, i.e., first LL rotation is performed on subtree and then RR rotation is performed on full tree, by full tree we mean the first node from the path of inserted node whose balance factor is other than -1, 0, or 1.
State | Action |
 | A node B has been inserted into the left subtree of C the right subtree of A, because of which A has become an unbalanced node having balance factor - 2. This case is RL rotation where: Inserted node is in the left subtree of right subtree of A |
 | As RL rotation = LL rotation + RR rotation, hence, LL (clockwise) on subtree rooted at C is performed first. By doing RR rotation, node C has become the right subtree of B. |
 | After performing LL rotation, node A is still unbalanced, i.e. having balance factor -2, which is because of the right-subtree of the right-subtree node A. |
 | Now we perform RR rotation (anticlockwise rotation) on full tree, i.e. on node A. Node C has now become the right subtree of node B, and node A has become the left subtree of B. |
 | Balance factor of each node is now either -1, 0, or 1, i.e., BST is balanced now. |
Unit - 3
Linked List- Linked List as ADT
Q1) What is a single link list?
A1) In programming, it is the most widely used linked list. When we talk about a linked list, we're talking about a singly linked list. The singly linked list is a data structure that is divided into two parts: the data portion and the address part, which contains the address of the next or successor node. A pointer is another name for the address component of a node.
Assume we have three nodes with addresses of 100, 200, and 300, respectively. The following diagram depicts the representation of three nodes as a linked list:
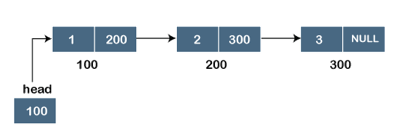
Fig 1: Singly linked list
In the diagram above, we can see three separate nodes with addresses of 100, 200, and 300, respectively. The first node has the address of the next node, which is 200, the second has the address of the last node, which is 300, and the third has the NULL value in its address portion because it does not point to any node. A head pointer is a pointer that stores the address of the first node.
Because there is just one link in the linked list depicted in the figure, it is referred to as a singly linked list. Just forward traversal is permitted in this list; we can't go backwards because there is only one link in the list.
Representation of the node in a singly linked list
Struct node
{
int data;
struct node *next;
}
In the above diagram, we've constructed a user-made structure called a node, which has two members: one is data of integer type, and the other is the node type's pointer (next).
Q2) Write the difference between malloc and calloc?
A2) Difference between malloc() and calloc()
Calloc() | Malloc() |
Calloc() sets the value of the allocated memory to zero. | Malloc() allocates memory and fills it with trash values. |
The total number of arguments is two. | There is just one argument. |
Syntax : (cast_type *)calloc(blocks , size_of_block); | Syntax : (cast_type *)malloc(Size_in_bytes); |
Q3) Define a double linked list?
A3) The doubly linked list, as its name implies, has two pointers. The doubly linked list can be described as a three-part linear data structure: the data component, the address part, and the other two address parts. A doubly linked list, in other terms, is a list with three parts in each node: one data portion, a pointer to the previous node, and a pointer to the next node.
Let's pretend we have three nodes with addresses of 100, 200, and 300, respectively. The representation of these nodes in a doubly-linked list is shown below:
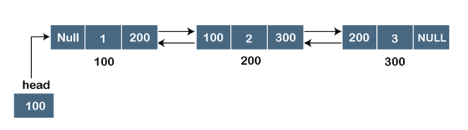
Fig 2: Doubly linked list
The node in a doubly-linked list contains two address portions, as shown in the diagram above; one part keeps the address of the next node, while the other half stores the address of the previous node. The address component of the first node in the doubly linked list is NULL, indicating that the prior node's address is NULL.
Representation of the node in a doubly linked list
Struct node
{
int data;
struct node *next;
Struct node *prev;
}
In the above representation, we've constructed a user-defined structure called a node, which has three members: one is data of integer type, and the other two are pointers of the node type, i.e. next and prev. The address of the next node is stored in the next pointer variable, whereas the address of the previous node is stored in the prev pointer variable. The type of both the pointers, i.e., next and prev is struct node as both the pointers are storing the address of the node of the struct node type.
Q4) Write short notes on a circular link list?
A4) Circular linked list
A singly linked list is a type of circular linked list. The sole difference between a singly linked list and a circular linked list is that the last node in a singly linked list does not point to any other node, therefore its link portion is NULL. The circular linked list, on the other hand, is a list in which the last node connects to the first node, and the address of the first node is stored in the link section of the last node.
There are no nodes at the beginning or finish of the circular linked list. We can travel in either way, backwards or forwards. The following is a diagrammatic illustration of the circular linked list:
Struct node
{
int data;
struct node *next;
}
A circular linked list is a collection of elements in which each node is linked to the next and the last node is linked to the first. The circular linked list will be represented similarly to the singly linked list, as demonstrated below:
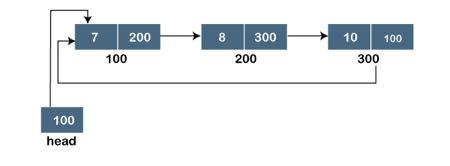
Fig 3: Circular linked list
Q5) Explain insertion operation of linked list?
A5) Insertion
When placing a node into a linked list, there are three possible scenarios:
● Insertion at the beginning
● Insertion at the end. (Append)
● Insertion after a given node
Insertion at the beginning
There's no need to look for the end of the list. If the list is empty, the new node becomes the list's head. Otherwise, we must connect the new node to the existing list's head and make the new node the list's head.
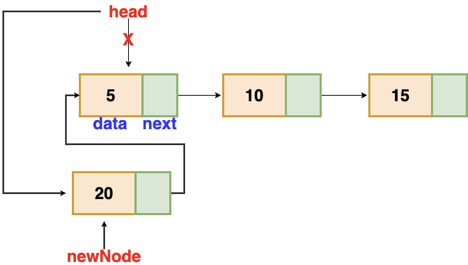
Fig 4: Insertion at beginning
// function is returning the head of the singly linked-list
Node insertAtBegin(Node head, int val)
{
newNode = new Node(val) // creating new node of linked list
if(head == NULL) // check if linked list is empty
return newNode
else // inserting the node at the beginning
{
newNode.next = head
return newNode
}
}
Insertion at the end
We'll go through the list till we reach the last node. The new node is then appended to the end of the list. It's worth noting that there are some exceptions, such as when the list is empty.
We will return the updated head of the linked list if the list is empty, because the inserted node is both the first and end node of the linked list in this case.
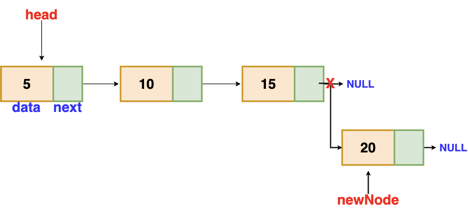
Fig 5: Insertion at end
// the function is returning the head of the singly linked list
Node insertAtEnd(Node head, int val)
{
if( head == NULL ) // handing the special case
{
newNode = new Node(val)
head = newNode
return head
}
Node temp = head
// traversing the list to get the last node
while( temp.next != NULL )
{
temp = temp.next
}
newNode = new Node(val)
temp.next = newNode
return head
}
Insertion after a given node
The reference to a node is passed to us, and the new node is put after it.
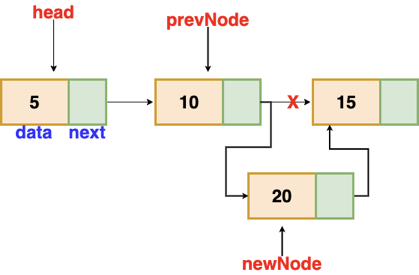
Fig 6: Insertion after given node
Void insertAfter(Node prevNode, int val)
{
newNode = new Node(val)
newNode.next = prevNode.next
prevNode.next = newNode
}
Q6) How deletion operation works on linked list?
A6) Deletion
These are the procedures to delete a node from a linked list.
● Find the previous node of the node to be deleted.
● Change the next pointer of the previous node
● Free the memory of the deleted node.
There is a specific circumstance in which the first node is removed upon deletion. We must update the connected list's head in this case.
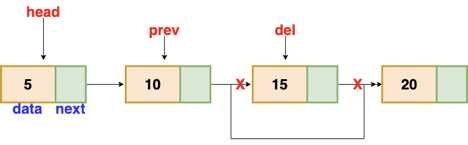
Fig 7: Deleting a node in linked list
// this function will return the head of the linked list
Node deleteLL(Node head, Node del)
{
if(head == del) // if the node to be deleted is the head node
{
return head.next // special case for the first Node
}
Node temp = head
while( temp.next != NULL )
{
if(temp.next == del) // finding the node to be deleted
{
temp.next = temp.next.next
delete del // free the memory of that Node
return head
}
temp = temp.next
}
return head // if no node matches in the Linked List
}
Q7) How to traverse a linked list?
A7) Traversal
The goal is to work your way through the list from start to finish. We might want to print the list or search for a certain node in it, for example.
The traversal algorithm for a list
● Start with the head of the list. Access the content of the head node if it is not null.
● Then go to the next node(if exists) and access the node information
● Continue until no more nodes (that is, you have reached the null node)
Void traverseLL(Node head) {
while(head != NULL)
{
print(head.data)
head = head.next
}
}
Q8) What do you mean by polynomial representation?
A8) Polynomials can be represented in a number of different ways. These are the following:
● By the use of arrays
● By the use of Linked List
Representation of polynomial using Arrays
There may be times when you need to evaluate a large number of polynomial expressions and execute fundamental arithmetic operations on them, such as addition and subtraction. You'll need a mechanism to express the polynomials for this. The simplest method is to express a polynomial of degree 'n' and store the coefficient of the polynomial's n+1 terms in an array. As a result, each array element will have two values:
● Coefficient and
● Exponent
Polynomial of representation using linked lists
An ordered list of non-zero terms can be thought of as a polynomial. Each non-zero word is a two-tuple, containing two pieces of data:
● The exponent part
● The coefficient part
Multiplication
To multiply two polynomials, multiply the terms of one polynomial by the terms of the other polynomial. Assume the two polynomials have n and m terms respectively. A polynomial with n times m terms will be created as a result of this method.
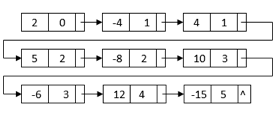
For example, we can construct a linked list by multiplying 2 – 4x + 5x2 and 1 + 2x – 3x3:
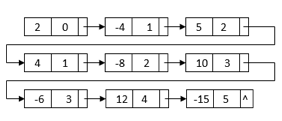
All of the terms we'll need to get the final outcome are in this linked list. The powers, on the other hand, do not sort it. It also has duplicate nodes with similar terms. We can merge sort the linked list depending on each node's power to get the final linked list:
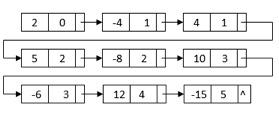
After sorting, the nodes with similar terms are clustered together. Then, for the final multiplication result, we can combine each set of like terms:

Code for Polynomial addition, subtraction and multiplication in C
#include<stdio.h>
#include<conio.h>
#include "poly.h"void main()
{
clrscr();
Polynomial *p1,*p2,*sum,*sub,*mul;
printf("\nENTER THE FIRST POLYNOMIAL.");
p1=createPolynomial();
printf("\nENTER THE SECOND POLYNOMIAL.");
p2=createPolynomial();
clrscr();
printf("\nFIRST : ");
displayPolynomial(p1);
printf("\nSECOND : ");
displayPolynomial(p2);
printf("\n\nADDITION IS : ");
sum=addPolynomial(p1,p2);
displayPolynomial(sum);
printf("\n\nSUBTRACTION IS : ");
sub=subPolynomial(p1,p2);
displayPolynomial(sub);
printf("\n\nMULTIPLICATION IS : ");
mul=mulPolynomial(p1,p2);
displayPolynomial(mul);
getch();
}
Q9) Introduce trees?
A9) Trees
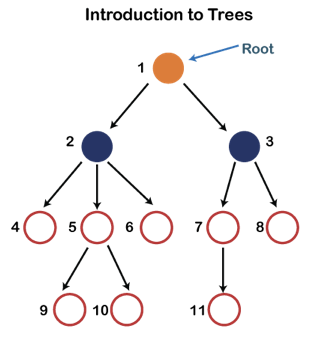
Fig 8: Tree
Each node in the above structure is labeled with a number. Each arrow in the diagram above represents a link between the two nodes.
