Unit - 3
BOOTP, DHCP and Domain name system
Q1) Explain Domain Name Space ?
A1)
Domain Name Space
Host names are split into multiple domains called bits. In a hierarchical system, domains are designed. The top-level domains refer to the type of entity to which the network belongs, and the particular network on which the host is situated is further identified by subdomains.
A domain name space was planned in order to provide a hierarchical name space. In this design, the names are described with the root at the top in an inverted-tree structure. There can only be 128 levels in the tree: from level 0 (root) to level 127.
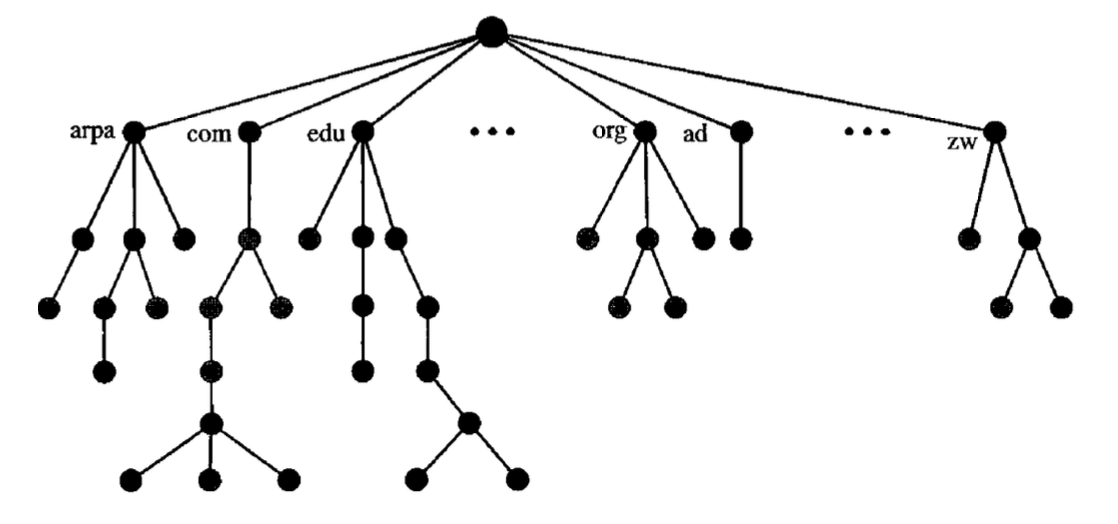
Fig : domain name space
Label : There is a mark for each node in the tree, which is a string of 63 characters at most. A null string is the root mark (empty string). DNS allows node children (nodes branching from the same node) to have different labels, which ensures that domain names are unique.
Domain name : There's a domain name for each node in the tree. A total domain name is a series of dot-separated labels (.). The domain names are read from the node to the root at all times. The last mark is the root label (null). This means that a null mark always ends with a complete domain name, which means that the last character is a circle, so there is nothing in the null string.
Fully qualified domain name : When a mark is terminated by a null string, a completely eligible domain name is named (FQDN). An FQDN is a domain name which contains a host's full name. It includes all the labels which uniquely identify the name of the host, from the most specific to the most general.
Partially qualified domain name : When a mark is not terminated by a null string, a partially eligible domain name is named (PQDN). A PQDN begins with a node, but does not enter the root. When the name to be resolved belongs to the same site as the customer, it is used. Here, the resolver will supply the missing component to construct a FQDN, called the suffix.
Domain : A domain is a domain name space subtree. The domain name is the node's domain name at the top of the subtree. Note that a domain can be separated into domains by itself.
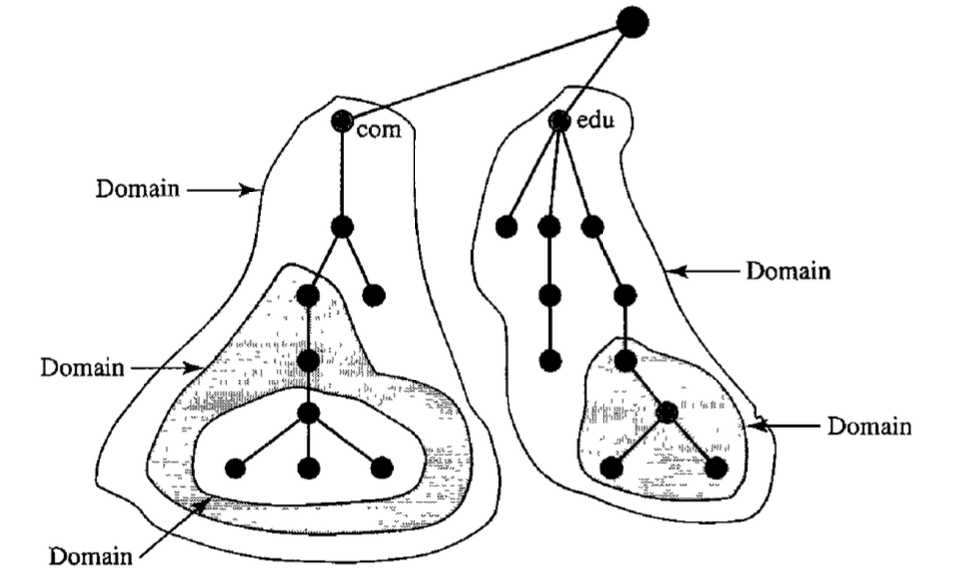
Fig : Domains
A machine that maintains a database of host names and IP addresses for one or more zones is a DNS master name server. If the primary server fails, it is advisable to have DNS slave name servers that can be synchronised with the master name server to act as backup name servers.
