UNIT - 1
Language Processors
Q1) Explain language processors?
A1)
Assembly language is machine dependent yet mnemonics that are being used to represent instructions in it are not directly understandable by machine and high Level language is machine independent. A computer understands instructions in machine code, i.e. in the form of 0s and 1s. It is a tedious task to write a computer program directly in machine code. The programs are written mostly in high level languages like Java, C++, Python etc. and are called source code. These source code cannot be executed directly by the computer and must be converted into machine language to be executed. Hence, a special translator system software is used to translate the program written in high-level language into machine code is called Language Processor and the program after translated into machine code (object program / object code).
The language processors can be any of the following three types:
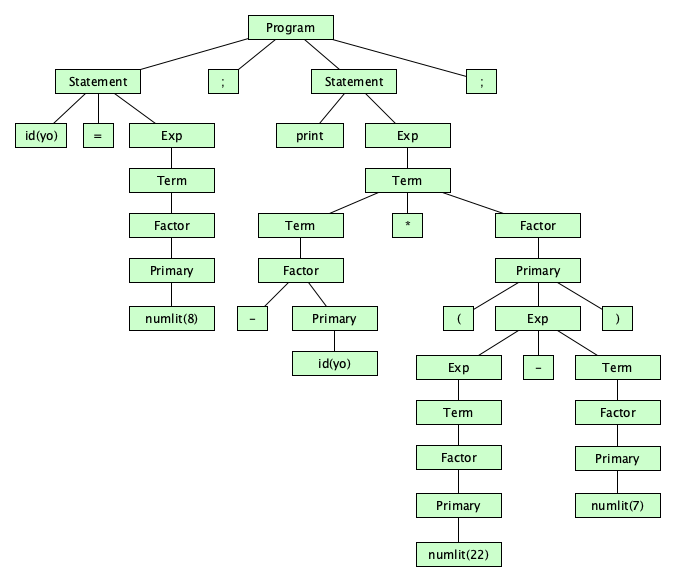
The language processor that reads the complete source program written in high level language as a whole in one go and translates it into an equivalent program in machine language is called as a Compiler.
Example: C, C++, C#, Java
In a compiler, the source code is translated to object code successfully if it is free of errors. The compiler specifies the errors at the end of compilation with line numbers when there are any errors in the source code. The errors must be removed before the compiler can successfully recompile the source code again.>
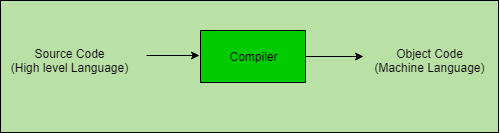
2. Assembler –
The Assembler is used to translate the program written in Assembly language into machine code. The source program is a input of assembler that contains assembly language instructions. The output generated by assembler is the object code or machine code understandable by the computer.
3. Interpreter –
The translation of single statement of source program into machine code is done by language processor and executes it immediately before moving on to the next line is called an interpreter. If there is an error in the statement, the interpreter terminates its translating process at that statement and displays an error message. The interpreter moves on to the next line for execution only after removal of the error. An Interpreter directly executes instructions written in a programming or scripting language without previously converting them to an object code or machine code.
Example: Perl, Python and Matlab.
Q2) Difference between Compiler and Interpreter?
A2)
Compiler | Interpreter |
A compiler is a program which coverts the entire source code of a programming language into executable machine code for a CPU. | interpreter takes a source program and runs it line by line, translating each line as it comes to it. |
Compiler takes large amount of time to analyze the entire source code but the overall execution time of the program is comparatively faster. | Interpreter takes less amount of time to analyze the source code but the overall execution time of the program is slower. |
Compiler generates the error message only after scanning the whole program, so debugging is comparatively hard as the error can be present any where in the program. | Its Debugging is easier as it continues translating the program until the error is met |
Generates intermediate object code. | No intermediate object code is generated. |
Examples: C, C++, Java | Examples: Python, Perl |
Q3) Explain Language processing activities?
