Unit - 4
Database Transactions Management
Q1) What is a transaction?
A1) A transaction is a logical unit of data processing that consists of a collection of database actions. One or more database operations, such as insert, remove, update, or retrieve data, are executed in a transaction. It is an atomic process that is either completed completely or not at all. A read-only transaction is one that involves simply data retrieval and no data updating.
A transaction is a group of operations that are logically related. It consists of a number of tasks. An activity or series of acts is referred to as a transaction. It is carried out by a single user to perform operations on the database's contents.
Each high-level operation can be broken down into several lower-level jobs or operations. A data update operation, for example, can be separated into three tasks:
Read_item() - retrieves a data item from storage and stores it in the main memory.
Modify_item() - Change the item's value in the main memory.
Write_item() - write the changed value to storage from main memory
Only the read item() and write item() methods have access to the database. Similarly, read and write are the fundamental database operations for all transactions.
Q2) Write about transaction management?
A2) A transaction is a group of operations that are logically related. If you were to transfer money from your bank account to a friend's account, the following actions would be performed:
Simple transaction example
1. Check the balance of your account
2. Subtract the money from your account.
3. Transfer the money to your account.
4. Check the balance of your friend's account.
5. Transfer the funds to his bank account.
6. Update his account with the new balance.
A transaction refers to the entire set of operations. Although I demonstrated read, write, and update actions in the above example, the transaction can also include read, write, insert, update, and delete operations.
Transaction failure in between operations
The major issue that can arise during a transaction is that it may fail before all of the actions in the set have been completed. This can happen as a result of a power outage, a system crash, or other factors. This is a major issue that could result in database inconsistency. If the transaction fails after the third operation (as in the example above), the money will be debited from your account, but it will not be sent to your buddy.
The following two operations can be used to fix this problem.
Commit - If all of the activities in a transaction are successful, the changes are permanently committed to the database.
Rollback - If any of the operations fails, undo all of the prior operations' changes.
Even while these activities can assist us prevent a variety of problems that can develop during a transaction, they are insufficient when two transactions are running at the same time. To solve these issues, we need to know about database ACID properties.
Uses of transaction management
● The DBMS is used to plan concurrent data access. It means the user can access many pieces of data from the database without interfering with one another. Concurrency is managed through transactions.
● It's also utilized to meet ACID requirements.
● It's a tool for resolving Read/Write Conflicts.
● Recoverability, Serializability, and Cascading are all implemented using it.
● Concurrency Control Protocols and data locking are also handled by Transaction Management.
Q3) What are the properties of transaction?
A3) A transaction in a database system must maintain Atomicity, Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy,
Completeness, and data integrity.
● Atomicity
● Consistency
● Isolation
● Durability.
Atomicity: -
● A transaction is an atomic unit of processing.
● It is either performed in its entirely or not performed at all.
● It means either all operations are reflected in the database or none are.
● It is responsibility of the transaction recovery subsystem to ensure atomicity.
● If a transaction fails to complete for some reason, recovery technique must undo any effects of the transaction on the database.
Consistency: -
● A transaction is consistency preserving if its complete execution takes the database from one consistent state to other.
● It is responsibility of the programmer who writes database programs.
● Database programs should be written in such a way that, if database is in a consistent state before execution of transaction, it will be in a consistent state after execution of transaction.
Eg. Transaction is :- Transfer $50 from account A to account B.
If account A having amount $100 & account B having amount $ 200 initially then after execution of transaction, A must have $ 50 & B must have $ 250.
Isolation: -
● If multiple transactions execute concurrently, they should produce the result as if they are working serially.
● It is enforced by concurrency control subsystem.
● To avoid the problem of concurrent execution, transaction should be executed in isolation.
Durability: -
● The changes applied to the database, by a committed transaction must persist in a database.
● The changes must not be lost because of any failure.
● It is the responsibility of the recovery subsystem of the DBMS.
Q4) Explain schedule?
A4) A schedule S of n transactions T1, T2, Tn is an ordering of the operations of the
Transactions, subject to the constraint that, for each transaction Ti, appearing in S, th
Operations of Ti in they occur in original Ti. So, the execution of sequences which
Represents the chronological order in which instructions are executed in the system, are called schedules.
