Module III
Database and MySQL
Q1) Explain select statements? 12 Marks
A1) The SELECT statement is used in the database to select / retrieve data from a tabLe. The most frequently used statement is the SQL Pick Statement.
The SELECT Statement question retrieves data from the table as a whole or from some particular columns.
We need to write SELECT statement queries in SQL if we want to retrieve any data from a table.
We retrieve the data by columns in SELECT Statement wise.
Syntax
The SQL SELECT Syntax is categorised into two sections, first we get complete table data from all columns, second we get some unique columns from a table.
SELECT all Columns data from a table
SELECT * FROM table_name ;
* = indicate the retrieve all the columns from a table.
Table_name = is the name of the table from which the data is retrieved.
SELECT some columns data from a table
SELECT Col1, Col2, Col3 FROM table_name
Col1, Col2, Col3 = is the column name from which data is retrieved.
Table_name = is the name of the table from which the data is retrieved.
A SELECT command has number of clauses :
WHERE clause
Any output row from the FROM stage applies a criterion, further reducing the number of rows.
When collecting data from a single table or merging many tables, the SQL WHERE clause is used to set a condition. Only a specific value from the table is returned if the stated condition is met. To filter the records and retrieve only the ones you need, use the WHERE clause.
The WHERE clause is utilized not just in the SELECT statement, but also in the UPDATE, DELETE, and other statements.
Syntax
The SELECT statement with the WHERE clause has the following basic syntax.
SELECT column1, column2, columnN
FROM table_name
WHERE [condition]
Example
Consider the CUSTOMERS table having the following records −
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The following code retrieves the ID, Name, and Salary fields from the CUSTOMERS database, where the salary is larger than 2000 dollars.
SQL> SELECT ID, NAME, SALARY
FROM CUSTOMERS
WHERE SALARY > 2000;
Result
+----+----------+----------+
| ID | NAME | SALARY |
+----+----------+----------+
| 4 | Chaitali | 6500.00 |
| 5 | Hardik | 8500.00 |
| 6 | Komal | 4500.00 |
| 7 | Muffy | 10000.00 |
+----+----------+----------+
GROUP BY clause
Class sets of rows with values balanced by columns in a group.
Syntax
The following code block illustrates the basic syntax of a GROUP BY clause. The GROUP BY clause must come after the WHERE clause's conditions and, if one is used, before the ORDER BY clause.
SELECT column1, column2
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2
ORDER BY column1, column2
Example
Consider the following records in the CUSTOMERS table:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The GROUP BY query might be as follows if you want to know the total amount of each customer's salary.
SQL> SELECT NAME, SUM(SALARY) FROM CUSTOMERS
GROUP BY NAME;
This would result in the following:
+----------+-------------+
| NAME | SUM(SALARY) |
+----------+-------------+
| Chaitali | 6500.00 |
| Hardik | 8500.00 |
| kaushik | 2000.00 |
| Khilan | 1500.00 |
| Komal | 4500.00 |
| Muffy | 10000.00 |
| Ramesh | 2000.00 |
+----------+-------------+
HAVING clause
Criteria for each group of rows are added. Criteria can only be extended to columns within a category that have constant values (those in the grouping columns or aggregate functions applied across the group).
Syntax
The HAVING Clause is shown in the following code block in a query.
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
In a query, the HAVING clause must come after the GROUP BY clause and, if used, before the ORDER BY clause. The syntax of the SELECT statement, including the HAVING clause, is shown in the following code block.
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
ORDER BY clause
The rows returned from the SELECT stage are sorted as desired. Supports sorting, ascending or descending on multiple columns in a specified order. The output columns will be similar and have the same name as the columns returned from the SELECT point.
Syntax
The ORDER BY clause's basic grammar is as follows:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. ColumnN] [ASC | DESC];
Example
Consider the following records in the CUSTOMERS table:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The following code block shows an example of sorting the results by NAME and SALARY in ascending order.
SQL> SELECT * FROM CUSTOMERS
ORDER BY NAME, SALARY;
This would result in the following:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
+----+----------+-----+-----------+----------+
Distinct
The SQL DISTINCT keyword is combined with the SELECT query to remove all duplicate records and return only unique records.