The DNS moves from the left node to the right node to deduce the IP address while executing the inverse resolution function, mapping an IP address to its host name. Unlike the host name, when heading to the right, the dot (.) notation of an IP address becomes more precise. Therefore, to accommodate this situation, the IP addresses in the DNS are represented in reverse order.
Q2) Write about the name space ?
A2)
Name Space
It is important to carefully select the names allocated to machines from a namespace with complete control over the binding between names and IP addresses. The names must, in other words, be unique because the addresses are unique. It is possible to arrange a namespace that maps each address to a specific name in two ways: fiat or hierarchical.
Flat name space
In a flat namespace, the address is assigned a name. A name in this space is a character sequence without a structure. There may be no common section for the names mayor; if they do, it does not have any significance. The biggest drawback of a fiat name space is that it can not be used because it must be centrally regulated to prevent misunderstanding and repetition in a large structure such as the Internet.
Hierarchical name space
Each name is made of several parts in a hierarchical name space. The first part may define the essence of the organisation, the second part may define the organization's name, the third part may define the organization's divisions, and so on. In this case, it is possible to decentralise the authority to grant and manage namespaces. The part of the name that determines the organization's existence and the organization's name may be assigned by a central authority.
It is possible to assign the organisation itself the responsibility for the remainder of the term. To identify its host or resource, the organisation may add suffixes (or prefixes) to the name. The organization's management need not fear if another organisation will take the prefix chosen for a host because, even though part of an address is the same, the entire address is different.
Q3) What do you mean by BOOTP?
A3)
BOOTP
The Bootstrap Protocol (BOOTP) is a client/server protocol designed for logical address mapping to include physical addresses. BOOTP is a protocol for an application layer. The client and the server either be placed on the same network or on different networks by the administrator. In a UDP packet, BOOTP messages are encapsulated, and the UDP packet itself is encapsulated in an IP packet.
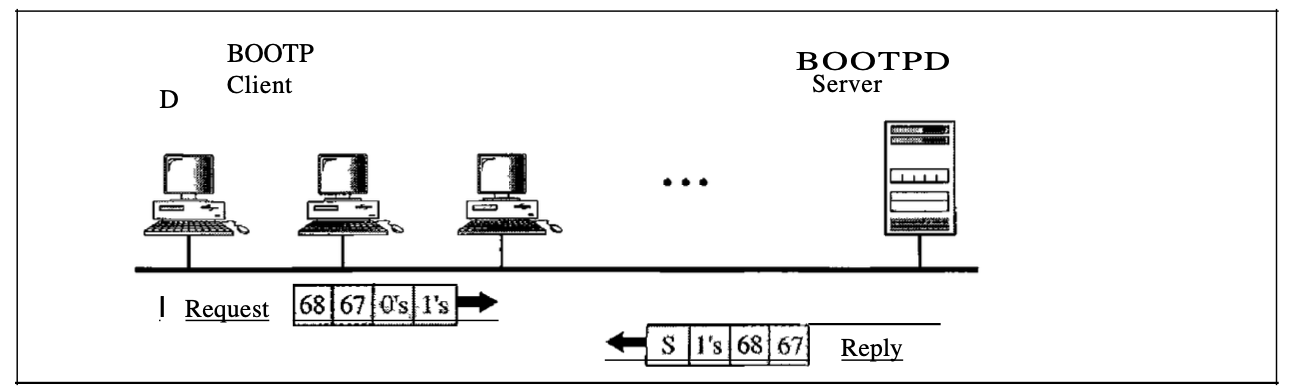
Fig : BOOTP client server on the same network
The reader can question how an IP datagram can be sent by a client when it knows neither its own IP address (the source address) nor the IP address of the server (the destination address). The client simply uses everything as the source address and a11Is as the address of the destination.
A client can be on one network and the server on another, separated by many other networks, as with other application-layer processes. There is one problem, however, which must be solved. The BOOTP request is broadcast because the IP address of the server is not identified by the client. No router can move via a broadcast IP datagram. There is a need for an intermediary to solve the problem. It is possible to use one of the hosts (or a router that can be configured to run on the application layer) as a relay. The host is considered a relay agent in this situation. The unicast address of a BOOTP server is identified by the relay agent.
