Unit 1
INTRODUCTION
Q1) Explain the Components of a computer system in detail?
A1)
A computer consists of five functionally independent main parts. They are:
1. Input
2. Memory
3. Arithmetic and logic
4. Output
5. Control unit
Basic functional units of a computer
The computer accepts programs and the data through an input and stores them in the memory. The stored data are processed by the arithmetic and logic unit under program control. The processed data is delivered through the output unit. All above activities are directed by control unit.
1) Input unit
The computer accepts coded information through input unit. The input can be from human operators, electromechanical devices such as keyboards or from other computer over communication lines.
Examples of input devices are Keyboard, joysticks, trackballs and mouse are used as graphic input devices in conjunction with display
Keyboard
It is a common input device. Whenever a key is pressed; the corresponding letter or digit is automatically translated into its corresponding binary code and transmitted over cable to the memory of the computer.
2 Memory unit
Memory unit is used to store programs as well as data. Memory is classified into primary and secondary storage.
It also called main memory. It operates at high speed and it is expensive. It ismade up of large number of semiconductor storage cells, each capable of storingone bit of information. These cells are grouped together in a fixed size called word. This facilitates reading and writing the content of one word (n bits) in single basic operation instead of reading and writing one bit for each operation.
It is slow in speed. It is cheaper than primary memory. Its capacity is high. It is used to store information that is not accessed frequently. Various secondary devices are magnetic tapes and disks, optical disks (CD-ROMs), floppy etc.
3 Arithmetic and logic unit
Arithmetic and logic unit (ALU) and control unit together form a processor. Actual execution of most computer operations takes place in arithmetic and logic unit of the processor. Example: Suppose two numbers located in the memory are to be added. They are brought into the processor, and the actual addition is carried out by the ALU.
Registers:
Registers are high speed storage elements available in the processor. Each register can store one word of data. When operands are brought into the processor for any operation, they are stored in the registers. Accessing data from register is faster than that of the memory.
4 Output unit
The function of output unit is to produce processed result to the outside world inhuman understandable form. Examples of output devices are Graphical display, Printers such as inkjet, laser, dot matrix and so on. The laser printer works faster.
5 Control unit
Control unit coordinates the operation of memory, arithmetic and logic unit, input unit, and output unit in some proper way. The control unit issues control signal sthat cause the CPU (and other components of the computer) to fetch the instruction to the IR (Instruction Register) and then execute the actions dictated by the machine language instruction that has been stored there. Control units are well defined, physically separate unit that interact with other parts of the machine.
A set of control lines carries the signals used for timing and synchronization of events in all units Example: Data transfers between the processor and the memory are controlled by the control unit through timing signals. Timing signals are the signals that determine when a given action is to take place.
Q2) What is the Basic Operational Concept in Advanced Computer Architecture?
A2)
PC the program counter contains the address of the assembly language instruction to be executed next. IR the instruction register contains the binary word corresponding to the machine language version of the instruction currently being executed.
MAR the memory address register contains the address of the word in main memory that is being accessed. The word being addressed contains either data ora machine language instruction to be executed.
MBR the memory buffer register (also called MDR for memory data register) is the register used to communicate data to and from the memory. The operation of a processor is characterized by a fetch-decode-execute cycle. In the first phase of the cycle, the processor fetches an instruction from memory. The address of the instruction to fetch is stored in an internal register named the program counter, or PC. As the processor is waiting for the memory to respond with the instruction, it increments the PC. This means the fetch phase of the next cycle will fetch the instruction in the next sequential location in memory.
In the decode phase the processor stores the information returned by the memory in another internal register, known as the instruction register, or IR. The IR now holds a single machine instruction, encoded as a binary number. The processor decodes the value in the IR in order to figure out which operations to perform in the next stage.
In the execution stage the processor actually carries out the instruction. This step often requires further memory operations; for example, the instruction may direct the processor to fetch two operands from memory, add them, and store the result in a third location (the addresses of the operands and the result are also encoded as part of the instruction). At the end of this phase the machine starts the cycle over again by entering the fetch phase for the next instruction. The CPU exchanges data with memory. For this purpose, it typically makes use of two internal (to the CPU) register:
An I/O addresses register (I/OAR) specifies a particular I/O device. An I/O buffer(I/OBR) register is used for the exchange of data between an I/O module and the CPU.A memory module consists of a set of locations, defined by sequentially numbered address. Each location contains a binary number that can be interpreted as either an instruction or data. An I/O module transfers data from external devices to CPU and memory, and vice versa.
It contains internal buffers for temporarily holding these data until they can be sent on. Instructions can be classified as one of three major types: arithmetic/logic, data transfer, and control. Arithmetic and logic instructions apply primitive functions of one or two arguments, for example addition, multiplication, or logical AND.
Q3) Define Computer Architecture. Illustrate the seven dimensions of an ISA?