E.g.
T1 T2 Read(A) A:= A+100; Write(A);
Read(A) A := A-200; Write(A).
|
* Schedule S *
Schedule S is serial because T1 & T2 are executing serially, T2 followed by T1.
If initial value of A = 500, then after successful execution of T1 & T2, A should have value =400.
Now, consider above transactions T1 & T2 are running concurrently like: -
A = 500
T1 T2 Read(A)
Read(A) (A=500) (A=500) A: = A+100;
A: = A-200; (A=600) (A=300) Write(A); Write(A); (A=600) (A=300)
|
*concurrent schedule S*
Here, instead of 400, schedule produces value of A=300. So, in this case database is in inconsistent state.
Conflict Operations: -
Two operations are said to be conflict if: -
i. They are from different transactions
Ii. They access same data item.
Iii. One of the operations is write operation.
Eg:
T1 T2
1. R(A)
2. W(A)
3. R(A)
4. W(A)
5. R(A)
6. R(B)
7.R(A)
8.W(B)
9. R(A)
Here, instructions: - 2 & 3, 4 & 5 ,6 & 8, 4& 9 are conflict instructions.
Instructions 8 & 9 are non-conflict because they are working on different data items.
Q5) What is the serial schedule?
A5) In the Serial Schedule, a transaction is completely completed until another transaction begins to be executed. In other words, you might assume that a transaction does not start execution in the serial schedule until the currently running transaction is executed. A non-interleaved execution is also known as this form of transaction execution.
Take one example:
R here refers to the operation of reading and W to the operation of writing. In this case, the execution of transaction T2 does not start until the completion of transaction T1.
T1 T2
---- ----
R(A)
R(B)
W(A)
Commit
R(B)
R(A)
W(B)
Commit
Q6) Explain conflict serializability?
A6) If a schedule can turn into a serial schedule by exchanging non-conflicting procedures, it is called conflict serializability.
If the schedule is conflict equivalent to a serial schedule, it will be conflict serializable.
When two active transactions conduct non-compatible activities in a schedule with numerous transactions, a conflict develops. When all three of the following requirements exist at the same time, two operations are said to be in conflict.
● The two activities are separated by a transaction.
● Both operations refer to the same data object.
● One of the actions is a write item() operation, which attempts to modify the data item.
Example
Only if S1 and S2 are logically equivalent may they be swapped.
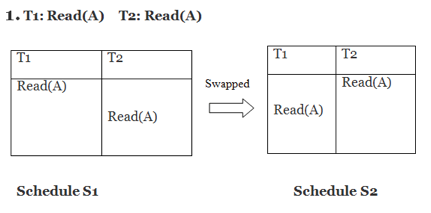
S1 = S2 in this case. This suggests there isn't any conflict.
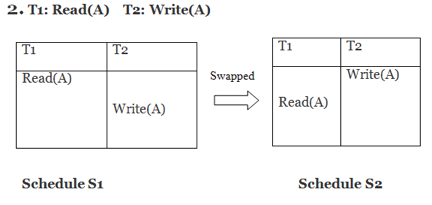
S1 ≠ S2 in this case. That suggests there's a fight going on.
Conflict Equivalent
By switching non-conflicting activities, one can be turned into another in the conflict equivalent. S2 is conflict equal to S1 in the example (S1 can be converted to S2 by swapping non-conflicting operations).
If and only if, two schedules are said to be conflict equivalent:
● They both have the identical set of transaction data.
● If each conflict operation pair is ordered the same way.
Example
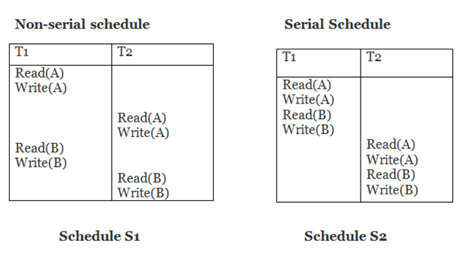
Schedule S2 is a serial schedule since it completes all T1 operations before beginning any T2 operations. By exchanging non-conflicting operations from S1, schedule S1 can be turned into a serial schedule.