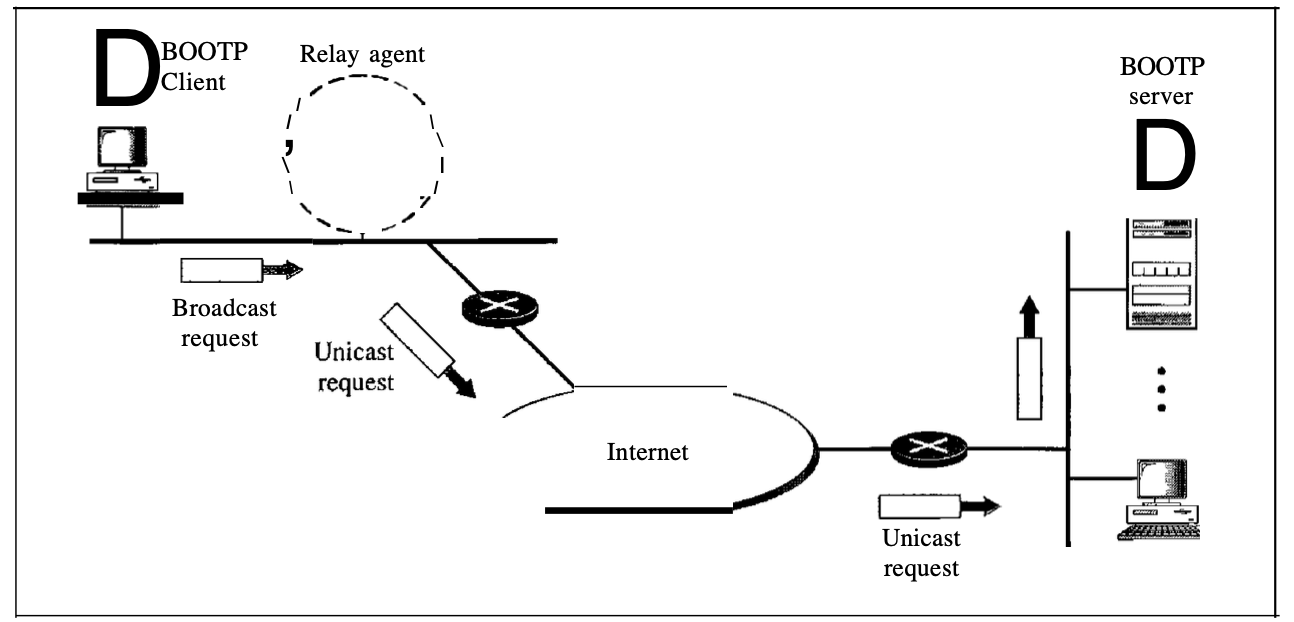
Fig : client server on the different network
BOOTP is not a protocol for complex configurations. When a client requests its IP address, a table comparing the client's physical address with its IP address is consulted by the BOOTP server. This means that there is already a connection between the physical address and the client's IP address.
Q4) Write down the DNS in the internet?
A4)
DNS in internet
A protocol that can be used on various platforms is DNS. The domain name space (tree) is split into three separate parts on the Internet: generic domains, country domains, and the inverse domain.
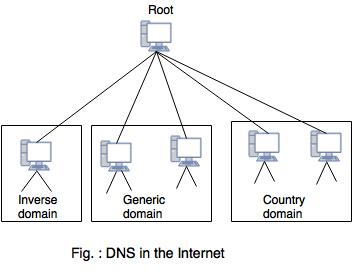
Fig : DNS in internet
Generic Domains
Based on their generic behaviour, the generic domains identify registered hosts. A domain, which is an index to the domain name space database, is specified by each node in the tree.