A3)
The computer designer has to ascertain the attributes that are important for a new computer and design the system to maximize the performance while staying within cost, power and availability constraints. The task has few important aspects such as Instruction Set design, Functional organization, Logic design and implementation.
Instruction Set Architecture (ISA)
ISA refers to the actual programmer visible Instruction set. The ISA serves as boundary between the software and hardware. Th e seven dimensions of the ISA are:
i)Class of ISA: Nearly all ISAs today ar e classified as General-Purpose-Register architectures. The operands are either Registers or Memory locations.The two popular versions of this class are:
ii)Memory addressing: Byte addressing scheme is most widely used in all desktop and server computers. Both 80x86 and MIPS use byte addressing. Incase of MIPS the object must be aligned. An access to an object of s byte atbyte address A is aligned if A mod s =0. 80x86 does not require alignment.
Accesses are faster if operands are aligned.
iii) Addressing modes :Specify the address of a M object apart from register and constant operands.
MIPS Addressing modes:
•Register mode addressing
•Immediate mode addressing
•Displacement mode addressing
80x86 in addition to the above addressing modes supports the additional modes of addressing:
i. Register Indirect
ii. Indexed
iii Based with Scaled index
iv) Types and sizes of operands:
MIPS and x86 support:
•8 bit (ASCII character), 16 bit(Unicode character)
•32 bit (Integer/word)
•64 bit (long integer/ Double word)
•32 bit (IEEE-754 floating point)
•64 bit (Double precision floating point)
•80x86 also supports 80 bit floating point operand.(extended double Precision).
v)Operations: The general category of operations are:
vi) Control flow instructions :All ISAs support:
Q4) List and explain important technologies, which has led to improvements in computer system?
A4)
The first and still the largest market in dollar terms is desktop computing. Desktop computing system cost range from $ 500 (low end) to $ 5000 (high-end configuration). Throughout this range in price, the desktop market tends to drive to optimize price- performance. The performance concerned is compute performance and graphics performance. The combination of performance and price are the driving factors to the customers and the computer designer. Hence, the newest, high performance and cost effective processor often appears first in desktop computers.
2. Servers
Servers provide large-scale and reliable computing and file services and are mainly used in the large-scale enterprise computing and web based services. The three important characteristics of servers are:
3. Embedded Computers
Simple embedded microprocessors are seen in washing machines, printers, network switches, handheld devices such as cell phones, smart cards video game devices etc. embedded computers have the widest spread of processing power an cost. The primary goal is often meeting the performance need at a minimum price rather than achieving higher performance at a higher price. The other two characteristic requirements are to minimize the memory and power. In many embedded applications, the memory can be substantial portion of the systems cost and it is very important to optimize the memory size in such cases. The application is expected to fit totally in the memory on the processor chip or off chip memory. The importance of memory size translates to an emphasis on code size which is dictated by the application. Larger memory consumes more power. All these aspects are considered while choosing or designing processor for the embedded applications.
Q5) Explain all the five generations of computer?
A5)
From the subject and software package points of read, initial generation computers were designed with one central process unit (CPU) that performed serial fixed-point arithmetic employing a program counter, branch directions, ANd an accumulator. The central processing unit should be concerned all told operation and I/O operations. Machine or assembly languages were used.
Representative systems embody the ENIAC (Electronic Numerical measuring device and Calculator) designed at the Moore faculty of the University of Pennsylvania in 1950; the IAS (Institute for Advanced Studies) laptop supported a style projected by John John von Neumann, Arthur Burks, and jazzman Goldstine at Princeton in 1946; and therefore the IBM until, the primary electronic stored-program business laptop designed by IBM in l953. Software package linkage wasn't enforced in early computers.
2. The Second Generation
Index registers, floating-point arithmetic, multiplexed memory, and I/O processors were introduced with second-generation computers. High-Level Languages (HLL), like FORTRAN, Algol, and COBOL, were introduced together with compilers, software package libraries, and execution monitors. Register transfer language was developed by Irving Reed (1957) for the systematic style of digital computers. Representative systems embody the IBM 7030 (the Stretch computer) that includes instruction look ahead and error-correcting recollections in built 1962, the Univac LARC (Livermore Atomic analysis Computer) inbuilt 1959, and therefore the agency 1604 in-built the Sixties.
3. Third Generation
The third generation was represented by the IBM 360/370 series, the CDC 6600/7600 series, Texas Instruments ASC and Digital Equipment’s PDP-8 Series from the mid-1960s to the mid-1970s.
Micro-programmed control became popular with this generation. Pipelining and cache memory were introduced to the close up the speed gap between the CPU and main memory. The idea of multiprogramming was implemented to interleave CPU and I/O activities across multiple user programs. This led to the development of time sharing operating system using virtual memory with greater sharing or multiplexing of resources.
