Unit - 6
Memory Management
Q1) Introduce memory management?
A1) Memory management is the functionality of an operating system which handles or manages primary memory and moves processes back and forth between main memory and disk during execution. Memory management keeps track of each and every memory location, regardless of either it is allocated to some process or it is free. It checks how much memory is to be allocated to processes. It decides which process will get memory at what time. It tracks whenever some memory gets freed or unallocated and correspondingly it updates the status.
Memory management, as the name suggests, is the administration of a computer's physical memory, also known as random access memory (RAM). Memory management's main goal is to dynamically distribute memory across all operating processes for optimal performance. Because each computer comes with preinstalled primary memory for running applications, no matter how large the memory capacity is, it cannot handle all of the running processes at the same time. Essentially, this is the process of directing and organizing computer memory by allocating some of the primary memory (blocks) to a running process or program. When the program request for the block of memory then the allocator assign memory block of the required size to the program.
When the main memory available for a program and its data is insufficient, the programmer may use a technique known as overlaying. It enables many modules to be allocated to the same memory region. One downside is that it takes a long time for the programmer to complete. The programmer in a multiprogramming environment has no idea how much memory will be accessible at the time of coding or where that memory will be located.
The operating system occupies a portion of memory in a multiprogramming computer, while the rest is used by many processes. Memory management is the practice of dividing memory across many operations. Memory management is an operating system approach for coordinating actions between main memory and disk during the execution of a task. The primary goal of memory management is to maximize memory use.
Q2) What are the requirements of memory management?
A2) Memory management keeps track of whether each memory region is allocated or unallocated. It dynamically allocates memory to applications upon their request and releases it for reuse when it is no longer required. Memory management was created to meet a set of requirements that we must remember.
These are the memory management requirements:
Relocation –
Because available memory in a multiprogramming system is usually shared among several processes, it is impossible to predict which other programs will be running in main memory at the time his program is executed. The operating system can have a larger pool of ready-to-execute processes by swapping active processes in and out of main memory.
When a program is swapped out to disk memory, it is not always possible for it to reclaim the prior memory position when it is swapped back into main memory, because the space may still be held by another process. It's possible that we'll have to move the process to a different part of the brain. As a result, swapping may cause the program to be transferred into main memory.
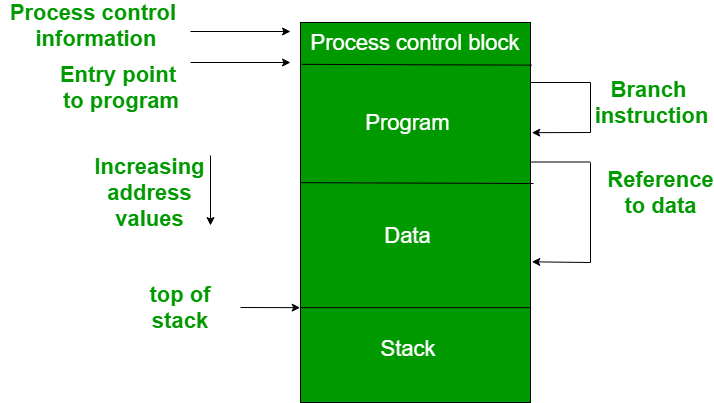
Fig 1: Memory management requirement
A process image is depicted in the diagram. A continuous section of main memory is occupied by the process image. Many things will be required of the operating system, including the location of process control information, the execution stack, and code entry. Memory references in various instructions inside a program are referred to as logical addresses.
The processor and operating system must be able to transform logical addresses into physical addresses after the program is loaded into main memory. The address of the next instruction to be performed is contained in branch instructions. The address of the byte or word of data referred is contained in data reference instructions.
Protection -
When we run numerous programs at the same time, there is always the risk that one of them will write to the address space of another. As a result, every process must be protected from undesired interference when another process tries to write in it, whether intentionally or unintentionally. A trade-off exists between the relocation and protection requirements, as achieving the relocation requirement increases the difficulty of satisfying the protection requirement.
Because it is impossible to predict a program's position in main memory, checking the absolute address at compile time to provide protection is impossible. The majority of programming languages allow for dynamic address computation during runtime. Because the operating system can't control a process when it occupies the CPU, the memory protection requirement must be met by the processor rather than the operating system. As a result, the correctness of memory references may be verified.
Sharing -
To allow multiple processes to access the same section of main memory, a protection mechanism is required. Rather than having their own distinct copy of the program, allowing each process access to the same copy has an advantage.
For example, if several processes use the same system file, it is logical to load one copy of the file into main memory and share it among them. Memory management's job is to enable for regulated access to shared memory locations without jeopardizing security. Mechanisms are in place to allow relocation-assisted sharing.
