Unit -2
Object and object relational databases
Q1) What is an object identity? Explain object structure and collection types?
A1)
Object Identity
An OO database system provides a singular identity to every independent object stored within the database. This unique identity is usually implemented via a singular, system-generated object identifier, or OID. The worth of an OID isn't visible to the external user, but it's used internally by the system to spot each object uniquely and to make and manage inter-object references.
The main property required of an OID is that it's immutable; that’s, the OID value of a specific object shouldn't change. This maintain the identity of the real-world object being represented. Hence, an OO database system must have some mechanism for generating OIDs and preserving the immutability property. It’s also desirable that every OID be used only once; that’s, albeit an object is far away from the database, its OID shouldn't be assigned to a different object.
These two properties imply that the OID shouldn't depend upon any attribute values of the thing, since the worth of an attribute could also be changed or corrected. It’s also generally considered inappropriate to base the OID on the physical address of the thing in storage, since the physical address can change after a physical reorganization of the database.
However, some systems do use the physical address as OID to extend the efficiency of object retrieval. If the physical address of the thing changes, an indirect pointer are often placed at the previous address, which provides the new physical location of the thing. It’s more common to use long integers as OIDs then to use some sort of hash table to map the OID value to the physical address of the thing.
Some early OO data models required that everything from an easy value to a posh object be represented as an object; hence, every basic value, like an integer, string, or Boolean value, has an OID. This enables two basic values to possess different OIDs, which may be useful in some cases. For instance, the integer value 50 are often used sometimes to mean a weight in kilograms and at other times to mean the age of an individual.
Object Structure
In OO databases, the state (current value) of a posh object could also be constructed from other objects by using certain type constructors. One formal way of representing such objects is to look at each object as a triple (i, c, v), where i may be a unique object identifier (the OID), c may be a type constructor, and v is that the object state. The info model will typically include several type constructors.
The three most elementary constructors are atom, tuple, and set. Other constructors contains list, bag, and array. The atom constructor is employed to represent all basic atomic values, like integers, real numbers, character strings, Booleans, and the other basic data types that the system supports directly.
The object state v of an object (i, c, v) is interpreted supported the constructor c. If c = atom, the state (value) v is an atomic value from the domain of basic values supported by the system. If c = set, the state v may be a set of object identifiers, which are the OIDs for a group of objects that are typically of an equivalent type. If c = tuple, the state v may be a tuple of the shape, where each is an attribute name an OID.
If c = list, the worth v is an ordered list of OIDs of objects of an equivalent type. An inventory is analogous to a group except that the OIDs during a list are ordered, and hence we will ask the primary, second, or object during a list. For c = array, the state of the thing may be a single-dimensional array of object identifiers.
The main difference between array and list is that an inventory can have an arbitrary number of elements whereas an array typically features a maximum size. The difference between set and bag is that each one elements during a set must be distinct whereas a bag can have duplicate elements.
EXAMPLE 1: A Complex Object
We now represent some objects from the electronic database shown as following, using the preceding model, where an object is defined by a triple (OID, type constructor, state) and therefore the available type constructors are atom, set, and tuple. We use i1, i2,i3,….to stand for unique system-generated object identifiers. Consider the subsequent objects:
O1 =(i1, atom, 'Houston')
O2=(i2, atom, 'Bellaire')
O3 =(i3 , atom, 'Sugarland')
O4=(i4,atom,5)
O5=(i5,atom,’Research’)
O6=(i6,atom,’1998-5-22’)
O7=(i7,set,{i1,i2,i3})
EXAMPLE 2: Identical Versus Equal Objects
A example can described the difference between the two definitions for comparing object states for equality. Consider the following objects
O1= (i1, tuple, <a1:i4 , a2:i6 >)
O2=(i2, tuple, <a1 :i5, a2:i6 >)
O3= (i3 , tuple, <a1:i4 , a2:i6 >)
O4 = (i4, atom, 10)
O5= (i5, atom, 10)
O6 =(i6 , atom, 20)
The objects O1 and O2 have equal states, since their states at the atomic level are an equivalent but the values are reached through distinct objects O4 and O5. However, the states of objects O1 and O3 are identical, albeit the objects themselves aren't because they need distinct OIDs. Similarly, although the states of O4 and O5 are identical, the particular objects O4 and O5 are equal but not identical, because they need distinct OIDs.