Root - In a tree hierarchy, the root node is the highest node. To put it another way, the root node is the one that has no children. The root node of the tree is numbered 1 in the above structure. A parent-child relationship exists when one node is directly linked to another node.
Child node - If a node is a descendant of another node, it is referred to as a child node.
Parent - If a node has a sub-node, the parent of that sub-node is said to be that node.
Sibling - Sibling nodes are those that have the same parent.
Leaf node - A leaf node is a node in the tree that does not have any descendant nodes. A leaf node is the tree's bottommost node. In a generic tree, there can be any number of leaf nodes. External nodes are also known as leaf nodes.
Internal node - An internal node is a node that has at least one child node.
Ancestor node - Any previous node on a path from the root to that node is an ancestor of that node. There are no ancestors for the root node. Nodes 1, 2, and 5 are the ancestors of node 10 in the tree depicted above.
Descendant node - A descendant of a node is the direct successor of the supplied node. In the diagram above, node 10 is a descendent of node 5.
Q10) Explain tree traversal?
A10) Traversal is a process to visit all the nodes of a tree and may print their values too. Because all nodes are connected via edges (links) we always start from the root (head) node. That is, we cannot randomly access a node in a tree. There are three ways which we use to traverse a tree −
● In-order Traversal
● Pre-order Traversal
● Post-order Traversal
Generally, we traverse a tree to search or locate a given item or key in the tree or to print all the values it contains.
In-order Traversal
In this traversal method, the left subtree is visited first, then the root and later the right subtree. We should always remember that every node may represent a subtree itself.
If a binary tree is traversed in-order, the output will produce sorted key values in an ascending order.
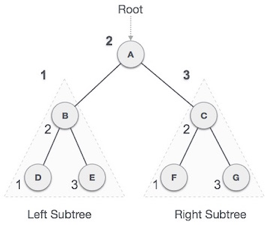
Fig 9: Inorder
We start from A, and following in-order traversal, we move to its left subtree B. B is also traversed in-order. The process goes on until all the nodes are visited. The output of inorder traversal of this tree will be −
D → B → E → A → F → C → G
Algorithm
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Visit root node.
Step 3 − Recursively traverse right subtree.
Pre-order Traversal
In this traversal method, the root node is visited first, then the left subtree and finally the right subtree.
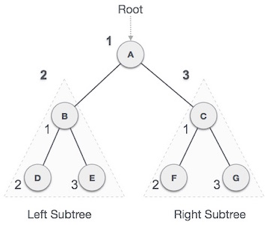
Fig 10: Pre order
We start from A, and following pre-order traversal, we first visit A itself and then move to its left subtree B. B is also traversed pre-order. The process goes on until all the nodes are visited. The output of pre-order traversal of this tree will be −
A → B → D → E → C → F → G
Algorithm
Until all nodes are traversed −
Step 1 − Visit root node.
Step 2 − Recursively traverse left subtree.
Step 3 − Recursively traverse right subtree.
Post-order Traversal
In this traversal method, the root node is visited last, hence the name. First we traverse the left subtree, then the right subtree and finally the root node.
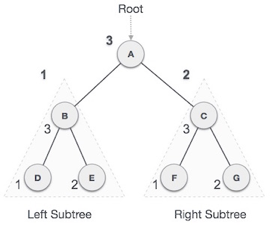
Fig 11: Post order
We start from A, and following Post-order traversal, we first visit the left subtree B. B is also traversed post-order. The process goes on until all the nodes are visited. The output of post-order traversal of this tree will be −
D → E → B → F → G → C → A
Algorithm
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Recursively traverse right subtree.
Step 3 − Visit root node.
Q11) Describe binary tree?
A11) The Binary tree means that the node can have a maximum of two children. Here, the binary name itself suggests 'two'; therefore, each node can have either 0, 1 or 2 children.
Let's understand the binary tree through an example.
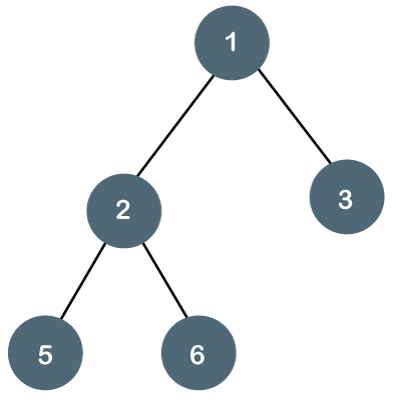
Fig 12: Example
The above tree is a binary tree because each node contains the utmost two children. The logical representation of the above tree is given below:
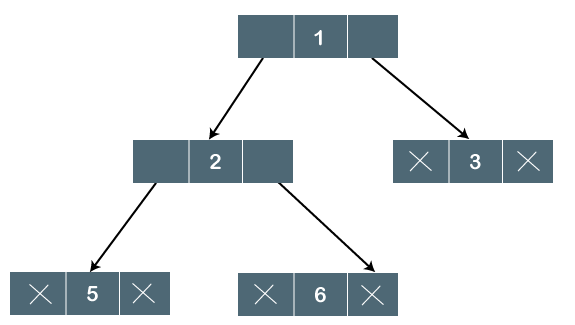
Fig 13: Logical representation
In the above tree, node 1 contains two pointers, i.e., left and a right pointer pointing to the left and right node respectively. The node 2 contains both the nodes (left and right node); therefore, it has two pointers (left and right). The nodes 3, 5 and 6 are the leaf nodes, so all these nodes contain NULL pointer on both left and right parts.
If there are 'n' number of nodes in the binary tree.
The minimum height can be computed as:
As we know that,
n = 2h+1 -1
n+1 = 2h+1
Taking log on both the sides,
Log2(n+1) = log2(2h+1)
Log2(n+1) = h+1
h = log2(n+1) - 1
The maximum height can be computed as:
As we know that,
n = h+1
h= n-1
Types of Binary Tree
There are four types of Binary tree:
● Full/ proper/ strict Binary tree
● Complete Binary tree
● Perfect Binary tree
● Degenerate Binary tree
● Balanced Binary tree
Q12) Write the properties of binary trees?
A12) Properties of Binary Tree
● At each level of i, the maximum number of nodes is 2i.
● The height of the tree is defined as the longest path from the root node to the leaf node. The tree which is shown above has a height equal to 3. Therefore, the maximum number of nodes at height 3 is equal to (1+2+4+8) = 15. In general, the maximum number of nodes possible at height h is (20 + 21 + 22+….2h) = 2h+1 -1.
● The minimum number of nodes possible at height h is equal to h+1.
● If the number of nodes is minimum, then the height of the tree would be maximum. Conversely, if the number of nodes is maximum, then the height of the tree would be minimum.
Q13) What is BST?
A13) A binary search tree is a type of binary tree in which the nodes are organized in a predetermined sequence. This is referred to as an ordered binary tree.
The value of all nodes in the left sub-tree is less than the value of the root in a binary search tree. Similarly, the value of all nodes in the right subtree is larger than or equal to the root's value. This rule will be applied recursively to all of the root's left and right subtrees.
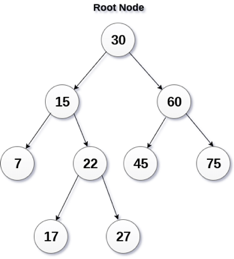
Fig 14: Binary search tree
A Binary Search Tree (BST) is a tree in which all nodes have the properties listed below.
● The key of the left subtree has a lower value than the key of its parent (root) node.
● The value of the right subkey tree's is larger than or equal to the value of the key of its parent (root) node.
● As a result, BST separates all of its sub-trees into two segments: the left and right subtrees, and can be characterized as
Left_subtree (keys) < node (key) ≤ right_subtree (keys)
Q14) What is insertion in BST?
A14) Insertion
The insertion operation in a binary search tree takes O(log n) time to complete. A new node is always added as a leaf node in a binary search tree. The following is how the insertion procedure is carried out...
Step 1: Create a newNode with the specified value and NULL left and right.
Step 2: Make sure the tree isn't empty.
Step 3 - Set root to newNode if the tree is empty.
Step 4 - If the tree isn't empty, see if newNode's value is smaller or larger than the node's value (here it is root node).
Step 5 - Go to the node's left child if newNode is smaller or equal to it. Move to new Nodes right child if the newNode is larger than the node.
Step 6- Continue in this manner until we reach the leaf node (i.e., reaches to NULL).
Step 7 - Once you've reached the leaf node, insert the newNode as a left child if it's smaller or equal to the leaf node, or as a right child otherwise.
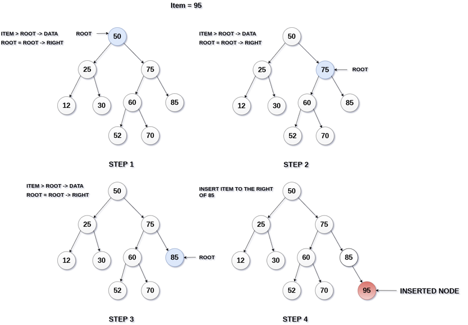
Fig 15: Example of insertion
Q15) Create a Binary Search Tree by adding the integers in the following order… 10,12,5,4,20,8,7,15 and 13?
A15) The following items are added into a Binary Search Tree in the following order...

Q16) Define expression tree?
A16) Expression trees are one of the most effective methods for representing language-level code as data stored in a tree-like structure. An expression tree is a representation of a lambda expression in memory. The tree clarifies and transparentes the structure holding the lambda expression. The expression tree was designed to turn code into strings that may be supplied as inputs to other processes. It contains the query's actual elements, rather than the query's actual result.
One of the most essential characteristics of expression trees is that they are immutable, which means that altering an existing expression tree requires creating a new expression tree by copying and updating the existing tree expression. In programming, an expression tree is commonly constructed using postfix expressions, which read one symbol at a time. A one-node tree is formed and a pointer to it is pushed into a stack if the symbol is an operand.
The expression tree is a type of tree that is used to represent different types of expressions. The expressional assertions are represented using a tree data structure. The operators are always represented by the internal node in this tree.
● The operands are always denoted by the leaf nodes.
● These operands are always used in the operations.
● The operator in the deepest part of the tree is always given priority.
● The operator who is not very deep in the tree is always given the lowest priority compared to the operators who are very deep in the tree.
● The operand will always be present at a depth of the tree, making it the most important of all the operators.
● In summary, as compared to the other operators at the top of the tree, the value existing at a depth of the tree has the most importance.
● These expression trees are primarily used to assess, analyse, and modify a variety of expressions.
● It's also utilised to determine each operator's associativity in the phrase.
● The + operator, for example, is left-associative, while the / operator is right-associative.
● Using expression trees, the conundrum of this associativity has been solved.
● A context-free grammar is used to create these expression trees.
● In context-free grammars, we've put a rule in front of each grammar production.
● These rules are also known as semantic rules, and we can easily design expression trees using these semantic rules.
● It is part of the semantic analysis process and is one of the most important aspects of compiler design.
● We will employ syntax-directed translations in our semantic analysis, and we will create an annotated parse tree as output.
● The basic parse associated with the type property and each production rule makes up an annotated parse tree.
● The fundamental goal of using expression trees is to create complex expressions that can be easily evaluated using these trees.
● It's immutable, which means that once we've generated an expression tree, we can't change or modify it.
● It is necessary to completely construct the new expression tree in order to make more changes.
● It's also used to evaluate expressions with postfixes, prefixes, and infixes.
Expression trees are extremely useful for encoding language-level code in the form of data, which is mostly kept in a tree-like structure. It's also used in the lambda expression's memory representation. We can represent the lambda expression more openly and explicitly using the tree data structure. It is first constructed to transform the code segment to the data segment, allowing the expression to be evaluated quickly.
The expression tree is a binary tree in which the operand is represented by the exterior or leaf node and the operators are represented by the internal or parent node. For example, the expression tree for 7 + ((1+8)*3) would be:
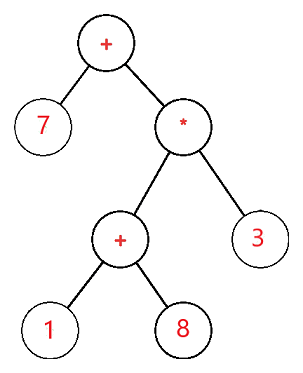
Q17) Write the use of expression tree?