There may be times when a table has several duplicate records. It makes more sense to fetch only those unique records rather than duplicate records when retrieving such records.
Syntax
The DISTINCT keyword's fundamental syntax for removing duplicate records is as follows:
SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]
Q2) What is logical opertor? 12 Marks
A2) You can use a logical operator to check if a condition is true. A logical operator, like a comparison operator, returns a value of true, false, or unknown.
Syntax
SELECT [column_name | * | expression] [logical operator]
[column_name | * | expression .....]
FROM <table_name>
WHERE <expressions> [ logical operator |
Arithmetic operator | ...] <expressions>;
Parameter :
Column_name - Name of the column of a table.
* - All the columns of a table.
Expression - Expressions are elements of a SQL query that compare values to other values or conduct arithmetic calculations and are made up of a single constant, variable, scalar function, or column name.
Table_name - name of the table.
Logical operator - AND, OR, NOT etc.
Arithmetic operator - plus, minus, multiply, divide.
The SQL logical operators are shown in the table below:
Operator | Description |
AND | The logical AND operator compares two Booleans as expressions and returns true if both are true. |
OR | The logical OR operator analyzes two Boolean expressions and returns true if one of them is true. |
NOT | As an argument, Not changes the value of a single Boolean from false to true or true to false. |
AND
Logical AND compares two Booleans as an expression, returning TRUE if both conditions are TRUE and FALSE if either condition is FALSE; else, returns UNKNOWN (an operator that has one or two NULL expressions returns UNKNOWN).
In SQL statements like SELECT, UPDATE, and DELETE, the AND operator allows you to create several criteria in the WHERE clause:
Expression1 AND expression2
If both expressions evaluate to true, the AND operator yields true.
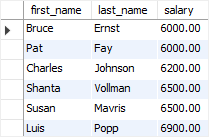
The following example discovers all employees with incomes between 5,000 and 7,000 dollars:
SELECT
First_name, last_name, salary
FROM
Employees
WHERE
Salary > 5000 AND salary < 7000
ORDER BY salary;
OR
Logical OR compares two Booleans as an expression, returning TRUE if either condition is TRUE and FALSE if both conditions are FALSE. Otherwise, UNKNOWN is returned (an operator that has one or two NULL expressions returns UNKNOWN).
The OR operator, like the AND operator, combines numerous conditions in the WHERE clause of a SQL statement:
Expression1 OR expression2
The OR operator, on the other hand, returns true if at least one expression is true.
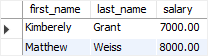
The following statement, for example, finds employees with a salary of either 7,000 or 8,000 dollars:
SELECT
First_name, last_name, salary
FROM
Employees
WHERE
Salary = 7000 OR salary = 8000
ORDER BY salary;
NOT
As an argument, logical NOT changes the value of a single Boolean from false to true or true to false.
The NOT operator is used to reverse the result of any Boolean statement. The NOT operator is demonstrated in the following example.
NOT [Boolean_expression]
The NOT operator's result is shown in the table below.
| NOT |
TRUE | FALSE |
FALSE | TRUE |
NULL | NULL |
For the demonstration of the NOT operator, we'll utilize the employees table.

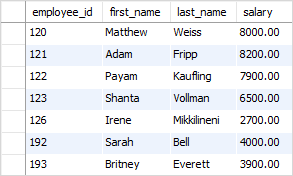
The following statement returns all employees in the department id 5 who work for the company.
SELECT
Employee_id,
First_name,
Last_name,
Salary
FROM
Employees
WHERE
Department_id = 5
ORDER BY
Salary;
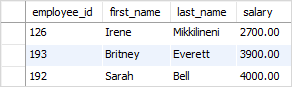
To find employees who work in department id 5 and make less than $5,000 per year.
SELECT
Employee_id,
First_name,
Last_name,
Salary
FROM
Employees
WHERE
Department_id = 5
AND NOT salary > 5000
ORDER BY
Salary;
LIKE
It's sometimes useful to see if an expression meets a specific pattern, such as finding all employees with first names that begin with Da or Sh. In these circumstances, the LIKE operator is required.
