Unit -1
Parallel and Distributed Databases
Q1) Evaluate the strategy for performing simple join and semijoin operation in distributed system?
A1)
Join Locations and Join Ordering
Consider the following relational-algebra expression:
r1 ⋈r2 ⋈r3
Consider that r1 is stored at site S1, r2 at S2, and r3 at S3. Let SI denote the site at which the query was issued. The system needs to produce the result at site SI. Among the possible strategies for processing this query are these:
• Ship copies of all three relations to site SI .
• Ship a copy of the r1 relation to site S2, and compute temp1 = r1 ⋈r2 at S2. Ship temp1 from S2 to S3, and compute temp2 = temp1 ⋈r3 at S3. Ship the result temp2 to SI .
• Devise strategies similar to the previous one, with the roles of S1, S2, S3 exchanged.
There are several other possible strategies.
No one strategy is always the best one. Considering the multiple factors that must the volume of data being shipped, the cost of transmitting a block of data between a pair of sites, and the relative speed of processing at each site. Consider the first strategy.
Suppose indices present at S2 and S3 are useful for computing the join. If we ship all three relations to SI , we would need to either re-create these indices at SI or use a different, possibly more expensive, join strategy. Re-creation of indices entails extra processing overhead and extra disk accesses. There are many variants of the second strategy, which process joins in different orders.
The cost of each of the strategies depends on the sizes of the intermediate results, the network transmission costs, and the costs of processing at each node. The query optimizer needs to choose the best strategy, based on cost estimates.
Semi join Strategy
Suppose that we want to evaluate the expression r1 ⋈r2, where r1 and r2 are stored at sites S1 and S2, respectively. Consider the schemas of r1 and r2 be R1 and R2. Suppose required the result at S1. If there are many tuples of r2 that do not join with any tuple of r1, then shipping r2 to S1 entails shipping tuples that fail to contribute to the result. We want to remove such tuples before shipping data to S1, particularly if network costs are high.
A possible strategy to accomplish all this is:
1. Compute temp1 ←ΠR1 ∩R2 (r1) at S1.
2. Ship temp1 from S1 to S2.
3. Compute temp2 ←r2 ⋈temp1 at S2.
4. Ship temp2 from S2 to S1.
5. Compute r1 ⋈temp2 at S1.The resulting relation is the same as r1 ⋈r2.
Before considering the efficiency of this strategy, let us verify that the strategy computes the correct answer. In step 3, temp2 has the result of
r2 ⋈ΠR1 ∩R2(r1).
In step 5, we compute: r1 ⋈r2 ⋈ΠR1 ∩R2(r1)
Since join is associative and commutative, we can rewrite this expression as:
(r1 ⋈ΠR1 ∩R2(r1)) ⋈r2
Since r1 ⋈Π(R1 ∩R2) (r1) = r1, the expression is, indeed, equal to r1 ⋈r2, the expression we are trying to evaluate.
This strategy is called a semijoin strategy, after the semijoin operator of the relational algebra. The natural semijoin of r1 with r2, denoted r1 ⋉r2, is defined as:
r1 ⋉r2 ≝ΠR1 (r1 ⋈r2)
Thus, r1 ⋉r2 selects those tuples of relation r1 that contributed to r1 ⋈r2. In step 3, temp2 = r2 ⋉r1. The semijoin operation is easily extended to theta-joins. The theta semijoin of r1 with r2, denoted r1 ⋉θr2, is defined as:
r1 ⋉θr2 ≝ΠR1 (r1 ⋈θr2)
For joins of several relations, the semijoin strategy can be extended to a series of semijoin steps. It is the job of the query optimizer to choose the best strategy based on cost estimates.
This strategy is particularly advantageous when relatively few tuples of r2 contribute to the join. This situation is likely to occur if r1 is the result of a relational-algebra expression involving selection. In such a case, temp2, that is, r2⋉r1,may have significantly fewer tuples than r2. The cost savings of the strategy result from having to ship only r2 ⋉r1, rather than all of r2, to S1.
Q2) With help of a suitable diagram, explain a typical transaction server system accessing data in a shared memory?
A2)
Transaction servers
Transaction server systems is known as query-server systems. These servers provides interface to the clients which can send requests to perform an action and in response they execute the some action and send back results to the client.
The client computer sends the transactions to the server systems then these transactions are executed, and results are send back to clients that are in charge of displaying the data. Requests are send with the help of SQL, and communicated to the server through a remote procedure call that is RPC mechanism. In that transactional RPC allows many RPC calls to form a transaction.
Open Database Connectivity (ODBC) is a C language application program interface standard from Microsoft for connecting to a server, sending SQL requests, and receiving results. JDBC standard is similar to ODBC, for Java.