Logical organization -
Main memory is either arranged in a linear fashion or as a one-dimensional address space made up of a series of bytes or words. The majority of the programs can be divided into modules, with some being unmodifiable (read-only, execute-only) and others containing data that can be changed. The operating system and computer hardware must provide a basic module to provide the appropriate protection and sharing when dealing with a user program.
It offers the following benefits:
● Modules are developed and compiled individually, and the system resolves all references from one module to another at run time.
● Different levels of protection are offered for different modules.
● Modules can be shared between processes via several ways. Sharing can be enabled on a module-by-module basis, allowing the user to decide the level of sharing they want.
Physical organization -
The main memory and secondary memory levels of computer memory are divided into two categories. When compared to secondary memory, main memory is both quick and expensive. The main memory is a volatile resource. As a result, secondary memory is given for long-term data storage, while the main memory is used to store currently running programs.
The flow of information between main memory and secondary memory is the most important system concern, and understanding it is difficult for programmers for two reasons:
● When the main memory available for a program and its data is insufficient, the programmer may use a technique known as overlaying. It enables many modules to be allocated to the same memory region. One downside is that it takes a long time for the programmer to complete.
● The programmer in a multiprogramming environment has no idea how much memory will be accessible at the time of coding or where that memory will be located.
Q3) What is fixed partitioning?
A3) Fixed partitioning, often known as contiguous memory allocation, is the oldest and most basic mechanism for loading many processes into the main memory.
The main memory is partitioned into divisions of equal or different sizes using this technique. The operating system is always stored in the first partition, whereas user processes can be stored in the other partitions. The RAM is allocated to the processes in a logical order.
When it comes to fixed partitioning,
● The dividers can't be stacked on top of each other.
● For execution, a process must be present in a partition in a continuous state.
Advantages
- Easy to implement - The algorithms required to implement Fixed Partitioning are simple to code. It merely entails assigning a process to a partition without regard for the formation of Internal and External Fragmentation.
- Little OS overhead - Fixed Partitioning processing necessitates less extra and indirect computational power.
Disadvantages
- Internal fragmentation - The utilization of main memory is inefficient. Any application, whatever of size, takes up a full partition. Internal fragmentation may result as a result of this.
- External fragmentation - Even when there is space available but not in a contiguous manner, the total unused space (as described above) of various partitions cannot be used to load the processes (as spanning is not allowed).
- Limit process size - Processes with a size greater than the partition size in Main Memory are not supported. The partition size cannot be adjusted to match the size of the incoming process. As a result, the 32MB process size in the above example is invalid.
- Degree of multiprogramming is less - The greatest number of processes that can be loaded into memory at the same time is referred to as the degree of multiprogramming. Because the size of the partition cannot be modified according to the quantity of processes, the degree of multiprogramming is fixed and very low in fixed partitioning.
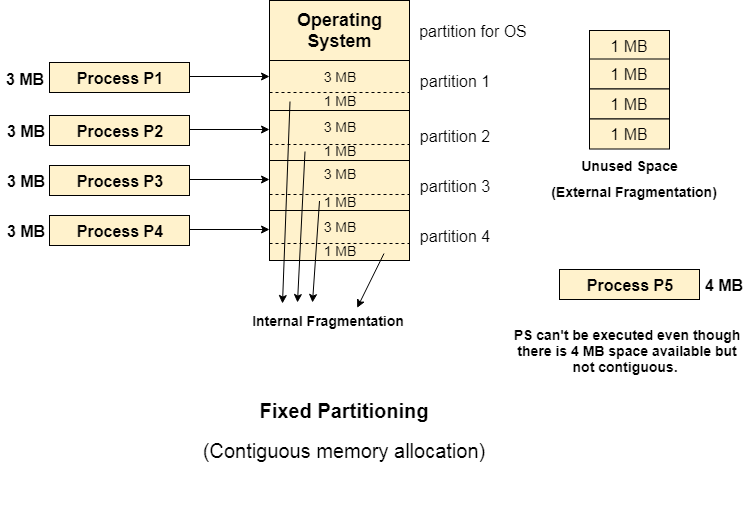
Fig 2: Fixed partitioning
Q4) Explain dynamic partitioning?
A4) Processes with a size greater than the partition size in Main Memory are not supported. The partition size cannot be adjusted to match the size of the incoming process. As a result, the 32MB process size in the above example is invalid.
The greatest number of processes that can be loaded into memory at the same time is referred to as the degree of multiprogramming. Because the size of the partition cannot be modified according to the quantity of processes, the degree of multiprogramming is fixed and very low in fixed partitioning.
Variable Partitioning has a number of characteristics.
● Instead of partitioning during system configuration, RAM is initially empty and partitions are made during run-time according to the needs of the processes.
● The partition will be the same size as the incoming process.
● The partition size varies depending on the process's requirements in order to avoid internal fragmentation and maximize RAM utilization.
● The number of RAM partitions is not fixed and is determined by the number of incoming processes and the size of Main Memory.