The schedule S1 becomes: after exchanging non-conflict operations
T1 | T2 |
Read(A) Write(A) Read(B) Write(B) |
Read(A) Write(A) Read(B) Write(B) |
Since, S1 is conflict serializable.
Q7) Describe View Serializability?
A7) If a schedule is viewed as equivalent to a serial schedule, it will be serializable.
If a schedule is view serializable, it is also conflict serializable.
Blind writes are contained in the view serializable, which does not conflict with serializable.
View Equivalent
If two schedules S1 and S2 meet the following criteria, they are said to be view equivalent:
1. Initial Read
Both schedules must be read at the same time. Assume there are two schedules, S1 and S2. If a transaction T1 in schedule S1 reads data item A, then transaction T1 in schedule S2 should likewise read A.
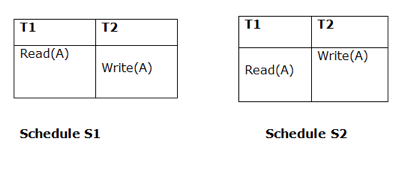
Because T1 performs the initial read operation in S1 and S2, the two schedules are considered comparable.
2. Updated Read
If Ti is reading A, which is updated by Tj in schedule S1, Ti should also read A, which is updated by Tj in schedule S2.

Because T3 in S1 is reading A updated by T2 and T3 in S2 is reading A updated by T1, the two schedules are not equivalent.
3. Final Write
The final writing for both schedules must be the same. If a transaction T1 updates A last in schedule S1, T1 should also perform final writes operations in schedule S2.

Because T3 performs the final write operation in S1 and T3 performs the final write operation in S2, the two schedules are considered equivalent.
Example

Schedule S
The total number of possible schedules grows to three with three transactions.
= 3! = 6
S1 = <T1 T2 T3>
S2 = <T1 T3 T2>
S3 = <T2 T3 T1>
S4 = <T2 T1 T3>
S5 = <T3 T1 T2>
S6 = <T3 T2 T1>
Taking first schedule S1:

Schedule S1:
Step 1 - final updation on data items
There is no read besides the initial read in both schedules S and S1, thus we don't need to check that condition.
Step 2 - Initial Read
T1 performs the initial read operation in S, and T1 also performs it in S1.
Step 3 - Final Write
T3 performs the final write operation in S, and T3 also performs it in S1. As a result, S and S1 are viewed as equivalent.
We don't need to verify another schedule because the first one, S1, meets all three criteria.
As a result, the comparable serial schedule is as follows:
T1 → T2 → T3
Q8) What is Recoverable schedules?
A8) Due to a software fault, system crash, or hardware malfunction, a transaction may not finish completely. The unsuccessful transaction must be rolled back in this scenario. However, the value generated by the unsuccessful transaction may have been utilised by another transaction. As a result, we must also rollback those transactions. Table displays a schedule with two transactions.
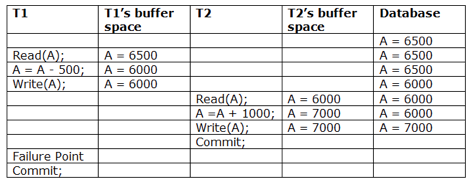
T1 reads and writes the value of A, which is read and written by T2.T2 commits, but T1 fails later. As a result of the failure, we must rollback T1.T2 should also be rolled back because it reads the value written by T1, but T2 can't because it has already committed.
Irrecoverable schedule: If Tj receives the revised value of Ti and commits before Ti commits, the schedule will be irreversible.
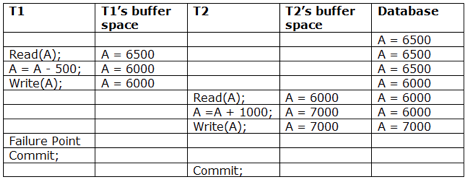
A schedule with two transactions is shown in table 2 above. Transaction T1 reads and writes A, and transaction T2 reads and writes that value. T1 eventually fails. As a result, T1 must be rolled back. Because T2 has read the value written by T1, T2 should be rolled back. We can rewind transaction T2 as well because it hasn't been committed before T1. As a result, cascade rollback can be used to recover it.