A3)
Language processing activities arise to bridge the ideas of software designer with actual execution on the computer system. Due to the differences between the manners in which a software designer describes the ideas concerning the behaviour of software and the manner in which these ideas are implemented in a computer system. The designer expresses the ideas in terms related to the application domain of the software. To implement these ideas, their description has to be interpreted in terms related to the execution domain of the computer system. We use the term semantics to represent the rules of meaning of a domain, and the term semantic gap to represent the difference between the semantics of two domains. The fundamental language processing activities can be divided into those that bridge the specification gap and those that bridge the execution gap.
· Program Generation Activities
· Program Execution Activities
A program generation activity aims at automatic generation of a program. The source language is a specification language of an application domain and the target language is typically a procedure oriented PL. A program execution activity, organizes this execution of a program written in a PL on a computer system. Its source language could be a procedure-oriented language or a problem oriented language.
Program Generation
The program generator is a software system which accepts the specification of a program to be generated, and generates a program in the target PL. We call this the program generator domain. The specification gap is now the gap between the application domain and the program generator domain. This gap is smaller than the gap between the application domain and the target PL domain.
Reduction in the specification gap increases the reliability of the generated program. Since the generator domain is close to the application domain, it is easy for the designer or programmer to write the specification of the program to be generated.
Program generator domain
The harder task of bridging the gap to the PL domain is performed by the generator. This would be performed while implementing the generator. To test an application generated by using the generator, it is necessary to only verify the correctness of the specification input to the program generator. This is a much simpler task than verifying correctness of the generated program. This task can be further simplified by providing a good diagnostic (i.e. error indication) capability in the program generator, which would detect inconsistencies in the specification.
It is more economical to develop a program generator than to develop a problem-oriented language. This is because a problem oriented language suffers a very large execution gap between the PL domain and the execution domain, whereas the program generator has a smaller semantic gap to the target PL domain, j which is the domain of a standard procedure oriented language. The execution gap between the target PL domain and the execution domain is bridged by the compiler or interpreter for the PL.
Program Execution
Two popular models for program execution are
· Translation
· Interpretation
Program Translation
Program translation model bridges the execution gap by translating a program written in a PL, called the source program (SP), into an equivalent program in the machine or assembly language of the computer system, called the target program (TP).
Q4) What are the Fundamentals of language processing?
A4)
Language processing = Analysis of source program + synthesis of target program.
Analysis of source program; It contains three types:
Figure shows phases of language processor.

Source program passed through analysis phase and it generate IR which is intermediate representation which is further passed to synthesis phase which finally generates target program.
In analysis phase we are using forward reference. Forward reference of a program entity is a reference to the entity which precedes its definition in the program IR is having following properties :-
In this way language processing takes place.
Q5) Explain Fundamentals of language specification?
A5)
Let’s consider the language of infix integer arithmetic expressions with optional parentheses, the operators plus, minus, times, divide, and unary negation, and with spaces and tabs allowed between numbers and operators. We’ll call the language Ael, for Arithmetic Expression Language.
Getting Started
When designing a language, it’s a good idea to start by sketching forms that you want to appear in your language as well as forms you do not want to appear.
Examples | Non-Examples |
432 24* (31/899 +3-0)/(54 /2+ 4+2*3) (2) 8*(((3-6))) | 43 2 24*(31/// /)/(5+---+)) [fwe]23re 3 1 124efr$#%^@ --2-- |
Concrete Syntax
Next, we look at the legal forms, and create a grammar for the concrete syntax. Here is our first try (it will turn out to not be very good, but it works):
For consistency, we’ll be using Ohm notation throughout this course, unless a different notation is specifically noted.
