Unit - 4
Database Security and Authorization
Q1) Explain different types of database security issues?
A1)
Types of Security
Database security is a very large area which contains many issues such as:
Threats to Databases
Threats to databases generate loss of all the security goals such as integrity, availability, and confidentiality.
• Loss of integrity: Database integrity means the need that information be protected from improper modification. Modification of data contains creation, insertion, modification, changing the status of data, and deletion. Integrity is lost if unauthorized changes are performed in data by intentional or accidental acts. If the loss of system or data integrity is not corrected then the continued use of the contaminated system or corrupted data could result in inaccuracy, fraud, or erroneous decisions.
• Loss of availability: Database availability refers to making objects available to a human user or a program to which they have a legitimate right.
• Loss of confidentiality: Database confidentiality means the protection of data from unauthorized disclosure. The effect of unauthorized disclosure of confidential information can range from violation of the Data Privacy Act of national security. Unauthorized, unanticipated, or unintentional disclosure could lead to loss of public confidence, embarrassment, or action against the organization.
To protect databases from these sorts of threats four types of methods are often implemented like access control, inference control, flow control, and encryption. During a multiuser database system, the DBMS need to provide techniques to enable certain users or user groups to access selected a part of a database without gaining access to the rest of the database. This is often important when a large integrated database is to be used by multiple users within an equivalent organization.
For example, sensitive information like employee salaries or performance reviews need to kept confidential from most of the database system's users. A DBMS contains a database security and authorization subsystem that's responsible for ensuring the security of portions of a database against unauthorized access. There are two kinds of database security mechanisms:
• Discretionary security mechanisms: These are used to grant privileges to users, including the capability to access specific data files, records, or fields in a specified mode like read, insert, delete, or update.
• Mandatory security mechanisms:These are used to perform multilevel security by classifying the data and users into multiple security levels and then implementing the suitable security policy of the organization. For example, a typical security policy is to permit users at a certain classification level to see only the data items classified at the user's own classification level. An extension of this is role-based security, which provides policies and privileges depends on the concept of roles.
A second security problem is that of preventing unauthorized persons from accessing the system itself, either to obtain information or to make malicious changes in a portion of the database. The protection mechanism of a DBMS must include provisions for restricting access to the database system as an entire. This function is named access control and is handled by creating user accounts and passwords to manage the login process by the DBMS. A third security problem is related with databases used controlling the access to a statistical database, which is used to provide statistical information.
For example, a database for population statistics provides statistics depends on age groups, income levels, size of household, education levels, and other criteria. Statistical database users like government statisticians or marketing research firms are allowed to access the database to retrieve statistical information a few population but to not access the detailed confidential information on specific individuals. Security for statistical databases confirm that information on individuals can't be accessed.
Another security issue is flow control used to prevent information from flowing to unauthorized users. Channels are ways for information to flow implicitly to violate the security policy of an organization are called covert channels.
The last security issue is data encryption used to guard sensitive data like credit card numbers that's being transmitted through communication network. Encryption provide additional protection for sensitive portions of a database also. The data is encoded using some coding algorithm. An unauthorized user who accesses encoded data will have difficulty deciphering it, but authorized users are given decoding or decrypting algorithms to decipher the data. Encrypting techniques are difficult to decode without a key which are developed for military applications.
Q2) Explain Discretionary access control based on granting and revoking privileges?
A2)
The method of performing discretionary access control in a database system is based on the granting and revoking of privileges. Consider privileges in the context of relational DBMS. Many current DBMSs use some variation of this technique. The idea is to add statements in the query language that allow the DBA and selected users to grant and revoke privileges.
1. Types of Discretionary Privileges
In SQL2, the concept of an authorization identifier is used to use a user account. For simplicity, we use the words user or account in place of authorization identifier. The DBMS need to provide selective access to each relation in the database based on specific accounts. Operations may also be controlled; thus, having an account does not necessarily entitle the account holder to all the functionality provided by the DBMS. Two types of levels for assigning privileges to use the database system:
• The account level: In this the DBA specifies the particular privileges that every account holds independently of the relations in the database.