A17) Use of Expression tree
● The fundamental goal of using expression trees is to create complex expressions that can be easily evaluated using these trees.
● It's also used to determine each operator's associativity in the phrase.
● It's also used to evaluate expressions with postfixes, prefixes, and infixes.
Q18) Describe AVL tree?
A18) AVL Tree was invented by GM Adelson - Velsky and EM Landis in 1962. The tree is named AVL in honor of its inventors.
AVL Tree can be defined as a height balanced binary search tree in which each node is associated with a balance factor which is calculated by subtracting the height of its right subtree from that of its left sub-tree.
Tree is said to be balanced if the balance factor of each node is in between -1 to 1, otherwise, the tree will be unbalanced and need to be balanced.
Balance Factor (k) = height (left(k)) - height (right(k))
If balance factor of any node is 1, it means that the left sub-tree is one level higher than the right subtree.
If balance factor of any node is 0, it means that the left subtree and right subtree contain equal height.
If balance factor of any node is -1, it means that the left sub-tree is one level lower than the right subtree.
An AVL tree is given in the following figure. We can see that, balance factor associated with each node is in between -1 and +1. Therefore, it is an example of AVL tree.
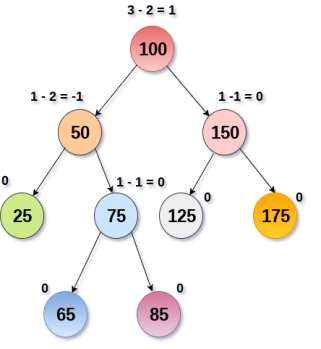
Fig 16 – AVL Tree
Complexity
Algorithm | Average case | Worst case |
Space | o(n) | o(n) |
Search | o(log n) | o(log n) |
Insert | o(log n) | o(log n) |
Delete | o(log n) | o(log n) |
Q19) Describe a heap tree?
A19) A binary heap is a data structure that resembles a complete binary tree in appearance. The ordering features of the heap data structure are explained here. A Heap is often represented by an array. We'll use H to represent a heap.
Because the elements of a heap are kept in an array, the position of the parent node of the ith element can be located at i/2 if the starting index is 1. Position 2i and 2i + 1 are the left and right children of the ith node, respectively.
Based on the ordering property, a binary heap can be classed as a max-heap or a min-heap.
Max Heap
A node's key value is larger than or equal to the key value of the highest child in this heap.
Hence, H[Parent(i)] ≥ H[i]
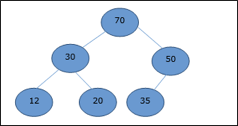
Fig 17: Max heap
Max Heap Construction Algorithm
The technique for creating Min Heap is similar to that for creating Max Heap, only we use min values instead of max values.
By inserting one element at a time, we will derive a method for max heap. The property of a heap must be maintained at all times. We also presume that we are inserting a node into an already heapify tree while inserting.
● Step 1: Make a new node at the bottom of the heap.
● Step 2: Give the node a new value.
● Step 3: Compare this child node's value to that of its parent.
● Step 4: If the parent's value is smaller than the child's, swap them.
● Step 5: Repeat steps 3 and 4 until the Heap property is maintained.
Min Heap
In mean-heap, a node's key value is less than or equal to the lowest child's key value.
Hence, H[Parent(i)] ≤ H[i]
Basic operations with respect to Max-Heap are shown below in this context. The insertion and deletion of elements in and out of heaps necessitates element reordering. As a result, the Heapify function must be used.
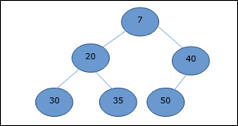
Fig 18: Min heap
Max Heap Deletion Algorithm
Let's create an algorithm for deleting from the maximum heap. The root of the Max (or Min) Heap is always deleted to remove the maximum (or minimum) value.
● Step 1: Remove the root node first.
● Step 2: Move the last element from the previous level to the root.
● Step 3: Compare this child node's value to that of its parent.
● Step 4: If the parent's value is smaller than the child's, swap them.
● Step 5: Repeat steps 3 and 4 until the Heap property is maintained.
Q20) Explain AVL rotations?
A20) AVL Rotations
We perform rotation in AVL tree only in case if Balance Factor is other than -1, 0, and 1. There are basically four types of rotations which are as follows:
- L L rotation: Inserted node is in the left subtree of left subtree of A
- R R rotation: Inserted node is in the right subtree of right subtree of A
- L R rotation: Inserted node is in the right subtree of left subtree of A
- R L rotation: Inserted node is in the left subtree of right subtree of A
Where node A is the node whose balance Factor is other than -1, 0, 1.
The first two rotations LL and RR are single rotations and the next two rotations LR and RL are double rotations. For a tree to be unbalanced, minimum height must be at least 2.
Let us understand each rotation
1. RR Rotation
When BST becomes unbalanced, due to a node is inserted into the right subtree of the right subtree of A, then we perform RR rotation, RR rotation is an anticlockwise rotation, which is applied on the edge below a node having balance factor -2
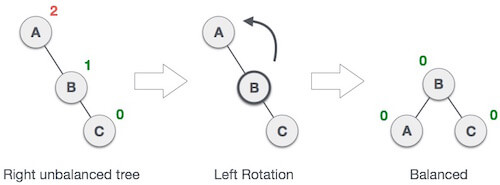
In above example, node A has balance factor -2 because a node C is inserted in the right subtree of A right subtree. We perform the RR rotation on the edge below A.
2. LL Rotation
When BST becomes unbalanced, due to a node is inserted into the left subtree of the left subtree of C, then we perform LL rotation, LL rotation is clockwise rotation, which is applied on the edge below a node having balance factor 2.
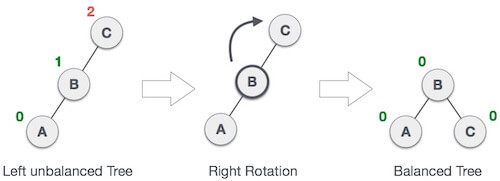
In above example, node C has balance factor 2 because a node A is inserted in the left subtree of C left subtree. We perform the LL rotation on the edge below A.
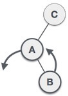
3. LR Rotation
Double rotations are bit tougher than single rotation which has already explained above. LR rotation = RR rotation + LL rotation, i.e., first RR rotation is performed on subtree and then LL rotation is performed on full tree, by full tree we mean the first node from the path of inserted node whose balance factor is other than -1, 0, or 1.
Let us understand each and every step very clearly:
State | Action |
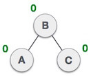
 | A node B has been inserted into the right subtree of A the left subtree of C, because of which C has become an unbalanced node having balance factor 2. This case is L R rotation where: Inserted node is in the right subtree of left subtree of C |
 | As LR rotation = RR + LL rotation, hence RR (anticlockwise) on subtree rooted at A is performed first. By doing RR rotation, node A, has become the left subtree of B. |
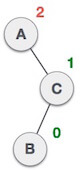
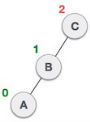 | After performing RR rotation, node C is still unbalanced, i.e., having balance factor 2, as inserted node A is in the left of left of C |
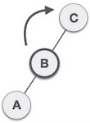 | Now we perform LL clockwise rotation on full tree, i.e. on node C. Node C has now become the right subtree of node B, A is left subtree of B |
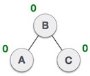 | Balance factor of each node is now either -1, 0, or 1, i.e. BST is balanced now. |
4. RL Rotation
As already discussed, that double rotations are bit tougher than single rotation which has already explained above. R L rotation = LL rotation + RR rotation, i.e., first LL rotation is performed on subtree and then RR rotation is performed on full tree, by full tree we mean the first node from the path of inserted node whose balance factor is other than -1, 0, or 1.
State | Action |
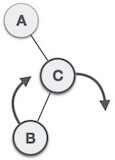
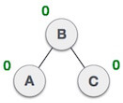
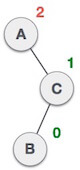 | A node B has been inserted into the left subtree of C the right subtree of A, because of which A has become an unbalanced node having balance factor - 2. This case is RL rotation where: Inserted node is in the left subtree of right subtree of A |
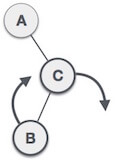 | As RL rotation = LL rotation + RR rotation, hence, LL (clockwise) on subtree rooted at C is performed first. By doing RR rotation, node C has become the right subtree of B. |
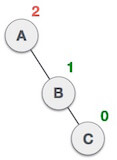
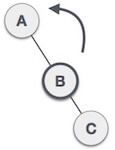
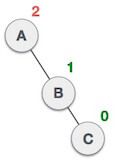 | After performing LL rotation, node A is still unbalanced, i.e. having balance factor -2, which is because of the right-subtree of the right-subtree node A. |
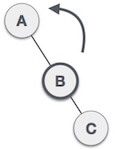 | Now we perform RR rotation (anticlockwise rotation) on full tree, i.e. on node A. Node C has now become the right subtree of node B, and node A has become the left subtree of B. |
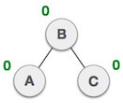 | Balance factor of each node is now either -1, 0, or 1, i.e., BST is balanced now. |
Unit - 3
Linked List- Linked List as ADT
Q1) What is a single link list?
A1) In programming, it is the most widely used linked list. When we talk about a linked list, we're talking about a singly linked list. The singly linked list is a data structure that is divided into two parts: the data portion and the address part, which contains the address of the next or successor node. A pointer is another name for the address component of a node.
Assume we have three nodes with addresses of 100, 200, and 300, respectively. The following diagram depicts the representation of three nodes as a linked list:
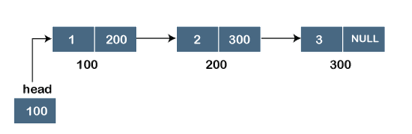
Fig 1: Singly linked list
In the diagram above, we can see three separate nodes with addresses of 100, 200, and 300, respectively. The first node has the address of the next node, which is 200, the second has the address of the last node, which is 300, and the third has the NULL value in its address portion because it does not point to any node. A head pointer is a pointer that stores the address of the first node.
Because there is just one link in the linked list depicted in the figure, it is referred to as a singly linked list. Just forward traversal is permitted in this list; we can't go backwards because there is only one link in the list.
Representation of the node in a singly linked list
Struct node
{
int data;
struct node *next;
}
In the above diagram, we've constructed a user-made structure called a node, which has two members: one is data of integer type, and the other is the node type's pointer (next).
Q2) Write the difference between malloc and calloc?
A2) Difference between malloc() and calloc()
Calloc() | Malloc() |
Calloc() sets the value of the allocated memory to zero. | Malloc() allocates memory and fills it with trash values. |
The total number of arguments is two. | There is just one argument. |
Syntax : (cast_type *)calloc(blocks , size_of_block); | Syntax : (cast_type *)malloc(Size_in_bytes); |
Q3) Define a double linked list?
A3) The doubly linked list, as its name implies, has two pointers. The doubly linked list can be described as a three-part linear data structure: the data component, the address part, and the other two address parts. A doubly linked list, in other terms, is a list with three parts in each node: one data portion, a pointer to the previous node, and a pointer to the next node.
Let's pretend we have three nodes with addresses of 100, 200, and 300, respectively. The representation of these nodes in a doubly-linked list is shown below:

Fig 2: Doubly linked list
The node in a doubly-linked list contains two address portions, as shown in the diagram above; one part keeps the address of the next node, while the other half stores the address of the previous node. The address component of the first node in the doubly linked list is NULL, indicating that the prior node's address is NULL.
Representation of the node in a doubly linked list
Struct node
{
int data;
struct node *next;
Struct node *prev;
}
In the above representation, we've constructed a user-defined structure called a node, which has three members: one is data of integer type, and the other two are pointers of the node type, i.e. next and prev. The address of the next node is stored in the next pointer variable, whereas the address of the previous node is stored in the prev pointer variable. The type of both the pointers, i.e., next and prev is struct node as both the pointers are storing the address of the node of the struct node type.
Q4) Write short notes on a circular link list?