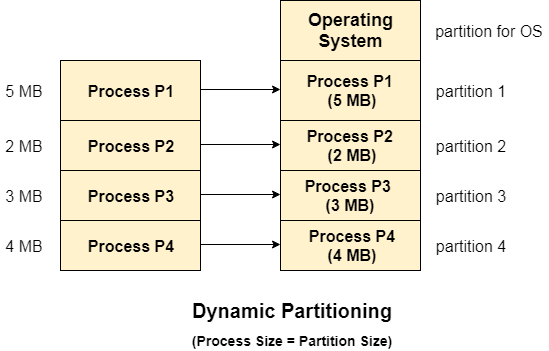
Fig 3: Dynamic partitioning
Advantages
- No internal fragmentation - Given that dynamic partitioning creates partitions based on the needs of the process, it is apparent that internal fragmentation will not occur because there will be no unused residual space in the partition.
- No limitation on the size of the process - Fixed partitioning prevents processes with sizes bigger than the largest partition from being loaded and divided, as this is invalid in the contiguous allocation technique. The process size cannot be limited in variable partitioning since the partition size is determined by the process size.
- Degree of multiprogramming is dynamic - Because there is no internal fragmentation, a greater number of processes can be accommodated. A process can be loaded indefinitely until memory is depleted.
Disadvantages
- Difficult Implementation - Variable implementation Partitioning is more complicated than Fixed Partitioning because it includes memory allocation during run-time rather than during system configuration.
- External fragmentation - Even if there is no internal fragmentation, there will be outward fragmentation. Assume that in the preceding example, processes P1(2MB) and P3(1MB) have completed their execution. As a result, two spaces remain: 2MB and 1MB. Assume that process P5 with a size of 3MB arrives. Because no spanning is allowed in contiguous allocation, the empty memory space cannot be assigned. To be run, the rule states that the process must be continuously present in main memory. As a result, External Fragmentation occurs.
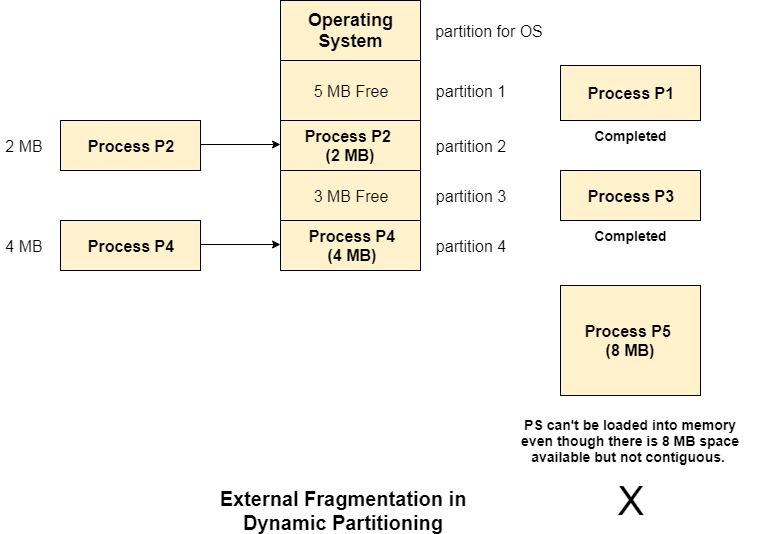
Fig 4: External fragmentation in dynamic partitioning
Q5) Write short notes on fragmentation?
A5) The free memory space is divided up into little bits as processes are loaded and withdrawn from memory. Sometimes, due to their small size, processes are unable to be assigned to memory blocks, and memory blocks stay unused. Fragmentation is the term for this issue.
There are two forms of fragmentation.
1. External fragmentation - Although total memory space is sufficient to satisfy a request or to house a process, it is not contiguous and hence cannot be utilized.
2. Internal fragmentation - The memory block allotted to the process is larger. Because it cannot be used by another process, some memory is left unused.
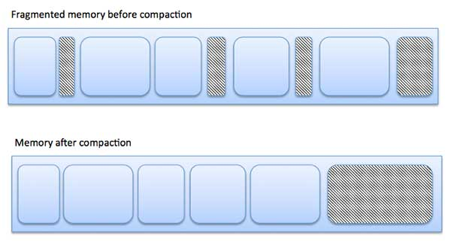
Fig 5: Fragmentation
The picture below illustrates how fragmentation can lead to memory waste and how a compaction technique can be used to extract more free memory from fragmented memory.
Compaction or shuffle memory contents to place all free memory in one large block can reduce external fragmentation. Relocation must be dynamic in order for compaction to be possible.
Internal fragmentation can be minimized by designating the smallest partition that is yet large enough for the process.
Q6) Write about paging?
A6) More memory can be addressed by a computer than is physically installed on the machine. This additional memory is known as virtual memory, and it is a part of a hard drive configured to simulate the computer's RAM. In order to implement virtual memory, the paging approach is crucial.
Paging is a memory management approach in which the process address space is divided into uniformly sized pieces known as pages (size is power of 2, between 512 bytes and 8192 bytes). The number of pages in the procedure is used to determine its size.
Similarly, main memory is partitioned into small fixed-size blocks of (physical) memory called frames, with the size of a frame being the same as that of a page in order to maximize main memory utilization and avoid external fragmentation.
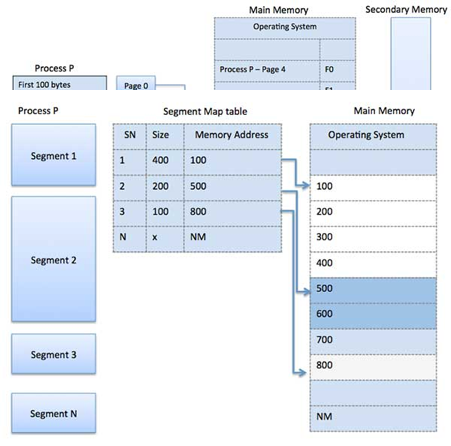
Fig 6: Paging
Q7) What is segmentation?
A7) Segmentation is a memory management strategy in which each job is broken into numerous smaller segments, one for each module, each of which contains parts that execute related functions. Each segment corresponds to a different program's logical address space.
When a process is ready to run, its associated segmentation is loaded into non-contiguous memory, though each segment is placed into a contiguous block of available memory.
Memory segmentation is similar to paging, except that segment are changeable in length, whereas paging pages are fixed in size. The program's main function, utility functions, data structures, and so on are all contained within a program segment. For each process, the operating system keeps a segment map table and a list of free memory blocks, together with segment numbers, sizes, and memory addresses in main memory.
The table stores the segment's starting address as well as its length for each segment. A value that identifies a segment and an offset are included in a reference to a memory location.
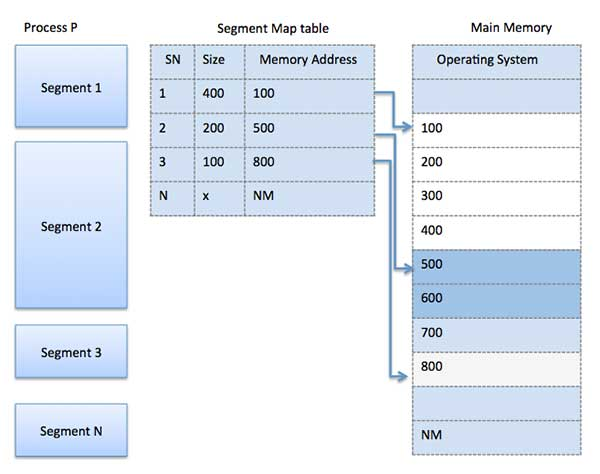
Fig 7: Segmentation
Q8) Define Address translation?
A8) The logical address of a page is represented by the page number and the offset.
Logical Address = Page number + page offset
A frame address is also known as a physical address, and it is made up of a frame number and an offset.
Physical Address = Frame number + page offset
To keep track of the relationship between a page of a process and a frame in physical memory, a data structure called a page map table is utilized.
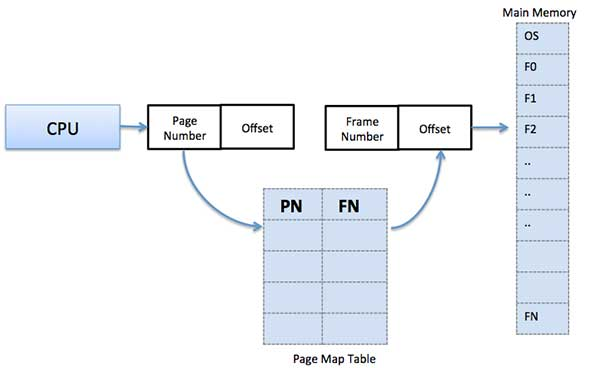
Fig 8: Relationship between a page of a process and a frame in physical memory
When the system assigns a frame to a page, it converts the logical address to a physical address and creates an entry in the page table that will be used throughout the program's execution.
When a process is to be run, its associated pages are loaded into any memory frames that are accessible. If you have an 8Kb software but your memory can only hold 5Kb at a given moment, you'll need to use the paging idea. When a computer's RAM runs out, the operating system (OS) moves idle or undesired pages of memory to secondary memory to free up RAM for other activities, then restores them when the program requires them.
This process continues throughout the program's execution, with the OS removing idle pages from main memory, writing them to secondary memory, and then bringing them back when the application requires them.
Q9) Describe placement strategies?
A9) When there are multiple partitions available to meet a process's request, a partition must be chosen in Partition Allocation. A partition allocation method is required to select a specific partition. Internal fragmentation is avoided with a better partition allocation approach.