• The relation level: In this the DBA control the privilege to access every relation or view in the database.
The privileges at the account level apply to the capabilities provided to the account itself and contains the CREATE SCHEMA or CREATE TABLE privilege, to make a schema or base relation; the CREATE VIEW privilege; the ALTER privilege, to use schema changes like adding or removing attributes from relations; the DROP privilege used to delete relations or views; the MODIFY privilege used to insert, delete, or update tuples; and therefore the SELECT privilege are used to retrieve information from the database by using a SELECT query.
Consider that these account privileges apply to the account generally. If a particular account doesn't have the CREATE TABLE privilege, no relations are often created from that account. Account-level privileges aren't defined as a part of SQL2. In earlier versions of SQL, a CREATETAB privilege existed to offer an account the privilege to make tables.
The second level of privileges applies to the relation level to find they are base relations or view or not. These privileges are defined for sQL2. The term relation may ask a base relation or to view until we explicitly specify one or the other. Privileges at the relation level specify for each user the individual relations on which each kind of command are often applied. Some privileges also ask individual columns of relations.
SQL2 commands provide privileges at the relation and attribute level only. this is often quite general, it makes it difficult to create accounts with limited privileges. The granting and revoking of privileges follow an authorization model for discretionary privileges called because the access matrix model, where the rows of a matrix M represent subjects like users, accounts, programs and therefore the columns represent objects like relations, records, columns, views, operations. Every position M (i,j) in matrix display the kinds of privileges like read, write, update that subject i holds on object j.
To control the granting and revoking of relation privileges every relation R in a database is assigned to owner account, in that the account was used when the relation was created within the first place. The owner of a relation is provides all privileges on relation. In SQL2, the DBA assign an owner to a whole schema by creating the schema and associating the particular authorization identifier with that schema, using the CREATE SCHEMA command. The owner account holder can pass privileges on any of the owned relations to other users by granting privileges to their accounts.
In SQL the show following types of privileges which are granted on every relation R:
• SELECT privilege on R: Provides retrieval privilege. In SQL it provides the privilege to use the SELECT statement to fetch the tuples from R.
• MODIFY privileges on R: This provides the capability to modify tuples of R. In SQL it is divided into UPDATE, DELETE, and INSERT privileges to apply the SQL command to R. The INSERT and UPDATE privileges specify only few attributes of R can be updated by the account.
• REFERENCES privilege on R: It provides the ability to reference relation R when specifying integrity constraints. It restricted to particular attributes of R.
2. Specifying Privileges Using Views
The concept of views is an important discretionary authorization process in its own right. For example, if the owner A of a relation R required another account B to be able to retrieve fields of R, then A can create a view V of R that contains only those attributes and then grant SELECT on V to B. The same applies to limiting B to retrieving only few tuples of R; a view Vi can be created by defining the view of a query that selects only those tuples from R that A wants to allow B to access.
3. Revoking Privileges
In some cases it is required to grant a privilege to a user temporarily. For example, the owner of a relation need to grant the SELECT privilege to a user for a certain task and then revoke that privilege when the task is completed. Therefore the method for revoking privileges is required. In SQL a REVOKE command is included for the purpose of canceling privileges.
4. Propagation of Privileges Using the GRANT OPTION
When the owner A of a relation R grants a privilege on R to a different account B, the privilege given to B with or no GRANT OPTION. If the GRANT OPTION is given, that's B also can grant that privilege on R to other accounts. Consider that B is given the GRANT OPTION by A which B then grants the privilege on R to a third account C with GRANTOPTION. Privileges on R propagate to other accounts without any information of the owner of R. If the owner account A revokes the privilege granted to B then all the privileges which B propagated depends on privilege automatically revoked by the system.
