Unit - 3
Estimation and Scheduling
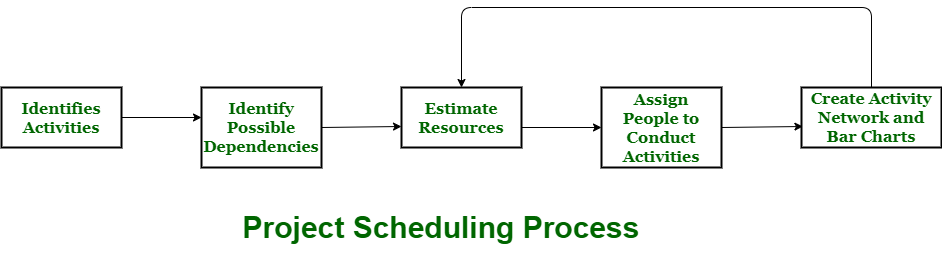
Q. 1) Explain project scheduling ? and also write the advantages ?
Sol : Project scheduling -
A schedule in the time table of your project actually consists of sequenced tasks and goals that need to be delivered within a given time span.
Project schedule essentially means a process that is used to communicate and understand that tasks are important and must be completed or carried out and which organisational resources are provided or allocated to these tasks and in what time span or time frame work is expected to be performed.
Successful scheduling of tasks leads to project performance, decreased costs, and improved customer satisfaction. In project management, scheduling means listing tasks, deliverables, and objectives that are delivered within a project. It includes more notes than your weekly planner's average notes. The Gantt chart is the most prevalent and significant form of project schedule.
Advantages of project scheduling -
In our project management, there are many benefits offered by the project schedule:
● It basically ensures that everyone stays on the same page as far as duties, dependencies, and deadlines are completed.
● It helps to recognise problems early on and issues such as resource shortage or unavailability.
● It also helps to establish relationships and process monitoring.
● It offers efficient control of budgets and risk reduction.
Q. 2) What are the requirements to prepare a Traceability matrix ? listed the types of Traceability matrix ?
Sol : Traceability matrix -
In the Requirement Traceability Matrix or RTM, we set up a process to record the relations between the client's suggested user specifications and the system being designed. In short, it is a high-level document that maps and traces user specifications with test cases to ensure that appropriate testing levels are accomplished with each and every requirement.
The method for evaluating all test cases specified for each requirement is called Traceability. Traceability helps us to assess which specifications have produced the most defects during the phase of testing.
Full test coverage is and should be the focus of every research interaction. It literally means, by coverage, that we need to test anything that needs to be tested. 100 percent test coverage should be the goal of every research project.
Requirements The Traceability Matrix offers a way to ensure that the coverage element is tested. It helps to define coverage gaps by providing a snapshot. In short, it can also be referred to as metrics that specify for each requirement the number of test cases run, passed, failed or blocked, etc.
Types of Traceability Matrix
Requirements for test cases of 'Forward Traceability'. It guarantees that the project is moving according to the desired path and that every condition is thoroughly tested.
2. Backward Traceability :
With the 'Backward Traceability' criteria, the test cases are mapped. Its primary objective is to ensure that the new product being produced is on the right track. It also helps to decide that no additional undefined features are implemented and the project's scope is therefore affected.
3. Bi-Directional Traceability :
Q. 3) Explain LOC based estimation and object point based estimation ?
Sol :
Method Lines of Code (LOC) tests software and the mechanism by which it is produced. Until a software estimation is made, it is critical and appropriate to understand and estimate the size of the software scope.
Lines of Code (LOC) is a direct approach method which, by decomposition and partitioning, involves a higher degree of detail. In comparison, Feature Points (FP) is an indirect approach method where it focuses on the domain characteristics instead of focusing on the function.
Using the following formula, an estimated value is then computed.
Where,
● EV - estimation variable.
● Sopt - optimistic estimate.
● Sm - most likely estimate.
● Spess - pessimistic estimate.
It is known that there is a very small chance that the effects of the actual size will fall beyond the value of optimism or pessimism.
Contemporary LOC or FP data are applied after the estimated value for the estimation variable has been determined, and personal months, costs etc. are measured using the following formula.
Productivity = KLOC / Person-month
Quality = Defects / KLOC
Cost = $ / LOC
Documentation = pages of documentation / KLOC
Where,
KLOC - no. of lines of code (in thousands).
Person-month - time(in months) taken by developers to finish the product.
Defects - Total Number of errors discovered
Object point is an alternative measure similar to feature points when the same language is used for growth. OP's are not the same as classes of objects.
A weighted calculation of the number of OPs in a programme is
● The number of different displays that will be shown.
● The number of reports that the device generates.
As they are simply concerned with displays, reports and 3GL modules, OPs are easier to estimate from a specification than feature points.
Consequently, they may be evaluated at an early stage in the production process. At this point, estimating the number of lines of code in a system is very difficult.
Q. 4) what do you mean by Estimation with use cases ?
Sol : Estimation with use cases -
You probably thought there should be a simple way to measure the total size of a project from all the effort that went into writing the use cases if you dealt with use cases. The relationship between use cases and code is evident in that complicated use cases normally take longer than simple use cases to code. Fortunately, there is an approach to calculating and preparing case points for use.
Use case points calculate the size of an application, close in definition to feature points. Once we know the estimated size of an application, if we also know (or can estimate) the rate of progress of the team, we can derive an anticipated timeline for the project.