Q2) Write a note on object persistence?
A2)
Specifying Object Persistence via Naming and Reachability
An OODBMS is usually closely including an OOPL. The OOPL is employed to specify the tactic implementations also as other application code. An object is usually created by some executing application, by invoking the thing constructor operation. Not all objects are meant to be stored permanently within the database. Transient objects exist within the executing program and disappear once the program terminates. Persistent objects are stored within the database and persist after program termination. The standard mechanisms for creating an object persistent are naming and reachability.
The naming mechanism involves giving an object a singular persistent name through which it are often retrieved by this and other programs. All such names given to things must be unique within a specific database. Hence, the named persistent objects are used as entry points to the database through which users and applications can start their database access.
Obviously, it's not practical to offer names to all or any objects during a large database that has thousands of objects, so most objects are made persistent by using the second mechanism, called reachability. The reachability mechanism works by making the thing reachable from some persistent object. An object B is claimed to be reachable from an object A if a sequence of references within the object graph lead from object A to object B.

Figure 2.1.4(II) Creating persistent objects by naming and reachability.
If we first create a named persistent object N, whose state is a set or list of objects of some class C, we will make objects of C persistent by adding them to the set or list, and thus making them reachable from N. Therefore N defines a persistent collection of objects of class C. For instance, we will define a class DepartmentSet whose objects are of type set (Department). Suppose that an object of type DepartmentSet is made, and suppose that it is named AllDepartments and thus made persistent.
Any Department object which is added to the set of AllDepartments by using the add_dept operation becomes persistent by virtue of its reachable from AllDepartments. The AllDepartments object is usually called the extent of the class Department, because it will hold all persistent objects of type Department. The ODMG ODL standard gives the schema designer the choice of naming an extent as a part of class definition.
The difference between traditional database models and OO databases during this respect. In traditional database models, like the relational model or the EER model, all objects are consider as persistent. Therefore when an entity type or class like EMPLOYEE is defined within the EER model, it represents both the type declaration for EMPLOYEE and a persistent set of all EMPLOYEE objects.
In the object oriented a class declaration of EMPLOYEE specifies only the type and operations for a class of objects. The user need to separately define a persistent object of type set(EMPLOYEE) or list(EMPLOYEE) whose value is the collection of references to all persistent EMPLOYEE objects, if this is desired. In fact, it is possible to define multiple persistent collections for the same class definition, if desired. This allows transient and persistent objects to follow the equivalent type and class declarations of the ODL and the OOPL.
Q3) Describe the inheritance hierarchy for the built in interface of the object model?
A3)
Type Hierarchies and Inheritance
Another characteristic of OO database systems is it allow type hierarchies and inheritance. Type hierarchies in databases imply a constraint on the extents related to the types in the hierarchy. We use a different OO model in a model in which attributes and operations are treated uniformly since both attributes and operations can be inherited.
Type Hierarchies and Inheritance
In all database applications, there are numerous objects of the same type or class. Therefore OO databases need to provide an ability for classifying objects based on their type. But in OO databases, a further requirement is that the system permit the definition of new types depends on other predefined types, leading to a type (or class) hierarchy.
A type is defined by assigning it a type name and then defining a number of attributes and operations for the type. In some cases, the attributes and operations are collectively called functions, since attributes resemble functions with zero arguments. A function name is used to refer to the value of an attribute or to refer to the resulting value of an operation.
A type in its simplest form will be defined by giving it a type name and then listing the names of its visible functions. When specifying a type we use the following format, which does not specify arguments of functions, to simplify the discussion:
TYPE_NAME: function, function, . . . , function
For example, a type that shows the characteristics of a PERSON can be defined as follows:
PERSON: Name, Address, Birthdate, Age, SSN
In the PERSON type, the Name, Address, SSN, and Birthdate functions are implemented as stored attributes and the Age function can be implemented as a method that calculates the Age from the value of the Birthdate attribute and the current date.
