UNIT 6
Standard Template Library (STL)
Components of STL
1. Containers 2. Algorithms 3. Iterators
Containers- Sequence container and associative containers, container adapters
Containers can be broadly categorized into 3 types :
1. Sequence containers
They store the elements in linear fashion and hence all the elements are accessed sequentially.
They are of three types :
(a) Vector :
Container template class for vector
(b) List
(c) Deque
2. Associative containers
(a) Set
(b) Multiset
(c) Map
(d) Multimap
Duplicate keys are permitted.
3. Derived Containers
(a) Stacks
Container template class for vector and stack
1. push : Inserts element
2. pop : Deletes element
3. size : Returns size of stack
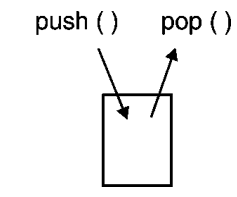
4. empty : test if stack is empty
Fig.
(b) queue

It permits insertion(enqueue)at rear end and deletion(dequeue) at fr
Fig.
(c) Priority Queue
2. Write an Application of Container classes: vector, list
(a) Vector :
Container template class for vector
6. size() : Returns the number of elements in a vector.
7. swap() : Exchanges the elements of two vectors.
8. data() : returns the pointer to first element of vector.
9. insert() : insert element at specified position.
10. erase() : Deletes element from specified position.
(b) List
3. Explain Set operations in detail with examples
Introduction to set
Sets are part of the C++ STL (Standard Template Library). Sets are the associative containers that stores sorted key, in which each key is unique and it can be inserted or deleted but cannot be altered.
Syntax
Parameter
T: Type of element stored in the container set.
Compare: A comparison class that takes two arguments of the same type bool and returns a value. This argument is optional and the binary predicate less<T>, is the default value.
Alloc: Type of the allocator object which is used to define the storage allocation model.
Member Functions
Below is the list of all member functions of set:
Constructor/Destructor
Functions | Description |
(constructor) | Construct set |
(destructor) | Set destructor |
operator= | Copy elements of the set to another set. |
Iterators
Functions | Description |
Begin | Returns an iterator pointing to the first element in the set. |
Cbegin | Returns a const iterator pointing to the first element in the set. |
End | Returns an iterator pointing to the past-end. |
Cend | Returns a constant iterator pointing to the past-end. |
Rbegin | Returns a reverse iterator pointing to the end. |
Rend | Returns a reverse iterator pointing to the beginning. |
Crbegin | Returns a constant reverse iterator pointing to the end. |
Crend | Returns a constant reverse iterator pointing to the beginning. |
Capacity
Functions | Description |
Empty | Returns true if set is empty. |
Size | Returns the number of elements in the set. |
max_size | Returns the maximum size of the set. |
Modifiers
Functions | Description |
Insert | Insert element in the set. |
Erase | Erase elements from the set. |
Swap | Exchange the content of the set. |
Clear | Delete all the elements of the set. |
emplace | Construct and insert the new elements into the set. |
emplace_hint | Construct and insert new elements into the set by hint. |
Observers
Functions | Description |
key_comp | Return a copy of key comparison object. |
value_comp | Return a copy of value comparison object. |
Operations
Functions | Description |
Find | Search for an element with given key. |
count | Gets the number of elements matching with given key. |
lower_bound | Returns an iterator to lower bound. |
upper_bound | Returns an iterator to upper bound. |
equal_range | Returns the range of elements matches with given key. |
Allocator
Functions | Description |
get_allocator | Returns an allocator object that is used to construct the set. |
Non-Member Overloaded Functions
Functions | Description |
operator== | Checks whether the two sets are equal or not. |
operator!= | Checks whether the two sets are equal or not. |
operator< | Checks whether the first set is less than other or not. |
operator<= | Checks whether the first set is less than or equal to other or not. |
operator> | Checks whether the first set is greater than other or not. |
operator>= | Checks whether the first set is greater than equal to other or not. |
swap() | Exchanges the element of two sets. |
4. Explain Heap sort in detail with examples
Heap Sort is based on the binary heap data structure. In the binary heap the child nodes of a parent node are smaller than or equal to it in the case of a max heap, and the child nodes of a parent node are greater than or equal to it in the case of a min heap.