A4) Circular linked list
A singly linked list is a type of circular linked list. The sole difference between a singly linked list and a circular linked list is that the last node in a singly linked list does not point to any other node, therefore its link portion is NULL. The circular linked list, on the other hand, is a list in which the last node connects to the first node, and the address of the first node is stored in the link section of the last node.
There are no nodes at the beginning or finish of the circular linked list. We can travel in either way, backwards or forwards. The following is a diagrammatic illustration of the circular linked list:
Struct node
{
int data;
struct node *next;
}
A circular linked list is a collection of elements in which each node is linked to the next and the last node is linked to the first. The circular linked list will be represented similarly to the singly linked list, as demonstrated below:
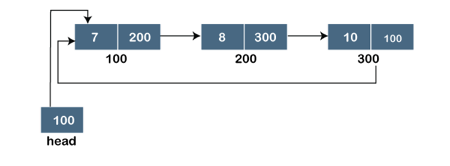
Fig 3: Circular linked list
Q5) Explain insertion operation of linked list?
A5) Insertion
When placing a node into a linked list, there are three possible scenarios:
● Insertion at the beginning
● Insertion at the end. (Append)
● Insertion after a given node
Insertion at the beginning
There's no need to look for the end of the list. If the list is empty, the new node becomes the list's head. Otherwise, we must connect the new node to the existing list's head and make the new node the list's head.
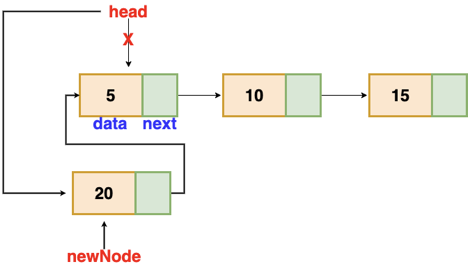
Fig 4: Insertion at beginning
// function is returning the head of the singly linked-list
Node insertAtBegin(Node head, int val)
{
newNode = new Node(val) // creating new node of linked list
if(head == NULL) // check if linked list is empty
return newNode
else // inserting the node at the beginning
{
newNode.next = head
return newNode
}
}
Insertion at the end
We'll go through the list till we reach the last node. The new node is then appended to the end of the list. It's worth noting that there are some exceptions, such as when the list is empty.
We will return the updated head of the linked list if the list is empty, because the inserted node is both the first and end node of the linked list in this case.
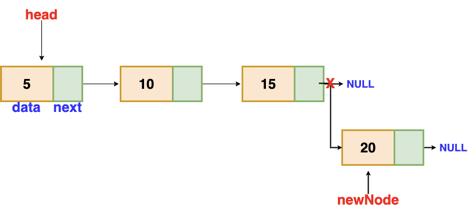
Fig 5: Insertion at end
// the function is returning the head of the singly linked list
Node insertAtEnd(Node head, int val)
{
if( head == NULL ) // handing the special case
{
newNode = new Node(val)
head = newNode
return head
}
Node temp = head
// traversing the list to get the last node
while( temp.next != NULL )
{
temp = temp.next
}
newNode = new Node(val)
temp.next = newNode
return head
}
Insertion after a given node
The reference to a node is passed to us, and the new node is put after it.
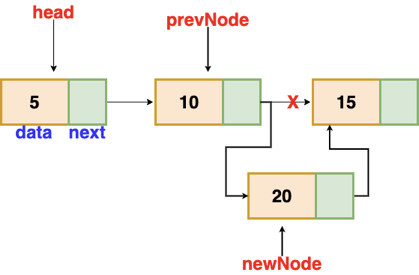
Fig 6: Insertion after given node
Void insertAfter(Node prevNode, int val)
{
newNode = new Node(val)
newNode.next = prevNode.next
prevNode.next = newNode
}
Q6) How deletion operation works on linked list?
A6) Deletion
These are the procedures to delete a node from a linked list.
● Find the previous node of the node to be deleted.
● Change the next pointer of the previous node
● Free the memory of the deleted node.
There is a specific circumstance in which the first node is removed upon deletion. We must update the connected list's head in this case.
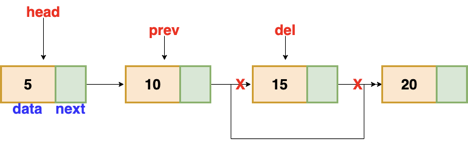
Fig 7: Deleting a node in linked list
// this function will return the head of the linked list
Node deleteLL(Node head, Node del)
{
if(head == del) // if the node to be deleted is the head node
{
return head.next // special case for the first Node
}
Node temp = head
while( temp.next != NULL )
{
if(temp.next == del) // finding the node to be deleted
{
temp.next = temp.next.next
delete del // free the memory of that Node
return head
}
temp = temp.next
}
return head // if no node matches in the Linked List
}
Q7) How to traverse a linked list?
A7) Traversal
The goal is to work your way through the list from start to finish. We might want to print the list or search for a certain node in it, for example.
The traversal algorithm for a list
● Start with the head of the list. Access the content of the head node if it is not null.
● Then go to the next node(if exists) and access the node information
● Continue until no more nodes (that is, you have reached the null node)
Void traverseLL(Node head) {
while(head != NULL)
{
print(head.data)
head = head.next
}
}
Q8) What do you mean by polynomial representation?
A8) Polynomials can be represented in a number of different ways. These are the following:
● By the use of arrays
● By the use of Linked List
Representation of polynomial using Arrays
There may be times when you need to evaluate a large number of polynomial expressions and execute fundamental arithmetic operations on them, such as addition and subtraction. You'll need a mechanism to express the polynomials for this. The simplest method is to express a polynomial of degree 'n' and store the coefficient of the polynomial's n+1 terms in an array. As a result, each array element will have two values:
● Coefficient and
● Exponent
Polynomial of representation using linked lists
An ordered list of non-zero terms can be thought of as a polynomial. Each non-zero word is a two-tuple, containing two pieces of data:
● The exponent part
● The coefficient part
Multiplication
To multiply two polynomials, multiply the terms of one polynomial by the terms of the other polynomial. Assume the two polynomials have n and m terms respectively. A polynomial with n times m terms will be created as a result of this method.
For example, we can construct a linked list by multiplying 2 – 4x + 5x2 and 1 + 2x – 3x3:

All of the terms we'll need to get the final outcome are in this linked list. The powers, on the other hand, do not sort it. It also has duplicate nodes with similar terms. We can merge sort the linked list depending on each node's power to get the final linked list:
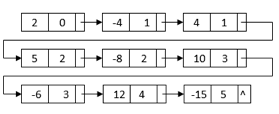
After sorting, the nodes with similar terms are clustered together. Then, for the final multiplication result, we can combine each set of like terms:

Code for Polynomial addition, subtraction and multiplication in C
#include<stdio.h>
#include<conio.h>
#include "poly.h"void main()
{
clrscr();
Polynomial *p1,*p2,*sum,*sub,*mul;
printf("\nENTER THE FIRST POLYNOMIAL.");
p1=createPolynomial();
printf("\nENTER THE SECOND POLYNOMIAL.");
p2=createPolynomial();
clrscr();
printf("\nFIRST : ");
displayPolynomial(p1);
printf("\nSECOND : ");
displayPolynomial(p2);
printf("\n\nADDITION IS : ");
sum=addPolynomial(p1,p2);
displayPolynomial(sum);
printf("\n\nSUBTRACTION IS : ");
sub=subPolynomial(p1,p2);
displayPolynomial(sub);
printf("\n\nMULTIPLICATION IS : ");
mul=mulPolynomial(p1,p2);
displayPolynomial(mul);
getch();
}
Q9) Introduce trees?
A9) Trees
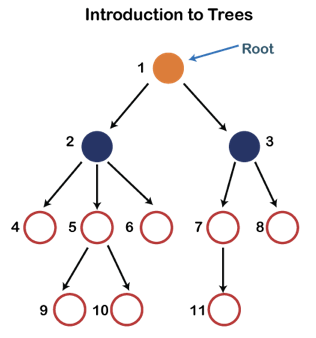
Fig 8: Tree
Each node in the above structure is labeled with a number. Each arrow in the diagram above represents a link between the two nodes.
Root - In a tree hierarchy, the root node is the highest node. To put it another way, the root node is the one that has no children. The root node of the tree is numbered 1 in the above structure. A parent-child relationship exists when one node is directly linked to another node.
Child node - If a node is a descendant of another node, it is referred to as a child node.
Parent - If a node has a sub-node, the parent of that sub-node is said to be that node.
Sibling - Sibling nodes are those that have the same parent.
Leaf node - A leaf node is a node in the tree that does not have any descendant nodes. A leaf node is the tree's bottommost node. In a generic tree, there can be any number of leaf nodes. External nodes are also known as leaf nodes.
Internal node - An internal node is a node that has at least one child node.
Ancestor node - Any previous node on a path from the root to that node is an ancestor of that node. There are no ancestors for the root node. Nodes 1, 2, and 5 are the ancestors of node 10 in the tree depicted above.
Descendant node - A descendant of a node is the direct successor of the supplied node. In the diagram above, node 10 is a descendent of node 5.
Q10) Explain tree traversal?
A10) Traversal is a process to visit all the nodes of a tree and may print their values too. Because all nodes are connected via edges (links) we always start from the root (head) node. That is, we cannot randomly access a node in a tree. There are three ways which we use to traverse a tree −
● In-order Traversal
● Pre-order Traversal
● Post-order Traversal
Generally, we traverse a tree to search or locate a given item or key in the tree or to print all the values it contains.
In-order Traversal
In this traversal method, the left subtree is visited first, then the root and later the right subtree. We should always remember that every node may represent a subtree itself.
If a binary tree is traversed in-order, the output will produce sorted key values in an ascending order.

Fig 9: Inorder
We start from A, and following in-order traversal, we move to its left subtree B. B is also traversed in-order. The process goes on until all the nodes are visited. The output of inorder traversal of this tree will be −
D → B → E → A → F → C → G
Algorithm
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Visit root node.
Step 3 − Recursively traverse right subtree.
Pre-order Traversal
In this traversal method, the root node is visited first, then the left subtree and finally the right subtree.
Fig 10: Pre order
We start from A, and following pre-order traversal, we first visit A itself and then move to its left subtree B. B is also traversed pre-order. The process goes on until all the nodes are visited. The output of pre-order traversal of this tree will be −
A → B → D → E → C → F → G
Algorithm
Until all nodes are traversed −
Step 1 − Visit root node.
Step 2 − Recursively traverse left subtree.
Step 3 − Recursively traverse right subtree.
Post-order Traversal
In this traversal method, the root node is visited last, hence the name. First we traverse the left subtree, then the right subtree and finally the root node.
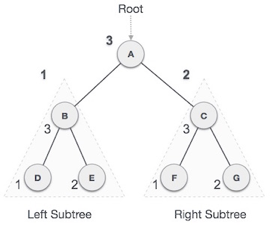
Fig 11: Post order
We start from A, and following Post-order traversal, we first visit the left subtree B. B is also traversed post-order. The process goes on until all the nodes are visited. The output of post-order traversal of this tree will be −
D → E → B → F → G → C → A
Algorithm
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Recursively traverse right subtree.
Step 3 − Visit root node.
Q11) Describe binary tree?
A11) The Binary tree means that the node can have a maximum of two children. Here, the binary name itself suggests 'two'; therefore, each node can have either 0, 1 or 2 children.
Let's understand the binary tree through an example.
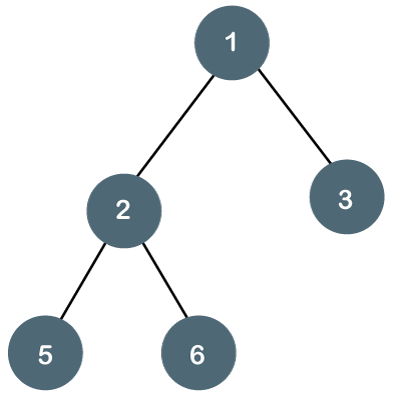
Fig 12: Example
The above tree is a binary tree because each node contains the utmost two children. The logical representation of the above tree is given below:
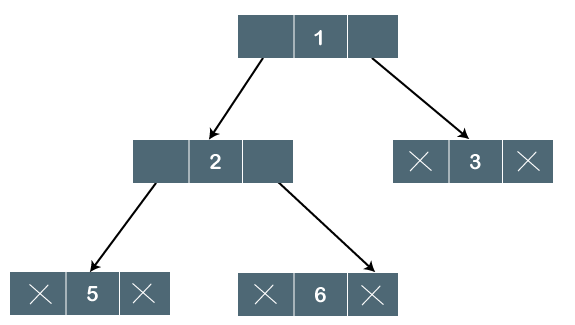
Fig 13: Logical representation
In the above tree, node 1 contains two pointers, i.e., left and a right pointer pointing to the left and right node respectively. The node 2 contains both the nodes (left and right node); therefore, it has two pointers (left and right). The nodes 3, 5 and 6 are the leaf nodes, so all these nodes contain NULL pointer on both left and right parts.