The concept of subtype is useful when the designer or user must create a new type which is similar but not identical to an already defined type. The subtype then inherits all the functions of the predefined type, which we call the supertype. For example consider that we want to define two new types EMPLOYEE and STUDENT as follows:
EMPLOYEE: Name, Address, Birthdate, Age, SSN, Salary, HireDate, Seniority
STUDENT: Name, Address, Birthdate, Age, SSN, Major, GPA
Since both STUDENT and EMPLOYEE contains all the functions defined for PERSON with some additional functions of their own, we will declare them to be subtypes of PERSON. Each will inherit the previously defined functions of PERSON namely, Name, Address, Birthdate, Age, and SSN. For STUDENT, it’s only necessary to define the new (local) functions Major and GPA, which not inherited.
Presumably, Major are often defined as a stored attribute, whereas GPA could be also implemented as a way that calculates the student’s grade mark average by accessing the Grade values that are internally stored (hidden) within every STUDENT object as private attributes. For EMPLOYEE, the Salary and HireDate functions are stored attributes, and Seniority could also be a way that calculates Seniority from the worth of HireDate.
The idea of defining a kind contains defining all of its functions and implementing them as attributes or methods. When a subtype is defined, it can then inherit all of those functions and their implementations. Only functions that are specific or local to the subtype, and hence aren't implemented within the supertype, got to be defined and implemented. Therefore, we will declare EMPLOYEE and STUDENT as follows:
EMPLOYEE subtype-of PERSON: Salary, HireDate, Seniority
STUDENT subtype-of PERSON: Major, GPA
In general, a subtype includes all of the functions that are defined for its supertype plus some additional functions that are specific only to the subtype. Hence, it's possible to get a type hierarchy to point out the supertype/subtype relationships among all the kinds declared within the system.
As another example, consider a kind that describes objects in geometry, which can be defined as follows:
GEOMETRY_OBJECT: Shape, Area, ReferencePoint
For the GEOMETRY_OBJECT type, Shape is implemented as an attribute and Area is a method that is applied to calculate the area. Consider that we want to define a number of subtypes for the GEOMETRY_OBJECT type, as follows:
RECTANGLE subtype-of GEOMETRY_OBJECT: Width, Height
TRIANGLE subtype-of GEOMETRY_OBJECT: Side1, Side2, Angle
CIRCLE subtype-of GEOMETRY_OBJECT: Radius
Notice that the Area operation cloud be also implemented by a special method for every subtype, since the procedure for area calculation is different for rectangles, triangles, and circles. Similarly, the attribute Reference Point may have a special meaning for every subtype; it might be the center point for RECTANGLE and CIRCLE objects, and therefore the vertex point between the two given sides for a TRIANGLE object. Some OO database systems allow the renaming of inherited functions in several subtypes to reflect the meaning more closely.
An alternative way of declaring these three subtypes is to specify the value of the Shape attribute as a condition that has got to satisfied for objects of every subtype:
RECTANGLE subtype-of GEOMETRY_OBJECT (Shape=‘rectangle’): Width, Height
TRIANGLE subtype-of GEOMETRY_OBJECT (Shape=‘triangle’): Side1, Side2, Angle
CIRCLE subtype-of GEOMETRY_OBJECT (Shape=‘circle’): Radius
Here, only GEOMETRY_OBJECT objects whose Shape=‘rectangle’ are of the subtype RECTANGLE, and same for the other two subtypes. In this all functions of the GEOMETRY_OBJECT supertype are inherited by each of the three subtypes, but the value of the Shape attribute is restricted to a specific value for each.
Constraints on Extents Corresponding to a Type Hierarchy
In most OO databases, the collection of objects in an extent has the equivalent type or class. However, this is often not a necessary condition. For instance SMALLTALK, a so-called typeless OO language, allows a set of objects to contain objects of various types.