When it's time to load a process into main memory, the OS chooses which free block of memory to allocate if there are multiple free blocks of adequate size.
Different Placement Algorithms exist:
- First Fit
- Best Fit
- Worst Fit
- Next Fit
First fit -
The partition is allocated in the first fit, which is the first sufficient block from the top of Main Memory. It starts scanning memory from the beginning and selects the first large enough block accessible. As a result, it assigns the first large enough hole.
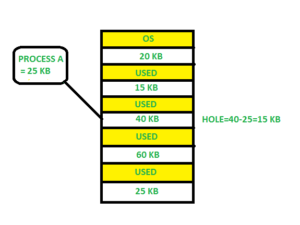
Fig 9: First fit
Best fit -
Allocate the process to the partition that is the first smallest and most suitable among the free partitions. It examines the whole list of holes for the smallest one that is larger than or equal to the process's size.
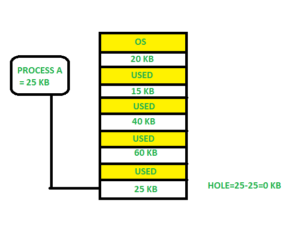
Fig 10: Best fit
Worst fit -
Allocate the process to the partition in the main memory that is the largest and most suitable among the free partitions. It works in the opposite direction of the best-fit algorithm. It looks through the complete list of holes to find the biggest one and assign it to processing.
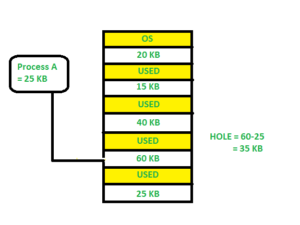
Fig 11: Worst fit
Next fit -
Next fit is similar to first fit, but it will search from the last allocation point for the first sufficient partition.
Q10) Explain virtual machines?
A10) Virtual memory is a memory management functionality of an operating system (OS) that utilizes hardware and software to enable a computer to make up for physical
Memory deficiencies by incidentally moving data from random access memory (RAM) to disk storage.
● Virtual address space is expanded utilizing active memory in RAM and inactive memory in hard disk drives (HDDs) to frame contiguous addresses that hold both the application and its data.
● Virtual Memory is a storage allocation plot in which secondary memory can be tended to just as it were a piece of main memory.
● The addresses a program may use to reference memory are recognized from the addresses the memory system uses to distinguish physical storage locales, and program created addresses are interpreted consequently to the relating machine addresses.
● The size of virtual storage is constrained by the addressing plan of the computer system and the measure of secondary memory is accessible not by the genuine number of the main storage locations.
● Virtual memory was created when physical memory - the installed RAM - was costly.
● Computers have a limited measure of RAM, so memory can run out, particularly when numerous programs keep running simultaneously.
● A system utilizing virtual memory utilizes a segment of the hard drive to copy RAM. With virtual memory, a system can stack bigger programs or various programs running simultaneously, enabling everyone to work as though it has vast memory and without obtaining more RAM.
● While duplicating virtual memory into physical memory, the OS partitions memory into page files or swap files with a fixed number of addresses. Each page is put away on a disk and when the page is required, the OS copies it from the disk to fundamental memory and makes an interpretation of the virtual addresses into real addresses.
● Current microprocessors expected for universally useful use, a memory management unit, or MMU, is incorporated with the hardware.
● The MMU's main responsibility is to interpret a virtual address into a physical address. A fundamental model is given underneath −
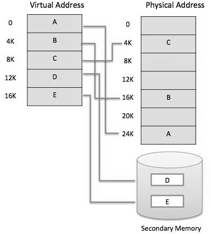
Fig 12: Memory address
● It is a procedure that is actualized utilizing both hardware and software. It maps memory addresses utilized by a program, called virtual addresses computers, into physical addresses in c memory.
- All memory references inside a process are logical addresses that are powerfully converted into physical addresses at run time. This implies a process can be swapped all through fundamental memory with the end goal that it involves better places in primary memory at various times throughout execution.
- A process might be broken into some pieces and these pieces need not be constantly situated in the main memory during execution. The blend of dynamic run-time address interpretation and utilization of page or portion table allows this.
● On the off chance that these attributes are available, at that point, not every one of the pages or portions do not have to be available in the main memory during execution. This implies the required pages should be stacked into memory at whatever point is required.
● Virtual memory is designed utilizing Demand Paging or Demand Segmentation.
Q11) Write about Swapping
A11) Swapping is a mechanism for temporarily moving a process from main memory to secondary storage (disk) and making that memory available to other processes. The system switches the process from secondary storage to main memory at a later time.
Though the swapping process degrades performance, it aids in the concurrent execution of various and large processes, which is why it's also known as a memory compression approach.
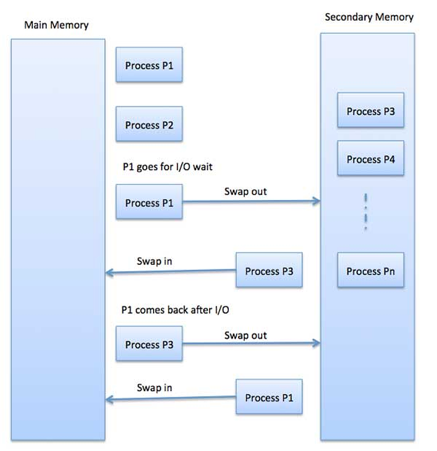
Fig 13: Swapping
The time it takes to relocate the entire process to a secondary disk and then copy it back to memory, as well as the time it takes to reclaim main memory, is included in the total time taken by the swapping operation.
Assume that the user process is 2048KB in size and that the data transmission rate on the standard hard disk where the swapping would take place is roughly 1 MB per second. The 1000K procedure will take some time to move to or from memory.
2048 KB / 1024KB per second
= 2 seconds
= 2000 milliseconds
In terms of in and out time, it will take a total of 4000 milliseconds, plus additional overhead while the process fights for main memory.
Q12) Explain VM with paging?
A12) According to the notion of Virtual Memory, only a portion of a process needs to be present in the main memory in order for it to be executed, which means that only a few pages will be stored in the main memory at any given moment.
Choosing which pages should be stored in the main memory and which should be kept in the secondary memory, on the other hand, will be challenging because we cannot predict when a process will demand a specific page at a specific time.
As a result, a concept known as Demand Paging was developed to address this issue. It recommends storing all of the frames' pages in secondary memory until they are needed. In other words, it says that do not load any page in the main memory until it is required.
Any page that is referred to for the first time in the main memory is also found in the secondary memory.

Fig 14: Paging
Q13) What is Page table structure?
A13) The Page Table is a data structure that is used by the virtual memory system in the operating system of a computer to record the mapping between physical and logical addresses.
Physical addresses are the memory's real frame addresses. They're mostly used by hardware, and more specifically RAM subsystems.
The page table converts the logical address generated by the CPU into the physical address, as we previously stated.
As a result, the page table primarily supplies the relevant frame number (frame base address) where that page is stored in main memory.
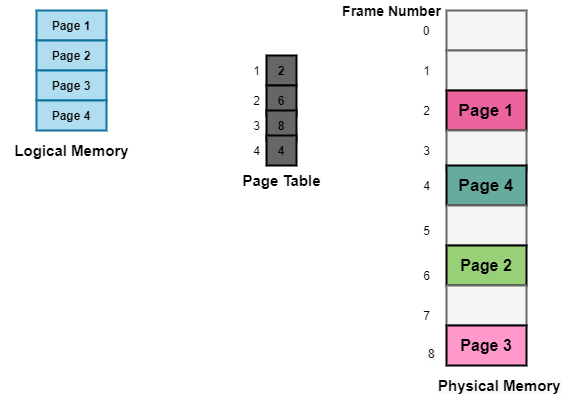
Fig 15: Page table
The paging paradigm of physical and logical memory is depicted in the diagram above.
Characteristics
The following are some of the features of the Page Table:
● It's saved in the system's main memory.
● In general, the number of entries in the page table equals the number of pages divided by the procedure.
● PTBR stands for page table base register, and it is used to store the base address for the current process's page table.
● Each process has its own table of contents.
Q14) Define Inverted page table?
A14) The Inverted Page table is a data structure that combines a page table and a frame table into one.
Each virtual page number and real memory page have their own entries.
The virtual address of the page stored in that real memory location, as well as information about the process that owns the page, make up the majority of the entry.
While this strategy reduces the amount of memory required to store each page table, it also increases the time required to search the table whenever a page reference is encountered.
The address translation scheme of the Inverted Page Table is shown in the diagram below:
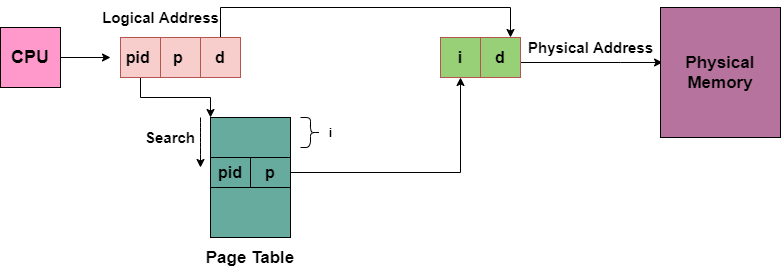
Fig 16: Inverted page table
Because numerous processes may have the identical logical addresses, we must keep track of the process id of each entry.
After running through the hash function, numerous entries can map to the same index in the page table. As a result, chaining is utilized to deal with this.
Q15) Explain Translation lookaside buffer?
A15) A Translation glance aside buffer is a memory cache that can be used to reduce the time it takes to repeatedly query the page table.