Recoverable with cascading rollback: If Tj reads the modified value of Ti, the schedule can be recovered using cascading rollback. Tj's commit is postponed till Ti's is completed.

A schedule with two transactions is shown in Table 3 above. T1 commits after reading and writing A, and T2 reads and writes that value. As a result, this is a less recoverable cascade schedule.
Q9) What are Non - recoverable schedules?
A15) Non - recoverable schedules
T1 T2 R(A) W(A)
R(X) Commit R(B) |
● Here, T2 commits immediately after R(A).
● If after T2 commit, because of some reason suppose T1 fails before it commits.
● T1 must be restarted. As T2 reads the value of X, written by T1, T2 must be restarted to ensure the property of atomicity.
● But as T2 has committed, it is not possible to abort & restart.
● So, it is impossible to recover from the failure of T1.
So, the schedule is not recoverable i.e. T1 is non- recoverable schedule.
E.g.
T1 T2 r(x) w(x)
r(X) r(y) w(x) Commit; Commit; |
Schedule is non-recoverable because T2 reads X which is modified by T1. But T2 commits before T1 commits.
Q10) Explain Locking methods?
A10) Locking methods
i. A lock is a variable associated with a data item which describes the status of the item with respect to possible operations that can be applied to it.
Ii. Generally, there is one lock for each data item in the database.
Iii. Locks are used as a means of synchronizing the access by concurrent transactions to the database items.
Locking Models: -
There are two models in which a data item may be locked: -
a. Shared (Read) Lock Mode &
b. Exclusive (write) Lock Mode
a. Shared-Lock Mode: -
● If a transaction Ti has obtained a shared mode lock on item Q, then Ti can read Q but cannot modify/write Q
● Shared lock is also called as a Read-lock because other transactions are allowed to read the item.
● It is denoted by s.
Eg. T1 T2
Locks(A);
Locks(B);
T1 has locked A in shared mode & T2 also has locked B in shared lock mode.
b. Exclusive-Lock Mode: -
● If a transaction Ti has obtained a exclusive-lock mode on item Q, then Ti can read & write Q
● Exclusive –lock is also called a write-lock because a single transaction exclusively holds the locks on the item
● It is denoted by X.
T1 T2
LockX(A)
LockX(B);
● T1 has locked A in exclusive-mode & T2 has locked B in exclusive mode.
Q11) What is the deadline handline?
A11) A deadlock occurs when two or more transactions are stuck waiting for one another to release locks indefinitely. Deadlock is regarded to be one of the most dreaded DBMS difficulties because no work is ever completed and remains in a waiting state indefinitely.
For example, transaction T1 has a lock on some entries in the student table and needs to update some rows in the grade table. At the same time, transaction T2 is holding locks on some rows in the grade table and needs to update the rows in the Student table that Transaction T1 is holding.
The primary issue now arises. T1 is currently waiting for T2 to release its lock, and T2 is currently waiting for T1 to release its lock. All actions come to a complete halt and remain in this state. It will remain at a halt until the database management system (DBMS) recognizes the deadlock and aborts one of the transactions.
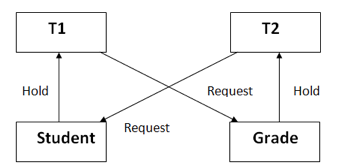
Fig: Deadlock
Deadlock Avoidance
When a database becomes stuck in a deadlock condition, it is preferable to avoid the database rather than abort or restate it. This is a waste of both time and money.
Any deadlock condition is detected in advance using a deadlock avoidance strategy. For detecting deadlocks, a method such as "wait for graph" is employed, although this method is only effective for smaller databases. A deadlock prevention strategy can be utilized for larger databases.
Deadlock Detection
When a transaction in a database waits endlessly for a lock, the database management system (DBMS) should determine whether the transaction is in a deadlock or not. The lock management keeps a Wait for the graph to detect the database's deadlock cycle.
Wait for Graph
This is the best way for detecting deadlock. This method generates a graph based on the transaction and its lock. There is a deadlock if the constructed graph has a cycle or closed loop.