This can even be the case when other non-object-oriented typeless languages, like LISP, are extended with OO concepts. However, most object oriented databases support types, we will assume that extents are collections of objects of the equivalent type.
It is common in database applications that every type or subtype will have an extent associated with it holds the set of all persistent objects of that type or subtype. In this case, the constraint is that every object in an extent that corresponds to a subtype must also be a member of the extent that corresponds to its supertype.
Some object oriented database systems have a predefined system type whose extent contains all the objects within the system. Classification then proceeds by assigning objects into additional subtypes that are meaningful to the application, creating a type hierarchy or class hierarchy for the system. All extents for system and user-defined classes are subsets of the extent related to the class OBJECT, directly or indirectly. In the ODMG model, the user may or may not specify an extent for each class (type), depending on the application.
In most object orientd systems, a distinction is made between persistent and transient objects and collections. A persistent collection is a collection of objects that is stored fixed in the database and can be accessed and shared by several programs. A transient collection exists temporarily during the execution of a program but is not kept when the program terminates.
For example, a transient collection could be also created during a program to carry the result of a query that selects some objects from a persistent collection and copies these objects into the transient collection. The transient collection has the identical type of objects because the persistent collection. The program manipulate the objects in the transient collection, and once the program terminates, the transient collection ceases to exist. Generally, numerous collections transient or persistent may contain objects of the equivalent type.
The type constructors allow the state of one object to be a set of objects. Therefore collection objects whose types are based on the set constructor can define a number of collections one like each object. The set-valued objects are members of another collection. This support for multilevel classification schemes, where an object in one collection has as its state a collection of objects of a different class.
The ODMG 2.0 model distinguishes between type inheritance called interface inheritance and denoted by the ":" symbol extent inheritance constraint denoted by the keyword EXTEND.
Q4) Define complex object?
A4)
Complex Objects
A principal motivation used to the development of object oriented systems to represent complex objects. There are two types of complex objects: structured and unstructured. A structured complex object is built with help of components and is defined by applying the available type constructor’s recursively at multiple levels. An unstructured complex object is a data type that need a large amount of storage, like a data type that represents an image or a large textual object.
Unstructured Complex Objects and Type Extensibility
An unstructured complex object is provided by a DBMS permits the storage and retrieval of large objects that are required by the database application. Consider example of objects are bitmap images and long text strings; they are called as binary large objects, or BLOBs in short. These objects are unstructured because the DBMS does not know what their structure is only the application that uses them can interpret their meaning.
For example, the application have functions to display an picture or to search for a few keywords during a long text string. The objects are considered complex because they have a large area of storage which isn’t part of the standard data types provided by DBMSs. Because the object size is big, a DBMS retrieve a part of the object and provide the application program before the entire object is retrieved. The DBMS use buffering and caching techniques to prefetch part of the object before the application program must access them.
The DBMS software does not have the capability to directly process selection conditions and other operations depends on values of these objects, unless the application provides the code to do the comparison operations required for the selection. In an OODBMS, this can be accomplished by defining a new abstract data type for the uninterpreted objects and by providing the methods for selecting, comparing, and displaying these objects.
For example, suppose objects that are two-dimensional bitmap images and the application required to select from a collection of such objects only those that include a certain pattern. In this case, the user needs to provide the pattern recognition program as a method on objects of the bitmap type. The OODBMS then retrieves an object from the database and runs the method for pattern recognition on it to determine whether the object includes the specified pattern.
Because an OODBMS allows users to make new types, and since a kind includes both structure and operations, we will view an OODBMS as having an extensible type system. We will create libraries of latest types by defining their structure and operations, including complex types. Applications can then use or modify these types, within the latter case by creating subtypes of the kinds provided within the libraries.
However, the DBMS internals must provide the underlying storage and retrieval capabilities for objects that need large amounts of storage in order that the operations could also be applied efficiently. Many OODBMSs provide for the storage and retrieval of huge unstructured objects like character strings or bit strings, which may be passed "as is" to the application program for interpretation. Recently, relational and extended relational DBMSs have also been ready to provide such capabilities.