If there are 'n' number of nodes in the binary tree.
The minimum height can be computed as:
As we know that,
n = 2h+1 -1
n+1 = 2h+1
Taking log on both the sides,
Log2(n+1) = log2(2h+1)
Log2(n+1) = h+1
h = log2(n+1) - 1
The maximum height can be computed as:
As we know that,
n = h+1
h= n-1
Types of Binary Tree
There are four types of Binary tree:
● Full/ proper/ strict Binary tree
● Complete Binary tree
● Perfect Binary tree
● Degenerate Binary tree
● Balanced Binary tree
Q12) Write the properties of binary trees?
A12) Properties of Binary Tree
● At each level of i, the maximum number of nodes is 2i.
● The height of the tree is defined as the longest path from the root node to the leaf node. The tree which is shown above has a height equal to 3. Therefore, the maximum number of nodes at height 3 is equal to (1+2+4+8) = 15. In general, the maximum number of nodes possible at height h is (20 + 21 + 22+….2h) = 2h+1 -1.
● The minimum number of nodes possible at height h is equal to h+1.
● If the number of nodes is minimum, then the height of the tree would be maximum. Conversely, if the number of nodes is maximum, then the height of the tree would be minimum.
Q13) What is BST?
A13) A binary search tree is a type of binary tree in which the nodes are organized in a predetermined sequence. This is referred to as an ordered binary tree.
The value of all nodes in the left sub-tree is less than the value of the root in a binary search tree. Similarly, the value of all nodes in the right subtree is larger than or equal to the root's value. This rule will be applied recursively to all of the root's left and right subtrees.
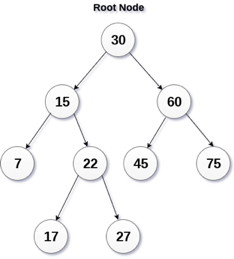
Fig 14: Binary search tree
A Binary Search Tree (BST) is a tree in which all nodes have the properties listed below.
● The key of the left subtree has a lower value than the key of its parent (root) node.
● The value of the right subkey tree's is larger than or equal to the value of the key of its parent (root) node.
● As a result, BST separates all of its sub-trees into two segments: the left and right subtrees, and can be characterized as
Left_subtree (keys) < node (key) ≤ right_subtree (keys)
Q14) What is insertion in BST?
A14) Insertion
The insertion operation in a binary search tree takes O(log n) time to complete. A new node is always added as a leaf node in a binary search tree. The following is how the insertion procedure is carried out...
Step 1: Create a newNode with the specified value and NULL left and right.
Step 2: Make sure the tree isn't empty.
Step 3 - Set root to newNode if the tree is empty.
Step 4 - If the tree isn't empty, see if newNode's value is smaller or larger than the node's value (here it is root node).
Step 5 - Go to the node's left child if newNode is smaller or equal to it. Move to new Nodes right child if the newNode is larger than the node.
Step 6- Continue in this manner until we reach the leaf node (i.e., reaches to NULL).
Step 7 - Once you've reached the leaf node, insert the newNode as a left child if it's smaller or equal to the leaf node, or as a right child otherwise.
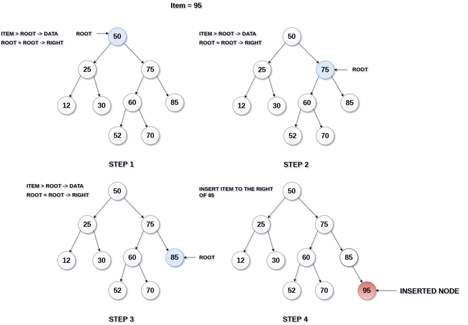
Fig 15: Example of insertion
Q15) Create a Binary Search Tree by adding the integers in the following order… 10,12,5,4,20,8,7,15 and 13?
A15) The following items are added into a Binary Search Tree in the following order...
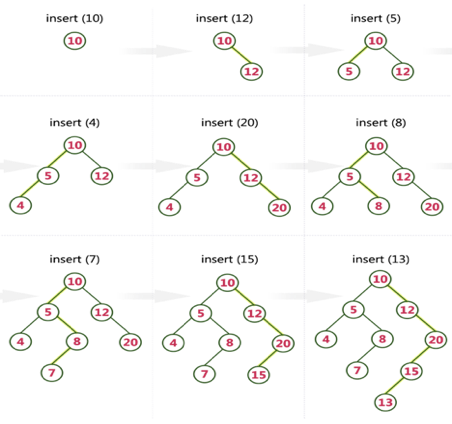
Q16) Define expression tree?
A16) Expression trees are one of the most effective methods for representing language-level code as data stored in a tree-like structure. An expression tree is a representation of a lambda expression in memory. The tree clarifies and transparentes the structure holding the lambda expression. The expression tree was designed to turn code into strings that may be supplied as inputs to other processes. It contains the query's actual elements, rather than the query's actual result.
One of the most essential characteristics of expression trees is that they are immutable, which means that altering an existing expression tree requires creating a new expression tree by copying and updating the existing tree expression. In programming, an expression tree is commonly constructed using postfix expressions, which read one symbol at a time. A one-node tree is formed and a pointer to it is pushed into a stack if the symbol is an operand.
The expression tree is a type of tree that is used to represent different types of expressions. The expressional assertions are represented using a tree data structure. The operators are always represented by the internal node in this tree.
● The operands are always denoted by the leaf nodes.
● These operands are always used in the operations.
● The operator in the deepest part of the tree is always given priority.
● The operator who is not very deep in the tree is always given the lowest priority compared to the operators who are very deep in the tree.
● The operand will always be present at a depth of the tree, making it the most important of all the operators.
● In summary, as compared to the other operators at the top of the tree, the value existing at a depth of the tree has the most importance.
● These expression trees are primarily used to assess, analyse, and modify a variety of expressions.
● It's also utilised to determine each operator's associativity in the phrase.
● The + operator, for example, is left-associative, while the / operator is right-associative.
● Using expression trees, the conundrum of this associativity has been solved.
● A context-free grammar is used to create these expression trees.
● In context-free grammars, we've put a rule in front of each grammar production.
● These rules are also known as semantic rules, and we can easily design expression trees using these semantic rules.
● It is part of the semantic analysis process and is one of the most important aspects of compiler design.
● We will employ syntax-directed translations in our semantic analysis, and we will create an annotated parse tree as output.
● The basic parse associated with the type property and each production rule makes up an annotated parse tree.
● The fundamental goal of using expression trees is to create complex expressions that can be easily evaluated using these trees.
● It's immutable, which means that once we've generated an expression tree, we can't change or modify it.
● It is necessary to completely construct the new expression tree in order to make more changes.
● It's also used to evaluate expressions with postfixes, prefixes, and infixes.
Expression trees are extremely useful for encoding language-level code in the form of data, which is mostly kept in a tree-like structure. It's also used in the lambda expression's memory representation. We can represent the lambda expression more openly and explicitly using the tree data structure. It is first constructed to transform the code segment to the data segment, allowing the expression to be evaluated quickly.
The expression tree is a binary tree in which the operand is represented by the exterior or leaf node and the operators are represented by the internal or parent node. For example, the expression tree for 7 + ((1+8)*3) would be:
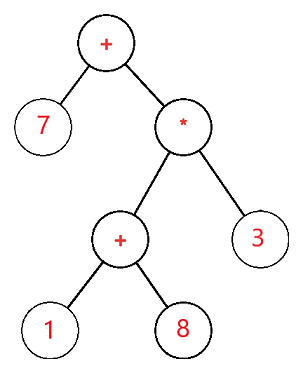
Q17) Write the use of expression tree?
A17) Use of Expression tree
● The fundamental goal of using expression trees is to create complex expressions that can be easily evaluated using these trees.
● It's also used to determine each operator's associativity in the phrase.
● It's also used to evaluate expressions with postfixes, prefixes, and infixes.
Q18) Describe AVL tree?
A18) AVL Tree was invented by GM Adelson - Velsky and EM Landis in 1962. The tree is named AVL in honor of its inventors.
AVL Tree can be defined as a height balanced binary search tree in which each node is associated with a balance factor which is calculated by subtracting the height of its right subtree from that of its left sub-tree.
Tree is said to be balanced if the balance factor of each node is in between -1 to 1, otherwise, the tree will be unbalanced and need to be balanced.
Balance Factor (k) = height (left(k)) - height (right(k))
If balance factor of any node is 1, it means that the left sub-tree is one level higher than the right subtree.
If balance factor of any node is 0, it means that the left subtree and right subtree contain equal height.
If balance factor of any node is -1, it means that the left sub-tree is one level lower than the right subtree.
An AVL tree is given in the following figure. We can see that, balance factor associated with each node is in between -1 and +1. Therefore, it is an example of AVL tree.

Fig 16 – AVL Tree
Complexity
Algorithm | Average case | Worst case |
Space | o(n) | o(n) |
Search | o(log n) | o(log n) |
Insert | o(log n) | o(log n) |
Delete | o(log n) | o(log n) |
Q19) Describe a heap tree?
A19) A binary heap is a data structure that resembles a complete binary tree in appearance. The ordering features of the heap data structure are explained here. A Heap is often represented by an array. We'll use H to represent a heap.
Because the elements of a heap are kept in an array, the position of the parent node of the ith element can be located at i/2 if the starting index is 1. Position 2i and 2i + 1 are the left and right children of the ith node, respectively.
Based on the ordering property, a binary heap can be classed as a max-heap or a min-heap.
Max Heap
A node's key value is larger than or equal to the key value of the highest child in this heap.
Hence, H[Parent(i)] ≥ H[i]
Fig 17: Max heap
Max Heap Construction Algorithm
The technique for creating Min Heap is similar to that for creating Max Heap, only we use min values instead of max values.
By inserting one element at a time, we will derive a method for max heap. The property of a heap must be maintained at all times. We also presume that we are inserting a node into an already heapify tree while inserting.
● Step 1: Make a new node at the bottom of the heap.
● Step 2: Give the node a new value.
● Step 3: Compare this child node's value to that of its parent.
● Step 4: If the parent's value is smaller than the child's, swap them.
● Step 5: Repeat steps 3 and 4 until the Heap property is maintained.
Min Heap
In mean-heap, a node's key value is less than or equal to the lowest child's key value.
Hence, H[Parent(i)] ≤ H[i]
Basic operations with respect to Max-Heap are shown below in this context. The insertion and deletion of elements in and out of heaps necessitates element reordering. As a result, the Heapify function must be used.

Fig 18: Min heap
Max Heap Deletion Algorithm
Let's create an algorithm for deleting from the maximum heap. The root of the Max (or Min) Heap is always deleted to remove the maximum (or minimum) value.
● Step 1: Remove the root node first.
● Step 2: Move the last element from the previous level to the root.
● Step 3: Compare this child node's value to that of its parent.
● Step 4: If the parent's value is smaller than the child's, swap them.
● Step 5: Repeat steps 3 and 4 until the Heap property is maintained.
Q20) Explain AVL rotations?
A20) AVL Rotations
We perform rotation in AVL tree only in case if Balance Factor is other than -1, 0, and 1. There are basically four types of rotations which are as follows:
- L L rotation: Inserted node is in the left subtree of left subtree of A
- R R rotation: Inserted node is in the right subtree of right subtree of A
- L R rotation: Inserted node is in the right subtree of left subtree of A
- R L rotation: Inserted node is in the left subtree of right subtree of A
Where node A is the node whose balance Factor is other than -1, 0, 1.
The first two rotations LL and RR are single rotations and the next two rotations LR and RL are double rotations. For a tree to be unbalanced, minimum height must be at least 2.