The LIKE operator determines whether or not an expression matches a pattern. Look at the syntax below:
Expression LIKE pattern
The LIKE operator returns true if the expression fits the pattern. Otherwise, false is returned.
In the WHERE clause of the SELECT, UPDATE, and DELETE statements, the LIKE operator is frequently utilized.
You use two SQL wildcard characters to create a pattern:
% percent sign matches zero, one, or more characters.
_ underscore sign matches a single character.
The table below depicts some patterns and their meanings:
Expression | Meaning |
LIKE 'Kim%' | Begins with Kim |
LIKE '%er' | Ends with er |
LIKE '%ch%' | Contains ch |
LIKE 'Le_' | It starts with Le and ends with at most one character, such as Les, Len... |
LIKE '_uy' | Ends in uy and has only one character before it, such as guy. |
LIKE '%are_' | Contains is defined as a string that starts with any number of characters and ends with only one character. |
LIKE '_are%' | Contains is a string of characters that starts with one and ends with any number of characters. |
If you want to match the wildcards percent or _, you must escape them with the backslash character. You can use the ESCAPE clause in the LIKE expression instead of the backslash if you want to use a different escape character than the backslash:
Expression LIKE pattern ESCAPE escape_character
Q3)Describe Arithmetic and Relational operator? 5 Marks
A3) Arithmetic and Relational operator
Assume 'variable a' holds 10 and 'variable b' holds 20, then −
Operator | Description | Example |
+ (Addition) | Adds values on either side of the operator. | a + b will give 30 |
- (Subtraction) | Subtracts right hand operand from left hand operand. | a - b will give -10 |
* (Multiplication) | Multiplies values on either side of the operator. | a * b will give 200 |
/ (Division) | Divides left hand operand by right hand operand. | b / a will give 2 |
% (Modulus) | Divides left hand operand by right hand operand and returns remainder. | b % a will give 0 |
Assume 'variable a' holds 10 and 'variable b' holds 20, then −
Operator | Description | Example |
= | Checks whether the values of two operands are equal, and if they are, the condition is true. | (a = b) is not true. |
!= | Checks whether the values of two operands are equivalent; if they aren't, the condition is true. | (a != b) is true. |
<> | Checks whether the values of two operands are equivalent; if they aren't, the condition is true. | (a <> b) is true. |
> | If the left operand's value is greater than the right operand's value, then the condition is true. | (a > b) is not true. |
< | Checks if the left operand's value is less than the right operand's value; if it is, the condition is true. | (a < b) is true. |
Q4) Aggregate Functions- count, sum, avg, max, min? 8 Marks
A4) Aggregate functions
The data that you need is not always stored in the tables. However, you can get it by performing the calculations of the stored data when you select it.
Suppose we have table:
Orderdetails |
*orderNumber *productCode QuantityOrdered PriceEach OrderLineNumber |
For example, you cannot get the total amount of each order by simply querying from the order details table because the order details table stores only quantity and price of each item. You have to select the quantity and price of an item for each order and calculate the order’s total.
To perform such calculations in a query, you use aggregate functions.
By definition, an aggregate function performs a calculation on a set of values and returns a single value.
MySQL provides aggregate functions like: AVG, MIN, MAX, SUM, COUNT.
Suppose we have employees table as shown below:
Mysql> select * from employees;
+------+--------+--------+
| e_id | e_name | salary |
+------+--------+--------+
| 1001 | Sam | 10000 |
| 1002 | Jerry | 11000 |
| 1003 | King | 25000 |
| 1004 | Harry | 50000 |
| 1005 | Tom | 45000 |
| 1006 | Johnny | 75000 |
| 1007 | Andrew | 5000 |
+------+--------+--------+
7 rows in set (0.00 sec)
AVERAGE:
Mysql> Select avg(salary) as “Average Salary” from employees;
+--------------------+
| Average Salary |
+--------------------+
| 31571.428571428572 |
+--------------------+
MINIMUM:
Mysql> Select min(salary) as “Minimum Salary” from employees;
+----------------+
| Minimum Salary |
+----------------+
| 5000 |
+----------------+
MAXIMUM:
Mysql> Select max(salary) as “Maximum Salary” from employees;
+----------------+
| Maximum Salary |
+----------------+
| 75000 |
+----------------+
TOTAL COUNT OF RECORDS IN TABLE:
Mysql>Select count(*) as “Total” from employees;
+-------+
| Total |
+-------+
| 7 |
+-------+
SUM:
Mysql> Select sum(salary) as “Total Salary” from employees;
+--------------+
| Total Salary |
+--------------+
| 221000 |
+--------------+
MATHEMATICAL FUNCTION:
Mysql> select e_id,salary*0.5 as “Half Salary” from employees;
+------+-------------+
| e_id | Half Salary |
+------+-------------+
| 1001 | 5000 |
| 1002 | 5500 |
| 1003 | 12500 |
| 1004 | 25000 |
| 1005 | 22500 |
| 1006 | 37500 |
| 1007 | 2500 |
+------+-------------+
Q5) Write about simple join (inner join)? 8 Marks
A5) Simple join
The simplest Join is INNER JOIN. A SQL Join statement joins data or rows from two or more tables together based on a common field.