It's a memory cache that's closer to the CPU, therefore it takes the CPU less time to access TLB than it does to access main memory.
To put it another way, TLB is faster and smaller than main memory, but it is also cheaper and larger than the register.
TLB adheres to the principle of locality of reference, which means it only stores the entries of the many pages that the CPU accesses regularly.
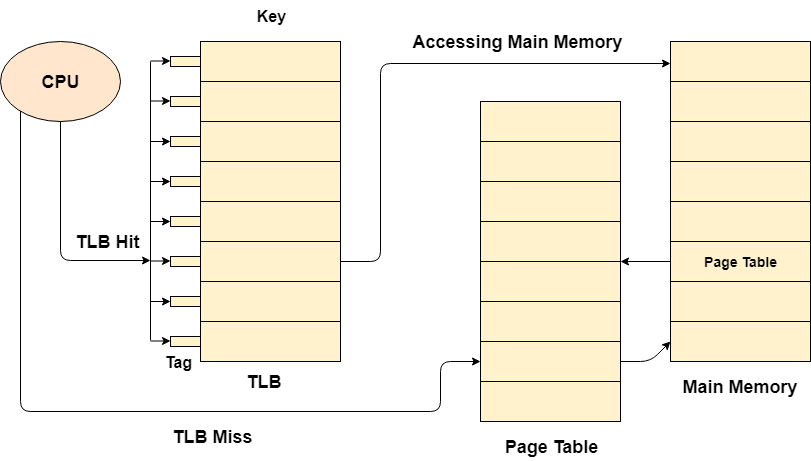
Fig 17: TLB
Look past the buffers in translation; there are tags and keys that are used to map data.
When the requested entry is located in the translation look aside buffer, it is referred to as a TLB hit. When this occurs, the CPU just accesses the actual location in main memory.
If the item isn't located in the TLB (TLB miss), the CPU must first read the page table in main memory, then the actual frame in main memory.
As a result, the effective access time in the case of a TLB hit will be less than in the case of a TLB miss.
If the chance of a TLB hit is P percent (TLB hit rate), the probability of a TLB miss is (1-P) % (TLB miss rate).
As a result, the effective access time can be calculated as follows:
EAT = P (t + m) + (1 - p) (t + k.m + m)
If single level paging has been implemented, p →TLB hit rate, t → time taken to access TLB, m time spent to access main memory, k = 1.
We can deduce from the formula that
● If the TLB hit rate is increased, the effective access time will be reduced.
● In the case of multilevel paging, the effective access time will be increased.
Q16) What do you mean by Page size?
A16) Any of the following terms can be used to describe page size:
- The size of a page, which is a block of recorded memory, is referred to as page size in computers. When running programs, the page size has an impact on the quantity of memory and space required. When a program starts, most operating systems determine the page size. This feature allows it to compute the most efficient memory usage while the program is running.
- When it comes to web pages, page size (also known as page weight) refers to the overall size of the page. All of the files that make up a web page are included in the page size. The HTML document, any included images, style sheets, scripts, and other material are all contained in these folders. A web page with a 10 K HTML document, a 20 K image file, and a 5 K style sheet file, for example, has a 35 K page size.
- The size of the paper for the final printed document is referred to as page size in print documents. Letter size (8.5 x 11 inches) and legal size are two examples (8.5 x 14-inches).
Q17) What is FIFO?
A17) In this algorithm, a queue is maintained. The page which is assigned the frame first will be replaced first. In other words, the page which resides at the rare end of the queue will be replaced on every page fault.
Example of FIFO
Consider the following size 12 page reference string: 1, 2, 3, 4, 5, 1, 3, 1, 6, 3, 2, 3 with frame size 4 (i.e., maximum 4 pages in a frame).
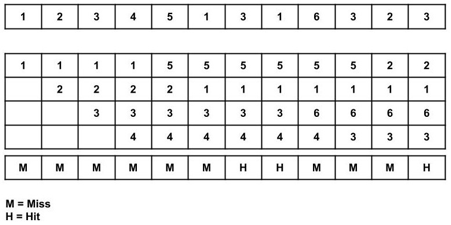
Total page fault = 9
All four spaces are initially empty, therefore when 1, 2, 3, and 4 arrive, they are assigned to the empty spots in the order of their arrival. This is a page fault because the numbers 1, 2, 3, and 4 are not in memory.
When page 5 arrives, it is not available in memory, so a page fault occurs, and the oldest page in memory, 1, is replaced.
Because 1 is not in memory when it arrives, a page fault occurs, and it replaces the oldest page in memory, i.e., 2.
When 3,1 arrives, it is already in the memory, i.e., Page Hit, therefore there is no need to update it.
When page 6 arrives, it is not in memory, therefore a page fault occurs, and the oldest page in memory, 3, is replaced.