It is possible for a user to receive a particular privilege from many sources. For instance, A4 may receive a particular UPDATE R privilege from both A2 and A3. If A2 revokes this privilege from A4 then A4 still have the privilege to getting granted it from A3. If A3 revokes the privilege from A4 then A4 loses the privilege. DBMS which permits propagation of privileges need to keep track of how all the privileges are granted in order that revoking of privileges are done correctly and completely.
5. An Example
Consider that DBA creates four accounts like A1, A2, A3, and A4 and wants only Al to create as base relation; then the DBA issue the following GRANT command in SQL:
GRANT CREATETAB TO Al;
The CREATETAB create table privilege gives Al the ability to make new database tables and apply the privilege. This privilege was a part of earlier versions of SQL but is now left to every individual system implementation to define. In SQL2 the same effect are accomplished by having the DBA issue a CREATE SCHEMA command, as follows:
CREATE SCHEMA EXAMPLE AUTHORIZATION Al;
Now user Al can create tables in the schema called EXAMPLE. Suppose that Al creates the 2 base relations EMPLOYEE and DEPARTMENT then A1 is then the owner of those two relations and hence has all the relation privileges on each of them. Consider that Al wants to grant the privilege to A2 to insert and delete tuples in both relations. However, Al doesn't want A2 to be ready to propagate these privileges to additional accounts. A1 can issue the subsequent command:
GRANT INSERT, DELETE ON EMPLOYEE, DEPARTMENT TO A2;
EMPLOYEE
NAME | SSN | BDATE | ADDRESS | SEX | SALARY | DNO |
DEPARTMENT
DNUMBER | DNAME | MGRSSN |
Figure4.2(I)
Schemas for the two relations EMPLOYEE and DEPARTMENT.
Consider that the owner account A1 of a relation automatically has the GRANT OPTION, allowing it to grant privileges on the reference to other accounts. However, account A2 cannot grant INSERT and DELETE privileges on the employee and DEPARTMENT tables, because A2 wasn't given the GRANT OPTION within the preceding command. Suppose that Ai wants to permit account A3 to retrieve information from either of the 2 tables and also ready to propagate the SELECT privilege to another accounts. Al can issue the subsequent command:
GRANT SELECT ON EMPLOYEE, DEPARTMENT TO A3 WITH GRANT OPTION;
The clause WITH GRANT OPTION means A3 apply the privilege to another accounts with the help of GRANT. For example A3 grant the SELECT privilege on the EMPLOYEE relation to A4 by with the help of following command:
GRANT SELECT ON EMPLOYEE TO A4;
A4 doesn’t apply the SELECT privilege to another accounts because the GRANT OPTION was not provided to A4. Consider that Ai decides to revoke the SELECT privilege on the EMPLOYEE relation from A3 then A1 issue this command:
REVOKE SELECT ON EMPLOYEE FROM A3;
The DBMS required to automatically revoke the SELECT privilege on EMPLOYEE from A4 because A3 granted that privilege to A4 and A3 doesn't have the any privilege. Consider that Ai wants to provide back to A3 a limited capability to pick from the employee relation and needs to permit A3 to be ready to propagate the privilege. The drawback is to retrieve only the NAME, BDATE, and ADDRESS attributes and just for the tuples with DNO = 5. Ai then can create the subsequent view:
CREATE VIEW A3EMPLOYEE AS SELECT NAME, BDATE, ADDRESS FROM EMPLOYEE WHERE DNO = 5;
After the view is created, Ai can grant SELECT on the view A3EMPLOYEE to A3 such as:
GRANT SELECT ON A3 EMPLOYEE TO A3 WITH GRANT OPTION;
Consider that Ai wants to allow A4 to update only the SALARY attribute of EMPLOYEE then Al issue the following command as
GRANT UPDATE ON EMPLOYEE (SALARY) TO A4;
The UPDATE or INSERT privilege describes particular attributes which can be updated or inserted in a relation. Other privileges like SELECT, DELETE are not attribute specific, because specificity can be controlled by creating the appropriate views which contains only the desired attributes and granting the those privileges on the views. Therefore updating views is not always possible and the UPDATE and INSERT privileges are provides the option to specify particular attributes of a base relation that may be updated.