Based on the join-predicate, the INNER JOIN produces a new result table by integrating column values from two tables (table1 and table2). To identify all pairs of rows that satisfy the join-predicate, the query compares each row of table1 with each row of table2. Column values for each matched pair of rows of A and B are combined into a result row when the join-predicate is satisfied.
The INNER JOIN is the most essential and often used of the joins. An EQUIJOIN is another name for them.
As long as the condition is met, the INNER JOIN keyword selects all rows from both tables. This keyword will generate a result-set by combining all rows from both tables that satisfy the requirement, i.e. the common field's value will be the same.
Syntax
SELECT table1.column1,table1.column2,table2.column1,....
FROM table1
INNER JOIN table2
ON table1.matching_column = table2.matching_column;
Table1: First table.
Table2: Second table
Matching_column: Column common to both the tables.
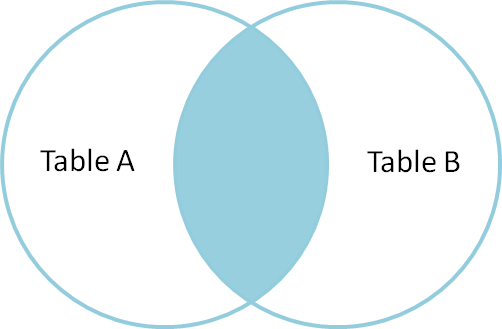
Fig 1: example of INNER join
Example
Table 1 − CUSTOMERS Table is as follows.
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
Table 2 − ORDERS Table is as follows.
+-----+---------------------+-------------+--------+
| OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+
Now, let us join these two tables using the INNER JOIN as follows −
SQL> SELECT ID, NAME, AMOUNT, DATE
FROM CUSTOMERS
INNER JOIN ORDERS
ON CUSTOMERS.ID = ORDERS.CUSTOMER_ID;
This would produce the following result.
+----+----------+--------+---------------------+
| ID | NAME | AMOUNT | DATE |
+----+----------+--------+---------------------+
| 3 | kaushik | 3000 | 2009-10-08 00:00:00 |
| 3 | kaushik | 1500 | 2009-10-08 00:00:00 |
| 2 | Khilan | 1560 | 2009-11-20 00:00:00 |
| 4 | Chaitali | 2060 | 2008-05-20 00:00:00 |
+----+----------+--------+---------------------+
Q6) Describe table aliases? 12 Marks
A6) For the purposes of a SQL query, aliases are the temporary names assigned to a table or column. Table aliases are used to rename a table within a SQL statement. The rename is only a cosmetic modification; the database table name remains unchanged. Column aliases are used to rename columns in a table for the purposes of a SQL query.
It's used when a column or table's name is changed from its original name, but the change is only temporary.
● Aliases are used to make table and column names easier to read.
● The renaming is only a temporary alteration, and the table name in the original database remains unchanged.
● When table or column names are long or difficult to understand, aliases come in handy.
● When a query involves more than one table, these are the best options.
Syntax
The basic syntax of a table alias is as follows.
SELECT column1, column2....
FROM table_name AS alias_name
WHERE [condition];
The basic syntax of a column alias is as follows.