Transaction Server Process Structure
A transaction server is collection of multiple processes which accessing data from shared memory. Following are the processes which are present in transaction server process structure.
Server processes
Server processes receive user queries that means transactions, execute these transactions and send the results back to the client. The queries may be submitted to the server processes from a user interface, or from a user process running embedded SQL, or through JDBC, ODBC, or similar protocols.
Some database systems use a separate process for each user session, and a few use a single database process for all user sessions, but with multiple threads so that multiple queries can execute concurrently. Many database systems use a hybrid architecture, with multiple processes, each one running multiple threads.
Database writer process
There are multiple processes that output modified buffer blocks back to disk on a continuous basis.
Lock manager process
This process performs lock manager functionality, which contains lock grant, lock release, and deadlock detection.
Log writer process
This process outputs log records from the log record buffer to stable storage.
Server processes can add log records to the log record buffer in shared memory, and if a log force is needed then they request the log writer process to output log records.
Checkpoint process
This process are used for periodic checkpoints.
Process monitor process
This process handles other processes, and if any of the process fails then it takes recovery actions for the process like aborting any transaction being executed by the failed process, and then restarting the process.

Figure 1.2 (I) shows shared memory and process structure.
The shared memory consist of all shared data, such as:
All database processes are used to access the data in shared memory. To perform these operation no two processes are accessing the same data structure at the same time therefore the databases systems implement mutual exclusion with the help of Operating system semaphores ar Atomic instructions like test-and-set.
To avoid overhead of inter process communication for lock request/grant, every database process operates directly on the lock table instead of sending requests to lock manager, process lock manager process still used for deadlock detection.
Q3) Explain general structure of a client-server system?
A3)
Client–Server Systems
As personal computers became faster, more powerful, and cheaper, therefore move away from the centralized system architecture. Personal computers supplanted terminals connected to centralized systems.
Personal computers assumed the user-interface functionality that used to be handled directly by the centralized systems. A centralized systems today act as server systems that satisfy requests generated by client systems.
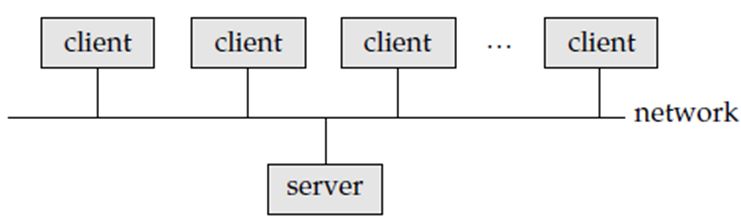
Figure 1.1.2(I) shows the general structure of a client–server system.
In the Client-server system Database functions can be divided into two parts as Front end and back end.
The front end of a database system contains tools such as forms, report writers, and graphical user interface facilities.
The back end is used to manage access structures of database, query evaluation and optimization, concurrency control, and recovery. In this Communication takes place between the front end and the back end through SQL or with the help of application programs.

Figure 1.1.2 (II) Front-end and back-end functionality.
Standards like ODBC and JDBC are developed to interface clients with servers. Any client that uses the ODBC or JDBC interfaces are connect to any server which provides the interface.
There are certain application programs, such as spreadsheets and statistical-analysis packages, use the client–server interface directly to access data from a back-end server.
Advantages of replacing mainframes with networks of workstations or personal computers connected to back-end server machines:
1. Provides the better functionality for the cost.
2. It supports flexibility for locating resources and increasing the facilities.
3. Easy to maintain.
4. It has Better user interface.
Q4) State issues in Data server architecture?
A4)
Data servers
Data-server systems supports clients to interact with the servers by sending requests to read or update data, in units like files or pages. For example, file servers provide a file-system interface then clients performs operations as create, update, read, and delete files.
Data servers for database systems provides more functionality. They support units of data like pages, tuples, or objects which are small than a file.
They provide indexing facilities for data, and provide transaction facilities therefore the data is not left in an inconsistent state when a client machine or process fails.
Issues occurs in such architecture
Page shipping versus item shipping
The unit of communication for data can be of coarse granularity, like a page, or fine granularity like a tuple.
Page shipping is considered as a form of prefetching if multiple items reside on a page, therefore all the items in the page are shipped when a process are ready to access a single item in the page.
Locking
Locks are granted by the server for the data items that it ships to the client machines.
A disadvantage of page shipping is that client machines might be granted locks of too coarse a granularity a lock on a page implicitly locks all items contained in the page. Even if the client is not accessing some items in the page, it has acquired locks on all pre-fetched items. Other client machines that require locks on same items may be blocked unnecessarily.
Data caching
Data that are shipped to a client in a transaction is cached at the client side, even after that the transaction completes, if there is required amount of storage space is available.