The system maintains a wait for the graph for each transaction that is awaiting data from another transaction. If there is a cycle in the graph, the system will keep checking it.

Fig: Wait for a graph
Deadlock Prevention
A huge database can benefit from a deadlock prevention strategy. Deadlock can be avoided if resources are distributed in such a way that deadlock never arises.
The database management system examines the transaction's operations to see if they are likely to cause a deadlock. If they do, the database management system (DBMS) never allows that transaction to be completed.
Q12) Describe Time stamping Methods?
A12) Time stamping methods
● Time stamp is a unique identifier created by the DBMS to identify a transaction.
● These values are assigned, in the order in which the transactions are submitted to the system, so timestamp can be thought of as the transaction start time.
● It is denoted as Ts(T).
● Note: - Concurrency control techniques based on timestamp ordering do not use locks, here deadlock cannot occur.
Generation of timestamp: -
Timestamps can be generated in several ways like: -
● Use a counter that is incremental each time its value is assigned to a transaction. Transaction timestamps are numbered 1,2, 3, in this scheme. The system must periodically reset the counter to zero when no transactions are executing for some short period of time.
● Another way is to use the current date/time of the system lock.
● Two timestamp values are associated with each database item X: -
1) Read-Ts(X): -
i. Read timestamp of X.
Ii.Read –Ts(X) = Ts(T)
Where T is the youngest transaction that has read X successfully.
2) Write-Ts(X): -
i. Write timestamp of X.
Ii.Write-Ts(X) = Ts(T),
Where T is the youngest transaction that has written X successfully.
These timestamps are updated whenever a new read(X) or write(X) instruction is executed.
Timestamp Ordering Algorithm: -
a. Whenever some transaction T issues a Read(X) or Write(X) operation, the algorithm compares Ts(T) with Read-Ts(X) & Write-Ts(X) to ensure that the timestamp order of execution is not violated.
b. If violate, transaction is aborted & resubmitted to system as a new transaction with new timestamp.
c. If T is aborted & rolled back, any transaction T1 that may have used a value written by T must also be rolled back.
d. Similarly, any transaction T2 that may have used a value written by T1 must also be rolled back & so on.
So, cascading rollback problems is associated with this algorithm.
Algorithm: -
1) If transaction T issues a written(X) operation: -
a) If Read-Ts(X) > Ts(T)
OR
Write-Ts(X) > Ts(T)
Then abort & rollback T & reject the operation.
This is done because some younger transaction with a timestamp greater than Ts(T) has already read/written the value of X before T had a chance to write(X), thus violating timestamp ordering.
b) If the condition in (a) does not occur then execute write (X) operation of T & set write-Ts(X) to Ts(T).
2) If a transaction T issues a read(X) operation.
a. If write-Ts(X) > Ts(T), then abort & Rollback T & reject the operation.
This should be done because some younger transaction with timestamp greater than Ts(T) has already written the value of X before T had a chance to read X.
b. If Write-Ts(X) ≤ Ts(T), then execute the read(X) operation of T & set read-Ts(X) to the larger of Ts(T) & current read-Ts(X).
Q13) Write the advantages and disadvantages of time stamping?
A13) Advantages: -
1. Timestamp ordering protocol ensures conflict serializability. This is because conflicting order.
2. The protocol ensures freedom from deadlock, since no transaction ever waits.
Disadvantages: -
1. There is a possibility of starvation of long transactions if a sequence of conflicting short transaction causes repeated restarting of long transaction.
2. The protocol can generate schedules that are not recoverable.
Q14) A two phase locking protocol variant that required that all locks be held until the transaction commit is called
- Lock-point two-phase locking protocol
- Deadlock two-phase locking protocol
- Strict two-phase locking protocol
- Rigorous two-phase locking protocol
A14) Correct answer is “ D ” .
Q15) How to recover from transaction failure?
A15) When a transaction fails to execute or reaches a point where it can't go any further, it is called a transaction failure. Transaction failure occurs when a number of transactions or processes are harmed.
Logical errors: When a transaction cannot complete owing to a coding error or an internal error situation, a logical error occurs.
Syntax error: When a database management system (DBMS) stops an active transaction because the database system is unable to perform it, this is known as a syntax error. For example, in the event of a deadlock or resource unavailability, the system aborts an active transaction.