SELECT column_name AS alias_name
FROM table_name
WHERE [condition];
Example
Consider the following two tables.
Table 1 − CUSTOMERS Table is as follows.
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
Table 2 − ORDERS Table is as follows.
+-----+---------------------+-------------+--------+
|OID | DATE | CUSTOMER_ID | AMOUNT |
+-----+---------------------+-------------+--------+
| 102 | 2009-10-08 00:00:00 | 3 | 3000 |
| 100 | 2009-10-08 00:00:00 | 3 | 1500 |
| 101 | 2009-11-20 00:00:00 | 2 | 1560 |
| 103 | 2008-05-20 00:00:00 | 4 | 2060 |
+-----+---------------------+-------------+--------+
Now, the following code block shows the usage of a table alias.
SQL> SELECT C.ID, C.NAME, C.AGE, O.AMOUNT
FROM CUSTOMERS AS C, ORDERS AS O
WHERE C.ID = O.CUSTOMER_ID;
This would produce the following result.
+----+----------+-----+--------+
| ID | NAME | AGE | AMOUNT |
+----+----------+-----+--------+
| 3 | kaushik | 23 | 3000 |
| 3 | kaushik | 23 | 1500 |
| 2 | Khilan | 25 | 1560 |
| 4 | Chaitali | 25 | 2060 |
+----+----------+-----+--------+
Following is the usage of a column alias.
SQL> SELECT ID AS CUSTOMER_ID, NAME AS CUSTOMER_NAME
FROM CUSTOMERS
WHERE SALARY IS NOT NULL;
This would produce the following result.
+-------------+---------------+
| CUSTOMER_ID | CUSTOMER_NAME |
+-------------+---------------+
| 1 | Ramesh |
| 2 | Khilan |
| 3 | kaushik |
| 4 | Chaitali |
| 5 | Hardik |
| 6 | Komal |
| 7 | Muffy |
+-------------+---------------+
Q7) Write short notes on qualified column names? 5 Marks
A7) Qualified column names
It can be difficult to tell which column belongs to which table when a query contains numerous tables, especially if the tables have the same column names. You can use SQL to fully qualify column names by defining the column as a database to assist distinguish between them. Schema.table.column.
The system requires the qualified column name to be in the form of exposed-table-reference when referring to column names in cross-database access. Column-name; where exposed-table-reference is any of the FROM clause's allowed table references.
For example, emp, admin.emp, dev.admin.emp, and dev..emp are all equivalent forms for the same table:
FROM emp WHERE dev.admin.emp.id = 10;
FROM dev.admin.emp WHERE emp.id = 10;
FROM emp WHERE admin.emp.id = 10;
FROM emp WHERE dev.admin.emp.id = 10;
FROM dev…. Emp WHERE admin.id = 10;
Q8) Write about all column selections self joins? 5 Marks
A8) All column selection self join
You can link a table to itself using a self join. It's useful for comparing rows inside the same database or searching hierarchical data.
The inner join or left join clause is used in a self join. Because the self join query refers to the same table, the table alias is used to give the same table multiple aliases within the query.
Syntax –
The syntax for linking table T to itself is as follows:
SELECT
Select_list
FROM
T t1
[INNER | LEFT] JOIN T t2 ON
Join_predicate;
The query makes two references to table T. The table aliases t1 and t2 are used in the query to give the T table distinct names.
Example
● Using self join to query hierarchical data
Take a look at the following table from the example database:

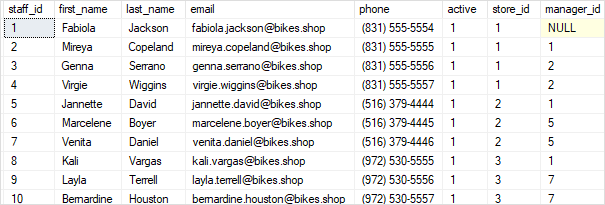
The staff table contains information about the employees, such as their ID, first name, last name, and email address. It also has a manager id column that identifies the direct manager. Mireya, for example, reports to Fabiola because the value of Mireya's manager id is Fabiola.
Because Fabiola does not have a manager, the manager id column is NULL.
