UNIT III
Measurement
Question Bank
Q1) Define Measurement.
A1) The process of observing and recording the observations collected as part of a research activity is known as Measurement. There are two main issues to consider here.
First, you need to understand the basic ideas associated with measurement. Here we consider two main measurement concepts. Scales explain the meaning of the four main scales (name, order, spacing, ratio). Next, we move on to the reliability of the measurements, such as the true score theory and the examination of various reliability estimates.
Second, we need to understand the different types of measures that may be used in social research. Consider four broad categories of measurements. Research studies include the design and implementation of interviews and questionnaires. Scaling involves exploring key ways to develop and implement scales. Qualitative research provides a broad overview of non-numerical measurement approaches. Inconspicuous measurements also offer a variety of measurement methods that do not interfere with or interfere with the context of the study.
Before you can use statistics to analyze your problem, you need to convert the basic material in question into data. This means that you need to establish or adopt a system that assigns values (mostly numbers) to the object or concept that is central to the problem you are investigating. This is not an esoteric process, but it's something you are doing a day. For example, if you buy something in a store, the price you pay is a measure. That is, a number is assigned to the amount of currency exchanged for the goods received. Similarly, once you tread on the size within the morning, the numbers you see are measurements of your weight. Depending on where you live, this number is expressed in pounds or kilograms, but the principle of assigning numbers to physical quantities (weight) applies in both cases.
Not all data need to be numeric. For example, the male and female categories are commonly used to classify people in both science and everyday life, and these categories have essentially no numbers. Similarly, we often talk about the colors of a wide class of objects such as "red" and "blue". These categories represent a great simplification from the infinite variety of colors that exist in the world. This is a very common method and is rarely reconsidered.
How specific you want these categories to be (for example, is "garnet" a different color than "red"? Do you need to assign transgender individuals to different categories?) Is your immediate goal. Depends on. Graphic artists can use even more colors. For example, a spiritual category of color than the average person. Similarly, the level of detail used to classify a survey depends on the purpose of the survey and the importance of understanding the nuances of each variable.
Q2) What are the are three main types of study design?
A2) There are three main types of study design:
Data Collection, Measurement and Analysis.
The type of research problem your organization faces determines your research design, but not the other way around. During the design phase of the survey, you decide which tools to use and how to use them.
Influential study designs usually minimize data bias and increase confidence in the accuracy of the collected data. Designs with minimal margin of error in experimental studies are generally considered desirable results. The key elements of study design are:
1. Exact purpose statement,
2. Techniques implemented to collect and analyze surveys,
3. Methods applied to the analysis of the collected details,
4. Types of survey methods,
5. Possible objections to research,
6. Research setting,
7. Timeline,
8. Measurement of analysis.
Proper research design will lead your research to success. Successful research studies provide accurate and unbiased insights. You need to create a survey that meets all the key characteristics of your design.
Q3) Suggest some different types of study design in order to choose the model to implement in their study.
A3) Researchers need a clear understanding of the different types of study design in order to choose the model to implement in their study. As with the study itself, study design can be broadly categorized quantitatively and qualitatively.
Qualitative research determines the relationship between collected data and observations based on mathematical calculations. Theories related to naturally occurring phenomena can be proved or disproved using statistical methods. Researchers believe qualitative research design techniques to conclude "why" a specific theory exists and what respondents must say about it.
2. Quantitative Research Design:
Quantitative research is used when statistical conclusions are essential to gather practical insights. The numbers provide a better perspective for making important business decisions. Quantitative research design techniques are required for organizational growth. The insights gained from solid numerical data and analysis have proven to be very effective in making decisions related to the future of the business.
Q4) What are the types of research design?
A4) You can further categorize the types of research design into five categories:
1. Descriptive Study Design: Researchers are only interested in describing situations or cases within a study with a descriptive design. This is a theory-based design method developed by collecting, analyzing, and presenting the collected data. This allows researchers to provide insights into the reasons and methods of study. Descriptive design helps others better understand their research requirements. If the problem description is not clear, you can perform an exploratory investigation.
2. Experimental Study Design: The relationship between the cause and effect of the situation is established by the experimental study design. This is a causal model that observes the effect of the independent variable on the dependent variable. For example, the impact of independent variables such as price on dependent variables such as customer satisfaction and brand loyalty is monitored. It is a very practical research design method to contribute to the solution of the problem at hand. The independent variable is manipulated to monitor the shift to the dependent variable.
In the social sciences, it is often used to analyze two groups and observe human behavior. To better understand social psychology, researchers can force participants to change their behavior and study how the individuals around them react.
3. Correlation Study Design: Correlation study is a non-experimental study design technique that helps researchers establish relationships between two closely related variables. Two different groups need this type of research. When evaluating the relationships between two different variables, there are no assumptions and the relationships between them are calculated by statistical analysis techniques.
The correlation between two variables whose values vary between -1 and +1 is determined by the correlation coefficient. A correlation coefficient of +1 indicates a positive relationship between variables, and -1 means a negative relationship between two variables.
4. Diagnostic Study Design: Researchers are trying to assess the root cause of a particular subject or phenomenon in a diagnostic design. This technique helps you learn more about the variables that create the problematic situation.
This design has three parts of research.
a) Problem occurrence.
b) Diagnosis of problems.
c) Solution to the problem.
5. Descriptive Study Design: Descriptive design explores their theory further, using the ideas and ideas of researchers on a topic. This survey details the unexplored aspects of the topic and what, how, and why the survey questions are asked.
Q5) What is Uni-Dimensional and Multi-Dimensional Scales?
A5) Scaling is a field of measurement that involves building equipment that associates qualitative configurations with quantitative metric units. Scaling evolved from psychological and educational efforts to measure "immeasurable" constructs such as authoritarianism and self-esteem. In many respects, scaling remains one of the most esoteric and misunderstood aspects of social research measurements. Then we try to measure abstract concepts, which is one of the most difficult research tasks.
Most people don't even understand what scaling is. The basic idea of scaling is explained in the general problem of scaling, including the important difference between scale and response format. Scales generally fall into two major categories: one-dimensional and multidimensional. The one-dimensional scaling method was developed in the first half of the 20th century and is generally named after the inventor. This section describes the following three types of one-dimensional scaling methods.
a) Thurstone or evenly spaced scaling.
b) Likert or "summary" scaling.
c) Guttman or "cumulative" scaling.