An example that explains all the steps in Heap Sort is as follows.
The original array with 10 elements before sorting is −
20 | 7 | 1 | 54 | 10 | 15 | 90 | 23 | 77 | 25 |
This array is built into a binary max heap using max-heapify. This max heap represented as an array is given as follows.
90 | 77 | 20 | 54 | 25 | 15 | 1 | 23 | 7 | 10 |
The root element of the max heap is extracted and placed at the end of the array. Then max heapify is called to convert the rest of the elements into a max heap. This is done until finally the sorted array is obtained which is given as follows −
1 | 7 | 10 | 15 | 20 | 23 | 25 | 54 | 77 | 90 |
The program to sort an array of 10 elements using the heap sort algorithm is given as follows.
Example
#include<iostream>
using namespace std;
void heapify(int arr[], int n, int i) {
int temp;
int largest = i;
int l = 2 * i + 1;
int r = 2 * i + 2;
if (l < n && arr[l] > arr[largest])
largest = l;
if (r < n && arr[r] > arr[largest])
largest = r;
if (largest != i) {
temp = arr[i];
arr[i] = arr[largest];
arr[largest] = temp;
heapify(arr, n, largest);
}
}
void heapSort(int arr[], int n) {
int temp;
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
for (int i = n - 1; i >= 0; i--) {
temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
heapify(arr, i, 0);
}
}
int main() {
int arr[] = { 20, 7, 1, 54, 10, 15, 90, 23, 77, 25};
int n = 10;
i nt i;
cout<<"Given array is: "<<endl;
for (i = 0; i *lt; n; i++)
cout<<arr[i]<<" ";
cout<<endl;
heapSort(arr, n);
printf("\nSorted array is: \n");
for (i = 0; i < n; ++i)
cout<<arr[i]<<" ";
}
Output
Given array is:
20 7 1 54 10 15 90 23 77 25
Sorted array is:
1 7 10 15 20 23 25 54 77 90
In the above program, the function heapify() is used to convert the elements into a heap. This function is a recursive function and it creates a max heap starting from the element it is called on i.e. i in this case. The code snippet demonstrating this is given as follows.
void heapify(int arr[], int n, int i) {
int temp;
int largest = i;
int l = 2 * i + 1;
int r = 2 * i + 2;
if (l < n && arr[l] > arr[largest])
largest = l;
if (r < n && arr[r] > arr[largest])
largest = r;
if (largest != i) {
temp = arr[i];
arr[i] = arr[largest];
arr[largest] = temp;
heapify(arr, n, largest);
}
}
The function heapSort() of sorts the array elements using heap sort. It starts from the non-leaf nodes and calls the heapify() on each of them. This converts the array into a binary max heap. This is shown as follows −
for (int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i);
After this, the function heapSort() takes the root element in each iteration of the for loop and puts it at the end of the array. Then heapify() is called to make sure the rest of the elements are a max heap. Eventually, all the elements are taken out of the max heap using this method and a sorted array is obtained. This is shown as follows.
for (int i = n - 1; i >= 0; i--) {
temp = arr[0];
arr[0] = arr[i];
arr[i] = temp;
heapify(arr, i, 0);
}
In the function main(), first the array is displayed. Then, the function heapSort() is called to sort the array. This is given by the following code snippet.
cout<<"Given array is: "<<endl;
for (i = 0; i < n; i++)
cout<<arr[i]<<" ";
cout<<endl;
heapSort(arr, n);
Finally, the sorted array is displayed. This is shown below.
printf("\nSorted array is: \n");
for (i = 0; i < n; ++i)
cout<<arr[i]<<" ";
5. What is Iterators- input, output, forward, bidirectional and random access?
1. Input : It performs single pass input operation.
2. Output : It performs single pass output operation.
3. Forward : It performs single pass input/output operation but only in forward direction.
4. Bidirectional : It performs single pass input/output operation in forward and backward direction.
5. Random : It performs single pass input/output operation in forward and backward direction. It has ability to jump to any random arbitrary location.