You can use the self join to find out who reports to whom, as seen in the following query:
SELECT
e.first_name + ' ' + e.last_name employee,
m.first_name + ' ' + m.last_name manager
FROM
Sales.staffs e
INNER JOIN sales.staffs m ON m.staff_id = e.manager_id
ORDER BY
Manager;
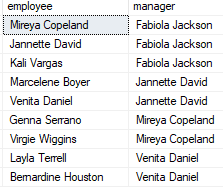
We referred to the staffs table twice in this example, once as e for employees and once as m for managers. Using the data in the e.manager id and m.staff id columns, the join predicate matches employee and manager relationships.
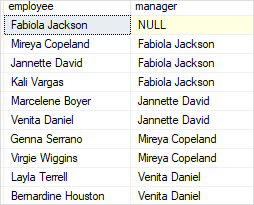
Because of the INNER JOIN effect, Fabiola Jackson does not appear in the employee column. If you substitute the INNER JOIN clause in the above query with the LEFT JOIN clause, you'll obtain the following result set, which includes Fabiola Jackson in the employee column:
SELECT
e.first_name + ' ' + e.last_name employee,
m.first_name + ' ' + m.last_name manager
FROM
Sales.staffs e
LEFT JOIN sales.staffs m ON m.staff_id = e.manager_id
ORDER BY
Manager;
Q9) Write about sub queries? 5 Marks
A9) Sub queries
A subquery, also known as an inner query or nested query, is a query that is placed within another SQL query's WHERE clause.
A subquery is used to return data that will be utilized as a condition in the main query to further limit the data that may be retrieved.
Subqueries can be used with SELECT, INSERT, UPDATE, and DELETE statements, as well as operators such as =, >, >=, =, IN, BETWEEN, and so on.
Subqueries must adhere to a set of guidelines.
● Parentheses must be used to surround subqueries.
● Unless many columns are in the main query for the subquery to compare its selected columns, a subquery can only have one column in the SELECT clause.
● An ORDER BY command cannot be used in a subquery, although it can be used in the main query. In a subquery, the GROUP BY command can accomplish the same function as the ORDER BY command.
● Multiple value operators, such as the IN operator, can only be used with subqueries that return more than one row.
● There can't be any references to values that evaluate to a BLOB, ARRAY, CLOB, or NCLOB in the SELECT list.
● A set function cannot immediately enclose a subquery.
● A subquery cannot be used with the BETWEEN operator. Within the subquery, however, the BETWEEN operator can be utilized.
Q10) Explain subqueries & joins? 5 Marks
A10) The DISTINCT keyword can be used to rewrite a subquery that uses IN, for example:
SELECT * FROM table1 WHERE col1 IN (SELECT col1 FROM table2);
Can be written as
SELECT DISTINCT table1.* FROM table1, table2 WHERE table1.col1=table2.col1;
It's also possible to rewrite NOT IN or NOT EXISTS queries. These two queries, for example, yield the same result:
SELECT * FROM table1 WHERE col1 NOT IN (SELECT col1 FROM table2);
SELECT * FROM table1 WHERE NOT EXISTS (SELECT col1 FROM table2 WHERE table1.col1=table2.col1);
Both of which can be rewritten as:
SELECT table1.* FROM table1 LEFT JOIN table2 ON table1.id=table2.id WHERE table2.id IS NULL;
In some cases, subqueries that can be rebuilt as an LEFT JOIN are more efficient.
