UNIT - 4
Compilers and Interpreters
Q1) What are the Aspects of compilation?
A1)
Introduction
The word compilation is used to denote the task of translating high level language (HLL) programs into machine language programs. Though the objective of this task of translation is similar to that of an assembler, the problem of compilation is much more complex than that of an assembler. A compiler is a program that does the compilation task. A compiler recognises programs in a particular HLL and produces equivalent output programs appropriate for some particular computer configuration (hardware and OS). Thus, an HLL program is to a great extent independent of the configuration of the machine it will eventually run on, as long as it is ensured that the program is compiled by a compiler that recognises that HLL and produces output for the required machine configuration. It is common for a machine to have compilers that would translate programs to produce executables for that machine (hosts). But there also are compilers that runs on one type of machine but the output of which are programs that shall run on some other machine configuration, such as generating an MS-DOS executable program by compiling an HLL program in UNIX. Such a compiler is called a cross compiler. Another kind of translator that accepts programs in HLL are known as interpreters. An interpreter translates an input HLL program and also runs the program on the same machine. Hence the output of running an interpreter is actually the output of the program that it translates.
Important phases in Compilation
The following is a typical breakdown of the overall task of a compiler in an approximate sequence -
Lexical analysis, Syntax analysis, Intermediate code generation, Code optimisation, Code generation.
Like an assembler, a compiler usually performs the above tasks by making multiple passes over the input or some intermediate representation of the same. The compilation task calls for intensive processing of information extracted from the input programs, and hence data structures for representing such information needs to be carefully selected. During the process of translation a compiler also detects certain kinds of errors in the input, and may try to take some recovery steps for these.
Q2) Explain lexical analysis and syntax analysis?
A2)
Lexical Analysis
Lexical analysis in a compiler can be performed in the same way as in an assembler. Generally in an HLL there are more number of tokens to be recognised - various keywords (such as, for, while, if, else, etc.), punctuation symbols (such as, comma, semi-colon, braces, etc.), operators (such as arithmatic operators, logical operators, etc.), identifiers, etc. Tools like lex or flex are used to create lexcical analysers.
Syntax Analysis
Syntax analysis deals with recognising the structure of input programs according to known set of syntax rules defined for the HLL. This is the most important aspect in which HLLs are significantly different from lower level languages such as assembly language. In assembly languages the syntax rules are simple which roughly requires that a program should be a sequence of statements, and each statement should esentially contain a mnemonic followed by zero or more operands depending on the mnemonic. Optionally, there can be also be an identifier preceding the mnemonic. In case of HLLs, the syntax rules are much more complicated. In most HLLs the notion of a statement itself is very flexible, and often allows recursion, making nested constructs valid. These languages usually support multiple data types and often allow programmers to define abstruct data types to be used in the programs. These and many other such features make the process of creating software easier and less error prone compared to assembly language programming. But, on the other hand, these features make the process of compilation complicated.
The non-trivial syntax rules of HLLs need to be cleverly specified using some suitable notation, so that these can be encoded in the compiler program. One commonly used formalism for this purpose is the Context Free Grammar (CFG). CFG is a formalism that is more powerful than regular grammars (used to write regular expressions to describe tokens in a lexical analyser). Recursion, which is a common feature in most constructs of HLLs, can be defined using a CFG in a concise way, whereas a regular grammar is incapable of doing so. It needs to be noted that there are certain constructs that cannot be adequately described using CFG, and may require other more powerful formalisms, such as Context Sensitive Grammars (CSG). A common notation used to write the rules of CFG or CSG is the BNF (Backus Naur Form).
During syntax analysis, the compiler tries to apply the rules of the grammar of the input HLL given using BNF, to recognise the structure of the input program. This is called parsing and the module that performs this task is called a parser. From a somewhat abstract point of view, the output of this phase is a parse tree that depicts how various rules of the grammar can be repetitively applied to recognise the input program. If the parser cannot create a parse tree for some given input program, then the input program is not valid according to the syntax of the HLL.
The soundness of the CFG formalism and the BNF notation makes it possible to create different types of efficient parsers to recognise input according to a given language. These parsers can be broadly classified as top-down parsers and bottom-up parsers. Recursive descent parsers and Predictive parsers are two examples of top-down parsers. SLR parsers and LALR parser are two examples of bottom-up parsers. For certain simple context free languages (languages that can be defined using CFG) simpler bottom-up parsers can be written. For example, for recognising mathematical expressions, an operator precedence parser can be created.
In creating a compiler, a parser is often built using tools such as yacc and bison. To do so the CFG of the input language is written in BNF notation, and given as input to the tool (along with other details).
Q3) Explain Intermediate Code Generation?