6. Specifying Limits on Propagation of Privileges
Techniques to limit the propagation of privileges are developed therefore they need not implemented in DBMSs and not a part of SQL. Limiting horizontal propagation to integer number i is that the account B provides the GRANT OPTION and grant privilege to i another accounts. Vertical propagation is more difficult and it provides the limited depth of the granting of privileges.
Granting a privilege with a vertical propagation of zero is same as granting the privilege with no GRANT OPTION. If account A grants a privilege to account B with the vertical propagation set to an integer number j > 0, this says that the account B has the GRANT OPTION thereon privilege, but B can grant the privilege to other accounts only with a vertical propagation but j. The vertical propagation limits the sequence of GRANT OPTIONs from one account to subsequent supported a single original grant of the privilege.
Consider that Al grants SELECT to A2 for worker relation with help of horizontal propagation is to 1 and vertical propagation is to 2. A2 can grant SELECT to at the one account because the horizontal propagation has limit to 1. Additionally A2 cannot grant the privilege to a special account except with vertical propagation set to 0 or 1; because A2 need reduce the vertical propagation by a minimum of 1 when passing the privilege to others. It shows, horizontal and vertical propagation techniques are designed to limit the propagation of privileges.
Q3) Write note on Role-Based Access Control?
A3)
Role-Based Access Control
Role-based access control (RBAC) emerged rapidly within the 1990s as a proven technology for managing and enforcing security in large-scale enterprise wide systems. Its basic notion is that permissions are related to roles and also users are assigned to their appropriate roles.
Roles are often created using the CREATE ROLE and DESTROY ROLE commands. The
GRANT and REVOKE commands discussed under DAC can then be wont to assign and revoke privileges from roles.
RBAC appears to be a viable alternative to traditional discretionary and mandatory access controls; it ensures that only authorized users are given access to certain data or resources. Users create sessions during which they'll activate a subset of roles to which they belong. Every session are often assigned too many roles, but it maps to just one user or one subject. Many DBMSs have allowed the concept of roles, where privileges are often assigned to roles.
Role hierarchy in RBAC is a natural way of organizing roles to reflect the organization's lines of authority and responsibility. The junior roles at the bottom are connected to senior roles and the move together up the hierarchy. The hierarchic diagrams are partial orders, in order that they are reflexive, transitive, and antisymmetric.
Another important consideration in RBAC systems is that the possible temporal constraints which will exist on roles, like the time and duration of role activations, and timed triggering of a role by an activation of another role. Using an RBAC model may be a highly desirable goal for addressing the key security requirements of Web-based applications. Roles are often assigned to workflow tasks in order that a user with any of the roles associated with a task could be authorized to execute it and play a particular role for a particular duration only.
RBAC models have many desirable features like flexibility, policy neutrality, better support for security management and administration, and other aspects that make them attractive candidates for developing secure Web-based applications. In contrast, DAC and mandatory access control (MAC) models lack capabilities needed to support the security requirements of emerging enterprises and Web-based applications.
In addition, RBAC models shows traditional DAC and MAC policies and user defined or organization-specific policies. Thus, RBAC becomes a superset model which will successively mimic the behavior of DAC and MAC systems. Therefore, an RBAC model provides a natural mechanism for addressing the security issues associated with the execution of tasks and workflows. Easier deployment over the web is one more reason for the success of RBAC models.
Q4) Write note on Database Audit Trail (DBA_AUDIT_TRAIL)?
A4)
The database audit trail consists of one table named SYS.AUD$ within the SYS schema of the data dictionary of every Oracle database. Several predefined views are provided to assist you use the knowledge during this table, like DBA_AUDIT_TRAIL.
Audit trail records can contain differing types of data, depending on the events audited and therefore the auditing options set. The partial list in following table shows columns that always appear within the audit trail. If the information they represent is out there, then that data populates the corresponding column.
Column Description (Name) | Also Appears in the Operating System Audit Trail? |
Operating system login user name (CLIENT USER) | Yes. |
Database user name (DATABASE USER) | Yes. |
Session identifier | Yes. |
Terminal identifier | Yes. |
Name of the schema object accessed | Yes. |
Operation performed or attempted (ACTION) | Yes. |
Completion code of the operation | Yes. |
Date and time stamp in UTC (Coordinated Universal Time) format | Date and time yes, but not in UTC format. |
System privileges used (PRIVILEGE) | Yes. |
Proxy Session audit ID | No. |
Global User unique ID | No. |
Distinguished name | Yes. |
Instance number | No. |
Process number | No. |
Transaction ID | No. |
SCN (system change number) for the SQL statement | No. |
SQL text that triggered the auditing (SQLTEXT) | No. |
Bind values used for the SQL statement, if any (SQLBIND) | No. |
If the database destination for audit records full or is unavailable, and is unable to accept new records, then an audited action cannot complete. Instead, it causes an error message and isn't done. In some cases, an OS log allows such an action to finish.
Q5) Explain Statistical Database Security in detail?
A5)
Introduction to Statistical Database Security
Statistical databases are used mainly to supply statistics on various populations. The database consist of confidential data on individuals, which was protected against user access. Therefore users are allow to retrieve statistical information on the populations as averages, sums, counts, maximums, minimums, and standard deviations.
A population is a set of tuples of a relation that fulfill some selection condition. Therefore every selection condition on the PERSON relation specify a specific population of PERSON tuples. For instance, the condition SEX = 'M' describes the male population; the condition ((SEX = 'F') AND (LAST_DEGREE = 'M. S.' OR LAST_DEGREE = 'PH. D. ')) describes the female population that has an M.S. or PH.D. Degree as their highest degree and then the condition CITY = 'Houston' specifies the population that lives in Houston.
Statistical queries involve applying statistical functions to a population of tuples. For instance, we might want to retrieve the number of people during a population or the typical income within the population. However, statistical users aren't allowed to retrieve individual data, like the income of a selected person. Statistical database security techniques must prohibit the retrieval of individual data. It is achieved by prohibiting queries which retrieve attribute values and by supporting only queries that present in statistical aggregate functions like COUNT, SUM, MIN, MAX, AVERAGE, and standard deviation. Such queries are sometimes called statistical queries.
It is the responsibility of a database management system to make sure the confidentiality of data about individuals, while still providing useful statistical summaries of data about those individuals to users. Provision of privacy protection of users during a statistical database is paramount; its violation is illustrated within the following example.
In some cases it's possible to refer the values of every tuples from a sequence of statistical queries. This is true when the conditions result in a population consist of a small number of tuples. As shown in figure consider the subsequent two statistical queries:
Q1: SELECT COUNT (*) FROM PERSON WHERE <CONDITION>;
Q2: SELECT AVG (INCOME) FROM PERSON WHERE <CONDITION>;
PERSON
NAME | SSN | INCOME | ADDRESS | CITY | STATE | ZIP | SEX | LAST_DEGREE |
Figure 4.5(I) The PERSON relation schema for representing statistical database security.
Suppose that we have an interest find the SALARY of 'Jane Smith’, and that we know that she contains a PH.D. Degree which she lives within the city of Bellaire, Texas. We issue the statistical query Q1 with the subsequent condition: (LAST~DEGREE='PH.D.' AND SEX='F' AND CITY='Bellaire' AND STATE='Texas').
If we get a results of 1 for this query then we issue Q2 with an equivalent condition and find the income of jane Smith. therefore the results of Q1 on the preceding condition isn't 1 but may be a small number-say, 2 or 3 we can issue statistical queries using the functions MAX, MIN, and AVERAGE to find out the possible range of values for the INCOME of Jane Smith.
The possibility of inferring every person’s information from statistical queries is reduced if no statistical queries are permitted when the number of tuples within the population represented by the selection condition falls below some threshold. Another technique for prohibiting retrieval of individual information is to ban sequences of queries that refer repeatedly to an equivalent population of tuples.