4. Fourth Generation
Parallel computers in various architectures appeared in the fourth generations of computers using shared or distributed memory or optional vector hardware. Multiprocessor OS, special languages, and compilers were developed for parallelism. Software tools and environments were created for parallel processing or distributed computing.
Representative system include the VAX 9000, Cray X-MP, IBM/3090 VF, BBN TC-2000, etc. During these 15 years, the technology of parallel processing gradually became mature and entered the production mainstream.
5. Fifth Generation
These systems emphasize superscalar processor, clusters computers, and massively parallel processing. Scalable and latency tolerant architectures are being adopted in MPP systems using advanced VLSI technologies, high- density packaging, and optical technologies.
Fifth-generations computers achieved Teraflops performance by the mid-1990s, and have now crossed the range. Heterogeneous processing is emerging to solve large-scaled problems using a networks of heterogeneous computers. Early fifth-generations MPP systems were represented by several projects at Fujitsu, Cray Research, Thinking Machine Corporation, and Intel.
Q6) Explain Flynn’s Classification?
A6)
Flynn’s Classification
Flynn’s classification distinguishes multi- processor computer architectures per 2 free dimensions of Instruction stream and data stream. Associate in instruction stream is the sequence of directions dead by machine. And an information stream may be a sequence of information together with input, partial or temporary results utilized by instruction stream. Every of those dimensions will have just one of 2 do-able states: Single or Multiple. Flynn’s classification depends on the excellence between the performances of management unit and therefore the processing unit instead of its operational and structural interconnect ions. Following square measure the four class of Flynn classification and characteristic feature of every of them.
a) Single Instruction Stream, Single Data Stream (SISD):
• They also are referred to as scalar processor i.e., one instruction at a time and every instruction have just one set of operands.
• Single instruction: just one instruction stream is being acted on by the mainframe throughout clock cycle.
• Single data: just one data stream is being employed as input throughout any clock cycle.
• Deterministic execution.
• This is that the oldest and till recently, the foremost prevailing variety of computers.
• Examples: most PCs, single mainframe workstations, and mainframes.
b) Single Instruction Stream, Multiple Data Stream (SIMD) processors:
• A sort of parallel computers.
• Single instruction: All process units execute identical instruction issued by the management unit at any given clock cycle.
• Multiple Data: every process unit will treat a special data part. The processor is connected to shared memory or interconnection network providing multiple knowledge to the process unit.
• This type of machine typically has an instruct ion dispatcher, a very high- bandwidth internal network, and a very large array of very small-capacity instruction units.
• Thus single instruction is dead by totally different process units on different sets of information.
• Best suited to specialised issues characterised by a high degree of regularity, like image processing and vector computation.
• Synchronous and settled execution
Multiple Instruction Stream, Single Data Stream (MISD):
• A single knowledge stream is feed into multiple process units.
• Each process unit operates on the information severally via freelance instruction streams. one data stream is forwarded to a special process unit that is connected to the various management unit and executes instruction given thereto by the management unit to that it's connected.
• This design is additionally called linear arrays for pipelined execution of specific directions.
• Few actual samples of this category of parallel computers have ever existed. One is that the experimental Carnegie-Mellon Comp computers (1971).
d) Multiple Instruction Stream, Multiple Data Stream (MIMD)
• Every Processor may be executing a different instruct ion stream
• Multiple Data: each processor is also operating with a special knowledge stream. Multiple knowledge stream is provided by shared memory.
• Can be classified as loosely coupled or tightly coupled counting on the sharing of information and control.
• Execution may be synchronous or asynchronous, settled, or non- settled.
• Examples: most current supercomputers, networked parallel computers “grids" and multi-processor.
Q7) Explain differences between UMA and NUMA?
A7)
S.NO | UMA | NUMA |
1. | UMA stands for Uniform Memory Access. | NUMA stands for Non-uniform Memory Access. |
2. | In Uniform Memory Access, Single memory controller is used. | In Non-uniform Memory Access, Different memory controller is used. |
3. | Uniform Memory Access is slower than non-uniform Memory Access. | Non-uniform Memory Access is faster than uniform Memory Access. |
4. | Uniform Memory Access has limited bandwidth. | Non-uniform Memory Access has more bandwidth than uniform Memory Access. |
5. | Uniform Memory Access is applicable for general purpose applications and time-sharing applications. | Non-uniform Memory Access is applicable for real-time applications and time-critical applications. |
6. | In uniform Memory Access, memory access time is balanced or equal. | In non-uniform Memory Access, memory access time is not equal. |
7. | There are 3 types of buses used in uniform Memory Access which are: Single, Multiple and Crossbar. | While in non-uniform Memory Access, There are 2 types of buses used which are: Tree and hierarchical. |
Q8) Explain various Technology trends in computer industry?
A8)
The designer must be especially aware of rapidly occurring changes in implementation technology. The following Four implementation technologies changed the computer industry.