Structured Complex Objects
A structured complex object differs from an unstructured complex object therein the object’s structure is defined by repeated application of the sort constructors provided by the OODBMS. Hence, the thing structure is defined and known to the OODBMS. As an example, consider the DEPARTMENT object shown in above Figure. At the primary level, the thing features a tuple structure with six attributes: DNAME, DNUMBER, MGR, LOCATIONS, EMPLOYEES, and PROJECTS.
Therefore two of these attribute like DNAME and DNUMBER contains a basic values; the other four contains complex values and therefore build the second level of the complex object structure. One of these four (MGR) has a tuple structure, and the other three (LOCATIONS, EMPLOYEES, PROJECTS) have set structures.
At the third level, for a MGR tuple value contains one basic attribute (MANAGERSTARTDATE) and one attribute (MANAGER) which refers to an employee object, which features a tuple structure. For a LOCATIONS set, we've a group of basic values, except for both the workers and therefore the PROJECTS sets, we've sets of tuple-structured objects.
There are two sorts of reference semantics available during a complex object and its components at every level. the primary type, says as ownership semantics, applies when the sub-objects of a posh object are encapsulated within the complex object and are considered as a part of the complex object. The second type, called reference semantics, applies when the components of the complex object are themselves independent objects but are often referenced from the complex object.
For example consider the DNAME, DNUMBER, MGR, and LOCATIONS attributes to be owned by a DEPARTMENT, whereas EMPLOYEES and PROJECTS are references because they reference independent objects. The first type is also referred to as the is-part-of or is-component-of relationship; and the second type is called the is-associated-with relationship and it describes an equal association between two independent objects.
The is-part-of relationship for constructing complex objects has the property that the component objects are encapsulated within the complex object and are considered a part of the internal object state. They have not have object identifiers and may only be accessed by methods of that object. They’re deleted if the thing itself is deleted. On the opposite hand, a complex object whose components are referenced is taken into account to contain independent objects which will have their own identity and methods.
When a complex object must access its referenced components, it must do so by invoking the acceptable methods of the components, since they're not encapsulated within the complex object. Hence, reference semantics represents relationships among independent objects. Additionally, a referenced component object could also be referenced by quite one complex object and hence isn't automatically deleted when the complex object is deleted.
An OODBMS should provide storage options for clustering the component objects of a complex object together on secondary storage so as to extend the efficiency of operations that access the complex object. In many cases, the thing structure is stored on disk pages in an uninterpreted fashion.
When a disk page that has an object is retrieved into memory, the OODBMS can build up the structured complex object from the knowledge on the disk pages, which can ask additional disk pages that has got to be retrieved. this is often referred to as complex object assembly.
Q5) Define attributes, relationships, and operations in a class definition?
A5)
The properties define the state of the object and are further distinguished into attributes and relationships. During this subsection, we describe on the three sorts of components—attributes, relationships, and operation during which a user-defined object type for atomic (structured) objects can include. We show our discussion with the 2 classes Employee and Department shown in Figure.

Figure 2.3(I) The attributes, relationships, and operations in a class definition.
An attribute may be a property that describes some aspect of an object. Attributes have values, which are typically literals having a simple or complex structure that are stored within the object. However, attribute values also can be Object_Ids of other objects. Attribute values can even be specified via methods that are wont to calculate the attribute value. The attributes for Employee are name, ssn, birthdate, sex, and age, and people for Department are dname, dnumber, mgr, locations, and projs.
A relationship isa property that specifies that two objects within the database are related together. Within the object model of ODMG, only binary relationships are explicitly represented, and every binary relationship is represented by a pair of inverse references specified via the keyword relationship. One relationship exists that relates each Employee to the Department during which he or she works the works for relationship of Employee.
In addition to attributes and relationships, the designer can include operations in object type (class) specifications. Each object type can have variety of operation signatures, which specify the operation name, its argument types, and its returned value, if applicable. Operation names are unique within each object type, but they will be overloaded by having an equivalent operation name appear in distinct object types.