When page 3 arrives, it is not in memory, therefore a page fault occurs, and the oldest page in memory, 4, is replaced.
When page 2 arrives, it is not in memory, therefore a page fault occurs, and the oldest page in memory, 5, is replaced.
When 3 arrives, it is already in the memory, i.e., Page Hit, therefore there is no need to update it.
Page Fault ratio = 9/12 i.e., total miss/total possible cases
Q18) Write about Least recent used (LRU) page replacement algorithm
A18) This algorithm replaces the page which has not been referred for a long time. This algorithm is just opposite to the optimal page replacement algorithm. In this, we look at the past instead of staring at future.
Example of LRU
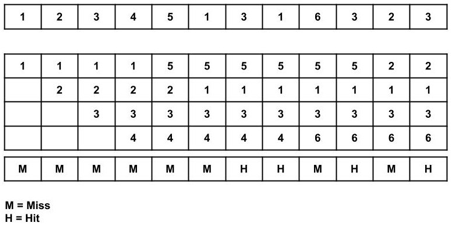
Total page fault = 8
All four spaces are initially empty, therefore when 1, 2, 3, and 4 arrive, they are assigned to the empty spots in the order of their arrival. This is a page fault because the numbers 1, 2, 3, and 4 are not in memory.
Because 5 is not in memory when it arrives, a page fault occurs, and it replaces 1 as the least recently utilized page.
When 1 arrives, it is not in memory, therefore a page fault occurs, and it takes the place of 2.
When 3,1 arrives, it is already in the memory, i.e., Page Hit, therefore there is no need to update it.
When 6 arrives, it is not found in memory, causing a page fault, and it takes the place of 4.
When 3 arrives, it is already in the memory, i.e., Page Hit, therefore there is no need to update it.
When 2 arrives, it is not found in memory, causing a page fault, and it takes the place of 5.
When 3 arrives, it is already in the memory, i.e., Page Hit, therefore there is no need to update it.
Page Fault ratio = 8/12
Q19) Explain Optimal Page Replacement algorithm?
A19) This algorithm replaces the page which will not be referred for so long in future. Although it cannot be practically implementable but it can be used as a benchmark. Other algorithms are compared to this in terms of optimality.
Example of Optimal page replacement
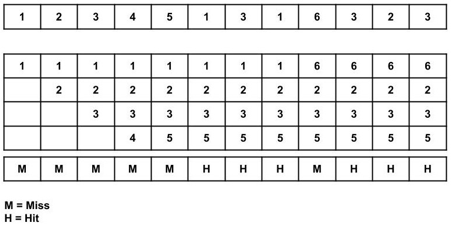
Total page fault = 6
All four spaces are initially empty, therefore when 1, 2, 3, and 4 arrive, they are assigned to the empty spots in the order of their arrival. This is a page fault because the numbers 1, 2, 3, and 4 are not in memory.
When 5 arrives, it is not in memory, causing a page fault, and it substitutes 4, which will be utilized the most in the future among 1, 2, 3, and 4.
When 1,3,1 arrives, they are already in the memory, i.e., Page Hit, therefore there is no need to update them.
When 6 arrives, it is not found in memory, causing a page fault, and it takes the place of 1.
When 3, 2, 3 appears, it is already in the memory, i.e., Page Hit, thus there is no need to update it.
Page Fault ratio = 6/12
Q20) What is thrashing?
A20) Thrashing is computer activity that makes little or no progress, usually because memory or other resources have become exhausted or too limited to perform needed operations. When this happens, a pattern typically develops in which a request is made of the operating system by a process or program, the operating system tries to find resources by taking them from some other process, which in turn makes new requests that can’t be satisfied. In a virtual storage system (an operating system that manages its logical storage or memory in units called pages), thrashing is a condition in which excessive paging operations are taking place.
A system that is thrashing can be perceived as either a very slow system or one that has come to a halt.
Causes of Thrashing:
- High degree of multiprogramming: If the number of processes in memory continues to grow, the number of frames assigned to each process will shrink. As a result, each process will have less frames available. As a result, page faults will become more often, more CPU time will be wasted switching in and out of pages, and utilization will continue to decline.
For example:
Let free frames = 400
Case 1: Number of process = 100
Then, each process will get 4 frames.
Case 2: Number of processes = 400
Each process will get 1 frame.
Case 2 is a thrashing circumstance in which the number of processes increases but the number of frames per process decreases. As a result, just swapping pages will waste CPU time.
2. Lacks of frames: When a process has fewer frames, fewer pages of that process may be stored in memory, necessitating more frequent shifting in and out. This could result in thrashing. As a result, each process must be given a sufficient number of frames to avoid thrashing.
Recovering of Thrashing
● By ordering the long-term scheduler not to put the processes into memory after the threshold, you can prevent the system from thrashing.
● If the system is already thrashing, tell the mid-term scheduler to pause some of the processes until the system is no longer thrashing.