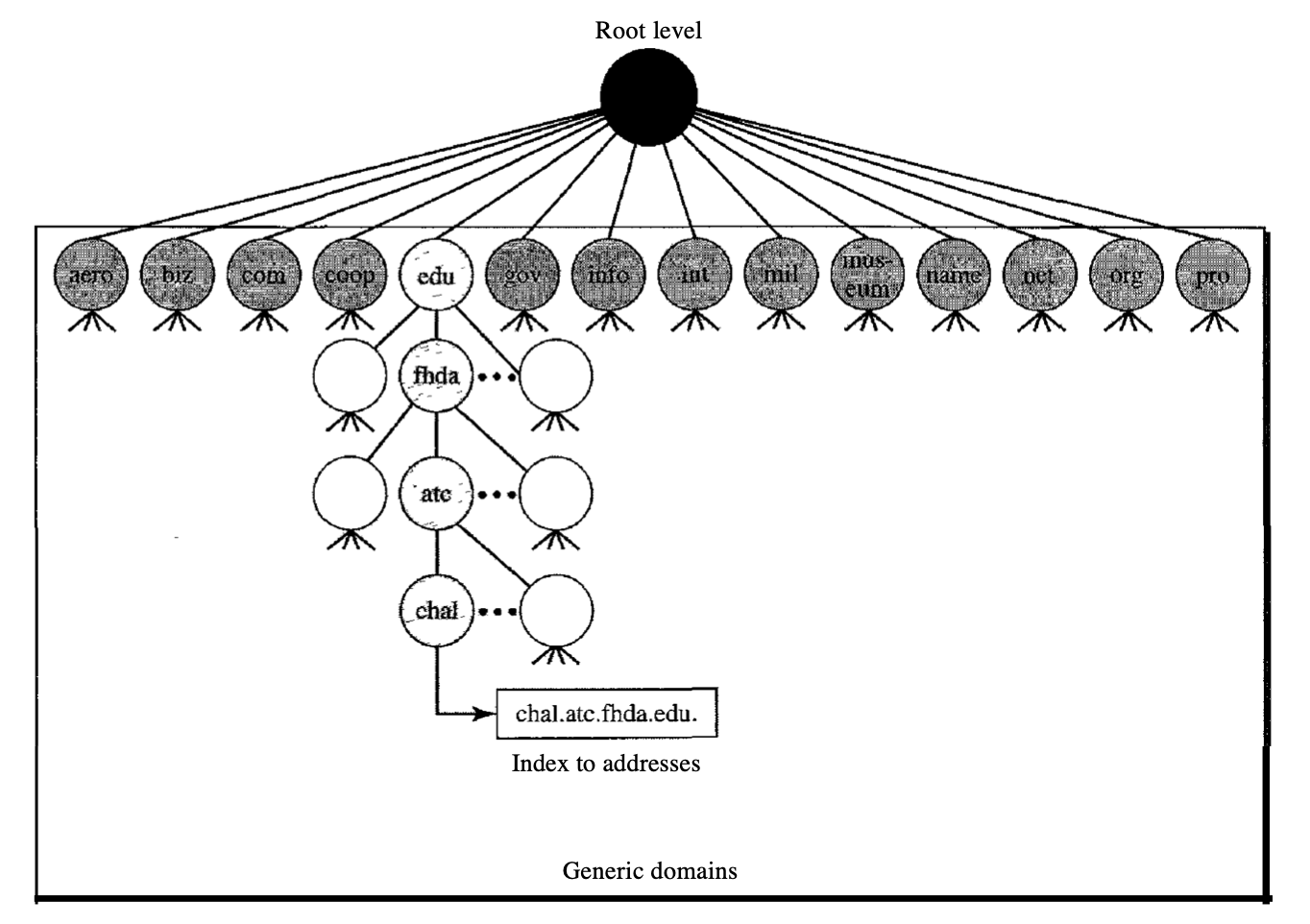
Fig : Generic domain
Looking at the tree, we see that 14 possible labels are allowed by the first level in the generic domains segment.
Label | Description |
aero | Airlines and aerospace companies |
biz | Business or firms |
com | Commercial organizations |
coop | Cooperative business organization |
edu | Educational institutions |
gov | Government institutions |
info | Information service provider |
int | International organizations |
mil | Military groups |
museum | Museum and other nonprofit organization |
name | Personal name |
net | Network support centers |
org | Nonprofit organizations |
pro | Professional individual organizations |
Country Domains
The segment on country domains utilises two-character country abbreviations (e.g., us for United States). The second labels may be organisational, or national designations may be more precise.
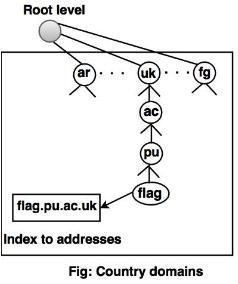
Fig : country domain
For instance, the country domain is "au" for Australia, India is .in, and the UK is .uk
Inverse domains
For mapping an address to a name, the inverse domain is used. This can happen when a server has received a request from a client to do a task for testing. Although the server has a file containing a list of approved clients, only the client's IP address (extracted from the IP packet received) is identified. The server prompts its resolver to send a question to the DNS server to map a name to an address to decide if the client is on the approved list.
A reverse or pointer (PTR) query is called this type of query. The inverse domain is added to the domain name space with a first-level node named arpa to handle a pointer query (for historical reasons). One single node called in-addr is also the second stage (for inverse address). IP addresses are specified in the rest of the domain.
Also, the servers managing the inverse domain are hierarchical.