1. Integrated circuit logic technology: Transistor density increases by about35% per year, and die size increases 10% to 20% per year. The combined effect is a growth rate in transistor count on a chip of about 55% per year.
2. Semiconductor DRAM: Density increases by between 40% and 60% per year and Cycle time has improved very slowly, decreasing by about one-third in 10years. Bandwidth per chip increases about twice as fast as latency decreases. In addition, changes to the DRAM interface have also improved the bandwidth.
3. Magnetic disk technology: it is improving more than 100% per year. Prior to1990, density increased by about 30% per year, doubling in three years. It appears that disk technology will continue the faster density growth rate for some time to come. Access time has improved one-third in 10 years.
4. Network Technology: Network Performance depends both on the performance of switches and on the performance of the transmission system, both latency and bandwidth can be improved, though recently bandwidth has been the primary focus.
Scaling of Transistor Performance, Wires, and Power in Integrated Circuits
Transistor Performance:
Integrated circuit processes are characterized by the feature size, which is decreased from 10 microns in 1971 to 0.18 microns in 2001. Since a transistor is a2-dimensional object, the density of transistors increases quadratically with a linear decrease in feature size. The increase in transistor performance, this combination of scaling factors leads to a complex interrelationship between transistor performance and process feature size.
Wires
The signal delay for a wire increases in proportion to the product of its resistanceand capacitance. As feature size shrinks wires get shorter, but the resistance and capacitance per unit length gets worse. Since both resistance and capacitance depend on detailed aspects of the process, the geometry of a wire, the loading on a wire, and even the adjacency to other structures.
Power
Power also provides challenges as devices are scaled. For modern CMOS microprocessors, the dominant energy consumption is in switching transistors. The energy required per transistor is proportional to the product of the load capacitance of the transistor, the frequency of switching, and the square of the voltage.
Q9) Explain Distributed System?
A9)
Distributed Memory
Advantages:
• Memory is ascendible with variety of processors. Increase the amount of processors and therefore the size of memory will increase proportionately.
• Each processor will speedily access its own memory while not interference and while not the overhead incurred with making an attempt to take care of cache coherency.
• Cost-effectiveness: will use goods, ready-made processors, and networking.
Disadvantages:
Q10) Explain PRAM and VLSI Model?
A10)
PRAM and VLSI Models
The ideal model gives a suitable framework for developing parallel algorithms without considering the physical constraints or implementation details.
The models can be enforced to obtain theoretical performance bounds on parallel computers or to evaluate VLSI complexity on chip area and operational time before the chip is fabricated.
Parallel Random-Access Machines
Shepherdson and Sturgis (1963) modelled the conventional Uniprocessor computers as random-access-machines (RAM). Fortune and Wyllie (1978) developed a parallel random-access-machine (PRAM) model for modelling an idealized parallel computer with zero memory access overhead and synchronization.
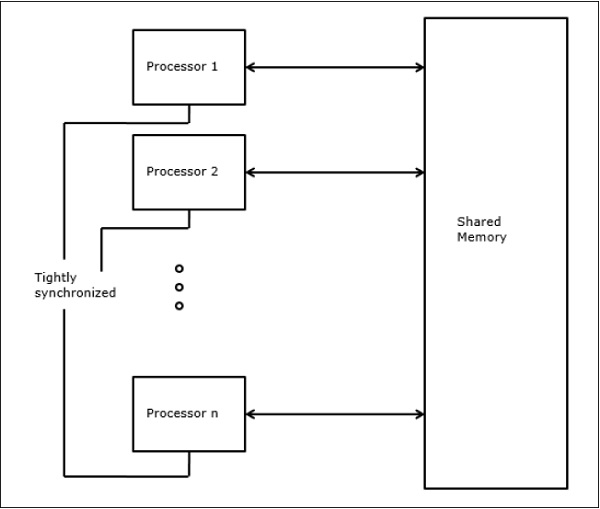
An N-processor PRAM has a shared memory unit. This shared memory can be centralized or distributed among the processors. These processors operate on a synchronized read-memory, write-memory and compute cycle. So, these models specify how concurrent read and write operations are handled.
Following are the possible memory update operations −
VLSI Complexity Model
Parallel computers use VLSI chips to fabricate processor arrays, memory arrays and large-scale switching networks.
Nowadays, VLSI technologies are 2-dimensional. The size of a VLSI chip is proportional to the amount of storage (memory) space available in that chip.
We can calculate the space complexity of an algorithm by the chip area (A) of the VLSI chip implementation of that algorithm. If T is the time (latency) needed to execute the algorithm, then A.T gives an upper bound on the total number of bits processed through the chip (or I/O). For certain computing, there exists a lower bound, f(s), such that
A.T2 >= O (f(s))
Where A=chip area and T=time