Successive transactions at the same client may be able to make use of the cached data. However, cache coherency is an issue: Even if a transaction finds cached data, it must make sure that those data are up to date, since they may have been updated by a different client after they were cached.
The message are still be exchanged with the server to check validity of the data, and to acquire a lock on the data.
Lock caching
Locks are absorbed by client system even in between transactions. The transactions can acquire cached locks locally, without contacting server. Server calls back locks from clients when it receives conflicting lock request. Client returns lock once no local transaction is using it same as de-escalation, but across transactions.
Q5) Explain the linear scalup in case of parallel system?
A5)
Scaleup related to the ability to process larger tasks in the same amount of time by providing more number of resources. Consider Q be a task, and QN is a task which is N times larger than Q. Suppose the execution time of task Q on a given machine MS is TS, and the execution time of task QN on a parallel machine ML is N times larger than MS, is TL.
The scaleup is defined as TS/TL. The parallel system ML is used for linear scaleup on task Q if TL = TS. If TL > TS, the system is said to be a sublinear scaleup. There are two types of scaleup in parallel database systems, based on how the size of the task is measured:
The goal of parallelism in database systems is to confirm that the database system can continue to perform at an acceptable speed, even as the size of the database and the number of transactions increases. Increasing the capacity of the system by increasing the parallelism provides a path for growth for an enterprise which replacing a centralized system by a faster machine.
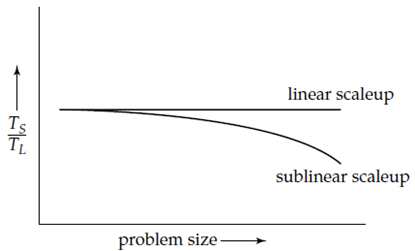
Figure 1.3(II) Scaleup with increasing problem size and resources.
More number of factors work against efficient parallel operation and effect on speedup and scaleup also.
Q6) Write note on interconnection networks?
A6)
Interconnection Networks
Parallel systems is a set of components like processors, memory, and disks which communicate with each other through an interconnection network. Following figure shows three types of interconnection networks:
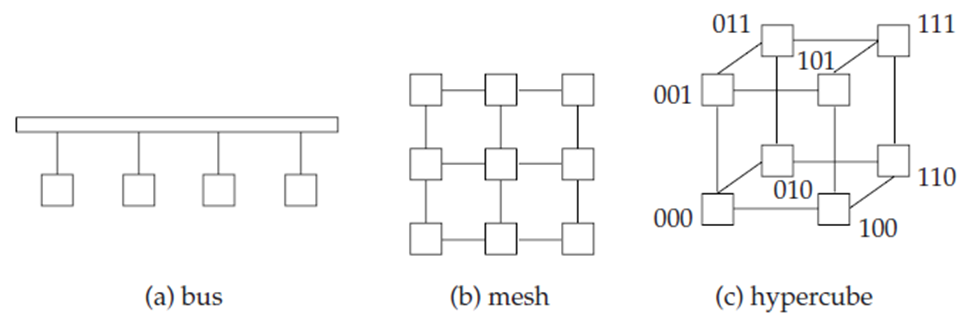
Figure 1.3(III) Interconnection networks.
Q7) Explain Parallel Database Architectures?
A7)
Parallel Database Architectures
There are many architectural models for parallel machine. Figure shows different architectures in which M represents memory, P represents a processor, and disks are shown as cylinders.
Techniques are used to increase the speed of transaction processing on data-server systems is data and lock caching and lock de-escalation. It is also used in shared-disk parallel databases and in shared-nothing parallel databases. They are very important for efficient transaction processing in such systems.

Figure 1.3 (IV) shows Parallel database architectures.
Shared Memory
In a shared-memory architecture, the processors and disks have access to a common memory through a bus or an interconnection network. The advantage of shared memory is extremely efficient communication between processors data in shared memory can be accessed by any processor without changing the software.
A processor send messages to other processors more faster by using memory writes than by sending a message via a communication mechanism. The drawbacks of shared-memory machines is that the architecture is not scalable more than 32 or 64 processors.
Adding multiple processors does not help after a point, since the processors will spend more time for waiting their turn on the bus to access memory. Shared-memory architectures consist of large memory caches at every processor therefore referencing of the shared memory is avoided when it possible. Therefore at least some of the data will not be in the cache, and accesses will go to the shared memory.
Shared Disk
In the shared-disk model all processors access multiple disks directly with help of an interconnection network, but the processors keeps a private memories. There are two benefits of this architecture compare with a shared-memory architecture. One is that every processor have its own memory and the memory bus is not a bottleneck. Second, it supports a cheap way to provide a degree of fault tolerance that means If a processor fails, the other processors can take over its tasks and the database is resident on disks that are accessible from all processors. The shared-disk architecture is used in many applications.