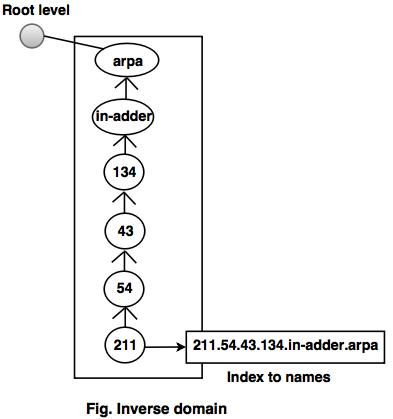
Fig : inverse domain
For example, when a client sends a request to a server to perform a specific task, the server finds an approved client list. The list includes only the client's IP addresses.
Q5) Describe resolution?
A5)
Resolution
Mapping a name to an address or an address to a name is called resolution of the name-address.
Resolver
The DNS is configured as a server/client programme. A DNS client named a resolver is called by a host which needs to map an address to a name or a name to an address. The Resolver accesses the nearest DNS server with a request for mapping.
It satisfies the resolver if the server has the information; otherwise, it either refers the resolver to other servers or asks other servers to supply the information. It interprets the answer after the resolver receives the mapping to see whether it is a real resolution or an error, and finally delivers the result to the process that requested it.
Mapping Name to Addresses
The resolver gives the server a domain name most of the time and asks for the corresponding address. In this scenario, to find the mapping, the server checks the generic domains or the country domains.
"If the domain name is from the generic domains segment, a domain name such as "chal.atc.jhda.edu." is received by the resolver. The question is submitted for resolution to the local DNS server by the resolver. If the question can not be answered by the local server, it either refers the resolver to other servers or directly asks other servers.
Mapping Addresses to Name
A client may send an IP address to a server for the domain name to be mapped. This is called a PTR query, as stated before. DNS uses the inverse domain to address queries of this type. However, the IP address is reversed in the request and the two in-addr and arpa labels are appended to create a domain that is appropriate in the inverse domain section. For instance, if the IF address 132.34.45.121 is received by the resolver, the resolver first inverts the address and then adds the two labels before sending them.
Recursive Resolution
The client (resolver) may ask a name server for a recursive response. This implies that the resolver expects the final response to be supplied by the server. If the server is the domain name authority, it checks the database and reacts.
If the server is not an authority, it sends the request (usually the parent) to another server and waits for an answer. It responds if the parent is the authority; otherwise, it sends the question to yet another server. The answer travels back when the question is eventually answered, until it finally reaches the requesting client. This is called resolving recursively.
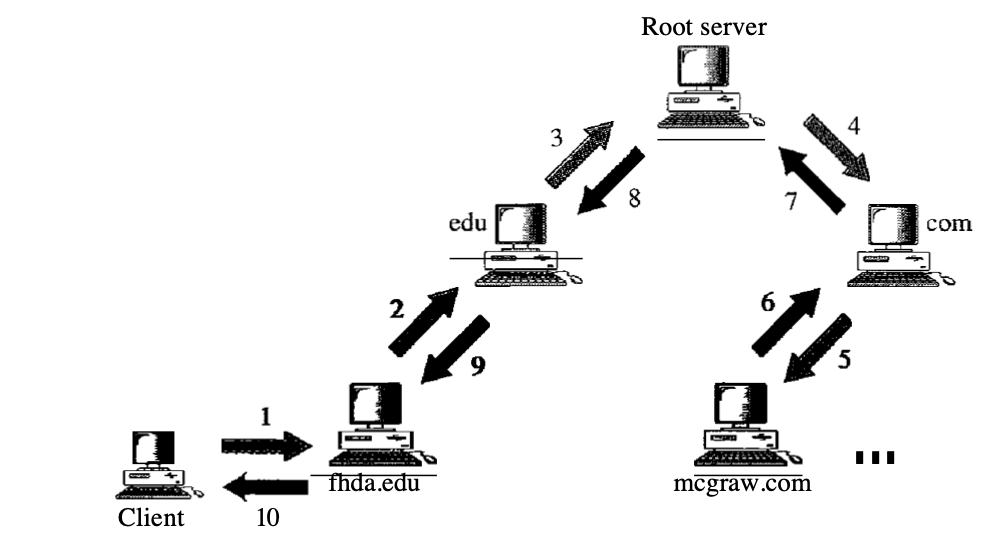
Fig : recursive resolution
Iterative Resolution
If the client does not request a recursive answer, the mapping can be performed iteratively. If the name authority is the server, the answer is sent. If it is not, the IP address of the server that it assumes can answer the query is returned (to the client). The client is responsible for repeating the query to this second server.
If the newly addressed server is able to resolve the problem, it responds with an IP address to the query; otherwise, it returns the new server's IP address to the client. Now the question must be replicated by the client to the third server. As the client repeats the same query to several servers, this process is called iterative resolution.
Caching
The IP address of the server must be checked in its database if a server receives a query for a name that is not in its domain. Reducing this search time will improve productivity. Through a method called caching, DNS manages this.