The number of case points for use in a project depends on the following:
● The number and sophistication of the system's use cases
● The number and sophistication of participants in the system
● Different non-functional specifications (such as portability, performance,
Maintenance) which are not written as use cases
● The atmosphere in which the project will be built (such as the language, enthusiasm of the team, etc.)
Five levels for use cases are identified: very high overview, summary, user goal, subfunction, and too low. The very high overview and summary usage cases of Cockburn are useful for establishing the framework under which cases of lower-level use work.
Q. 5) Describe the Project Planning Process ?
Sol : Project Planning Process -
Project Planning is an organized and integrated management process, which focuses on activities required for successful completion of the project. Planning is undertaken and completed even before any development activity starts.
Project preparation for software is a task that is carried out before software development actually begins. It is there for the development of software but does not involve any specific operation linked to software production in any direction; rather, it is a collection of multiple processes that encourage software production.
Estimating the subsequent attributes of the project
● Project Size: What’s going to be the size of the project?
● Cost: How much is it going to cost to develop the software?
● Duration: How long will it take to develop the complete project?
● Effort: What proportion of effort would be required to develop a project?
The effectiveness of the following relies on the accuracy of those estimations.
● Planning force and alternative resources
● Workers organization and staffing plans
● Risk identification, analysis and designing
● Miscellaneous activities such as configuration, quality assurance plan, management, etc.
Estimating the project could include the following:
● Size of software
● Software quality
● Hardware
● Additional software or tools, licenses etc.
● Skilled personnel with task-specific skills
● Travel involved
● Communication
● Training and support
Q. 6) Defining Software Scope and Checking Feasibility ?
Sol : Scope -
The spectrum of applications determines -
- The functions and features that are to be given to end users.
- The input and output data from the machine.
- Content that is given to users as a result of the programme being used.
- Performance, constraints, interfaces and system-bound reliability.
Scopes can be described by two methods -
- After consultation with all stakeholders, a narrative description of the software scope is developed.
- End users build a set of use cases.
-
Two questions are asked after the scope has been established
- Can we develop applications to comply with this range?
- Is the project practicable?
-
Too frequently, software developers hurry through these issues.
Feasibility -
Feasibility is discussed until the scope is resolved.
Four dimensions of software viability—
- Technology : Technically, is the project feasible? Is it just the state of the art? Can vulnerabilities be minimised to a degree that suits the needs of the application?
- Finance : Is it financially achievable? Can production be done at an expense that can be afforded by the software enterprise, its customer, or the market?
- Time : Can the time-to-market of the project beat the competition?
- Resources : Does the software organisation have the resources available to do the project successfully?
Q.7) What do you mean by problem- based Estimation ?
Sol : Start with a restricted declaration of scope .Decompose the programme into problem functions that can be independently calculated for each one. For each function, compute a LOC or FP value. By adding the LOC or FP values to the base productivity metrics (e.g. LOC/person-month or FP/person-month) to extract cost or effort estimates. Merge for the whole project.
LOC and FP estimation are different estimation methods, but both have a number of characteristics in common. The project manager starts with a restricted software scope statement and tries to decompose software into problem functions that can be independently calculated from this statement. LOC or FP (the estimation variable) is then estimated for each function.
It is then possible to compute a three-point or predicted value. The expected value can be calculated as a weighted average of the positive (sopt), most likely (sm), and pessimistic (spess) estimates for the estimation variable (size), S.
For instance,
S = (sopt + 4sm + spess)/6
Q.8) write the difference between process based and problem based estimation?
Sol : Problem based estimation:
● Begins with a statement of scope.
● The software is decomposed into problem functions.
● Estimating FP or LOC.
● Combine those estimates and produce an overall estimate.
Process based estimation:
● The functions of the software are identified.
● The framework is formulated.
● Estimate effort to complete each software function.
● Apply average labor rates, compute the total cost and compare the estimates.
Q. 9) Describe the COCOMO II model ?
Sol : COCOMO model II -
The updated version of the original Cocomo (Constructive Cost Model) is COCOMO-II, which was produced at the University of Southern California. It is the model that helps us, when planning a new software development activity, to estimate the cost, effort and schedule.
It is composed of three sub-models:
Under this sub-model, application generators are used. By using these programme generators, the end user writes the code.
Example – Spreadsheets, report generator, etc.
2. Intermediate sector
This category would create essentially prepackaged user programming capabilities.There will be several reusable components in their brand. Typical companies operating in this industry are Microsoft, Lotus, Oracle, IBM, Borland, Novell.
This group is too diversified and pre-packaged solutions must be addressed. It includes Interface, databases, domain-specific components such as packages for control of financial, medical or industrial processes.
Large scale and highly embedded systems are discussed in this category.
3 . Infrastructure sector
This class provides software development infrastructure such as the Operating System, Database Management System, User Interface Management System, Networking System, etc.
Q.10) Define Process based Estimation ?
Sol : Process based Estimation -
The most popular way of estimating a project is to base the estimation on the method that will be used. That is, the method is broken down into a relatively small set of tasks and it calculates the effort needed to accomplish each task.
Process-based estimation starts, like problem-based techniques, with a delineation of software functions obtained from the scope of the project. For each function, a sequence of software process operations must be performed.
Functions and related activities of the software process can be described as part of a table .
When problem functions and process activities are melded, the planner calculates the effort needed to execute each software process operation for each software function (e.g., person-months). These data constitute the table's core matrix.
The calculated effort for each process operation is then compared to average labour rates (i.e., cost/unit effort). For each job, it is very possible that the labour rate would differ. In general, senior employees heavily involved in early operations are more expensive than junior employees involved in later design projects, code creation, and early testing.