Let us understand each rotation
1. RR Rotation
When BST becomes unbalanced, due to a node is inserted into the right subtree of the right subtree of A, then we perform RR rotation, RR rotation is an anticlockwise rotation, which is applied on the edge below a node having balance factor -2
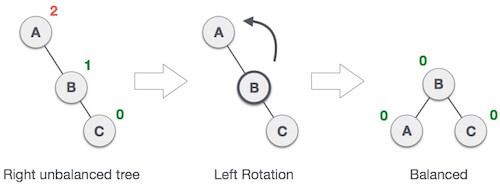
In above example, node A has balance factor -2 because a node C is inserted in the right subtree of A right subtree. We perform the RR rotation on the edge below A.
2. LL Rotation
When BST becomes unbalanced, due to a node is inserted into the left subtree of the left subtree of C, then we perform LL rotation, LL rotation is clockwise rotation, which is applied on the edge below a node having balance factor 2.
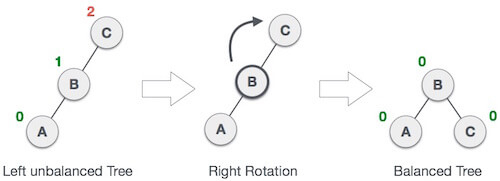
In above example, node C has balance factor 2 because a node A is inserted in the left subtree of C left subtree. We perform the LL rotation on the edge below A.
3. LR Rotation
Double rotations are bit tougher than single rotation which has already explained above. LR rotation = RR rotation + LL rotation, i.e., first RR rotation is performed on subtree and then LL rotation is performed on full tree, by full tree we mean the first node from the path of inserted node whose balance factor is other than -1, 0, or 1.
Let us understand each and every step very clearly:
State | Action |
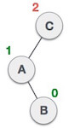 | A node B has been inserted into the right subtree of A the left subtree of C, because of which C has become an unbalanced node having balance factor 2. This case is L R rotation where: Inserted node is in the right subtree of left subtree of C |
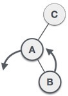 | As LR rotation = RR + LL rotation, hence RR (anticlockwise) on subtree rooted at A is performed first. By doing RR rotation, node A, has become the left subtree of B. |
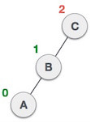 | After performing RR rotation, node C is still unbalanced, i.e., having balance factor 2, as inserted node A is in the left of left of C |
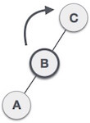 | Now we perform LL clockwise rotation on full tree, i.e. on node C. Node C has now become the right subtree of node B, A is left subtree of B |
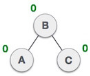 | Balance factor of each node is now either -1, 0, or 1, i.e. BST is balanced now. |
4. RL Rotation
As already discussed, that double rotations are bit tougher than single rotation which has already explained above. R L rotation = LL rotation + RR rotation, i.e., first LL rotation is performed on subtree and then RR rotation is performed on full tree, by full tree we mean the first node from the path of inserted node whose balance factor is other than -1, 0, or 1.
State | Action |
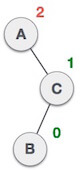 | A node B has been inserted into the left subtree of C the right subtree of A, because of which A has become an unbalanced node having balance factor - 2. This case is RL rotation where: Inserted node is in the left subtree of right subtree of A |
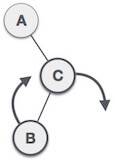 | As RL rotation = LL rotation + RR rotation, hence, LL (clockwise) on subtree rooted at C is performed first. By doing RR rotation, node C has become the right subtree of B. |
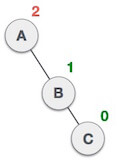 | After performing LL rotation, node A is still unbalanced, i.e. having balance factor -2, which is because of the right-subtree of the right-subtree node A. |
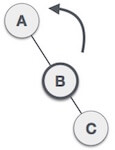 | Now we perform RR rotation (anticlockwise rotation) on full tree, i.e. on node A. Node C has now become the right subtree of node B, and node A has become the left subtree of B. |
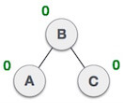 | Balance factor of each node is now either -1, 0, or 1, i.e., BST is balanced now. |
Unit - 3
Unit - 3
Linked List- Linked List as ADT
Q1) What is a single link list?
A1) In programming, it is the most widely used linked list. When we talk about a linked list, we're talking about a singly linked list. The singly linked list is a data structure that is divided into two parts: the data portion and the address part, which contains the address of the next or successor node. A pointer is another name for the address component of a node.
Assume we have three nodes with addresses of 100, 200, and 300, respectively. The following diagram depicts the representation of three nodes as a linked list:
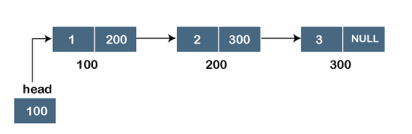
Fig 1: Singly linked list
In the diagram above, we can see three separate nodes with addresses of 100, 200, and 300, respectively. The first node has the address of the next node, which is 200, the second has the address of the last node, which is 300, and the third has the NULL value in its address portion because it does not point to any node. A head pointer is a pointer that stores the address of the first node.
Because there is just one link in the linked list depicted in the figure, it is referred to as a singly linked list. Just forward traversal is permitted in this list; we can't go backwards because there is only one link in the list.
Representation of the node in a singly linked list
Struct node
{
int data;
struct node *next;
}
In the above diagram, we've constructed a user-made structure called a node, which has two members: one is data of integer type, and the other is the node type's pointer (next).
Q2) Write the difference between malloc and calloc?
A2) Difference between malloc() and calloc()
Calloc() | Malloc() |
Calloc() sets the value of the allocated memory to zero. | Malloc() allocates memory and fills it with trash values. |
The total number of arguments is two. | There is just one argument. |
Syntax : (cast_type *)calloc(blocks , size_of_block); | Syntax : (cast_type *)malloc(Size_in_bytes); |
Q3) Define a double linked list?
A3) The doubly linked list, as its name implies, has two pointers. The doubly linked list can be described as a three-part linear data structure: the data component, the address part, and the other two address parts. A doubly linked list, in other terms, is a list with three parts in each node: one data portion, a pointer to the previous node, and a pointer to the next node.
Let's pretend we have three nodes with addresses of 100, 200, and 300, respectively. The representation of these nodes in a doubly-linked list is shown below:
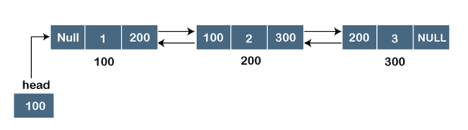
Fig 2: Doubly linked list
The node in a doubly-linked list contains two address portions, as shown in the diagram above; one part keeps the address of the next node, while the other half stores the address of the previous node. The address component of the first node in the doubly linked list is NULL, indicating that the prior node's address is NULL.
Representation of the node in a doubly linked list
Struct node
{
int data;
struct node *next;
Struct node *prev;
}
In the above representation, we've constructed a user-defined structure called a node, which has three members: one is data of integer type, and the other two are pointers of the node type, i.e. next and prev. The address of the next node is stored in the next pointer variable, whereas the address of the previous node is stored in the prev pointer variable. The type of both the pointers, i.e., next and prev is struct node as both the pointers are storing the address of the node of the struct node type.
Q4) Write short notes on a circular link list?
A4) Circular linked list
A singly linked list is a type of circular linked list. The sole difference between a singly linked list and a circular linked list is that the last node in a singly linked list does not point to any other node, therefore its link portion is NULL. The circular linked list, on the other hand, is a list in which the last node connects to the first node, and the address of the first node is stored in the link section of the last node.
There are no nodes at the beginning or finish of the circular linked list. We can travel in either way, backwards or forwards. The following is a diagrammatic illustration of the circular linked list:
Struct node
{
int data;
struct node *next;
}
A circular linked list is a collection of elements in which each node is linked to the next and the last node is linked to the first. The circular linked list will be represented similarly to the singly linked list, as demonstrated below:
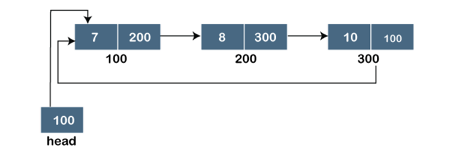
Fig 3: Circular linked list
Q5) Explain insertion operation of linked list?
A5) Insertion
When placing a node into a linked list, there are three possible scenarios:
● Insertion at the beginning
● Insertion at the end. (Append)
● Insertion after a given node
Insertion at the beginning
There's no need to look for the end of the list. If the list is empty, the new node becomes the list's head. Otherwise, we must connect the new node to the existing list's head and make the new node the list's head.
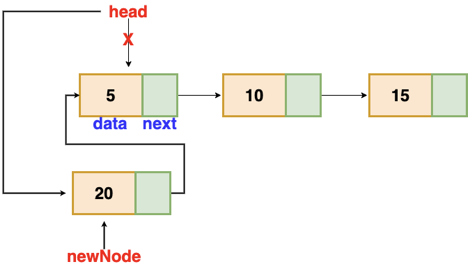
Fig 4: Insertion at beginning
// function is returning the head of the singly linked-list
Node insertAtBegin(Node head, int val)
{
newNode = new Node(val) // creating new node of linked list
if(head == NULL) // check if linked list is empty
return newNode
else // inserting the node at the beginning
{
newNode.next = head
return newNode
}
}
Insertion at the end
We'll go through the list till we reach the last node. The new node is then appended to the end of the list. It's worth noting that there are some exceptions, such as when the list is empty.
We will return the updated head of the linked list if the list is empty, because the inserted node is both the first and end node of the linked list in this case.
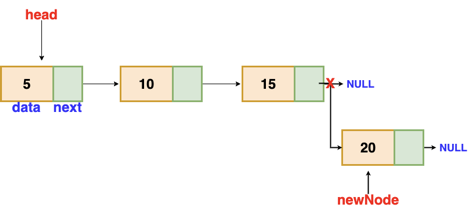
Fig 5: Insertion at end
// the function is returning the head of the singly linked list
Node insertAtEnd(Node head, int val)
{
if( head == NULL ) // handing the special case
{
newNode = new Node(val)
head = newNode
return head
}
Node temp = head
// traversing the list to get the last node
while( temp.next != NULL )
{
temp = temp.next
}
newNode = new Node(val)
temp.next = newNode
return head
}
Insertion after a given node
The reference to a node is passed to us, and the new node is put after it.
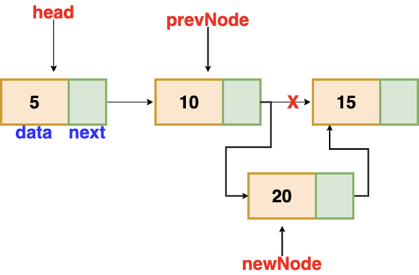
Fig 6: Insertion after given node
Void insertAfter(Node prevNode, int val)
{
newNode = new Node(val)
newNode.next = prevNode.next
prevNode.next = newNode
}
Q6) How deletion operation works on linked list?
A6) Deletion
These are the procedures to delete a node from a linked list.
● Find the previous node of the node to be deleted.
● Change the next pointer of the previous node
● Free the memory of the deleted node.
There is a specific circumstance in which the first node is removed upon deletion. We must update the connected list's head in this case.
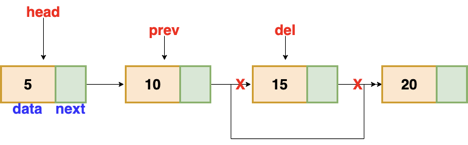
Fig 7: Deleting a node in linked list
// this function will return the head of the linked list
Node deleteLL(Node head, Node del)
{
if(head == del) // if the node to be deleted is the head node
{
return head.next // special case for the first Node
}
Node temp = head
while( temp.next != NULL )
{
if(temp.next == del) // finding the node to be deleted
{
temp.next = temp.next.next
delete del // free the memory of that Node
return head
}
temp = temp.next
}
return head // if no node matches in the Linked List
}
Q7) How to traverse a linked list?
A7) Traversal
The goal is to work your way through the list from start to finish. We might want to print the list or search for a certain node in it, for example.
The traversal algorithm for a list
● Start with the head of the list. Access the content of the head node if it is not null.