exp = space* exp space* op space* exp space*
| space* numlit space*
| space* "-" space* exp space*
| space* "(" space* exp space* ")" space*
op = "+" | "-" | "*" | "/"
numlit = digit+
digit = "0".."9"
space = " " | "\t"
Augh! All those “space*” occurrences make the description hard to read. But we’re using so, so let’s use the fact that if a rule name begins with a capital letter, it will be as if space* appears between all of the expressions on the right hand side. This gives us:
Exp = Exp op Exp
| numlit
| "-" Exp
| "(" Exp ")"
op = "+" | "-" | "*" | "/"
numlit = digit+
digit = "0".."9"
space = " " | "\t"
This simple but very powerful idea leads to some useful terminology: Lexical categories start with lowercase letters. Phrase categories start with capital letters. The lexical definitions show us how to combine characters into words and punctuation (called tokens), and the phrase definitions show us how to combine words and symbols into phrases (where the words and symbols can, if you wish, be surrounded by spacing).
Q6) Meditate on how profound this is. Have you seen anything like this before?
A6)
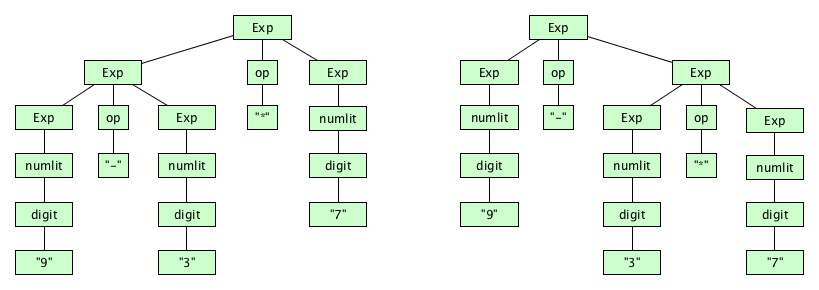
But we still have problems. This grammar can parse the string 9-3*7 in two ways:
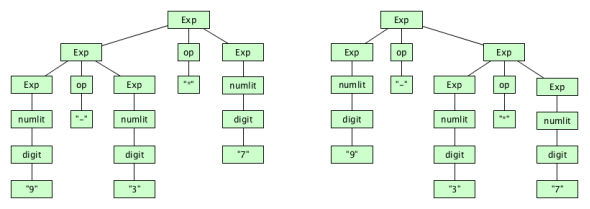
This means our syntax description is ambiguous. One way to get rid of the ambiguity is to add extra rules to build in an operator precedence:
Exp = Term (("+" | "-") Term)*
Term = Factor (("*" | "/") Factor)*
Factor = "-"? Primary
Primary = "(" Exp ")" | numlit
numlit = digit+
digit = "0".."9"
space = " " | "\t"
Q7) Show that this grammar leads to only one parse tree for the string 3*9-7?
A7)
This takes care of precedence concerns, but what if we wanted our grammar to specify associativity? We can do that too. Here is a way to make our binary operators left-associative:
Exp = Term | Exp ("+" | "-") Term
Term = Factor | Term ("*" | "/") Factor
Factor = Primary | "-" Primary
Primary = numlit | "(" Exp ")"
digit = "0".."9"
numlit = digit+
space = " " | "\t"
Q8) Give the parse tree for 3-5-8-2*8-9-7-1 according to this grammar.
Abstract Syntax?
A8)
We had to do a lot of specification work to define expressions as strings of characters. For example, we needed extra tokens (parentheses) and extra categories (Term, Factor, Primary) in order to capture precedence, and use other tricks to capture associativity. None of this crap matters if our languages were just trees! So let’s define function A
to turn a phrase into an abstract syntax tree. We write trees in the form {ABC...} where A is the root and B, C
, ... are the children.
