|
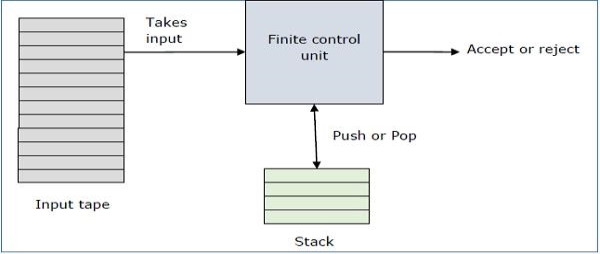
|
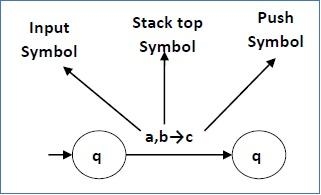
|
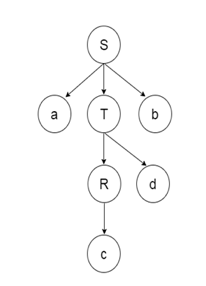
|
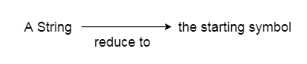
{x ∈ {a,b,c}* : x = wcwR for w ∈ {a,b}*} |
|
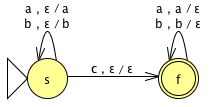
{x ∈ {a,b}* : x = wwR for w ∈ {a,b}*} |
| |||
This PDA is identical to the previous |
| |||

Top down parsing | Bottom up parsing |
It is a parsing technique that first looks at the highest level of the parse tree and, using the grammar rules, works down the parse tree. | It is a parsing technique that first looks at the lowest level of the parse tree and, using the grammar rules, works up the parse tree. |
Top-down parsing tries to locate most of the input string derivations to the left. | It is possible to describe bottom-up parsing as an attempt to decrease the input string to initiate a grammar symbol. |
In this parsing technique, we begin top-down parsing from top (parse tree start symbol) to down (parse tree leaf node). | In this parsing technique, we begin to parse from the bottom (parse tree leaf node) to the top (parse tree start symbol) in the bottom-up manner. |
Left Most Derivation is used for this research methodology. | This technique of parsing uses the most accurate derivation. |
In order to build the string, the key decision is to choose which production rule to use. | Choosing when to use a development rule to decrease the string to get the starting symbol is the key decision. |
|

|