It is also possible to introduce slight inaccuracies or "noise" into the results of statistical queries deliberately, to form it difficult to reduce individual information from the results. Another technique is partitioning of the database. Partitioning implies that records are stored in groups of some minimum size; queries can ask any complete group or set of groups, but never to subsets of records within a group.
Q6) Explain bell-lapadula model for multilevel security?
A6)
The model which is used for multilevel security consider as the Bell-LaPadula model, divides each subject as user, account, and program and object relation, tuple, column, view, operation into one among the security classifications TS, S, C, or U. we'll ask divide subject S as class S and to the classification of an object O as class (D). Two restrictions are enforced on data access supported the subject/object classifications:
1. A subject S not allowed read access to an object O unless class(S) ≥ class(O).
This is referred to as the easy security property.
2. A subject S isn't allowed to write down an object O unless class(S) ≥ class(O). This is often called because the star property (or *property).
The first restriction is intuitive and enforces the present rule that no subject can read an object whose security classification is above the subject's security clearance. The second restriction is a smaller amount intuitive. It restricts a subject from writing an object at a lower security types than the subject's security clearance. Violation of this rule allow information to flow from higher to lower, which violates a basic form of multilevel security. For instance, a user with TS clearance may create a copy of an object with classification TS and write it back as a new object with classification U therefore it is visible in the system.
To map multilevel security notions into the relational database model, it's common to consider about attribute values and tuples as data objects. Therefore every attribute A is related to a classification attribute C within the schema, and every attribute value during a tuple is related with a corresponding security classification. Additionally, in some models, a tuple classification attribute TC is added to the relation attributes to supply a classification for every tuple as an entire. Therefore a multilevel relation schema R with n attributes shows as follows
R(A1,C1,A2,C2……An, Cn)
Where each C, represents the classification attribute related to attribute Aj .
The value of the TC attribute in every tuple t is the highest of all attribute classification values within t provides a general classification for the tuple itself, where every C, provides a finer security classification for every attribute value within the tuple. The present key of a multilevel relation is that the set of attributes that might have formed the primary key during a regular relation. A multilevel relation contain different data to subjects (users) with different clearance levels. In few cases, it's possible to store one tuple within the relation at a better classification level and generates the appropriate tuples at a lower-level classification through a process called as filtering. it's need to store two or more tuples at different classification levels with an equivalent value for the apparent key.
This results in the concept of poly-instantiation where multiple tuples can have an equivalent apparent key value but have different attribute values for users at different classification levels. Consider that the Name attribute is that the apparent key, and consider the query SELECT * FROM employee. A user with security clearance S would see an equivalent relation shown in Figure (a), since all tuple classifications are less than or equal to S.
However, a user with security clearance C wouldn't be allowed to examine values for Salary of Brown and JobPerformance of Smith, since they need higher classification. The tuples are filtered as shown in Figure (b), with Salary and JobPerformance as null. For a user with security clearance U, the filtering allows only the Name attribute of Smith to appear, with all the other attributes present as null (Figure c).
Therefore filtering represents null values for attribute values whose security classification is above the user's security clearance.
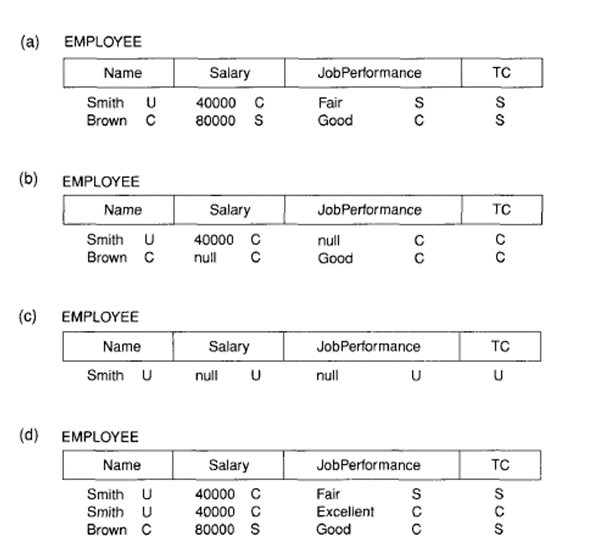
Figure 4.3(I) A multilevel relation to illustrate multilevel security. (a) The original EMPLOYEE tuples. (b) EMPLOYEE as after filtering for classification C users. (c) EMPLOYEE as after filtering for classification U users. (d) Polyinstantiation of the Smith tuple.