A(E+T)={PlusA(E)A(T)}
A(E−T)={MinusA(E)A(T)}
A(T∗F)={TimesA(T)A(F)}
A(T/F)={DivideA(T)A(F)}
A(−P)={NegateA(P)}
A(n)={Numlitn}
A((E))=A(E)
Static Semantics
Think of how in a language like Java, an expression like x+5 looks beautifully well-formed and well-structured. But if x
hasn’t been declared, or has a type other than a number or string, the expression doesn’t mean anything. So while it is syntactically correct, it can be determined meaningless without ever running a program containing it.
Ael doesn’t have any semantic rules that can be checked statically. Perhaps we could imagine some.... If we had, say, limited all integer literals to 64 bits, we would probably put that requirement in the static semantics (even though in theory it is checkable in the syntax).
Q9) Write a microsyntax rule for nonnegative integers less than 128,Write a microsyntax rule for nonnegative integers less than 263 Is this busy work?
A9)
Dynamic Semantics
A dynamic semantics computes the meaning of an abstract syntax tree. In Ael, the meaning of expressions will be integer numeric values. Assuming the existence of a function valueof
for turning number tokens into numeric values, we’ll define function E
, mapping abstract syntax trees to value, as follows:
E{Pluse1e2}=Ee1+Ee2
E{Minuse1e2}=Ee1−Ee2
E{Timese1e2}=Ee1×Ee2
E{Dividee1e2}=Ee1÷Ee2
E{Negatee}=−Ee
E{Numlitn}=valueof(n)
Applying the Specification
Let’s determine the meaning of this string:
-8 * (22- 7)
The character string is:
SPACE HYPHEN DIGIT EIGHT SPACE TAB ASTERISK SPACE LEFTPAREN DIGIT TWO DIGIT TWO HYPHEN SPACE SPACE DIGIT SEVEN RIGHTPAREN
Let’s apply the lexical rules to tokenize the string:
space - numlit(8) space space * space ( numlit(22) - space space numlit(7) )
The spaces will be skipped eventually, so we can just as well view the token stream like this:
- numlit(8) * ( numlit(22) - numlit(7) )
Parsing uncovers the derivation tree, also known as the concrete syntax tree:
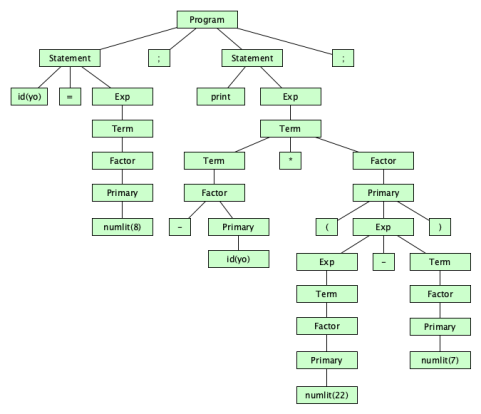
The static semantics is applied to the concrete syntax tree to produce the abstract syntax tree, namely:
{Times{Negate{Numlit8}}{Minus{Numlit22}{Numlit7}}}
which might be a little easier to read like this:
{Times{Negate{Numlit8}}{Minus{Numlit22}{Numlit7}}}
or even easier to read in tree form like this:
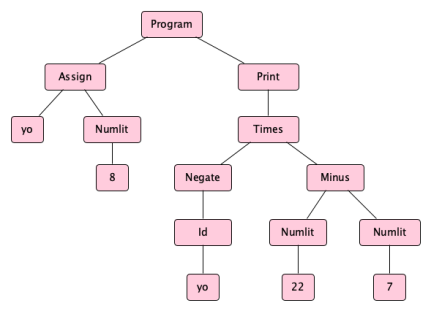
which, informally can be shortened to:
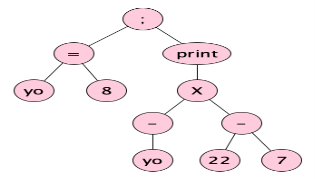
Notice how ASTs are way simpler than concrete trees. In fact in real compilers, unless the language is extraordinarily simple, you never see a concrete tree! Parsers generally go straight to the abstract syntax tree (though there are exceptions).