The main problem with a shared-disk system is scalability. Compared to shared-memory systems, shared-disk systems can scale to a larger number of processors, but communication with processors is slower.
Shared Nothing
In shared-nothing system every node consists of a processor, memory, and one or more disks. The processors at one node communicate with another processor at another node by a high-speed interconnection network.
Since local disk references are serviced by local disks at each processor, the shared-nothing model minimize the disadvantage of requiring all I/O to go through a single interconnection network; only queries, accesses to nonlocal disks, and result relations pass through the network.
The interconnection networks for shared-nothing systems are designed to be scalable, so their transmission capacity increases as more number of nodes are added. Shared-nothing architectures are more scalable and also support a large number of processors.
The drawbacks of shared-nothing systems is the costs of communication and of non local disk access, which is higher compare with shared-memory or shared-disk architecture since sending data contains a software interaction at both ends.The Grace and the Gamma research prototypes also used shared-nothing architectures.
Hierarchical
The hierarchical architecture combines the properties of shared-memory, shared disk, and shared-nothing architectures. At the top level is shared nothing architecture in this the system contains nodes connected by an interconnection network, and do not share disks or memory with others. Every node of the system is a shared-memory system with a few processors.
Every node is a shared-disk system share a set of disks is a shared-memory system. Therefore a system is built as a hierarchy, with help of shared-memory architecture, processors at the base, and a shared nothing architecture at the top and shared-disk architecture in the middle.
Figure d shows a hierarchical architecture with shared-memory nodes connected with each other in a shared-nothing architecture. Commercial parallel database systems today run on several of these architectures.
Q8) Explain in detail Implementation Issues for Distributed Databases?
A8)
Implementation Issues for Distributed Databases
Atomicity of transactions is important issue in distributed database system. If a transaction runs across two sites, unless the system designers are careful, it may commit at one site and abort at another and maintain an inconsistent state.
In transaction commit protocols these situation cannot arise. The two-phase commit protocol (2PC) is the mostly used in these protocols.
Concurrency control is also issue in a distributed database. Transaction can access data items from multiple sites, transaction managers at multiple sites need to coordinate to implement concurrency control.
Locking can be performed locally at the sites consist of accessed data items, but there is a possibility of deadlock taking part in transactions originating at multiple sites. Therefore deadlock detection required to be carried out across multiple sites.
Another disadvantage of distributed database systems is the added complexity need to make proper coordination between the sites. This increased complexity has multiple forms such as:
Software-development cost
It is more difficult to implement a distributed database system therefore it is more costly.
Greater potential for bugs
The sites witch contains the distributed system operate in parallel, it is harder to achive the correctness of algorithms also operation during failures of part of the system, and recovery from failures.
Increased processing overhead
The interchange of messages and the additional computation need to achieve inter site coordination are a form of overhead that doesn’t arise in centralized systems.
Q9) Write note on I/O Parallelism?
A9)
I/O Parallelism
I/O parallelism minimize the time needed to retrieve relations from disk by partitioning the relations on multiple disks. The common form of data partitioning in a parallel database is horizontal partitioning. In horizontal partitioning, the tuples in relation are divided into multiple disks, so that every tuple based on one disk.
Partitioning Techniques
There are three types of data-partitioning techniques. Consider there are n disks, D0, D1, . . ., Dn−1, across which the data are to be partitioned.
Q10) Write a short note on Inter query Parallelism?
A10)
Inter query Parallelism
In inter query parallelism multiple queries or transactions execute in parallel with one another. Transaction throughput is increased by this form of parallelism. Therefore the response times of every transactions are no faster than they would be if the transactions were run in isolation. The main use of interquery parallelism is to scaleup a transaction-processing system to support a larger number of transactions per second.
Interquery parallelism is the easiest form of parallelism to support in a database system particularly in a shared-memory parallel system. Database systems designed for single-processor systems can be used with no changes on a shared-memory parallel architecture even sequential database systems support concurrent processing. Transactions are operated in a time-shared concurrent manner on a sequential machine operate in parallel in the shared-memory parallel architecture.
Inter query parallelism is more complicated in a shared-disk or shared nothing architecture. Processors perform some tasks like locking and logging, in a coordinated fashion, and that requires that they pass messages to each other. A parallel database system ensure that two processors do not update the same data independently at the same time.
When a processor accesses or updates data then database system must ensure that the processor has the latest version of the data in its buffer pool. The problem is occur in this version is called as the cache-coherency problem.