● Then go to the next node(if exists) and access the node information
● Continue until no more nodes (that is, you have reached the null node)
Void traverseLL(Node head) {
while(head != NULL)
{
print(head.data)
head = head.next
}
}
Q8) What do you mean by polynomial representation?
A8) Polynomials can be represented in a number of different ways. These are the following:
● By the use of arrays
● By the use of Linked List
Representation of polynomial using Arrays
There may be times when you need to evaluate a large number of polynomial expressions and execute fundamental arithmetic operations on them, such as addition and subtraction. You'll need a mechanism to express the polynomials for this. The simplest method is to express a polynomial of degree 'n' and store the coefficient of the polynomial's n+1 terms in an array. As a result, each array element will have two values:
● Coefficient and
● Exponent
Polynomial of representation using linked lists
An ordered list of non-zero terms can be thought of as a polynomial. Each non-zero word is a two-tuple, containing two pieces of data:
● The exponent part
● The coefficient part
Multiplication
To multiply two polynomials, multiply the terms of one polynomial by the terms of the other polynomial. Assume the two polynomials have n and m terms respectively. A polynomial with n times m terms will be created as a result of this method.
For example, we can construct a linked list by multiplying 2 – 4x + 5x2 and 1 + 2x – 3x3:
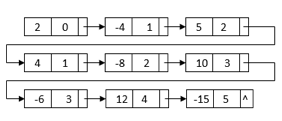
All of the terms we'll need to get the final outcome are in this linked list. The powers, on the other hand, do not sort it. It also has duplicate nodes with similar terms. We can merge sort the linked list depending on each node's power to get the final linked list:
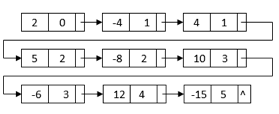
After sorting, the nodes with similar terms are clustered together. Then, for the final multiplication result, we can combine each set of like terms:

Code for Polynomial addition, subtraction and multiplication in C
#include<stdio.h>
#include<conio.h>
#include "poly.h"void main()
{
clrscr();
Polynomial *p1,*p2,*sum,*sub,*mul;
printf("\nENTER THE FIRST POLYNOMIAL.");
p1=createPolynomial();
printf("\nENTER THE SECOND POLYNOMIAL.");
p2=createPolynomial();
clrscr();
printf("\nFIRST : ");
displayPolynomial(p1);
printf("\nSECOND : ");
displayPolynomial(p2);
printf("\n\nADDITION IS : ");
sum=addPolynomial(p1,p2);
displayPolynomial(sum);
printf("\n\nSUBTRACTION IS : ");
sub=subPolynomial(p1,p2);
displayPolynomial(sub);
printf("\n\nMULTIPLICATION IS : ");
mul=mulPolynomial(p1,p2);
displayPolynomial(mul);
getch();
}
Q9) Introduce trees?
A9) Trees
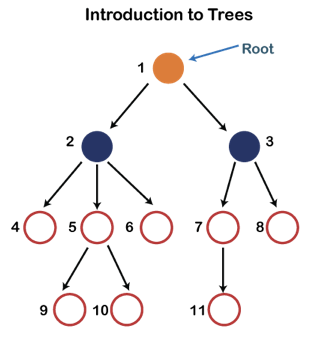
Fig 8: Tree
Each node in the above structure is labeled with a number. Each arrow in the diagram above represents a link between the two nodes.
Root - In a tree hierarchy, the root node is the highest node. To put it another way, the root node is the one that has no children. The root node of the tree is numbered 1 in the above structure. A parent-child relationship exists when one node is directly linked to another node.
Child node - If a node is a descendant of another node, it is referred to as a child node.
Parent - If a node has a sub-node, the parent of that sub-node is said to be that node.
Sibling - Sibling nodes are those that have the same parent.
Leaf node - A leaf node is a node in the tree that does not have any descendant nodes. A leaf node is the tree's bottommost node. In a generic tree, there can be any number of leaf nodes. External nodes are also known as leaf nodes.
Internal node - An internal node is a node that has at least one child node.
Ancestor node - Any previous node on a path from the root to that node is an ancestor of that node. There are no ancestors for the root node. Nodes 1, 2, and 5 are the ancestors of node 10 in the tree depicted above.
Descendant node - A descendant of a node is the direct successor of the supplied node. In the diagram above, node 10 is a descendent of node 5.
Q10) Explain tree traversal?
A10) Traversal is a process to visit all the nodes of a tree and may print their values too. Because all nodes are connected via edges (links) we always start from the root (head) node. That is, we cannot randomly access a node in a tree. There are three ways which we use to traverse a tree −
● In-order Traversal
● Pre-order Traversal
● Post-order Traversal
Generally, we traverse a tree to search or locate a given item or key in the tree or to print all the values it contains.
In-order Traversal
In this traversal method, the left subtree is visited first, then the root and later the right subtree. We should always remember that every node may represent a subtree itself.
If a binary tree is traversed in-order, the output will produce sorted key values in an ascending order.
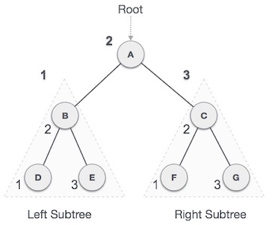
Fig 9: Inorder
We start from A, and following in-order traversal, we move to its left subtree B. B is also traversed in-order. The process goes on until all the nodes are visited. The output of inorder traversal of this tree will be −
D → B → E → A → F → C → G
Algorithm
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Visit root node.
Step 3 − Recursively traverse right subtree.
Pre-order Traversal
In this traversal method, the root node is visited first, then the left subtree and finally the right subtree.
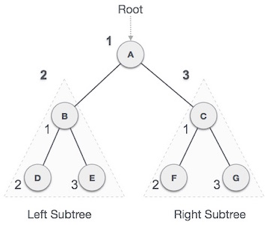
Fig 10: Pre order
We start from A, and following pre-order traversal, we first visit A itself and then move to its left subtree B. B is also traversed pre-order. The process goes on until all the nodes are visited. The output of pre-order traversal of this tree will be −
A → B → D → E → C → F → G
Algorithm
Until all nodes are traversed −
Step 1 − Visit root node.
Step 2 − Recursively traverse left subtree.
Step 3 − Recursively traverse right subtree.
Post-order Traversal
In this traversal method, the root node is visited last, hence the name. First we traverse the left subtree, then the right subtree and finally the root node.
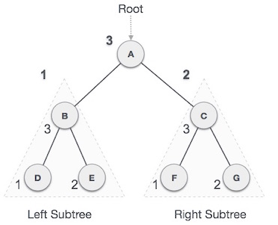
Fig 11: Post order
We start from A, and following Post-order traversal, we first visit the left subtree B. B is also traversed post-order. The process goes on until all the nodes are visited. The output of post-order traversal of this tree will be −
D → E → B → F → G → C → A
Algorithm
Until all nodes are traversed −
Step 1 − Recursively traverse left subtree.
Step 2 − Recursively traverse right subtree.
Step 3 − Visit root node.
Q11) Describe binary tree?
A11) The Binary tree means that the node can have a maximum of two children. Here, the binary name itself suggests 'two'; therefore, each node can have either 0, 1 or 2 children.
Let's understand the binary tree through an example.
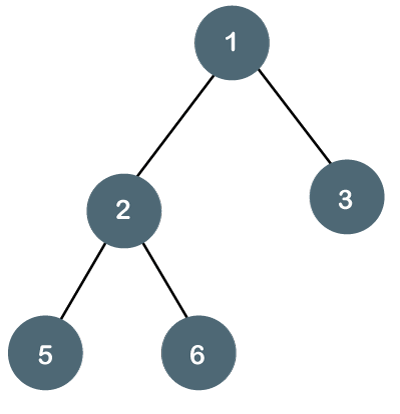
Fig 12: Example
The above tree is a binary tree because each node contains the utmost two children. The logical representation of the above tree is given below:
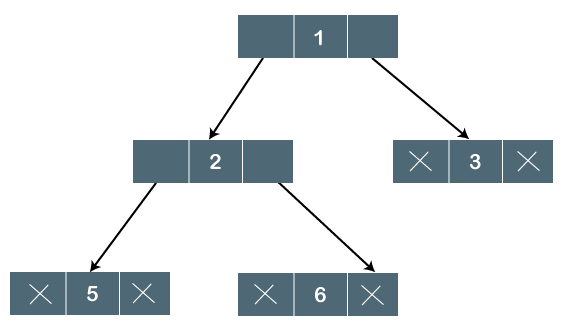
Fig 13: Logical representation
In the above tree, node 1 contains two pointers, i.e., left and a right pointer pointing to the left and right node respectively. The node 2 contains both the nodes (left and right node); therefore, it has two pointers (left and right). The nodes 3, 5 and 6 are the leaf nodes, so all these nodes contain NULL pointer on both left and right parts.
If there are 'n' number of nodes in the binary tree.
The minimum height can be computed as:
As we know that,
n = 2h+1 -1
n+1 = 2h+1
Taking log on both the sides,
Log2(n+1) = log2(2h+1)
Log2(n+1) = h+1
h = log2(n+1) - 1
The maximum height can be computed as:
As we know that,
n = h+1
h= n-1
Types of Binary Tree
There are four types of Binary tree:
● Full/ proper/ strict Binary tree
● Complete Binary tree
● Perfect Binary tree
● Degenerate Binary tree
● Balanced Binary tree
Q12) Write the properties of binary trees?
A12) Properties of Binary Tree
● At each level of i, the maximum number of nodes is 2i.
● The height of the tree is defined as the longest path from the root node to the leaf node. The tree which is shown above has a height equal to 3. Therefore, the maximum number of nodes at height 3 is equal to (1+2+4+8) = 15. In general, the maximum number of nodes possible at height h is (20 + 21 + 22+….2h) = 2h+1 -1.
● The minimum number of nodes possible at height h is equal to h+1.
● If the number of nodes is minimum, then the height of the tree would be maximum. Conversely, if the number of nodes is maximum, then the height of the tree would be minimum.
Q13) What is BST?
A13) A binary search tree is a type of binary tree in which the nodes are organized in a predetermined sequence. This is referred to as an ordered binary tree.
The value of all nodes in the left sub-tree is less than the value of the root in a binary search tree. Similarly, the value of all nodes in the right subtree is larger than or equal to the root's value. This rule will be applied recursively to all of the root's left and right subtrees.
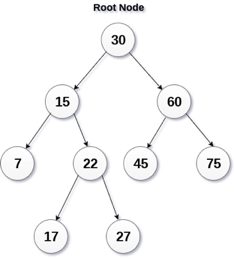
Fig 14: Binary search tree
A Binary Search Tree (BST) is a tree in which all nodes have the properties listed below.
● The key of the left subtree has a lower value than the key of its parent (root) node.
● The value of the right subkey tree's is larger than or equal to the value of the key of its parent (root) node.
● As a result, BST separates all of its sub-trees into two segments: the left and right subtrees, and can be characterized as
Left_subtree (keys) < node (key) ≤ right_subtree (keys)
Q14) What is insertion in BST?
A14) Insertion
The insertion operation in a binary search tree takes O(log n) time to complete. A new node is always added as a leaf node in a binary search tree. The following is how the insertion procedure is carried out...
Step 1: Create a newNode with the specified value and NULL left and right.
Step 2: Make sure the tree isn't empty.
Step 3 - Set root to newNode if the tree is empty.
Step 4 - If the tree isn't empty, see if newNode's value is smaller or larger than the node's value (here it is root node).
Step 5 - Go to the node's left child if newNode is smaller or equal to it. Move to new Nodes right child if the newNode is larger than the node.
Step 6- Continue in this manner until we reach the leaf node (i.e., reaches to NULL).
Step 7 - Once you've reached the leaf node, insert the newNode as a left child if it's smaller or equal to the leaf node, or as a right child otherwise.
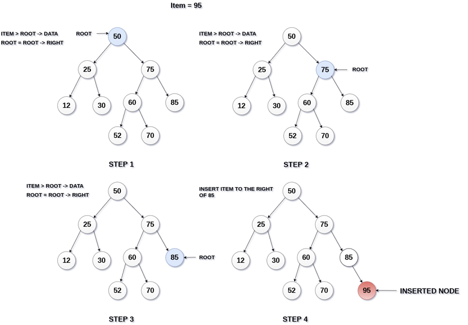
Fig 15: Example of insertion
Q15) Create a Binary Search Tree by adding the integers in the following order… 10,12,5,4,20,8,7,15 and 13?