Finally, we apply the dynamic semantics to the AST to compute the meaning:
E{Times{Negate{Numlit8}}{Minus{Numlit22}{Numlit7}}}=E{Negate{Numlit8}}×E{Minus{Numlit22}{Numlit7}}}=−E{Numlit8}×(E{Numlit22}−E{Numlit7})=−8×(22−7)=−8×15=−120
Q10) Explain Language processor development tools?
A10)
The analysis phase of the language processor has a standard form. The source text is subjected to lexical, syntax and semantic analysis. The result of the analysis phase is IR. Thus writing of language processors has become very important. This has led to the development of a set of language processor development tools (LPDT).
Schematic of LPDT: The figure below shows a schematic of language processor development tool that generates the analysis phase of language processor whose source language is L.
Source Program

The language processor development tool requires two set of inputs:
1. Specification of grammar of a language L.
2. Specification of semantic actions to be performed in the analysis phase.
Introduction to LEX and YACC: There are two language processor development tools namely LEX and YACC. LEX is the lexical analyzer that performs lexical analysis of SP written in a programming language L. YACC is the parser generator that constructs the syntactic structure of the source statement. The input to these tools is the specification of lexical and syntactic constructs of L, and semantic actions to be performed on recognizing the constructs. The specification consists of a set of translation rules of the form <string specification> {<semantic action>}. Here semantic action> consist of C code that is executed when a string matching <string specification> is encountered in the input. The figure below shows the schematic for the development of analysis phase of a compiler for language L using LEX and YACC.
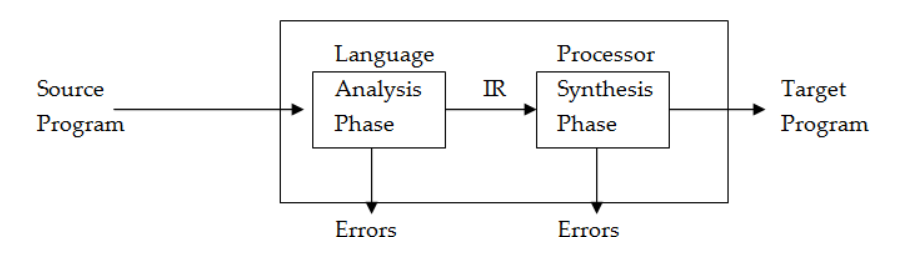
The analysis phase processes the source program to build an intermediate representation. A single pass compiler can be built using LEX and YACC if the semantic actions are aimed at generating target code instead of IR. Scanner also generates an intermediate representation of a source program for use by the parser. We call it IRl to differentiate from the IR of analysis phase.
LEX: LEX accepts an input specification which consists of two components. The first component is the specification of strings representing lexical units in L. e.g, id, constants etc. The second component is the semantic actions aimed at building the IR. As already seen, the IR consists of tables of information (symbol table) and a sequence of tokens representing source statement. Accordingly semantic actions make new entries in the tables and build tokens for the lexical units.
Example: Following is a sample input to LEX.
The sample input consists of following components:
1. The first component between %{ and }% defines the symbols in specifying the strings of L. It defines the symbol ͚Letter͛ for any uppercase or lowercase letter and ͚Digit͛ to stand for any digit.
2. The second component between %% and %% are the translation rules.
3. The third component contains auxiliary routines which can be used in semantic actions.
YACC: Each string specification in the input to YACC resembles a grammar production. The parser generated by YACC performs reductions according to this grammar. The actions associated with the string specification are executed when a reduction is made according to the specification. An attribute is associated with every non-terminal symbol. The value of this attribute can be manipulated during parsing. The attribute can be given any user-designed structure. The symbol ͚$n͛ in the action part of a translation rule refers to nth symbol in the RHS of the string specification. ͚$$͛ represent the attribute of the LHS symbol of the string specification.