From the late 1950s to the early 1960s, measurement theorists developed more advanced techniques for creating multidimensional scales. These techniques are not considered here, but to see the power of these multivariate techniques, it is advisable to consider a concept mapping technique that relies on that approach.
Q6) What are the General Scaling Issues?
A6) S.S. Stevens came up with what I think is the simplest and simplest definition of scaling. He said:
Scaling is the assignment of objects to numbers according to rules.
But what does that mean? In most scaling, the object is a text statement, usually a statement of attitude or belief. An example is shown in the figure.
There are three statements that explain the attitude towards immigrants. To scale these statements, you need to assign them a number. In general, the result should be at least an interval scale (see Scale), as shown by the ruler in the figure. And what does it mean to "follow the rules"? The statement shows that as you read, your attitude towards immigrants becomes more restrictive. Anyone who agrees with the statements on the list may also agree with all the statements above. list. In this case, the "rules" are cumulative. So what is scaling? This is a way to get a number that can be meaningfully assigned to an object. This is a series of steps. Here are some different approaches:
But first, I need to get rid of one of my pet's pee. People often confuse the idea of scale with response scale. Response scales are a way of collecting responses from people on musical instruments. You may use a dichotomized response scale such as agree / disagree, true / false, or yes / no. Alternatively, you can use an interval response scale such as a 1: 5 or 1: 7 rating. However, if you just attach a response scale to an object or statement, you cannot call that scale. As you can see, scaling involves steps that are independent of the respondent so that you can come up with a number for the object. In true scaling studies, scaling procedures are used to develop equipment (scales) and response scales are used to collect responses from participants.
Q7) What is the Purpose of Scaling?
A7) Why do you scale? Would you like to create a text statement or question and use the answer format to collect your answers? First, you may want to scale to test your hypothesis. You may want to know if a structure or concept is one-dimensional or multidimensional (we'll talk more about dimensions later). Scaling may also be done as part of exploratory research. I want to know the dimensions that underlie a series of evaluations. For example, when creating a series of questions, you can use scaling to determine how "hanging together" the questions are, whether to measure one concept or multiple concepts. But perhaps the most common reason for scaling is for scoring purposes. When a participant answers a set of items, they often want to assign a single number that represents their overall attitude or belief. In the figure above, for example, I would like to show one number that represents an individual's attitude towards immigrants.
Q8) Explain the Curse of Dimensionality.
A8) The scale can contain any number of dimensions. Most scales we develop have only a few dimensions. What is a dimension? Think of the dimensions as a number line. When measuring a construct, you need to determine if you can measure the construct properly with a single number line, or if you need more lines.
For example, height is a one-dimensional or one-dimensional concept. The concept of height can be measured very well with just one number line (such as a ruler). Weight is also one-dimensional-we can measure it on a scale. Thirst can also be considered a one-dimensional concept-you are always more or less thirsty. It's easy to see that height and weight are one-dimensional. But what about concepts like self-esteem? If you think you can measure a person's self-esteem well with a single ruler that changes from low to high, you probably have a one-dimensional structure.
Q9) What is the two-dimensional concept?
A9) Many models of intelligence or achievement presuppose two main aspects: mathematical and linguistic competence. In this type of 2D model, one can say that one has two types of achievements. Some people will have high language skills and low math. For others, the opposite is true. However, if the concept is really two-dimensional, it is not possible to use just one number line to represent the level of that conceptual person. In other words, we need to find a person as a point in two-dimensional (x, y) space to explain the achievement.
Let's take this one step further. What about the 3D concept? Psychologists studying the concept of meaning have theorized that the meaning of a term can be fully explained in three dimensions. In other words, any object can be distinguished or distinguished from each other in three dimensions. They have labelled these three dimensions of activity, assessment, and potency. They called this general semantics a semantic differential. Their theory states that essentially any object can be evaluated along these three dimensions. For example, consider the idea of "ballet". If you like ballet, you will probably rate it as active, high in evaluation, advantageous in evaluation, and powerful in potency. On the other hand, think of the concept of a "book" like a novel. You may rate it as inactive (passive), positively rated (assuming you like it), and nearly average potency. Now, believe the thought of "going to the dentist". Most people rate low activity (passive activity), poor evaluation, and powerlessness (there are few daily activities that feel powerless!). The theorists who came up with the idea of semantic differentials thought that by evaluating a concept in these three dimensions, the meaning of any concept could be well explained. In other words, to explain the meaning of an object, you need to place it as a dot somewhere in the cube (three-dimensional space).
Q10) Define measurement scales.
A10) To perform a statistical analysis of your data, it is important to first understand the variables and what you need to measure with them. There are various scales of statistics, and the data measured using them can be broadly divided into qualitative data and quantitative data.
First, let's understand what variables are. Values change throughout the population and the measurable quantities are called variables. For example, consider a sample of individuals employed. Variables in this population set include industry, location, gender, age, skills, and occupation. The value of the variable varies from employee to employee.
For example, it is virtually impossible to calculate the average hourly wage of US workers. Therefore, the sample audience is randomly selected to better represent a larger population. The average hourly wage for this sample audience is then calculated. Statistical tests can be used to conclude the average hourly wage of a larger population.
The variable scale determines the type of statistical test to use. The mathematical nature of a variable, that is, how it is measured, is considered a measure.
Q11) Explain the levels of Nominal Scale.
A11) The details of the four scales in surveys and statistics are nominal, order, interval, and ratio.
Nominal Scale: 1st Level Scale
Nominal scales, also known as categorical variable scales, are defined as scales used to label variables into individual classifications and do not include quantitative values or order. This scale is the simplest of the four variable measurement scales. The calculations done on these variables are wasted because there are no optional numbers.
This scale may be used for classification purposes. The numbers associated with variables of this scale are just classification or division tags. The calculations performed on these numbers are useless because they have no quantitative significance.
For questions such as:
Where do you live?
1-Suburbs
2-City
3-Town
Nominal scales are often used in surveys and surveys where only variable labels are important.