The entity integrity rule for multilevel relations states that each one attributes that are members of the apparent key not be null and have an equivalent security classification within each individual tuple. Additionally, all other attribute values which is in the tuple need a security classification larger than or equal to the apparent key.
This constraint make sure that a user see the key if the user is permitted to examine any a part of the tuple in the least. Other integrity rules known as null integrity and inter-instance integrity, make sure that if a tuple value at some security level are filtered from a higher-classified tuple, then it's sufficient to store the higher-classified tuple in the multilevel relation.
To describe polyinstantiation further, consider that a user with security clearance C tries to update the value of JobPerformance of Smith in Figure to 'Exce11ent ‘; this relates to the subsequent SQL update being issued:
UPDATE EMPLOYEE SET JobPerformance = 'Excellent'WHERE Name = 'Smith';
From where the view provided to users with security clearance C (see Figure (b)) allows update then the system do not reject it; otherwise, the user could infer that some non-null value present for the JobPerformance attribute of Smith instead of null value that present.
This is an example of inferring information through what's called as a covert channel, which shouldn't be permitted in highly secure systems. Therefore the user shouldn't be allowed to overwrite the present value of obPerformance at the upper classification level. The answer is to make a polvinstantiation for the Smith tuple at the lower classification level C, as shown in Figure (d).
This is necessary since the new tuple can't be filtered from the present tuple at classification S. the basic update operations of the relational model as insert, delete, and update need to modify to handle this and similar situations, but this aspect of the matter is outside the scope of our presentation.
Q7) What is the role of DBA with respect to security?
A7)
The database administrator (DBA) is the central authority for managing a database system. The DBA's responsible for granting privileges to users who use the system and classifying users and data in related with the rules of the organization. The DBA features a DBAaccount within the DBMS, sometimes called a system or superuser account, which provides powerful capabilities that aren't made available to regular database accounts and users.
DBA-privileged commands contains commands for granting and revoking privileges to individual accounts, users, or user groups and for performing the subsequent types of actions:
1. Account creation: It creates a new account and password for a user or a group of users to provide access to the DBMS.
2. Privilege granting: It allows the DBA to grant certain privileges to certain accounts.
3. Privilege revocation: It allows the DBA to revoke certain privileges that were previously given to accounts.
4. Security level assignment: It consists of assigning user accounts to the appropriate security classification level.
Access Protection, User Accounts, and Database Audits
When an individual or a group of persons must access a database system, the individual or group must first apply for a user account. The DBA will then create a new account number and password for the user if there's a requirement to access the database. The user need to log within the DBMS by entering the account number and password whenever database access is required. The DBMS checks that the account number and password are valid then the user is permitted to use the DBMS and to access the database.
Application programs considered as users and wish to provide passwords. It’s straightforward to keep track of database users and their accounts and passwords by creating an encrypted table or file with the 2 fields AccountNumber and Password. This table maintained by the DBMS. Whenever a new account is made, a new record is inserted into the table. When account is canceled, the related record are deleted from the table.
The database system maintain the track of all operations on the database which are applied by a particular user in the login session, which contains the sequence of database interactions that a user performs from the time of logging in to the time of logging off. When a user logs in then the DBMS save the user's account number and related with the terminal from where the user logged in. All operations applied from that terminal are attributed to the user's account until the user logs off.
It is important to keep track of update operations that are applied to the database in order that, if the database is tampered with, the DBA can determine which user did the tampering. To keep a record of all updates applied to the database and of the actual user who applied each update, we will modify the system log.