Many protocols present to guarantee cache coherency and cache-coherency protocols are integrated with concurrency-control protocols so that their overhead is reduced. One protocol is used for a shared-disk system is this:
This protocol is used when a transaction sets a shared or exclusive lock on a page then gets the correct copy of the page. More complex protocols avoid the repeated reading and writing to disk needed by the preceding protocol. These protocols do not write pages to disk when exclusive locks are released. When a shared or exclusive lock is obtained and if the most recent version of a page is in the buffer pool of some processor then the page is obtained from there.
The protocols are designed to handle concurrent requests. The shared disk protocols can be extended to shared-nothing architectures by this method: Each page has a home processor Pi, and is stored on disk Di. When other processors want to read or write the page then they send requests to the home processor Pi of the page and they cannot directly communicate with the disk.
Q11) Write a short note on Intra query Parallelism?
A11)
Intra query Parallelism
Intra query parallelism is used for the execution of a single query in parallel on multiple processors and disks. Using intra query parallelism is important for speeding up long-running queries. Inter query parallelism does not help in this task and each query is run sequentially.
Suppose the relation is partitioned in multiple disks by range partitioning on some attribute, and the sort is requested on the partitioning attribute. The sort operation is apply by sorting each partition in parallel, then concatenating the sorted partitions to get the final sorted relation.
We can parallelize a query by parallelizing individual operations. There is another source of parallelism in evaluating a query: The operator tree for a query can contain many operations. We can parallelize the evaluation of the operator tree by evaluating in parallel some of the operations that do not depend on each other. The two operations can be executed in parallel on separate processors, one generate output that is consumed by the other.
The execution of a single query is parallelized in two different ways:
The number of operations in a typical query is small, compared to the number of tuples processed by each operation, the first form of parallelism can scale better with increasing parallelism. Therfore with the relatively small number of processors in parallel systems today, both forms of parallelism are important.
Q12) Explain Data Replication and Data Fragmentation?
A12)
Data Replication
If relation r is replicated, a copy of relation r is stored on multiple sites. In the some cases we have full replication, in which a copy is stored in every site in the system. There are a many advantages and disadvantages to replication.
Replication boost the performance of read operations and increases the availability of data which is related to read-only operations. Therefore update transactions produce greater overhead. Controlling concurrent updates with the help of multiple transactions to replicated data is more complex than in centralized systems. We can simplify the management of replicas of relation r by selecting one of them as the primary copy of r. Consider the example of banking in which account is related with the site in that account is opened. Same as in an airline reservation system, a flight is related with the site at which the flight originates.
Data Fragmentation
If relation r is fragmented, r is divided into many fragments like r1, r2, . . . , rn. These fragments contain sufficient information to allow reconstruction of the original relation r. There are two different technique for fragmenting a relation: horizontal fragmentation and vertical fragmentation. Horizontal fragmentation divide the relation with related to every tuple of r to multiple fragments. Vertical fragmentation divides the relation by decomposing the scheme R of relation r. Consider account schema
Account-schema = (account-number, branch-name, balance)
In horizontal fragmentation the relation r is divided into a number of subsets, r1, r2, . . . , rn. Each tuple of relation r is from at least one of the fragments, so that the original relation can be reconstructed, if needed. The account relation can be divided into multiple different fragments, each consists of tuples of accounts belonging to a particular branch.
If the banking system has only two branches Hillside and Valleyview then there are two different fragments:
account1 = σbranch-name = “Hillside” (account)
account2 = σbranch-name = “Valleyview” (account)
Horizontal fragmentation is used to maintain the tuples at the sites where they are used to reduce data transfer. A horizontal fragment is defined as a selection on the global relation r. In that we use a predicate Pi to construct fragment ri:
ri = σPi (r)
We reconstruct the relation r by taking the union of all fragments like
r =r1 ∪ r2 ∪···∪ rn
In example, the fragments are disjoint. By changing the selection predicates used to construct the fragments, we can have a particular tuple of r present in more than one of the ri. The vertical fragmentation is the same as decomposition. Vertical fragmentation of r(R) contains the definition of multiple subsets of attributes R1, R2, . . .,Rn of the schema R so that
R=R1 ∪ R2 ∪···∪ Rn
Each fragment ri of r is defined by
ri = ΠRi (r)
The fragmentation should be done like we can reconstruct relation r from the fragments by taking the natural join
r=r1 ⋈ r2 ⋈ r3 ⋈···⋈ rn
In vertical fragmentation, consider the example of company database with a relation employee-data it stores data of employee like empid, name, designation, salary etc. For security this relation is divided into a relation empprivate data contains empid and salary, and another relation emppublic-data consist of attributes empid, name, and designation. These are stored at multiple sites for security purpose.
The two types of fragmentation which are used with a single schema; for instance, the fragments achieved by horizontally fragmenting a relation which is afterwords partitioned vertically. Fragments are also be replicated.