When a system crashes, numerous transactions may be running and various files may be open, allowing them to modify data items. Transactions are made up of a variety of operations that are all atomic. However, atomicity of transactions as a whole must be preserved, which means that either all or none of the operations must be done, depending on the ACID features of DBMS.
When a database management system (DBMS) recovers after a crash -
● It should check the statuses of all the transactions that were in progress.
● A transaction may be in the middle of an operation; in this situation, the DBMS must ensure the transaction's atomicity.
● It should determine if the transaction can be completed at this time or whether it has to be turned back.
● There would be no transactions that would leave the DBMS in an inconsistent state.
Maintaining the logs of each transaction and writing them onto some stable storage before actually altering the database are two strategies that can assist a DBMS in recovering and maintaining the atomicity of a transaction.
There are two sorts of approaches that can assist a DBMS in recovering and sustaining transaction atomicity.
● Maintaining shadow paging, in which updates are made in volatile memory and the actual database is updated afterwards.
● Before actually altering the database, keep track of each transaction's logs and save them somewhere safe.
Q16) How are transactions implemented in the database?
A16) Even the simple update of one record contain these substeps within the system:
- Locate the record to be updated from secondary storage
- Transfer the block disk into the memory buffer
- Make the update to tuple in the buffer buffer
- Write the modified block back out to disk
- Make an entry to a log
More complicated transactions may involve several separate SQL updates
Between each step is an opportunity that another user or different transaction step could occur
Also....the modified buffer block may not be written to disk immediately after transaction terminates. We must assume there is a delay before actual write is completed , e.g., the block remains in the disk cache.
Q17) Explain lock compatibility matrix?
A17) Lock-Compatibility Matrix: -
| S | X |
S | ✓ | X |
X | X | X |
● If a transaction Ti has locked Q in shared mode, then another transaction Tj can lock Q in shared mode only. This is called as composite mode.
● If a transaction Ti has locked Q in S mode, another transaction Tj can’t lock Q in X mode. This is called incompatible mode.
● Similarly, if a transaction Ti has locked Q in X mode, then other transaction Tj can’t lock Q in either S or X mode.
● To access, a data item, transaction Ti must first lock that item.
● If the data item is already locked by another transaction in an incompatible mode, the concurrency control manager will not grant the lock until lock has been released.
● Thus, Ti is mode to wait until all incompatible locks have been released.
● A transaction can unlock a data item by unlock (Q)instruction.
Eg.1. Transaction T1 displays total amount of money in accounts A & B.
Without-locking modes: -
T1
R(A)
R(B)
Display(A+B)
With-locking modes: -
T1
Locks(A)
R(A) unlock(A)
Locks(B)
R(B) unlock(B)
Display(A+B)
T1 locks A & B in shared mode because T1 uses A & B only for reading purposes.
Q18) Describe two phase locking protocols?
A18) Two-Phase Locking Protocol: -
● Each transaction in the system should follow a set of rules, called locking protocol.
● A transaction is said to follow the two-phase locking protocol, if all locking operation (shared, exclusive protocol) precede the first unlock operation.
● Such a transaction can be divided into two phases: Growing & shrinking phase.
● During Expanding / Growing phase, new locks on items can be acquired but no one can be released.
● During a shrinking phase, existing locks can be released but no new locks can be acquired.
● If every transaction in a schedule follows the two-phase locking protocol, the schedule is guaranteed to be serialization, obviating the need to test for Serializability.
● Consider, following schedules S11, S12. S11 does not follow two-phase locking &S12 follows two-phase locking protocol.
T1
Lock_S(Y) R(Y) Unlock(Y) Lock_X(Q) R(Q) Unlock(Q) Q: = Q + Y; W(Q); Unlock(Q)
|
This schedule does not follow two phase locking because 3 rd instruction lock-X(Q) appears after unlock(Y) instruction.
T1
Lock_S(Y) R(Y) Lock_X(Q) R(Q) Q: = Q + Y; W(Q); Unlock(Q); Unlock(Y); |
This schedule follows two-phase locking because all lock instructions appear before first unlock instruction.