A15) The following items are added into a Binary Search Tree in the following order...
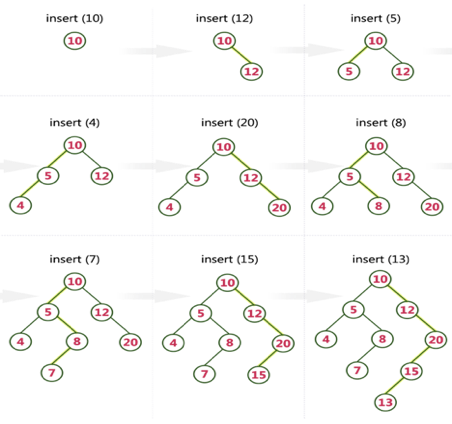
Q16) Define expression tree?
A16) Expression trees are one of the most effective methods for representing language-level code as data stored in a tree-like structure. An expression tree is a representation of a lambda expression in memory. The tree clarifies and transparentes the structure holding the lambda expression. The expression tree was designed to turn code into strings that may be supplied as inputs to other processes. It contains the query's actual elements, rather than the query's actual result.
One of the most essential characteristics of expression trees is that they are immutable, which means that altering an existing expression tree requires creating a new expression tree by copying and updating the existing tree expression. In programming, an expression tree is commonly constructed using postfix expressions, which read one symbol at a time. A one-node tree is formed and a pointer to it is pushed into a stack if the symbol is an operand.
The expression tree is a type of tree that is used to represent different types of expressions. The expressional assertions are represented using a tree data structure. The operators are always represented by the internal node in this tree.
● The operands are always denoted by the leaf nodes.
● These operands are always used in the operations.
● The operator in the deepest part of the tree is always given priority.
● The operator who is not very deep in the tree is always given the lowest priority compared to the operators who are very deep in the tree.
● The operand will always be present at a depth of the tree, making it the most important of all the operators.
● In summary, as compared to the other operators at the top of the tree, the value existing at a depth of the tree has the most importance.
● These expression trees are primarily used to assess, analyse, and modify a variety of expressions.
● It's also utilised to determine each operator's associativity in the phrase.
● The + operator, for example, is left-associative, while the / operator is right-associative.
● Using expression trees, the conundrum of this associativity has been solved.
● A context-free grammar is used to create these expression trees.
● In context-free grammars, we've put a rule in front of each grammar production.
● These rules are also known as semantic rules, and we can easily design expression trees using these semantic rules.
● It is part of the semantic analysis process and is one of the most important aspects of compiler design.
● We will employ syntax-directed translations in our semantic analysis, and we will create an annotated parse tree as output.
● The basic parse associated with the type property and each production rule makes up an annotated parse tree.
● The fundamental goal of using expression trees is to create complex expressions that can be easily evaluated using these trees.
● It's immutable, which means that once we've generated an expression tree, we can't change or modify it.
● It is necessary to completely construct the new expression tree in order to make more changes.
● It's also used to evaluate expressions with postfixes, prefixes, and infixes.
Expression trees are extremely useful for encoding language-level code in the form of data, which is mostly kept in a tree-like structure. It's also used in the lambda expression's memory representation. We can represent the lambda expression more openly and explicitly using the tree data structure. It is first constructed to transform the code segment to the data segment, allowing the expression to be evaluated quickly.
The expression tree is a binary tree in which the operand is represented by the exterior or leaf node and the operators are represented by the internal or parent node. For example, the expression tree for 7 + ((1+8)*3) would be:
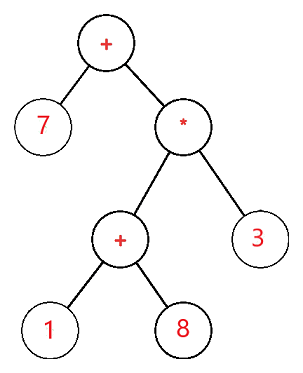
Q17) Write the use of expression tree?
A17) Use of Expression tree
● The fundamental goal of using expression trees is to create complex expressions that can be easily evaluated using these trees.
● It's also used to determine each operator's associativity in the phrase.
● It's also used to evaluate expressions with postfixes, prefixes, and infixes.
Q18) Describe AVL tree?
A18) AVL Tree was invented by GM Adelson - Velsky and EM Landis in 1962. The tree is named AVL in honor of its inventors.
AVL Tree can be defined as a height balanced binary search tree in which each node is associated with a balance factor which is calculated by subtracting the height of its right subtree from that of its left sub-tree.
Tree is said to be balanced if the balance factor of each node is in between -1 to 1, otherwise, the tree will be unbalanced and need to be balanced.
Balance Factor (k) = height (left(k)) - height (right(k))
If balance factor of any node is 1, it means that the left sub-tree is one level higher than the right subtree.
If balance factor of any node is 0, it means that the left subtree and right subtree contain equal height.
If balance factor of any node is -1, it means that the left sub-tree is one level lower than the right subtree.
An AVL tree is given in the following figure. We can see that, balance factor associated with each node is in between -1 and +1. Therefore, it is an example of AVL tree.
Fig 16 – AVL Tree
Complexity
Algorithm | Average case | Worst case |
Space | o(n) | o(n) |
Search | o(log n) | o(log n) |
Insert | o(log n) | o(log n) |
Delete | o(log n) | o(log n) |
Q19) Describe a heap tree?
A19) A binary heap is a data structure that resembles a complete binary tree in appearance. The ordering features of the heap data structure are explained here. A Heap is often represented by an array. We'll use H to represent a heap.
Because the elements of a heap are kept in an array, the position of the parent node of the ith element can be located at i/2 if the starting index is 1. Position 2i and 2i + 1 are the left and right children of the ith node, respectively.
Based on the ordering property, a binary heap can be classed as a max-heap or a min-heap.
Max Heap
A node's key value is larger than or equal to the key value of the highest child in this heap.
Hence, H[Parent(i)] ≥ H[i]
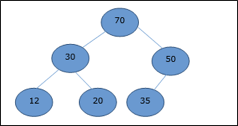
Fig 17: Max heap
Max Heap Construction Algorithm
The technique for creating Min Heap is similar to that for creating Max Heap, only we use min values instead of max values.
By inserting one element at a time, we will derive a method for max heap. The property of a heap must be maintained at all times. We also presume that we are inserting a node into an already heapify tree while inserting.
● Step 1: Make a new node at the bottom of the heap.
● Step 2: Give the node a new value.
● Step 3: Compare this child node's value to that of its parent.
● Step 4: If the parent's value is smaller than the child's, swap them.
● Step 5: Repeat steps 3 and 4 until the Heap property is maintained.
Min Heap
In mean-heap, a node's key value is less than or equal to the lowest child's key value.
Hence, H[Parent(i)] ≤ H[i]
Basic operations with respect to Max-Heap are shown below in this context. The insertion and deletion of elements in and out of heaps necessitates element reordering. As a result, the Heapify function must be used.
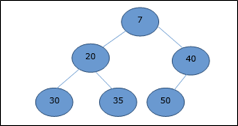
Fig 18: Min heap
Max Heap Deletion Algorithm
Let's create an algorithm for deleting from the maximum heap. The root of the Max (or Min) Heap is always deleted to remove the maximum (or minimum) value.
● Step 1: Remove the root node first.
● Step 2: Move the last element from the previous level to the root.
● Step 3: Compare this child node's value to that of its parent.
● Step 4: If the parent's value is smaller than the child's, swap them.
● Step 5: Repeat steps 3 and 4 until the Heap property is maintained.
Q20) Explain AVL rotations?
A20) AVL Rotations
We perform rotation in AVL tree only in case if Balance Factor is other than -1, 0, and 1. There are basically four types of rotations which are as follows:
- L L rotation: Inserted node is in the left subtree of left subtree of A
- R R rotation: Inserted node is in the right subtree of right subtree of A
- L R rotation: Inserted node is in the right subtree of left subtree of A
- R L rotation: Inserted node is in the left subtree of right subtree of A
Where node A is the node whose balance Factor is other than -1, 0, 1.
The first two rotations LL and RR are single rotations and the next two rotations LR and RL are double rotations. For a tree to be unbalanced, minimum height must be at least 2.
Let us understand each rotation
1. RR Rotation
When BST becomes unbalanced, due to a node is inserted into the right subtree of the right subtree of A, then we perform RR rotation, RR rotation is an anticlockwise rotation, which is applied on the edge below a node having balance factor -2
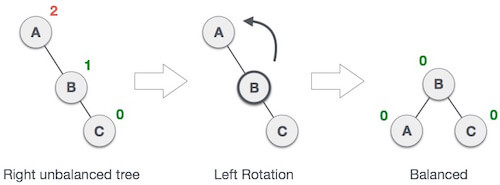
In above example, node A has balance factor -2 because a node C is inserted in the right subtree of A right subtree. We perform the RR rotation on the edge below A.
2. LL Rotation
When BST becomes unbalanced, due to a node is inserted into the left subtree of the left subtree of C, then we perform LL rotation, LL rotation is clockwise rotation, which is applied on the edge below a node having balance factor 2.
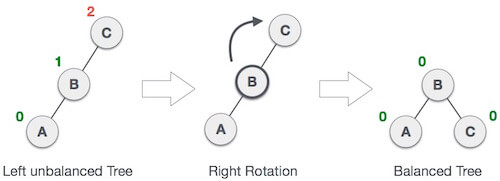
In above example, node C has balance factor 2 because a node A is inserted in the left subtree of C left subtree. We perform the LL rotation on the edge below A.
3. LR Rotation
Double rotations are bit tougher than single rotation which has already explained above. LR rotation = RR rotation + LL rotation, i.e., first RR rotation is performed on subtree and then LL rotation is performed on full tree, by full tree we mean the first node from the path of inserted node whose balance factor is other than -1, 0, or 1.
Let us understand each and every step very clearly:
State | Action |
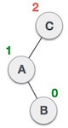 | A node B has been inserted into the right subtree of A the left subtree of C, because of which C has become an unbalanced node having balance factor 2. This case is L R rotation where: Inserted node is in the right subtree of left subtree of C |
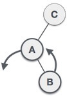 | As LR rotation = RR + LL rotation, hence RR (anticlockwise) on subtree rooted at A is performed first. By doing RR rotation, node A, has become the left subtree of B. |
 | After performing RR rotation, node C is still unbalanced, i.e., having balance factor 2, as inserted node A is in the left of left of C |
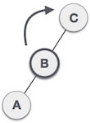 | Now we perform LL clockwise rotation on full tree, i.e. on node C. Node C has now become the right subtree of node B, A is left subtree of B |
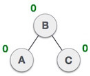 | Balance factor of each node is now either -1, 0, or 1, i.e. BST is balanced now. |
4. RL Rotation
As already discussed, that double rotations are bit tougher than single rotation which has already explained above. R L rotation = LL rotation + RR rotation, i.e., first LL rotation is performed on subtree and then RR rotation is performed on full tree, by full tree we mean the first node from the path of inserted node whose balance factor is other than -1, 0, or 1.
State | Action |
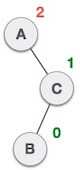 | A node B has been inserted into the left subtree of C the right subtree of A, because of which A has become an unbalanced node having balance factor - 2. This case is RL rotation where: Inserted node is in the left subtree of right subtree of A |
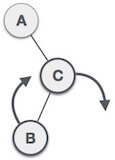 | As RL rotation = LL rotation + RR rotation, hence, LL (clockwise) on subtree rooted at C is performed first. By doing RR rotation, node C has become the right subtree of B. |
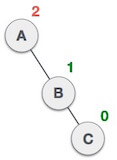 | After performing LL rotation, node A is still unbalanced, i.e. having balance factor -2, which is because of the right-subtree of the right-subtree node A. |
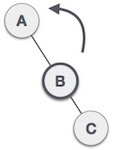 | Now we perform RR rotation (anticlockwise rotation) on full tree, i.e. on node A. Node C has now become the right subtree of node B, and node A has become the left subtree of B. |
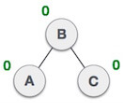 | Balance factor of each node is now either -1, 0, or 1, i.e., BST is balanced now. |