Q13) Write a note on System Failure Modes Distributed Transactions?
A13)
System Failure Modes
In distributed system same types of failure occur that a centralized system does same as software errors, hardware errors, or disk crashes. There are additional types of failure with which we need to handle in a distributed environment. The basic types of failure are
The loss of messages is always a presented in a distributed system. The system uses transmission-control protocols, like TCP/IP, to handle these types of errors.
If two sites A and B are not directly connected, messages from one to the other must be routed through a sequence of communication links. If a communication link fails then the data transmitted over the link need to routed again. In some cases, it is possible to find another route via the network, so that the messages reach to their destination. In other cases, a failure may result in there being no connection between some pairs of sites. A system is partitioned if it has been divide into two subsystems, called partitions that lack any connection between them.
Q14) Describe how the two phase commit protocol operates during normal operation?
A14)
Two-Phase Commit
Consider a transaction T initiated at site Si and the Ci is a transaction coordinator.
The Commit Protocol
When transaction T completes its execution then all the sites at which T has executed inform Ci that T has completed and Ci starts the 2PC protocol.
The coordinator sends either a commit T or an abort T message to all participating sites. When a site receives a message after that it records the message in the log record.
A site at which T executed can unconditionally abort T at any time before it sends the message ready T to the coordinator. When the message is sent, the transaction in the ready state at the site. The ready T message is, in effect follow the coordinator’s order to commit T or to abort T. To make such a promise, the required data must first be stored in stable storage. Otherwise, if the site crashes after sending ready T. The locks acquired by the transaction need continue to be held until the transaction completes.
Handling of Failures
The 2PC protocol performed in different ways to several types of failures:
If no site has the actual information, then Sk neither abort nor commit T. The choice concerning T is postponed until Sk can obtain the needed information. Thus, Sk must periodically resend the query status message to the other sites. It continues to until a site which contains the needed information recovers.
d. The log contains no control records like abort, commit, ready related with T.Therefore the Sk failed before responding to the prepare T message from Ci. Since the failure of Sk precludes the sending of such a response, by our algorithm Ci need to abort T. Hence, Sk must execute undo(T).
Network partition.
When a network partitions, two possibilities exist:
The coordinator sites that are same partition coordinator follow commit protocol, assuming that the sites other partitions have failed. Thus, disadvantage of the 2PC protocol is that coordinator failure may blocking, where either to commit or to abort T may be postponed until Ci recovers.
Recovery and Concurrency Control
Recovery and Concurrency Control When a failed site restarts, perform recovery by using, the recovery algorithm. To deal with distributed commit protocols, the recovery procedure must treat in-doubt transactions specially; in-doubt transactions are transactions for which a <ready T> log record is found, but neither a <commit T> log record nor an <abort T> log record is found. The recovering site need to determine the commit–abort status of such transactions by contacting other sites. If recovery is completed as just described, however, normal transaction processing at the location cannot begin until all in-doubt transactions are committed or rolled back.
Finding the status of in-doubt transactions are often slow, since multiple sites may need to be contacted. Further, if the coordinator has failed, and no other site has information about the commit–abort status of an incomplete transaction, recovery potentially could become blocked if 2PC is employed .
As a result, the location performing restart recovery may remain unusable for an extended period. to bypass this problem, recovery algorithms typically provide support for noting lock information within the log. Instead of writing a <ready T> log record, the algorithm writes a <ready T, L> log record, where L is a list of all write locks held by the transaction T when the log record is written. At recovery time, after performing local recovery actions, for every in-doubt transaction T, all the write locks noted in the <ready T, L> log record are reacquired.
After lock reacquisition is complete for all in-doubt transactions, transaction processing can start at the location , even before the commit–abort status of the in-doubt transactions is decided .
The commit or rollback of in-doubt transactions proceeds concurrently with the execution of latest transactions. Thus, site recovery is quicker , and never gets blocked. Note that new transactions that have a lock conflict with anywrite locks held by in-doubt transactions are going to be unable to form progress until the conflicting in-doubt transactions are committed or rolled back.
Q15) Explain locking protocols in concurrency control system?
A15)
Locking Protocols
The various locking protocols introduced in concurrency-control are utilized in a distributed environment. the sole change that must be incorporated is within the way the lock manager deals with replicated data. We present several possible schemes that are applicable to an environment where data are often replicated in several sites. As in concurrency-control we shall assume the existence of the shared and exclusive lock modes.
1. Single Lock-Manager Approach
In the single lock-manager approach, the system maintains one lock manager that resides during a single chosen site say Si. All lock and unlock requests used at site Si. When a transaction must lock a knowledge item, it sends a lock request to Si. The lock manager determines whether the lock are often granted immediately.