Q11) What is nested subqueries? 8 Marks
A11) Subqueries can be nested inside each other. SQL allows you to stack queries inside of each other. A subquery is a SELECT statement that returns intermediate results and is nested within another SELECT statement. The innermost subquery is executed first, followed by the following level. Take a look at the following examples:
Example
If we want to get that unique job id and their average salary from the employees table, we can use the following SQL statement: If we want to get that unique job id and their average salary from the employees table, we can use the following SQL statement: If we want to get that unique job id and their average salary from the employees table, we can use the following SQL statement:
Table : employee
Emp_id first_name last_name email phone_number hire_date job_id salary department_id
----------- ---------- ---------- ---------- ------------ ---------- ---------- ----------
---------
100 Steven King SKING 515.123.4567 6/17/1987 AD_PRES 24000
90
101 Neena Kochhar NKOCHHAR 515.123.4568 6/18/1987 AD_VP 17000 90
102 Lex De Haan LDEHAAN 515.123.4569 6/19/1987 AD_VP 17000
90
103 Alexander Hunold AHUNOLD 590.423.4567 6/20/1987 IT_PROG 9000 60
104 Bruce Ernst BERNST 590.423.4568 6/21/1987 IT_PROG 6000
60
105 David Austin DAUSTIN 590.423.4569 6/22/1987 IT_PROG 4800 60
Table : job
JOB_ID | JOB_TITLE | MIN_SALARY | MAX_SALARY |
AD_PRES | President | 20000 | 40000 |
AD_VP | Administration Vice President | 15000 | 30000 |
AD_ASST | Administration Assistant | 3000 | 6000 |
FI_MGR | Finance Manager | 8200 | 16000 |
FI_ACCOUNT | Accountant | 4200 | 9000 |
AC_MGR | Accounting Manager | 8200 | 16000 |
AC_ACCOUNT | Public Accountant | 4200 | 9000 |
Sql code
SELECT job_id,AVG(salary)
FROM employees
GROUP BY job_id
HAVING AVG(salary)< (SELECT MAX(AVG(min_salary))
FROM jobs WHERE job_id IN (SELECT job_id FROM job_history
WHERE department_id BETWEEN 50 AND 100)
GROUP BY job_id);
Output
JOB_ID AVG(SALARY)
---------- -----------
AC_ACCOUNT 8300
AD_ASST 4400
FI_ACCOUNT 7920
There are three inquiries in this example: a nested subquery, a subquery, and the outer query. These sections of queries are executed in the order listed.
Let's break down the example into three pieces and look at the results.
The nested subquery is constructed as follows:
SELECT job_id FROM job_history
WHERE department_id
BETWEEN 50 AND 100;
Q12) Define correlated subqueries? 5 Marks
A12) Row-by-row processing is done with related subqueries. For each row in the outer query, each subquery is run once.
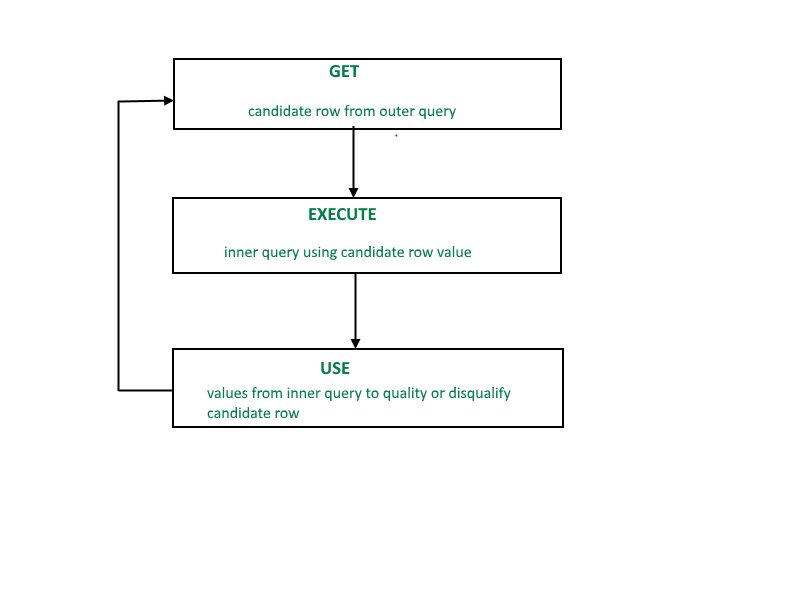
Fig 1: processing
For each row processed by the parent statement, a connected subquery is examined once. A SELECT, UPDATE, or DELETE statement can be the parent statement.
SELECT column1, column2, ....
FROM table1 outer
WHERE column1 operator
(SELECT column1, column2
FROM table2
WHERE expr1 =
Outer.expr2);
A correlated subquery is a method of reading each row of a table and comparing the values in each row to related data. It's utilized when a subquery has to deliver a different result or collection of results for each candidate row that the main query considers. To put it another way, a correlated subquery can be used to answer a multipart question whose response is dependent on the value in each row processed by the parent statement.