When a server requests a map from another server and receives an answer, this information is stored in its cache memory until it is sent to the client. If the same or other client requests the same mapping, its cache memory can be verified and the issue solved.
Caching accelerates resolution, but it can be troublesome as well. If a mapping is cached for a long time by a server, it will give the client an obsolete mapping. Two approaches are used to address this. Next, the authoritative server often adds data named time-to-live to the mapping (TTL)
Q6) What do you mean by the distribution of name space ?
A6)
Distribution of Name Space
It is important to store the information stored in the domain name space. It is quite inefficient, however, and therefore unstable to have such an immense amount of knowledge in only one computer store. It is inefficient because it puts a heavy burden on the device to respond to requests from all over the world. It is not inaccurate because the data is made unavailable by any malfunction.
Hierarchical of Name Servers
Distributing information between several computers called DNS servers is the solution to these problems. Centered on the first level, one way to do this is to split the entire space into several domains. In other words, as there are first level nodes, we let the root stand alone and build as many domains (subtrees).
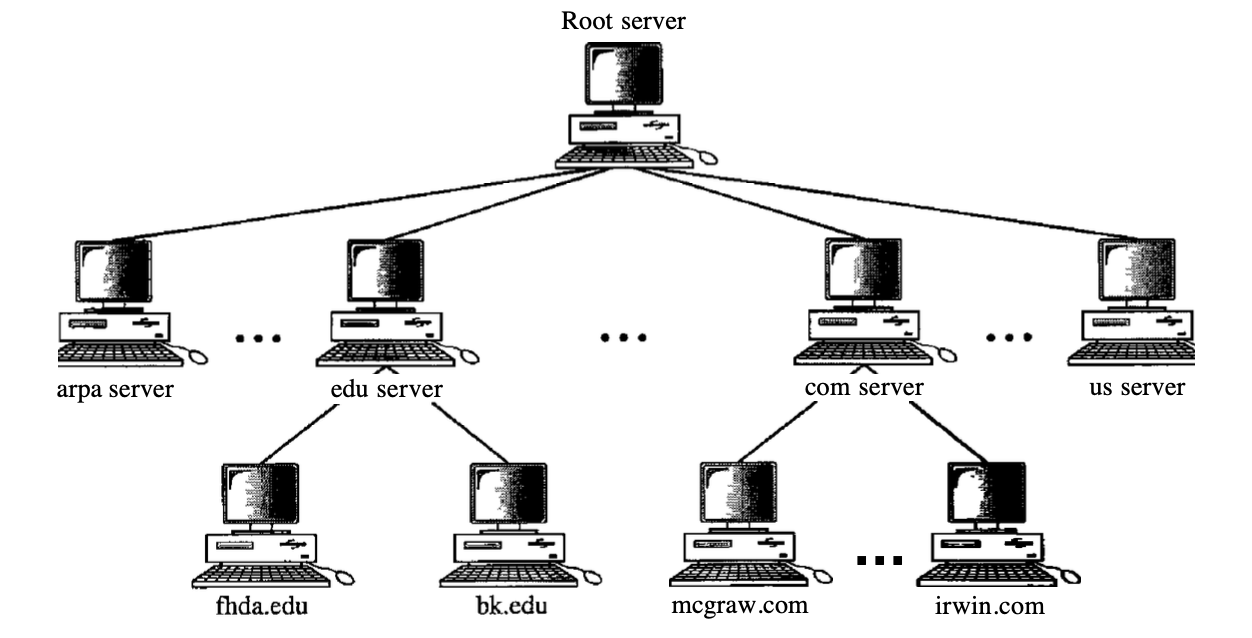
Fig : hierarchical of name server
Zone
A zone is called what a server is liable for or has jurisdiction over it. The "domain" and the "zone" refers to the same thing if a server takes responsibility for a domain and does not divide the domain into smaller domains (subdomains). The server maintains a database called a zone file and holds all the information under that domain for each node. However, if a server splits its domain into subdomains and transfers part of its authority to other servers, "domain" and "domain".
A server can split its domain and delegate responsibility as well, but still maintain part of the domain for itself. In this case, extensive details on the portion of the domain that is not delegated and references to those sections that are delegated constitute its region.