If the lock are often granted, the lock manager sends a message thereto effect to the location at which the lock request was initiated. Otherwise, the request is delayed until it are often granted, at which era a message is shipped to the location at which the lock request was initiated. The transaction can read the info item from anybody of the sites at which a reproduction of the info item resides. within the case of a write, all the sites where a reproduction of the info item resides must be involved within the writing.
The scheme has these advantages:
• Simple implementation. This scheme requires two messages for handling lock requests, and one message for handling unlock requests.
• Simple deadlock handling. Since all lock and unlock requests are made at one site, the deadlock-handling algorithms discussed in concurrency control are often applied on to this environment.
The disadvantages of the scheme are:
• Bottleneck. the location Si becomes a bottleneck, since all requests must be processed there.
• Vulnerability. If the location Si fails, the concurrency controller is lost. Either processing must stop, or a recovery scheme must be used in order that a backup site can take over lock management from Si.
2. Distributed Lock Manager
A compromise between the benefits and drawbacks are often achieved through the distributed lock-manager approach, during which the lock-manager function is distributed over several sites. Each site maintains an area lock manager whose function is to administer the lock and unlock requests for those data items that are stored therein site.
When a transaction wishes to lock data item Q, which isn't replicated and resides at site Si, a message is shipped to the lock manager at site Si requesting a lock . If data item Q is locked in an incompatible mode, then the request is delayed until it are often granted. Once it's determined that the lock request are often granted, the lock manager sends a message back to the initiator indicating that it's granted the lock request.
There are several other ways of handling replication of knowledge items. The distributed lock manager scheme has the advantage of straightforward implementation, and reduces the degree to which the coordinator may be a bottleneck. it's a fairly low overhead, requiring two message transfers for handling lock requests, and one message transfer for handling unlock requests. However, deadlock handling is more complex, since the lock and unlock requests are not any longer made at one site:
There could also be inter site deadlocks even when there's no deadlock within one site. The deadlock-handling algorithms discussed in must be modified, to detect global deadlocks.
3. Primary Copy
When a system uses data replication, we will choose one among the replicas because the primary copy. Thus, for every data item Q, the first copy of Q must reside in just one site, which we call the first site of Q.When a transaction must lock a knowledge item Q, it requests a lock at the first site of Q. As before, the response to the request is delayed until it are often granted.
Thus, the first copy enables concurrency control for replicated data to be handled like that for un-replicated data. This similarity allows for an easy implementation. However, if the first site of Q fails, Q is inaccessible, albeit other sites containing a reproduction could also be accessible.
4. Majority Protocol
The majority protocol works this way: If data item Q is replicated in n different sites, then a lock-request message must be sent to quite one-half of the n sites during which Q is stored. Each lock manager find out whether the lock are granted immediately.
As before, the response is delayed until the request are often granted. The transaction doesn't operate Q until it's successfully obtained a lock on a majority of the replicas of Q. This scheme deals with replicated data during a decentralized manner, thus avoiding the drawbacks of central control. However, it suffers from these disadvantages:
•Implementation. the bulk protocol is more complicated to implement than are the previous schemes. It requires 2(n/2 + 1) messages for handling lock requests, and (n/2 + 1) messages for handling unlock requests.
• Deadlock handling. additionally to the matter of worldwide deadlocks thanks to the utilization of a distributed lock-manager approach, it's possible for a deadlock to occur albeit just one data item is being locked. As an illustration, consider a system with four sites and full replication. Suppose that transactions T1 and T2 want to lock data item Q in exclusive mode.
Transaction T1 may achieve locking Q at sites S1 and S3 and the transaction T2 may acquire locking Q at sites S2 and S4. Each then must wait to accumulate the third lock; hence, a deadlock has occurred. Luckily, we will avoid such deadlocks with relative ease, by requiring all sites to request locks on the replicas of a knowledge item within the same predetermined order.
5. Biased Protocol
The biased protocol is another approach to handling replication. The difference from the bulk protocol is that requests for shared locks are given more favorable treatment than requests for exclusive locks.
• Shared locks. When a transaction must lock data item Q, it simply requests a lock on Q from the lock manager at one site that contains a reproduction of Q.
•Exclusive locks. When a transaction need to lock data item Q, it requests a lock on Q from the lock manager in the least sites that contain a reproduction of Q. As earlier the response to the request is delayed until it are often granted. The biased scheme has the advantage of imposing less overhead on read operations than does the bulk protocol.
This savings is particularly significant in common cases during which the frequency of read is far greater than the frequency of write. However, the extra overhead on writes may be a disadvantage. Furthermore, the biased protocol shares the bulk protocol’s drawback of complexity in handling deadlock.