6. Write short note on Encapsulation
Encapsulation keeps every object’s internal state variables safe from the outside. The ideal case is that your program would consist of “islands of objects” each with their own states passing messages back and forth. This sounds like a good idea in theory if you are building a perfectly distributed system but in practice, designing a program consisting of perfectly self-contained objects is hard and limiting.
Lots of real world applications require solving difficult problems with many moving parts. When you take an OOP approach to design your application, you’re going to run into conundrums like how do you divide up the functionalities of your overall applications between different objects and how to manage interactions and data sharing between different objects. This article has some interesting points about the design challenges OOP applications:
When we consider the needed functionality of our code, many behaviors are inherently cross-cutting concerns and so don’t really belong to any particular data type. Yet these behaviors have to live somewhere, so we end up concocting nonsense doer classes to contain them…And these nonsense entities have a habit of begetting more nonsense entities: when I have umpteen Manager objects, I then need a ManagerManager.
It’s true. I’ve seen “ManagerManager classes” in production software that wasn’t originally designed to be this way has grown in complexity over the years.
As we will see next when I introduce function composition (the alternative to OOP), we have something much simpler than objects that encapsulates its private variables and performs a specific task — it’s called functions!
But before we go there, we need to talk about the last cornerstone of OOP:
7. Explain in brief Polymorphism
Polymorphism let’s us specify behavior regardless of data type. In OOP, this means designing a class or prototype that can be adapted by objects that need to work with different kinds of data. The objects that use the polymorphic class/prototype needs to define type-specific behavior to make it work. Let’s see an example.
Suppose to want to create a general (polymorphic) object that takes some data and a status flag as parameters. If the status says the data is valid (i.e., status === true), a function can be applied onto the data and the result, along with the status flag, will be returned. If the status flags the data as invalid, then the function will not be applied onto the data and the data, along with the invalid status flag, will be returned.
Let’s start with creating a polymorphic prototype object called Maybe:
function Maybe({data, status}) {
this.data = data
this.status = status
}
Maybe is a wrapper for data. To wrap the data in Maybe, we provide an additional field called status that indicates if the data is valid or not.
We can make Maybe a prototype with a function called apply, which takes a function and applies it on the data only if the status of the data indicates that it is valid.
Maybe.prototype.apply = function (f) {
if(this.status) {
return new Maybe({data: f(this.data), status: this.status})
}
return new Maybe({data: this.data, status: this.status})
}
We can add another function to the Maybe prototype which gets the data or returns a message if there’s an error with the data.
Maybe.prototype.getOrElse = function (msg) {
if(this.status) return this.data
return msg
}
Now we create two objects from the Maybe prototype called Number:
function Number(data) {
let status = (typeof data === 'number')
Maybe.call(this, {data, status})
}
Number.prototype = Object.create(Maybe.prototype)
and String:
function String(data) {
let status = (typeof data === ‘string’)
Maybe.call(this, {data, status})
}
String.prototype = Object.create(Maybe.prototype)
Let’s see our objects in action. We create a function called increment that’s only defined for numbers and another function called split that’s only defined for strings:
const increment = num => num + 1
const split = str => str.split('')
Because JavaScript is not type safe, it won’t prevent you from incrementing a string or splitting a number. You will see a runtime error when you uses an undefined method on a data type. For example, suppose we try the following:
let foop = 12
foop.split('')
That’s going to give you a type error when you run the code.