Q13) Explain subqueries in the HAVING clause? 8 Marks
A13) Although subqueries are typically used as search criteria in the WHERE clause, they can also be used in the HAVING clause. When a subquery appears in the HAVING clause, it is used as part of the row group selection, just like any other expression in the HAVING clause.
"Which goods' average in-stock quantity is more than double the average number of each item ordered per customer?" is a request that easily lends itself to a query using a subquery in the HAVING clause.
Example
SELECT Name, AVG( Quantity )
FROM Products
GROUP BY Name
HAVING AVG( Quantity ) > 2* (
SELECT AVG( Quantity )
FROM SalesOrderItems
);
Name | AVG(Products.Qunatity) |
Baseball Cap | 62.000000 |
Shorts | 80.000000 |
Tee Shirt | 52.333333 |
The following is how the query works:
● The average quantity of items in the SalesOrderItems table is calculated by the subquery.
● The primary query then traverses the Products dataset, determining the average quantity per product and grouping by product name.
● The HAVING clause then checks if each average quantity is greater than twice the subquery's result. If this is the case, the main query will return that row group; otherwise, it will not.
● The SELECT clause generates one summary row for each group, indicating the name of each product as well as the average quantity of that product in stock.
Outer references can also be used in a HAVING clause, as seen in the example below, which is a small variant on the one above.
Example 2
This example identifies the product ID numbers and line ID numbers of products whose average ordered quantities are greater than half of their in-stock amounts.
SELECT ProductID, LineID
FROM SalesOrderItems
GROUP BY ProductID, LineID
HAVING 2* AVG( Quantity ) > (
SELECT Quantity
FROM Products
WHERE Products.ID = SalesOrderItems.ProductID );
ProductID | LineID |
601 | 3 |
601 | 2 |
601 | 1 |
600 | 2 |
…….. | ……. |
In this case, the subquery must return the in-stock quantity of the product that corresponds to the HAVING clause's row group. Using the outer reference SalesOrderItems.ProductID, the subquery retrieves records for that specific product.
Q14) Describe Simple Transaction illustrating COMMIT, and ROLLBACK? 12 Marks
A14) A transaction is a logical unit of work performed on a database. Transactions are logically ordered units or sequences of work that can be completed manually by a human or automatically by a database application.
The propagation of one or more changes to the database is referred to as a transaction. For instance, whether you create, update, or delete a record from a table, you are completing a transaction on that table. To preserve data integrity and address database issues, it's critical to keep track of these transactions.
In practice, you'll group several SQL queries together and run them all at the same time as part of a transaction.
COMMIT
The transactional command COMMIT is used to save changes made by a transaction to the database.
The transactional command COMMIT is used to save changes made by a transaction to the database. Since the last COMMIT or ROLLBACK command, the COMMIT command saves all transactions to the database.
The COMMIT command has the following syntax.
COMMIT;
Example
Consider the following records in the CUSTOMERS table:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The example below will delete all records in the table with an age of 25 and then COMMIT the changes to the database.
SQL> DELETE FROM CUSTOMERS
WHERE AGE = 25;
SQL> COMMIT;
As a result, two rows from the table are removed, and the SELECT command yields the following result.
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
ROLLBACK
The transactional command ROLLBACK is used to undo transactions that have not yet been recorded to the database. This command can only be used to reverse transactions that have occurred since the last COMMIT or ROLLBACK command.
The ROLLBACK command has the following syntax:
ROLLBACK;
Example
Consider the following records in the CUSTOMERS table:
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+
The following is an example that would delete all records in the table with the age of 25 and then ROLLBACK the database modifications.
SQL> DELETE FROM CUSTOMERS
WHERE AGE = 25;
SQL> ROLLBACK;
As a result, the delete action has no effect on the table, and the SELECT command yields the following result.
+----+----------+-----+-----------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+-----------+----------+
| 1 | Ramesh | 32 | Ahmedabad | 2000.00 |
| 2 | Khilan | 25 | Delhi | 1500.00 |
| 3 | kaushik | 23 | Kota | 2000.00 |
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 6 | Komal | 22 | MP | 4500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+-----------+----------+