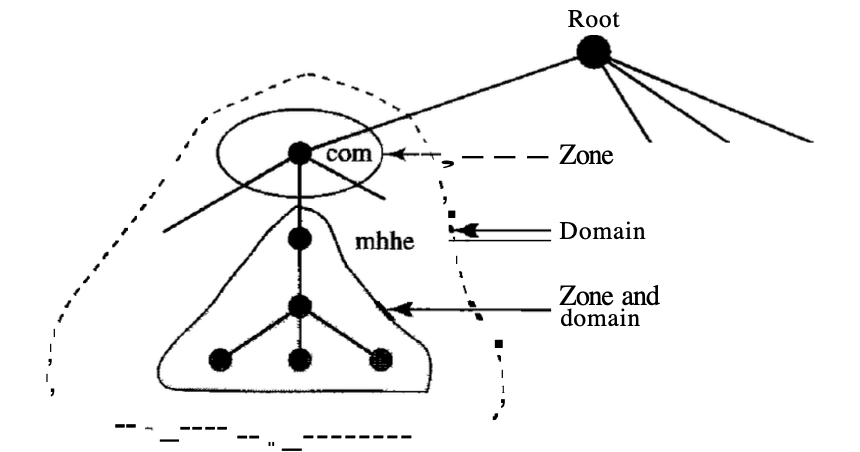
Fig : Zone and domain
Root Server
A root server is a server whose zone is made up of an entire tree. Usually, a root server does not store any domain information but delegates its authority to other servers, retaining references to those servers. Several root servers exist, each covering the entire domain name space. The servers are spread across the globe.
Primary and Secondary Servers
Two types of servers are identified by DNS: primary and secondary. A primary server is a server that stores a file for an authority about the zone for which it is. It is the responsibility of the zone file formation, maintenance, and updating. This stores a file of the zone on a local disc.
A secondary server is a server that transfers from another server (primary or secondary) the complete zone information and stores the file on its local disc. Neither the zone files are generated nor modified by the secondary server. If updating is needed, the primary server that sends the updated version to the secondary version must do so.
For the zones they cover, the main and secondary servers are both authoritative. The aim is not to place the secondary server at a lower authority level, but to create redundancy for the data so that the other can continue serving clients if one server fails. It should also be remembered that a server may be a primary server for a particular zone and a secondary server for a different zone.
Q7) Write short notes on DHCP?
A7)
DHCP
The Dynamic Host Configuration Protocol (DHCP) was developed to provide manual or automatic static and dynamic address allocation.
Static Address Allocation DHCP acts as BOOTP does in this capacity. It is backward-compatible with BOOTP, meaning that a host that runs a BOOTP client will request a static address from a DHCP server. A DHCP server has a database which binds physical addresses to IP addresses statically.
Allocation of Dynamic Addresses DHCP has a second database with a pool of IP addresses available. DHCP is made complex by this second database. The DHCP server goes to the pool of usable (unused) IP addresses when a DHCP client requests a temporary IP address, and assigns an IP address for a negotiable period of time.
The server tests its static database first when a DHCP client sends a request to a DHCP server. The permanent IP address of the client is returned if an entry with the requested physical address occurs in the static database. If the entry does not exist in the static database, on the other hand, the server selects an IP address from the pool available, assigns the address to the client, and adds the entry to the dynamic database.
When a host moves from network to network, or is connected and disconnected from a network, the dynamic feature of DHCP is necessary (as is a subscriber to a service provider). For a limited period, DHCP offers temporary IP addresses.
Temporary addresses are the addresses allocated by the pool. For a particular period, the DHCP server issues a contract. The client must either avoid using the IP address when the lease expires or renew the lease. The server has the choice to consent to the renewal or disagree with it. The client avoids using the address if the server disagrees.
Q8) Write short on encapsulatio?
A8)
Encapsulation
Either UDP or TCP can be used by DNS. The well-known port used by the server in both instances is port 53. UDP is used when the response message size is less than 512 bytes, so there is a 512-byte packet size limit for most UDP packets. If the response message size reaches 512 bytes, a TCP link will be used.
Either of two scenarios can occur in that case:
● If the resolver has prior knowledge that the response message size exceeds 512 bytes, the TCP link is used. For instance, if a secondary name server (acting as a client) requires a zone transfer from a primary server, the TCP link is used because the size of the transferred information normally exceeds 512 bytes.
● If the resolver is unaware of the size of the response packet, the UDP port may be used. If the response message size is more than 512 bytes, however, the server truncates the message and turns the TC bit on. The resolver now opens a TCP link and repeats the request from the server to get a complete answer.
Q9) Write the types of records?
A9)
Types of Records
In the question portion of the query and answer messages, the question records are used. In the answer, authoritative, and additional information parts of the response letter, the resource records are used.
Question Record
In order to get information from a server, a query record is used by the client. It requires a domain name.
Resource Record
Each domain name is associated with a database called the resource record (each node on the tree). The database of the server consists of records of resources. Resource records are what the server returns to the client, too.
A DNS resource record has six field :
<NAME>, <TYPE>, <CLASS>, <TTL>, <RD LENGTH>, and <RDATA>
These fields are :
Name - The DNS name, also known as the owner name, to which the RR belongs, is defined in this area.
Type - This field is a 2-byte value that specifies the resource type that the resource record identifies. This field is important because there can be more than one kind of RR for a DNS term.