Interfaces, Classes, and Inheritance
In the ODMG 2.0 object model, two concepts exist for specifying object types: interfaces and classes. Additionally, two sorts of inheritance relationships exist. During this section, we discuss the differences and similarities among these concepts. Following the ODMG 2.0 terminology, we use the word behavior to see operations, and state to refer to properties.
An interface may be a specification of the abstract behavior of an object type, which specifies the operation signatures. Although an interface may have state properties as a part of its specifications, these can't be inherited from the interface, as we shall see. An interface is also no instantiable that's , one cannot create objects that correspond to an interface definition.
A class may be a specification of both the abstract behavior and abstract state of an object type, and is instantiable that's , one can create individual object instances like a class definition. Because interfaces are non-instantiable, they're mainly wont to specify abstract operations which will be inherited by classes or by other interfaces.
This is called behavior inheritance and is specified by the ":" symbol. Hence, within the ODMG 2.0 object model, behavior inheritance requires the supertype to be an interface, whereas the subtype might be either a class or another interface.
Another inheritance relationship, called EXTENDS and specified by the extends keyword, is employed to inherit both state and behavior strictly among classes. In an EXTENDS inheritance, both the supertype and therefore the subtype must be classes.
Multiple inheritance via EXTENDS isn't permitted. However, multiple inheritance is allowed for behavior inheritance via ":". Hence, an interface may inherit behavior from several other interfaces. a class can also inherit behavior from several interfaces via ":", additionally to inheriting behavior and state from at the most one other class via EXTENDS.
Q6) Define ODL?
A6)
The Object Definition Language
The ODL is designed to support the semantic constructs of the ODMG 2.0 object model and is independent of any particular programming language. Its main use is to create object specifications like a classes and interfaces.
Hence, ODL is not a full programming language. A user can specify a database schema in ODL independently of any programming language, then use the specific language is to specify how ODL constructs can be mapped to constructs in specific programming languages like C++, SMALLTALK, and JAVA.
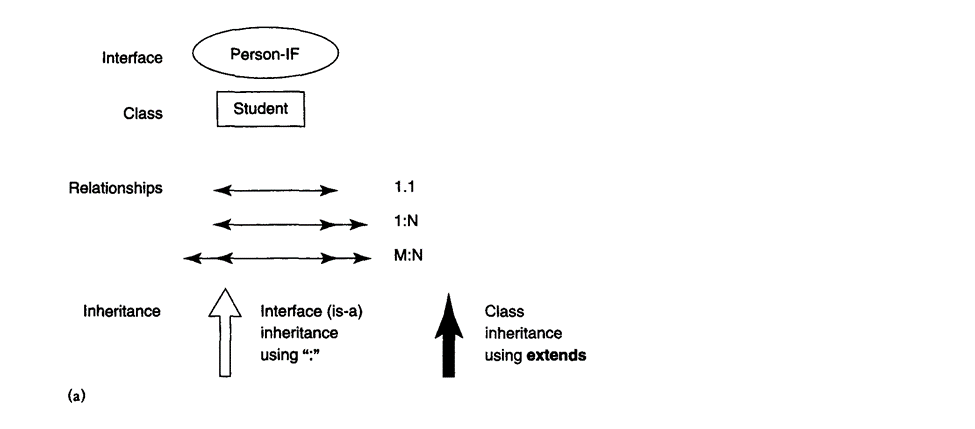
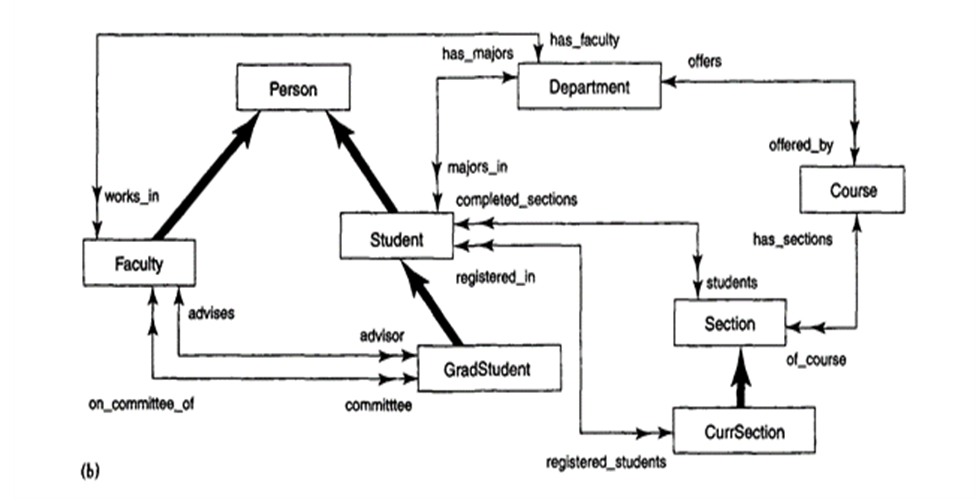
Figure 2.4.1(I)
An example of a database schema. (a) Graphical notation for representing mas. (b) A graphical object database schema for part of the UNIVERSITY database.