6. Quorum Consensus Protocol
The quorum consensus protocol is a next version of the majority protocol. The quorum consensus protocol assigns each site a non negative weight. It assigns read and write operations on an item x two integers, called read quorum Qr and write quorum Qw, that must satisfy the following condition, where S is the total weight of all sites at which x resides:
Qr + Qw > S and 2 * Qw > S
To execute a read operation required replicas must be read that their total weight is ≥ Qr. To execute a write operation, enough replicas must be written so that their total weight is ≥ Qw. The benifit of the quorum consensus approach is that it can permit the cost of either reads or writes to be selectively reduced by appropriately defining the read and write quorums.
For instance, with a little read quorum, reads got to read fewer replicas, but the write quorum are going to be higher, hence writes can succeed as long as correspondingly more replicas are available. Also, if higher weights are given to some sites , fewer sites got to be accessed for acquiring locks. In fact, by setting weights and quorums appropriately, the quorum consensus protocol can simulate the bulk protocol and therefore the biased protocols.
Q16) Write note on Deadlock Handling?
A16)
Deadlock Handling
The deadlock-prevention and deadlock-detection algorithms in Concurrency Control is used in a distributed system which provides modifications are made. For example, we will use the tree protocol by defining a worldwide tree among the system data items.
Similarly, the timestamp-ordering approach might be directly applied to a distributed environment. Deadlock prevention may end in unnecessary waiting and rollback. Furthermore, certain deadlock-prevention techniques may require more sites to be involved within the execution of a transaction than would rather be the case.
If we allow deadlocks to occur and believe deadlock detection, the most problem during a distributed system is deciding the way to maintain the wait-for graph. Common techniques for handling this issue require that every site keep an area wait-for graph. The nodes of the graph correspond to all or any the transactions that are currently either holding or requesting any of the things local thereto site.
For example, Figure shows a system containing two sites, each maintaining its local wait-for graph. Note that transactions T2 and T3 appear in both graphs, indicating that the transactions have requested items at both sites.
These local wait-for graphs are constructed within the usual manner for local transactions and data items. When a transaction Ti on site S1 needs a resource in site S2, it sends an invitation message to site S2. If the resource is held by transaction Tj , the system inserts a foothold Ti → Tj within the local wait-for graph of site S2.
Clearly, if any local wait-for graph features a cycle, deadlock has occurred. On the opposite hand, the very fact that there are not any t any cycles in any of the local wait-for graphs doesn't mean that there are no deadlocks. for instance this problem, we consider the local wait-for graphs of Figure. Each wait-for graph is a cyclic; nevertheless, a deadlock exists within the system because the union of the local wait-for graphs contains a cycle. This graph appears in Figure.
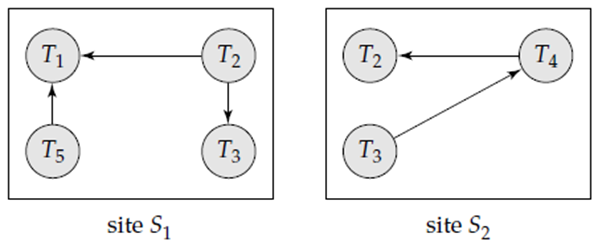
Figure Local wait-for graphs.
Figure Global wait-for graph.
In the centralized deadlock detection approach, the system constructs and maintains a global wait-for graph in a single site: the deadlock-detection coordinator. There is communication delay in the system need to distinguish between two types of wait-for graphs. The real graph shows the real but unknown state of the system at any instance in time. The constructed graph is an approximation generated by the controller during the execution of the controller’s algorithm. The global wait-for graph can be reconstructed or updated under following conditions:
• Whenever a new edge is added in or removed from one of the local wait-for graphs.
• Periodically, when a number of changes have occurred in a local wait-for graph.
• When the coordinator required to invoke the cycle-detection algorithm.
When the coordinator invokes the deadlock-detection algorithm, it searches its global graph. If it finds a cycle, it selects a victim to be rolled back. The coordinator need to notify all the sites that a particular transaction has been selected as victim. The sites, in turn, roll back the victim transaction. This scheme may produce unnecessary rollbacks if:
• False cycles present in the global wait-for graph. As shown in figure, consider a snapshot of the system represented by the local wait-for graphs of Figure . Suppose that T2 releases the resource that it is holding in site S1, resulting in the deletion of the edge T1 → T2 in S1.
Transaction T2 requests a resource held by T3 at site S2, resulting in the addition of the edge T2 → T3 in S2. If the insert T2 → T3 message from S2 arrives before the remove T1 → T2 message from S1, the coordinator may discover the false cycle T1 → T2 → T3 after the insert Deadlock recovery may be initiated therefore no deadlock has occurred.