Class - For the RR record, this defines the protocol family. IN, which stands for Internet, for instance.
TTL (time to live)- This field is the time, in seconds, for which an RR can be cached by the name server. A zero TTL means the RRR should not be cached by a computer.
Rd length - This field is the length of the RDATA field in bytes.
Rdata - This is a resource data field and is the attribute that is mapped to by the entity defined in the NAME field. For each form of RRR it is special.
Q10) What do you mean by DNS message ?
A10)
DNS Messages
Two types of messages are available for DNS: query and response. There's the same format for both styles. The query message consists of a header and a question record; a header, question records, reply records, authoritative records, and additional records are the reply message.
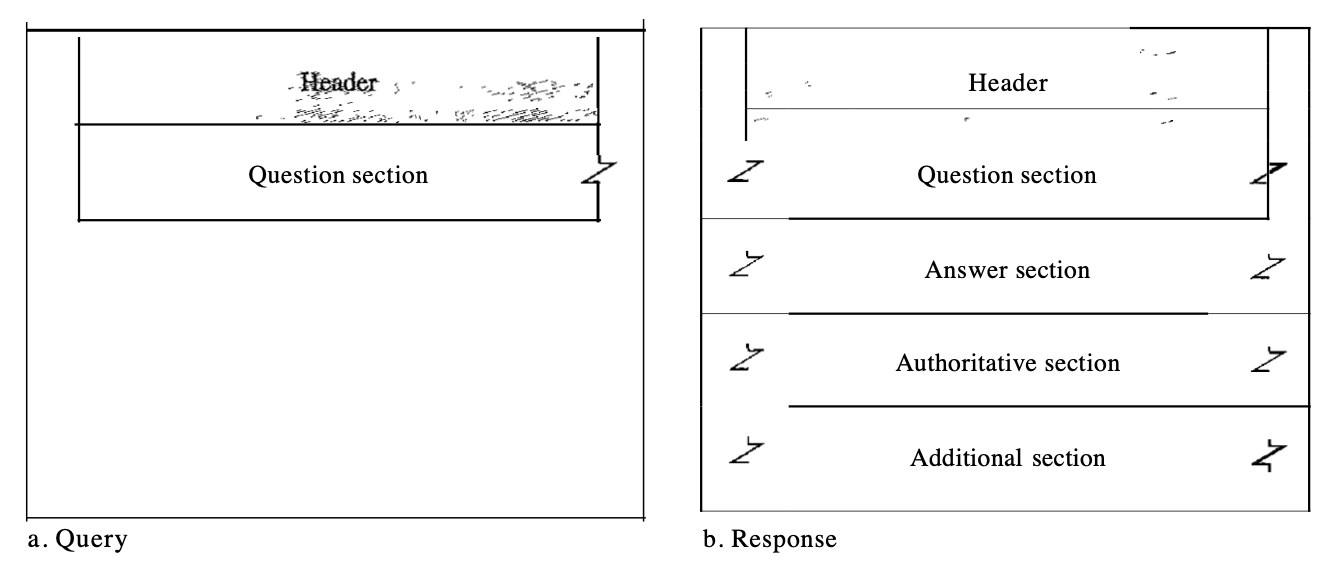
Fig : query and response message
Header
For query messages, all query and response messages have the same header format, with certain fields set to zero.
The header is 12 bytes, and below is the format:
Identification | Flag |
Number of question records | Number of answer records (All os in query message) |
Number of authoritative records(All os in query message) | Number of additional records (All os in query message) |
● Identification : The 16 bit field that the client uses to align the response with the question. Any time a question is submitted, the client uses identification numbers. The server, in answer, duplicates this number.
● Flag : Subfield flags are a set of subfields that specify the message type, the type of response requested, the type of resolution requested (recursive or iterative), and so on.
Number of question records : This is a 16-bit field consisting of the number of message segment queries in question.
Number of answer records : This is a 16-bit field containing the number of reply records found in the reply message section. Its value is 0 in the message demand.
Number of authoritative records : A sixteen-bit field that indicates the number of authoritative records in the answer message's authoritative portion. In the question message, its value is zero.
Number of additional records : This is a 16-bit field that contains the number of additional records in the answer message's additional portion.
Question section
This is a segment made up of records of one or more issues. In both query and answer messages, it is present. In a subsequent segment, we will address the query documents.
Answer section
This is a section which consists of one or more records of resources. Only answer messages are present. This section contains a response to the client from the server (resolver).
Authoritative section
This is a section which consists of one or more records of resources. Only answer messages are present. This section contains information about one or more authoritative servers for the question (domain name).
Additional information section
This is a section which consists of one or more records of resources. Only answer messages are present.
For example, in the Authoritative section, a server can give the domain name of an authoritative server to the resolver and provide the IP address of the same authoritative server in the Additional Information section.