The graphical notation for Figure (b) is described in Figure (a) and can be considered as a variation of EER diagrams with the added concept of interface inheritance but without several EER concepts, such as categories and attributes of relationships.
Figure shows one possible set of ODL class definitions for the UNIVERSITY database. In general, there may be several possible mappings from an object schema diagram (or EER schema diagram) into ODL classes.

Figure 2/4/1(II) Possible ODL schema for the UNIVERSITY database
Entity types are mapped into ODL classes, and inheritance is performed using EXTENDS. There is no direct way to map categories or to do multiple inheritance. In Figure the classes Person, Faculty, Student, and GradStudent have the extents persons, faculty, students, and grad_students, respectively. Both Faculty and Student EXTENDS Person, and GradStudent EXTENDS Student.
The collection of students is constrained to be a subset of the collection of persons at any point in time. Same as the group of grad_students will be a subset of students. At the same time, individual Student and Faculty objects will inherit the properties and operations of Person, and individual GradStudent objects will inherit those of Student.
Multiple inheritance of interfaces by a class is allowed, as multiple inheritance of interfaces by another interface. Therefore with the EXTENDS inheritance, multiple inheritance is not permitted. So a class can inherit through EXTENDS from at most one class.
Q7) Define OQL?
A7)
The Object Query Language
The object query language (OQL) is the query language proposed for the ODMG object model. It’s designed to closely with the programming languages that an ODMG binding is defined, like C++, SMALLTALK, and JAVA. OQL query is embedded into one among above programming languages can return objects that match the sort system of that language.
In addition, the implementations of class operations in an ODMG schema also have their code written in these programming languages. The OQL syntax for queries is same as to the syntax of the relational standard query language SQL, with extra features for ODMG concepts, like object identity, complex objects, operations, inheritance, polymorphism, and relationships.
Simple OQL Queries, Database Entry Points, and Iterator Variables
The basic OQL syntax is a select . . . from . . . where . . . structure, as for SQL. For example, the query to retrieve the names of all departments in the college of ‘Engineering’ was written as follows:
Q0: select d.dname from d in departments where d.college=’Engineering’;
In general, an entry point to the database is need for every query, which can be any named persistent object. For several queries, the entry point is that the name of the extent of a class. Recall that the extent name is taken into account to be the name of a persistent object whose type may be a group of objects from the class.
The use of an extent name departments in Q0 as an entry point referred a persistent collection of objects. Whenever a set is referenced in an OQL query is always define an iterator variable d in Q0 that ranges over each object within the collection. In many cases, as in Q0, the query will select certain objects from the collection, supported the conditions per the where-clause.
In Q0, only persistent objects d within the collection of departments that satisfy the condition d.college = ‘Engineering’ are selected for the query result. for every selected object d, the value of d.dname is retrieved within the query result. Hence, the kind of the result for Q0 is bag, because the type of every dname value is string. Generally, the results of a query would be of type bag for select . . . from . . . and of type set for select distinct . . . from . . ., as in SQL (adding the keyword distinct eliminates duplicates).