For example, there is a customer survey that asks, "Which brand of smartphone do you like?" Options: "Apple"-1, "Samsung" -2, "OnePlus" -3.
In this survey question, only the brand name is important to researchers conducting consumer surveys. You don't need to order any of these brands. However, while acquiring nominal data, researchers base their analysis on relevant labels.
In the example above, if survey respondents select Apple as their preferred brand, the input and associated data will be "1". This helped us quantify and answer the last question (the number of respondents who chose Apple, the number of Samsung, the number of OnePlus), and which one was the highest.
This is the basis of quantitative research, and the nominal scale is the most basic research scale.
Nominal Scale example
a) Political preference
b) living place
c) Nominal scale SPSS
SPSS allows you to specify a scale as a scale (numerical data for intervals or ratio scales), order, or name. Nominal and ordinal data are either alphanumeric or numeric strings.
When you import variable data into an SPSS input file, it is used as a scale variable by default because the data basically contains numbers. It is important to change the name or order, or keep it as a scale, depending on the variables that the data represents.
Order scale: 2nd level scale
The order scale is defined as a variable measure scale used to simply represent the order of variables, not the difference between each variable. These scales are commonly used to represent non-mathematical ideas such as frequency, satisfaction, well-being, and degree of pain. The "ordinal" is similar to the "order", so it's very easy to remember the implementation of this scale. This is exactly the purpose of this scale.
An ordinal scale maintains description quality with a unique order, but the distance between variables cannot be calculated because there is no scale origin. Description Quality indicates tagging properties similar to the nominal scale. In addition, the ordinal scale also has relative positions for variables. There is no fixed start or "true zero" because the origin of this scale does not exist.
Interval Scale: 3rd Level Scale
The interval scale is defined as a numeric scale that knows the order of the variables and the differences between them. Variables with familiar, constant, and computable differences are categorized using the interval scale. You can easily remember the main role of this scale. "Interval" indicates "distance between two entities". This is what the interval scale helps to achieve.
These scales are effective because they open the door to statistical analysis of the data provided. You can use the mean, median, or mode to calculate the central tendency of this scale. The only drawback of this scale is that there is no pre-determined starting point or true zero value.
Ratio Scale: 4th Level Scale
The ratio scale is defined as a variable measure scale that not only produces the order of variables, but also knows the differences between variables along side information about truth value of zero. this is often calculated assuming that the variable has zero options, the difference between the 2 variables is that the same, and there's a selected order between the choices.
The true zero option allows you to use a spread of inference and descriptive analysis techniques to variables. Ratio scales also can establish values for temperature, additionally to the very fact that nominal scales, ordinal scales, and interval scales do everything they will. the simplest samples of ratio scales are weight and height. marketing research uses ratio scales to calculate market share, annual sales, prices for next products, number of consumers, and more.
The ratio scale provides the foremost detailed information because researchers and statisticians can calculate central tendency using statistical methods like mean, median, and mode. Methods like mean, coefficient of variation, and mean also are available on this scale.
The ratio scale corresponds to the characteristics of the opposite three variable measurement scales. That is, the labelling of variables, the importance of the order of variables, and therefore the computable differences between variables (usually equidistant).
There are not any negative values within the ratio scale because there's a real zero value.
To decide when to use the ratio scale, researchers got to observe whether the variable has all the characteristics of the interval scale with the presence of temperature.
The mean, mode, and median are often calculated using the ratio scale.
Q12) What is Sequence data and analysis?
A12) Sequential scale data can be displayed in tabular or graphical format for convenient analysis of the data collected by researchers. You can also analyze ordinal data using methods such as the Mann-Whitney U test and the Kruskal-Wallis H test. These methods are usually implemented to compare two or more ordinal groups.
The Mann-Whitney U test allows researchers to conclude which variable in a group is greater or lesser than another in a randomly selected group. The Clascal Wallis H test allows researchers to analyze whether the median of two or more ordered groups is the same.
Q13) Give an Ordinal scale example.
A13) Workplace status, tournament team rankings, product quality order, consent or satisfaction order are some of the most common examples of ordering scales. These scales are commonly used in market research to collect and evaluate relative feedback on product satisfaction, perceived changes due to product upgrades, and more.
For example, the following semantic differential scale question:
How satisfied are you with our service?
Very dissatisfied – 1
Dissatisfaction – 2
Neutral – 3
Satisfaction – 4
Very satisfied – 5
The order of the variables is of utmost importance here, and labeling is also important. Very dissatisfied will always be worse than dissatisfaction, and satisfaction will be much worse than satisfaction.
This is when the ordinal scale is one step above the nominal scale. The order is related to the result, and so is the name.
Analyzing results based on order and name is a convenient process for researchers.
If you want to get more information than you collect using the nominal scale, you can use the ordinal scale.
This scale not only assigns values to variables, but also measures the rank or order of variables, such as:
a) Grades
b) Satisfaction
c) happiness
How satisfied are you with our service?
1-Very dissatisfied
2-Dissatisfaction
3-Neural
4-Satisfaction
5-Very satisfied
Q14) Define Interval Data and analysis with example.
A14) All techniques applicable to nominal and sequential data analysis can also be applied to interval data. Apart from these methods, there are several analytical methods, such as descriptive statistics and correlated regression analysis, which is widely used to analyze interval data.
Descriptive statistics is a term given to the analysis of numerical data that helps describe, depict, or summarize data in a meaningful way and helps calculate mean, median, and mode.
Interval scale example
There are situations where the attitude scale is considered the interval scale.
Apart from the temperature scale, time is also a very common example of the interval scale because the values are already established, constant and measurable.
Calendar years and times also fall into this category of measurement scales.
Likert scales, Net Promoter scores, Semantic differential scales, and bipolar matrix tables are examples of the most commonly used interval scales.
The following questions comes in the interval scale category.
a) How Much Does Your Family Make?
b) What is the temperature in your city?
Q15) Define Ratio Data and Analysis.
A15) At a basic level, ratio scale data is quantitative in nature, so you'll use all quantitative chemical analysis techniques like SWOT, TURF, crosstab, and conjoint to calculate ratio data. Some techniques, like SWOT and TURF, analyze ratio data in order that researchers can create a roadmap of the way to improve their products and services, but crosstabs are cross-tabulations to ascertain if new features help the target market. Helps you understand.
Example of ratio scale
The following questions fall under the category of ratio scales.
How tall is your daughter now?
Less than 5 feet.
5 feet 1 inch – 5 feet 5 inches
5ft 6inch-6ft
6 feet or more
What is your weight in kilograms?
Less than 50 kilograms
51-70 kg
71-90 kg
91-110 kg
110 kg or more
Summary – Level of measurement
The four data measures of nominal, order, interval, and ratio are often discussed in academic education. The subsequent easy-to-remember graphs are often useful for statistical testing.
Q16) What is Rating Scale?
A16) Rating scales are defined as closed-end survey questions used to represent respondent feedback in a specific feature / product / service comparison format. This is one of the most established question types in online and offline surveys where survey respondents are expected to evaluate attributes or features. A rating scale is a variant of a popular multiple-choice question that is widely used to collect information that provides relative information on a particular topic.
Researchers use evaluation scales in their studies once they shall associate qualitative scales with different aspects of a product or function. This scale is commonly used to evaluate product or service performance, employee skills, customer service performance, processes performed for specific goals, and more. Evaluation scale survey questions can be compared to checkbox questions, but evaluation scales provide more information than just information.
The interval scale contains all the properties of the ordinal scale, plus provides a calculation of the differences between the variables. The main feature of this scale is that the equidistant difference between objects.
For example, consider a Celsius / Fahrenheit temperature scale –
80 degrees is usually above 50 degrees, and therefore the difference between these two temperatures is that the same because the difference between 70 degrees and 40 degrees.
Also, the value 0 is arbitrary because there are negative values for temperature. This makes the Celsius / Fahrenheit temperature scale a classic example of an interval scale.
Interval scales are often chosen in study cases where differences between variables are essential. This cannot be achieved using the nominal or ordinal scale. The interval scale quantifies the difference between two variables, while the other two scales can only associate qualitative values with variables.
Unlike the previous two scales, you can evaluate the mean and median of the ordinal scale.
Interval scales are often used in statistics because you can not only assign numbers to variables, but also calculate based on those values.
Even if the interval scale is amazing, the "true zero" value is not calculated, so the next scale comes up.
Q17) What are the Evaluation Scale Type?
A17) Broadly speaking, evaluation scales can be divided into two categories: ordinal scales and interval scales.
The ordinal scale is a scale that represents answer options in an ordered manner. The difference between the two answer options may not be calculable, but the answer options are always in a particular unique order. Parameters such as attitude and feedback can be presented using the ordinal scale.
The interval scale is a scale that not only establishes the order of the answer variables, but also calculates the magnitude of the difference between each answer variable. Absolute or true zero values do not exist on the interval scale. Celsius or Fahrenheit temperatures are the most common example of an interval scale. The Net Promoter Score, Likert Scale, and Bipolar Matrix Table are some of the most effective types of interval scales.
There are four main types of valuation scales that can be used appropriately in online surveys.
a) Graphic evaluation scale.
b) Numerical evaluation scale.
c) Descriptive evaluation scale.
d) Comparative evaluation scale
Graphic Rating Scale: The Graphic Rating Scale indicates answer options on a scale such as 1-3, 1-5, and so on. The Likert scale is an example of a common graphic evaluation scale. Respondents can select specific options with lines or scales to represent their rating. This valuation scale is often implemented by HR managers to evaluate employees.
Numerical Evaluation Scale: The numerical evaluation scale has numbers as answer options, and each number does not correspond to a characteristic or meaning. For example, a visual analogue scale or a semantic differential scale can be presented using a numerical evaluation scale.
Descriptive Rating Scale: The Descriptive Rating Scale explains each response option in detail to respondents. Numerical values are not always associated with descriptive rating scale response options. There is a specific survey. For example, a customer satisfaction survey should elaborate on all response options so that all customers can be thoroughly informed about what they expect from the survey.
Comparative Rating Scale: As the name implies, the Comparative Rating Scale is based on the respondent's point of view of comparison, that is, based on relative measurements or holding other organizations / products / features as a reference. Expect to answer specific questions.
Q18) What are the Ranking Pros and Cons?
A18) The weakness of the ranking scale is also its strength. Consumers need to focus on one item over another. However, there may be more than one item that consumers rate equally. Ranking does not disclose that information.
Ranking is a great way to ask a question if you are trying to decide how to compare specific products to each other. In addition to measuring the satisfaction a consumer has with a single item, rankings can be used to see together the unique value of several different items.
Do you remember the soda brand example? Many well-known soda brands have continuously rebranded millions of brands at the expense of sales and public opinion.
These mistakes can be avoided. Polling a consumer-based audience using surveys can have a dramatic impact on new product rollout (or rollout potential). For example, suppose your soda company wants to introduce some new flavours. Once you have completed the evaluation survey to determine which flavours are most preferred, the ranking survey will help you find the best order to release new flavours.
“Rank these three flavours from the ones you like the most to the ones you dislike most.” We already know that flavours are preferred, so we'll start with the flavors we release first, or the flavours we release first, from the ranks we like. Find out the most effective flavours.
In some cases, ranking or comparison questions reduce cross-cultural survey responses and language bias. This could be especially It helps different consumers across the country and in different regions decide how to receive their products.
However, the ranking scale has its own set of problems. Respondents are mentally burdened if there are too many categories. I can't answer the question or the ranking isn't clearly considered.
Q19) How to get the most out of your research?
A19) When it comes to R & D, top companies show that consumer feedback is one of the most important factors in getting the most out of your budget and products.
Q20) How do you create a survey that gives you quick and useful insights?
A20) The answer is the question. You can get incredible consumer feedback in minutes by combining different types of questions and retargeting questions that require more detailed data.
Customize your question
Suzy ™ makes it easy to create both rating and ranking questions using multiple-choice options. You can also add free-form questions to your survey to gain more insight into respondents and members.
When you're ready to rebrand your package, use the rating scale to ask members to provide feedback on the proposed package. Or, even better, offer some options and ask you to choose the top three or four.
The Suzy ™ platform gives you room to customize your questions and get better answers from your members. You can randomize the answer choices so that members are unaffected by the order, or allow users to select multiple options to view partial rankings for multiple items.
Q21) Define Thurstone Scale.
A21) The Thurstone scale is defined as a one-dimensional scale used to track a respondent's behavior, attitude, or emotion towards a subject. This scale consists of statements about a particular question or topic, and each statement has a number that indicates that the respondent's attitude towards the topic is positive or unfavourable. Respondents indicate a statement they agree and the average is calculated. The average consent or disagreement score is calculated as the respondent's attitude towards the topic.
This scale was developed by Robert Thurstone to estimate measurements at interval levels that look similar. Although the Thurstone scale is built on the basis of the Likert scale, this method of building an attitude scale not only considers the value of each item when assessing the final attitude score, but is also a neutral item. It also corresponds to. The Guttman and Bogardas social distance scales are also variations of the one-dimensional scale that allow you to sort elements hierarchically.
While talking about the Thurstone scale question, there are three scales, but this scale is also known as the equal occurrence interval scale because the most commonly used method is equal occurrence intervals. The other two are a bit more complicated to develop, but still have the same consent / disagreement quiz question type. They are the continuous interval method and the paired comparison method.
Q22) How to perform a Thurston scale survey using an example?
A22) An example of a Thurstone scale survey is understanding the attitudes of employees within an organization towards diversity recruitment within the organization. The Thurstone Scale question has two distinct milestones. Derive the final question, manage the Thurstone scale question, and perform its analysis.
Derive the last question
There are five distinctive steps to deriving the final question. they are:
Step 1-Create a statement: Create a number of consent / disagreement statements on a particular topic. For example, if you want to know people's attitudes towards diversity adoption policies in your organization, you can use a statement like this:
a) The policy on diversity recruitment is wrong.
b) Recruiting diversity robs the right candidates of work.
c) Adopting diversity gives the team different perspectives.
d) The adoption of diversity brings out the best in the community.
e) Adopting diversity helps to enhance the brand's reputation.
Step 2-Rank each statement by the jury: The next step is to have the jury evaluate each item on a scale of 1 to 11. Here, 1 is the most unfavorable attitude towards the common vector – adoption of diversity and 11 is a very positive attitude. It is important to note that the judges must evaluate each option and do not agree or disagree with them.
Step 3 – Calculate Median and / or Interquartile Range (IQR): Then analyze the data collected from all judges and tabulate the mean or median in ascending order. To do. Using the median or average is a personal choice, and the options give accurate results no matter which one you use. If you have 50 statements, you need an average / median of 50 and an IQR of 50.
Step 4 – Sort Tables: The data should be sorted based on the minimum to maximum median / mean, and the IQR for each median / mean should be in descending order. This can be expressed as:
Statement | Median or Mean | IQR |
43 | 1 | 1.25 |
21 | 1 | 1 |
16 | 1.5 | 1 |
3 | 3 | 2 |
6 | 5 | 2 |
28 | 6 | 1 |
37 | 7 | 3 |
9 | 7.5 | 1.5 |
18 | 9 | 2 |
26 | 11 | 2 |
Step 5 – Final Variable or Option Selection: Select an option based on the table above. For example, you can select one item from each mean / median. You want the most consensus statement among the judges. For each median, this is the item with the lowest interquartile range. This is a "rule of thumb". You do not need to select this item. If you determine that the wording is inadequate or ambiguous, select the item above it (IQR is next lowest).
Management and analysis of Thurstone scale questions
Once the final questions are determined, they are shared with the respondents and they choose to agree or disagree. Ratings are shown in parentheses but are not shared with the actual respondents.
Median or average management and analysis: Questions and subsequent options can be managed by respondents using either the median or median in the following formats: The statement weights are summed and divided by the number of checked statements. If the respondent agrees with statements 2, 5, 7, and 10. The attitude score is 10.5 + 2.5 + 4.5 + 6.0 = 23.5 / 4 = 5.8. Dividing the number of statements, this score is just above the midpoint on the scale of 1-11. This score shows a slight advantage in attitudes towards diversity recruitment within the organization.

Simple Count or Percentage Management and Analysis: In the same example above, if the question is managed without an average or median score, the calculation can be expressed as a simple score. The number of agreements on a scale or percentage from 1 to 11. If the respondent agrees with statements 1, 4, 5, 6, 8, 9, and 11. The number of contracts is 7 out of 11, which is 63.63%, which means that the attitude toward diversity recruitment is good.
Features of Thurstone Scale Questions
Some of the distinctive features of the Thurstone scale question are:
They are divided into two stages: Thurstone scale questions will not be asked in the first iteration without a judge's evaluation. This is an important feature of this question, as the options that respondents see are weighted and there is consensus that they are included in the survey.
The mean or median is always calculated: Each option is weighted, so the mean or median is calculated for each option. This is also the basis for the selection method for use in the final survey.
Consent or disagree options only: Respondents make choices only based on their consent or disagreement with the statement.
Q23) What is Use of Thurston Scale Survey?
A23) Thurstone scale surveys are used to measure respondents' attitudes towards a particular subject. This scale can be applied to a wide range of market research, including:
a) Opinion-Measuring Surveys: Thurstone-scale questions generate quantifiable data about measuring the strength of opinions of respondents.
b) Measures of attitudes and emotions: This scale is effectively used for customer satisfaction to predict future buying trends and employee involvement in calculating sales.
Q24) What is the Likert Scale?
A24) Definition: The Likert scale is a one-dimensional scale used by researchers to collect the attitudes and opinions of respondents. Researchers often use this psychometric scale to understand their views and perspectives on a brand, product, or target market.
The various variations of the Likert scale focus directly on measuring people's opinions, such as the Guttman scale, the Bogardas scale, and the Thurstone scale. Psychologist Rensis Likert has established a distinction between scales that materialize from a collection of responses to groups of items (perhaps eight or more). The response is measured in the range of values.
Likert scale example:
For example, to collect product feedback, researchers use Likert-scale questions in the form of dichotomized optional questions. He / she assembled the question "The product was a good purchase" and the options are listed as for or against. Another way to assemble this question is "state your satisfaction with the product" and you have a choice from very dissatisfied to very satisfied.
When responding to Likert scale items, the user responds explicitly based on the level of consent or disagreement. These measures allow you to determine the level of approval or disapproval of respondents. The Likert scale assumes that the intensity and intensity of experience is linear. Therefore, assuming that attitudes can be measured, it goes from a perfect match to a perfect mismatch.
Q25) Explain the Likert scale types and examples.
A25) Likert scales are popular among researchers for gathering opinions about customer satisfaction and employee experience. This scale can be divided into two main types.
a) Even the Likert scale.
b) Odd Likert Scale.
Even the Likert scale
Researchers use the Likert scale to collect extreme feedback without offering a neutral option.
4-Point Likert Scale for Importance: This type of Likert Scale allows researchers to include four extreme options without a neutral choice. Here, the various importance is represented by a 4-point Likert scale.
Recommended 8-point possibilities: This is a variation of the 4-point Likert scale described earlier. The only difference is that this scale has eight options for collecting feedback on possible recommendations.
Odd Likert Scale
Researchers use a strange Likert scale to give respondents the option to answer neutrally.
a) 5-Point Likert Scale: Using 5 Answer Options, researchers can use this strange Likert Scale question to choose a neutral answer option that respondents can choose if they do not want to answer from extreme options Gather information about the topic by including.
b) 7-Point Likert Scale: The 7-Point Likert Scale adds two more answer options at both ends of the 5-Point Likert Scale question.
c) 9-Point Likert Scale: The 9-point Likert Scale is very rare, but can be used by adding two more answer options to the 7-Point Likert Scale question.
Q26) What are the Features of Likert scale?
A26) The Likert scale was born in 1932 in the form of a five-point scale and is now widely used. These measures range from a group of general topics to the most specific topics that ask respondents to indicate their level of consent, approval, or belief. Some important features of the Likert scale are:
a) Relevant Answer: The item should be easily related to the sentence answer, regardless of whether the item-sentence relationship is clear.
b) Scale type: The item always requires two extremum positions and an intermediate answer option that acts as a tick mark between the extremums.
c) Number of answer options: The most common Likert scale is a five-item scale, but using more items will help improve the accuracy of the results.
d) Increased scale reliability: Researchers often increase the edges of the scale to create a 7-point scale by adding "very" to the top and bottom of the 5-point scale. The 7-point scale reaches the upper limit of scale reliability.
e) Use of a wide scale: As a general rule, it is recommended to use the widest possible scale, such as Likert. If desired, you can always group your answers into a concise group for analysis.
f) Lack of Neutral Options: By considering these details, the scale is reduced to even categories (usually 4) to eliminate the possibility of "neutral" on the "forced selection" survey scale.
g) Inherent Variables: The primary Likert record clearly indicates that there may be an indigenous variable whose value indicates the feedback or attitude of the respondent. The underlying variable is, at best, the interval level.
Q27) Classify Likert Scale Data and Analysis.
A27) Researchers use surveys on a regular basis to measure and analyze the quality of a product or service. The Likert scale is a standard form of classification for research. Respondents gave their opinions (data) on the quality of products / services from the highest to the highest using 2, 4, 5, or 7 levels can be low, or good or bad.
Researchers and auditors typically group the collected data into a hierarchy of four basic measurement levels (nominal, order, interval, and ratio measurement levels) for further analysis.
Nominal data: The data in which the variable-classified answers do not necessarily have quantitative data or order is called nominal data.
Order data: Data that allows you to sort and classify answers, but cannot measure distance, is called order data.
Interval data: Aggregate data that can measure order and distance is called interval data.
Ratio data: Ratio data is analogous to interval data. The only difference is the equally decisive ratio between each data and the absolute "zero" treated as the origin.
Q28) What are the various application of Data Analysis?
A28) Data analysis using nominal, interval, and ratio data is generally transparent and straightforward. Ordinal data analyzes data, especially with respect to Likert or other measures in the survey. This is not a new issue. The effectiveness of processing ordinal data as interval data remains controversial in research analysis in various application areas. Here are some details to stay in mind:
Statistical tests: Researchers sometimes treat ordinal data as interval data because they claim that parametric statistical tests are more powerful than nonparametric alternatives. In addition, inferences from parametric tests are easier to interpret and provide more information than nonparametric options.
Focus on Likert Scales: However, treating ordinal data as interval data without examining the values in the dataset and the purpose of the analysis can mislead or misrepresent the findings. To better analyze scalar data, researchers prefer to consider ordinal data as interval data and focus on the Likert scale.
Median or range for examining data: The universal guideline is that if the data is on a normal scale, the mean and standard deviation are unfounded for detailed statistics, similar to parametric analysis based on a normal distribution. It suggests that it is a parameter. Nonparametric tests are based on the appropriate median or range for inspecting the data.
Q29) What are the best practices for analyzing Likert scale results?
A29) Due to the discrete, ordered, and limited scope of Likert element data, there has long been controversy over the most logical way to analyze Likert data. The first option is between parametric and nonparametric tests. The strengths and weaknesses of each type of analysis are commonly described as follows:
Q30) Explain the Benefits of Likert Scale.
A30) There are many advantages to using the Likert scale in market research they are:
Likert scale surveys are a comprehensive method for measuring feedback and information, making them much easier to understand and respond to. This is an important question for measuring opinions and attitudes on a particular topic and will be very helpful in the next step of the survey.
If your organization needs more information about this and other questions within the platform, please refer to our online chat and tell us about your project. We are happy to provide you with one of the best research tools for these needs.
Q31) What is the Semantic Differential Scale?
A31) The Semantic Differential Scale is a survey or survey rating scale that asks people to rate a product, company, brand, or any "entity" within the framework of a multipoint rating option. These survey response options are grammatically opposite adjectives. For example, love-hate, satisfaction-dissatisfaction, and likely to come back-it is unlikely to come back with an intermediate option in between.
Surveys or surveys using the Semantic Differential Scale Survey feature are the most reliable way to get information about people's emotional attitudes towards a topic of interest.
Well-known American psychologist Charles Egerton Osgood invented the Semantic Differential Scale to record and effectively utilize this "meaning" of emotional attitudes towards the entity.
Osgood conducted this study in an extensive database and found that the three scales are generally useful, regardless of race, culture, or language.
a) Estimate: A combination similar to good or bad.
b) Authority: Powerful-A pair on the week line.
c) Active: Active-Passive-like combo.
Researchers can use these combinations to measure a variety of subjects, such as customer prospects and employee satisfaction with future product launches.
Q32) What is the Semantic Differential Scale?
A32) It's very reliable because it's easy to understand and popular. Data collection is accurate due to the variety of questions in these surveys.
Researchers use semantic differential scale questions to describe a product, organization, or service, likely / unlikely, happy / sad, like / dislike service, etc., at the extremes of this scale. Ask respondents to rate with multipoint questions that use polar adjectives.
Semantic differential scale examples and question types
1. Slider Rating Scale: Questions with graphical sliders provide respondents with a more interactive way to answer questions on the Semantic Differential Scale.
2. Non-slider rating scale: Non-slider questions use radio buttons that are common to the look and feel of traditional research. Respondents are accustomed to answering.
3. Free-form questions: These questions give users the freedom to express their feelings about an organization, product, or service.
4. Ordering: Ordering questions provide a range for assessing the parameters that respondents find best or worst, depending on their personal experience.
5. Satisfaction Rating: The simplest and most eye-catching Semantic Differential Scale question is the Satisfaction Rating question.
Q33) What are the Benefits of Semantic Differential?
A33) Benefits of Semantic Differential
Q34) What all things to consider when using semantic differentials?
A34) Question Pro provides the resources you need to collect a wide variety of data of all kinds, including the Semantic Differential Survey feature. However, when looking for an alternative solution provider, consider the following:
Create: What do I need to get a free account? Can you sign up in just a few seconds? Is it easy to create a survey after logging in? Can you create your study within minutes, or are you struck by tabs, options, and various windows that are difficult to manage? How about customization? Is it easy to edit the survey to suit your specific needs?
Question Pro gives you the options you need to create a survey.
Distribution: How difficult is it to send once the survey is complete? Does your solution provide access to edit and manage personal mailing lists for distribution? Why not provide a direct hyperlink so that you can easily share your survey on Facebook and LinkedIn? How about providing embeddable HTML code for posting your research on a website or blog?
Question Pro provides all the solutions mentioned.
Analysis: How easy is it to report the results once the respondents' responses have been collected? Can I access the snapshot during the collection process to get an overview of the results? How easy is it to filter data? What if you need a more detailed analysis? Can I export the resolution & Would you like to put them in Excel for a more detailed evaluation?
With Question Pro you can do all of the above.
Using Semantic Differential Scale: Question Pro Process
1. Create a survey: Question Pro gives you access to over 350 different templates for distribution, editing, or simply brainstorming new ideas. Customize the question, question type, order, and color to your exact needs.
2. Collect Answers: Once you've created your survey, you can distribute it by email, direct link, or embed HTML code in your website or blog. You can view a snapshot report of the current response in real time.
3. Analyze Survey Results: Once the survey is complete and the responses have been collected, you can customize and view detailed reports at your fingertips. You can apply filters, manipulate pivot tables, and view trend analysis.
Q35) Define Paired Comparison.
A35) Definition: Paired comparison scaling may be a comparison scaling technique that needs respondents to ascertain two objects at an equivalent time and choose one consistent with defined criteria. The resulting data is actually ordered.
Paired comparison scaling is usually used when the stimulus object may be a physical product. The comparison data thus obtained are often analyzed by either method. First, researchers can calculate the share of respondents preferring one object to a different by adding a matrix of every respondent, dividing the entire by the amount of respondents, then multiplying by 100. this manner you'll evaluate all stimulus objects. at an equivalent time.
Second, under the idea of transition (if brand X takes precedence over brand Y and brand Y takes precedence over brand Z, it means brand X takes precedence over brand Z). Paired comparison data are often converted in order . to work out the order, researchers identify the amount of times an object is prioritized by summing all the matrices.
The paired comparison method is effective when the amount of objects is restricted because it requires an immediate comparison. Also, an outsized number of stimulus objects can make comparisons cumbersome. Also, if you violate the transitive assumptions, the order during which the objects are placed can bias the results.
All potential options are visually compared to offer an instantaneous overview of the proper decision. This makes it easy to match the relative importance of the other criteria. Paired comparisons are often a really useful gizmo when there's no objective data available to form a choice. This method is additionally referred to as pair comparison and pairwise comparison.
Q36) How does chi-square statistics work?
A36) Chi-square statistics are most commonly used when evaluating independence tests (also known as bivariate tables) using crosstabs. The distributions of the two categorical variables are displayed simultaneously by crosstab, and the intersection of the variable's categories is displayed in the table cell. By comparing the pattern of responses observed in the cell with the pattern expected if the variables are truly independent of each other, the independence test assesses whether there is an association between the two variables. I will. By calculating chi-square statistics and comparing them to the critical values of the chi-square distribution, researchers can assess whether the observed number of cells is significantly different from the expected number of cells.
Calculating chi-square statistics is fairly straightforward and intuitive.
Here, fo = frequency observed (count observed in the cell)
And the expected frequency if there is no relationship between fe = variables
The chi-square statistics shown in the equation are based on the difference between what is actually observed in the data and what is expected if the variables are not really related.
Q37) How are chi-square statistics performed in SPSS and how are the outputs interpreted?
A37) Chi-square statistics are displayed as an option when requesting crosstabs in SPSS. The chi-square test is labelled as output. Pearson Chi-Square is a chi-square statistic used in the independence test.
You can evaluate this statistic by comparing the actual value with the critical value found in the chi-square distribution (degrees of freedom are calculated as row-1 x column-1), but it is easy to find. I will. The p value provided by SPSS. This value is labelled to conclude the hypothesis with 95% confidence. Sig. Sec.
(This is the p-value of the chi-square statistic) must be less than .055 (alpha level associated with a 95% confidence level).P value less than .05 (labelled Asymp? Sig.)? If so, we can conclude that the variables are not independent of each other and the categorical variables are in a statistical relationship.
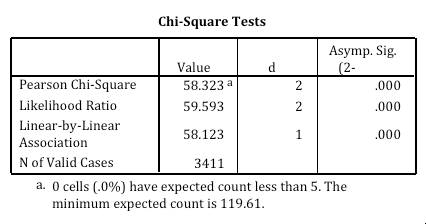
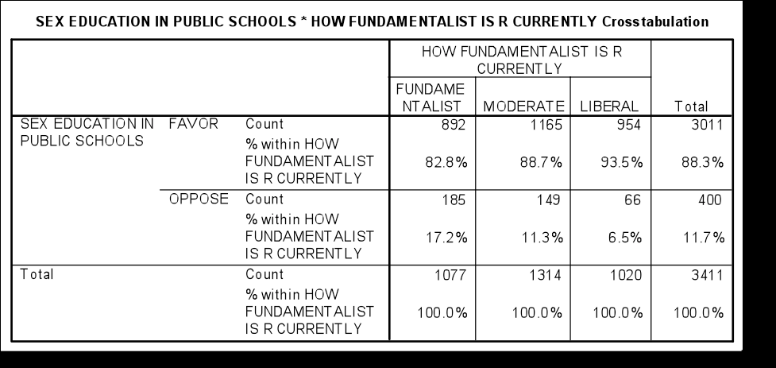
In this case, there is a link between fundamentalism and public-school views on sex education. 17.2% of fundamentalists oppose teaching sex education, while only 6.5% of liberals oppose it. The p value indicates that these variables are not independent of each other and that the categorical variables are statistically significant.
Q38.) What are your special concerns regarding chi-square statistics?
A38) There are some important considerations when evaluating crosstabs using chi-square statistics. Due to the chi-square calculation method, it is very sensitive to sample size. If the sample size is too large (~ 500), almost all small differences will appear statistically significant. It's also sensitive to distribution within cells, and SPSS will display a warning message if there are less than 5 cell cases. This can be addressed by always using a categorical variable with a limited number of categories (for example, combining categories to create a smaller table as needed).
Q39) What is a Nonparametric Test?
A39) Nonparametric tests are mathematical methods used in statistical hypothesis testing and make no assumptions about the frequency distribution of the variables being evaluated. Nonparametric experiments are used when there is biased data and consist of methods that do not depend on the data associated with a particular distribution.
The term nonparametric does not mean that these models have no parameters. In fact, the characteristics and number of parameters are very flexible and undefined. Therefore, these models are called distribution-free models.
Q40) What does a nonparametric test mean?
A40) Nonparametric test is one of the methods of statistical analysis, it does not require a distribution to meet the required assumptions and must be analyzed. Therefore, nonparametric tests are called non-distributed tests.
Q41) What are the benefits and demerit of nonparametric tests?
A41) The advantage of nonparametric tests over parametric tests is that they do not take into account data assumptions.
The disadvantages of nonparametric tests are:
Q42) Is chi-square a nonparametric test?
A42) Yes, the chi-square test is a nonparametric test in statistics and is called a non-distributed test.
Q43) Mention different types of nonparametric tests.
A43) The different types of nonparametric tests are:
Q44) When do you use parametric and nonparametric tests?
A44) If the mean of the data more accurately represents the center of the distribution and the sample size is large enough, you can use a parametric test. On the other hand, if the median of the data more accurately represents the center of the distribution and the sample size is large, you can use a nonparametric distribution.
Q45) What is the Testing the assumptions of Classical Normal Linear Regression?
A45) Linear regression is an analysis that evaluates whether one or more predictors explain dependent (reference) variables. There are five important assumptions about regression.
Note on sample size. As a rule of thumb for sample size, rectilinear regression requires a minimum of 20 cases for every experimental variable of the analysis.
First, rectilinear regression requires that the connection between the independent and dependent variables be linear. Checking for outliers is additionally important because rectilinear regression is sensitive to the consequences of outliers. Linearity assumptions can best be tested on scatter plots. the subsequent two examples show two cases, one with no linearity and one with little linearity.
Second, rectilinear regression analysis requires that each one variables be multivariate normal. This assumption is best seen during a histogram or Q-Q plot. Normality is often confirmed by a goodness-of-fit test like the Kolmogorov-Smirnov test. Nonlinear transformations (such as logarithmic transformations) may fix this problem if the info isn't normally distributed.
Third, rectilinear regression assumes that the info has little or no multicollinearity. Multicollinearity occurs when the independent variables are too highly correlated.
Multicollinearity are often tested on three central criteria:
1) Matrix – When calculating a Pearson bivariate matrix between all independent variables, the coefficient of correlation should be but 1.
2) Tolerance – Tolerance measures the effect of 1 experimental variable on all other independent variables. The margin of error is calculated within the first rectilinear regression analysis. In these first-step regression analyzes, the margin of error is defined as T = 1 – R². If T 10, there's certainly multicollinearity between the variables.
If you discover multicollinearity in your data, cantering the info (that is, subtracting the mean of the variables from each score) may help solve the matter. However, the simplest thanks to affect this problem is to get rid of the experimental variable with a high VIF value.
Fourth, rectilinear regression analysis requires that the info have little or no autocorrelation. Autocorrelation occurs when the residuals aren't independent of every other. for instance, this usually happens when the stock price isn't independent of the previous price.
4) Conditional Index – Conditional Index is calculated using correlational analysis of independent variables. Values between 10 and 30 indicate mediocre multicollinearity of rectilinear regression variables, and values above 30 indicate strong multicollinearity.
If multicollinearity is found within the data-centric data, it's going to help solve the matter by subtracting the typical score. Another alternative to tackle the matter is to perform an element analysis and rotate the factors to make sure their independence during a rectilinear regression analysis.
Fourth, rectilinear regression analysis requires that the info have little or no autocorrelation. Autocorrelation occurs when the residuals aren't independent of every other. In other words, the worth of y (x + 1) isn't independent of the worth of y (x).
You can see the autocorrelation within the scatter plot, but you'll use the Durbin-Watson test to check a rectilinear regression model of the autocorrelation. Durbin-Watson's d tests the null hypothesis that the residuals aren't linearly autocorrelated. d can take values between 0 and 4, but values near 2 indicate no autocorrelation. As a rule of thumb, a worth of 1.5