However, if we used our Number and String objects to wrap the numbers and strings before operating on them, we can prevent these run time errors:
let numValid = new Number(12)
let numInvalid = new Number(“foo”)
let strValid = new String(“hello world”)
let strInvalid = new String(-1)let a = numValid.apply(increment).getOrElse('TypeError!')
let b = numInvalid.apply(increment).getOrElse('TypeError Oh no!')
let c = strValid.apply(split).getOrElse('TypeError!')
let d = strInvalid.apply(split).getOrElse('TypeError :(')
What will the following print out?
console.log({a, b, c, d})
Since we designed our Maybe prototype to only apply the function onto the data if the data is the right type, this will be logged to console:
{
a: 13,
b: ‘TypeError Oh no!’,
c: [ 'h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd' ],
d: ‘TypeError :(‘
}
What we just did is a type of a monad (albeit I didn’t implement Maybe to follow all the monad laws). The Maybe monad is a wrapper that’s used when a value can be absent or some validation can fail and you don’t care about the exact cause. Typically this can occur during data retrieval and validation. Maybe handles failure in validation or failure in applying a function similar to the try-catch you’ve likely seen before. In Maybe, we are handling the failure in type validation by printing to a string, but we can easily revise the getOrElse function to call another function which handles the validation error.
Some programming languages like Haskell come with a built-in monad type, but in JavaScript, you have to roll your own. ES6 introduced Promise, which is a monad for dealing with latency. Sometimes you need data that could take a while to retrieve. Promise lets you write code that appears synchronous while delaying operation on the data until the data becomes available. Using Promise is a cleaner way of asynchronous programming than using callback functions, which could lead to a phenomenon called the callback hell.
8. Explain in brief Composition
As alluded to earlier, there’s something much simpler than class/prototypes which can be easily reused, encapsulates internal states, performs a given operation on any type of data, and be polymorphic — it’s called functional composition.
JavaScript easily lets us bundle related functions and data together in an object:
const Person = {
firstName: 'firstName',
lastName: 'lastName',
getFullName: function() {
return ${this.firstName} ${this.lastName}
}
}
Then we can use the Person object directly like this:
let person = Object.create(Person)person.getFullName() //> “firstName lastName”// Assign internal state variables
person.firstName = 'Dan'
person.lastName = 'Abramov'// Access internal state variables
person.getFullName() //> “Dan Abramov”
Let’s make a User object by cloning the Person object, then augmenting it with additional data and functions:
const User = Object.create(Person)
User.email = ''
User.password = ''
User.getEmail = function() {
return this.email
}
Then we can create an instance of user using Object.create
let user = Object.create(User)
user.firstName = 'Dan'
user.lastName = 'Abramov'
user.email = 'dan@abramov.com'
user.password = 'iLuvES6'
A gotcha here is use Object.create whenever you want to copy. Objects in JavaScript are mutable so when you straight out assigning to create a new object and you mutate the second object, it will change the original object!
Except for numbers, strings, and boolean, everything in JavaScript is an object.
// Wrong
const arr = [1,2,3]
const arr2 = arr
arr2.pop()
arr //> [1,2]
In the above example, I used const to show that it doesn’t protect you from mutating objects. Objects are defined by their reference so while const prevents you from reassigning arr, it doesn’t make the object “constant”.
Object.create makes sure we are copying an object instead of passing its reference around.
Like Lego pieces, we can create copies of the same objects and tweak them, compose them, and pass them onto other objects to augment the capability of other objects.
For example, we define a Customer object with data and functions. When our User converts, we want to add the Customer stuff to our user instance.
const Customer = {
plan: 'trial'
}
Customer.setPremium = function() {
this.plan = 'premium'
}
Now we can augment user object with an Customer methods and fields.
User.customer = Customer
user.customer.setPremium()
After running the above two lines of codes, this becomes our user object:
{
firstName: 'Dan',
lastName: 'Abramov',
email: 'dan@abramov.com',
password: 'iLuvES6',
customer: { plan: 'premium', setPremium: [Function] }
}
When we want to supply a object with some additional capability, higher order objects cover every use case.
Classical inheritance creates is-a relationships with restrictive taxonomies, all of which are eventually wrong for new use-cases. But it turns out, we usually employ inheritance for has-a, uses-a, or can-do relationships.