Using the example in Q0, there are three syntactic options for specifying iterator variables:
d in departments
departments d
departments as d
We will use the primary construct in our examples.
The named objects used as database entry points for OQL queries aren't limited to the names of extents. Any named persistent object, it refers to an atomic object or to a collection object can be used as a database entry point.
Query Results and Path Expressions
The result of a query can in general be of any type that can be expressed in the ODMG object model. A query does not have to follow the select . . . from . . . where . . . structure; in the simplest case, any persistent name on its own is a query, whose result is a reference to that persistent object. For example, the query
Q1: departments;
Returns a regard to the collection of all persistent department objects, whose type is about. Similarly, suppose we had given a persistent name csdepartment to one department object (the computer science department); then, the query:
Q1a: csdepartment;
Returns a regard to that individual object of type Department. Once an entry point is specified, the concept of a path expression are often used to specify a path to related attributes and objects. A path expression typically starts at a persistent object name, or at the iterator variable that ranges over individual objects during a collection.
This name are going to be followed by zero or more relationship names or attribute names connected using the dot notation. For instance, referring to the UNIVERSITY database the subsequent are samples of path expressions, which also are valid queries in OQL:
Q2: csdepartment.chair;
Q2a: csdepartment.chair.rank;
Q2b: csdepartment.has_faculty;
The first expression Q2 returns an object of type Faculty, because that's the type of the attribute chair of the Department class. this may be a regard to the faculty object that's associated with the department object whose persistent name is csdepartment via the attribute chair; that's , a regard to the faculty object who is chairperson of the computer science department.
The second expression Q2a is analogous, except that it returns the rank of this Faculty object instead of the thing reference; hence, the type returned by Q2a is string, which is that the data type for the rank attribute of the faculty class.
Path expressions Q2 and Q2a return single values, because the attributes chair (of Department) and rank (of Faculty) are both single-valued and that they are applied to one object. The third expression Q2b is different; it returns an object of type set even when applied to one object, because that's the type of the relationship has_faculty of the Department class.
The collection returned will include references to all or any Faculty objects that are associated with the department object whose persistent name is csdepartment via the relationship has faculty; that's , references to all or any Faculty objects who are working within the computer science department. Now, to return the ranks of computer science faculty, we cannot write
Q3’: csdepartment.has_faculty.rank;
This is because it's not clear whether the object returned would be of type set or bag. Due to this type of ambiguity problem, OQL doesn't allow expressions like Q3’. Rather, one must use an iterator variable over these collections, as in Q3a or Q3b below:
Q3a: select f.rank from f in csdepartment.has_faculty;
Q3b: select distinct f.rank from f in csdepartment.has_faculty;
Here, Q3a returns bag that means duplicate rank values appear within the result, whereas Q3b returns set. Both Q3a and Q3b illustrate how an iterator variable are often defined within the from-clause to range over a restricted collection specified in the query.
The variable f in Q3a and Q3b ranges over the weather of the collection csdepartment.has_faculty, which is of type set, and includes only those faculty that are members of the computer science department.
In general, an OQL query can return a result with a complex structure specified in the query itself by utilizing the struct keyword. Consider the subsequent two examples:
Q4: csdepartment.chair.advises;
Q4a: select struct (name:struct(last_name: s.name.lname, first_name: s.name.fname), degrees:(select struct (deg: d.degree, yr: d.year, college: d.college) from d in s.degrees) from s in csdepartment.chair.advises;
Here, Q4 is simple, returning an object of type set as its result; this is often the collection of graduate students that are advised by the chair of the computer science department. Now, suppose that a query is required to retrieve the last and first names of those graduate students, plus the list of previous degrees of every . This are often written as in Q4a, where the variable s ranges over the collection of graduate students advised by the chairperson, and therefore the variable d ranges over the degrees of every such student s. the type of the results of Q4a may be a collection of (first-level) structs where each struct has two components: name and degrees. The name component may be a further struct made from last_name and first_name, each being a single string. The degrees component is defined by an embedded query and is itself a set of further structs, each with three string components: deg, yr, and college.