A3)
Having recognised a given input program as valid, a compiler tries to create the equivalent program in the language of the target environment. In case of an assembler this translation was somewhat simpler since the operation implied by the mnemonic opcode in each statement in the input program, there is some equivalent machine opcode. The number of operands applicable for each operation in the machine language is the same as allowed for the corresponding assembly language mnemonic opcodes. Thus for the assembly language the translation for each statement can be done for each statement almost independently of the rest of the program. But, in case of an HLL, it is futile to try to associate a single machine opcode for each statement of the input language. One of the reasons for this is, as stated above, the extent of a statement is not always fixed and may contain recursion. Moreover, data references in HLL programs can assume significant levels of abstractions in comparision to what the target execution environment may directly support. The task of associating meanings (in terms of primitive operations that can be supported by a machine) to programs or segments of a program is called semantic processing.
Syntax Directed Translation
Though it is not entirely straightforward to associate target language operations to statements in the HLL programs, the CFG for the HLL allows one to associate semantic actions (or implications) for the various syntactic rules. Hence in the broad task of translation, when the input program is parsed, a compiler also tries to perform certain semantic actions corresponding to the various syntactic rules that are eventually applied. However, most HLLs contain certain syntactic features for which the semantic actions are to be determined using some additional information, such as the contents of the symbol table. Hence, building and usage of data-structures such as the symbol table are an important part of the semantic action that are performed by the compiler.
Upon carrying out the semantic processing a more manageable equivalent form of the input program is obtained. This is stored (represented) using some Intermediate code representation that makes further processing easy. In this representation, the compiler often has to introduce several temporary variables to store intermediate results of various operations. The language used for the intermediate code is generally not any particular machine language, but is such which can be efficiently converted to a required machine language (some form of assembly language can be considered for such use).
Q4) Define Code Optimisation?
A4)
The programs represented in the intermediate code form usually contains much scope for optimisation both in terms of storage space as well as run time efficiency of the intended output program. Sometimes the input program itself contains such scope. Besides that, the process of generating the intermediate code representation usually leaves much room for such optimisation. Hence, compilers usually implement explicit steps to optimise the intermediate code.
Q5) Define Code Generation?
A5)
Finally, the compiler converts the (optimised) program in the intermediate code representation to the required machine language. It needs to be noted that if the program being translated by the compiler actually has dependencies on some external modules, then linking has to be performed to the output of the compiler. These activities are independent of whether the input program was in HLL or assembly language.
Q6) Define Run-time Storage Administration?
A6)
One of the important aspects of the semantic actions of a compiler is to ensure an efficient and error free run-time storage model to the output program. Most modern programming languages allows some extent of block-structuring, nesting of constructs, and recursion of subroutines. All these calls for an efficient modelling of data storage that is dynamic, and it turns out that a stack meets much of the criteria. Thus allocation and access of storage for program variables, subroutine parameters, and compiler generated internal variables on the stack is an important part of the task of a compiler.
Q7) What are the Memory Management Techniques?
A7)
Here, are some most crucial memory management techniques:
Single Contiguous Allocation
It is the easiest memory management technique. In this method, all types of computer's memory except a small portion which is reserved for the OS is available for one application. For example, MS-DOS operating system allocates memory in this way. An embedded system also runs on a single application.
Partitioned Allocation
It divides primary memory into various memory partitions, which is mostly contiguous areas of memory. Every partition stores all the information for a specific task or job. This method consists of allotting a partition to a job when it starts & unallocate when it ends.
Paged Memory Management
This method divides the computer's main memory into fixed-size units known as page frames. This hardware memory management unit maps pages into frames which should be allocated on a page basis.
Segmented Memory Management
Segmented memory is the only memory management method that does not provide the user's program with a linear and contiguous address space.
Segments need hardware support in the form of a segment table. It contains the physical address of the section in memory, size, and other data like access protection bits and status.
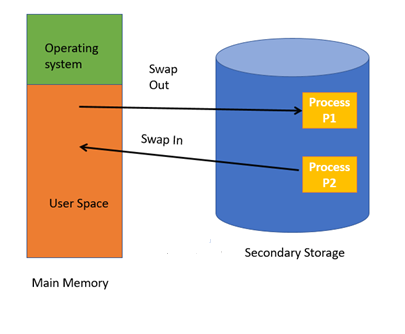
Q8) What is Swapping?
A8)
Swapping is a method in which the process should be swapped temporarily from the main memory to the backing store. It will be later brought back into the memory for continue execution.
Backing store is a hard disk or some other secondary storage device that should be big enough inorder to accommodate copies of all memory images for all users. It is also capable of offering direct access to these memory images.
Benefits of Swapping
Here, are major benefits/pros of swapping:
Q9) What is Memory allocation?
A9)
Memory allocation is a process by which computer programs are assigned memory or space.
Here, main memory is divided into two types of partitions
Partition Allocation
Memory is divided into different blocks or partitions. Each process is allocated according to the requirement. Partition allocation is an ideal method to avoid internal fragmentation.
Below are the various partition allocation schemes :
Q10) What is Fragmentation?
A10)
Processes are stored and removed from memory, which creates free memory space, which are too small to use by other processes.
After sometimes, that processes not able to allocate to memory blocks because its small size and memory blocks always remain unused is called fragmentation. This type of problem happens during a dynamic memory allocation system when free blocks are quite small, so it is not able to fulfill any request.
Two types of Fragmentation methods are:




